大模型离线部署docker(推荐) + dify部署(docker)
背景:离线环境安装大模型
在 openEuler A40 单卡上通过 Docker 离线部署 vLLM 和 DeepSeek-R1-Distill-Qwen-14B INT4
准备工作
-
硬件要求:
- NVIDIA A40 GPU (48GB 显存)
- 至少 100GB 可用磁盘空间 (用于 Docker 镜像和模型)
-
软件要求:
- openEuler 操作系统
- Docker 已安装
- NVIDIA Container Toolkit 已安装
部署步骤
1. 在有网络的环境中准备 Docker 镜像和模型
1.1 构建或下载 vLLM Docker 镜像
- 或者使用Dockerfile,注意Dockerfile的f要小写,Dockerfile文件中内容,
去掉文件后缀,windows如 .txt,注意: dockerfile文件中pip3 install vllm要指定镜像源,否则会链接超时错误
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04# 安装基础软件
RUN apt-get update && apt-get install -y \python3 \python3-pip \curl \&& rm -rf /var/lib/apt/lists/*# 安装 vLLM
RUN pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm# 创建模型目录
RUN mkdir -p /app/models# 设置工作目录
WORKDIR /app# 设置默认环境变量
ENV MODEL_PATH=/app/models# 创建启动脚本
RUN echo '#!/bin/bash\n\
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--host 0.0.0.0 \
--port 8000' > start.shRUN chmod +x start.sh# 暴露端口
EXPOSE 8000# 启动命令
CMD ["./start.sh"]
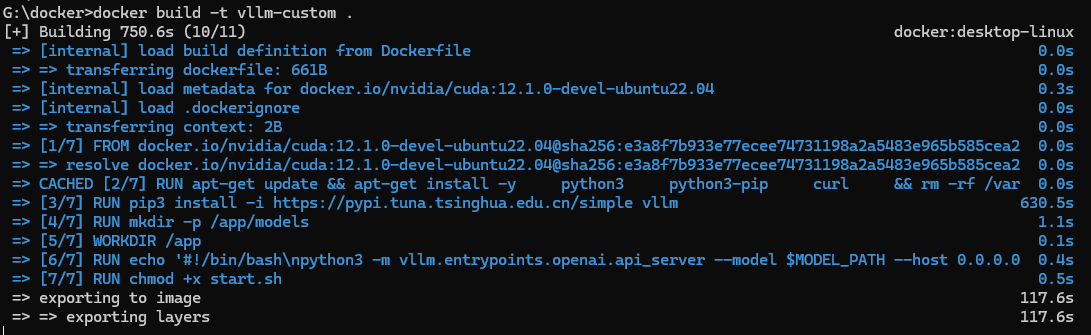
- 构建镜像
# 保存镜像为离线文件
docker save vllm/vllm-openai:latest -o vllm-image.tar
# 或
docker save vllm-custom -o vllm-custom-image.tar
- 安装过程截图
- 容器启动脚本
# 导入镜像
docker load -i vllm-custom.tar# 运行容器(需要指定模型路径)(已实操)
# --tensor-parallel-size 1
:张量并行数:1,含义:模型在单个 GPU 上运行(不进行多卡并行)如果有多张卡:可以设置为 GPU 数量,如 --tensor-parallel-size 2
:此命令是vLLM应用参数(在镜像名之后)
:Docker 运行时参数(在镜像名之前),vLLM 应用参数(在镜像名之后)
# --shm-size=2g
:共享内存设置的大一些,开始没设置容器启动时会报错,应该默认会很小
# --max-model-len 32000
:也会进行设置,参数设置的会小一些,因为模型需要的序列Gpu没法完全提供,会报错
docker run -d \--gpus all \--shm-size=2g-p 8000:8000 \-v /path/to/your/models:/app/models \--name vllm-server \vllm-custom \python3 -m vllm.entrypoints.openai.api_server \--model /app/models/deepseek-14b--tensor-parallel-size 2 --gpu-memory-utilization 0.9--max-model-len 32000# 可能会存在iptables规则问题,导致8000无法请求
iptables -A INPUT -p tcp --dport 8000 -j ACCEPT
# 记得重启docker服务
# 再重新docker run一下
# 容器运行后稍等一会模型加载。可以通过命令监控gpn使用情况
watch -n -1 nvidia-smi# 这是量化模型启动命令(未实操过)
docker run -itd --gpus all \-p 8000:8000 \-v /data/models:/models \--name vllm-server \vllm/vllm-openai:latest \python3 -m vllm.entrypoints.openai.api_server \--model /models/DeepSeek-R1-Distill-Qwen-14B-INT4 \--tensor-parallel-size 1 \--gpu-memory-utilization 0.9 \--quantization awq # 如果是AWQ量化模型# MODEL_PATH的作用,可以指定不同模型运行
# 使用中文模型
docker run -e MODEL_PATH=/app/models/chinese-model ...# 使用英文模型
docker run -e MODEL_PATH=/app/models/english-model ...# 使用代码模型
docker run -e MODEL_PATH=/app/models/code-model ...
- 请求
1.2 下载模型文件
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B-INT4
2. 将文件传输到离线环境
将以下文件复制到离线机器:
vllm-image.tar或vllm-custom-image.tarDeepSeek-R1-Distill-Qwen-14B-INT4整个目录
3. 在离线环境中加载 Docker 镜像
# 加载 Docker 镜像
docker load -i vllm-custom-image.tar# 验证镜像加载
docker images
6. 验证服务
# 检查容器日志
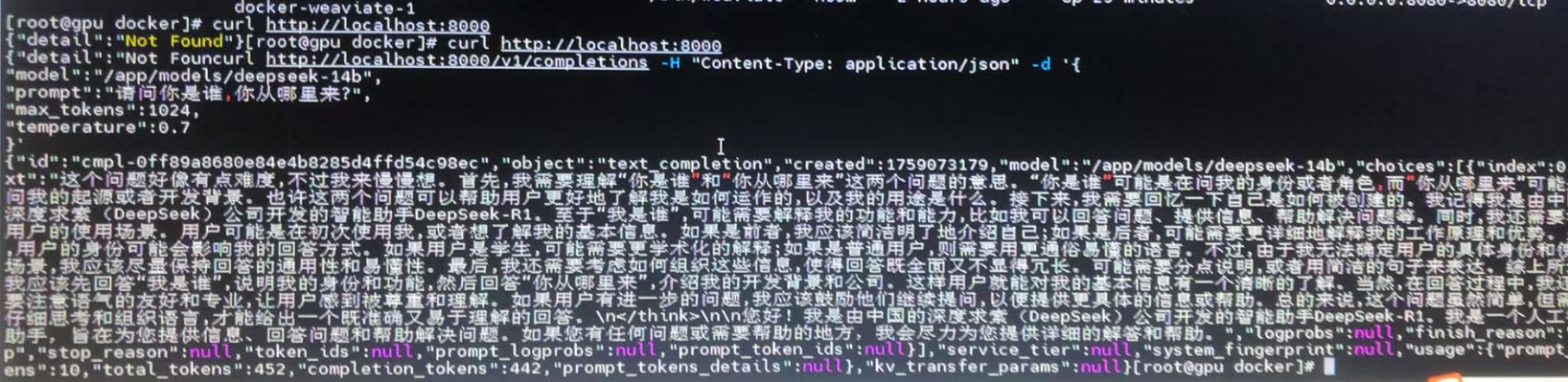
docker logs vllm-server# 测试API (在容器内部或从主机)
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "/models/DeepSeek-R1-Distill-Qwen-14B-INT4","prompt": "请介绍一下人工智能的发展历史","max_tokens": 100,"temperature": 0.7}'
替代方案:使用预构建的启动脚本
创建 start_vllm.sh 脚本:
#!/bin/bashMODEL_PATH="/models/DeepSeek-R1-Distill-Qwen-14B-INT4"docker run -itd --gpus all \-p 8000:8000 \-v $(dirname $MODEL_PATH):/models \--name vllm-server \vllm/vllm-openai:latest \python3 -m vllm.entrypoints.openai.api_server \--model $MODEL_PATH \--tensor-parallel-size 1 \--gpu-memory-utilization 0.9 \--quantization awq
然后运行:
chmod +x start_vllm.sh
./start_vllm.sh
在 openEuler A40 单卡上离线部署 vLLM 和 DeepSeek-R1-Distill-Qwen-14B INT4
准备工作
-
硬件要求:
- NVIDIA A40 GPU (48GB显存)
- 足够的内存和存储空间
-
系统要求:
- openEuler 操作系统
- 已安装 NVIDIA 驱动和 CUDA
安装步骤
1. 安装依赖
# 安装基础依赖
sudo yum install -y python3 python3-devel git cmake gcc-c++# 安装CUDA相关工具包
sudo yum install -y cuda-toolkit-11-8 # 根据实际CUDA版本调整# 创建Python虚拟环境
python3 -m venv vllm-env
source vllm-env/bin/activate
2. 离线安装 vLLM
由于是离线环境,需要提前在有网络的环境中下载好所有依赖:
# 在有网络的环境中下载vLLM及其依赖
mkdir vllm-offline && cd vllm-offline
pip download vllm
pip download torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 # 根据CUDA版本调整
将下载的包(*.whl和*.tar.gz文件)复制到离线机器上,然后安装:
pip install --no-index --find-links=/path/to/vllm-offline vllm
3. 下载 DeepSeek-R1-Distill-Qwen-14B INT4 模型
在有网络的环境中下载模型:
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B-INT4
将整个模型目录复制到离线机器上。
4. 运行推理
创建推理脚本inference.py:
from vllm import LLM, SamplingParams# 初始化模型
llm = LLM(model="/path/to/DeepSeek-R1-Distill-Qwen-14B-INT4")# 设置采样参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=200)# 推理
prompt = "请介绍一下人工智能的发展历史"
outputs = llm.generate([prompt], sampling_params)# 输出结果
for output in outputs:print(f"Prompt: {output.prompt}")print(f"Generated text: {output.outputs[0].text}")
运行脚本:
python inference.py
注意事项
-
显存限制:A40有48GB显存,对于14B INT4模型应该足够,但如果遇到OOM错误,可以尝试:
- 减少
max_tokens - 使用
enable_prefix_caching=True参数
- 减少
-
性能优化:
llm = LLM(model="/path/to/DeepSeek-R1-Distill-Qwen-14B-INT4",tensor_parallel_size=1, # 单卡设置为1gpu_memory_utilization=0.9 # 可以调整以优化显存使用 ) -
模型路径:确保模型路径正确,且模型文件完整。
-
量化版本:INT4模型需要确保vLLM支持该量化格式,如有问题可能需要使用特定分支或版本的vLLM。
如需进一步优化性能或解决特定问题,可能需要根据实际环境调整参数。
注意事项
- 模型量化格式:确保使用正确的量化参数,INT4 模型通常是 AWQ 或 GPTQ 量化
- 显存限制:A40 有 48GB 显存,14B INT4 模型应该足够,但可以调整
--gpu-memory-utilization - 性能优化:可以尝试添加
--enforce-eager参数减少内存使用 - Docker 权限:确保当前用户有权限访问 GPU (在 docker 用户组中)
如果遇到问题,可以检查容器日志:
docker logs -f vllm-server
dify的离线安装
- 已经将需要的镜像上传到了服务器。

- 安装步骤
- 指南
涉及docker安装及操作均为root dify可以通过普通用户操作 需要加入docker组
#docker安装
1. 解压并安装
tar xzvf docker-24.0.7.tgz
sudo cp docker/* /usr/bin/2. 配置 Docker 服务# 创建 systemd 服务
sudo tee /etc/systemd/system/docker.service <<EOF
[Unit]
Description=Docker Application Container Engine
After=network.target[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP \$MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process[Install]
WantedBy=multi-user.target
EOF3. 启动 Docker
sudo systemctl enable docker
sudo systemctl start docker
4. 验证安装
docker --version#docker-compose安装
cp docker-compose-linux-x86_64 /usr/local/bin/docker-compose
# 赋予执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 验证安装
docker-compose --version# 手动创建 docker 组
sudo groupadd docker
授权devuser加入docker组
sudo usermod -aG docker devuser离线镜像导入
docker load -i nginx.tar
docker load -i dify-plugin-daemon.tar
docker load -i dify-web.tar
docker load -i dify-api.tar
docker load -i postgres.tar
docker load -i dify-sandbox.tar
docker load -i redis.tar
docker load -i weaviate.tar
docker load -i squid.tar重启docker
sudo systemctl restart docker修改并替换IP
.env docker-compose.middleware.yaml docker-compose.yaml middleware.env
192.168.100.105 替换为部署服务器IP
# 此处的docker目录在dify源文件中,一定要进入目录后启动应用,否则会报错
加入docker组的用户 上传dify源文件 并进入docker目录启动应用
docker-compose -f docker-compose.yaml -f docker-compose.middleware.yaml up -d
检查
docker ps登录dify首页
http://ip
首次登录需要注册 记住用户名和密码 - 解压tar文件
tar -xzvf filename.tar.gz
- 执行
# 批量导入所有镜像
docker load -i dify-api.tar
docker load -i dify-web.tar
docker load -i nginx.tar
docker load -i postgres.tar
docker load -i redis.tar
docker load -i weaviate.tar
docker load -i dify-sandbox.tar
docker load -i dify-plugin-daemon.tar
docker load -i squid.tar# 查看导入的镜像
docker images# 给执行权限(如果需要)
chmod +x docker-compose-linux-x86_64# 直接运行
./docker-compose-linux-x86_64 up -d# 等基础服务正常后,再单独处理 nginx
./docker-compose-linux-x86_64 up -d nginx# 指定启动
./docker-compose-linux-x86_64 -f docker-compose.yml up -d# 直接使用 docker ps 查看,按名称过滤
docker ps --filter "name=$(basename $(pwd))" --format "table {{.Names}}\t{{.Status}}\t{{.Ports}}"# 查看服务状态(格式化看的更清楚)
./docker-compose-linux-x86_64 ps# 查看日志
./docker-compose-linux-x86_64 logs redis# 查看所有服务的完整日志
./docker-compose-linux-x86_64 logs --tail=20# 停止所有服务,但保留容器和数据
./docker-compose-linux-x86_64 stop# 停止并移除所有容器(但保留数据卷和镜像)
./docker-compose-linux-x86_64 down# 强制快速停止
./docker-compose-linux-x86_64 down --timeout=0# 检查是否所有服务都停止了
./docker-compose-linux-x86_64 pshttp://你的服务器IP# 检查所有容器是否正常运行
docker ps# 检查服务健康状态
curl http://localhost/v1/health
- 如果使用docker compose 二进制文件直接运行需要知道volumn映射的位置
# 如果有 docker-compose.yml 文件
cat docker-compose.yml | grep -A 10 -B 2 volumes# 或者查看完整的 compose 配置
./docker-compose-linux-x86_64 config
- 查看特定服务的 volume
# 查看 postgres 的 volume 映射
docker inspect $(./docker-compose-linux-x86_64 ps -q postgres) | grep -A 10 -B 5 Mounts# 或者使用 format
docker inspect $(./docker-compose-linux-x86_64 ps -q postgres) --format='{{range .Mounts}}{{.Source}}:{{.Destination}}{{end}}'
- 假设你想查看 Dify 项目的 volume 映射
# 1. 首先启动服务(如果还没启动)
./docker-compose-linux-x86_64 up -d# 2. 查看所有服务的 volume 映射
echo "=== 所有服务的 Volume 映射 ==="
./docker-compose-linux-x86_64 ps -q | while read container_id; docontainer_name=$(docker inspect --format='{{.Name}}' $container_id)echo "容器: $container_name"docker inspect --format='{{range .Mounts}}源: {{.Source}} -> 目标: {{.Destination}} (类型: {{.Type}})
{{end}}' $container_idecho "---"
done# 3. 查看创建的 volumes
echo "=== Docker Volumes ==="
docker volume ls | grep $(basename $(pwd))# 4. 查看 compose 配置中的 volume 定义
echo "=== Compose 文件中的 Volume 配置 ==="
./docker-compose-linux-x86_64 config | grep -A 20 volumes