【Day 65】Linux-ELK
一、ELK简单介绍
ELK Stack(Elasticsearch、Logstash、Kibana)是一套开源的日志管理解决方案。
主要作用:
- 集中收集分散在各服务器上的日志数据
- 对日志进行清洗、过滤和结构化处理
- 提供高效的日志存储和检索能力
- 通过可视化界面实现日志分析与监控告警→可以建图表统计分析
- 支持大规模分布式部署,满足高可用需求
核心组件:
- Beat 系列采集工具
- Elasticsearch,简称ES
- Logstash
- Kibana
(一)Beat 系列采集工具
Beat 是部署在业务服务器上的轻量级数据采集代理,负责将日志数据发送到 Logstash 或 Elasticsearch。常用组件包括:
- Topbeat // 系统级别的日志
- Metricbeat // 替代传统的 Topbeat,用于收集系统和服务的性能指标
- Filebeat // 用于搜集应用级别日志文件,轻量高效且资源占用低
- // 应用日志(如 Nginx 的
access.log、Java 应用的catalina.out、微服务的service.log) - Winlogbeat // 专门用于收集 Windows 操作系统的事件日志
- Packetbeat // 用于捕获网络流量数据,分析网络性能和行为
- Heartbeat // 用于监控服务可用性和响应时间
(二)Elasticsearch,简称ES
分布式搜索引擎,核心功能:数据存储、检索
-
数据存储:提供高可用、高扩展的日志数据存储
-
检索分析:支持全文检索和复杂聚合分析
-
高可用保障:基于分片和副本机制保证数据安全
-
集群扩展:通过集群实现负载均衡和水平扩展
1、ES 存储格式
ES 存储的基本单位是文档(Document),本质是一个 JSON 格式的键值对集合。
{"timestamp": "2023-10-01 12:00:00","ip": "192.168.1.1","request": "/api/login","status": 200,"response_time": 150
}
这种结构的优势:
- 天然适配日志 / 半结构化数据:日志中的 “时间、IP、请求路径” 等字段可直接映射为 JSON 字段,无需预定义严格表结构(支持动态字段扩展);
- 便于索引构建:ES 会自动对 JSON 中的每个字段进行分析(如分词、类型识别)并建立索引,为后续检索提速。
2、ES 分布式存储
ES 不会将数据 “堆” 在单个节点,而是通过 “索引拆分 + 分片分布” 实现分布式存储:
① 索引(Index):数据的逻辑容器
-
ES 的索引是逻辑概念(不直接存储数据),不直接存储数据。索引更像一个 “容器的标签”,用于定义一组文档的共同属性(如字段类型、分词器、分片策略等),但实际数据存储在索引所管理的分片中。
-
每个索引在创建时需要指定主分片数量(不可修改)和副本分片数量(可动态调整)
-
例如设置 3 个主分片,意味着该索引的数据会被拆分为 3 份,分别存储在 3 个分片中。
- 实际数据被拆分为 3 份,分别存储在
P0、P1、P2三个主分片中; - 副本分片
R0、R1、R2是主分片的备份,与主分片数据一致,但由索引统一管理其分布(确保主副分片不在同一节点)。
-
-
索引的核心作用是:
- 定义分片的分配规则(如数据如何路由到不同主分片);
- 维护分片的元数据(如分片属于哪个索引、当前状态是否可用);
- 提供统一的接口(如
PUT /web-logs/_doc/1),让用户无需关心数据具体存在哪个分片。
② 分片(Shard):数据的物理载体
-
主分片(Primary Shard):数据写入的 “第一落点”,负责承载索引的一部分数据。
-
// 数据路由规则:文档写入时,ES 通过
hash(文档ID) % 主分片数量计算该文档属于哪个主分片,确保数据均匀分布; -
副本分片(Replica Shard):主分片的 “备份”,与主分片数据完全一致,但:
-
不直接处理写入请求(数据由主分片同步而来);
-
可处理读取请求(分担主分片的查询压力);
-
主分片故障时可升级为新的主分片(保障高可用)。
-
③ 分片的 “分布式部署” 原则
-
主分片与副本分片不会存储在同一节点(避免单节点故障导致数据丢失);
-
分片会均匀分布在集群的所有数据节点(Data Node)上,例如 3 个主分片 + 3 个副本分片,会分散在 3 个节点上,每个节点承载 2 个分片(1 主 1 副)。
-
主分片负责 “写入数据”,副本分片负责 “备份数据 + 响应读取请求”。
3、ES 写入数据数据流程
① 写入主分片:
-
客户端请求先路由到目标主分片所在的节点;
-
数据先写入内存缓冲区(In-Memory Buffer),同时记录到事务日志(Translog)—— 防止内存数据丢失;
② 刷新(Refresh)生成可检索数据:
-
每隔 1 秒(默认),内存缓冲区的数据会被 “刷新” 到文件系统缓存(FileSystem Cache),生成一个不可变的段(Segment);
-
此时数据可被检索(但尚未写入磁盘);
③ 落盘(Flush)确保数据安全:
-
当事务日志达到一定大小或间隔一定时间,触发 “Flush” 操作:
-
将文件系统缓存中的段写入磁盘(永久保存);
-
清空内存缓冲区和事务日志;
-
-
即使节点宕机,已写入磁盘的段数据也不会丢失。
④ 副本同步:
-
主分片完成写入后,会异步将数据同步到所有副本分片(副本分片重复上述写入流程);
-
可通过
wait_for_active_shards配置控制 “写入成功” 的确认条件(如至少 1 个副本同步成功才返回成功)。
ES 通过 “主从副本” 机制确保节点故障时数据安全、服务正常。
为每个 “主分片” 创建多个 “副本分片(Replica Shard)”,主分片负责 “写入数据”,副本分片负责 “备份数据 + 响应读取请求”,当主分片所在节点故障时,副本分片自动升级为主分片,避免数据丢失和服务中断。
4、ES面向检索的设计
-
检索:从海量日志中快速匹配目标数据(如 “5 分钟前某 IP 的错误日志”);
-
分析:基于检索结果做统计计算(如 “今日各响应码的日志数量占比”“Top 10 访问量的页面”)。
(1)全文检索:倒排索引(Inverted Index)驱动
传统日志查询是 “逐行扫描文本”(如grep命令),而 ES 不直接 “扫日志”,而是先给日志的 “关键字段”(比如 request 路径、IP、状态码) 建一个 “目录”—— 这就是 倒排索引。
例:
2024-05-20 10:00:01 192.168.1.1 GET /login 200
2024-05-20 10:00:02 192.168.1.2 GET /home 200
2024-05-20 10:00:03 192.168.1.3 GET /login 200① 拆分 “字段值” 与 “日志位置”
ES 会先把每条日志的 request 字段值(/login、/home、/login)拆出来,再关联每条日志的 “唯一位置”(可以理解为日志的 “身份证号”,比如文档 ID):
- 日志 1(ID:1)的 request 是
/login→ 关联关系:/login → ID:1 - 日志 2(ID:2)的 request 是
/home→ 关联关系:/home → ID:2 - 日志 3(ID:3)的 request 是
/login→ 关联关系:/login → ID:3
② 整理成 “倒排索引表”
ES 会把相同的字段值合并,形成一张 “字段值→所有关联日志位置” 的表。
| 字段值(request) | 关联的日志位置(文档 ID) |
|---|---|
| /login | 1、3 |
| /home | 2 |
③ 查询时:直接查 “目录”,跳过 “逐行扫描”
当在 ES 中查询 “包含 /login 的日志” 时,流程完全变了:
- ES 先去查
request字段的倒排索引表,直接找到/login对应的日志位置是 “1、3”; - 根据 “1、3” 这两个位置,直接从存储中取出这两条日志;
- 立刻返回结果,全程不用碰其他无关的日志(比如 ID:2 的
/home日志)。
-
当查询 “包含
/login的日志” 时,ES 直接通过倒排索引定位到目标日志,无需扫描所有数据,毫秒级响应(即使百万级日志)。
(2)复杂聚合分析:聚合查询(Aggregation)
支持多维度统计分析,无需导出数据到第三方工具,直接在 ES 中完成计算:
-
指标聚合:统计日志总数、平均响应时间、响应码为 500 的错误日志数;
-
桶聚合:按字段分组统计(如按 “小时” 分组统计每小时访问量、按 “clientip” 分组统计 Top 10 访问 IP);
-
管道聚合:基于聚合结果再计算(如先统计每小时访问量,再计算全天访问量峰值)。
-
// 适配 ELK 流程:Kibana 的 “Discover”“Visualize” 功能均依赖 ES 的检索分析能力,所有图表数据直接来自 ES 聚合查询。
5、ES水平拓展
动态扩容支持:随着业务增长,当日志量增长(如从 100GB 增至 1TB)时,可通过 “水平扩展(增加节点)+ 调整分片分配” 扩展存储能力,ES 会自动将现有分片均衡迁移到新节点,无需中断服务。
原理:ES 集群会自动将分片(主分片 + 副本分片)均衡分配到所有节点,新增节点后,主节点会重新分配现有分片到新节点,实现 “存储容量” 和 “处理性能” 的线性提升(即增加 1 个节点,存储和性能约提升 1 倍)。
技术实现:
-
分片自动均衡:主节点会监控各节点的 “分片数量”“磁盘使用率”“CPU 负载”,若某节点分片过多,自动将部分分片迁移到负载较低的节点(如节点 A 有 6 个分片,节点 B 有 2 个分片,主节点会将节点 A 的 2 个分片迁移到节点 B);
-
无感知扩容:新增节点只需配置 “集群发现地址(如
discovery.seed_hosts: ["es-master:9300"])”,加入集群后自动参与分片存储和请求处理,无需重启现有节点; -
负载均衡:客户端(如 Logstash、Kibana)访问 ES 时,会自动连接任意节点,该节点会将请求路由到 “分片所在节点”(如查询某分片的数据,路由到该分片的主 / 副本节点),实现请求负载分散。
实际价值:
-
成本可控:无需购买 “高性能服务器”,通过增加普通服务器即可扩容,降低硬件成本;
-
弹性适配:日志量峰值时临时增加节点,峰值过后下线节点,灵活应对业务波动;
-
长期支撑:从 “3 节点小集群” 扩展到 “10 + 节点大集群”,无需重构架构,满足业务长期增长需求。
(三)Logstash
日志处理管道工具,主要功能:日志过滤
- 数据接收:接收来自 Beat 或其他来源的日志数据
- 数据处理:对日志进行过滤、转换、解析等处理(如格式转换、字段提取)
- 插件扩展:支持丰富的插件生态,可扩展处理能力
- 数据输出:将处理后的结构化数据输出到 Elasticsearch 等存储目标
// 连接 “非结构化 / 半结构化日志” 与 “结构化存储(如 Elasticsearch)”,通过 “接收 - 处理 - 输出” 的管道化流程,解决日志数据 “格式乱、质量低、难分析” 的问题。
1、 数据接收:
Logstash 作为日志处理管道的 “输入端”,需兼容不同来源、不同格式的日志(如业务服务器的文件日志、消息队列的实时日志、数据库的增量日志等),核心解决 “多源日志集中接入” 的问题。
通过统一的接收机制,将来自 Beat 代理、本地文件、消息队列、API 等多渠道的日志,汇聚到同一处理管道,避免为每种数据源单独开发接入逻辑。
Logstash 的接收能力完全依赖 “输入插件”,每种数据源对应一款插件,常用场景包括:
(1)对接 Beat 系列(ELK 主流场景)
通过 beats 输入插件接收来自 Filebeat、Metricbeat 等代理的日志,是 ELK 中 “业务日志采集” 的标准方案:
-
技术细节:默认监听 5044 端口(可配置),Beat 代理通过 TCP 协议将日志推送到 Logstash;支持 “批量接收” 和 “断点续传”,避免网络波动导致的日志丢失;
-
场景示例:Web 服务器的 Filebeat 采集 Apache 访问日志后,通过
192.168.140.10:5044推送到 Logstash,实现 “分布式日志集中接入”。
(2)读取本地 / 远程文件
通过 file 输入插件直接读取服务器本地日志文件(如 /var/log/messages),或通过 ssh 插件读取远程服务器文件:
-
技术细节:基于 “文件监控机制(如 inotify)” 实时检测文件新增内容,支持按 “行” 读取文本日志,自动记录读取位置(避免重复读取);
-
场景示例:直接读取 ES 集群节点的 /app/elk/elasticsearch-7.6.2/logs/es-cluster.log,监控 ES 自身运行日志。
(3)对接消息队列(高并发场景)
通过 kafka/rabbitmq 输入插件从消息队列读取日志,适配 “高并发、高吞吐” 的业务场景(如电商秒杀日志):
-
技术细节:支持消费指定 Topic/Queue,配置消费者组(Consumer Group)实现负载均衡,避免单 Logstash 节点压力过大;
-
场景价值:当日志峰值达到 “每秒 10 万条” 时,先将日志写入 Kafka 缓冲,Logstash 按能力消费,避免 “日志积压” 或 “Logstash 宕机”。
(4)其他常见输入源
-
jdbc 插件:从 MySQL、PostgreSQL 等数据库读取增量数据(如业务订单表的新增记录)
-
http 插件:接收通过 API 推送的日志(如业务系统通过 POST 请求提交的操作日志)
-
syslog 插件:直接接收网络设备(路由器、交换机)发送的 Syslog 日志。
2、数据处理:
Logstash 最核心的价值在于 “数据处理”—— 将原始的 “非结构化文本日志”(如 192.168.1.100 - - [10/Oct/2024:14:30:00 +0800] "GET /login HTTP/1.1" 200 1234)转换为 “结构化 JSON 数据”,方便后续 Elasticsearch 检索和 Kibana 分析。
通过 “过滤插件(Filter Plugins)” 组成的处理链,完成 “解析字段→清洗数据→丰富信息→转换格式” 四大动作,最终输出 “字段清晰、格式统一、质量可靠” 的结构化日志。
常用过滤插件与典型处理场景:
(1)解析非结构化日志:grok 插件(最核心)
原始日志多为 “无固定分隔符的文本”,grok 插件通过 “模式匹配” 将文本拆分为明确字段,是 Logstash 处理日志的 “基石”:
-
技术原理:预定义大量日志模式(如
%{IP:clientip}匹配 IP 地址,%{HTTPDATE:timestamp}匹配 HTTP 日志时间),支持自定义模式组合; -
场景示例:解析 Apache 访问日志(原始文本:
192.168.1.100 - admin [10/Oct/2024:14:30:00 +0800] "GET /login HTTP/1.1" 200 1234):filter {grok {match => { "message" => "%{IP:clientip} %{USER:auth_user} %{USER:remote_user} \[%{HTTPDATE:request_time}\] \"%{WORD:method} %{URIPATH:request_path} %{URIPROTO:protocol}\" %{NUMBER:response_code:int} %{NUMBER:response_size:int}" }} }解析后输出结构化 JSON:
{"clientip": "192.168.1.100","auth_user": "-","remote_user": "admin","request_time": "10/Oct/2024:14:30:00 +0800","method": "GET","request_path": "/login","protocol": "HTTP/1.1","response_code": 200,"response_size": 1234 }
(2)时间格式统一:date 插件
原始日志的时间格式可能不统一(如 Apache 日志的 10/Oct/2024:14:30:00 +0800、Nginx 日志的 2024-10-10T14:30:00+08:00),date 插件将时间字段转换为 ES 支持的 @timestamp 格式(ISO8601),确保时间筛选和排序正确:
-
配置示例:
filter {date {match => ["request_time", "dd/MMM/yyyy:HH:mm:ss Z"] # 匹配原始时间格式target => "@timestamp" # 转换后存入 @timestamp 字段(ES 默认时间字段)} }
(3)数据清洗:mutate/drop 插件
-
丢弃无用日志:用
drop插件过滤无效日志(如响应码为 200 的健康检查日志,无需存储):filter {if [response_code] == 200 and [request_path] == "/health" {drop {} # 丢弃健康检查日志,减少 ES 存储压力} } -
字段调整:用
mutate插件添加、删除、重命名字段,或转换数据类型(如将response_code从字符串转为整数,方便后续统计):filter {mutate {add_field => { "service" => "web-server" } # 新增字段标识服务类型rename => { "response_code" => "http_status" } # 重命名字段convert => { "http_status" => "integer" } # 转换为整数类型} }
(4)数据丰富:geoip/useragent 插件
为日志补充额外有价值的信息,提升分析维度:
-
geoip插件:根据clientip解析地理位置(国家、城市、经纬度),支持后续 Kibana 地图可视化(如 “各地区访问量分布”); -
useragent插件:解析用户请求的User-Agent字段,提取浏览器类型(Chrome/Firefox)、操作系统(Windows/macOS)、设备类型(手机 / PC)。
3、插件扩展:
Logstash 本身是轻量级框架,其 “多源接入”“复杂处理”“多端输出” 的能力完全依赖插件生态,核心解决 “场景适配灵活性” 的问题 —— 无论用户需要对接新的数据源、新增处理逻辑,还是输出到新的存储目标,都无需修改 Logstash 核心代码,只需安装对应插件。
采用 “插件化架构”,将 “输入、过滤、输出” 的每一个功能点都设计为独立插件,官方维护 + 社区贡献的插件库覆盖 99% 以上的日志处理场景,同时支持自定义开发插件(基于 Ruby 语言)。
插件分类与使用方式:
(1)插件分类(三大核心类型)
| 插件类型 | 核心作用 | 常用插件示例 |
|---|---|---|
| 输入插件(Input) | 接入日志来源 |
|
| 过滤插件(Filter) | 处理日志数据 |
|
| 输出插件(Output) | 输出处理后的数据 |
|
(2)插件使用流程
-
查看已安装插件:
bin/logstash-plugin list; -
安装官方插件:
bin/logstash-plugin install logstash-filter-geoip(安装 geoip 过滤插件); -
安装社区插件:从 Elastic 插件市场 下载,通过
bin/logstash-plugin install /path/to/plugin.zip安装; -
自定义插件:基于 Ruby 开发,遵循 Logstash 插件规范(如输入插件需继承
LogStash::Inputs::Base类),适合企业私有场景(如对接内部自研系统)。
4、数据输出:
Logstash 作为 “处理中枢”,最终需将结构化后的日志输出到目标系统(如 Elasticsearch 存储、文件归档、消息队列转发),核心解决 “处理后数据的落地与流转” 问题,完成日志处理的闭环。
通过 “输出插件(Output Plugins)” 将同一批处理后的日志,灵活输出到一个或多个目标(支持 “多输出”,如同时输出到 ES 用于分析、输出到文件用于归档),适配不同的业务需求(实时分析、长期归档、二次转发)。
主流输出场景与配置
(1)输出到 Elasticsearch(ELK 核心场景)
将结构化日志写入 ES,是 ELK 中 “日志存储与检索” 的标准流程,通过 elasticsearch 输出插件实现:
-
核心配置:
output {elasticsearch {hosts => ["http://es-master:9200", "http://es-node01:9200"] # ES 集群地址(高可用)index => "web-access-log-%{+YYYY.MM.dd}" # 按日期分索引(如 web-access-log-2024.10.10)document_type => "_doc" # ES 7.x+ 仅支持 _doc 类型template => "/app/elk/logstash-7.6.2/config/es-template.json" # 字段映射模板(提前定义字段类型)template_overwrite => true # 允许覆盖现有模板} } -
关键特性:
-
支持 ES 集群地址列表(避免单节点故障);
-
按时间分索引(便于日志生命周期管理,如删除 30 天前的旧索引);
-
支持 “批量写入”(默认批量大小 500 条),提升写入性能;
-
支持 “重试机制”(ES 节点故障时自动重试),避免数据丢失。
-
(2)输出到文件(长期归档场景)
将日志写入本地或共享存储文件(如 NFS),用于 “长期归档”(如合规要求保存 1 年的原始日志),通过 file 输出插件实现:
-
配置示例:
output {file {path => "/data/logs/archive/web-access-%{+YYYY.MM.dd}.log" # 按日期归档文件format => "json_lines" # 按 JSON 行格式写入(便于后续恢复)gzip => true # 启用 Gzip 压缩(减少存储占用)} }
(3)输出到消息队列(二次转发场景)
将处理后的日志写入 Kafka/RabbitMQ,供其他系统(如 Spark、Flink)消费,用于 “离线数据分析”,通过 kafka 输出插件实现:
-
配置示例:
output {kafka {bootstrap_servers => "kafka-node01:9092,kafka-node02:9092" # Kafka 集群地址topic_id => "logstash-processed-logs" # 写入的 Kafka Topiccompression_type => "gzip" # 启用压缩batch_size => 1000 # 批量写入大小} }
(4)其他输出场景
-
email 插件:当检测到异常日志(如响应码 500)时,发送邮件告警;
-
elasticsearch_http 插件:通过 HTTP 协议写入 ES(适合 ES 开启安全认证场景);
-
stdout 插件:输出到控制台(用于调试,如 stdout { codec => rubydebug })。
(四)Kibana
可视化分析平台,主要功能:
- 界面展示:提供直观的 Web 界面用于日志数据展示
- 可视化制作:支持创建自定义仪表板和图表
- 日志检索:提供日志搜索和筛选功能
- 告警监控:支持创建告警规则监控异常情况
(二)ELK 部署与配置步骤
1、环境规划
使用4G以上的系统
| 服务器 IP | 主机名 | 角色 | 安装组件 |
| 192.168.140.10 | es-master.linux.com | 主节点 | JDK、Elasticsearch、Kibana、Logstash |
| 192.168.140.20 | es-node01.linux.com | 数据节点 | JDK、Elasticsearch |
| 192.168.140.21 | es-node02.linux.com | 数据节点 | JDK、Elasticsearch |
| 192.168.140.50 | web_server.linux.com | 业务服务器 | HTTPD、Filebeat |
2、基础环境准备
① 关闭 SELinux 并配置时间同步
# 临时关闭SELinux
setenforce 0
# 永久关闭SELinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 安装时间同步工具。
# 对于 ELK 集群,推荐优先使用 chrony 或 ntpd(持续运行的服务),确保节点间时间一致(误差控制在毫秒级),避免日志时序混乱或分片同步异常。
yum install -y chrony
# 1. 清理 yum 缓存(包括过期缓存和数据库)
yum clean all
# 2. 重建 yum 缓存(确保 yum 能识别最新的包状态)
yum makecache
# 3. 强制重新安装 chrony(即使 yum 认为已安装,也会覆盖并补全缺失文件)
yum reinstall -y chrony# 启动并设置开机自启
systemctl start chronyd
systemctl enable chronyd
# systemd 依赖 “配置缓存”,安装软件后若未刷新缓存,可能出现 “文件存在但系统不识别”;
# 同步时间
chronyc sources② 配置主机名解析
在所有主机上配置:
cat >> /etc/hosts << EOF
192.168.140.10 es_master.linux.com es_master
192.168.140.20 es_node01.linux.com es_node01
192.168.140.30 es_node02.linux.com es_node02
192.168.140.50 web.linux.com web
EOF
ping es_master # 应返回 192.168.140.10
ping es_node01 # 应返回 192.168.140.20
ping es_node02 # 应返回 192.168.140.30③ 配置防火墙规则
# 在ES集群节点上开放端口
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --zone=public --add-port=9300/tcp --permanent
# 在主节点上开放Kibana和Logstash端口
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --zone=public --add-port=5044/tcp --permanent# 重新加载防火墙规则
firewall-cmd --reload3、安装 JDK
1)# Elasticsearch 7.6.2 推荐使用 JDK 15以上的版本:
which java # 显示 java 命令路径(如:/usr/local/jdk1.8.0_91/bin/java)
ls -l /usr/local/jdk1.8.0_91 # 确认 JDK 目录是否存在
rm -rf /usr/local/jdk1.8.0_91
# 手动安装(常见于 .tar.gz 或 .zip 解压):直接删除 JDK 目录即可。包管理器安装需通过命令卸载。
# rpm安装:
rpm -qa | grep -i java # 列出所有 Java 相关包
rpm -e --nodeps 包名 # 强制卸载(例如:rpm -e --nodeps java-1.8.0-openjdk)
# yum安装:
yum remove java-1.8.0-openjdk* # 卸载所有 OpenJDK 相关包sudo vim /etc/profile # 删除 JAVA_HOME 相关行
source /etc/profile # 刷新全局配置
vim ~/.bashrc # 删除 JAVA_HOME 相关行
vim ~/.bash_profile # 检查并删除
source ~/.bashrc # 刷新当前用户配置java -version # 应提示 "未找到命令"
unset JAVA_HOME # 清除当前会话变量(仅临时生效)或重启
echo $JAVA_HOME # 输出应为空,重启、应该也为空# 在所有ES节点上执行
tar xf jdk-15.0.2_linux-x64_bin.tar.gz -C /usr/local/
# 配置环境变量
cat >> /etc/profile << EOF
export JAVA_HOME=/usr/local/jdk-15.0.2
export PATH=$PATH:$JAVA_HOME/bin
EOFsource /etc/profile
java -version
# java version "15.0.2" 2021-01-19
4、调整系统资源限制
ulimit -a # 查看当前系统资源限制
# 在所有 ES 节点上执行: 修改文件描述符限制
# /etc/security/limits.conf 用户级资源限制
vim /etc/security/limits.conf
* soft nofile 65536 # 软限制、最多可打开的文件描述符数量,*是用户名,所有用户生效
* hard nofile 65536 # 硬限制、最多可打开的文件描述符数量
* soft nproc 4096 # 最大进程数
* hard nproc 8192
* soft memlock unlimited # 内存锁定(不允许内存被交换到磁盘 swap)
* hard memlock unlimited # 内存锁定的上限(unlimited 表示无限制)# 修改系统内核参数
vim /etc/sysctl.conf
vm.max_map_count = 262144 # 系统允许的最大内存映射区域数量
fs.file-max = 655360 # 系统级别的最大文件句柄数量
net.ipv4.ip_local_port_range = 1024 65535 # 本地 TCP/UDP 端口的可用范围# 生效内核参数
sysctl -p5、部署 Elasticsearch 集群
1. 创建用户并安装软件
# 在所有ES节点上执行
useradd elk
mkdir -p /app/elk
tar xf elasticsearch-7.6.2-linux-x86_64.tar.gz -C /app/elk/
chown -R elk.elk /app/elk/
# 创建数据目录
su - elk -c "mkdir /app/elk/elasticsearch-7.6.2/data"
# 查看目录权限(应显示 owner 和 group 为 elk)
ls -ld /app/elk/elasticsearch-7.6.2/data/ /app/elk/elasticsearch-7.6.2/logs/2. 配置 Elasticsearch
(1)es-master 节点配置
su - elk -c "vim /app/elk/elasticsearch-7.6.2/config/elasticsearch.yml"cluster.name: es-cluster # 集群名、取名。 所有节点必须相同,标识同一集群
node.name: es-master # 此机器在此集群中的主机名
# node.name 是节点在集群中的唯一标识,需与 cluster.initial_master_nodes 中指定的候选主节点名称完全一致,否则主节点选举会失败。
path.data: /app/elk/elasticsearch-7.6.2/data/ # 日志存储目录(原本就有)
path.logs: /app/elk/elasticsearch-7.6.2/logs/ # 数据存储目录(自创。属主属组 elk:elk)
network.host: 192.168.140.11 # 节点实际IP,工作在哪个ip的
http.port: 9200 # 业务端口。工作在哪个端口,默认9200
transport.tcp.port: 9300 # (手动加)集群内部通信端口
discovery.seed_hosts: ["es_master:9300", "es_node01:9300", "es_node02:9300"]
# 哪几个机器生成es集群,列出所有节点的通信地址(主节点+数据节点)支持 IP 或主机名
cluster.initial_master_nodes: ["es_master"] # 始候选主节点(仅首次启动生效,指定主节点)
# 节点角色:专用主节点(仅负责集群管理,不存储数据/处理预处理)
node.master: true # 允许作为主节点。认值为 true(所有节点都可参与主节点选举)。
node.data: true # 不存储数据分片
node.ingest: false # 不处理数据预处理(如Logstash已处理数据,此处可关闭)
node.ml: false # 关闭机器学习(非必需功能)
# 跨域配置(允许Kibana访问)
http.cors.enabled: true
http.cors.allow-origin: true
# 禁用远程集群连接(非必需)
cluster.remote.connect: false(2、3、4)es-node01/02/03 节点配置
cluster.name: es_cluster # 与主节点一致
node.name: es_node01 # 数据节点1唯一标识
path.data: /app/elk/elasticsearch-7.6.2/data/
path.logs: /app/elk/elasticsearch-7.6.2/logs/
network.host: 192.168.140.12 # 数据节点1实际IP
http.port: 9200
transport.tcp.port: 9300
# 集群发现:与主节点配置一致
discovery.seed_hosts: ["es_master:9300", "es_node01:9300", "es_node02:9300", "es-node03:9300"]
# 初始候选主节点(与主节点一致,首次启动时生效)
cluster.initial_master_nodes: ["es_master"]
# 节点角色:数据节点(存储数据,处理预处理)
node.master: false # 不参与主节点选举
node.data: true # 存储数据分片
node.ingest: false # 处理数据预处理
node.ml: false
# 跨域配置
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.remote.connect: false# 配置中使用了主机名(es-master:9300、es-node01:9300 等),需确保所有节点的 /etc/hosts 中已配置主机名与 IP 的映射,否则节点启动时会因无法解析主机名而无法发现集群。
# 若无法确保主机名解析,建议直接使用 IP 地址(更可靠):
discovery.seed_hosts: ["192.168.140.11:9300", "192.168.140.12:9300", "192.168.140.13:9300", "192.168.140.14:9300"]3. 配置 JVM 参数
在所有 ES 节点上配置:
su - elk -c "vim /app/elk/elasticsearch-7.6.2/config/jvm.options"
设置堆内存大小(通常为服务器内存的一半,不超过 31GB):
-Xms2g
-Xmx2g4. 启动 Elasticsearch 集群
# 在每个节点上分别启动
[elk@host-10 ~]$ /app/elk/elasticsearch-7.6.2/bin/elasticsearch -d
# 若 重启 ES(先杀进程,再启动)
[elk@host-10 ~]$ ps -ef | grep elasticsearch | grep -v grep | awk '{print $2}' | xargs kill -9
[elk@host-10 ~]$ /app/elk/elasticsearch-7.6.2/bin/elasticsearch -d[root@host-10 ~] curl http://192.168.140.21:9200 # 10,20,21,都有输出
# 验证启动状态
[root@host-10 ~]# netstat -tunlp | grep 9200
[root@host-10 ~]# netstat -tunlp | grep 93005. 检查集群状态
# 查看集群健康状态
curl http://es_master:9200/_cluster/health?pretty # ES 集群健康,无报错则正常
[root@host-10 ~] curl http://es_master:9200/_cluster/health?pretty
{"cluster_name" : "es_cluster","status" : "green", // 健康状态:green(最佳)、yellow(可容忍)、red(异常)"timed_out" : false,"number_of_nodes" : 3, // 总节点数(1主+2数据,应为3)"number_of_data_nodes" : 2, // 数据节点数(应为2)"active_primary_shards" : 0, // 主分片数(无索引时为0,正常)"active_shards" : 0, // 所有分片数(无索引时为0)"relocating_shards" : 0, // 迁移中的分片(应为0)"initializing_shards" : 0, // 初始化中的分片(应为0)"unassigned_shards" : 0, // 未分配的分片(green状态时为0)"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}# 查看节点列表
curl -X GET "http://es_master:9200/_cat/nodes?v"
(1)健康状态说明
green:所有主分片和副本分片都正常运行
yellow:所有主分片正常运行,但部分副本分片未正常运行
red:部分主分片未正常运行6、配置 Logstash
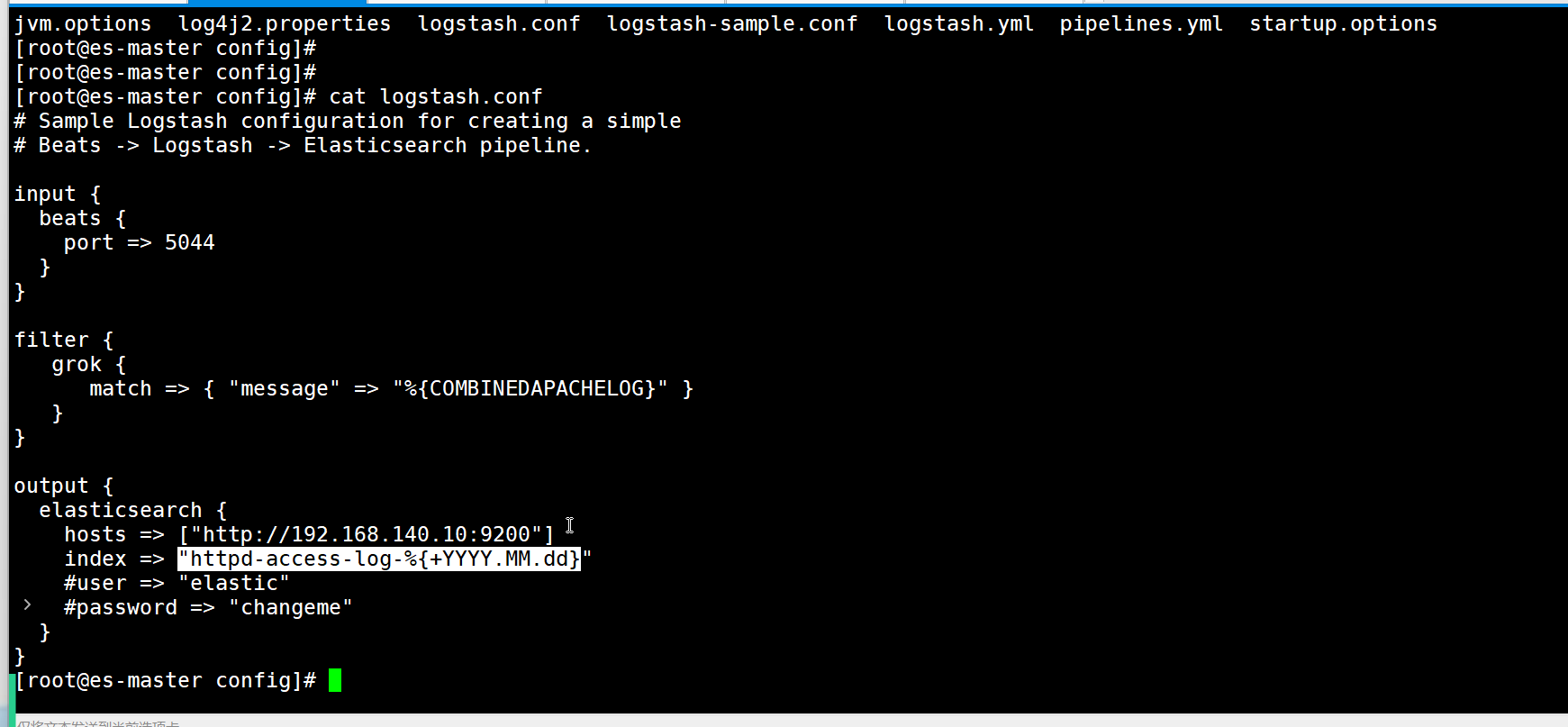
1. 安装 Logstash
# 在es-master节点上执行
tar xf logstash-7.6.2.tar.gz -C /app/elk/
chown -R elk.elk /app/elk/logstash-7.6.2/
cd /app/elk/logstash-7.6.2/config/
cp logstash-sample.conf logstash.conf2. 配置 Logstash
vim /app/elk/logstash-7.6.2/config/logstash.conf
# 数据输入源,通过 beats 插件,让 Logstash 监听服务器的 5044 端口,接收来自 Filebeat(Beats 家族中用于日志采集的工具)发送的日志数据。
input {beats {port => 5044 # 监听 5044 端口,接收来自 Beats 工具的数据}
}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" } # 用预定义模式解析日志tag_on_failure => ["_grokparsefailure"] # 解析失败时添加此标签}
}
# %{COMBINEDAPACHELOG} 模式:这是 Logstash 预定义的一个通用日志模式,专门匹配 Apache/Nginx/Tomcat 等 Web 服务器的访问日志
# 目录 /app/elk/logstash-7.6.2/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns 是 Logstash 内置 grok 模式文件的存放路径,这些文件定义了大量预定义的日志解析规则(即 “过滤日志的方法”),用于快速匹配常见日志格式(如 Apache、Nginx、Java、Syslog 等)output {elasticsearch {hosts => ["http://192.168.140.10:9200"] # Elasticsearch 地址(主节点 HTTP 端口)index => "web-access-log-%{+YYYY.MM.dd}" # 写入 ES 的索引名(按日期分片)# user => "elastic" # 若 ES 开启认证,需填写用户名# password => "changeme" # 若 ES 开启认证,需填写密码}
}3. 配置 Logstash JVM 参数
vim /app/elk/logstash-7.6.2/config/jvm.options
设置合适的内存大小:
-Xms1g
-Xmx1g
# 禁用GC垃圾回收机制
#-XX:+UseConcMarkSweepGC
#-XX:CMSInitiatingOccupancyFraction=75
#-XX:+UseCMSInitiatingOccupancyOnly[root@host-10 config]# nohup /app/elk/logstash-7.6.2/bin/logstash -f /app/elk/logstash-7.6.2/config/logstash.conf &
[root@host-10 config]# nohup: 忽略输入并把输出追加到"nohup.out"
^C[root@host-10 config] netstat -tunlp | grep 5044
# tcp6 0 0 :::5044 :::* LISTEN 2508/java 

7、安装 Kibana
1. 安装并配置 Kibana
# 在es-master节点上执行
[root@host-10 ~] tar xf kibana-7.6.2-linux-x86_64.tar.gz -C /app/elk/
[root@host-10 ~] mkdir -p /app/elk/kibana-7.6.2-linux-x86_64/logs
[root@host-10 ~] chown -R elk.elk /app/elk/kibana-7.6.2-linux-x86_64/# 配置Kibana
[root@host-10 ~] su - elk
[elk@host-10 ~]$ vim /app/elk/kibana-7.6.2-linux-x86_64/config/kibana.yml
配置内容:
server.port: 5601
server.host: "192.168.140.10" # 监听ip
elasticsearch.hosts: ["http://es-master:9200"] # 主机名/ip
kibana.index: ".kibana"
logging.dest: /app/elk/kibana-7.6.2-linux-x86_64/logs/kibana.log
i18n.locale: "zh-CN" # 设置中文界面2. 启动 Kibana
su - elk
[elk@es-master ~]$ nohup /app/elk/kibana-7.6.2-linux-x86_64/bin/kibana &[elk@es-master ~]$ ps -elf | grep kibana
# 0 R elk 40227 39800 99 80 0 - 293743 - 14:47 pts/0 00:00:57 /app/elk/kibana-7.6.2-linux-x86_64/bin/../node/bin/node /app/elk/kibana-7.6.2-linux-x86_64/bin/../src/cli[elk@es-master ~]$ netstat -antp | grep 5601
# (Not all processes could be identified, non-owned process info
# will not be shown, you would have to be root to see it all.)
# tcp 0 0 192.168.140.10:5601 0.0.0.0:* LISTEN
// Kibana 启动分两步:
- 第一步:资源优化(CPU 高,无端口监听):Kibana 基于 Node.js 开发,首次启动或版本更新后,会自动执行 “前端资源优化”(如编译 React 组件、打包静态资源、生成缓存),这个过程需要大量 CPU 计算(所以显示 91%-99%),且 不会立即监听 5601 端口;
- 第二步:服务就绪(CPU 下降,端口监听):资源优化完成后,Kibana 才会启动 HTTP 服务,监听 5601 端口,此时 CPU 使用率会降到正常水平(10% 以内)。
- “进程存在但端口没监听”,是 优化阶段的预期状态,不是故障!
8、在业务服务器部署 Filebeat
1. 安装 HTTP 服务(如未安装)
# 在web_server节点上执行
yum install -y httpd
systemctl start httpd
systemctl enable httpd2. 安装 Filebeat
# 在web_server节点上执行
tar xf filebeat-7.6.2-linux-x86_64.tar.gz -C /usr/local/
mv /usr/local/filebeat-7.6.2-linux-x86_64 /usr/local/filebeat
chown -R root.root /usr/local/filebeat/3. 配置 Filebeat
vim /usr/local/filebeat/filebeat.yml
配置内容:#=========================== Filebeat inputs =============================filebeat.inputs:
- type: logenabled: truepaths:- /var/log/httpd/access_log#============================== Dashboards =====================================
setup.dashboards.enabled: false#============================== Kibana =====================================
setup.kibana:host: "192.168.140.10:5601"#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:# Array of hosts to connect to.
# hosts: ["localhost:9200"]#----------------------------- Logstash output --------------------------------
output.logstash:# The Logstash hostshosts: ["192.168.140.10:5044"]4. 启动 Filebeat
[root@host_50 ~] cd /usr/local/filebeat/
[root@host_50 filebeat] nohup ./filebeat -c filebeat.yml &
[1] 2261
[root@host_50 filebeat] nohup: 忽略输入并把输出追加到"nohup.out"
^C
[root@host_50 filebeat] ps -elf | grep file
# 4 S dbus 693 1 0 80 0 - 14555 ep_pol 11:37 ? 00:00:00 4 S dbus 704 1 0 80 0 - 14555 ep_pol 12:35 ? 00:00:00 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
# 0 S root 2261 1680 0 80 0 - 121235 futex_ 19:56 pts/0 00:00:00 ./filebeat -c filebeat.yml三、ELK 平台测试与使用
(一)访问 Kibana 界面
在浏览器中访问:http://192.168.140.10:5601
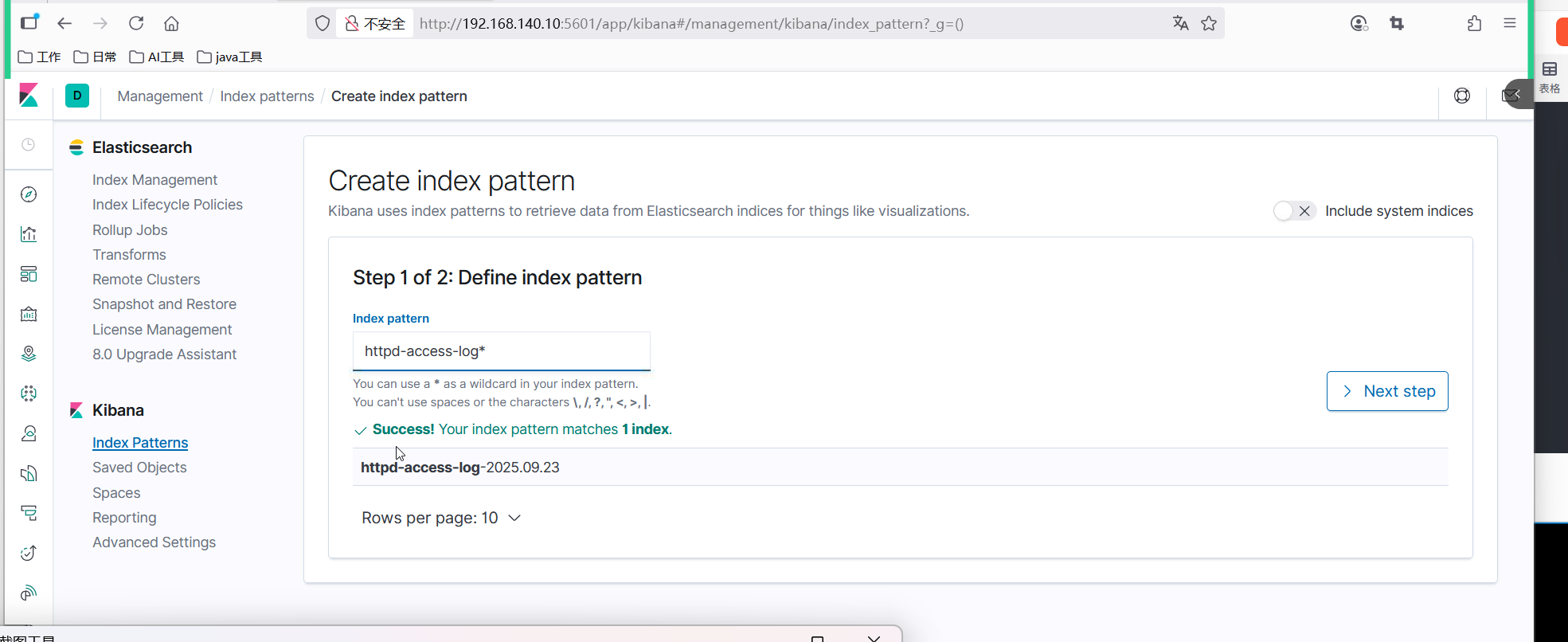

(二)创建索引模式
- 首次登录 Kibana 后,点击左侧导航栏的 "Management" → "Kibana" → "Index Patterns"
- 点击 "Create index pattern"
- 在 "Index pattern" 输入框中输入 web-access-log-*
- 点击 "Next step"
- 在 "Time Filter field name" 下拉菜单中选择 @timestamp
- 点击 "Create index pattern"
(三)查看日志数据
- 点击左侧导航栏的 "Discover"
- 在顶部的索引模式下拉菜单中选择 web-access-log-*
- 可以看到收集的 Apache 访问日志数据
- 使用时间范围选择器筛选特定时间段的日志
- 使用搜索框进行关键词搜索,如 response:500 搜索服务器错误日志
(四)创建可视化图表
- 点击左侧导航栏的 "Visualize"
- 点击 "Create visualization"
- 选择图表类型,如 "Line"
- 选择索引模式 web-access-log-*
- 在 Y 轴设置中,选择 "Count"
- 在 X 轴设置中,选择 "Date Histogram",字段选择 @timestamp,间隔选择 "Auto"
- 点击 "Apply changes" 查看网站访问量趋势图
- 点击 "Save" 保存可视化图表
(五)创建仪表板
- 点击左侧导航栏的 "Dashboard"
- 点击 "Create dashboard"
- 点击 "Add" 添加之前创建的可视化图表
- 可以调整图表位置和大小
- 点击 "Save" 保存仪表板
(六)验证数据流程
1、在 web 服务器上生成测试日志:
for i in {1..100};do curl http://localhost;done2、在 Kibana 中查看是否有新日志产生
3、检查可视化图表是否更新
四、常见问题排查
(1)Elasticsearch 启动失败
① JDK 版本兼容性:确认 JDK 版本是否符合 Elasticsearch 7.6.2 要求(推荐 JDK 8/11)
② 文件权限:检查/app/elk/elasticsearch-7.6.2目录及子目录权限是否为elk:elk
③ 系统资源限制:重新执行sysctl -p和source /etc/profile确保资源限制生效
④ 日志查看:分析日志文件定位问题:/app/elk/elasticsearch-7.6.2/logs/es-cluster.log
(2)Logstash 无输出
① 配置语法检查:执行命令验证配置文件:/app/elk/logstash-7.6.2/bin/logstash -f /app/elk/logstash-7.6.2/config/logstash.conf --config.test_and_exit
② 日志分析:查看 Logstash 运行日志:/app/elk/logstash-7.6.2/logs/logstash-plain.log
③ 端口连通性:检查 5044 端口是否正常开放:netstat -tunlp | grep 5044
(3)Filebeat 无法发送日志
① 配置验证:执行配置检查:/usr/local/filebeat/filebeat test config
② 输出连接测试:测试与 Logstash 的连接:/usr/local/filebeat/filebeat test output
③ 日志排查:查看 Filebeat 日志:/var/log/filebeat/filebeat
(4)Kibana 无数据显示
① 索引模式验证
确认索引模式web-access-log-*已正确创建且包含数据
② Elasticsearch 索引检查
执行命令查看索引是否存在:curl http://es-master:9200/_cat/indices?v
③ 连接状态
确认 Kibana 与 Elasticsearch 通信正常,检查 Kibana 配置文件中的elasticsearch.hosts参数