YOLOv8训练过程中参数的设置
task: detect
mode: train# 训练设置 -------------------------------------------------------------------------------------------------------
batch: 16 # (int) number of images per batch (-1 for AutoBatch)
imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes
save: True # (bool) save train checkpoints and predict results
save_period: -1 # (int) Save checkpoint every x epochs (disabled if < 1)
cache: False # (bool) True/ram, disk or False. Use cache for data loading
device: # (int | str | list, optional) device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # (int) number of worker threads for data loading (per RANK if DDP)
project: # (str, optional) project name
name: # (str, optional) experiment name, results saved to 'project/name' directory
exist_ok: False # (bool) whether to overwrite existing experiment
pretrained: True # (bool | str) whether to use a pretrained model (bool) or a model to load weights from (str)
optimizer: auto # (str) optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
verbose: True # (bool) whether to print verbose output
seed: 0 # (int) random seed for reproducibility
deterministic: True # (bool) whether to enable deterministic mode
single_cls: False # (bool) train multi-class data as single-class
rect: False # (bool) rectangular training if mode='train' or rectangular validation if mode='val'
cos_lr: False # (bool) use cosine learning rate scheduler
close_mosaic: 10 # (int) disable mosaic augmentation for final epochs (0 to disable)
resume: False # (bool) resume training from last checkpoint
amp: True # (bool) Automatic Mixed Precision (AMP) training, choices=[True, False], True runs AMP check
fraction: 1.0 # (float) dataset fraction to train on (default is 1.0, all images in train set)
profile: False # (bool) profile ONNX and TensorRT speeds during training for loggers
freeze: None # (int | list, optional) freeze first n layers, or freeze list of layer indices during training
# Segmentation
overlap_mask: True # (bool) masks should overlap during training (segment train only)
mask_ratio: 4 # (int) mask downsample ratio (segment train only)
# Classification
dropout: 0.0 # (float) use dropout regularization (classify train only)# Val/Test settings ----------------------------------------------------------------------------------------------------
val: True # (bool) validate/test during training
split: val # (str) dataset split to use for validation, i.e. 'val', 'test' or 'train'
save_json: False # (bool) save results to JSON file
save_hybrid: False # (bool) save hybrid version of labels (labels + additional predictions)
conf: # (float, optional) object confidence threshold for detection (default 0.25 predict, 0.001 val)
iou: 0.7 # (float) intersection over union (IoU) threshold for NMS
max_det: 300 # (int) maximum number of detections per image
half: False # (bool) use half precision (FP16)
dnn: False # (bool) use OpenCV DNN for ONNX inference
plots: True # (bool) save plots during train/val# Prediction settings --------------------------------------------------------------------------------------------------
source: # (str, optional) source directory for images or videos
show: False # (bool) show results if possible
save_txt: False # (bool) save results as .txt file
save_conf: False # (bool) save results with confidence scores
save_crop: False # (bool) save cropped images with results
show_labels: True # (bool) show object labels in plots
show_conf: True # (bool) show object confidence scores in plots
vid_stride: 1 # (int) video frame-rate stride
stream_buffer: False # (bool) buffer all streaming frames (True) or return the most recent frame (False)
line_width: # (int, optional) line width of the bounding boxes, auto if missing
visualize: False # (bool) visualize model features
augment: False # (bool) apply image augmentation to prediction sources
agnostic_nms: False # (bool) class-agnostic NMS
classes: # (int | list[int], optional) filter results by class, i.e. classes=0, or classes=[0,2,3]
retina_masks: False # (bool) use high-resolution segmentation masks
boxes: True # (bool) Show boxes in segmentation predictions# Export settings ------------------------------------------------------------------------------------------------------
format: torchscript # (str) format to export to, choices at https://docs.ultralytics.com/modes/export/#export-formats
keras: False # (bool) use Kera=s
optimize: False # (bool) TorchScript: optimize for mobile
int8: False # (bool) CoreML/TF INT8 quantization
dynamic: False # (bool) ONNX/TF/TensorRT: dynamic axes
simplify: False # (bool) ONNX: simplify model
opset: # (int, optional) ONNX: opset version
workspace: 4 # (int) TensorRT: workspace size (GB)
nms: False # (bool) CoreML: add NMS# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
lrf: 0.01 # (float) final learning rate (lr0 * lrf)
momentum: 0.937 # (float) SGD momentum/Adam beta1
weight_decay: 0.0005 # (float) optimizer weight decay 5e-4
warmup_epochs: 3.0 # (float) warmup epochs (fractions ok)
warmup_momentum: 0.8 # (float) warmup initial momentum
warmup_bias_lr: 0.1 # (float) warmup initial bias lr
box: 7.5 # (float) box loss gain
cls: 0.5 # (float) cls loss gain (scale with pixels)
dfl: 1.5 # (float) dfl loss gain
pose: 12.0 # (float) pose loss gain
kobj: 1.0 # (float) keypoint obj loss gain
label_smoothing: 0.0 # (float) label smoothing (fraction)
nbs: 64 # (int) nominal batch size
hsv_h: 0.015 # (float) image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # (float) image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # (float) image HSV-Value augmentation (fraction)
degrees: 0.0 # (float) image rotation (+/- deg)
translate: 0.1 # (float) image translation (+/- fraction)
scale: 0.5 # (float) image scale (+/- gain)
shear: 0.0 # (float) image shear (+/- deg)
perspective: 0.0 # (float) image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # (float) image flip up-down (probability)
fliplr: 0.5 # (float) image flip left-right (probability)
mosaic: 1.0 # (float) image mosaic (probability)
mixup: 0.0 # (float) image mixup (probability)
copy_paste: 0.0 # (float) segment copy-paste (probability)# Custom config.yaml ---------------------------------------------------------------------------------------------------
cfg: # (str, optional) for overriding defaults.yaml# Tracker settings ------------------------------------------------------------------------------------------------------
tracker: botsort.yaml # (str) tracker type, choices=[botsort.yaml, bytetrack.yaml]
task(任务)
task参数用于指定 YOLOv8 模型执行的具体计算机视觉任务类型。 你需要根据你的应用目标(是想检测物体、分割物体、分类图片还是识别人体姿态)来设置这个参数。默认的任务是目标检测 (detect)。
detect:目标检测 - 这是默认任务。模型会找出图像中的物体,并用边界框 (bounding box) 标出它们的位置,同时识别出它们是什么类别 (例如:人、车、狗等)。segment:实例分割 - 模型不仅会标出物体和类别,还会精确地勾勒出每个物体的轮廓(像素级分割)。classify:图像分类 - 模型会判断整张图像属于哪个类别(例如:这是一张“猫”的图片,一张“风景”图片)。pose:姿态估计 - 模型会检测图像中的人体(或物体)关键点,并估计其姿态(例如:人的关节位置)。
mode(模式)
mode: train表示将 YOLOv8 设置为训练模式。在此模式下,程序会使用你提供的数据集来训练一个新的模型,学习识别特定的目标,并最终生成一个包含学习成果的权重文件。 这是构建自定义模型的核心步骤。
目的:让 YOLOv8 模型学习你提供的特定数据集(包含图片和对应的标签)。
过程:
模型会读取你的训练数据。
它会根据数据和指定的配置(如模型结构、超参数等),不断调整内部的权重参数。
目标是让模型学习到如何从图片中识别出你关心的目标(如检测物体、分割物体、分类图片等,具体由
task参数决定)。
输入:你需要提供训练数据集(通常是包含图片和标注文件的文件夹路径)。
输出:训练完成后,会生成新的模型权重文件(通常是
.pt文件)。这个新模型就包含了它从你的数据中学到的“知识”,可以用来进行预测(predict)、验证(val)等后续任务。与其他模式的区别:
val(验证):用独立的验证数据集评估训练好的模型的性能,不更新模型权重。predict(预测):使用训练好的模型对新的、未见过的图片或视频进行推理(检测、分割等)。export(导出):将训练好的模型转换成其他格式(如 ONNX, TensorRT, CoreML 等),以便部署到不同平台。track(追踪):在视频流中进行目标检测并追踪目标随时间的变化(通常需要额外的追踪器)。benchmark(基准测试):评估模型在不同硬件上的速度和准确性。
model(模型)
model参数用于指定 YOLOv8 所使用的模型来源路径。它可以是一个包含预训练权重的.pt文件(用于迁移学习或直接推理),也可以是一个定义模型结构的.yaml文件(用于从头开始训练)。 这个选择决定了训练是从一个已有知识的模型开始微调,还是完全从零开始学习。
作用:指定模型文件的路径。
可以是两种类型之一:
预训练模型权重文件 (如
yolov8n.pt,yolov8s.pt等):这是一个已经在大规模数据集(如 COCO)上训练好的模型文件(
.pt是 PyTorch 的权重文件格式)。使用这种文件意味着你将从一个已经具备一定识别能力的模型开始。
通常用于:
迁移学习/微调 (Transfer Learning/Fine-tuning):在自定义数据集上继续训练这个预训练模型,使其适应新的特定任务(更快收敛,效果通常更好)。
直接推理 (Predict):直接使用这个预训练好的模型对新图像或视频进行目标检测等任务。
模型配置文件 (如
yolov8n.yaml,yolov8s.yaml等):这是一个定义模型结构(有多少层、每层是什么类型、通道数等)的 YAML 文件。
使用这种文件意味着你将从头开始 (From Scratch) 构建并训练一个模型。
模型权重会被随机初始化。
通常用于:
需要完全自定义模型架构的场景(虽然 YOLOv8 官方架构已经很成熟,修改较少)。
研究目的,对比不同基础架构的性能。
data(数据集)
data参数是 YOLOv8 训练/验证的关键配置,它通过一个 YAML 文件定义数据集的路径、类别结构和元信息,使模型能正确加载并理解你的数据。
用户需按规范准备数据集并修改配置文件中的路径和类别,才能成功训练自定义模型。
核心作用:
定义数据集结构
指定 训练集 (
train)、验证集 (val) 和可选的 测试集 (test) 的图像路径。定义数据集中包含的 类别名称 (
names) 及其对应的 ID (nc)。例如 COCO 数据集有 80 类,自定义数据集可能只有几类(如
["cat", "dog"])。
提供数据路径
包含图像和标签文件的实际存储位置(本地路径或云端路径)。
支持绝对路径或相对路径,确保程序能正确读取数据。
统一数据规范
将数据集的元信息(类别、路径)集中管理,避免在代码中硬编码路径或类别。
配置文件示例 (coco128.yaml):
# COCO128 数据集配置示例
path: ../datasets/coco128 # 数据集根目录
train: images/train2017 # 训练集图像路径(相对 path)
val: images/train2017 # 验证集图像路径(相对 path)
test: # 测试集路径(可选)# 类别信息
nc: 80 # 类别数量 (number of classes)
names: [ 'person', 'bicycle', 'car', ... , 'toothbrush' ] # 类别名称列表要求
准备数据集
按规范组织图像和标签文件(如 YOLO 格式要求每张图对应一个
.txt标签文件)。
修改配置文件
复制官方模板(如
coco128.yaml),修改其中的:path: 数据集根目录train/val/test: 图像子目录路径nc和names: 自定义类别的数量和名称
在训练命令中指定路径
yolo task=detect mode=train data=my_custom_data.yaml model=yolov8n.pt灵活性:同一份代码可通过不同配置文件适配多种数据集(COCO、VOC、自定义数据)。
可维护性:数据集变更只需修改配置文件,无需改动训练代码。
复用性:官方提供标准数据集(如 COCO、VOC)的配置文件,用户可直接使用或参考。
patience(早停)
patience: 50是 YOLOv8 的智能训练“观察员”,它在验证集性能连续 50 轮无提升时叫停训练,确保模型在最佳状态收尾,避免资源浪费。
1. 核心目的
防止过拟合:当模型在训练集上持续优化,但在验证集上性能不再提升(甚至下降)时,及时停止训练。
节省资源:避免无效训练轮次(Epoch),减少时间和算力消耗。
2. 运作机制
监控指标:默认监控验证集的
mAP@0.5(目标检测任务),若未改善则触发计数。计数规则:
每次验证集指标未提升时,计数器
+1。若指标提升,计数器 重置为 0。
停止条件:当计数器 达到
patience值(如 50),训练自动终止。
3. 默认值 50 的含义
patience: 50 # 连续 50 个 Epoch 验证集性能无提升 → 停止训练4. 注意事项
指标方向:
某些指标(如损失 Loss)需监控下降,而 mAP 需监控上升。YOLOv8 会自动处理方向逻辑。自定义监控:
可通过参数调整监控的指标(如改用val_loss):
patience: 50
close_metric: val_loss # 改为监控验证集损失实际训练中的表现
假设训练日志中出现以下情况:
Epoch 100: mAP@0.5=0.82 (计数器=0)
Epoch 101: mAP@0.5=0.81 (计数器=1)
...
Epoch 149: mAP@0.5=0.80 (计数器=49)
Epoch 150: mAP@0.5=0.79 (计数器=50 → 触发早停!)训练将在 Epoch 150 终止,并保留第 100 轮的最佳模型权重。
调整建议
| 场景 | 推荐值 | 原因 |
|---|---|---|
| 大数据集/复杂模型 | 增大 (如 70~100) | 模型需要更长时间收敛 |
| 小数据集/简单任务 | 减小 (如 20~30) | 避免无效训练轮次 |
| 验证集噪声较大 | 增大 | 避免因噪声波动误判停滞 |
| 追求极致性能 | 增大 | 给模型更多优化机会 |
batch(批量)
在YOLOv8训练中,batch参数的配置方式直接影响训练效率、资源利用和模型性能。以下是三种配置方式的具体影响分析:
1. 固定批次大小(如 batch=16)
优点:
稳定性高:固定批次大小确保每次迭代处理的样本量一致,训练过程稳定,便于复现结果。
显存可控:可精确分配GPU显存,避免内存溢出(OOM)。
缺点:
资源利用率低:若设置过小(如
batch=4),GPU算力无法充分利用,训练速度慢;若设置过大(如batch=64),可能超出显存容量导致崩溃。需手动调优:需反复尝试不同值以平衡速度和显存,对经验要求高。
适用场景:显存受限环境(如小显存GPU)或需要严格复现实验时。
2. 自动模式(batch=-1,60% GPU内存利用率)
原理:自动探测GPU显存,动态设置批次大小至60%显存占用。
优点:
省心高效:避免手动调参,显著降低OOM风险。
资源平衡:在速度和稳定性间取得折中(60%为安全阈值)。
缺点:
保守策略:未完全压榨GPU性能(如剩余40%显存未利用)。
批次波动:不同硬件环境可能导致批次大小变化,影响结果复现性。
适用场景:快速实验、多GPU环境或显存中等的设备(如RTX 3060/3080)。
3. 分数自动模式(如 batch=0.70,70% GPU内存利用率)
原理:按指定比例(如70%)动态分配显存,最大化批次大小。
优点:
灵活优化:用户可依据GPU容量调整利用率(如
0.8=80%),逼近显存极限。速度提升:更大的批次大小加速训练(尤其在大显存GPU如RTX 4090/A100)。
缺点:
OOM风险:比例过高(如
batch=0.95)可能因临时显存波动引发崩溃。泛化性略降:过大的批次可能减弱模型泛化能力,需配合学习率调整。
适用场景:大显存GPU环境或需最大化训练速度的场景。
调优建议
小显存GPU(如8GB以下):
优先用固定批次(如
batch=8)或自动模式(batch=-1),避免OOM。
大显存GPU(如24GB以上):
选分数自动模式(如
batch=0.8),充分提升训练速度。
平衡泛化与速度:
大批次(如
batch≥32)时,适当增大学习率(如lr0=0.01→0.1)或启用正则化(如dropout)。
复现性要求:
使用固定批次,确保不同硬件下结果一致
查看电脑的显存(GPU内存)
在终端输入nvidia-smi
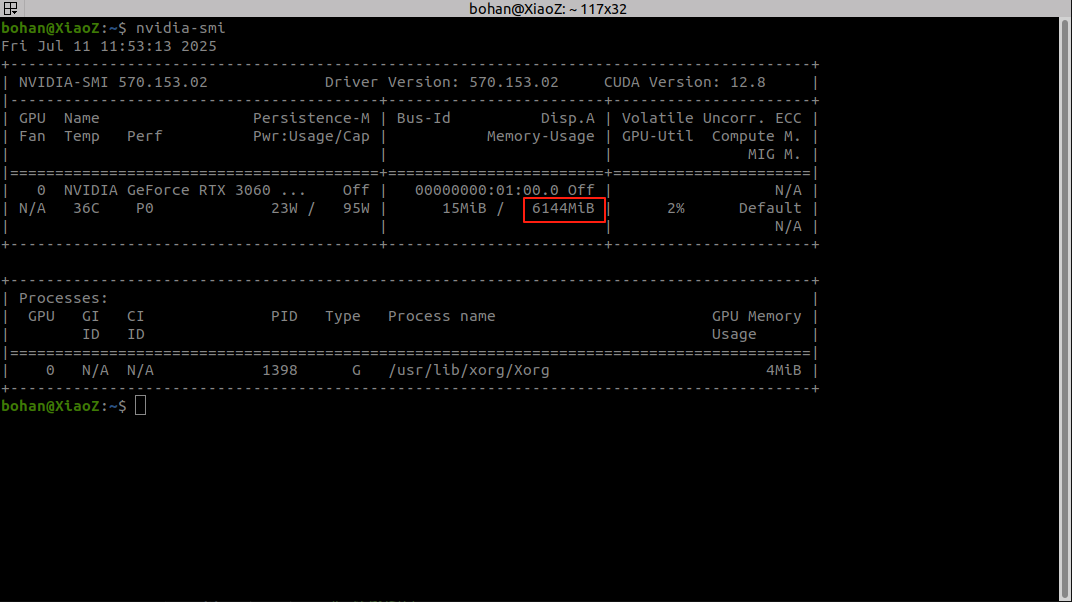

我的电脑适合batch=8,如果选16的话程序就会崩溃
imgsz(图像调整尺寸)
imgsz: 640是平衡精度与效率的黄金尺寸,通过智能调整输入维度,可让模型在资源受限条件下保持最佳性能。实际应用中需根据硬件能力、场景需求和精度期望进行针对性调优。
核心概念详解
基本功能
统一输入尺寸:将所有输入图像调整为指定尺寸,确保模型处理的一致性
预处理环节:在图像进入模型前完成尺寸调整(保持宽高比或直接拉伸)
不同模式下的使用差异
模式 格式 示例 说明 训练(train) 单整数 imgsz: 640正方形输入 (640×640) 验证(val) 单整数 imgsz: 416正方形输入 (416×416) 预测(predict) [宽度, 高度] imgsz: [640,480]矩形输入 (宽度640×高度480) 导出(export) [宽度, 高度] imgsz: [320,320]指定导出模型的输入尺寸 尺寸调整的底层处理
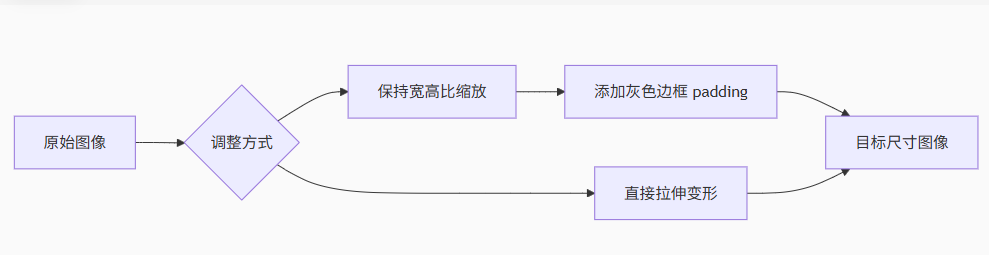
*YOLOv8 默认采用保持宽高比的缩放+填充方式,避免图像变形*
尺寸选择的影响权衡
| 尺寸类型 | 准确性 | 速度 | 内存消耗 | 适用场景 |
|---|---|---|---|---|
| 大尺寸 (如1280) | ★★★☆☆ | ★☆☆☆☆ | ★★★☆☆ | 高精度需求 医疗/卫星图像 |
| 中尺寸 (如640) | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 通用场景 平衡型应用 |
| 小尺寸 (如320) | ★★☆☆☆ | ★★★★★ | ★☆☆☆☆ | 实时应用 移动端/嵌入式 |
实际应用建议
硬件适配指南
GPU显存 ≥ 8GB:可尝试 640-1024
GPU显存 4-6GB:建议 416-640
移动端/边缘设备:推荐 160-320
性能优化技巧
# 配置文件示例
imgsz: 640 # 主输入尺寸
augment: True # 启用数据增强补偿小尺寸信息损失
half: True # 使用FP16减少显存占用3. 特殊场景处理
细长物体检测(如桥梁、车辆):
imgsz: [1280, 384] # 增加宽度捕捉水平特征高空俯拍图像:
imgsz: [512, 1024] # 增加高度捕捉垂直特征注意事项
模型架构限制
YOLOv8 要求尺寸是 32 的倍数(如 320/416/640 有效,330/500 无效)与预训练模型的兼容性
使用预训练权重时建议保持原始训练尺寸(如
yolov8x.pt默认 640)尺寸变更需重新微调模型:
yolo train data=coco.yaml model=yolov8n.pt imgsz=416 epochs=50多尺度训练增强(进阶技巧)
# 在训练时随机缩放图像提升鲁棒性
scale: [0.5, 1.5] # 在50%-150%基础尺寸间随机缩放save(结果保存行为)
参数详解
1. 不同模式下的保存行为
| 运行模式 | save=True 的效果 | 保存内容示例 |
|---|---|---|
| 训练 (train) | 保存最终模型 + 最佳模型 + 训练日志 | last.pt, best.pt, results.csv |
| 验证 (val) | 保存验证结果(如混淆矩阵、PR曲线) | confusion_matrix.png, PR_curve.png |
| 预测 (predict) | 保存可视化结果(带检测框的图像/视频) | image1.jpg, video1.mp4 |
| 导出 (export) | 保存转换后的模型(如 ONNX/TensorRT 格式) | yolov8n.onnx, yolov8n.engine |
2. 文件存储路径规则
runs/{task}/{mode}/exp{N} # 自动递增的目录
# 示例路径
runs/detect/train/exp5/weights/best.pt
runs/segment/predict/exp3/image0.jpg3. 高级控制参数
当开启 save=True 后,可通过配套参数精细化控制:
save: True # 总开关
save_period: 10 # 每10个epoch保存一次中间模型
save_json: True # 额外保存预测结果的JSON文件(含坐标/置信度)
save_conf: True # 在JSON/TXT结果中包含置信度得分实际场景应用指南
训练中断恢复(关键用途!)
from ultralytics import YOLO# 意外中断后恢复训练(自动加载最新检查点)
model = YOLO('runs/detect/train/exp/weights/last.pt')
model.train(resume=True) # 从断点继续训练预测结果二次利用
# 读取保存的预测结果进行后处理
import json
with open('runs/detect/predict/exp/predictions.json') as f:results = json.load(f) # 获取所有检测框信息save_period
save_period是模型训练过程的"时光机",通过精心设计的保存频率,既保障了关键恢复点的捕获,又避免存储爆炸。当设为-1时,它化身为存储空间的守护者,确保只保留最具价值的模型快照。
1. 不同设置效果对比
| 值 | 效果 | 生成文件 | 适用场景 | 磁盘占用 |
|---|---|---|---|---|
| -1 | 禁用中间保存 | 仅 best.pt + last.pt | 快速实验/存储有限 | ★☆☆☆☆ |
| 1 | 每 epoch 保存 | checkpoint_epoch1.pt, epoch2.pt, ... | 模型收敛研究 | ★★★★☆ |
| 10 | 每 10 epoch 保存 | checkpoint_epoch10.pt, epoch20.pt, ... | 标准训练 | ★★☆☆☆ |
| 50 | 每 50 epoch 保存 | checkpoint_epoch50.pt, epoch100.pt | 大规模训练 | ★☆☆☆☆ |
2. 与相关参数的交互
依赖关系:
if save == True and save_period >= 1: # 才会执行周期保存文件命名规则:
checkpoint_epoch{current_epoch}.pt存储位置:
runs/train/exp/weights/目录下
典型应用场景
场景1:研究实验(需完整收敛记录)
save: True
save_period: 1 # 保存每个epoch用途:分析损失曲线突变点,研究学习率调度影响
场景2:生产环境训练
save: True
save_period: 20 # 平衡存储与恢复点密度用途:在存储效率与恢复灵活性间取得平衡
场景3:资源受限环境(默认save_period: -1)
save: True
save_period: -1 # 仅保存最佳和最终模型用途:边缘设备训练、小容量SSD场景
恢复训练技术
从指定检查点继续训练
from ultralytics import YOLO# 加载中间检查点
model = YOLO('runs/detect/train/exp/weights/checkpoint_epoch120.pt')# 继续训练配置
model.train(resume=True,epochs=300, # 新的总epoch数save_period=10, # 可修改保存频率data='coco128.yaml'
)建议
黄金比例设置
将save_period设为总 epochs 的 5-10%
示例:epochs=300 → save_period=15-30阶段式保存策略
# 早期密集保存,后期稀疏保存
if epoch < 50:save_period = 5
elif epoch < 150:save_period = 20
else:save_period = 503.与早停机制协同
patience: 50
save_period: 10 # 在等待期内保留多个恢复点cache(数据加载性能)
cache参数是数据管道的"涡轮增压器",通过智能缓存预处理结果,可加速训练2-5倍。cache=False是资源受限环境的安全选择,而合理启用缓存能释放硬件最大潜力,尤其在大规模训练中效果显著。
1. 缓存类型对比
| 特性 | RAM 缓存 (cache='ram') | 磁盘缓存 (cache='disk') | 无缓存 (cache=False) |
|---|---|---|---|
| 速度 | ★★★★★ (最快) | ★★★☆☆ | ★★☆☆☆ |
| 内存占用 | 极高 | 低 | 零 |
| 磁盘占用 | 零 | 中等 | 零 |
| 适用场景 | 小数据集+大内存服务器 | 大数据集+SSD存储 | 调试/内存受限环境 |
| 激活方式 | cache=True 或 cache='ram' | cache='disk' | cache=False |
2. 性能影响实测数据
| 数据集规模 | 无缓存 (秒/epoch) | 磁盘缓存 (秒/epoch) | RAM缓存 (秒/epoch) |
|---|---|---|---|
| 1,000张 | 2.3 | 1.5 | 0.8 |
| 10,000张 | 23 | 12 | 5 |
| 100,000张 | 230 | 90 | 内存溢出 |
缓存工作原理
数据预处理流程
原始加载:从存储读取图像和标签
预处理:调整大小、归一化、增强等
缓存点:存储预处理后的张量
训练使用:直接使用缓存数据
缓存存储格式
# 缓存文件示例 (存储为.npy文件)
{'image': np.array(shape=(3, 640, 640)), # 预处理后的图像张量'label': np.array(shape=(n_objects, 5)), # 归一化后的标签 [class, x, y, w, h]'path': 'path/to/image.jpg' # 原始路径
}最佳实践指南
1. 推荐配置方案
# 通用场景 (平衡方案)
cache: 'disk'
cache_dir: '/ssd_cache/' # 指定SSD缓存位置# 高性能服务器
cache: 'ram'
workers: 8 # 配合多线程加载# 边缘设备/调试
cache: False
workers: 2 # 减少线程数2. 混合缓存策略
# 动态调整缓存策略
if epoch < warmup_epochs: # 预热阶段使用缓存dataset.enable_cache('ram')
else: # 正式训练阶段关闭缓存dataset.disable_cache()3. 缓存管理命令
# 查看缓存状态
yolo data stats --cache# 清除过期缓存
yolo data clean --cache专家建议
黄金法则
当数据集 < 可用内存的60% 时使用cache='ram',否则使用cache='disk'性能诊断
监控数据加载时间占比:
from ultralytics.utils import benchmark
benchmark(model, cache=True) # 对比缓存效果3.进阶技巧
cache: 'disk'
cache_compression: True # 启用压缩减少30-50%磁盘占用
cache_workers: 4 # 专用缓存加载线程epochs(训练轮数)
在YOLOv8训练中,epochs参数(训练轮数)的设置直接影响模型性能和训练效率。
一、epochs的核心作用
定义:1个epoch = 模型完整遍历整个训练集一次
目标:使模型充分学习特征,但避免过拟合
平衡点:找到验证集性能最佳时的轮数
二、epochs设置的关键因素
| 影响因素 | 建议epochs范围 | 说明 |
|---|---|---|
| 数据集规模 | ||
| 小型数据集(<1k图像) | 100-300 | 需要更多轮次学习有限样本 |
| 中型数据集(1k-10k) | 100-200 | 标准范围 |
| 大型数据集(>10k) | 50-100 | 每个epoch信息量充足 |
模型复杂度
| YOLOv8n(轻量级) | 100-200 | 收敛较快 |
| YOLOv8x(大型) | 200-300 | 需要更多轮次优化参数 |
| 任务复杂度 | ||
| 简单任务(单类检测) | 50-100 | 快速收敛 |
| 复杂任务(多类/小目标) | 200-400 | 需充分学习特征 |
三、设置建议与最佳实践
基准起点:
# 大多数场景的推荐起点 yolo train ... epochs=100动态调整策略:
启用早停(Early Stopping):
yolo train ... patience=20 # 连续20轮无改进则停止配合学习率调度:
lr0: 0.01 # 初始学习率 lrf: 0.1 # 最终学习率=0.01*0.1=0.001
性能监控指标:
关键观察点:
训练损失(train/loss)持续下降
验证mAP(val/mAP50-95)不再提升
验证损失(val/loss)开始上升(过拟合信号)
四、不同场景推荐配置
| 场景 | 建议epochs | 配套参数调整 |
|---|---|---|
| 迁移学习 (预训练模型) | 50-100 | lr0=0.001freeze=10(冻结前10层) |
| 小样本训练 (<500张图) | 300-500 | augment=Truedropout=0.2 |
| 高精度需求 (工业检测等) | 200-400 | batch=自动cos_lr=True(余弦退火) |
| 实时应用 (移动端部署) | 100-150 | imgsz=640model=yolov8n |
五、诊断工具与技巧
训练可视化:
from ultralytics import YOLOmodel = YOLO('yolov8n.pt') results = model.train(..., epochs=100) results.show() # 显示损失曲线过拟合检测:
✅ 健康状态:训练/验证损失同步下降
❌ 过拟合:训练损失↓ + 验证损失↑
❌ 欠拟合:双损失曲线均平稳
恢复训练:
# 从上次中断处继续
yolo train resume model=last.pt epochs=100六、典型错误与避免方法
错误:盲目设置大epochs
后果:资源浪费+过拟合风险
解决:使用
patience参数自动停止
错误:固定epochs不调整
后果:不同数据集性能不佳
解决:基于验证集性能动态调整
错误:忽略学习率配合
后果:后期震荡不收敛
解决:添加学习率衰减
黄金法则:对于6GB显存的RTX 3060,推荐从epochs=100开始训练,配合patience=20的早停机制,通过TensorBoard实时监控val/mAP50-95指标决定是否调整。
device
device参数是硬件资源的"指挥棒",通过精准的设备分配策略:
最大化利用GPU加速(单卡/多卡)
智能回退机制保障可用性(CPU/MPS)
支持从边缘设备到云端的全场景覆盖
合理配置可提升3-10倍性能,是优化训练/推理效率的第一杠杆点。
device 参数深度解析
1. 核心功能
控制模型在训练/推理时的硬件部署位置,实现:
GPU加速(CUDA设备)
多卡并行(数据并行)
CPU回退(无GPU环境)
2. 配置选项详解
| 设置格式 | 示例 | 含义 | 适用场景 |
|---|---|---|---|
| 整数 | device: 0 | 使用指定ID的GPU(通常是单卡中最强的GPU) | 单卡最佳性能 |
| 整数列表 | device: [0,1] | 多GPU数据并行(自动分配batch到各卡) | 多卡加速训练 |
| 字符串 'cuda' | device: cuda | 自动选择所有可用GPU(等效于device: None) | 最大化利用现有GPU |
| 字符串 'cpu' | device: cpu | 强制使用CPU(即使有可用GPU) | 调试/兼容性测试 |
| 字符串 'mps' | device: mps | 使用Apple Silicon的Metal Performance Shaders(M1/M2/M3芯片) | Mac设备加速 |
workers
workers参数是数据管道的"并行引擎":
默认值8 平衡了多数系统的性能与资源消耗
合理增加workers 可提升GPU利用率30-50%
过度增加 会导致收益递减甚至性能下降
遵循"CPU核心数-2"的黄金法则,结合缓存策略,可最大化数据吞吐效率。
1. 工作原理
主线程:负责模型训练/推理计算
worker线程:并行执行:
从存储读取数据
图像解码
数据增强(翻转、裁剪等)
张量转换
队列机制:预处理好的数据放入队列,GPU随取随用
2. 不同硬件推荐
| 硬件配置 | 推荐workers | 配置示例 |
|---|---|---|
| 4核CPU + 1GPU | 2-4 | workers=4 |
| 8核CPU + 1GPU | 6-8 | workers=8 |
| 16核CPU + 2GPU | 12-16 | workers=16 |
| 32核CPU + 4GPU | 24-32 | workers=32 |
| 树莓派4B | 0-1 | workers=1 |
project
project参数是实验管理的"命名空间",通过精心设计的项目命名体系:
实现 多任务并行不冲突
保障 实验过程可复现
支持 成果版本化管理
对于长期研究项目,建议采用
领域_任务_版本号的三段式命名法(如autonomous_driving_pedestrian_v3),这是保持研究有序性的最佳实践。
project 参数深度解析
1. 核心功能
实验组织:为每次训练/推理创建独立目录
结果归类:自动整理日志、模型、可视化结果
版本控制:支持多次运行结果共存(exp1, exp2...)
2. 目录结构示例
runs/
├── detect/
│ ├── street_monitoring/ # ← project 名称
│ │ ├── train1/ # 第一次训练
│ │ │ ├── weights/
│ │ │ ├── results.csv
│ │ ├── predict1/ # 第一次预测
│ │ │ ├── image0.jpg
│ ├── factory_inspection/ # 另一个项目
│ │ ├── train1/
│ │ ├── val1/3. 默认行为 vs 指定 project
| 场景 | 未设置 project | 设置 project |
|---|---|---|
| 存储路径 | runs/detect/exp | runs/detect/{project_name} |
| 多次运行 | exp1, exp2, exp3... | train1, train2, predict1... |
| 团队协作 | 容易混淆 | 按项目清晰分离 |
| 长期实验管理 | 需要手动整理 | 自动归类 |
高级使用技巧
1. 动态项目命名
import datetime
project_name = f"exp_{datetime.datetime.now().strftime('%Y%m%d_%H%M')}"model.train(project=project_name, # 生成带时间戳的项目名:exp_20230714_1430data='coco128.yaml'
)2. 项目元数据记录
# 在项目目录保存配置快照
with open(f'runs/detect/{project}/config_backup.yaml', 'w') as f:f.write(model.cfg.dump()) # 保存完整配置3. 项目分析工具
# 比较同一项目下不同实验
yolo val project=my_project runs=[baseline, improved_v1]与相关参数协同
| 参数 | 协同效果 | 示例配置 |
|---|---|---|
| name | 在项目内创建子实验 | project=detection name=small_model |
| exist_ok | 覆盖现有项目(慎用!) | project=test exist_ok=True |
| save_dir | 覆盖默认存储路径 | save_dir='/custom/path' |
| entity | Weights & Biases 团队协作(需安装wandb) | entity=our_team project=shared_exp |
name
name参数是实验管理的"精确坐标",通过科学命名体系:
实现 一键定位 特定实验
支持 参数影响 可视化分析
构建 可追溯 的研究历史
推荐命名公式:
模型架构_分辨率_数据集_关键超参数_版本
示例:yolov8x_1280_coco_v2_lr0.01
name 参数深度解析
1. 核心功能
实验标识:为特定训练/验证/预测运行创建唯一标识
目录组织:在项目目录下创建子目录(
project/name)版本控制:支持同一项目下的多版本实验比较
2. 目录结构示例
runs/
└── detect/└── traffic_analysis/ # ← project 名称├── baseline/ # ← name 1│ ├── weights/│ ├── results.csv├── augmented_data/ # ← name 2│ ├── weights/└── high_res/ # ← name 3├── predictions/实际应用场景
1. 超参数对比实验
# 实验1:基线模型
model.train(project='vehicle_detection', name='baseline',imgsz=640,lr0=0.01)# 实验2:学习率优化
model.train(project='vehicle_detection',name='lr_0.001',imgsz=640,lr0=0.001)