ChatBI 学习
参考:从0到1拆解FreeWheel ChatBI:大模型如何重塑视频广告智能数据分析新生态-腾讯云开发者社区-腾讯云
- 智能追问与多轮对话:通过引入 HITL(Human-in-the-Loop 人在回环)机制,面对模糊提问时主动追问澄清意图;支持多轮对话,能够准确理解上下文,持续、连贯地推进数据分析。
- 交互式数据分析:用户经常会问某个指标有没有异常,异常发生的原因(如“为什么 XXX 业务昨天的曝光量下降了?”- Why did the impressions for network XXX decline yesterday?),或者希望下钻到某一个维度(如“是哪个站点导致的问题?” - Which site cause the issue?),又或者仅仅是查询跟某指标变化相关的指标,依托 LLM 的推理能力和外部算法库,快速定位数据,执行统计分析、异常检测、根因排查等任务,并提供优化建议,为决策提供及时有力的数据支持。本文第四章重点介绍数据分析。
2. 引入术语体系与知识库
针对业务术语、行业黑话及关键指标,我们分为两部分处理:
- 高频术语与常用黑话:作为 System Prompt 的一部分,直接提供给 LLM;
- 全量术语、数据指标等复杂知识资产:构建在向量数据库中,通过 RAG 机制动态检索,辅助模型理解更细节的问题。
关键词提取
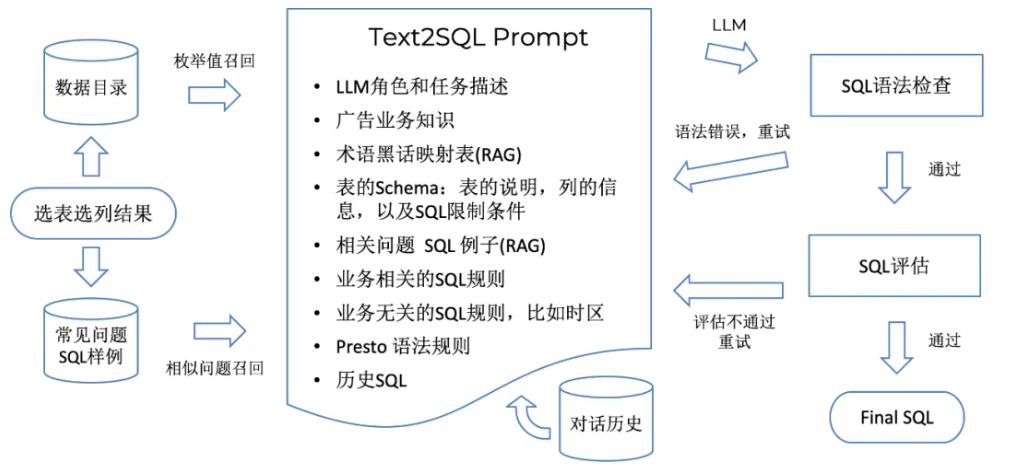
理解了用户意图之后,对业务问题的进一步理解就是能够对问题进行结构化表达,我们把这一步叫做关键词提取。系统会精准识别用户表达中的关键信息,提取包括维度、查询指标、过滤条件、时间区间、时区等关键词。同时,为了解决指标别名或同义问题,我们将上述业务知识嵌入到提示词中,提升 LLM 对业务语义的感知能力。例如,在我们的业务语境中,“Asset” 和 “Video” 表示相同含义。
关键词提取完成后,系统会结合上下文语义对原始问题进行改写,将用户的口语化表达转化为结构清晰、逻辑严谨的数据查询或者分析请求。
分层数据仓库系统包括了维度数据表、明细事实数据(主要是广告日志明细)、通用聚合数据、领域聚合数据、应用聚合数据
三层聚合数据粒度分别从细到粗,定位不同的产品用途,可以支持不同的查询需求。
列表召回和排序、选表选列于列表校验这三步组成了智能选表
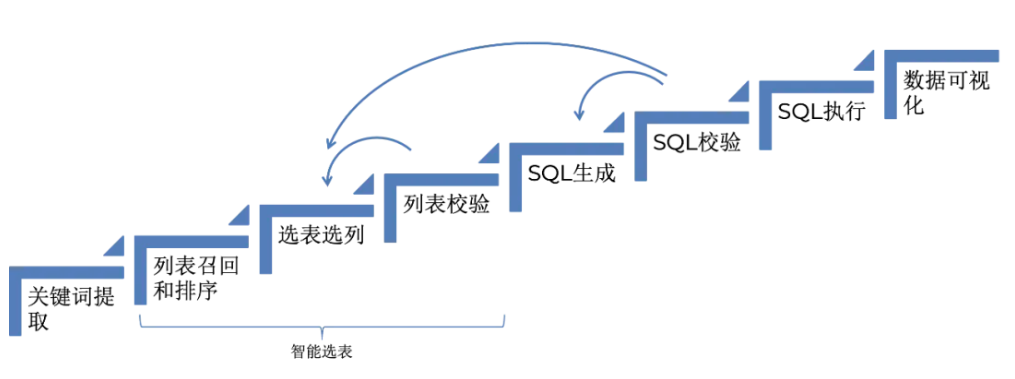
列表校验、SQL 校验失败都会退回到上一步重试,SQL 校验时,如果发现这张表无法解决用户的问题,说明选择的表不合适,重新进行选表。
我们通过建立数据目录和元数据管理系统,对数据仓库进行统一梳理和标注,涵盖以下多个方面:
- 数据目录与数据仓库概述:对数据目录和数据仓库进行高层次描述,阐明其分层架构、数据来源、表的种类以及业务场景等。
- 表的详细说明:清晰阐述每张表的功能,以及其在数据产品中的应用场景,例如某张程序化交易广告销售数据表,可用于生成程序化交易洞察分析、第三方 DSP 竞价仪表盘等数据产品。
- 表的选择逻辑:明确界定表的适用范围,比如某些表仅适用于特定业务场景,如 Marketplace 订单销售表,仅适应于 Marketplace 业务下的供需分析和销售分析;同时说明哪些场景下该表不适用,避免错误使用导致数据分析偏差。
- 字段详情:针对每个字段,明确其类型,判断是维度(用于描述业务实体的特征,如网站、地区等)、指标(可量化的业务衡量标准,如请求量、曝光量)还是错误度量(用于记录广告投放过程中的相关问题,如行业限制、竞争失败等);阐述字段含义,列举可能的取值范围;若为维度字段,指出与之关联的维度表,类似数据库中的外键关系,方便数据关联。
- 衍生指标(Derived Metric):详细解释衍生指标的计算逻辑与业务含义,例如,广告填充率 = 填充广告数 / 视频广告位 。
- 字段唯一性保障:我们仔细梳理不同数据表中的同名或同义字段,明确其语义一致性,针对字段含义的特殊情况,进行详细说明与标注,确保数据解读的准确性与连贯性。
- SQL 限制条件:列出表在 SQL 查询中的限制条件,例如对某些敏感字段的访问限制,或是特定业务逻辑下对数据检索的条件约束,确保数据使用的合规性与准确性。
Text2SQL 可将自然语言直接转为标准 SQL 查询,便于集成,且通过对多表 JOIN、聚合等操作的支持,它能够灵活应对复杂的业务查询需求,但因 SQL 语法与逻辑复杂,基于 LLM 生成的 SQL 很难保证业务逻辑的绝对准确。
Text2DSL 通过预先设计的 DSL(如 LookML,明确规定数据模型、查询维度、指标、时间区间等结构)结构化映射为 SQL 查询,能提升准确性,却面临维护成本高、复杂查询(如多表 JOIN、嵌套聚合)支持不足的问题。
系统能够针对用户的问题自动生成 SQL 并可视化呈现,用户可以对生成的 SQL 进行审查,询问 SQL 表达式的含义,通过多轮对话不断优化,直至精确获取所需数据。
表和列的初步召回
选表的第一步是在大量的表和字段中召回可能相关的表和字段。我们根据提取的维度和指标等关键词,结合元数据信息,通过融合多种检索方式从数据目录中初步筛选相关表和字段。
GraphRAG:我们借鉴 Graph RAG 的思路,但不需要社区摘要的步骤。首先借助 LLM 构建 entity-column 知识图谱,实体包括两类,一类是抽象实体,另一类是列实体,抽象实体包括了业务概念、抽象的维度、指标大类等,人工可以 Review 并修改实体和关系的定义。检索时,一方面通过 embedding 向量检索 entity,再召回链接的列,另一方面检索关系,再传播到 entity 和列。
表级检索:区分事实表和维度表
当用户提出 “上个月程序化交易渠道的收入趋势如何” 的问题时,系统会自动解析 “程序化交易”“收入” 等核心关键词。随后,LLM 会参考元数据中对各数据表的详细描述及选表逻辑,并结合与该问题语义相近的过往示例,从数据库中精准筛选出程序化交易事实表中粗粒度表 programmatic_summary(鉴于问题未涉及更多维度),以及渠道维度表。当用户问题为统计 2025 年 Q1 各销售渠道的收入时,同理则需要选择 demand_portfolio_summary。