性能革命的底层逻辑:深入理解 Spring Cloud Gateway 的 Reactor 核心
性能革命的底层逻辑:深入理解 Spring Cloud Gateway 的 Reactor 核心
前几天在Spring Cloud Gateway 补充了接口签名,现在又来回顾下
如果你曾好奇 Spring Cloud Gateway 为什么能以极高的吞吐量处理数以万计的并发请求,那么答案就藏在 响应式编程(Reactive Programming) 的核心库中:Project Reactor。
它彻底改变了我们处理 I/O 密集型任务的方式,将传统的“阻塞等待”模式升级为高效的“事件驱动”模式。简单来说,Reactor 的作用就是让你的程序不再浪费时间去等待。,在发生IO阻塞的地方,线程可以去干点其他事情,而不是傻傻的等待IO完成再继续干事情。
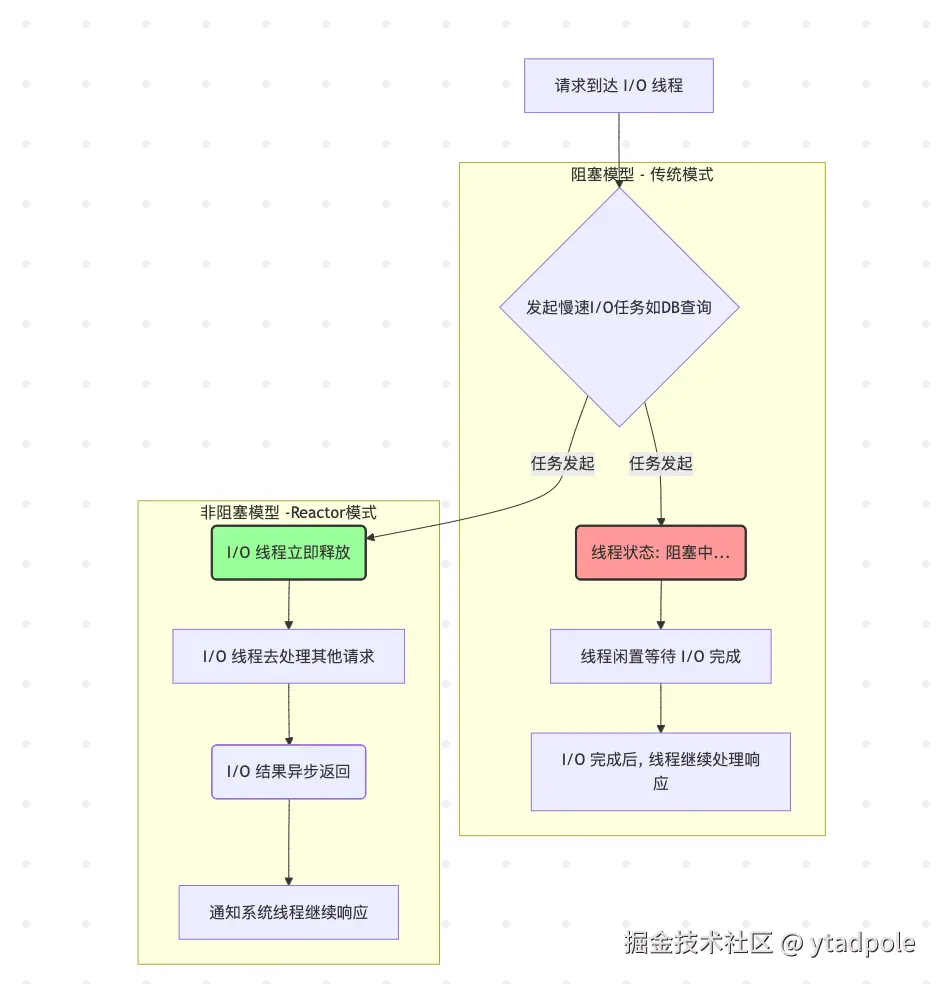
传统模式的瓶颈
在传统的 Java Web 应用中,系统通常采用 “每请求一线程”(Thread-per-Request) 模型。当一个请求需要等待 I/O 操作(例如数据库查询或微服务调用)时,处理该请求的线程就会闲置等待,造成资源浪费。
Reactor 的解决方案:非阻塞 I/O。
在 Spring WebFlux/Gateway 中,系统只使用少数几个线程(通常与 CPU 核心数一致)。当一个请求开始等待 I/O 时,线程会立即被释放,去处理其他请求。这使得 极少的线程就能高效处理大量的并发连接,将系统瓶颈从线程数量转移到 CPU 核心的处理速度。
Reactor:数据流与背压
响应式编程提供了很多好处,能够非阻塞化我们的程序,对程序的执行线程进行合理的管控,以及更加方便的处理一些异常情况提升稳定性。
响应式编程的核心在于将一切视为异步数据流(Data Streams) 。为了确保数据流动稳定,Reactor 遵循 Reactive Streams 规范:
- Publisher (发布者) 与 Subscriber (订阅者): 构成了数据流的源头和终点。
- 背压(Backpressure): 这是流控的关键。它允许下游Subscriber主动通过
request(n)方法向上游请求自己能处理的数据量,从而防止生产者发送过多数据而淹没系统。
Mono 与 Flux
Project Reactor 用两个核心类型来表示这些数据流:
| 主角 | 含义 | 数据量范围 | 典型应用场景 |
|---|---|---|---|
| Mono | 单一/空流 | 0 或 1 个元素 | 查询单个用户、异步操作的完成信号 (Mono<Void>) |
| Flux | 连续流 | 0 到 N 个元素 | 查询列表、持续的日志消息、WebSocket 连接 |
在 Spring Cloud Gateway 中,你随处可见 Mono<Void>,它代表我已启动一个异步操作,请等待其完成信号。
驱动异步:操作符
在 Filter 或业务逻辑中,我们使用 操作符 (Operators) 来声明式地处理数据流。
map()(同步转换): 接收一个元素,并同步地将其转换为另一种类型。flatMap()(异步转换与串联): 它是异步操作的连接器。 当你需要在一个流的结果基础上发起另一个异步 I/O 操作时,flatMap会立即订阅这个新的异步流(例如 HTTP 请求返回的Mono),在不阻塞当前线程的情况下,将其结果扁平化地合并到主数据流中。
操作符代表能做什么动作,还有些其他的操作符,转换与整形,过滤与限流,组合与聚合,辅助与副作用。这里不详细阐述了。
非阻塞与阻塞
下面对比一个在 Gateway Filter 中常见的异步转发场景:
响应式代码(非阻塞)
// 串联异步I/O:在不阻塞线程的情况下,依次获取ID、查询用户、进行鉴权
Mono.just("user-123") .flatMap(userId -> userService.getUserDetailsAsync(userId)) // I/O等待时,线程释放.flatMap(user -> authService.checkPermissionAsync(user)).onErrorResume(e -> Mono.just(false)); // 错误恢复
// 优势:线程资源利用率极高,高并发稳定
传统阻塞代码(后果)
// 传统阻塞逻辑
public Boolean checkAuthBlocking(String userId) {UserDetails details = userService.getUserDetailsBlocking(userId); // !!! 线程在这里被挂起等待!Boolean hasPermission = authService.checkPermissionBlocking(details); // !!! 线程再次被挂起等待!return hasPermission;
}
// 后果:在高并发下,线程池很快耗尽,新请求被延迟或拒绝。
调度器
在 Reactor 中,我们不能直接操作线程,而是通过 调度器(Scheduler) 来管理线程池。你可以把调度器看作是 Reactor 的线程管家。
核心机制:subscribeOn vs. publishOn
这两个操作符负责在流的不同阶段进行线程的切换:
| 操作符 | 作用范围 | 类比 | 关键用途 |
|---|---|---|---|
subscribeOn(S) | 影响整个流(从源头到订阅)。无论它被放在链条的哪个位置,它都决定了流的起始执行线程。 | 决定你的产品在 哪个工厂 开始生产。 | 用于将 阻塞 I/O 任务转移到专用的线程池(如 Schedulers.boundedElastic()),以解放 WebFlux 的主 I/O 线程。 |
publishOn(S) | 只影响它下游的操作符。 | 决定从这里开始,改用 哪家快递公司 进行派送。 | 用于在处理过程中,将执行上下文从一个线程池切换到另一个线程池。 |
线程切换
假设我们有一个简单的流,通过 publishOn 切换线程:
System.out.println("主线程: " + Thread.currentThread().getName());Flux.just(1).map(i -> {// 执行在主线程System.out.println("Map 1 (当前线程): " + Thread.currentThread().getName()); return i;}).publishOn(Schedulers.parallel()) // <--- 线程切换点.map(i -> {// 执行在 Schedulers.parallel 的线程池中System.out.println("Map 2 (当前线程): " + Thread.currentThread().getName());return i;}).blockLast();
运行结果(简化):
主线程: main
Map 1 (当前线程): main // 初始执行
Map 2 (当前线程): parallel-1 // 线程已切换
publishOn(Schedulers.parallel()) 告诉 Reactor:从这里开始的所有下游操作,请在 parallel() 线程池上执行。这就是 Reactor 实现 细粒度并发控制 的核心。
调度器的两大实际用途
调度器和线程切换的核心作用就是:保护系统的 VIP 通道,并确保每种工作都在最合适的场所进行。
1. 隔离与保护(防止阻塞)
- 场景: 在 Spring Cloud Gateway 中,核心的 Netty 线程(I/O 线程)是程序的“高速 VIP 通道”。 如果我们必须调用一个传统的、阻塞的服务(例如遗留系统的 JDBC 数据库查询),我们就必须使用
subscribeOn(Schedulers.boundedElastic())。
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;public Mono<User> findUserReactive(int id) {return Mono.fromCallable(() -> {// [A] 封装:将阻塞调用放入一个可执行任务中String threadName = Thread.currentThread().getName();System.out.println("[Reactor] 任务定义在线程: " + threadName);return findUserBlocking(id); })// [B] 隔离:关键!将这个阻塞任务转移到 Schedulers.boundedElastic 线程池.subscribeOn(Schedulers.boundedElastic());
}
- 好处: 这确保了阻塞任务被转移到一个专用的、弹性伸缩的线程池上去执行,从而解放了 I/O 线程。这就像将“慢速车”引导到专用的慢速车道,保证了高速通道的畅通无阻。
2. 性能优化与精确控制(提高效率)
-
场景: 你的业务逻辑中,前半段是 I/O 操作,后半段是 CPU 密集型的计算。
-
作用: 你可以使用
publishOn()来切换线程池。例如:- I/O 操作 在 Netty 线程上开始(等待时间长)。
- CPU 计算操作 通过
publishOn(Schedulers.parallel())切换到 CPU 核心数匹配的线程池,进行高效的并行计算。
-
好处: 确保每种性质的任务都在最高效的环境中运行,最大化程序的性能。
健壮性:onErrorResume 优雅地处理错误
我们在前面提到了 onErrorResume,它是处理失败的关键。当数据流发出 onError(Throwable) 信号时,为了防止流彻底中断,我们通常使用它来:
- 捕获错误: 识别发生的异常(例如网络超时)。
- 执行恢复逻辑: 在
onErrorResume内部,异步地设置 HTTP 错误状态码,并写入自定义的错误响应体。 - 平稳终止: 最终返回一个
Mono<Void>,取代错误的转发,确保服务实现优雅降级。
场景:将 TimeoutException 转化为 HTTP 503 响应
假设我们在一个 Gateway Filter 中调用下游服务时发生了超时。我们不能让请求崩溃,必须给客户端一个友好的错误提示。
import org.springframework.http.server.reactive.ServerHttpResponse;
import reactor.core.publisher.Mono;
import java.util.concurrent.TimeoutException;// 1. 模拟一个调用失败的下游服务
private Mono<String> callFailingService() {// 假设下游服务超时,发出 onError 信号return Mono.error(new TimeoutException("Upstream Service Timeout."));
}// 2. 带有 onErrorResume 的请求处理逻辑
public Mono<Void> handleRequest(ServerHttpResponse response) {return callFailingService()// 假设这是一个成功的操作,我们用 then() 替代实际的成功处理.then(Mono.empty()) // 3. 【核心】捕获错误并执行恢复逻辑.onErrorResume(TimeoutException.class, error -> {// 3a. 设置 HTTP 状态码(非阻塞操作)response.setStatusCode(HttpStatus.SERVICE_UNAVAILABLE); // 设置 503// 3b. 构建自定义的 JSON 错误响应体String jsonError = "{"code": 503, "message": "Service is temporarily unavailable."}";// 3c. 写入响应体并返回 Mono<Void>(非阻塞操作)// writeWith 返回的 Mono<Void> 代表着数据已写入完成return response.writeWith(Mono.just(response.bufferFactory().wrap(jsonError.getBytes()))).then(); // 确保返回的是 Mono<Void>});
}
核心作用:优雅降级
在这个案例中,onErrorResume 做了两件至关重要的事情:
- 捕获与替换: 它捕获了
TimeoutException这个onError信号,阻止了数据流的崩溃。 - 非阻塞恢复: 它返回了一个新的
Mono<Void>(即response.writeWith(...)的结果),这个新的Mono包含了设置 HTTP 状态码和写入响应体的逻辑,并且整个过程是非阻塞的。
通过 onErrorResume,一个原本会导致连接中断的错误,被转化为一个优雅、可控的 HTTP 503 响应。
SCG 源码分析
我们看看Spring Cloud GateWay里面的org.springframework.cloud.gateway.filter.NettyRoutingFilter#filter代码,它是整个网关请求转发链的终点,负责将请求真正发送到下游微服务。
异步串联的操作
异步串联(相当于我们说的 flatMap)的核心部分是 httpClient 的方法链:
// ...
Flux<HttpClientResponse> responseFlux = getHttpClient(...).request(method).uri(url).send(...) // 异步发送请求体.responseConnection((res, connection) -> {// [A] 这里是处理下游响应的异步逻辑// ...return Mono.just(res); // 内部返回一个 Mono,被外部流扁平化});
// ...
这里的 .send(...) 和 .responseConnection(...) 确保了:在等待下游服务返回响应时,当前的 I/O 线程不会阻塞。responseConnection 的功能就是:当客户端收到响应时,异步执行你传入的函数(即处理头部、设置状态码等)。
线程隔离与路由 (Schedulers 的应用)
虽然代码中没有直接出现 publishOn(Schedulers.parallel()),但 getHttpClient(route, exchange) 方法内部已配置好,确保了 Netty Client 使用自己的 事件循环线程(Event Loop Threads) ,而不是 Gateway Filter 线程,实现了线程隔离。
核心问题:健壮性(Resilience)
看这段代码块的最后部分,它完美地实践了我们之前讨论过的 onErrorResume 原理:
// ...Duration responseTimeout = getResponseTimeout(route);if (responseTimeout != null) {responseFlux = responseFlux.timeout(responseTimeout,Mono.error(new TimeoutException("Response took longer than timeout: " + responseTimeout))).onErrorMap(TimeoutException.class,th -> new ResponseStatusException(HttpStatus.GATEWAY_TIMEOUT, th.getMessage(), th));}return responseFlux.then(chain.filter(exchange));
}
总结
Project Reactor 的核心价值是利用数据流和非阻塞 I/O,通过 Mono/Flux 和操作符,实现了对异步逻辑的声明式控制。Spring Cloud Gateway 正是基于这套机制,才能以极低的资源占用和极高的吞吐量,成为微服务架构中可靠的流量枢纽。