VLMs距离空间智能还有多远的路要走?
VLMs距离空间智能还有多远的路要走?
- 省流不看版本:
- 我们的出发点:
- 方法和任务的梳理:
- 系列测评:
- 写在最后:

省流不看版本:
1.详细梳理了在视觉空间推理任务上的方法,包括多模态信息融合,模型结构,训练方式以及推理策略;
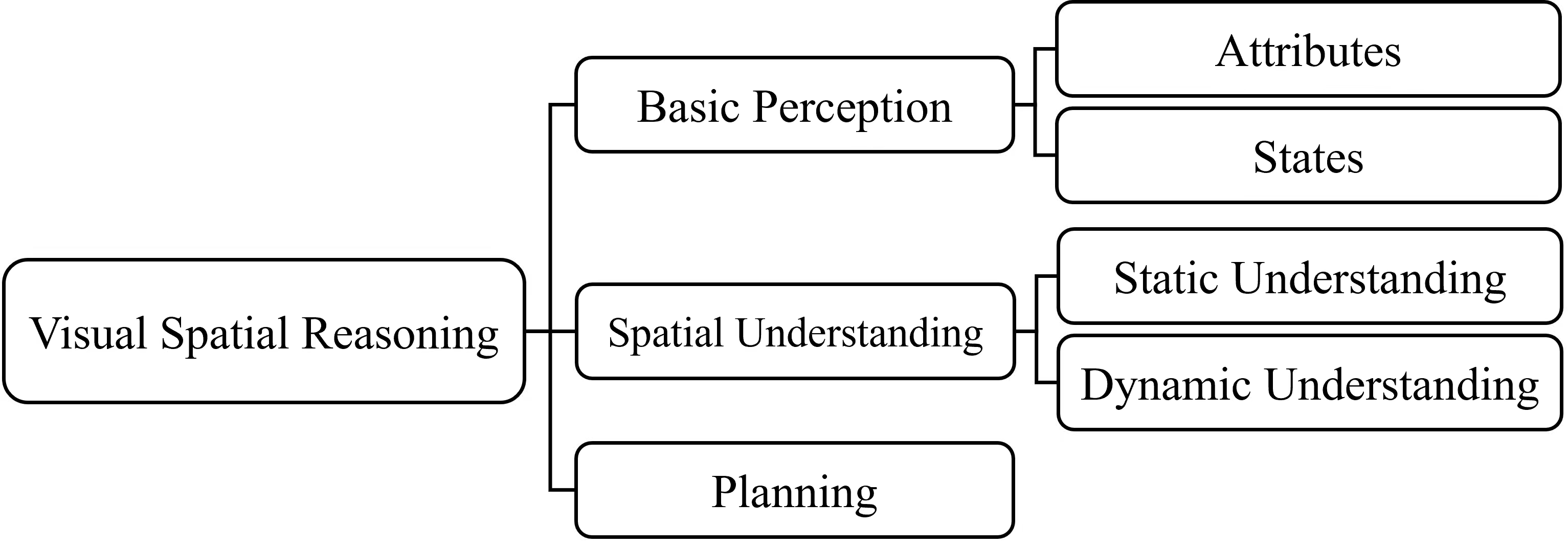
2.对现有的空间推理任务进行分层次整理和介绍,包括基础感知,空间理解,以及规划;
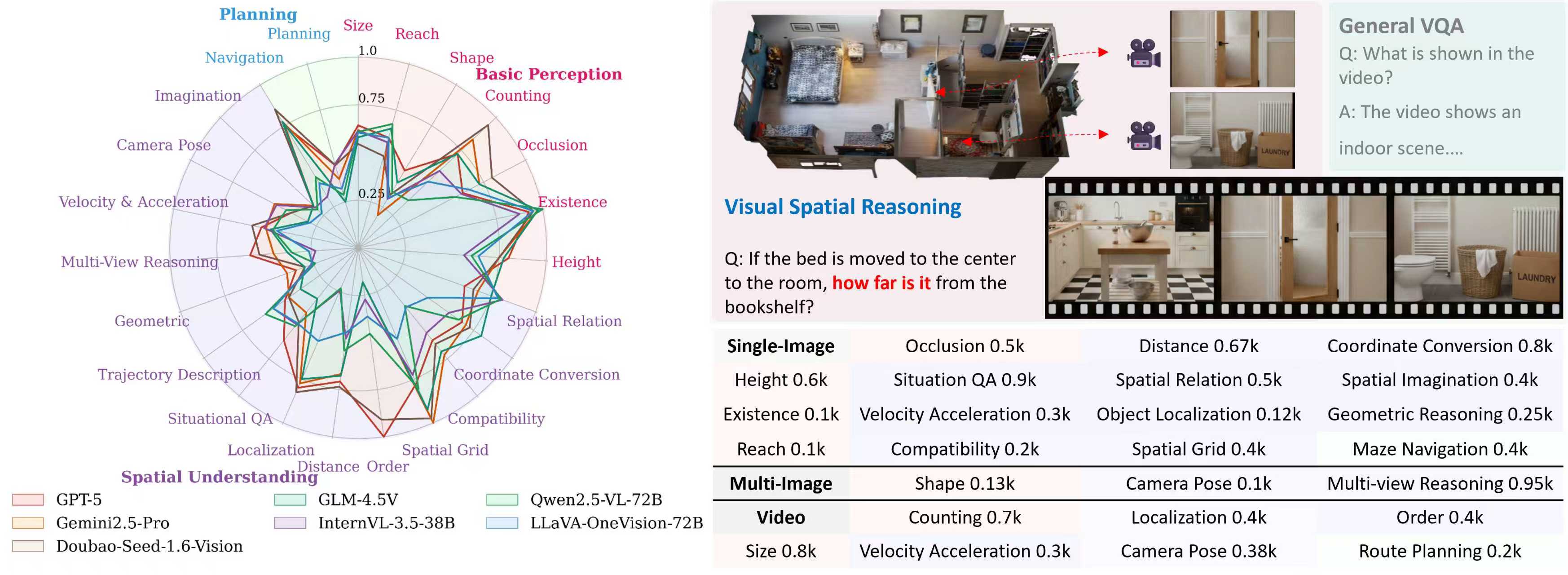
3.整理了一个较为全面的测试基准 SIBench,涵盖23种任务设定(来源于近20个开源Benchmark ),
包含三种输入类型,三种问题类型;
👉👉关注我们的leaderboard
👉👉使用我们的测评工具
👉👉浏览论文更多细节
👉👉空间推理的论文集锦
我们的出发点:
VLM的空间推理能力在自动驾驶,具身应用中至关重要,近期也得到了社区的广泛关注,越来越多的工作从不同的方面对空间推理能力进行测评,从而出现了各种各样的任务设定。我们希望通过对这些工作做一个系统性的回顾,对改进方法,空间推理任务进行梳理,方便社区未来的研究。另外,现有的测评基准都集中于几个任务设定,缺少一个比较全面且方便的测评工具,于是我们收集了18个开源benchmark,并对其中的数据进行了筛选,最终组成了SIBench。
通过系列的测评,我们希望能够一定程度上回答这样一个问题:距离空间智能,我们到底还有多远?
方法和任务的梳理:
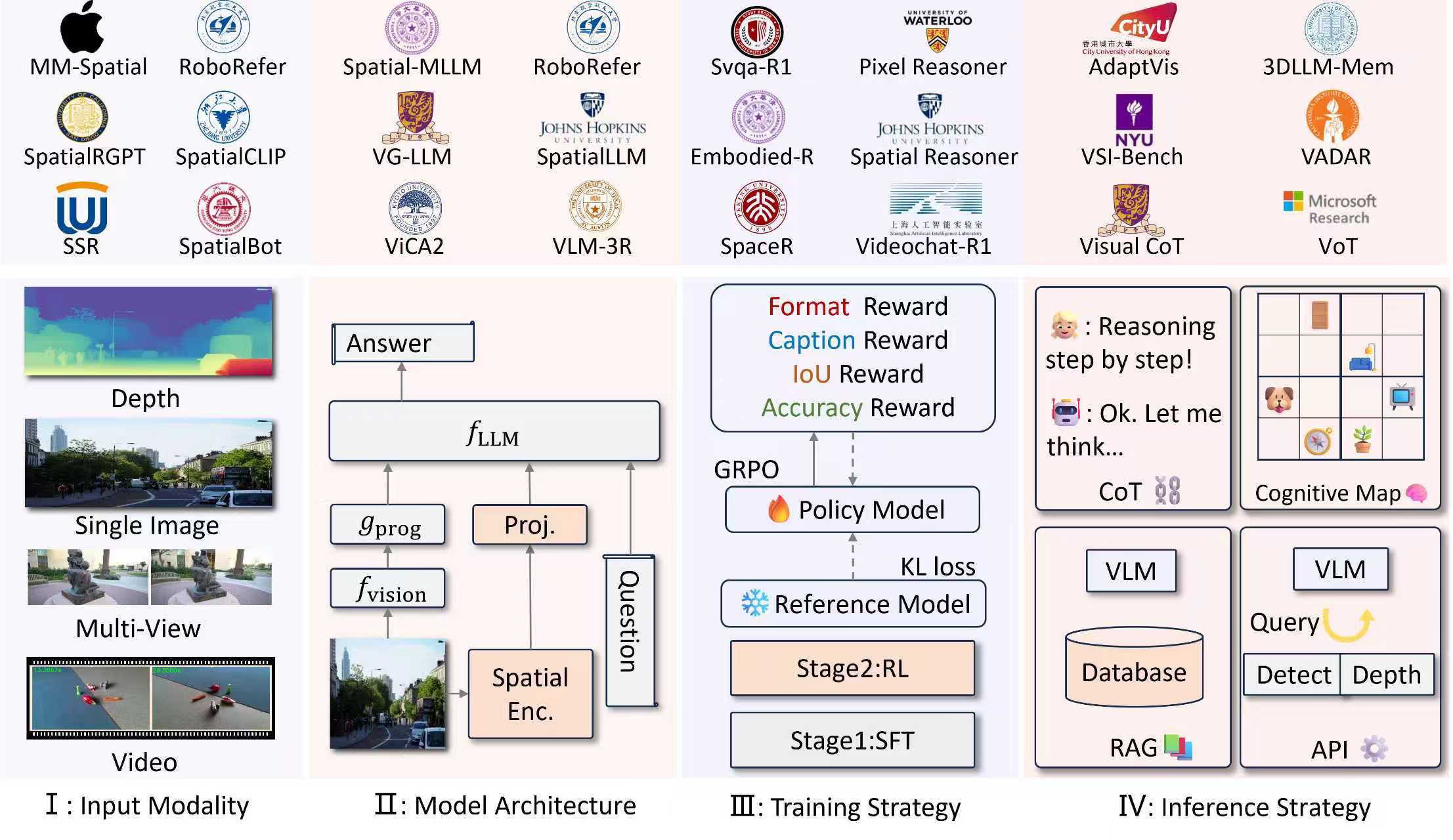
图2:对于方法,我们从输入模态,模型的结构,训练方式,以及推理策略进行了梳理。对于视觉空间推理任务而言,难点之一在于从2D的输入中恢复投影前的3D结构,里面许多工作围绕着一点展开。
图3:对于任务设定,按照推理的层次,我们将其划分为基础感知,空间理解,以及规划。
具体来说,基础感知只涉及某一个或某一类目标的属性,比如目标的大小,高度,状态等;
空间理解涉及两个目标以上,或者目标和环境之间的关系,比如距离,相对位置等;
规划则是在空间约束下,找寻满意解决方案。
系列测评:
经过初步的调研,发现其实有大概四五十个开源benchmark与空间推理任务相关,我们对任务设定的合理性,数据质量进行了评估,最终选择了近20个开源benchmark进行进一步的整合(剔除了一些类似于Visual Puzzles的数据,非视觉的输入,非人工标注的数据),得到了一个较为全面的测评基准,SIBench。
对许多模型进行了评测,比如GPT-5,Gemni2.5-Pro,Doubao-seed-1.6-Vision等等。实验数据欢迎查看我们的论文,以及项目页。基本的缺陷大概如下:
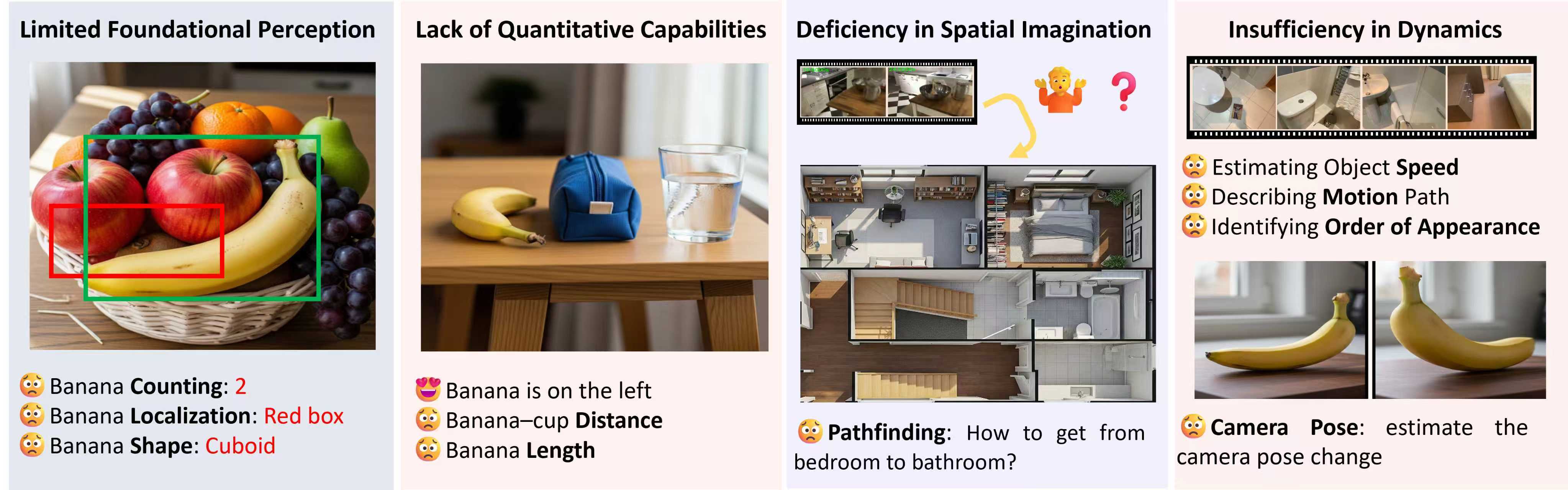
1.基础感知能力仍然有限,比如形状,目标的定位,计数等等。我们认为,即便许多模型已经取得了不错的效果,但是基础感知能力作为空间推理的基础,是累计误差最根源的一环,远未达到理想的水平。
2.量化推理能力不足,比如高度,距离等。由于尺度不明确,从单纯的视觉输入去估计这些数据本身是一件比较困难的事,或许应该寻求更有效的方法。
3.动态信息的处理能力弱,比如估计相机视角的变化,多视角推理,路径的描述等。这部分的难点一方面来自于从不同的视角理解视觉线索的差异以及共同点,从而构建对真实3D世界的理解;另一方面来自于对时序信息的理解不够充分。
4.空间想象能力的缺失。
写在最后:
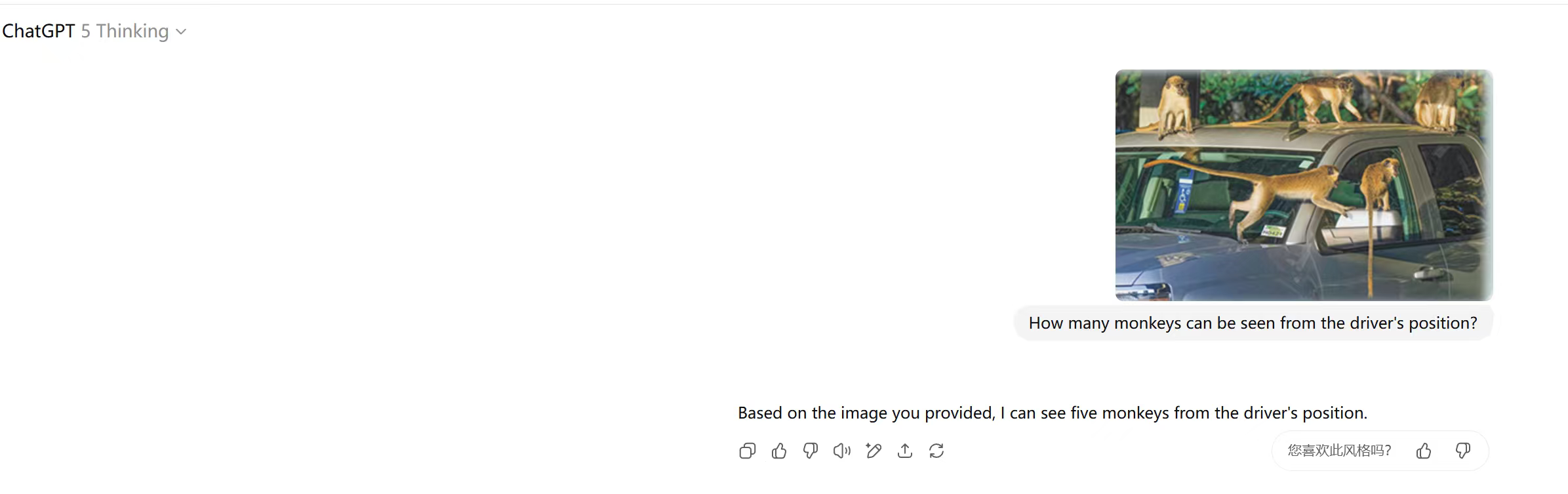
完成这个课题,最大的感受其实是VLMs对于空间想象能力的严重缺失。具体而言,VLMs更擅长直接从图中读取问题相关的信息,我们暂且称之为事实查询类问题。而对于真实答案和提供的视觉线索稍有出入的问题,比如perspective taking(切换一个参考系回答问题),模型的表现就非常糟糕。
最后提供了一个有趣的例子,我们称之为数猴难题,博君一乐,欢迎大家讨论为什么VLMs对于这种需要空间想象的问题,或者说反事实推理问题,表现不尽人意呢?