C++指针笔试题1
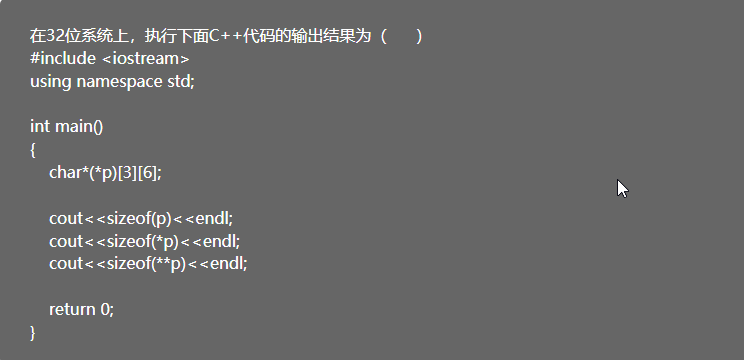
分析 char*(*p)[3][6]; 的类型
p是一个指针,它指向的类型是char*[3][6](一个 3 行 6 列、元素为char*的二维数组)。
计算 sizeof(p)
p 是指针,在 32 位系统中,指针的大小固定为 4 字节,所以 sizeof(p) = 4。
计算 sizeof(*p)
*p 表示 p 指向的对象,即 char*[3][6] 类型的二维数组。
- 这个二维数组有
3行、6列,每个元素是char*(大小为 4 字节)。 - 数组总大小 = 行数 × 列数 × 每个元素的大小,即
3 × 6 × 4 = 72,所以sizeof(*p) = 72。
计算 sizeof(**p)
**p 表示二维数组中第一行的数组(类型为 char*[6],即 1 行 6 列、元素为 char* 的一维数组)。
- 该一维数组有
6个元素,每个元素是char*(大小为 4 字节)。 - 数组总大小 = 列数 × 每个元素的大小,即
6 × 4 = 24,所以sizeof(**p) = 24。
为什么会有 *p 和 **p?
指针的解引用(*)本质是 “获取指针指向的对象”,而对象的类型决定了 “是否可以继续解引用”:
p的类型:char*(*)[3][6](指向二维数组的指针)p存储的是 “整个二维数组的起始地址”,解引用*p得到的是p指向的二维数组本身(类型为char*[3][6])。注意:这个二维数组虽然是 “实体”,但在多数语境下会隐式退化—— 作为 “由多个行数组组成的集合”,它会退化为指向 “第一行数组” 的指针(类似一维数组名退化为指向首元素的指针)。其实,退化是常态,** 只要*p离开 “不会退化的特殊语境”(如sizeof(*p)、&*p),就会自动退化 **。*p的类型:char*[3][6](二维数组)→ 退化后为char*(*)[6](指向行数组的指针)当*p退化为 “指向第一行数组的指针” 时,对其再次解引用(**p),得到的就是 这个指针指向的对象—— 即二维数组的第一行数组(类型为char*[6])。
最终输出
代码会依次输出:
plaintext
4
72
24备注:
1、
#include <stdio.h>int main() {int arr[5] = {1,2,3,4,5};int (*p)[5] = &arr; // 指向数组的指针(数组指针)int* q = arr; // 指向int的指针(普通指针)// 1. 指针本身的sizeof:结果相同printf("sizeof(p) = %zu\n", sizeof(p)); // 32位系统输出4,64位输出8printf("sizeof(q) = %zu\n", sizeof(q)); // 结果和上面完全一致// 2. 指针指向对象的sizeof:结果不同(类型差异的体现)printf("sizeof(*p) = %zu\n", sizeof(*p)); // *p是整个数组,大小=5*4=20printf("sizeof(*q) = %zu\n", sizeof(*q)); // *q是单个int,大小=4return 0;
}2、
1. 数组名 arr 不是指针,而是 “数组类型的标识符”
数组名代表的是整个数组的实体,而非指针变量。例如:
int arr[5]; // arr 是 "int[5]" 类型的数组,不是指针
- 指针是独立的变量,存储内存地址,可被赋值修改(如
int* p; p = &x;); - 数组名是 “常量标识符”,不能被赋值(如
arr = &x;会报错),它与数组在内存中的存储绑定,本身不占用额外内存(指针变量则占用内存)。
2. 数组名可以用 sizeof,因为 sizeof 识别数组类型
sizeof(arr) 计算的是整个数组的总字节数,这是因为 sizeof 是编译期运算符,能直接识别数组的完整类型(如 int[5]):
int arr[5];
printf("%zu", sizeof(arr)); // 输出 20(5个int,每个4字节)
- 若
arr是指针,sizeof(arr)会输出指针大小(如 8 字节),但实际输出的是数组总大小,证明arr不是指针。 - 只有数组名作为
sizeof的操作数时,才不会退化(保持数组类型),这是sizeof对数组的特殊处理。
3. 数组名 “退化” 为指针的原因:简化数组访问
在多数语境下(除 sizeof(arr)、&arr 等少数情况),数组名会隐式转换为指向首元素的指针(类型为 元素类型*),这是 C 语言设计的便利性:
int arr[5];
int* p = arr; // 等价于 p = &arr[0],arr 退化为 int* 类型
退化的目的是方便通过指针访问数组元素(如 arr[i] 等价于 *(arr + i)),避免每次都手动写 &arr[0]。
常见的退化场景:
- 数组名作为函数参数(如
void func(int arr[])中,arr实际是int*指针); - 数组名参与指针运算(如
arr + 1指向arr[1]); - 数组名赋值给同类型指针变量(如上面的
p = arr)。
4. 数组名arr只占编译时内存不占运行时内存。
- 若问 “编译阶段
arr是否占内存”:是,它作为编译器符号表的一条记录,占用编译器进程的内存(但这是编译器的工作内存,与你的程序无关)。 - 若问 “程序运行时
arr是否占内存”:否,此时只有数组的实体数据在内存中,arr这个名字已被编译器转换为具体地址,不再以独立形式存在。
5.若 q 是 int* 类型,&q 的类型就固定为 int**,不能用 int* 类型的 r 接收,否则编译器会报错(类型不匹配)。
6.int *p[2][5] 和 int (*p)[2][5] —— 完全不一样
这两个声明的本质、p 的类型、用途都截然不同,核心区别是 p 是 “数组” 还是 “指针”。
1. int *p[2][5] —— 二维数组(元素为 int*)
- 结合逻辑:
[]的优先级高于*,所以p先与[2][5]结合,声明为 “2 行 5 列的二维数组”;数组的每个元素是int*(指向int的指针)。 - 类型:
p是int*[2][5]类型(二维数组,元素为一级指针)。 - 内存占用:数组大小 = 行数 × 列数 × 每个元素大小(如 64 位系统中,
int*占 8 字节,总大小 = 2×5×8 = 80 字节)。 - 示例:可存储 10 个
int*指针,每个指针指向一个int变量或数组。
[] 先绑定 p 确定其为数组,* 再限定数组元素的指针属性,int 最后限定指针指向的类型。
2. int (*p)[2][5] —— 三维数组指针(指向 int[2][5] 类型的二维数组)
- 结合逻辑:括号
()强制p先与*结合,声明为 “指针”;指针指向的类型是int[2][5](2 行 5 列的二维数组)。 - 类型:
p是int (*)[2][5]类型(指向二维数组的指针,属于 “数组指针”)。 - 内存占用:指针本身的大小(与系统位数相关,64 位系统占 8 字节,32 位占 4 字节),与指向的数组大小无关。
- 示例:需指向一个已存在的
int[2][5]二维数组(如int arr[2][5]; p = &arr;)。
7.int *p、int (*p) 和 int* p 这三种写法中,int *p 和 int* p 完全等价,而 int (*p) 与前两者在 “语法效果上一致(均为一级指针),但括号冗余且不常用”—— 核心区别仅在于 * 与 int/p 的排版方式,以及是否存在冗余括号,本质都是 “声明一个指向 int 类型的一级指针 p”。
1. 先明确:C/C++ 中 * 是 “跟随变量” 的,而非 “跟随类型”
首先要纠正一个常见误区:int* 不是一个 “整体类型”(虽然我们常口头说 “int* 类型的指针”),在语法层面,* 是 “绑定到变量名” 的运算符。比如 int* p1, p2; 实际声明的是:p1 是 int* 指针,p2 是普通 int 变量 —— 因为 * 只绑定到 p1,没绑定到 p2。这也是为什么 int *p(* 靠近 p)和 int* p(* 靠近 int)在语法上完全等价:无论 * 排版在哪里,它最终都是与变量 p 结合,声明 p 是指针。
2. 逐一分析三种写法
(1)int *p 和 int* p —— 完全等价
- 核心逻辑:两者都是声明 “变量
p是指向int类型的一级指针”,唯一区别是*的排版位置(靠近p还是靠近int)。 - 编译效果:编译器会将两者解析为完全相同的代码,无任何区别。
- 示例:
int a = 10; int *p1 = &a; // 正确,p1 是 int* 指针 int* p2 = &a; // 正确,p2 也是 int* 指针,与 p1 完全等价 printf("%d %d", *p1, *p2); // 均输出 10 - 开发习惯:两种写法都很常见,
int *p更强调 “p是指针”,int* p更强调 “p的类型是int*”,但本质无差异。
(2)int (*p) —— 语法有效,但括号冗余
- 核心逻辑:括号
()强制p先与*结合,但由于没有其他高优先级运算符(如数组下标[]、函数()),括号没有实际作用,最终效果与int *p一致。 - 编译效果:编译器会忽略冗余的括号,将其解析为 “
p是int*指针”,与前两种写法无区别。 - 示例:
int a = 20; int (*p3) = &a; // 正确,p3 是 int* 指针,括号冗余 printf("%d", *p3); // 输出 20 - 注意:实际开发中很少这么写,因为括号不仅没有必要,还会略微降低代码可读性(容易让人误以为有特殊逻辑)。
8.*p 的退化不是 “在取 **p 时才发生”,而是在多数语境下(包括作为 * 运算符的操作数时)会自动发生,**p 只是利用了这种退化的结果。
具体拆解:*p 的退化时机
当 p 是 char*(*)[3][6] 类型(指向二维数组的指针)时:
*p得到的是char*[3][6]类型的二维数组(p指向的实体)。此时,只要*p出现在 “需要指针的语境” 中(如赋值给指针变量、参与指针运算、作为*的操作数等),就会立即退化为char*(*)[6]类型(指向第一行数组的指针)。当执行
**p时:- 第一步:
*p先退化(因为它作为*运算符的操作数,处于 “需要指针的语境”),变成指向第一行的指针(char*(*)[6]类型); - 第二步:对这个 “指向第一行的指针” 解引用(
*),得到第一行数组(char*[6]类型)。
- 第一步:
关键:退化是 “语境触发”,而非 “显式取 * 时才触发”
*p 的退化不是 “等待 **p 时才发生”,而是:** 只要 *p 离开 “不会退化的特殊语境”(如 sizeof(*p)、&*p),就会自动退化 **。例如,即使不写 **p,单独使用 *p 时也会退化:
char* arr[3][6];
char*(*p)[3][6] = &arr; // p 指向二维数组char*(*q)[6] = *p; // 正确:*p 退化后是 char*(*)[6] 类型,可直接赋值给 q
这里 *p 并没有参与 **p 运算,但依然发生了退化(否则无法赋值给 q)。
总结
退化的触发时机很普遍:*p 的退化不是 “在取 **p 时才发生”,而是在大多数语境下(包括作为 * 运算符的操作数)会自动发生,**p 只是对退化后的指针再次解引用的结果。简单说:退化是 *p 自身在多数语境下的特性,**p 是利用了这个特性进行的二次操作。