solidworks ppo 试做1
https://www.bilibili.com/video/BV15Qx5eREdJ
Search | DeepWiki

行为分是算行为执行之后的所有得分总和42.30
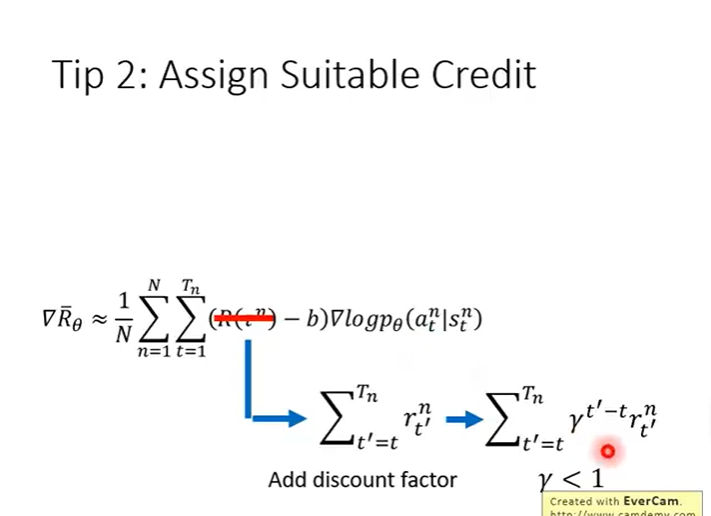
γ^(t‘-t)远处衰减
架构设计
state用截图后dinov3提取的特征
action 为画草图,画基准面,拉伸,放样
reward用当前截图的提取特征和输入图像的提取特征做余弦相似度
伪代码
import os
import random
import time
from dataclasses import dataclass
from typing import Optional import gymnasium as gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import tyro
from torch.distributions.categorical import Categorical
from torch.utils.tensorboard import SummaryWriter
from transformers import Dinov2Model, Dinov2Processor
from sklearn.metrics.pairwise import cosine_similarity
import cv2 @dataclass
class Args: exp_name: str = os.path.basename(__file__)[: -len(".py")] seed: int = 1 torch_deterministic: bool = True cuda: bool = True track: bool = False wandb_project_name: str = "cad-ppo" wandb_entity: Optional[str] = None capture_video: bool = False # Algorithm specific arguments total_timesteps: int = 500000 learning_rate: float = 2.5e-4 num_envs: int = 1 num_steps: int = 128 anneal_lr: bool = True gamma: float = 0.99 gae_lambda: float = 0.95 num_minibatches: int = 4 update_epochs: int = 4 norm_adv: bool = True clip_coef: float = 0.2 clip_vloss: bool = True ent_coef: float = 0.01 vf_coef: float = 0.5 max_grad_norm: float = 0.5 target_kl: Optional[float] = None # CAD specific arguments target_image_path: str = "target_design.png" def layer_init(layer, std=np.sqrt(2), bias_const=0.0): torch.nn.init.orthogonal_(layer.weight, std) torch.nn.init.constant_(layer.bias, bias_const) return layer class CADEnvironment: def __init__(self, target_image_path): # 加载DINOv3模型用于特征提取 self.dinov3_processor = Dinov2Processor.from_pretrained("facebook/dinov2-base") self.dinov3_model = Dinov2Model.from_pretrained("facebook/dinov2-base") # 加载目标图像并提取特征 self.target_image = cv2.imread(target_image_path) self.target_features = self._extract_features(self.target_image) # 动作空间:4个离散动作 self.action_space = gym.spaces.Discrete(4) # 画草图、画基准面、拉伸、放样 self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(768,), dtype=np.float32) def _extract_features(self, image): """使用DINOv3提取图像特征""" inputs = self.dinov3_processor(images=image, return_tensors="pt") with torch.no_grad(): outputs = self.dinov3_model(**inputs) return outputs.last_hidden_state.mean(dim=1).squeeze().numpy() def _calculate_reward(self, current_screenshot): """计算余弦相似度作为奖励""" current_features = self._extract_features(current_screenshot) similarity = cosine_similarity([current_features], [self.target_features])[0][0] return similarity def reset(self, seed=None): # 重置CAD环境到初始状态 self.reset_cad_environment() current_screenshot = self.capture_cad_screenshot() features = self._extract_features(current_screenshot) return features, {} def step(self, action): # 执行动作 self.execute_cad_action(action) # 获取新状态 current_screenshot = self.capture_cad_screenshot() features = self._extract_features(current_screenshot) # 计算奖励 reward = self._calculate_reward(current_screenshot) # 判断是否结束(可以根据相似度阈值或步数限制) done = reward > 0.95 or self.step_count > 100 truncated = False self.step_count += 1 return features, reward, done, truncated, {} def execute_cad_action(self, action_id): """执行具体的CAD操作 - 需要您根据具体CAD软件实现""" if action_id == 0: # 画草图 self.draw_sketch() elif action_id == 1: # 画基准面 self.create_reference_plane() elif action_id == 2: # 拉伸操作 self.perform_extrusion() elif action_id == 3: # 放样操作 self.perform_loft() def capture_cad_screenshot(self): """捕获CAD界面截图 - 需要您根据具体CAD软件实现""" # 示例:使用PIL或其他库截图 # screenshot = ImageGrab.grab() # return np.array(screenshot) pass def reset_cad_environment(self): """重置CAD环境到初始状态 - 需要您根据具体CAD软件实现""" self.step_count = 0 pass def draw_sketch(self): """画草图 - 需要您根据具体CAD软件实现""" pass def create_reference_plane(self): """画基准面 - 需要您根据具体CAD软件实现""" pass def perform_extrusion(self): """拉伸操作 - 需要您根据具体CAD软件实现""" pass def perform_loft(self): """放样操作 - 需要您根据具体CAD软件实现""" pass class CADAgent(nn.Module): def __init__(self, feature_dim=768): super().__init__() # 特征处理网络 self.feature_network = nn.Sequential( layer_init(nn.Linear(feature_dim, 512)), nn.ReLU(), layer_init(nn.Linear(512, 256)), nn.ReLU(), ) # 策略网络(4个动作:画草图、画基准面、拉伸、放样) self.actor = layer_init(nn.Linear(256, 4), std=0.01) # 价值网络 self.critic = layer_init(nn.Linear(256, 1), std=1) def get_value(self, x): hidden = self.feature_network(x) return self.critic(hidden) def get_action_and_value(self, x, action=None): hidden = self.feature_network(x) logits = self.actor(hidden) probs = Categorical(logits=logits) if action is None: action = probs.sample() return action, probs.log_prob(action), probs.entropy(), self.critic(hidden) if __name__ == "__main__": args = tyro.cli(Args) args.batch_size = int(args.num_envs * args.num_steps) args.minibatch_size = int(args.batch_size // args.num_minibatches) args.num_iterations = args.total_timesteps // args.batch_size run_name = f"{args.exp_name}__{args.seed}__{int(time.time())}" if args.track: import wandb wandb.init( project=args.wandb_project_name, entity=args.wandb_entity, sync_tensorboard=True, config=vars(args), name=run_name, monitor_gym=True, save_code=True, ) writer = SummaryWriter(f"runs/{run_name}") writer.add_text( "hyperparameters", "|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])), ) # 设置随机种子 random.seed(args.seed) np.random.seed(args.seed) torch.manual_seed(args.seed) torch.backends.cudnn.deterministic = args.torch_deterministic device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu") # 环境设置 env = CADEnvironment(args.target_image_path) # 智能体初始化 agent = CADAgent().to(device) optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5) # 存储空间设置 obs = torch.zeros((args.num_steps, args.num_envs, 768)).to(device) actions = torch.zeros((args.num_steps, args.num_envs)).to(device) logprobs = torch.zeros((args.num_steps, args.num_envs)).to(device) rewards = torch.zeros((args.num_steps, args.num_envs)).to(device) dones = torch.zeros((args.num_steps, args.num_envs)).to(device) values = torch.zeros((args.num_steps, args.num_envs)).to(device) # 开始训练 global_step = 0 start_time = time.time() next_obs, _ = env.reset(seed=args.seed) next_obs = torch.Tensor(next_obs).to(device).unsqueeze(0) next_done = torch.zeros(args.num_envs).to(device) for iteration in range(1, args.num_iterations + 1): # 学习率退火 if args.anneal_lr: frac = 1.0 - (iteration - 1.0) / args.num_iterations lrnow = frac * args.learning_rate optimizer.param_groups[0]["lr"] = lrnow for step in range(0, args.num_steps): global_step += args.num_envs obs[step] = next_obs dones[step] = next_done # 动作选择 with torch.no_grad(): action, logprob, _, value = agent.get_action_and_value(next_obs) values[step] = value.flatten() actions[step] = action logprobs[step] = logprob # 执行动作 next_obs_np, reward, termination, truncation, info = env.step(action.cpu().numpy()[0]) next_done_np = np.logical_or(termination, truncation) rewards[step] = torch.tensor([reward]).to(device).view(-1) next_obs, next_done = torch.Tensor(next_obs_np).to(device).unsqueeze(0), torch.Tensor([next_done_np]).to(device) if termination or truncation: print(f"global_step={global_step}, episodic_return={reward}") writer.add_scalar("charts/episodic_return", reward, global_step) next_obs, _ = env.reset() next_obs = torch.Tensor(next_obs).to(device).unsqueeze(0) # 计算优势函数 with torch.no_grad(): next_value = agent.get_value(next_obs).reshape(1, -1) advantages = torch.zeros_like(rewards).to(device) lastgaelam = 0 for t in reversed(range(args.num_steps)): if t == args.num_steps - 1: nextnonterminal = 1.0 - next_done nextvalues = next_value else: nextnonterminal = 1.0 - dones[t + 1] nextvalues = values[t + 1] delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t] advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam returns = advantages + values # 展平批次 b_obs = obs.reshape((-1, 768)) b_logprobs = logprobs.reshape(-1) b_actions = actions.reshape(-1) b_advantages = advantages.reshape(-1) b_returns = returns.reshape(-1) b_values = values.reshape(-1) # 优化策略和价值网络 b_inds = np.arange(args.batch_size) clipfracs = [] for epoch in range(args.update_epochs): np.random.shuffle(b_inds) for start in range(0, args.batch_size, args.minibatch_size): end = start + args.minibatch_size mb_inds = b_inds[start:end] _, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds]) logratio = newlogprob - b_logprobs[mb_inds] ratio = logratio.exp() with torch.no_grad(): old_approx_kl = (-logratio).mean() approx_kl = ((ratio - 1) - logratio).mean() clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()] mb_advantages = b_advantages[mb_inds] if args.norm_adv: mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8) # 策略损失 pg_loss1 = -mb_advantages * ratio pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef) pg_loss = torch.max(pg_loss1, pg_loss2).mean() # 价值损失 newvalue = newvalue.view(-1) if args.clip_vloss: v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2 b
我来帮你设计一个API框架,用于将DINOv3特征提取和基于余弦相似度的奖励机制集成到强化学习环境中。
API 设计概述
基于你的需求,我建议设计如下API组件:
1. 特征提取器接口
# feature_extractor.py
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import numpy as npclass DINOv3FeatureExtractor:def __init__(self, model_name="dinov3_vits14", device="cuda" if torch.cuda.is_available() else "cpu"):"""初始化DINOv3特征提取器"""self.device = device# 加载DINOv3模型self.model = torch.hub.load("facebookresearch/dinov3", model_name)self.model.to(self.device)self.model.eval()# 图像预处理self.transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def extract_features(self, image):"""从图像中提取DINOv3特征:param image: PIL图像或numpy数组:return: 特征向量"""if isinstance(image, np.ndarray):image = Image.fromarray(image)with torch.no_grad():transformed_image = self.transform(image).unsqueeze(0).to(self.device)features = self.model(transformed_image)return features.cpu().numpy().flatten()2. 自定义SolidWorks环境
# solidworks_env.py
import gymnasium as gym
import numpy as np
from typing import Optional, Dict, Any
from feature_extractor import DINOv3FeatureExtractorclass SolidWorksEnv(gym.Env):def __init__(self, target_image_path: str):"""初始化SolidWorks环境:param target_image_path: 目标图像路径"""super().__init__()# 动作空间:画草图,画基准面,拉伸,放样self.action_space = gym.spaces.Discrete(4)self.action_names = ["sketch", "reference_plane", "extrude", "loft"]# 观察空间:DINOv3特征向量self.feature_extractor = DINOv3FeatureExtractor()self.observation_space = gym.spaces.Box(low=-np.inf, high=np.inf, shape=(384,), # DINOv3 small模型的特征维度dtype=np.float32)# 加载目标图像并提取特征self.target_image_features = self.feature_extractor.extract_features(target_image_path)# 初始化环境状态self.current_state = Noneself.step_count = 0self.max_steps = 50 # 最大步数def reset(self, seed: Optional[int] = None, options: Optional[Dict[str, Any]] = None):"""重置环境"""super().reset(seed=seed)# 重置SolidWorks状态self._reset_solidworks()self.step_count = 0# 获取初始状态图像并提取特征initial_image = self._capture_screenshot()self.current_state = self.feature_extractor.extract_features(initial_image)return self.current_state, {}def step(self, action: int):"""执行动作:param action: 动作索引:return: (observation, reward, terminated, truncated, info)"""# 执行SolidWorks操作self._execute_solidworks_action(action)# 获取新状态图像并提取特征new_image = self._capture_screenshot()self.current_state = self.feature_extractor.extract_features(new_image)# 计算奖励reward = self._compute_reward(self.current_state)# 检查终止条件self.step_count += 1terminated = self._check_termination()truncated = self.step_count >= self.max_stepsinfo = {"action": self.action_names[action],"step": self.step_count}return self.current_state, reward, terminated, truncated, infodef _compute_reward(self, current_features):"""基于余弦相似度计算奖励:param current_features: 当前状态特征:return: 奖励值"""# 计算余弦相似度cos_sim = np.dot(current_features, self.target_image_features) / \(np.linalg.norm(current_features) * np.linalg.norm(self.target_image_features))return cos_simdef _reset_solidworks(self):"""重置SolidWorks环境"""# 这里需要实现与SolidWorks的交互逻辑passdef _execute_solidworks_action(self, action: int):"""在SolidWorks中执行动作:param action: 动作索引"""# 这里需要实现与SolidWorks的交互逻辑action_name = self.action_names[action]# 执行对应的操作passdef _capture_screenshot(self):"""捕获当前SolidWorks界面截图:return: 截图图像"""# 这里需要实现截图逻辑# 返回PIL图像或numpy数组passdef _check_termination(self):"""检查是否达到终止条件:return: 是否终止"""# 可以根据具体需求定义终止条件# 例如:达到足够高的相似度return False3. 强化学习代理适配器
# rl_adapter.py
import torch
import torch.nn as nn
from feature_extractor import DINOv3FeatureExtractorclass SolidWorksAgent(nn.Module):def __init__(self, feature_dim=384, action_dim=4):"""为SolidWorks环境设计的强化学习代理:param feature_dim: DINOv3特征维度:param action_dim: 动作空间维度"""super().__init__()self.feature_dim = feature_dimself.action_dim = action_dim# 策略网络self.actor = nn.Sequential(nn.Linear(feature_dim, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, action_dim),nn.Softmax(dim=-1))# 价值网络self.critic = nn.Sequential(nn.Linear(feature_dim, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 1))def get_action(self, features):"""根据特征选择动作:param features: DINOv3特征:return: 动作概率分布"""action_probs = self.actor(features)return action_probsdef get_value(self, features):"""评估状态价值:param features: DINOv3特征:return: 状态价值"""value = self.critic(features)return value4. 训练脚本示例
# train_solidworks.py
import gymnasium as gym
from solidworks_env import SolidWorksEnv
from rl_adapter import SolidWorksAgent
import torch.optim as optim
import torchdef train_agent():# 创建环境env = SolidWorksEnv(target_image_path="path/to/target/image.png")# 创建代理agent = SolidWorksAgent()optimizer = optim.Adam(agent.parameters(), lr=1e-4)# 训练循环num_episodes = 1000for episode in range(num_episodes):obs, _ = env.reset()done = Falsetotal_reward = 0while not done:# 选择动作obs_tensor = torch.FloatTensor(obs).unsqueeze(0)action_probs = agent.get_action(obs_tensor)action = torch.multinomial(action_probs, 1).item()# 执行动作next_obs, reward, terminated, truncated, _ = env.step(action)done = terminated or truncated# 计算损失并更新网络# 这里需要实现具体的PPO或其他RL算法逻辑obs = next_obstotal_reward += rewardprint(f"Episode {episode}, Total Reward: {total_reward}")if __name__ == "__main__":train_agent()主要组件说明
-
特征提取器 (
DINOv3FeatureExtractor):- 使用Facebook的DINOv3模型提取图像特征
- 支持从截图中提取特征向量
-
自定义环境 (
SolidWorksEnv):- 定义了4种动作空间:画草图、画基准面、拉伸、放样
- 使用DINOv3特征作为状态表示
- 基于余弦相似度计算奖励
-
强化学习代理 (
SolidWorksAgent):- 适配特征输入的神经网络结构
- 包含策略网络和价值网络
这个API设计允许你:
- 使用DINOv3提取SolidWorks界面截图特征
- 定义特定的CAD操作动作空间
- 基于目标图像与当前状态的相似度计算奖励
- 后续可以方便地集成到PPO等强化学习算法中