数据库-锁
1. 锁的基本概念
为什么需要锁?
想象一下多人同时编辑同一个文档的场景:
用户A和用户B同时读取余额为100元
用户A存入50元,余额变为150元
用户B取出30元,余额变为70元(应该是120元才对!)
这就是典型的并发问题,锁就是为了解决这类问题而生的。
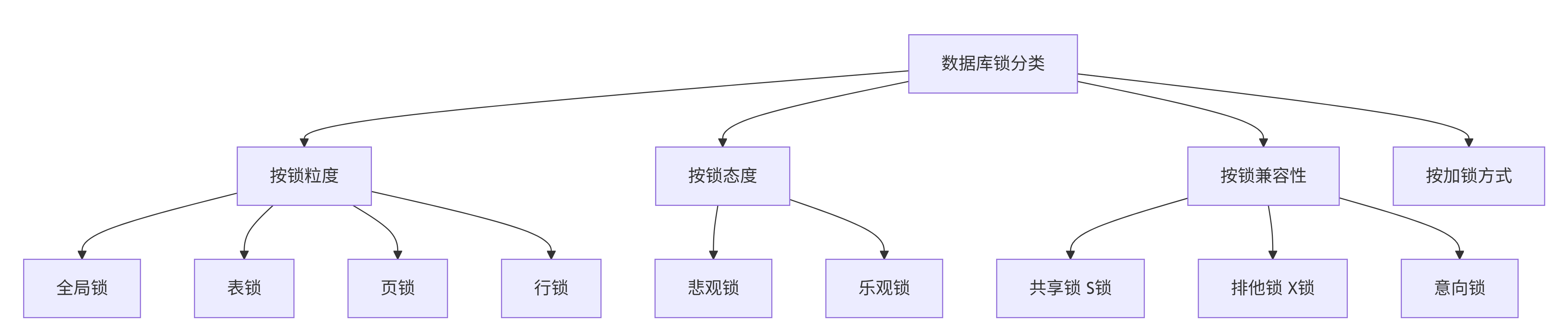 锁的分类维度
锁的分类维度
2. 按锁粒度划分
2.1 全局锁
是什么:锁定整个数据库实例,让数据库处于只读状态。
使用场景:
全库逻辑备份
重大数据库维护操作
MySQL示例:
sql
-- 加全局锁 FLUSH TABLES WITH READ LOCK;-- 执行备份操作...-- 释放锁 UNLOCK TABLES;
特点:
🔴 影响极大:整个数据库无法写入
⚡ 性能影响:所有写操作被阻塞
🎯 使用谨慎:只在维护和备份时使用
2.2 表锁
是什么:锁定整张表。
分类:
表共享读锁:多个事务可以同时读,但不能写
表独占写锁:只有一个事务能读写,其他事务都不能访问
MySQL示例:
sql
-- 手动加表锁 LOCK TABLES users READ; -- 读锁 LOCK TABLES users WRITE; -- 写锁-- 操作完成后解锁 UNLOCK TABLES;-- InnoDB自动表锁的情况 ALTER TABLE users ADD COLUMN age INT; -- DDL语句会自动加表锁
特点:
🔴 粒度较粗:影响整张表
⚡ 性能中等:并发度较低
🎯 适用场景:表结构变更、全表更新
2.3 行锁
是什么:只锁定表中的某一行或多行。
MySQL InnoDB行锁实现:
sql
-- 事务1 BEGIN; UPDATE users SET balance = balance - 100 WHERE id = 1; -- 对id=1的行加行锁-- 事务2(同时执行) BEGIN; UPDATE users SET balance = balance + 50 WHERE id = 2; -- 可以执行,不影响 UPDATE users SET balance = balance + 50 WHERE id = 1; -- 被阻塞,等待事务1释放锁
行锁的细分类型:
记录锁:锁定单条记录
间隙锁:锁定记录之间的间隙,防止幻读
临键锁:记录锁+间隙锁,InnoDB默认行锁算法
间隙锁示例:
sql
-- 假设id有记录:1, 3, 5, 7, 9 BEGIN; SELECT * FROM users WHERE id > 5 AND id < 9 FOR UPDATE;-- 这会锁定(5,7)和(7,9)这两个区间 -- 其他事务无法在区间内插入新记录,如无法插入id=6或id=8的记录
特点:
🟢 粒度最细:只影响被锁定的行
⚡ 性能最佳:并发度最高
🔧 实现复杂:需要更多系统资源
3. 按锁态度划分
3.1 悲观锁
核心思想:"凡事做好最坏的打算",认为数据在并发访问时很可能被修改,所以先加锁再访问。
实现方式:
sql
-- MySQL悲观锁实现 BEGIN;-- 方式1:SELECT ... FOR UPDATE (排他锁) SELECT * FROM accounts WHERE user_id = 123 FOR UPDATE; -- 执行业务逻辑... UPDATE accounts SET balance = balance - 100 WHERE user_id = 123;COMMIT;-- 方式2:SELECT ... LOCK IN SHARE MODE (共享锁) SELECT * FROM products WHERE stock > 0 LOCK IN SHARE MODE;
适用场景:
写多读少的场景
对数据一致性要求极高的场景(如金融交易)
临界区代码执行时间较长的场景
3.2 乐观锁
核心思想:"相信大家都很守规矩",认为并发冲突很少发生,只在更新时检查数据是否被修改。
实现方式:
版本号机制
sql
-- 数据库表增加version字段 CREATE TABLE products (id BIGINT PRIMARY KEY,name VARCHAR(100),stock INT,version INT DEFAULT 0 );-- 业务逻辑(需要重试机制) -- 第一次读取 SELECT id, stock, version FROM products WHERE id = 1; -- 假设读到:stock=10, version=1-- 更新时检查版本号 UPDATE products SET stock = stock - 1, version = version + 1 WHERE id = 1 AND version = 1; -- 关键:带上版本号条件-- 如果受影响行数为0,说明版本号不匹配,需要重试
时间戳机制
sql
-- 使用update_time作为乐观锁条件 UPDATE orders SET status = 'PAID', update_time = NOW() WHERE order_id = 1001 AND update_time = '2023-10-27 10:00:00';
条件判断机制
sql
-- 基于业务字段的条件 UPDATE accounts SET balance = balance - 100 WHERE user_id = 123 AND balance >= 100; -- 余额足够才更新
适用场景:
读多写少的场景
系统吞吐量要求高的场景
冲突概率较低的业务场景
4. 按锁兼容性划分
4.1 共享锁
特性:
多个事务可以同时获取共享锁
不能与排他锁共存
用于读取操作
sql
-- MySQL SELECT * FROM table_name LOCK IN SHARE MODE;-- SQL Server SELECT * FROM table_name WITH (HOLDLOCK);
4.2 排他锁
特性:
只有一个事务能获取排他锁
不能与其他任何锁共存
用于写入操作
sql
-- MySQL SELECT * FROM table_name FOR UPDATE;-- SQL Server UPDATE table_name SET column = value WHERE condition;
4.3 意向锁
作用:为了在表级和行级锁之间建立协调机制,提高锁检查效率。
类型:
意向共享锁:事务打算在表中的某些行上加共享锁
意向排他锁:事务打算在表中的某些行上加排他锁
锁兼容性矩阵:
| 当前锁 → 请求锁 ↓ | 无锁 | 共享锁(S) | 排他锁(X) | 意向共享(IS) | 意向排他(IX) |
|---|---|---|---|---|---|
| 共享锁(S) | ✅ | ✅ | ❌ | ✅ | ❌ |
| 排他锁(X) | ✅ | ❌ | ❌ | ❌ | ❌ |
| 意向共享(IS) | ✅ | ✅ | ❌ | ✅ | ✅ |
| 意向排他(IX) | ✅ | ❌ | ❌ | ✅ | ✅ |
5. 实际应用场景分析
5.1 电商库存扣减场景
方案1:悲观锁实现
sql
BEGIN; -- 锁定要更新的商品记录 SELECT stock FROM products WHERE id = 1001 FOR UPDATE;-- 检查库存 -- 业务逻辑:如果stock >= 要购买的数量,则扣减 UPDATE products SET stock = stock - 1 WHERE id = 1001; COMMIT;
优点:强一致性,不会超卖
缺点:并发性能较低
方案2:乐观锁实现
java
// Java代码示例(需要重试机制)
@Transactional
public boolean deductStock(Long productId, Integer quantity) {int maxRetries = 3;for (int i = 0; i < maxRetries; i++) {Product product = productMapper.selectById(productId);if (product.getStock() < quantity) {return false; // 库存不足}int rows = productMapper.updateStock(productId, quantity, product.getVersion());if (rows > 0) {return true; // 更新成功}// 版本冲突,重试Thread.sleep(50); // 短暂等待后重试}throw new RuntimeException("库存扣减失败,请重试");
}sql
-- 对应的Mapper SQL
UPDATE products
SET stock = stock - #{quantity}, version = version + 1
WHERE id = #{productId} AND version = #{version} AND stock >= #{quantity};5.2 银行转账场景
sql
-- 必须使用悲观锁保证强一致性 BEGIN;-- 锁定转出账户 SELECT * FROM accounts WHERE account_no = 'A001' FOR UPDATE; -- 锁定转入账户(注意顺序,避免死锁) SELECT * FROM accounts WHERE account_no = 'B002' FOR UPDATE;-- 执行转账 UPDATE accounts SET balance = balance - 100 WHERE account_no = 'A001'; UPDATE accounts SET balance = balance + 100 WHERE account_no = 'B002';COMMIT;
6. 死锁与解决方案
死锁产生条件
互斥条件:资源不能被共享
占有且等待:持有资源并等待其他资源
不可抢占:资源只能自愿释放
循环等待:多个进程形成等待环
死锁示例
sql
-- 事务1 BEGIN; UPDATE users SET name = 'A' WHERE id = 1; -- 锁定id=1 UPDATE users SET name = 'B' WHERE id = 2; -- 等待事务2释放id=2-- 事务2(同时执行) BEGIN; UPDATE users SET name = 'C' WHERE id = 2; -- 锁定id=2 UPDATE users SET name = 'D' WHERE id = 1; -- 等待事务1释放id=1 -- 💥 死锁发生!
死锁预防和解决
保持锁顺序:总是按相同顺序获取锁
设置锁超时:
SET innodb_lock_wait_timeout = 50;死锁检测:数据库自动检测并回滚代价较小的事务
降低隔离级别:从可重复读降为读已提交,减少间隙锁
7. 面试高频题目
题目1:悲观锁 vs 乐观锁
Q:请详细说明悲观锁和乐观锁的区别及适用场景。
A:
思想差异:悲观锁认为冲突经常发生,先加锁再访问;乐观锁认为冲突很少发生,先访问再检查
实现方式:悲观锁通过数据库锁机制实现;乐观锁通过版本号/时间戳实现
性能差异:悲观锁并发度低但一致性强;乐观锁并发度高但需要重试机制
适用场景:悲观锁适合写多读少、强一致性场景;乐观锁适合读多写少、高并发场景
题目2:数据库锁粒度
Q:谈谈你对数据库锁粒度的理解,不同粒度的锁各有什么优缺点?
A:
行锁:粒度最小,并发度高,但开销大,可能死锁
表锁:粒度大,并发度低,但开销小,不会死锁
页锁:介于行锁和表锁之间
选择原则:根据业务并发性和数据一致性要求选择合适粒度
题目3:死锁处理
Q:数据库中出现死锁时,MySQL是如何处理的?
A:
死锁检测:InnoDB会检测死锁循环
选择牺牲者:回滚undo量最小的事务
错误返回:向客户端返回
ERROR 1213 (40001): Deadlock found事务回滚:被选择的事务自动回滚
题目4:实战设计题
Q:设计一个电商秒杀系统的库存扣减方案,要求保证不超卖且性能良好。
A:
sql
-- 方案:Redis预减库存 + 数据库最终扣减 + 乐观锁
-- 1. Redis预扣库存(减轻数据库压力)
-- 2. 数据库最终扣减使用乐观锁
UPDATE products
SET stock = stock - 1, version = version + 1,sale_count = sale_count + 1
WHERE id = #{productId} AND version = #{version} AND stock > 0;-- 3. 如果更新失败,在Redis中恢复库存
-- 4. 前端配合排队、限流机制题目5:锁的升级和降级
Q:什么情况下会发生锁升级?有什么影响?
A:
锁升级:当单个事务持有的行锁超过阈值时,数据库可能将行锁升级为表锁
触发条件:SQL Server中当行锁数量超过5000,MySQL InnoDB较少发生
影响:并发度急剧下降,可能引发阻塞链
避免方法:优化事务,减少锁持有数量和时间
总结
数据库锁是一个复杂的主题,但掌握它对于构建高并发、高可用的系统至关重要。关键要点:
理解不同粒度的锁及其适用场景
根据业务特点选择悲观锁或乐观锁
注意死锁的预防和处理
在实际应用中考虑性能和一致性的平衡