C语言 ——— 指针
目录
指针+-整数
指针的类型决定了地址偏移的 “步长”
通过指针对数组元素进行赋值和打印
指针-指针
指针解引用
指针解引用时访问的内存空间大小
二级指针
指针数组
指针+-整数
指针的类型决定了地址偏移的 “步长”
代码演示:
int a = 0x11223344;int* pa = &a;
char* pc = &a;printf("pa = %p\n", pa);
printf("pc = %p\n\n", pc);printf("pa+1 = %p\n", pa + 1);
printf("pc+1 = %p\n", pc + 1);1. 初始变量与指针的基础关联
首先定义 int a = 0x11223344:0x 是 16 进制数的标识,而 16 进制中每两个数字对应 1 个字节(如 0x11 是 1 字节,0x22 是另一字节),0x11223344 共 4 个 “两数字组”,恰好填满 int 类型通常占用的4 字节空间(这也是选择该值的原因)。
随后定义两个不同类型的指针:int* pa = &a(pa 是指向 int 类型的指针,存储 a 的起始地址)和 char* pc = &a(pc 是指向 char 类型的指针,同样存储 a 的起始地址)。由于二者都指向变量 a 的起始内存地址,因此首次打印 pa 和 pc 时,输出的地址值完全相同 —— 指针的 “指向位置” 一致,但 “类型属性” 不同,这为后续加 1 操作的差异埋下伏笔。
2. 指针加 1 的关键差异:步长由类型决定
当对指针执行 “+1” 操作时,并非简单地让地址值加 1,而是按指针指向的数据类型的大小,调整地址偏移量—— 这个偏移量就是 “步长”,而步长的大小由指针类型直接决定:
- 对于
int* pa:int类型占 4 字节,因此pa + 1会让地址值增加 4(即跳过 1 个完整的int类型所占的内存空间); - 对于
char* pc:char类型占 1 字节,因此pc + 1只会让地址值增加 1(即跳过 1 个char类型所占的内存空间)。
这就是为什么 “初始地址相同的两个指针,加 1 后地址不同”:指针类型不同 → 步长不同 → 地址偏移量不同,这是指针 ± 整数操作最核心的规律。
3. 核心结论:指针类型需与指向数据类型匹配
代码隐含的关键原则是:什么类型的变量,就该用对应类型的指针接收其地址。若随意混用(如用 char* 接收 int 变量的地址),虽不会导致初始地址错误,但后续执行 ± 整数、解引用等操作时,会因步长错误或访问范围错误,引发不可预期的问题(例如用 pc 遍历 int 变量 a 时,每次只能访问 1 字节,无法完整获取 a 的 4 字节数据)。
代码验证: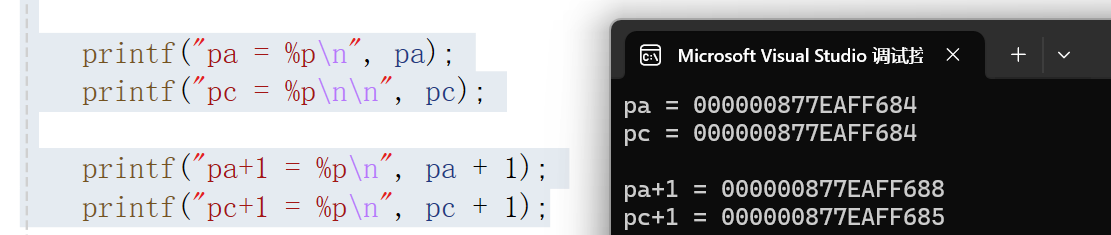
通过指针对数组元素进行赋值和打印
代码演示:
int arr[10] = { 0 };
int* p = arr;int sz = sizeof(arr) / sizeof(arr[0]);for (int i = 0; i < sz; i++)
{*(p + i) = i;
}for (int i = 0; i < sz; i++)
{printf("%d ", *(p + i));
}第一个for循环:通过指针给数组元素赋值
循环体为 *(p + i) = i;,核心逻辑是:
p是指向数组arr首元素(arr[0])的int*类型指针(数组名arr本质是首元素地址,因此p = arr表示p指向arr[0])。p + i是指针的偏移运算:由于p是int*类型,p + i会指向数组的第i个元素(arr[i])—— 偏移步长由指针类型决定(int占 4 字节,p + i实际地址比p大i * 4字节,恰好跳过前i个int元素)。*(p + i)是对偏移后指针的解引用:表示访问p + i所指向的内存空间,即数组的第i个元素arr[i]。
因此,*(p + i) = i 等价于 arr[i] = i,循环执行后,数组 arr 的元素被依次赋值为 0, 1, 2, ..., 9。
第二个for循环:通过指针打印数组元素
循环体为 printf("%d ", *(p + i));,核心逻辑与赋值循环一致:
- 同样通过
p + i定位到数组的第i个元素arr[i],再通过解引用*(p + i)获取该元素的值。 - 循环依次打印
arr[0]到arr[9]的值,最终输出0 1 2 3 4 5 6 7 8 9。
核心结论
代码通过 *(p + i) 的形式,将指针的偏移运算与解引用结合,实现了对数组元素的访问 —— 这本质上是数组下标访问(arr[i])的底层实现逻辑:数组下标 i 本质是指针从首元素开始的偏移量,arr[i] 等价于 *(arr + i),也等价于 *(p + i)(因为 p = arr)。这种指针操作更直观地体现了数组在内存中连续存储的特性,也展示了指针在数组操作中的灵活性。
指针-指针
代码演示:
int arr[10] = { 0 };printf("%d\n", &arr[9] - &arr[0]);指针减法运算的规则与前提
指针之间的减法运算并非简单的 “地址数值相减”,而是有明确的含义和严格限制:
- 运算结果的含义:两个指针相减,最终得到的是它们所指向位置之间的 “元素个数”(而非地址值相减的绝对值)。具体来说,结果数值 = (后指针地址值 - 前指针地址值) ÷ 指针指向元素的类型大小,本质是统计两个指针中间能容纳多少个目标类型的元素。
- 严格前提条件:执行指针减法的两个指针,必须指向同一块连续的内存空间(例如同一个数组、同一个结构体的连续成员区域等)。若两个指针指向无关的内存(比如一个指向数组 A,一个指向单独的 int 变量 B),此时减法运算的结果没有任何实际意义,甚至可能引发未定义行为(程序逻辑混乱或崩溃)。
代码结果解析
要理解输出结果,需结合数组的内存特性和指针减法规则:
- 数组的内存本质:
int arr[10]是一个包含 10 个 int 类型元素的数组,在内存中以连续方式存储—— 从arr[0]到arr[9],每个元素依次排列,且每个 int 元素占 4 字节(默认情况下)。 - 指针的指向:
&arr[0]是数组首元素(第 0 个元素)的地址,&arr[9]是数组最后一个元素(第 9 个元素)的地址,这两个指针明确指向同一块空间(arr 数组的内存区域),完全满足指针减法的前提条件。 - 运算过程与结果:指针减法会自动根据元素类型(int,4 字节)计算 “元素个数”:
- 地址差:
&arr[9]的地址值 -&arr[0]的地址值 = 9 × 4 字节(因为从第 0 个到第 9 个元素,中间间隔 9 个 int 元素,每个占 4 字节); - 元素个数:地址差 ÷ 元素类型大小 = (9×4)÷4 = 9。
- 地址差:
因此,printf 最终输出的结果是 9,即 &arr[9] 与 &arr[0] 之间有 9 个 int 类型的元素(从 arr[1] 到 arr[8],加上首尾本身,共 10 个元素,间隔 9 个)。
指针解引用
指针解引用时访问的内存空间大小
代码演示:
int a = 0x11223344;
int b = 0x11223344;int* pa = &a;
char* pc = &b;*pa = 0;
*pc = 0;printf("a = %x\n", a);
printf("b = %x\n", b);1. *pa 访问的空间:4 字节(int 类型大小)
pa 是 int* 类型指针(指向 int 变量 a)。解引用操作 *pa 时,会按照 int 类型的大小(通常 4 字节)访问内存—— 即从 a 的起始地址开始,连续操作 4 个字节的空间。
当执行 *pa = 0 时,会将 a 所占的全部 4 字节都赋值为 0(16 进制下为 00 00 00 00)。因此,a 的值被完整覆盖为 0,以 %x 打印时结果为 0。
2. *pc 访问的空间:1 字节(char 类型大小)
pc 是 char* 类型指针(指向 int 变量 b)。解引用操作 *pc 时,只会按照 char 类型的大小(1 字节)访问内存—— 即仅操作 b 起始地址处的 1 个字节,其他 3 个字节不受影响。
初始时 b = 0x11223344(假设内存按 “小端存储”,低地址存储低字节,即 4 个字节从低到高为 0x44、0x33、0x22、0x11)。执行 *pc = 0 时,仅将起始地址的第一个字节(0x44)改为 0,其余 3 个字节(0x33、0x22、0x11)保持不变。因此,b 的值变为 0x11223300,以 %x 打印时结果为 11223300。
核心结论
指针的类型决定了解引用时访问的内存空间大小:int* 解引用访问 4 字节,char* 解引用仅访问 1 字节。这种差异导致同样执行 “赋值 0” 操作,a 被完整清零,b 仅部分字节被修改,最终 16 进制打印结果不同。这也体现了 “指针类型不仅决定步长,还决定内存操作范围” 的核心特性。
二级指针
代码演示:
int a = 10;int* p = &a;
int** pp = &p;1. 一级指针变量 p:指向普通变量的地址
p 是一级指针变量,其类型为 int*(读作 “指向 int 的指针”)。它的核心作用是存储普通变量的内存地址—— 这里通过 &a(取 a 的地址)将 a 的内存地址赋值给 p,意味着 p 指向了变量 a。简单来说,一级指针是 “连接代码与普通数据” 的桥梁:通过 p 我们能找到 a 的地址,再通过解引用 *p 就能直接操作 a 的值(比如 *p = 20 会将 a 的值改为 20)。
2. 关键前提:指针本身也是变量,有自己的地址
很多人容易忽略一个核心事实:指针变量本质上也是 “变量”。和 a 一样,p 作为一级指针变量,在内存中同样会占据一块存储空间(例如在 32 位系统中,所有指针变量都占 4 字节,64 位系统占 8 字节),因此 p 自身也拥有一个独立的内存地址。正是因为指针变量有自己的地址,才为 “二级指针” 的存在提供了基础 —— 二级指针的作用,就是存储这个 “指针变量的地址”。
3. 二级指针变量 pp:指向一级指针变量的地址
pp 是二级指针变量,其类型为 int**(读作 “指向 int 指针的指针”)。它的核心作用与一级指针不同:不再存储普通变量的地址,而是专门存储一级指针变量的内存地址—— 这里通过 &p(取 p 的地址)将 p 的内存地址赋值给 pp,意味着 pp 指向了一级指针变量 p。可以理解为,二级指针是 “连接代码与一级指针” 的桥梁:通过 pp 能找到 p 的地址,再通过一次解引用 *pp 能得到 p 的值(即 a 的地址),若再解引用一次 **pp,就能最终操作 a 的值(比如 **pp = 30 会将 a 的值改为 30)。
指针数组
指针数组,核心是数组,但它的每个元素不是普通数据(如int、char),而是同类型的指针变量—— 简单说,这是一个 “专门用来存储指针的数组”。
代码演示:
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6,7 };
int arr3[] = { 3,4,5,6,7,8,9 };int sz[] = { sizeof(arr1) / sizeof(arr1[0]),sizeof(arr2) / sizeof(arr2[0]),sizeof(arr3) / sizeof(arr3[0]) };int* parr[] = { arr1,arr2,arr3 };int psz = (int)(sizeof(parr) / sizeof(parr[0]));for (int i = 0; i < psz; i++)
{for (int j = 0; j < sz[i]; j++){// printf("%d ", *(*(parr + i) + j));printf("%d ", parr[i][j]);}printf("\n");
}一、先明确:指针数组的本质
代码中的int* parr[]就是典型的指针数组:数组parr的每个元素都是int*类型(指向int的指针),专门存储arr1、arr2、arr3这三个普通int数组的首元素地址(数组名本身就是首元素地址),这是parr与三个子数组产生联动的基础。
二、重点解析嵌套 for 循环:parr 与子数组的联动逻辑
循环的核心是 “通过指针数组parr,统一遍历arr1、arr2、arr3三个子数组”,外层循环管理 “指向哪个子数组”,内层循环管理 “访问子数组的哪个元素”,二者通过parr的指针特性紧密联动,具体拆解如下:
1. 外层循环(i从 0 到psz-1):通过parr[i]定位子数组
psz是指针数组parr的元素个数(sizeof(parr)/sizeof(parr[0]),结果为 3,对应arr1、arr2、arr3三个子数组)。
- 当
i=0时,parr[i]即parr[0],存储的是arr1的首元素地址(parr[0] = arr1),此时parr[0]就相当于arr1的 “别名指针”,通过它能找到arr1的内存起始位置; - 当
i=1时,parr[1]存储arr2的首元素地址,通过它定位arr2; - 当
i=2时,parr[2]存储arr3的首元素地址,通过它定位arr3。
这一步是联动的关键:parr通过 “元素存储子数组首地址”,将三个独立的子数组 “串联” 起来,外层循环只需改变i,就能切换到不同的子数组,无需单独处理每个子数组的地址。
2. 内层循环(j从 0 到sz[i]-1):通过parr[i][j]访问子数组元素
sz[i]存储的是第i个子数组的元素个数(sz[0]=5对应arr1,sz[1]=6对应arr2,sz[2]=7对应arr3),内层循环负责遍历当前子数组的所有元素,核心是parr[i][j]这个表达式:
parr[i][j]本质是 “指针数组的下标访问 + 子数组的下标访问” 的结合,可拆解为(parr[i])[j]:① 先看parr[i]:它是parr数组的第i个元素,本质是一个int*类型的指针(指向第i个子数组的首地址);② 再看(parr[i])[j]:对 “parr[i]这个指针” 进行下标访问 —— 由于parr[i]指向int数组,(parr[i])[j]等价于*(parr[i] + j),意思是 “从parr[i]指向的首地址开始,向右偏移j个int类型的步长(每个步长 4 字节),然后解引用访问这个位置的元素”,也就是第i个子数组的第j个元素。
比如:
- 当
i=0、j=2时,parr[0][2]=(parr[0])[2]=*(arr1 + 2)=arr1[2],值为 3; - 当
i=1、j=4时,parr[1][4]=arr2[4],值为 6; - 当
i=2、j=5时,parr[2][5]=arr3[5],值为 8。
而注释中的*(*(parr + i) + j),是parr[i][j]的底层指针写法,二者完全等价(数组下标arr[k]本质是*(arr + k)),只是前者更直观,后者更体现 “指针操作” 的本质。
3. 联动性的最终表现:统一遍历多个子数组
通过parr的 “指针数组特性”,原本三个独立、长度不同的子数组(arr15 个元素、arr26 个、arr37 个),被纳入同一个嵌套循环中处理:外层循环通过parr[i]切换子数组,内层循环通过parr[i][j]访问子数组元素,最终依次打印出arr1、arr2、arr3的所有元素,实现了 “用一套逻辑管理多组数据” 的效果。