【论文阅读】ASPS: Augmented Segment Anything Model for Polyp Segmentation
论文链接:https://arxiv.org/abs/2407.00718
Code: https://github.com/HuiqianLi/ASPS
来源: Medical Image Computing and Computer Assisted Intervention – MICCAI 2024
摘要:
背景:息肉分割对于结直肠癌的早期诊断非常关键。最近出现的SAM展现了在大规模数据集预训练基础上的巨大潜力,有望推动息肉分割技术的进步。
挑战:SAM在应用到内窥镜图像时遇到两个主要问题:
- 结构偏向:作为基于Transformer的模型,偏重于全局和低频信息,可能忽略细节,从而引入偏差。
- 领域差异:SAM是在自然图像上预训练的,直接应用到内窥镜图像时,表现出较差的
out-of-distribution(OOD)性能,导致预测不精准、置信度偏差。
方法:为解决这些问题,本文提出Augmented SAM for Polyp Segmentation(ASPS),包含两个核心模块:
- Cross-branch Feature Augmentation(CFA):结合可训练的
CNN编码器(增强局部和高频信息)与固定的视觉Transformer(ViT)编码器,实现域知识的融合,弥补SAM在细节捕获上的不足。 - Uncertainty-guided Prediction Regularization(UPR):利用
SAM输出的IoU得分作为指导,调整训练过程中的预测不确定性,增强模型对不同域数据(尤其是OOD数据)的适应能力。
结论:大量实验验证了该方法在提升SAM在息肉分割中的效果和泛化能力方面的有效性。
1. 引言
背景和现状:
-
重要性: 息肉分割是结直肠癌诊断中的关键工具,有助于有效干预和及时治疗。
-
已有研究:
- 使用不同的Transformer或卷积方法,如Polyp-PVT、SSFormer利用金字塔视觉Transformer(Pyramid Vision Transformer);
- CFANet结合边界信息进行多层次特征融合;
- Endo-FM捕获空间-时间依赖关系,构建基础模型。
这些方法在模型大小有限的情况下,仍面临特征表达和提取能力不足的问题,难以充分刻画息肉的形态和特征。
-
数据集局限: 数据规模有限影响模型的多样性和泛化能力。
引入SAM(Segment Anything Model):
- 优势:
- SAM在大规模数据集(SA-1B)上预训练,展现出极强的分割能力,带来了新的视角
- 增强的表示和特征提取能力,优于之前的方案。
- 不足:
- 由于训练于自然图像,存在领域差异(domain gap),导致在息肉图像上的性能不理想。
- 不能有效捕捉息肉的特征,学习偏差明显。
- 其对提示(prompts)的依赖也降低了临床应用的便利性。
- 现有改进方案如MedSAM和SAMUS,要么依赖提示、要么模型复杂、只适合处理小图像,限制其实用性。
贡献和方案:
- 提出基于SAM的新方法(ASPS),从**领域适应(domain adaptation)**角度,提升特征提取和泛化能力,且不依赖于提示。
- 核心模块:
- 交叉分支特征增强(CFA):加入一个可训练的卷积神经网络编码器分支,与固定的ViT编码器配合,捕获多尺度、多层次特征,补充SAM在细节捕捉上的不足。
- 不确定性引导的预测正则化(UPR):调整归一化层,利用提示信息减少训练中的不确定性,改善模型对未知数据(OOD)的表现和泛化能力。
总结:
- 通过这些改进,作者构建了一个名为ASPS(Augmented SAM for Polyp Segmentation) 的模型,实现在无需提示的情况下,自主提升息肉分割的性能和泛化能力。
- 在五个常用息肉数据集上的广泛实验验证了该方法的有效性和优越性。
2. 方法
总体架构(Overview): 网络结构如图1所示,旨在解决SAM模型存在的领域退化(domain degradation)问题,即模型在不同数据域(如从自然图片到息肉内窥镜图像)上的表现下降。
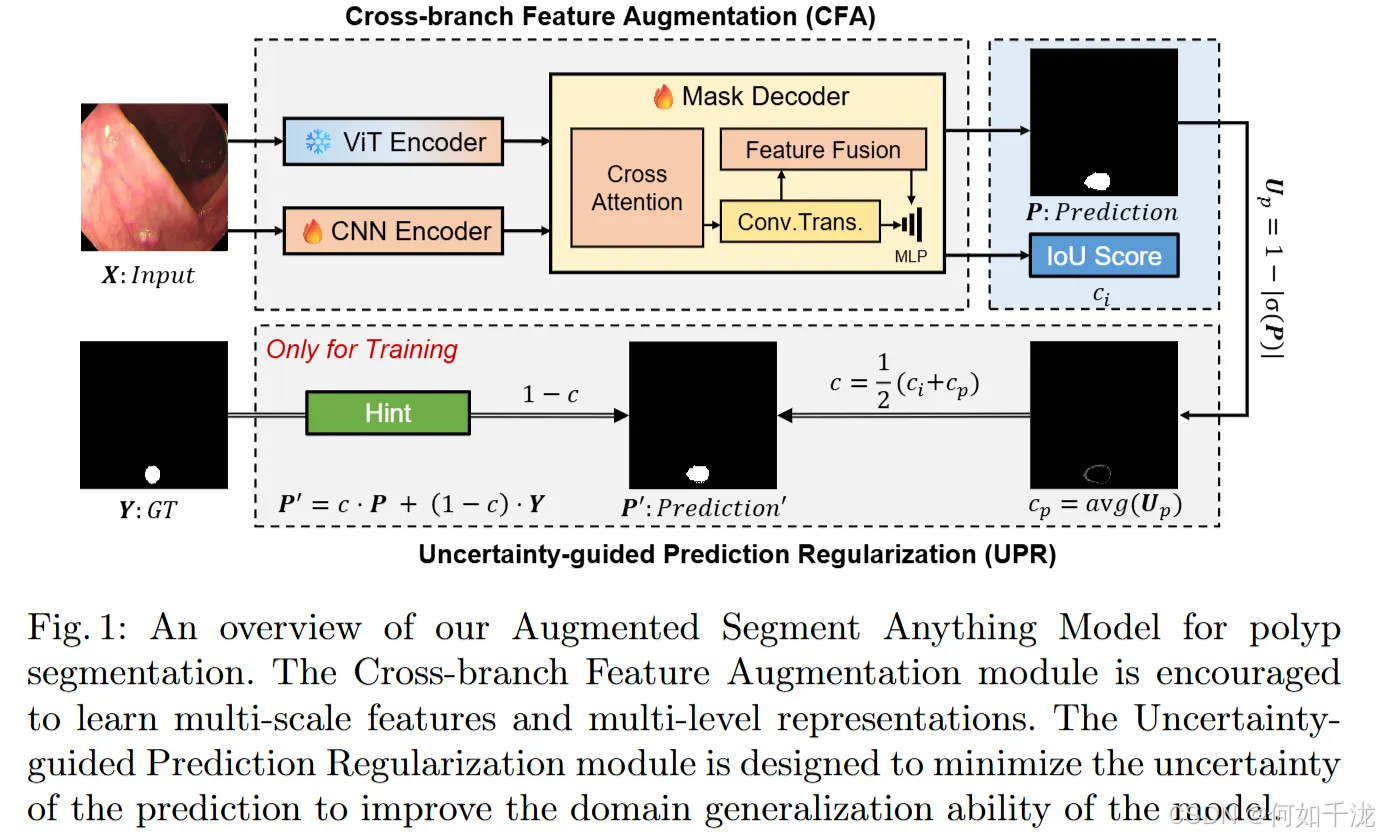
主要目标:
- 增强特征提取能力:让模型更好地捕捉息肉图像中的关键信息。
- 提升领域泛化能力:确保模型在不同来源或条件下都能保持良好的分割性能。
引入的两个关键模块:
- CFA(Cross-branch Feature Augmentation,交叉分支特征增强)模块:
- 将训练中的 CNN 编码器提取的局部、高频信息与预训练的 ViT(视觉Transformer)全局信息结合。
- 这种融合实现特征的泛化学习,提高模型对不同数据域的适应性。
- 具体机制包括:从深层(高抽象)信息帮助改善浅层(低级)特征,结合浅层的空间位置(通过引入位置编码或浅层特征)以增强边界和细节的表达能力。
- UPR(Uncertainty-guided Prediction Regularization,不确定性引导的预测正则化)模块:
- 在训练过程中,旨在减少预测的不确定性,提升模型的信心校准(confidence calibration)。
- 利用提示(hints),即利用真实的标注信息(ground truth)作为辅助,指导模型更准确地学习。
- 采用一种基于预测不确定性(如信心值或置信度)的训练策略,让模型在训练中更稳定、可靠。
训练方式:网络采用端到端(end-to-end)训练,不依赖额外的提示(prompt),同时优化这两个模块以实现最优性能。
2.1 跨分支特征增强模块
问题背景: 虽然SAM在许多图像分割任务取得了成功,但在息肉分割中存在不足,主要原因是其图像编码器(Vision Transformer,ViT)不能充分有效地从未见过的内窥镜图像中提取足够的特征。
改进目标:为了增强特征提取能力,设计了CFA(Cross-branch Feature Augmentation)模块,其作用是学习多尺度和多层次的特征表示。
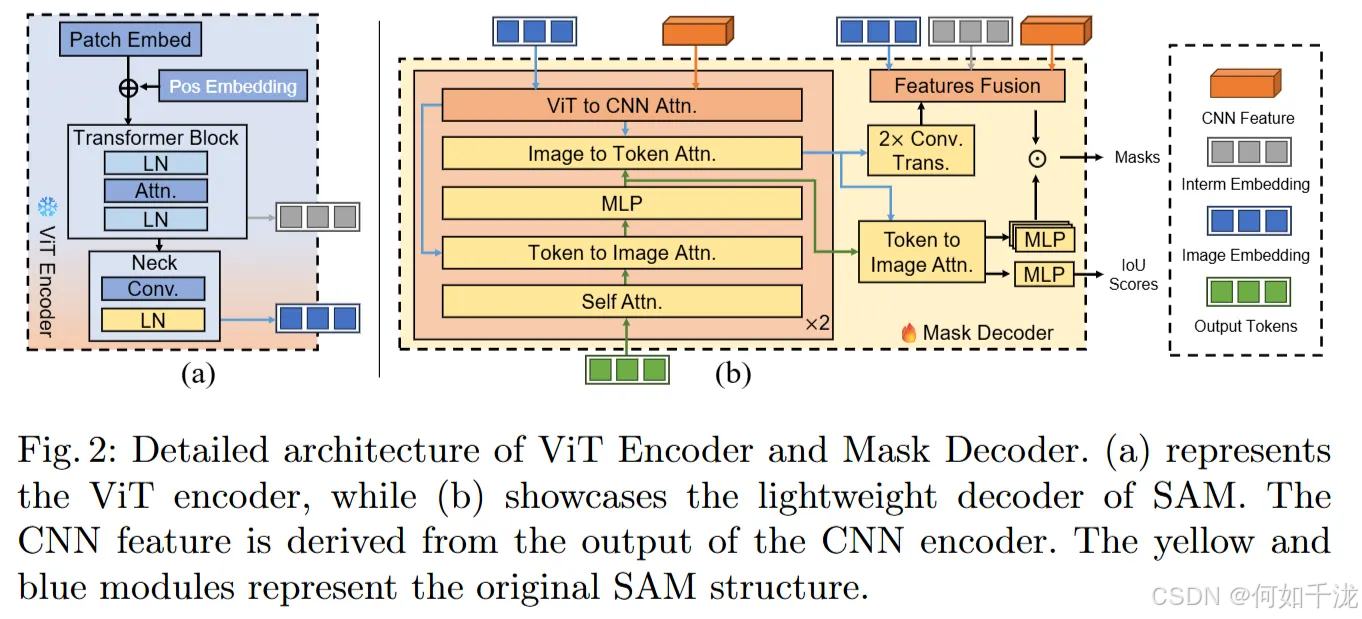
模型架构修改:
-
原始的SAM架构中含有提示(prompt)输入和提示编码器组件,为了进行自动化无需提示的分割,作者将这些部分移除。
-
保留的部分包括图像编码器(图像特征提取部分)和掩码解码器(用以生成分割掩码)。
-
融合不同特征的设计思路:研究发现,ViT更关注低频信号(全局信息),而卷积神经网络(CNN)更擅长处理高频信号(局部、细节信息)。因此,引入平行的CNN编码支路,用以补充ViT在高频和局部特征的不足。
-
跨分支注意机制(Cross-branch Attention):
-
在掩码解码器中加入多头交叉注意(multi-head cross-branch attention),实现来自ViT和CNN两个编码器的特征融合。
-
数学表达式如下:
CrossBranchAttention(Fc,Fv)=Softmax(QKTd)V\text{CrossBranchAttention}(F_c,F_v)=\text{Softmax}(\frac {QK^T} {\sqrt {d}})V CrossBranchAttention(Fc,Fv)=Softmax(dQKT)V
其中:
- Q=FvWQQ = F_v W^QQ=FvWQ(ViT特征经过线性变换获得查询)
- K=V=FcWKK = V = F_c W^KK=V=FcWK(CNN特征经过线性变换获得键和值)
- ddd 为每个注意头的通道数
-
-
位置编码的替换:因为CNN特征提供更准确的空间位置(空间信息),将原本SAM掩码解码器中的位置嵌入(position embedding)替换为CNN编码器的输出特征,提高空间细节的表达。
-
多次注意融合:该交叉注意机制在掩码解码器中重复使用两次,以确保来自ViT和CNN的多尺度、多层次特征得到充分整合。
-
多层次特征整合: 除了跨分支注意,还结合了不同层级的特征:
- ViT的中间浅层局部特征(边缘和细节)
- ViT的最终全局特征(整体上下文信息)
- CNN的最终特征(高频细节和空间位置)
这样可以充分利用边缘信息、全局上下文和局部空间细节,提高分割的精度。
2.2 不确定性引导的预测正则化模块
为了增强SAM(Segment Anything Model)在特定领域(如内窥镜图像)中的泛化能力,作者提出的训练策略,特别是关于调整归一化层(LayerNorm)以及利用置信度调节进行训练引导的方法。具体内容可以分为以下几个要点:
调整归一化层(LayerNorm)以缓解域转移问题
-
SAM是在自然图片上训练的,但在特定领域如内窥镜图像上表现不佳,主要因数据分布的差异引起的内部协变量偏移(internal covariate shift)。
-
通过细调模型的归一化层(LayerNorm),使模型更好地适应目标域(内窥镜数据)中的数据分布,从而提高泛化能力。
-
具体地,把SAM的Vision Transformer(ViT)编码器中的LayerNorm分成两个部分:
- Transformer块的归一化(transformer block norm)
- 颈层归一化(neck layer norm),
最终只训练“颈层”归一化(靠近输出的层),实现针对性微调,这一做法类似于通过调整归一化参数解决域差异问题。
利用模型输出的不确定性(Confidence)辅助训练
- SAM提供了一个IoU分数输出,用来表示预测的“置信度”或不确定性。低不确定性对应更高的预测可靠性。
- 然而,在面向未知或新域数据时,SAM可能在高置信度下给出错误预测,这不利于模型的可靠性和域适应。
- 为此,在训练过程中减小模型的预测不确定性(即提高置信度),用“ground truth(真实标签)”作为一种“提示”指导模型学习。
利用置信度调节“提示”引入
c=12(ci+cp)c = \frac {1} {2}(c_i + c_p) c=21(ci+cp)
- cic_ici:SAM的IoU得分,作为图像层级置信度;
- cpc_pcp:据像素不确定性UpU_pUp计算像素层面置信度,其中Up=1−σ(∣P∣)U_p=1-\sigma(|P|)Up=1−σ(∣P∣),PPP为预测分割结果;
这个信心值决定了是否用ground truth作为“提示”帮助模型:置信度低时,模型需要“提示”以学习正确的掩码(mask)。具体做法是将预测P和真实标签Y通过权重c线性结合:P′=c⋅P+(1−c)⋅YP^′ = c · P + (1 − c) · YP′=c⋅P+(1−c)⋅Y。
引入“信心损失”以防模型过度依赖提示
整体损失是分割损失Ls=Lce+0.5⋅Ldice+LmseL_s=L_{ce}+0.5 \cdot L_{dice} + L_{mse}Ls=Lce+0.5⋅Ldice+Lmse与信心损失Lc=−log(c)L_c = -log(c)Lc=−log(c)之和:
L=Ls+λLcL = L_s + \lambda L_c L=Ls+λLc
其中λ是超参数,用于平衡两部分的影响。
- 如果只最小化分割损失,模型会试图让c趋向0(即总是直接用ground truth),这会导致模型无法自主学习和适应。
- 因此引入信心损失Lc=−log(c)L_c = -log(c)Lc=−log(c),这个损失会在c趋向0时变得很大,从而惩罚模型试图总是用
ground truth,促使模型自己学会合理估计置信度。
3. 实验
数据集(Datasets):实验在五个常用的息肉分割数据集上进行:Kvasir-SEG、CVC-ClinicDB、CVC-ColonDB、ETIS、EndoScene。
- 训练集:使用Kvasir-SEG中900张图像和CVC-ClinicDB中550张图像。
- 测试集:分别包括100张来自Kvasir、62张来自CVC-ClinicDB、380张来自CVC-ColonDB、60张来自EndoScene、以及196张来自ETIS。
实现细节(Implementations):
- 使用PyTorch框架,在一台NVIDIA RTX 3090 GPU上进行实验。
- 优化器采用AdamW,训练16,000次迭代,学习率1e-5,权重衰减1e-4,批次大小为4。
模型组成:
- CNN部分采用SegNeXt。
- 输入图片尺寸:ViT分支为1024×1024,CNN分支为320×320。
评估指标:使用Dice系数和IoU。
结果与分析:将提出的方法与一些领先的分割模型和某些基于SAM的方法进行了对比。
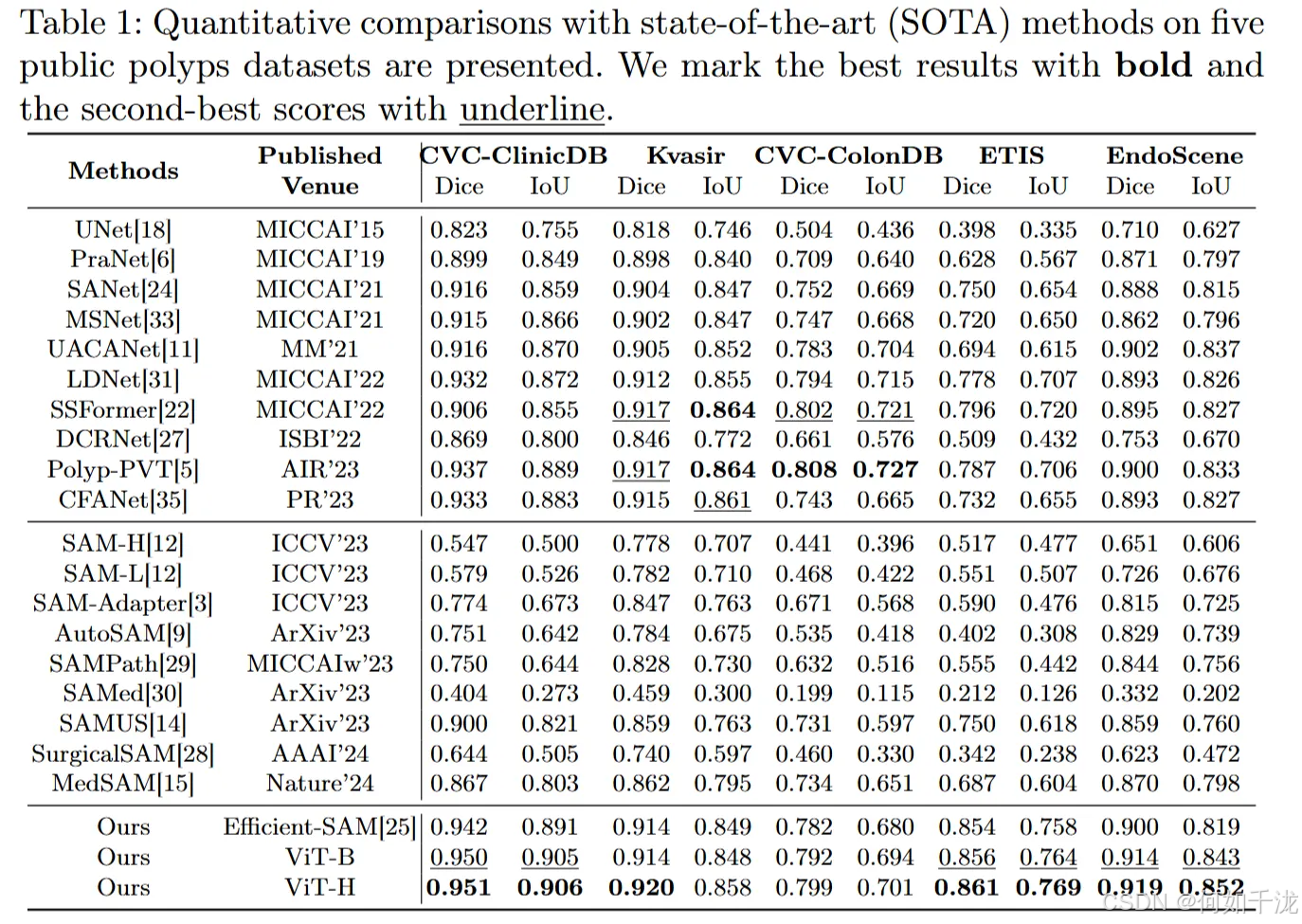
- 性能表现:在Kvasir和CVC-ColonDB上提升相对较小,但在CVC-ClinicDB、ETIS和EndoScene上有显著改进。
- 对比概述:
- Polyp-PVT在所有数据集上表现不错,平均Dice为0.870,IoU为0.804。本方法达到了0.890(Dice)和0.817(IoU),显示出其有效性。
- 其优越性尤其体现在所有五个数据集中的优势,超过了所有SAM(Transformer基础)方法。
- 注意事项:像MedSAM和SAMUS这类方法仍使用了Prompt机制,实验中则不使用Prompt。由于训练参数不匹配,未能取得理想的效果的模型包括SurgicalSAM和SAMed,但SAMUS通过引入CNN辅助分支验证了CNN的有效性。
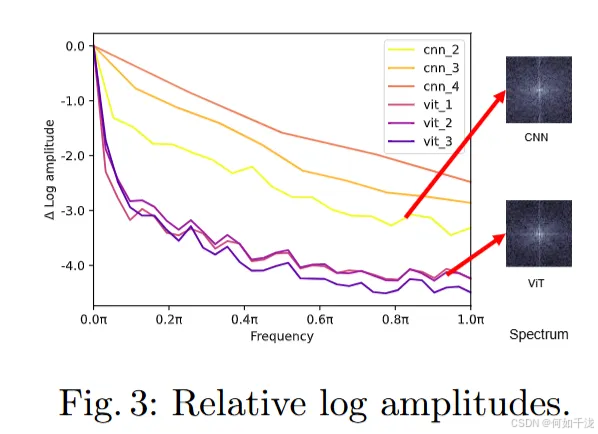
傅里叶分析:通过傅里叶变换显示,CNN分支比ViT基础模型捕获了更多的高频信号,强调其高频信息提取能力。
定性的结果:作者的预测结果更接近真实标签。

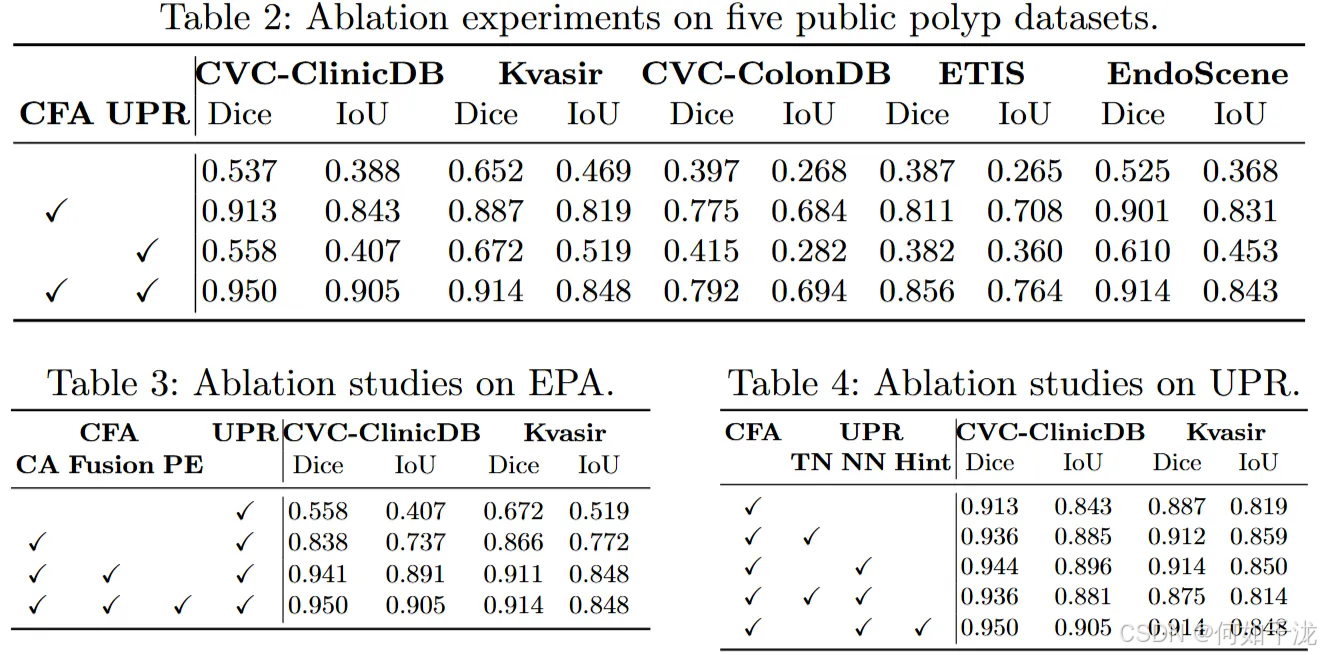
消融实验(Ablation Study):
- 基础模型:以ViT-B为主干,去掉prompt编码器,作为对比。
- CFA验证:实验对比了多项内容,包括交叉注意(CA)、多层次特征融合(Fusion)和位置嵌入替换(PE),结果显示加入这些模块显著提升了性能(Dice提升31.7%,IoU提升41.4%)。
- UPR验证:比较了只训练Transformer块归一化(TN)、只训练颈层归一化(NN)以及两者同时训练(Both),发现只有训练颈层归一化(NN)达到了更优性能。
4. 结论
本文提出的一种新颖的多任务方法,名为ASPS(Augmented Segment Anything Model for Polyp Segmentation),旨在改善原始的SAM模型在息肉分割任务中的不足。具体内容如下:
目标:解决SAM模型在信息捕获方面存在的限制,弥合自然图像与内窥镜图像之间的域差异(域适应问题)。
核心组件:
- CFA模块(Cross-branch Feature Augmentation):引入一个可训练的卷积神经网络(CNN)编码器分支,用来补充冻结的Vision Transformer(ViT)编码器,从而融合多尺度和多层次的特征,增强模型的特征提取能力。
- UPR模块(Uncertainty-guided Prediction Regularization):通过引入提示信息(hints)和调节归一化层(Normalization Layer),在训练过程中减少模型的不确定性,促进模型在内窥镜图像领域的适应能力。
验证效果:通过在五个常用的息肉数据集上的实验,验证了所提方法的有效性和优越性。