Unity学习之常用的数据结构
在 Unity 开发中,选择正确的数据结构对于代码的性能、可读性和可维护性至关重要。一个不合适的数据结构可能会在游戏运行时,尤其是在性能敏感的部分(如Update循环、物理回调),成为性能瓶颈。
以下是 Unity(C#)开发中最常用的数据结构的详细总结,涵盖了从基础到高级的各类结构,并重点分析了它们的优缺点、适用场景和开发注意事项。
一、线性集合 (Linear Collections)
这类数据结构中的元素按顺序排列,适合需要遍历所有元素的场景。
1. List<T>
(1) List<T>是什么?
List<T> 是 C# 中最常用的泛型动态数组,它属于 System.Collections.Generic 命名空间。当容量不足时,会创建一个更大的新数组,并将旧数组的元素复制过去。
(2) List<T>的核心工作原理
List<T> 的内部其实维护着一个私有的数组来存储数据。当你添加元素时:
a. 如果内部数组还有空间,直接将元素放入。
b. 如果内部数组已满,List<T> 会执行以下操作:
-- 创建一个更大的新数组(通常是当前容量的 2 倍)
-- 将旧数组中的所有元素复制到新数组中。
-- 释放旧数组的内存。
-- 将新元素添加到新数组中。
注意:
这个 “扩容” 过程是性能开销较大的操作,因为它涉及到内存分配和数据复制。因此,如果你预先知道大概需要存储多少元素,可以使用 Capacity 属性或 List<T>(int capacity) 构造函数来预先分配足够的空间,从而避免频繁的自动扩容。
(3) List<T>常用的接口(方法与属性)
Count: List 中实际包含的元素数量。
Capacity: List 内部数组可以容纳的元素总数(不重新分配内存的情况下)。
-- 始终满足 Capacity >= Count
-- 当 Count 即将超过 Capacity 时,List 会自动扩容。
创建和初始化
// 1. 创建一个空的List
List<string> fruits = new List<string>();// 2. 创建一个具有指定初始容量的List
List<int> numbers = new List<int>(100); // 预先分配100个元素的空间// 3. 使用集合初始化器创建并添加元素
List<string> colors = new List<string> { "Red", "Green", "Blue" };// 4. 从一个已有的数组或IEnumerable创建
int[] arr = { 1, 2, 3 };
List<int> numList = new List<int>(arr);添加元素
List<string> fruits = new List<string>();// 添加单个元素
fruits.Add("Apple");
fruits.Add("Banana");// 添加另一个集合中的所有元素
List<string> moreFruits = new List<string> { "Orange", "Grape" };
fruits.AddRange(moreFruits); // fruits: { "Apple", "Banana", "Orange", "Grape" }// 在指定索引处插入元素
fruits.Insert(1, "Pineapple"); // fruits: { "Apple", "Pineapple", "Banana", "Orange", "Grape" }访问和修改元素
List<string> fruits = new List<string> { "Apple", "Banana", "Orange" };// 通过索引访问(和数组一样)
string firstFruit = fruits[0]; // "Apple"// 通过索引修改
fruits[1] = "Mango"; // fruits: { "Apple", "Mango", "Orange" }// 获取所有元素的只读列表
IReadOnlyList<string> readOnlyFruits = fruits.AsReadOnly();
// readOnlyFruits[0] = "Pear"; // 错误!只读列表不能修改查找元素
List<string> fruits = new List<string> { "Apple", "Banana", "Orange", "Apple" };// 检查是否包含某个元素
bool hasBanana = fruits.Contains("Banana"); // true// 查找某个元素的索引
int index = fruits.IndexOf("Apple"); // 0 (返回第一个匹配项的索引)
int lastIndex = fruits.LastIndexOf("Apple"); // 3 (返回最后一个匹配项的索引)// 查找第一个满足条件的元素 (非常常用!)
string longNameFruit = fruits.Find(f => f.Length > 5); // "Banana"// 查找所有满足条件的元素
List<string> shortNameFruits = fruits.FindAll(f => f.Length <= 5); // { "Apple", "Apple" }删除元素
List<string> fruits = new List<string> { "Apple", "Banana", "Orange", "Grape" };// 按值删除(删除第一个匹配项)
bool removed = fruits.Remove("Banana"); // true, fruits: { "Apple", "Orange", "Grape" }// 按索引删除
fruits.RemoveAt(1); // fruits: { "Apple", "Grape" }// 删除所有满足条件的元素
fruits.RemoveAll(f => f.StartsWith("A")); // fruits: { "Grape" }// 清空列表
fruits.Clear(); // fruits: { }排序和反转
List<int> numbers = new List<int> { 5, 2, 8, 1, 9, 4 };// 排序(默认升序)
numbers.Sort(); // numbers: { 1, 2, 4, 5, 8, 9 }// 使用自定义比较器排序(降序)
numbers.Sort((a, b) => b.CompareTo(a)); // numbers: { 9, 8, 5, 4, 2, 1 }// 反转列表顺序
numbers.Reverse(); // numbers: { 1, 2, 4, 5, 8, 9 }转换数组Array,以及字符串
List<int> numbers = new List<int> { 1, 2, 3, 4 };// 转换为数组
int[] numArray = numbers.ToArray();// 转换为字符串(需要先选择字符串表示)
string numbersString = string.Join(", ", numbers); // "1, 2, 3, 4"2. List<T>与Array、ArrayList
Array(T[]) 固定大小的一维数组。连续的内存块。命名空间System。
ArrayList 动态数组。非泛型的、可调整大小的对象集合。命名空间System.Collections。
List<T> 动态数组。内部维护一个数组,大小可自动调整。命名空间System.Collections.Generic
(1) 类型安全(Type Safey)
这是 ArrayList 与其他两者最核心的区别。
Array与List<T> 类型安全(强类型),在声明时必须指定元素类型,如 List<int>、string[]。
编译时检查。如果你尝试添加错误类型的元素,编译器会立即报错。无需装箱 / 拆箱。值类型(如 int, float)可以直接存储,性能高。
List<int> intList = new List<int>();
intList.Add(10); // 正确
// intList.Add("hello"); // 编译时错误!无法将 string 转换为 intArrayList 弱类型。它将所有元素都视为 object 类型。你可以向其中添加任何类型的元素,编译器不会阻止你。
装箱 : 当你添加一个值类型(如 int)时,它会被包装成一个 object 对象,这涉及到堆内存分配,开销较大。
拆箱: 当你从 ArrayList 中取出元素时,必须进行强制类型转换,将 object 转换回原始类型。如果类型不匹配,会在运行时抛出 InvalidCastException 异常。
ArrayList arrayList = new ArrayList();
arrayList.Add(10); // int 被装箱为 object
arrayList.Add("hello"); // string 是引用类型,无需装箱
arrayList.Add(true); // bool 被装箱为 object// 运行时错误!无法将 string "hello" 转换为 int
// int value = (int)arrayList[1]; (2) 大小与灵活性
List<T> 和 ArrayList:动态大小。可以随时通过 Add()、AddRange()、Insert() 等方法添加元素,集合会自动扩容。可以删除。提供了 Remove()、RemoveAt()、RemoveAll() 等方法来删除元素。
Array(T[]) 固定大小。在创建时必须指定其长度,之后不能更改。不能直接添加 / 删除。如果你想 “添加” 或 “删除” 元素,必须创建一个新的数组,将旧数组的元素复制过去,这是一个 O (n) 的高开销操作。
// 数组的“添加”操作很麻烦
int[] oldArray = { 1, 2, 3 };
int[] newArray = new int[oldArray.Length + 1];
for (int i = 0; i < oldArray.Length; i++)
{newArray[i] = oldArray[i];
}
newArray[newArray.Length - 1] = 4; // newArray: {1, 2, 3, 4}(3) 三者性能比较
随机访问
Array O(1)最快
List<T> O(1) 非常快
ArrayList O(1) 快 但是有拆箱的开销
末尾添加元素
Array 不支持(一开始固定数组)
List<T> O(1) (平均)。如果内部数组未满,是 O (1)。如果需要扩容,则是 O (n)。
ArrayList O(1) (平均)。同 List<T>,但有装箱开销。
遍历元素
Array 不支持
List<T> O(n)。需要移动后续所有元素。
ArrayList O(n)。同 List<T>,但有装箱 / 拆箱开销。
中间 / 头部添加 / 删除
Array 最快。内存连续,CPU 缓存友好
List<T> 快。强类型,无拆箱。
ArrayList 慢。需要对每个元素进行拆箱,开销大。
内存开销
Array 额外开销。除了元素本身,还需要存储 Count 和 Capacity 等信息。可能有未使用的内存(Capacity > Count)。
List<T> 快。强类型,无拆箱。
ArrayList 额外开销。除了元素本身,还有 Count 和 Capacity。每个值类型元素都有装箱的额外开销。
推荐:
1. C# 开发中,大多数情况优先选择 List<T>。它在类型安全、性能和开发效率之间取得了最佳平衡。
2. 只有当你明确需要极致的性能和最小的内存占用,并且数据大小固定时,才考虑使用 T[]。
3. ArrayList 是一个过时的类型,仅应用于维护旧项目。在任何新代码中使用它都应被视为代码异味(Code Smell)。
3. Queue<T>
Queue<T>(泛型队列)是一种遵循先进先出(FIFO, First-In-First-Out) 规则的动态数据结构,专门用于处理 “先进入的数据先被处理” 的场景(如任务排队、消息队列等)。
(1) 基本概念
--- FIFO 规则:第一个添加的元素(队首,Head)会第一个被移除,最后添加的元素(队尾,Tail)最后被移除,类似现实中的 “排队买票”。
--- 类型安全:通过泛型 <T> 限定元素类型,避免非泛型 Queue 的装箱 / 拆箱开销和类型转换错误。
--- 动态扩容:初始容量可配置,当元素数量超过容量时,会自动扩容以容纳更多元素。
(2) 底层实现原理
Queue<T> 内部通过循环数组(Circular Array) 实现,而非链表(链表实现的队列通常叫 LinkedList<T>),其核心设计是为了平衡 “随机访问效率” 和 “队列操作效率”:
--- 循环数组:数组的首尾逻辑上相连,通过两个指针(_head 指向队首,_tail 指向队尾的下一个位置)标记队列范围,避免元素移动带来的性能损耗。
--- 扩容机制:当元素数量(Count)达到数组容量(Capacity)时,会创建一个新的、容量为原容量 2 倍的数组,并将原数组的元素按顺序复制到新数组,最后替换原数组(类似 List<T> 的扩容逻辑)。
(3)Queue<T> 常用接口(方法与属性)
Queue<T> 的接口设计简洁且专注于队列核心操作(添加、移除、查看),避免冗余功能,以下是高频使用的属性和方法:
初始化
using System.Collections.Generic;// 1. 无参构造:初始容量为 4,元素类型为 int
Queue<int> taskQueue = new Queue<int>();// 2. 指定初始容量:避免频繁扩容(推荐已知元素数量范围时使用)
Queue<string> messageQueue = new Queue<string>(100); // 初始容量 100// 3. 从现有集合初始化:将 IEnumerable<T> 的元素按顺序加入队列
List<DateTime> timeList = new List<DateTime> { DateTime.Now, DateTime.Now.AddHours(1) };
Queue<DateTime> timeQueue = new Queue<DateTime>(timeList); // 队列元素:[Now, Now+1h]核心操作(Enqueue/Dequeue/Peek)
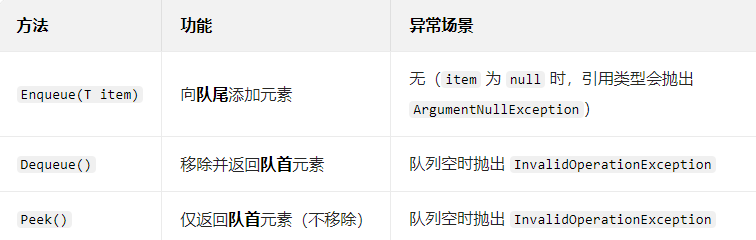
Queue<string> orderQueue = new Queue<string>();// 1. 入队(Enqueue):添加订单到队尾
orderQueue.Enqueue("订单001");
orderQueue.Enqueue("订单002");
orderQueue.Enqueue("订单003");
Console.WriteLine($"队列元素数:{orderQueue.Count}"); // 输出:3// 2. 查看队首(Peek):查看第一个订单,不移除
string firstOrder = orderQueue.Peek();
Console.WriteLine($"当前第一个订单:{firstOrder}"); // 输出:订单001
Console.WriteLine($"查看后元素数:{orderQueue.Count}"); // 输出:3(未减少)// 3. 出队(Dequeue):处理第一个订单,移除并返回
string processedOrder = orderQueue.Dequeue();
Console.WriteLine($"处理完成的订单:{processedOrder}"); // 输出:订单001
Console.WriteLine($"处理后元素数:{orderQueue.Count}"); // 输出:2(减少1)// 4. 循环出队:处理剩余订单
while (orderQueue.Count > 0)
{string nextOrder = orderQueue.Dequeue();Console.WriteLine($"处理订单:{nextOrder}"); // 依次输出:订单002、订单003
}// 5. 空队列操作:会抛出异常
// orderQueue.Dequeue(); // 抛出 InvalidOperationException: 队列是空的辅助操作(判断、清空、复制)
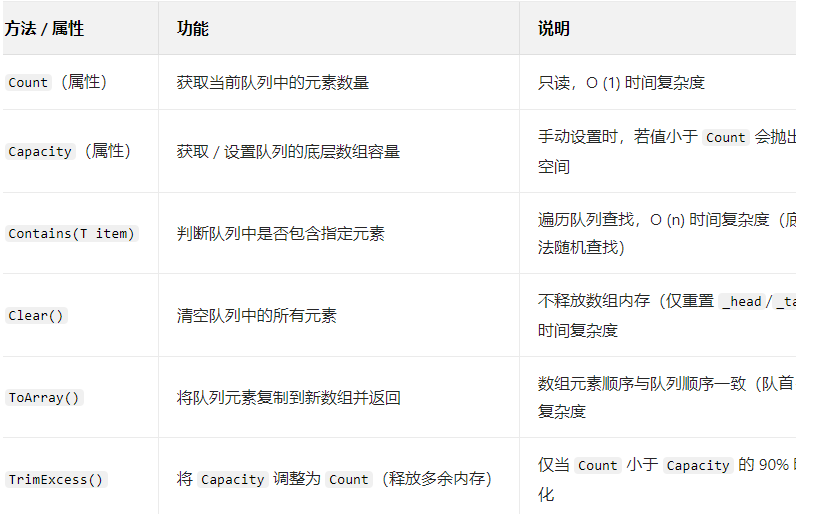
Queue<int> numQueue = new Queue<int>(new[] { 1, 2, 3, 4, 5 });// 1. 判断元素是否存在
bool has3 = numQueue.Contains(3); // true
bool has6 = numQueue.Contains(6); // false// 2. 查看容量与元素数
Console.WriteLine($"容量:{numQueue.Capacity}"); // 初始容量 5(因初始化数组长度为5)
Console.WriteLine($"元素数:{numQueue.Count}"); // 5// 3. 手动调整容量(预分配空间)
numQueue.Capacity = 10; // 扩容到10,此时 Count=5,Capacity=10
Console.WriteLine($"调整后容量:{numQueue.Capacity}"); // 10// 4. 释放多余内存
numQueue.TrimExcess(); // 因 Count=5 < 10*90%=9,Capacity 调整为5
Console.WriteLine($"Trim后容量:{numQueue.Capacity}"); // 5// 5. 转为数组
int[] numArray = numQueue.ToArray(); // 数组:[1,2,3,4,5]// 6. 清空队列
numQueue.Clear();
Console.WriteLine($"清空后元素数:{numQueue.Count}"); // 0
Console.WriteLine($"清空后容量:{numQueue.Capacity}"); // 5(数组内存未释放)4. Stack<T>
Stack<T> 是一种遵循后进先出(LIFO, Last-In-First-Out) 规则的动态数据结构,其核心思想是 “最后放入的元素最先被取出”,类似于现实生活中 “一摞盘子” 或 “浏览器的后退按钮”。
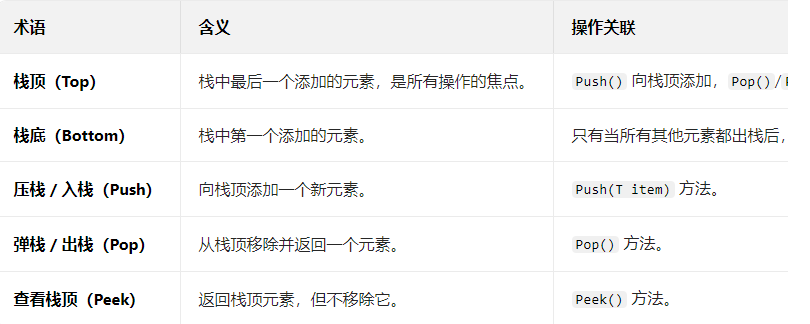
(1) 基本概率
--- LIFO 规则:最后一个添加的元素(栈顶,Top)会第一个被移除,第一个添加的元素(栈底,Bottom)最后被移除。
--- 类型安全:通过泛型 <T> 限定元素类型,避免了非泛型 Stack 的装箱 / 拆箱开销和类型转换错误。
--- 动态扩容:初始容量可配置,当元素数量超过容量时,会自动扩容以容纳更多元素。
(2)底层实现原理
Stack<T> 的内部实现非常直接,就是一个动态数组。它维护一个指针(_size)来记录栈顶的位置。
a. 入栈(Push):将元素添加到数组的当前 _size 位置,然后 _size 加 1。
b. 出栈(Pop):将 _size 减 1,然后返回数组 _size 位置的元素。
c. 扩容机制:当元素数量(Count)达到数组容量(Capacity)时,会创建一个新的、容量为原容量 2 倍的数组,并将原数组的元素按顺序复制到新数组中,最后替换原数组。
(3) Stack<T> 的常用接口(方法与属性)
Stack<string> browserHistory = new Stack<string>();// 1. 入栈(Push):记录浏览历史
browserHistory.Push("首页");
browserHistory.Push("产品列表");
browserHistory.Push("产品详情页");
Console.WriteLine($"栈中元素数:{browserHistory.Count}"); // 输出:3// 2. 查看栈顶(Peek):查看当前页面,不移除记录
string currentPage = browserHistory.Peek();
Console.WriteLine($"当前页面:{currentPage}"); // 输出:产品详情页
Console.WriteLine($"查看后元素数:{browserHistory.Count}"); // 输出:3(未减少)// 3. 出栈(Pop):点击后退按钮,移除当前页并返回上一页
string previousPage = browserHistory.Pop();
Console.WriteLine($"从 '{previousPage}' 后退"); // 输出:从 '产品详情页' 后退
Console.WriteLine($"后退后当前页面:{browserHistory.Peek()}"); // 输出:产品列表
Console.WriteLine($"后退后元素数:{browserHistory.Count}"); // 输出:2(减少1)// 4. 循环出栈:连续后退
while (browserHistory.Count > 0)
{string page = browserHistory.Pop();Console.WriteLine($"继续后退到:{page}"); // 依次输出:产品列表、首页
}// 5. 空栈操作:会抛出异常
// browserHistory.Pop(); // 抛出 InvalidOperationException: 栈为空。5.LinkedList<T>
LinkedList<T> 属于 System.Collections.Generic 命名空间,是一个泛型双向链表。
(1) 基本概念
--- 非连续存储:元素(节点)在内存中不是连续存放的,每个节点都包含数据和指向下一个 / 上一个节点的引用。
--- 双向链接:每个节点(LinkedListNode<T>)都有一个 Next 引用(指向下一个节点)和一个 Previous 引用(指向上一个节点),这使得正向和反向遍历都非常高效。
--- 动态大小:链表的大小可以动态增长或收缩,无需像数组那样预先分配内存或在容量不足时进行昂贵的 “扩容” 操作。
(2)底层实现原理
LinkedList<T> 的内部由一系列 LinkedListNode<T> 对象组成,其核心结构包括:
--- 头节点(Head):链表的第一个节点。
--- 尾节点(Tail):链表的最后一个节点。
--- 节点(LinkedListNode<T>):链表的基本单元,包含三个关键部分:
a. Value:节点存储的实际数据(类型为 T)。
b. Next:指向下一个 LinkedListNode<T> 的引用。
c. Previous:指向上一个 LinkedListNode<T> 的引用。
(3)LinkedList<T> 的常用接口(方法与属性)
LinkedList<string> fruits = new LinkedList<string>();// 1. 在开头和末尾添加
fruits.AddLast("Apple"); // [Apple]
fruits.AddFirst("Banana"); // [Banana, Apple]
fruits.AddLast("Cherry"); // [Banana, Apple, Cherry]// 2. 查找节点
LinkedListNode<string> appleNode = fruits.Find("Apple"); // 获取 "Apple" 节点的引用// 3. 在指定节点前后添加
if (appleNode != null)
{fruits.AddBefore(appleNode, "Peach"); // [Banana, Peach, Apple, Cherry]fruits.AddAfter(appleNode, "Orange"); // [Banana, Peach, Apple, Orange, Cherry]
}// 4. 删除节点
fruits.RemoveFirst(); // 移除 "Banana" -> [Peach, Apple, Orange, Cherry]
fruits.RemoveLast(); // 移除 "Cherry" -> [Peach, Apple, Orange]// 通过值删除(内部会先 Find,所以是 O(n))
fruits.Remove("Apple"); // [Peach, Orange]// 通过节点引用删除(O(1))
LinkedListNode<string> orangeNode = fruits.Find("Orange");
if (orangeNode != null)
{fruits.Remove(orangeNode); // [Peach]
}二、 键值对集合 (Key-Value Pair Collections)
这类数据结构通过一个唯一的 “键”(Key)来快速访问 “值”(Value),是快速查找的首选。
1. Dictionary<TKey, TValue>
Dictionary<TKey, TValue> 是一种键值对(Key-Value Pair) 集合,它通过一个唯一的 “键”(Key)来快速查找对应的 “值”(Value)。其核心优势是极快的查找速度,这得益于其底层的哈希表(Hash Table) 数据结构。
(1) 基本概念
Dictionary<TKey, TValue> 属于 System.Collections.Generic 命名空间。
a. 键值对存储:每个元素都是一个 KeyValuePair<TKey, TValue> 结构,包含一个键和一个值。
b. 键的唯一性:字典中的每个键(Key)都必须是唯一的。如果你尝试添加一个已存在的键,会抛出 ArgumentException。
c. 类型安全:通过泛型 <TKey, TValue> 分别限定键和值的类型,避免了非泛型 Hashtable 的装箱 / 拆箱和类型转换问题。
(2)底层实现原理
a. 内部结构:字典内部维护一个桶(Buckets)数组。每个 “桶” 可以看作是一个槽位,它可能为空,也可能指向一个链表或数组(用于解决哈希冲突)
b. 存储过程(Add 或 [] 赋值):
--- 当你添加一个键值对 (key, value) 时,字典会首先调用 key.GetHashCode() 方法,计算出一个哈希码(Hash Code)。
--- 字典使用一个哈希函数将这个哈希码转换为一个索引,该索引对应于 “桶” 数组的某个位置。
--- 字典将包含 key 和 value 的数据结构放入该索引对应的 “桶” 中。
c. 查找过程(ContainsKey, TryGetValue, [] 取值):
--- 当你根据一个 key 查找值时,字典会执行与存储时完全相同的操作。
--- 再次调用 key.GetHashCode() 获取哈希码。
--- 通过相同的哈希函数计算出索引,直接定位到目标 “桶”。在该 “桶” 中查找与传入 key 完全匹配(使用 key.Equals() 方法)的项并返回其值。
(3)基本操作接口
核心操作(添加、访问、修改、删除)
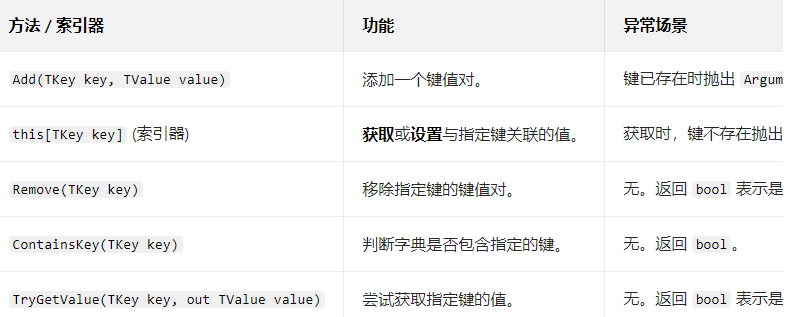
Dictionary<string, string> capitals = new Dictionary<string, string>();// 1. 添加元素
capitals.Add("China", "Beijing");
capitals.Add("USA", "Washington D.C.");
// capitals.Add("China", "Shanghai"); // 错误!键 "China" 已存在,会抛出 ArgumentException// 2. 使用索引器添加或修改
capitals["Japan"] = "Tokyo"; // 添加新键值对
capitals["USA"] = "Washington"; // 修改已存在键的值// 3. 访问元素
string chinaCapital = capitals["China"]; // 获取值
Console.WriteLine($"中国的首都是: {chinaCapital}");// 4. 安全访问元素 (推荐)
if (capitals.TryGetValue("France", out string franceCapital))
{Console.WriteLine($"法国的首都是: {franceCapital}");
}
else
{Console.WriteLine("字典中没有找到法国。");
}// 5. 判断键是否存在
if (capitals.ContainsKey("Japan"))
{Console.WriteLine("字典中包含日本。");
}// 6. 删除元素
bool isRemoved = capitals.Remove("USA");
if (isRemoved)
{Console.WriteLine("已成功移除美国。");
}注意:
--- 使用 dict["key"] 获取值时,如果键不存在,会抛出 KeyNotFoundException 异常。你需要使用 try-catch 块来处理,或者在获取前先用 ContainsKey 判断。
--- 使用 dict.TryGetValue("key", out var value) 是更高效、更推荐的方式。它不会抛出异常,而是通过返回 bool 值来告诉你键是否存在,同时将获取到的值通过 out 参数返回。
字典数据遍历
Dictionary<string, int> productPrices = new Dictionary<string, int>
{{"Apple", 5},{"Banana", 3},{"Orange", 4}
};// 方式1:遍历所有键值对 (最常用)
Console.WriteLine("--- 遍历所有键值对 ---");
foreach (var item in productPrices)
{Console.WriteLine($"商品: {item.Key}, 价格: {item.Value}");
}// 方式2:只遍历键
Console.WriteLine("\n--- 只遍历键 ---");
foreach (var key in productPrices.Keys)
{Console.WriteLine($"商品名称: {key}");
}// 方式3:只遍历值
Console.WriteLine("\n--- 只遍历值 ---");
foreach (var value in productPrices.Values)
{Console.WriteLine($"商品价格: {value}");
}2.HashSet<T>
HashSet<T> 泛型哈希集是一种专门用于存储唯一元素的集合,它不保证元素的任何特定顺序。其核心价值在于提供了极快的添加、删除和查找操作,这同样得益于其底层的哈希表(Hash Table) 数据结构。
(1)基本概念
HashSet<T> 属于 System.Collections.Generic 命名空间。
--- 唯一性:集合中不允许存在重复的元素。如果你尝试添加一个已存在的元素,操作将被忽略,不会抛出异常。
--- 无序性:HashSet<T> 不保证元素的顺序。元素的存储位置由其哈希码决定,因此遍历 HashSet<T> 的结果顺序可能与添加顺序不同。
--- 高性能:基于哈希表实现,使其添加、删除和查找元素的平均时间复杂度都为 O(1)。
(2)底层实现原理
HashSet<T> 的底层实现与 Dictionary<TKey, TValue> 非常相似,但它只存储 “键”(即元素本身),而没有与之关联的 “值”。
--- 内部结构:同样维护一个桶(Buckets)数组。每个 “桶” 对应一个哈希码,并可能指向一个存储元素的链表或数组(用于解决哈希冲突)。
--- 存储过程(Add):
a. 调用元素的 GetHashCode() 方法计算哈希码。
b. 过哈希函数将哈希码转换为 “桶” 数组的索引。
c. 在该索引对应的 “桶” 中查找元素是否已存在(使用 Equals() 方法比较)。如果元素不存在,则将其添加到 “桶” 中。如果元素已存在,则 Add 方法返回 false,表示添加失败。
--- 查找过程(Contains):
a. 调用元素的 GetHashCode() 方法计算哈希码。
b. 通过哈希函数定位到 “桶”。
c. 在 “桶” 中查找元素。如果找到,Contains 方法返回 true。
(3)基本操作接口
HashSet<string> fruits = new HashSet<string>();// 1. 添加元素
bool isAppleAdded = fruits.Add("Apple"); // true, fruits: { "Apple" }
bool isBananaAdded = fruits.Add("Banana"); // true, fruits: { "Apple", "Banana" }
bool isAppleAddedAgain = fruits.Add("Apple"); // false, "Apple" 已存在, fruits: { "Apple", "Banana" }Console.WriteLine($"Apple 添加成功? {isAppleAdded}");
Console.WriteLine($"Apple 再次添加成功? {isAppleAddedAgain}");// 2. 判断元素是否存在
bool hasBanana = fruits.Contains("Banana"); // true
bool hasOrange = fruits.Contains("Orange"); // false// 3. 删除元素
bool isBananaRemoved = fruits.Remove("Banana"); // true, fruits: { "Apple" }
bool isOrangeRemoved = fruits.Remove("Orange"); // false, "Orange" 不存在// 4. 清空集合
fruits.Clear(); // fruits: { }