使用神经网络预测天气
实现了一个完整的温度预测流程,包括数据预处理、模型定义、训练、保存和加载、预测以及可视化。它使用了一个简单的全连接神经网络,并对特征进行了标准化和独热编码处理。主程序执行时,会训练模型并保存,然后对第一行数据进行预测,展示预测效果
环境的准备
使用conda的方式,首先下载conda,然后在pycharm中配置conda进行调试
数据集的准备
有300多行的数据,在项目工程中
1.导入库
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn import preprocessing
import matplotlib.pyplot as plt
import datetime
import warnings
- 导入了数据处理、神经网络训练、可视化等必要的库
warnings.filterwarnings("ignore")用于忽略警告信息
2. 神经网络模型定义
class TemperaturePredictor(nn.Module):
def __init__(self, input_size, hidden_size=128, output_size=1):
super(TemperaturePredictor, self).__init__()
self.network = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.Sigmoid(),
nn.Linear(hidden_size, output_size)
)
def forward(self, x):
return self.network(x)
- 定义了一个简单的两层神经网络
- 输入层 → Sigmoid激活 → 隐藏层 → 输出层
- 默认隐藏层大小为128个神经元
3. 数据加载和预处理
def load_and_preprocess_data(filepath='data\\temps.csv'):
# 加载数据
features = pd.read_csv(filepath)
# 处理日期数据
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 独热编码
features = pd.get_dummies(features)
feature_list = list(features.columns)
# 分离标签和特征
labels = np.array(features['actual'])
features = features.drop('actual', axis=1)
feature_list.remove('actual')
features = np.array(features)
# 特征标准化
scaler = preprocessing.StandardScaler().fit(features)
features_scaled = scaler.transform(features)
# 返回原始特征 DataFrame 用于绘图
original_features_df = pd.read_csv(filepath)
return features_scaled, labels, feature_list, scaler, dates, original_features_df
- 加载CSV格式的温度数据
- 将年、月、日组合成日期对象
- 对类别特征(星期几)进行独热编码
- 分离目标值(实际温度)和特征
- 对特征进行标准化(均值为0,方差为1)
- 返回处理后的数据和原始数据(用于可视化)
4. 模型训练
def train_model(features, labels, input_size, hidden_size=128, output_size=1,
batch_size=16, learning_rate=0.001, epochs=1000, print_interval=100):
# 定义模型、损失函数和优化器
model = TemperaturePredictor(input_size, hidden_size, output_size)
criterion = nn.MSELoss(reduction='mean')
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练循环
for i in range(epochs):
epoch_loss = []
# MINI-Batch训练
for start in range(0, len(features), batch_size):
# 获取小批量数据
end = min(start + batch_size, len(features))
x_batch = torch.tensor(features[start:end], dtype=torch.float, requires_grad=True)
y_batch = torch.tensor(labels[start:end], dtype=torch.float, requires_grad=True).view(-1, 1)
# 前向传播
predictions = model(x_batch)
loss = criterion(predictions, y_batch)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss.append(loss.item())
# 打印训练进度
if i % print_interval == 0:
avg_loss = np.mean(epoch_loss)
print(f'Epoch [{i}/{epochs}], Loss: {avg_loss:.4f}')
return model
- 使用均方误差损失函数
- 使用Adam优化器
- 采用小批量梯度下降训练
- 定期打印训练损失
5. 模型保存和加载
def save_model(model, scaler, feature_list, model_path='temperature_model.pth',
scaler_path='scaler.pkl', feature_list_path='feature_list.pkl'):
# 保存模型参数
torch.save(model.state_dict(), model_path)
# 保存标准化器和特征列表
import pickle
with open(scaler_path, 'wb') as f:
pickle.dump(scaler, f)
with open(feature_list_path, 'wb') as f:
pickle.dump(feature_list, f)
def load_model(model_path='temperature_model.pth', scaler_path='scaler.pkl',
feature_list_path='feature_list.pkl', input_size=None,
hidden_size=128, output_size=1):
# 加载标准化器和特征列表
import pickle
with open(scaler_path, 'rb') as f:
scaler = pickle.load(f)
with open(feature_list_path, 'rb') as f:
feature_list = pickle.load(f)
# 加载模型
model = TemperaturePredictor(input_size, hidden_size, output_size)
model.load_state_dict(torch.load(model_path))
model.eval() # 设置为评估模式
return model, scaler, feature_list
- 保存模型参数、标准化器和特征列表
- 加载时恢复整个预测流程所需的所有组件
6. 预测函数
def predict_single_sample(model, scaler, feature_list, input_dict):
# 构造特征向量
try:
input_features = np.array([input_dict[feature] for feature in feature_list])
except KeyError as e:
raise KeyError(f"输入字典缺少特征: {e}")
# 标准化
input_features_scaled = scaler.transform(input_features.reshape(1, -1))
# 转换为Tensor
input_tensor = torch.tensor(input_features_scaled, dtype=torch.float)
# 预测
with torch.no_grad():
prediction = model(input_tensor)
return prediction.item()
7. 可视化功能
def plot_features(dates, features_df):
# 绘制4个关键特征随时间变化的图表
plt.style.use('fivethirtyeight')
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
# 实际温度
ax1.plot(dates, features_df['actual'])
ax1.set_title('Max Temp')
# 前一天温度
ax2.plot(dates, features_df['temp_1'])
ax2.set_title('Previous Max Temp')
# 前两天温度
ax3.plot(dates, features_df['temp_2'])
ax3.set_title('Two Days Prior Max Temp')
# 朋友预测的温度
ax4.plot(dates, features_df['friend'])
ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
plt.show()
8. 主执行流程
if __name__ == '__main__':
# 参数设置
DATA_FILE = 'data\\temps.csv'
MODEL_PATH = 'temperature_model.pth'
SCALER_PATH = 'scaler.pkl'
FEATURE_LIST_PATH = 'feature_list.pkl'
HIDDEN_SIZE = 128
OUTPUT_SIZE = 1
BATCH_SIZE = 16
LEARNING_RATE = 0.001
EPOCHS = 1000
PRINT_INTERVAL = 100
# 加载和预处理数据
features_scaled, labels, feature_list, scaler, dates, original_features_df = load_and_preprocess_data(DATA_FILE)
input_size = features_scaled.shape[1]
# 绘制特征图表
plot_features(dates, original_features_df)
# 训练模型
model = train_model(features_scaled, labels, input_size, HIDDEN_SIZE, OUTPUT_SIZE,
BATCH_SIZE, LEARNING_RATE, EPOCHS, PRINT_INTERVAL)
# 保存模型
save_model(model, scaler, feature_list, MODEL_PATH, SCALER_PATH, FEATURE_LIST_PATH)
# 示例预测
original_features_df = pd.read_csv(DATA_FILE)
original_features_df = pd.get_dummies(original_features_df)
example_row = original_features_df.iloc[0].drop('actual').to_dict()
predicted_temp = predict_single_sample(model, scaler, feature_list, example_row)
actual_temp = original_features_df.iloc[0]['actual']
print(f"真实温度: {actual_temp}")
print(f"预测温度: {predicted_temp:.2f}")
- 设置数据路径和模型参数
- 加载和预处理数据
- 可视化特征趋势
- 训练模型
- 保存模型
- 使用第一行数据进行预测演示
关键特点
- 端到端解决方案:从数据加载到预测的完整流程
- 可复现性:保存标准化器和特征列表确保预测一致性
- 错误处理:包含异常捕获和详细日志
- 模块化设计:各功能解耦,便于扩展和维护
- 可视化支持:直观展示特征趋势
- 小批量训练:提高训练效率和内存利用率
将系统发布为Web应用系统。由用户输入
增加flash的框架。用户访问
127.0.0.1:5000
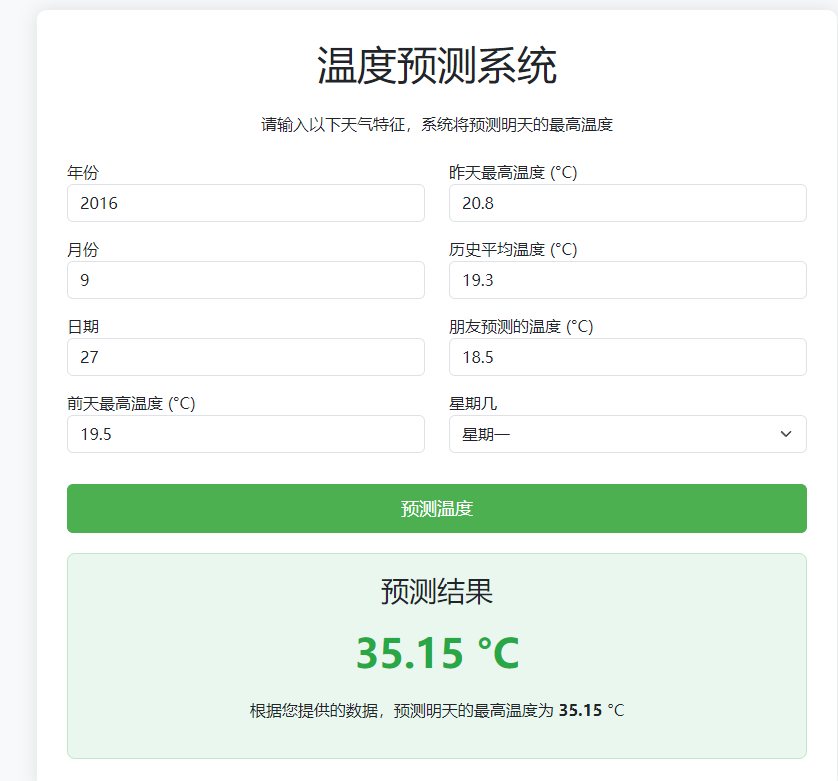
源码地址
https://gitee.com/stevenworkshop_admin/temperaturepredictor.git
Python语言在使用的体会
函数可以有多个返回值