图文讲解k8s中Service、Selector、EndpointSlice的运行原理
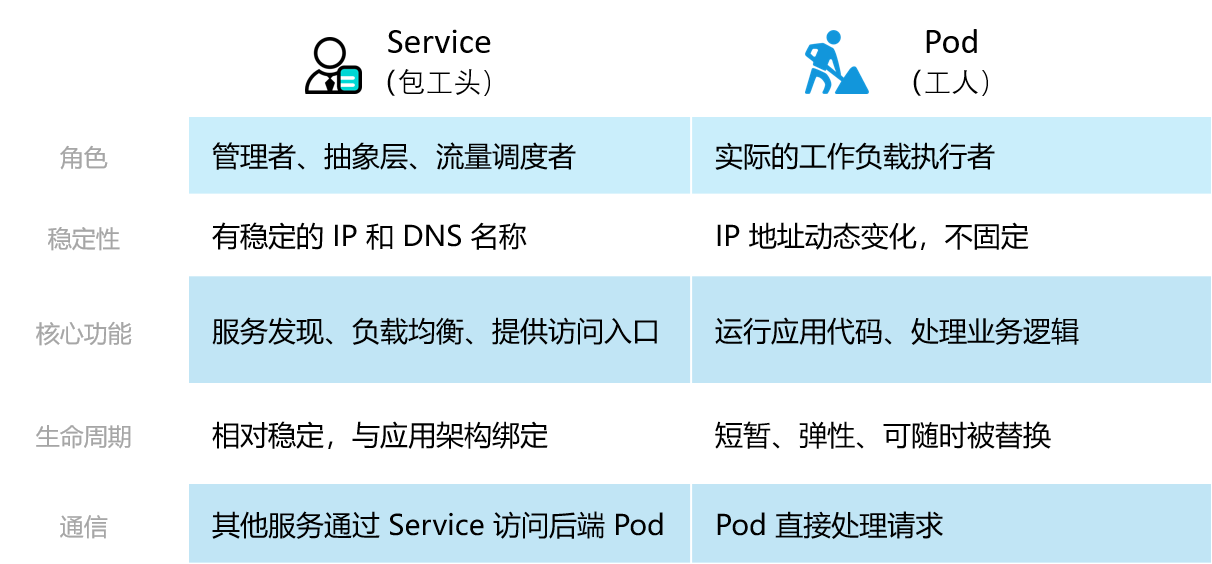
K8s中,Pod对象用来执行某种任务,它们的结果要能被其它应用组Pod访问的话,必须有一个稳定的代理对象,因为Pod个体自身状态是脆弱的。访问者需要连接稳定的代理对象服务,这就是service的用途和意义。
Service的官方定义:
Kubernetes 中 Service 是 将运行在一个或一组 Pod 上的网络应用程序公开为网络服务的方法。
Kubernetes 中 Service 的一个关键目标是让你无需修改现有应用以使用某种不熟悉的服务发现机制。
上面的定义对新手来说,还是比较抽象。下面是用比喻法来说明Service定义。
一、k8s中的service如同“包工头”角色
想象一个建筑工地(Kubernetes 集群):
-
Pod = 干活的工人:他们是实际执行任务的个体(运行容器应用)。工人们可能因为各种原因(生病、请假、被调去别的工地)来来去去,他们的姓名(Pod IP)和位置(在哪个节点上)是动态变化的。
-
Service = 包工头:他本身不亲自砌砖、搬水泥,但他有非常重要的作用:
1. 统一接口与负载均衡
包工头:是和外界的唯一联络点。需求方不需要知道具体是张三还是李四在干活,他只需要把任务要求告诉包工头。
Service:Service 提供一个稳定的访问端点(VIP 和 DNS 名称),比如
my-app-service。前端服务或用户只需要访问这个固定的地址,而不需要关心后端具体是哪个 Pod 在响应。Service 会自动将请求负载均衡到后端健康的 Pod 上。
2. 服务发现
包工头:包工头手里有一份最新的、可用的工人名单。当有工人离开或新工人加入时,他会实时更新这份名单。
Service:Service 通过 Label Selector(标签选择器)来识别和管理属于它的 Pod。例如,所有带有
app: my-app标签的 Pod 都会被这个 Service 管理。当新的 Pod 被创建并带有匹配的标签时,Service 会自动将其加入负载均衡池;当 Pod 被删除时,会自动将其移除。这就是 Kubernetes 的服务发现机制。
3. 屏蔽后端变化
包工头:即使工地上的工人换了一茬又一茬,项目经理也感觉不到,因为他只跟包工头打交道。
Service:Pod 是“ ephemeral ”(短暂的)的,它们的 IP 地址会随着重启、调度而改变。但 Service 的 IP 地址(ClusterIP)和 DNS 名称在生命周期内是稳定的。这为微服务架构提供了强大的抽象能力,使得服务间的通信不依赖于易变的后端实例。
4. 定义不同的访问方式(Service Type)
包工头可以根据项目需求,提供不同的对接方式:
ClusterIP(默认):像一个内部工头。他只负责在工地内部(集群内部)协调各个施工队(服务)之间的协作。外部无法直接访问他。
NodePort:像一个在工地围墙上开了几个固定通道的工头。外部人员可以通过访问任意一个工地大门(任意节点的 IP 地址)和指定的门牌号(端口号)来找到这个工头,进而进入工地。
LoadBalancer:像一个配备了专业接待大厅和指路牌的工头。通常由云服务商(如 AWS, GCP)提供,它会自动创建一个外部负载均衡器,并分配一个外部 IP。外部用户直接访问这个 VIP 接待大厅即可。
ExternalName:像一个转接电话的工头。当有人来找一个服务时,他实际上是把请求转发到集群外部的另一个地址(例如,一个传统数据库服务)。
“包工头”比喻能够准确地描述了 Service 的核心价值——提供一个稳定的抽象层,来屏蔽后端 Pod 的动态和不稳定性,并智能地分发流量。
这正是微服务在动态的云原生环境中能够可靠运行的关键所在。
每当想到 Service 时,脑子里浮现出这个精明能干、手握工人名单、负责派活儿的“包工头”,就完全理解了它的作用!
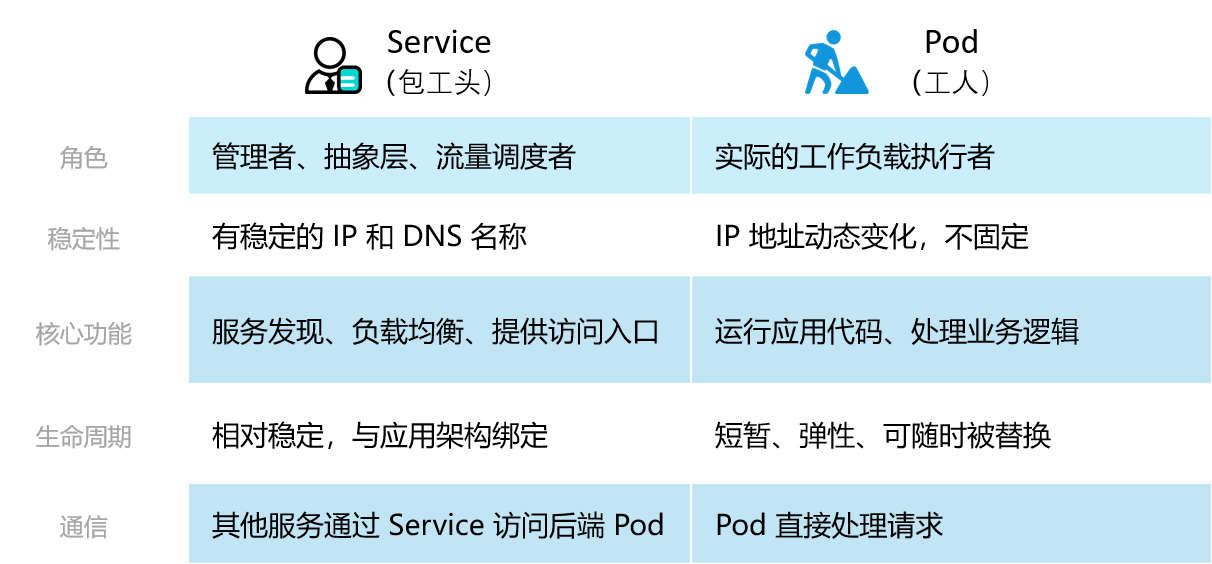
二、与Service相关的Selector和EndpointSlice用途
一个 Service 指向的一组 Pod 是由标签选择算符定义的。
Selector(选择器) 是 Kubernetes 中用于筛选和关联一组具有相同标签(Labels)的 Pod 或其他 API 对象的机制。
您可以把它理解为一个过滤器或查询条件。Service通过使用选择器,来找到它们需要管理或交互的 Pod。
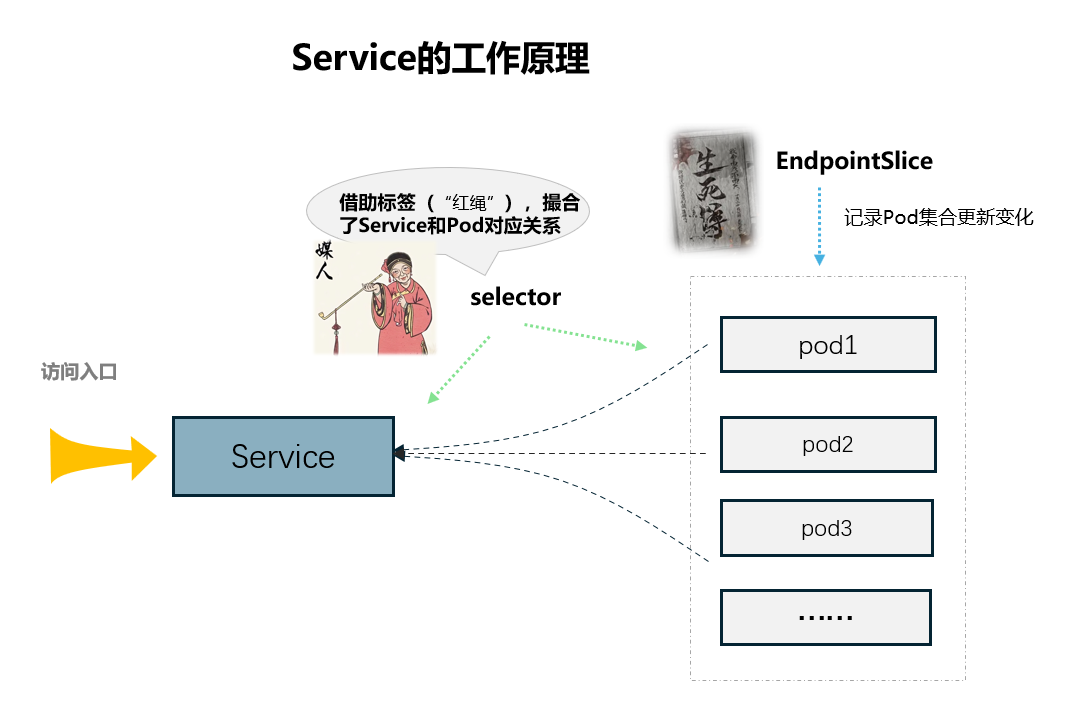
k8s中的Selector就像媒婆或者红娘一样,专为Service和pod牵线,在“媒婆” 的小笔记本里,偷偷记录了Service的目标条件 (Selector 条件),再去看看哪些Pod 身上(配置里lable值)有这样的标签,如果匹配一致,然后两边就牵手成功。
这里不得不提到EndpointSlice的作用。
在Kubernetes中,Service通过Selector选择一组Pod,然后Service的流量会被负载均衡到这些Pod上。但是,Service并不是直接存储这些Pod的IP地址,而是通过EndpointSlice(在旧版本中是通过Endpoints)来维护这些Pod的地址信息。
关于EndpointSlice的介绍请看2.3章节。
1. Service和Pod 的关联示例
# Pod (通常由 Deployment 管理,这里只显示 Pod 的标签部分)
apiVersion: v1
kind: Pod
metadata:name: my-app-podlabels:app: my-app # <-- 这个标签tier: backend
spec:containers:- name: my-appimage: my-app:latest---
# Service
apiVersion: v1
kind: Service
metadata:name: my-service
spec:selector:app: my-app # <-- 选择所有带有 `app: my-app` 标签的 Podports:- protocol: TCPport: 80targetPort: 8080定义 Service 的流量目标,这是 Selector 最常用、最直接的用途。Service 通过 selector 字段来指定哪些 Pod 应该作为服务的后端,接收由 Service 负载均衡的流量。
2.Selector 的匹配类型
在定义 Selector 时,主要有两种匹配方式:
1.matchLabels:精确的键值对匹配。这是最常用的方式。
selector:matchLabels:app: my-appenvironment: production2.matchExpressions:基于表达式进行更复杂的匹配,支持 In、NotIn、Exists 和 DoesNotExist 等操作符。
selector:matchExpressions:- {key: tier, operator: In, values: [frontend, backend]}- {key: environment, operator: NotIn, values: [dev]}简单来说,Selector 是 Kubernetes 中实现松耦合、动态关联的核心。
它通过一个简单的“标签-选择器”机制,将不同的组件(如 Service、Deployment、Pod)灵活地连接在一起,而无需硬编码 IP 地址或 Pod 名称。这使得应用部署、扩展和管理变得非常灵活和强大。
3.EndpointSlice用途介绍
EndpointSlice 充当了 Service 和 Pod 之间的动态桥梁。
1. 存储和分发后端端点信息
EndpointSlice 自动维护并存储所有与 Service Selector 匹配的、状态为 Ready 的 Pod 的网络端点(IP:Port)信息。
工作流程如下:
1.用户创建 Service:您在 Service 的 spec.selector 中定义了 app: my-app。
2.EndpointSlice 控制器开始工作:Kubernetes 系统中的一个控制器(endpointslice-controller)会持续监控:
- 所有 Pod 的变化(创建、删除、就绪状态变更)。
- 所有 Service 的变化。
3. 动态匹配与更新:
- 控制器使用 Service 的 Selector 作为查询条件,去筛选集群中的所有 Pod。
- 它会找到所有标签为 app: my-app 且 status.phase 为 Running 并且所有容器的就绪探针通过的 Pod。
- 对于每个匹配的 Pod,控制器会创建一个 Endpoint 记录(注意,这里是 EndpointSlice 里的一个条目,不是旧的 Endpoints 对象)。
4.创建 EndpointSlice 对象:这些端点的集合被组织成一个或多个 EndpointSlice 对象。每个 EndpointSlice 包含最多 100 个端点(这是可配置的),以避免单个对象过大。
2. 为 kube-proxy 提供高效的数据源
这是 EndpointSlice 最重要的消费者端。
kube-proxy 在每个节点上运行,它负责配置节点上的 iptables、ipvs 或 nftables 规则,以实现 Service 的负载均衡和流量转发。
kube-proxy 监听(Watch)EndpointSlice 的 API,而不是旧的 Endpoints。
当 EndpointSlice 发生变化时(例如,一个新的 Pod 被创建并就绪),kube-proxy 会立即收到通知。
kube-proxy 根据新的 EndpointSlice 数据,更新本地的负载均衡规则,将新的 Pod IP 加入转发目标,或将不可用的 Pod IP 移除。
换个概念讲,EndpointSlice 就是Pod 的“生死簿”。Pod集合内有新增、死亡都会更新到EndpointSlice那里,然后再给Service和kube-proxy提供分发、路由策略。
三、k8s中创建Service的命令
当每个 Service 创建时,会被分配一个唯一的 IP 地址(也称为 clusterIP)。 这个 IP 地址与 Service 的生命周期绑定在一起,只要 Service 存在,它就不会改变。
假设有一组在一个扁平的、集群范围的地址空间中运行 Nginx 服务的 Pod。
可以使用 kubectl expose 命令为 2 个 Nginx 副本创建一个 Service:
kubectl expose deployment/my-nginxservice/my-nginx exposed这等价于使用 kubectl create -f 命令及如下的 yaml 文件创建:
apiVersion: v1
kind: Service
metadata:name: my-nginxlabels:run: my-nginx
spec:ports:- port: 80protocol: TCPselector:run: my-nginx
上述命令将创建一个 Service,该 Service 会将所有具有标签 run: my-nginx 的 Pod 的 TCP 80 端口暴露到一个抽象的 Service 端口上(targetPort:容器接收流量的端口;port: 可任意取值的抽象的 Service 端口,其他 Pod 通过该端口访问 Service)。
查看你的 Service 资源:
kubectl get svc my-nginxNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s一个 Service 由一组 Pod 提供支撑。这些 Pod 通过 EndpointSlices 暴露出来。 Service Selector 将持续评估,结果被 POST 到使用标签与该 Service 连接的一个 EndpointSlice。 当 Pod 终止后,它会自动从包含该 Pod 的 EndpointSlices 中移除。 新的能够匹配上 Service Selector 的 Pod 将被自动地为该 Service 添加到 EndpointSlice 中。
kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.0.162.149
IPs: 10.0.162.149
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.5:80,10.244.3.4:80
Session Affinity: None
Events: <none>你应该能够从集群中任意节点上使用 curl 命令向 <CLUSTER-IP>:<PORT> 发送请求以访问 Nginx Service。 注意 Service IP 完全是虚拟的。。
kubectl get endpointslices -l kubernetes.io/service-name=my-nginx
NAME ADDRESSTYPE PORTS ENDPOINTS AGE
my-nginx-7vzhx IPv4 80 10.244.2.5,10.244.3.4 21s