一文读懂:大模型RAG(检索增强生成)
什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种让大语言模型(LLM)实时利用外部知识库的技术方案。
核心思想:
在用户提问时,系统先从外部知识库中检索到相关内容,然后把检索到的内容+用户问题一起输入模型,由模型生成最终答案。
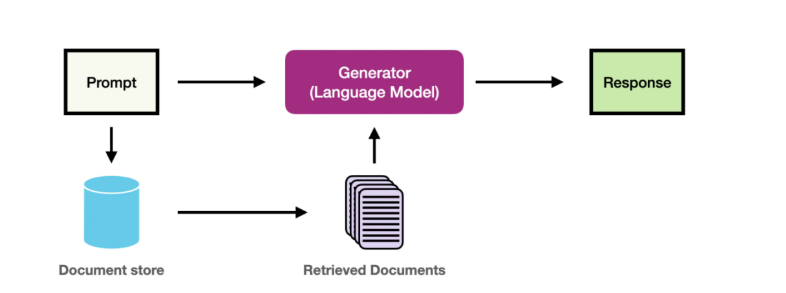
RAG的作用
有了通用LLM为什么还需要RAG,主要是以下几个方面:
知识的局限性:LLM的知识来源于训练数据,而训练数据有一个截止时间,模型训练完成后,它对新事件、新技术、新法规等信息一无所知。
幻觉问题:模型会在缺乏知识或遇到不确定问题时,编造貌似合理但错误的答。这是因为LLM本质上是语言概率模型,它会生成最可能的词,并不保证内容真实。
领域知识不足:LLM是个全量知识库,所以如果我们想模型扮演一个专业领域的角色,那么就需要专业领域的知识,这种垂直领域的需求通用LLM无法满足。
模型更新成本高:如果我们想做垂直领域的智能体,就需要给模型灌输一些专业领域的知识,可以通过模型微调的方式,但是这种方式成本太高,计算量太大。
隐私性问题:如果用户直接把敏感资料(公司文档、机密数据)输入到云端 LLM,存在数据泄露风险
🔧 为什么 RAG 是解决方案
RAG 在这些问题上提供了解决思路:
时效性:知识库可随时更新,无需重新训练模型。
上下文扩展:检索到相关文档后再传给模型,绕过窗口限制。
降低幻觉:模型基于真实文档生成答案,减少编造。
行业定制:直接接入企业内部资料,快速适配专业领域。
安全合规:知识库可以私有化部署,数据不出企业内网。
RAG使用原理
RAG 可以看作是两个模块的协同工作:
检索模块(Retriever):从外部知识库中找出与用户问题最相关的文档片段。
生成模块(Generator):将检索结果与用户问题一起作为输入,交给 LLM(如 GPT、LLaMA)生成最终回答。
🔹 形象比喻:
LLM = 一个“聪明的作家”,擅长写作但不一定知道最新知识。
检索模块 = 一个“图书管理员”,负责从资料库里找出最相关的资料。
RAG = 作家写作前先问图书管理员拿到资料,再写文章。
一句话总结:
RAG(中文为检索增强生成) = 检索技术 + LLM 提示。
当用户给模型输入一个问题(question),模型首先会去搜索各种数据源,也就是外部知识库,搜索到符合要求的topk内容(文档或者具体内容)。然后将用户的问题和搜索到的内容一起作为prompt传给模型,这样模型回到的时候就有知识库这方面的内容可以借鉴,最终给出符合要求的回答(answer)
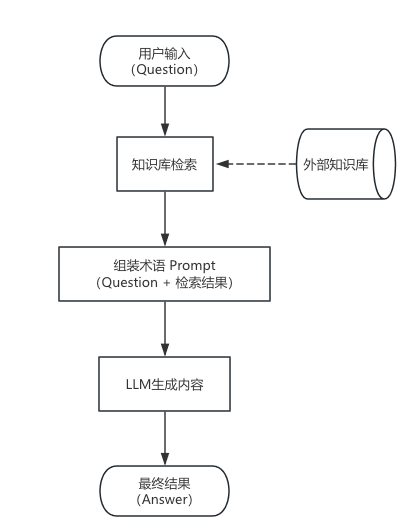
RAG 的工作原理(详细分解)
RAG 的工作可分为两个阶段:
1️⃣ 离线阶段:构建知识库,这个一般是使用向量数据库,将知识库的内容初始化到数据库中
2️⃣ 在线阶段:用户提问 -> 检索 -> 生成
(1)离线阶段:构建知识库
数据收集
来源:PDF、网页、数据库、API、日志文件等。
文本切分
长文档拆分成小段落(chunk),避免超出模型输入长度。
例如:每段 500~1000 字。
向量化(Embedding)
使用文本向量模型(例如
sentence-transformers、OpenAI Embeddings、BGE)将每段文本转换为高维向量(例如 768 维的浮点数数组)。这些向量可以表示文本语义。
存储到向量数据库
典型数据库:FAISS、Milvus、Pinecone、Weaviate、Elasticsearch(向量索引)。
数据库保存文本+向量,方便后续相似度检索。
(2)在线阶段:检索+生成
当用户提出问题时:
用户输入
用户问:“华为 ADS 4 的主要新功能是什么?”
向量化问题
将问题转换成向量。
向量检索
在向量数据库中检索与问题最接近的文档片段。
例如检索到 5 段最相关的资料。
构建 Prompt
将System Prompt(系统指令)+用户问题+检索到的文档拼接成一个输入。
例如:
你是一个华为汽车专家,请根据以下资料回答用户问题: [资料1]... [资料2]... 用户问题:华为 ADS 4 的主要新功能是什么?
生成回答
LLM 根据真实资料生成最终答案。
模型可以引用检索内容,降低幻觉风险。