【MySQL 高阶】MySQL 架构与存储引擎全面详解
目录
一、 连接层 (The Connection Layer)
1.1 核心功能与组件
1.2 监控与代码示例
二、 服务层 (The Server Layer)
2.1 核心组件详解
2.2 代码示例:查看执行计划
三、 存储引擎层 (The Storage Engine Layer)
3.1 查看与设置存储引擎
3.2 各存储引擎深度对比与详解
3.3 各存储引擎详解与代码示例
四、 文件系统层 (The File System Layer)
面试题解答
MySQL 的整体架构设计精巧且高度模块化,其核心在于 “服务与存储分离” ,通过定义清晰的API接口,实现了可插拔的存储引擎架构。这意味着你可以根据不同的业务场景(如事务型处理、数据分析、归档等)为不同的表选择最合适的存储引擎,从而获得极致的性能和数据管理体验。
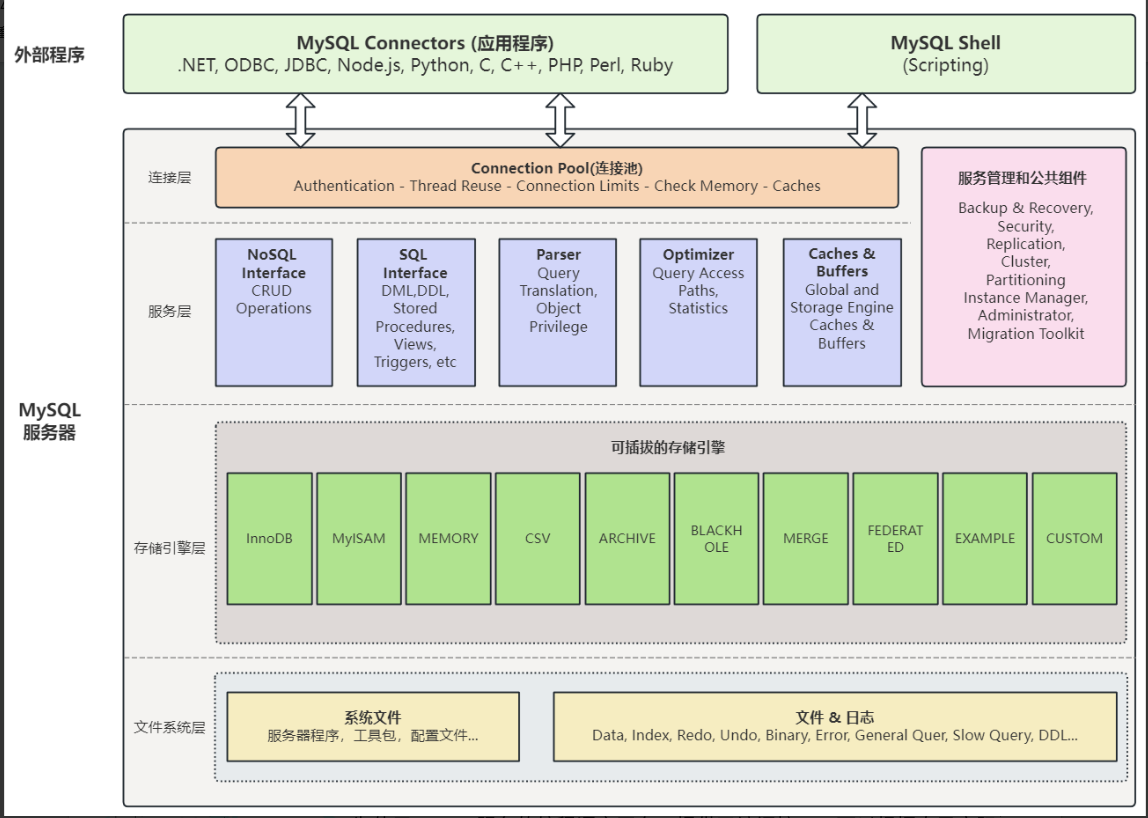
其架构自上而下可分为四大层次:连接层、服务层、存储引擎层和文件系统层。下面我们逐层进行深入剖析。
一、 连接层 (The Connection Layer)
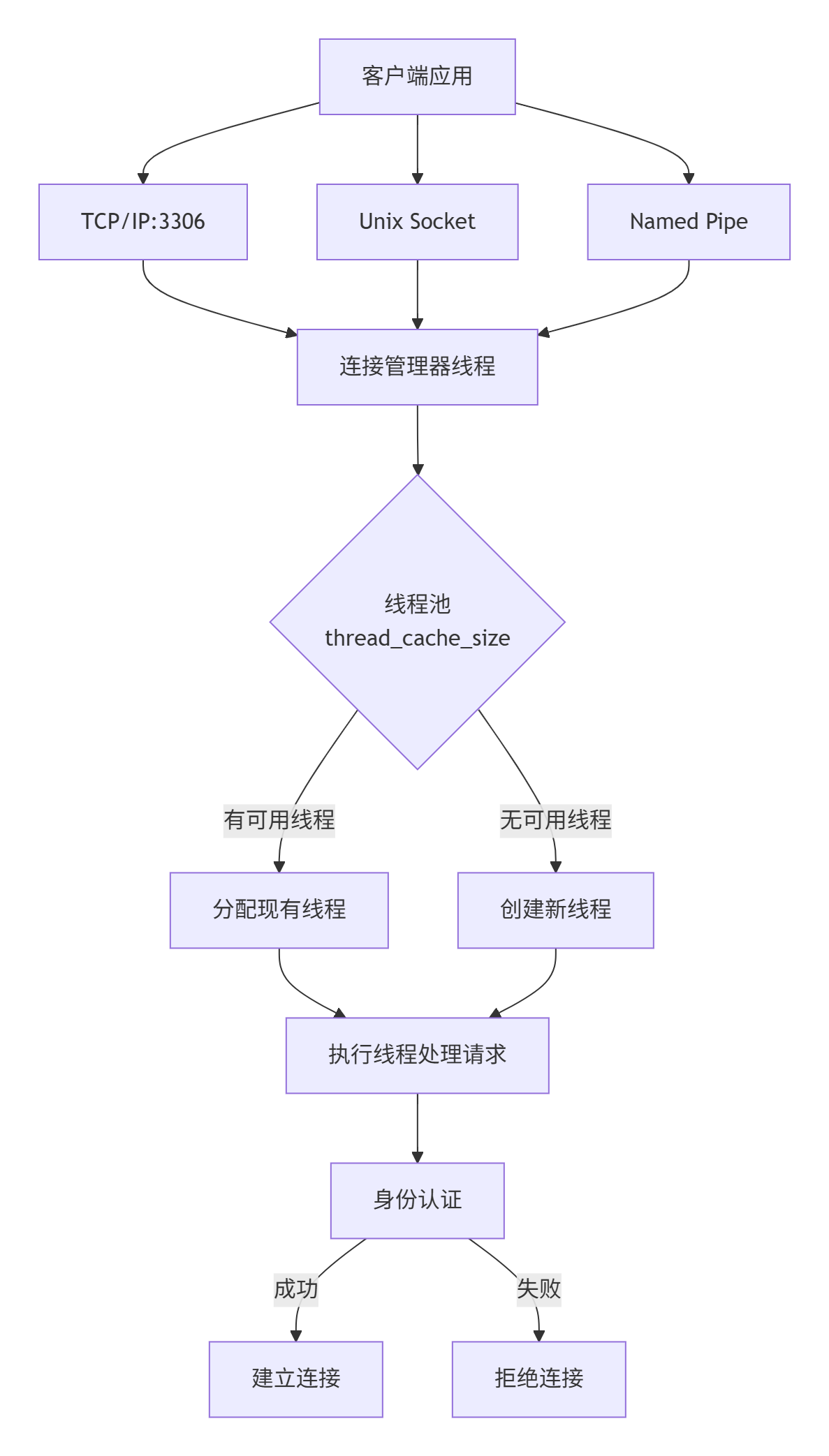
连接层是MySQL的“门户”,负责处理所有客户端的接入、认证和管理工作。
1.1 核心功能与组件
-
连接协议与端口管理:
-
MySQL服务器可以监听多个网络端口(如默认的3306端口)。这通过在配置文件(如
my.cnf或my.ini)中设置port选项来实现。
[mysqld] port=3306 port=3307 # 可以配置多个端口-
服务器使用连接管理器线程 (Connection Manager Threads) 来监听这些端口。不同平台有不同的管理策略:
-
所有平台:一个独立的线程处理所有TCP/IP连接请求。
-
Unix/Linux:同一个管理器线程还能处理Unix Socket文件连接。
-
Windows:单独的线程处理命名管道(Named-pipe)和共享内存(Shared-memory)连接。
-
-
-
身份认证:客户端连接时,连接层会对其进行用户名、密码及主机权限的校验。
-
线程管理与线程池:
-
连接管理器接收到连接后,会将其转交给一个执行线程来处理该连接的所有请求。
-
为了应对大量并发连接并避免频繁创建销毁线程的开销,MySQL使用了线程池 (Thread Cache) 技术。
-
工作流程:新连接到来 -> 从线程池获取空闲线程 -> 若池为空则创建新线程 -> 连接结束时,线程返回池中缓存以待重用。
-
-
关键系统变量:
-
thread_cache_size:定义了线程池的大小。这是重要的性能调优参数。 -
thread_stack:定义了每个线程的堆栈大小,处理复杂SQL时可能需要调整。
-
-
-
连接数限制:
-
max_connections:控制服务器允许的最大并发连接数。连接数达到此限后,新连接将被拒绝。 -
管理员特权:MySQL设计了一个“后门”,允许最多
max_connections + 1个连接。这额外的一个连接预留给拥有CONNECTION_ADMIN权限的账户,确保在普通连接爆满时,管理员依然可以登录进行管理和故障排查。
-
1.2 监控与代码示例
-- 查看线程池相关的状态变量
SHOW GLOBAL STATUS LIKE 'Threads_cached'; -- 当前缓存的空闲线程数
SHOW GLOBAL STATUS LIKE 'Threads_created'; -- 服务器启动后创建的线程总数
SHOW GLOBAL STATUS LIKE 'Connections'; -- 尝试连接的总次数-- 如果Threads_created值很大,意味着线程池命中率低,应考虑增大thread_cache_size
SHOW VARIABLES LIKE 'thread_cache_size'; -- 查看当前线程池大小
SET GLOBAL thread_cache_size = 32; -- 在线修改(重启后失效)-- 查看最大连接数
SHOW VARIABLES LIKE 'max_connections';
SET GLOBAL max_connections = 500; -- 在线修改连接层工作流程示意图:
二、 服务层 (The Server Layer)
服务层是MySQL的“大脑”和“指挥中心”,负责SQL的解析、优化、缓存等所有核心逻辑运算。它不负责实际的数据存储,而是指挥存储引擎层去干活。
2.1 核心组件详解
-
连接池 (Connection Pool):
-
管理并缓冲用户连接,并非所有连接都时刻活跃,连接池负责高效复用。
-
-
服务管理与工具 (Utilities):
-
提供了一系列数据库管理功能,这些功能通常是独立于存储引擎的:
-
备份与恢复 (Backup & Recovery)
-
主从复制 (Replication)
-
集群管理 (Cluster)
-
安全管理 (Security):如权限验证(连接层是基础认证,这里是更全面的权限检查)。
-
表分区 (Partitioning)
-
-
-
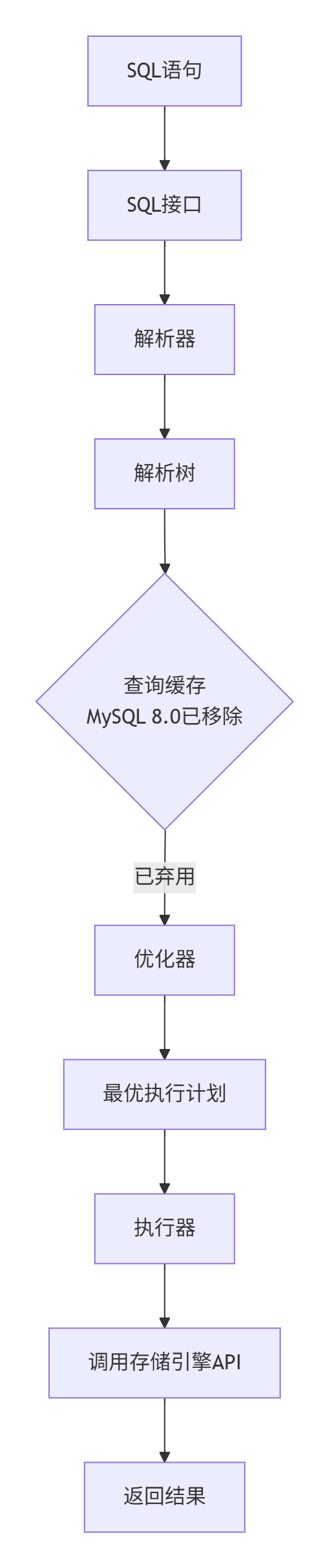
SQL接口 (SQL Interface):
-
接收客户端发送的SQL语句(
DML,DDL,存储过程调用等),并返回执行结果。
-
-
解析器 (Parser):
-
词法分析 (Lexical Analysis):将SQL语句拆分成一个个有意义的“词元”(Tokens),如识别出
SELECT,FROM,student等。 -
语法分析 (Syntax Analysis):根据MySQL语法规则检查SQL语句的结构是否正确。如果错误,则抛出
ERROR 1064 (42000)。 -
最终生成一棵解析树 (Parse Tree),这棵树精确地描述了SQL的语义结构。
-
示例:对于
SELECT sn, name FROM student WHERE id = 1,解析树会明确标识出查询目标(student表)、要选择的列(sn,name)和过滤条件(id=1)。
-
-
优化器 (Query Optimizer):
-
这是最复杂和智能的组件。它接收解析树,并为其生成一个成本最低的执行计划 (Execution Plan)。
-
它可能进行以下操作:
-
重写查询:改变查询的执行顺序(但结果不变)。
-
选择索引:决定使用哪个索引来最高效地查找数据。
-
决定连接顺序:对于多表连接(JOIN),决定先读哪张表,后读哪张表。
-
-
优化基于表的统计信息和系统配置。你可以使用
EXPLAIN命令来查看优化器选择的执行计划。
-
-
缓存 (Caches & Buffers):
-
历史与现状:在MySQL 5.7及以前,服务层有一个查询缓存 (Query Cache),它缓存完整的SELECT语句及其结果。但在MySQL 8.0中已被彻底移除。原因在于:① 失效机制僵化(任何表有更新,该表所有相关缓存全部失效);② 并发锁竞争激烈,在高并发环境下反而成为性能瓶颈。
-
注意:服务层缓存虽已消失,但存储引擎层有自己的缓存(如InnoDB的缓冲池),这对性能至关重要。
-
2.2 代码示例:查看执行计划
-- 使用EXPLAIN查看优化器选择的执行计划
EXPLAIN SELECT * FROM student WHERE name = '张三';-- 输出结果包含:
-- id: 执行顺序
-- select_type: 查询类型
-- table: 查询涉及的表
-- type: 访问类型(如index, all, range等,这是优化重点)
-- possible_keys: 可能使用的索引
-- key: 实际使用的索引
-- rows: 预估需要扫描的行数
-- Extra: 额外信息(如Using where, Using index等)服务层SQL处理流程图:
三、 存储引擎层 (The Storage Engine Layer)
这是MySQL最具特色的部分,真正负责数据的存储和提取。存储引擎是可插拔的,意味着你可以像更换汽车的发动机一样,为不同的表选择不同的存储引擎。
3.1 查看与设置存储引擎
-- 查看当前服务器支持的所有存储引擎及其状态
SHOW ENGINES;-- 查看某张表使用的存储引擎
SHOW TABLE STATUS LIKE 'student';
-- 或
SELECT TABLE_NAME, ENGINE FROM information_schema.TABLES WHERE TABLE_SCHEMA = 'your_database';-- 创建表时指定存储引擎
CREATE TABLE my_innodb_table (id INT PRIMARY KEY,data VARCHAR(100)
) ENGINE=InnoDB;-- 修改现有表的存储引擎(谨慎操作,会锁表并重建表)
ALTER TABLE my_myisam_table ENGINE = InnoDB;3.2 各存储引擎深度对比与详解
以下是对MySQL常见存储引擎的详细对比和说明:
| 特性 | InnoDB | MyISAM | MEMORY | CSV | ARCHIVE |
|---|---|---|---|---|---|
| 事务支持 | 支持 (ACID) | 不支持 | 不支持 | 不支持 | 不支持 |
| 锁粒度 | 行级锁 | 表级锁 | 表级锁 | 表级锁 | 行级锁 |
| 外键支持 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 崩溃恢复 | 支持 (Crash-Safe) | 不支持 | 数据丢失 | 需修复 | 不支持 |
| 缓存机制 | 缓冲池(缓存数据和索引) | 只缓存索引 | 数据在内存中 | 无 | 无 |
| 压缩特性 | 支持表压缩 | 支持压缩表(只读) | 无 | 无 | 极高压缩率 |
| 存储限制 | 64TB | 256TB | 受限于内存 | 受限于文件系统 | 受限于文件系统 |
| 适用场景 | 绝大多数场景 | 只读或读多写少 | 临时表、缓存 | 数据交换、日志 | 归档历史数据 |
3.3 各存储引擎详解与代码示例
1. InnoDB (默认引擎)
-
特点:支持事务、行级锁、外键,具有崩溃恢复能力,是MySQL的首选存储引擎,适用于绝大多数需要数据一致性和高并发性能的场景。
-
文件:
-
.ibd文件:独立表空间文件,存储每个表的数据和索引(当innodb_file_per_table=ON时)。 -
系统表空间:
ibdata1文件,存储数据字典、undo日志等。
-
-
最佳实践:
-- 确保使用InnoDB CREATE TABLE orders (order_id INT AUTO_INCREMENT PRIMARY KEY, -- 定义明确的主键user_id INT,amount DECIMAL(10,2),FOREIGN KEY (user_id) REFERENCES users(user_id) -- 外键约束 ) ENGINE=InnoDB;-- 事务操作 START TRANSACTION; INSERT INTO orders (user_id, amount) VALUES (1, 99.99); UPDATE accounts SET balance = balance - 99.99 WHERE user_id = 1; COMMIT; -- 提交事务
2. MyISAM
-
特点:不支持事务和行级锁(只有表锁),不支持外键。强调读取性能,支持全文索引(FULLTEXT)。在MySQL 8.0中,InnoDB也已支持全文索引,使其优势不再明显。
-
文件:
-
.MYD文件:存储数据。 -
.MYI文件:存储索引。 -
.sdi文件:存储表元数据(8.0版本)。
-
-
代码示例:
CREATE TABLE web_log (id INT PRIMARY KEY AUTO_INCREMENT,log_time DATETIME,message TEXT,FULLTEXT INDEX (message) -- 全文索引 ) ENGINE=MyISAM;
3. MEMORY ( formerly HEAP)
-
特点:所有数据存储在RAM中,速度极快。服务重启或崩溃后数据丢失。使用表级锁。
-
适用场景:临时工作区、缓存映射表、会话管理。
-
代码示例:
CREATE TEMPORARY TABLE session_cache (session_id VARCHAR(32) PRIMARY KEY,user_data TEXT ) ENGINE=MEMORY;-- 设置内存表最大大小(会话级) SET max_heap_table_size = 1024 * 1024 * 64; -- 64MB INSERT INTO session_cache VALUES ('abc123', '{"user_id": 1}');
4. CSV
-
特点:以逗号分隔值的文本格式存储数据。可以直接用文本编辑器打开查看,便于与外部系统(如Excel)交换数据。
-
文件:
-
.CSV文件:数据文件。 -
.CSM文件:元数据文件。
-
-
代码示例:
CREATE TABLE data_export (id INT NOT NULL,content CHAR(100) NOT NULL ) ENGINE=CSV;-- 插入数据后,可直接查看.CSV文件 INSERT INTO data_export VALUES (1, 'Hello, World'); -- 文件内容: 1,"Hello, World"
5. ARCHIVE
-
特点:专为高速插入和压缩存储而设计。只支持INSERT和SELECT,不支持DELETE、UPDATE和索引。压缩率非常高,非常适合存储海量的历史归档数据。
-
文件:
.ARZ文件(数据文件)。 -
代码示例:
CREATE TABLE audit_log_archive (id INT AUTO_INCREMENT PRIMARY KEY,log_time DATETIME,action TEXT ) ENGINE=ARCHIVE;-- 从InnoDB表归档数据 INSERT INTO audit_log_archive SELECT * FROM audit_log WHERE log_time < '2023-01-01';
四、 文件系统层 (The File System Layer)
这是数据的最终物理存储层。所有数据库、表结构、数据、索引、日志最终都以文件的形式存储在磁盘上。
-
文件类型:
-
表结构文件:
.sdi(Serialized Dictionary Information) 文件,在MySQL 8.0中用于存储表定义信息(取代了旧版的.frm文件)。 -
数据与索引文件:如InnoDB的
.ibd文件,MyISAM的.MYD和.MYI文件。 -
日志文件:
-
重做日志 (Redo Log):
ib_logfile0,ib_logfile1,用于InnoDB的崩溃恢复。 -
二进制日志 (Binlog):
binlog.xxxxxx,用于主从复制和数据恢复。 -
错误日志:记录启动、运行、停止时的错误信息。
-
慢查询日志:记录执行时间超过阈值的SQL语句。
-
-
-
物理结构:数据最终存储在磁盘的数据页中(通常是16KB大小),通过B+树等数据结构进行组织,以实现高效读写。
面试题解答
7.1.1 说一下MySQL的系统架构
MySQL采用分层、可插拔的架构设计,主要分为四层:
连接层:负责客户端连接的建立、认证和管理。通过线程池技术处理高并发连接,并设有最大连接数限制。
服务层:是MySQL的核心,包含SQL接口、解析器、优化器、执行器等组件。它负责SQL的解析、校验、优化(生成执行计划),但本身不存储数据。
存储引擎层:真正负责数据的存储和提取。MySQL支持多种可插拔的存储引擎(如InnoDB、MyISAM),开发者可以根据业务特性(如是否需要事务)为表选择合适的引擎。这是MySQL区别于其他数据库的一大特色。
文件系统层:将数据库、表、索引等数据以文件形式持久化到物理磁盘上,并管理各种日志文件。
这种架构使得数据处理逻辑与数据存储分离,提供了极大的灵活性和可定制性。
7.1.2 MySQL支持哪些存储引擎?
MySQL支持多种存储引擎,核心的有:
InnoDB:默认引擎。支持事务、行级锁、外键,提供崩溃恢复能力,适用于绝大多数需要数据一致性和高并发读写的OLTP应用。
MyISAM:不支持事务和行级锁。表级锁使其更适合读多写少的静态表、数据仓库或Web应用。支持全文索引(但MySQL 8.0的InnoDB也支持了)。
MEMORY:将数据完全存放在内存中,速度极快,但服务重启后数据丢失。用于临时表和缓存。
CSV:以CSV文本格式存储数据,便于与外部系统(如Excel)进行数据交换。
ARCHIVE:专为高速插入和压缩而设计,压缩率极高,只支持INSERT和SELECT,非常适合归档历史数据。
此外,还有MERGE、FEDERATED等引擎,但最常用的是InnoDB和MyISAM。
7.1.3 介绍一下InnoDB和MyISAM的区别
InnoDB和MyISAM是MySQL最常用的两种存储引擎,它们的核心区别如下:
特性
InnoDB
MyISAM
事务
支持 (ACID)
不支持
锁机制
行级锁,适合高并发
表级锁,写操作会锁全表,并发性能差
外键
支持
不支持
崩溃恢复
支持,能从意外关机中恢复数据
不支持,表易损坏,需手动修复
缓存
缓冲池,缓存数据和索引
只缓存索引,不缓存数据
主键
聚簇索引,数据文件本身按主键排序
非聚簇索引,索引和数据文件分离
全文索引
MySQL 5.6+ 支持
支持
count() *
需要扫描表(或有查询条件时)
存储了总行数,直接返回,非常快
适用场景
OLTP、高并发、要求事务一致性的业务
只读或读多写少、不需要事务的业务
总结:在现代MySQL版本中,InnoDB因其事务安全性和高并发支持,已成为绝对的主流和默认选择。除非有非常特殊的只读场景,否则都应优先使用InnoDB。MyISAM正在逐渐被淘汰。