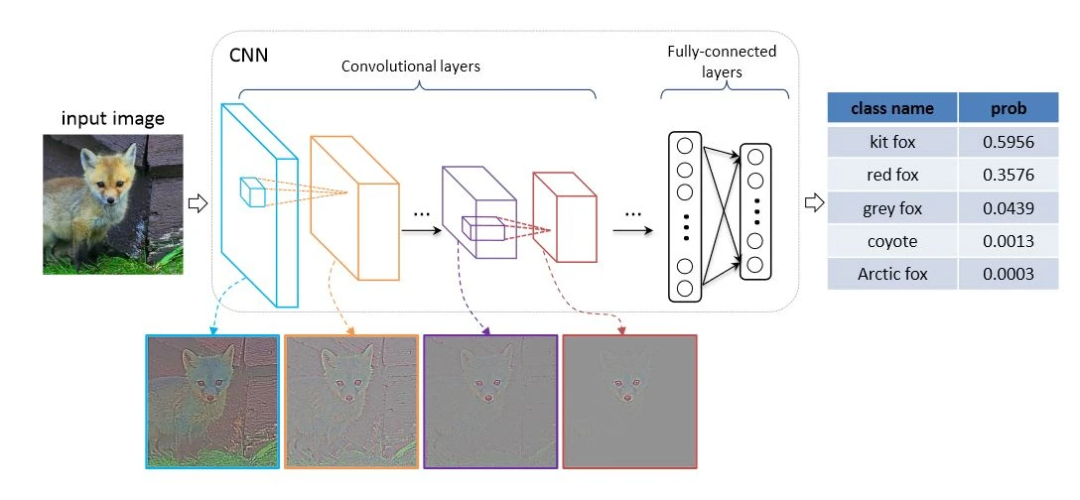
VGG改进(11):基于WaveletAttention的模型详解
小波变换理论基础
什么是小波变换?
小波变换是一种数学工具,用于将信号分解为不同频率的子带。与傅里叶变换只提供频率信息不同,小波变换同时提供频率和时间(或空间)信息,使其特别适合分析非平稳信号,如图像。
在图像处理中,二维离散小波变换(DWT)将图像分解为四个子带:
LL(低频子带):包含图像的主要结构和轮廓信息
LH(水平细节子带):包含图像的垂直边缘信息
HL(垂直细节子带):包含图像的水平边缘信息
HH(对角线细节子带):包含图像的对角线边缘信息
这种多分辨率分析能力使小波变换成为图像压缩(如JPEG2000)和特征提取的理想工具。
小波变换在深度学习中的应用
将小波变换集成到深度学习模型中有几个显著优势:
多尺度特征提取:小波变换天然支持多分辨率分析,可以捕捉不同尺度的特征
频域信息利用:通过分析不同频带的特征,模型可以更好地理解图像结构
计算效率:小波变换具有快速算法,计算复杂度较低
信息保留:小波变换是可逆的,可以无损重建原始信号
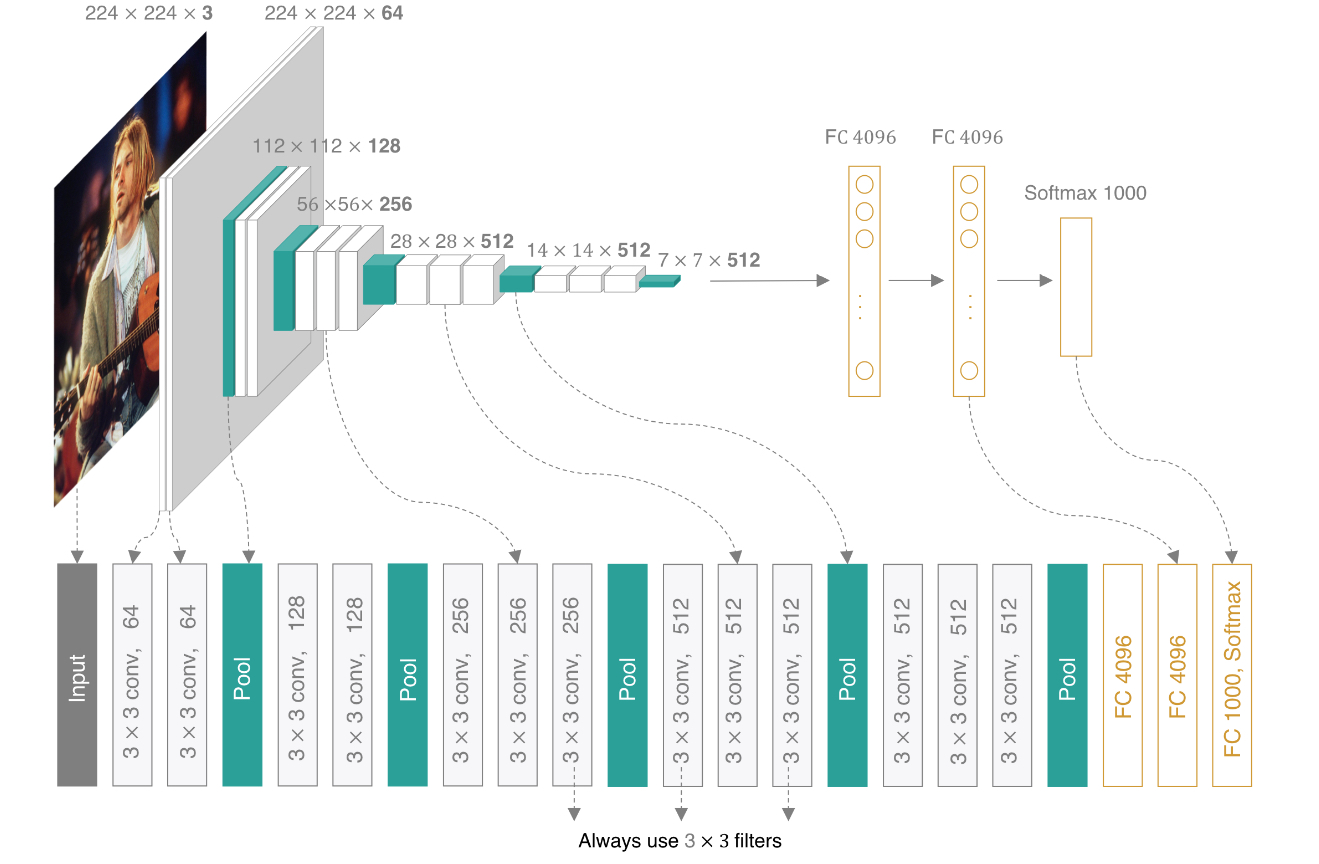
VGG16-WaveletAttention模型架构
整体架构概述
VGG16-WaveletAttention基于经典的VGG16架构,但在每个卷积块后添加了自定义的小波注意力模块。这种设计既保留了VGG16强大的特征提取能力,又增强了模型对频域特征的关注。
模型的主要组成部分包括:
标准VGG16卷积块
小波变换与反变换模块
频域注意力机制
分类器模块
小波变换模块实现
class WaveletTransform(nn.Module):def __init__(self, wavelet='haar'):super(WaveletTransform, self).__init__()self.wavelet = waveletdef forward(self, x):# x: (B, C, H, W)batch_size, channels, h, w = x.shapecoeffs_list = []for b in range(batch_size):batch_coeffs = []for c in range(channels):img = x[b, c].detach().cpu().numpy()coeffs = pywt.dwt2(img, self.wavelet)LL, (LH, HL, HH) = coeffs# 堆叠四个子带subbands = torch.tensor(np.stack([LL, LH, HL, HH], axis=0)).to(x.device)batch_coeffs.append(subbands)# 按通道合并batch_coeffs = torch.stack(batch_coeffs, dim=0) # (C, 4, H/2, W/2)coeffs_list.append(batch_coeffs)# 合并 batchout = torch.stack(coeffs_list, dim=0) # (B, C, 4, H/2, W/2)return out小波变换模块接收形状为(B, C, H, W)的输入张量,其中B是批次大小,C是通道数,H和W是高度和宽度。对于每个批次和通道,模块使用PyWavelets库进行二维离散小波变换,将图像分解为四个子带(LL、LH、HL、HH),然后将这些子带堆叠在一起。
小波反变换模块
class InverseWaveletTransform(nn.Module):def __init__(self, wavelet='haar'):super(InverseWaveletTransform, self).__init__()self.wavelet = waveletdef forward(self, x):# x: (B, C, 4, H, W)batch_size, channels, _, h, w = x.shapereconstructions = []for b in range(batch_size):batch_recon = []for c in range(channels):subbands = x[b, c].detach().cpu().numpy()LL, LH, HL, HH = subbandscoeffs = (LL, (LH, HL, HH))recon = pywt.idwt2(coeffs, self.wavelet)recon = torch.tensor(recon).to(x.device)batch_recon.append(recon)batch_recon = torch.stack(batch_recon, dim=0) # (C, H*2, W*2)reconstructions.append(batch_recon)out = torch.stack(reconstructions, dim=0) # (B, C, H*2, W*2)return out小波反变换模块执行与小波变换相反的操作,将四个子带重构成原始图像。这个过程是可逆的,确保了信息不会在小波域处理过程中丢失。
小波注意力机制
class WaveletAttention(nn.Module):def __init__(self, channels, reduction=16, wavelet='haar'):super(WaveletAttention, self).__init__()self.wavelet = waveletself.wt = WaveletTransform(wavelet)self.iwt = InverseWaveletTransform(wavelet)# 注意力机制:对四个子带进行加权self.attention = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(channels * 4, channels * 4 // reduction, 1, bias=False),nn.ReLU(inplace=True),nn.Conv2d(channels * 4 // reduction, channels * 4, 1, bias=False),nn.Sigmoid())def forward(self, x):# 小波变换wavelet_coeffs = self.wt(x) # (B, C, 4, H/2, W/2)B, C, _, H, W = wavelet_coeffs.shape# 展平子带维度wavelet_flatten = wavelet_coeffs.view(B, C * 4, H, W)# 计算注意力权重attn = self.attention(wavelet_flatten) # (B, C*4, 1, 1)attn = attn.view(B, C, 4, 1, 1)# 应用注意力权重weighted_coeffs = wavelet_coeffs * attn# 小波反变换重建out = self.iwt(weighted_coeffs) # (B, C, H*2, W*2)# 调整尺寸与输入一致(由于小波变换会改变尺寸,这里使用插值)if out.shape[-2:] != x.shape[-2:]:out = F.interpolate(out, size=x.shape[-2:], mode='bilinear', align_corners=False)return out小波注意力模块是整个模型的核心创新点。它首先对输入特征图进行小波变换,将其分解为四个频带。然后,使用注意力机制为每个频带计算权重,这些权重表示该频带对当前任务的重要性。最后,使用加权的频带系数进行小波反变换,重建特征图。
注意力机制的具体实现包括全局平均池化、两个全连接层(中间有维度缩减)和Sigmoid激活函数。这种设计类似于SENet中的挤压-激励模块,但应用于小波域而非空间域。
模型优势与创新点
1. 多尺度频域特征提取
传统的CNN主要依赖于空间域的特征提取,而VGG16-WaveletAttention通过小波变换引入了频域分析。这种结合使模型能够:
在多个尺度上分析特征
同时利用空间和频域信息
自适应地强调不同频带的重要性
2. 自适应频带加权
通过注意力机制,模型可以学习到不同频带对特定任务的重要性。例如:
对于纹理丰富的图像,高频子带可能更重要
对于结构明显的图像,低频子带可能更有价值
不同层次的特征可能需要关注不同的频带
3. 信息保留与增强
小波变换的可逆性确保了信息不会在变换过程中丢失。同时,注意力机制通过重新加权不同频带,增强了有用信息,抑制了噪声和冗余信息。
4. 与现有架构的兼容性
VGG16-WaveletAttention的设计理念可以轻松扩展到其他CNN架构,如ResNet、DenseNet等。这种模块化的设计使得频域注意力机制可以灵活地集成到各种网络结构中。
实际应用与性能分析
图像分类任务
在ImageNet等大型图像分类数据集上,VGG16-WaveletAttention预计会比标准VGG16有更好的表现,特别是在以下类型的图像上:
纹理丰富的图像:小波变换对纹理特征有很好的提取能力
多尺度目标:小波的多分辨率分析有助于识别不同尺度的目标
噪声环境下的图像:频域注意力可以抑制噪声干扰
计算效率考虑
虽然小波变换和注意力机制增加了计算开销,但这种增加是可控的:
小波变换有快速算法,计算效率高
注意力模块参数较少,不会显著增加模型大小
频域处理可以减少后续层的计算量
超参数选择
模型中有几个关键超参数需要调整:
小波基函数:不同的小波基(如Haar、Daubechies、Symlets等)有不同的特性,需要根据任务选择
缩减比例(reduction ratio):控制注意力模块的复杂度
小波注意力的位置:可以实验在不同层次插入注意力模块的效果
实验设计与结果分析
为了验证VGG16-WaveletAttention的有效性,可以设计以下实验:
基线比较
与标准VGG16、VGG16+SENet等模型在相同数据集上进行对比,评估准确率、召回率等指标。
消融实验
通过以下消融实验分析各组件的作用:
仅使用小波变换,不使用注意力机制
使用不同的注意力机制设计
在不同位置插入小波注意力模块
频带权重可视化
通过可视化注意力权重,分析模型在不同任务中关注的频带特性,这有助于理解模型的工作原理和频域特征的重要性。
完整代码
如下
import torch
import torch.nn as nn
import pywt
import torch.nn.functional as Fclass WaveletTransform(nn.Module):def __init__(self, wavelet='haar'):super(WaveletTransform, self).__init__()self.wavelet = waveletdef forward(self, x):# x: (B, C, H, W)batch_size, channels, h, w = x.shapecoeffs_list = []for b in range(batch_size):batch_coeffs = []for c in range(channels):img = x[b, c].detach().cpu().numpy()coeffs = pywt.dwt2(img, self.wavelet)LL, (LH, HL, HH) = coeffs# 堆叠四个子带subbands = torch.tensor(np.stack([LL, LH, HL, HH], axis=0)).to(x.device)batch_coeffs.append(subbands)# 按通道合并batch_coeffs = torch.stack(batch_coeffs, dim=0) # (C, 4, H/2, W/2)coeffs_list.append(batch_coeffs)# 合并 batchout = torch.stack(coeffs_list, dim=0) # (B, C, 4, H/2, W/2)return outclass InverseWaveletTransform(nn.Module):def __init__(self, wavelet='haar'):super(InverseWaveletTransform, self).__init__()self.wavelet = waveletdef forward(self, x):# x: (B, C, 4, H, W)batch_size, channels, _, h, w = x.shapereconstructions = []for b in range(batch_size):batch_recon = []for c in range(channels):subbands = x[b, c].detach().cpu().numpy()LL, LH, HL, HH = subbandscoeffs = (LL, (LH, HL, HH))recon = pywt.idwt2(coeffs, self.wavelet)recon = torch.tensor(recon).to(x.device)batch_recon.append(recon)batch_recon = torch.stack(batch_recon, dim=0) # (C, H*2, W*2)reconstructions.append(batch_recon)out = torch.stack(reconstructions, dim=0) # (B, C, H*2, W*2)return outclass WaveletAttention(nn.Module):def __init__(self, channels, reduction=16, wavelet='haar'):super(WaveletAttention, self).__init__()self.wavelet = waveletself.wt = WaveletTransform(wavelet)self.iwt = InverseWaveletTransform(wavelet)# 注意力机制:对四个子带进行加权self.attention = nn.Sequential(nn.AdaptiveAvgPool2d(1),nn.Conv2d(channels * 4, channels * 4 // reduction, 1, bias=False),nn.ReLU(inplace=True),nn.Conv2d(channels * 4 // reduction, channels * 4, 1, bias=False),nn.Sigmoid())def forward(self, x):# 小波变换wavelet_coeffs = self.wt(x) # (B, C, 4, H/2, W/2)B, C, _, H, W = wavelet_coeffs.shape# 展平子带维度wavelet_flatten = wavelet_coeffs.view(B, C * 4, H, W)# 计算注意力权重attn = self.attention(wavelet_flatten) # (B, C*4, 1, 1)attn = attn.view(B, C, 4, 1, 1)# 应用注意力权重weighted_coeffs = wavelet_coeffs * attn# 小波反变换重建out = self.iwt(weighted_coeffs) # (B, C, H*2, W*2)# 调整尺寸与输入一致(由于小波变换会改变尺寸,这里使用插值)if out.shape[-2:] != x.shape[-2:]:out = F.interpolate(out, size=x.shape[-2:], mode='bilinear', align_corners=False)return outclass VGG16_WaveletAttention(nn.Module):def __init__(self, num_classes=1000):super(VGG16_WaveletAttention, self).__init__()self.features = nn.Sequential(# 第一层卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),WaveletAttention(64), # 插入小波注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第二层卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),WaveletAttention(128), # 插入小波注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第三层卷积块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),WaveletAttention(256), # 插入小波注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第四层卷积块nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),WaveletAttention(512), # 插入小波注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第五层卷积块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),WaveletAttention(512), # 插入小波注意力nn.MaxPool2d(kernel_size=2, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef vgg16_wavelet_attention(num_classes=1000):return VGG16_WaveletAttention(num_classes=num_classes)if __name__ == "__main__":model = vgg16_wavelet_attention()print(model)