CustomKD论文阅读

2025.3
1.摘要
background
大型视觉基础模型(LVFMs)如DINOv2和CLIP在各种任务上表现出色,但由于其巨大的计算成本和参数量,很难部署在资源受限的边缘设备(如手机)上。边缘模型(如MobileNetV3)计算高效,但性能有限。知识蒸馏(Knowledge Distillation, KD)是一种很有前景的技术,可以将大型教师模型(LVFMs)的知识迁移到小型的学生模型(边缘模型)上,以在不增加推理成本的情况下提升其性能。LVFMs(通常是ViT架构)和边缘模型(通常是CNN架构)之间存在巨大的模型容量和架构差异。这种“模型差异”(model discrepancy)导致现有的知识蒸馏方法效果不佳。论文观察到一个关键现象:当教师模型从一个较小的版本(如ViT-S)升级到一个更大的版本(如ViT-L)时,教师自身的性能提升很明显,但通过蒸馏带给学生模型的性能增益却非常有限。
innovation
核心思想: 为了解决模型差异问题,论文提出了一种名为CustomKD的新型知识蒸馏方法。其核心洞见是,不应强迫学生去模仿难以理解的教师特征,而应该主动地将教师的特征“定制”成学生更容易理解的形式。
创新方法: CustomKD通过一个两阶段交替进行的训练过程来实现这一目标:
1.特征定制阶段 (Feature Customization): 此阶段的目标是让教师说“学生的语言”。它借用学生模型的头部“分类器”(classifier head),来对教师模型的特征进行微调。具体来说,它在固定的教师主干网络之上,训练一个投影层,使得投影后的特征能够被学生的分类器很好地识别。这样就生成了一套为学生量身定制的、任务相关的“学生友好型”特征。
2.知识蒸馏阶段 (Knowledge Distillation): 在这个阶段,学生模型被要求同时模仿两种来自教师的知识:一种是教师模型原始的、任务通用的特征;另一种是经过第一阶段生成的、定制化的、任务相关的特征。
2. 方法 Method
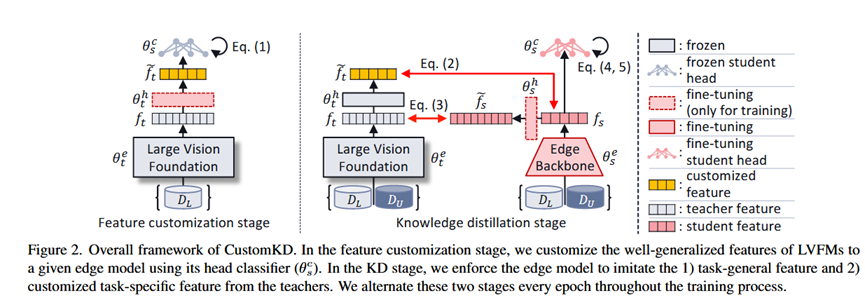
CustomKD的流程是“特征定制”和“知识蒸馏”两个阶段在每个训练周期(epoch)中交替进行。
整体流程:
输入: 一个预训练好的大型教师模型(LVFM),一个预训练好的小型学生模型(边缘模型),少量有标签数据 DL,大量无标签数据 Du。
输出: 一个性能得到显著提升的学生模型。
阶段一: 特征定制 (Feature Customization Stage)
目标: 将教师的原始特征 ft 转换成学生更容易理解的定制化特征 f̃t。
具体做法:
1.冻结教师模型的主干网络 θt^e。
2.“借用”学生模型的头部 θs^h,并将其冻结。
3.在这两者之间插入一个可训练的投影层 θp^h。
4.使用有标签数据 DL 进行训练,目标是让 θs^h(θp^h(ft)) 的分类结果正确。在这个过程中,只更新投影层 θp^h 的参数。
此阶段的输出: 训练好的投影层 θp^h,它可以将任何教师特征 ft 转换为定制特征 f̃t。
阶段二: 知识蒸馏 (Knowledge Distillation Stage)
目标: 更新学生模型(主干 θs^e 和头部 θs^h),让它同时学习两种知识。
具体做法:
1.学生模型 θs 的总损失函数由四部分加权构成:
定制特征模仿损失 (L_f̃t): 让学生的特征 fs 与教师的定制特征 f̃t 在特征空间上尽可能接近(如使用MSE损失)。这部分是学习任务相关的特定知识。
通用特征模仿损失 (L_ft): 让学生的特征 fs 经过一个投影层后,与教师的原始特征 ft 尽可能接近。这部分是学习任务通用的通用知识。
监督损失 (LL): 在有标签数据 DL 上的标准交叉熵损失。
无监督损失 (LU): 在无标签数据 Du 上的熵最小化损失,以利用无标签数据提升模型泛化能力。
2.通过反向传播,同时更新学生模型的主干 θs^e、头部 θs^h 以及用于模仿通用特征的投影层。
此阶段的输出: 更新后的学生模型 θs。
这两个阶段在整个训练过程中反复交替,从而逐步提升学生模型的性能。
3. 实验 Experimental Results
实验数据集:
无监督域适应 (UDA): OfficeHome, DomainNet。
半监督学习 (SSL): CIFAR-100, ImageNet (1% 和 10% 标签子集)。
实验结论:
核心有效性验证: 在UDA和SSL的多个基准测试中,CustomKD均显著优于传统的UDA方法和多种知识蒸馏基线方法,证明了其有效性和先进性。(见Table 1, 2, 3, 4)
动机验证实验: 实验首先验证了论文的动机:随着教师模型从ViT-S增大到ViT-L,传统KD方法带给学生的收益停滞不前,而CustomKD则能持续带来显著的性能提升,成功解决了模型差异问题。(见Figure 1)
跨主干网络扩展性实验: 为了证明CustomKD在面对更大的模型差异时效果更佳,实验比较了仅使用通用特征损失 (L_ft) 和同时使用两种特征损失 (L_ft + L_f̃t) 的效果。结果表明,当教师和学生的模型差异增大时,引入定制化特征损失带来的性能增益也越大。(见Table 5)
学生分类头重要性实验: 实验证明,在特征定制阶段使用“学生的分类头”比使用一个随机初始化的头效果更好。CKA(Centered Kernel Alignment)相似度分析和t-SNE可视化进一步表明,这样做能更有效地对齐师生模型的特征表示空间。(见Table 6, Figure 3)
消融实验: 实验分析了不同损失函数的贡献以及交替训练频率的影响。结果显示,通用知识和定制化知识的学习都至关重要,两者结合效果最好。同时,每轮都进行一次交替(1:1)的训练频率能达到最佳性能。(见Table 7)
4. 总结 Conclusion
当教师(LVFM)与学生(边缘模型)之间存在巨大的模型和架构差异时,传统知识蒸馏方法会失效。CustomKD通过“特征定制”这一创新步骤,让教师的知识变得对学生更“友好”,从而有效解决了这一核心痛点。这是一个简单、有效且无推理成本的方案,能将大型基础模型的强大能力高效地迁移到实际应用的边缘模型中。