MIT 6.S081 文件系统的基本结构 (Lab10:File system)
目录
文件系统
文件系统层次
底层物理层的实现
buffer cache(块缓存) VS icache(inode缓存)
块的分布情况
inode
目录
XV6文件系统的实践
实验Lab
Large files
Symbolic links
实验总结
文件系统
文件系统层次
从宏观上而言,文件系统的分布如下图所示,最底层是实际的物理disk以及其驱动程序,上方是buf cache,缓存区缓存,用于对物理块的缓存,再上方是日志logging,之后是icache,将最近使用的inode信息缓存到内存中,提升文件系统的效率,也方便对同一物理块的不同inode节点统一写回,在上方就是inode数据结构,和文件一一对应,在上方就是应用层的文件名和文件描述符。
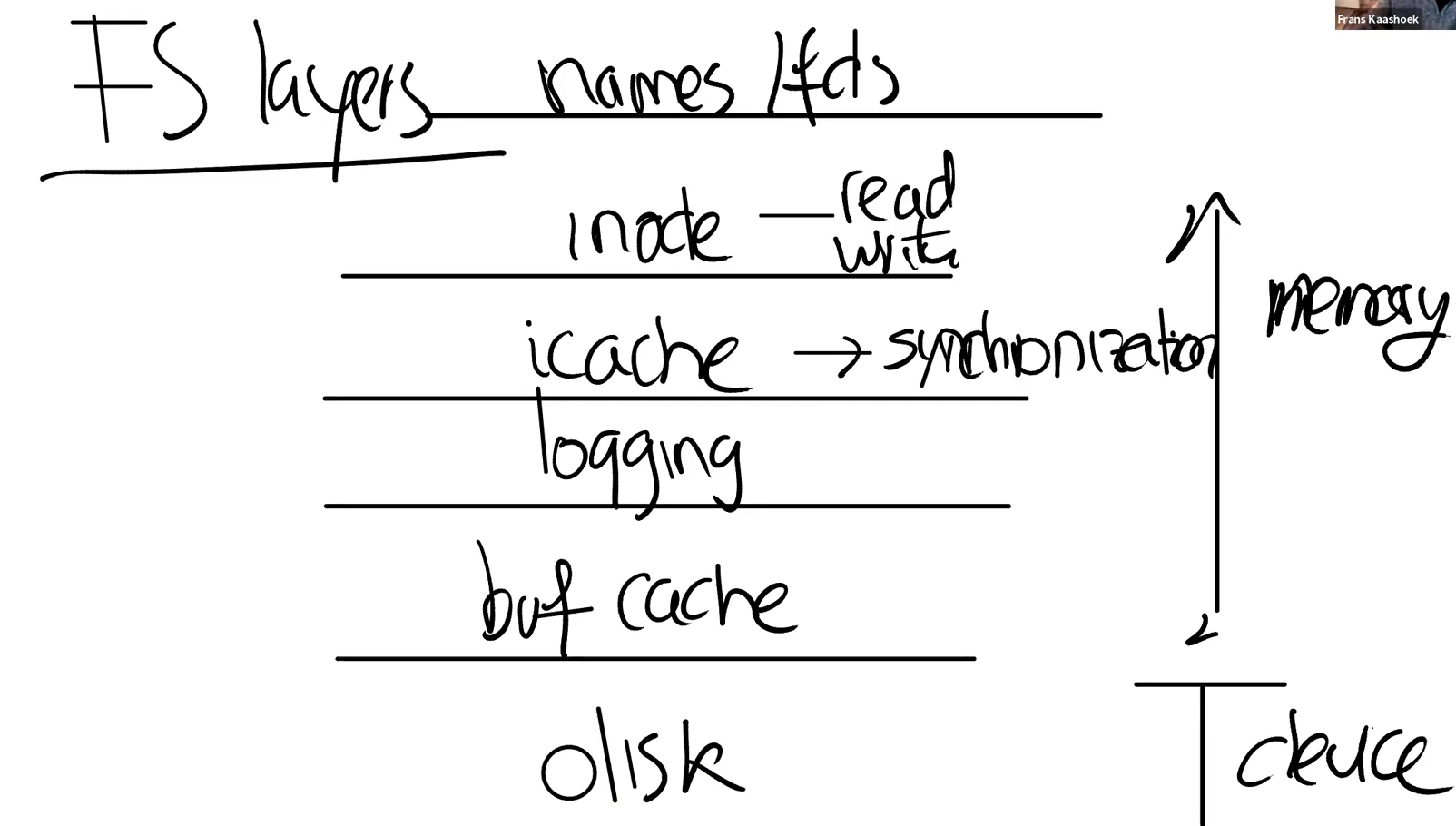
底层物理层的实现
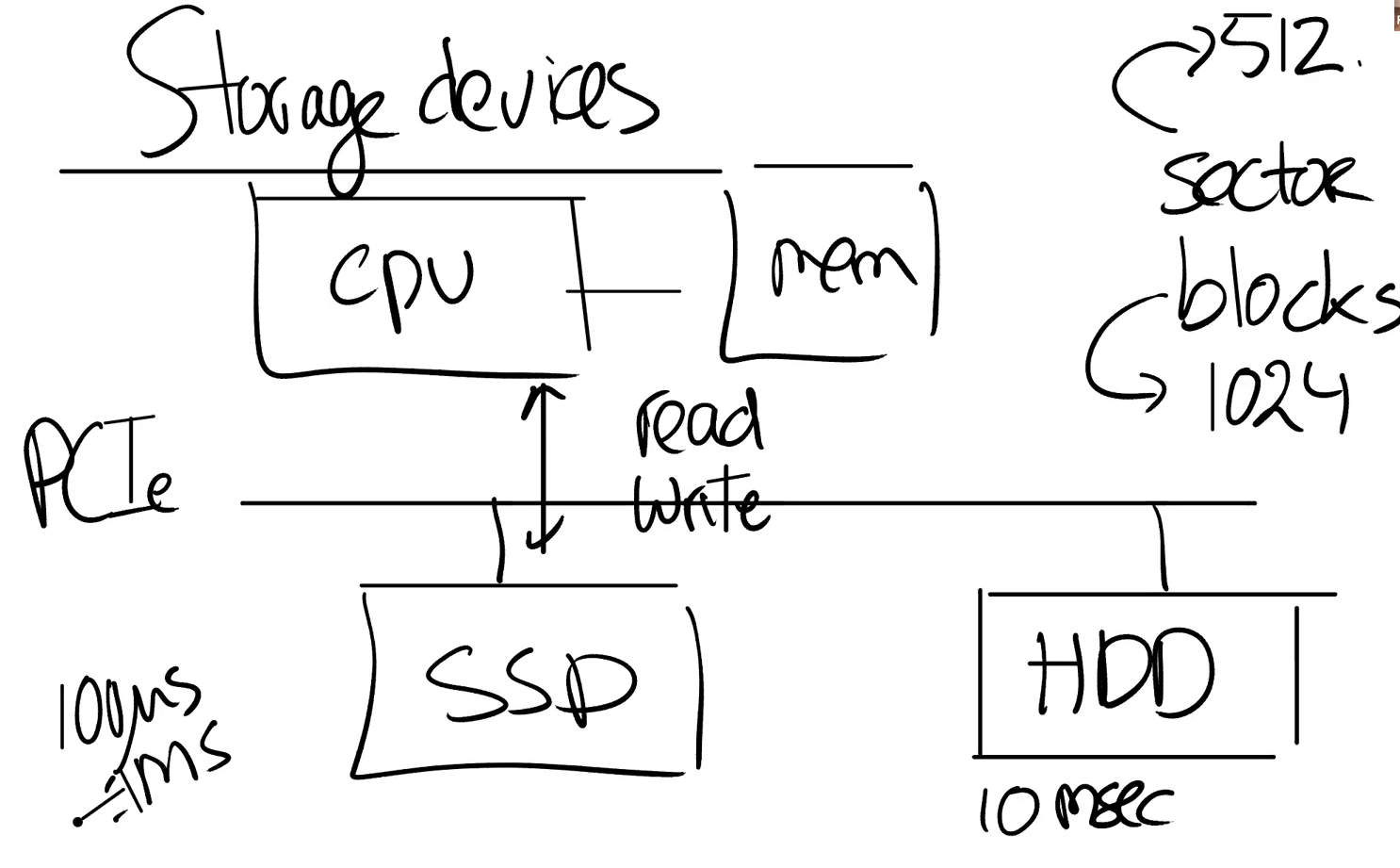
如下图所示,底层存储设备包括SSD(机械硬盘)和HDD(固态硬盘),这些设备连接在主板上,通过总线和CPU,内存等联通,通过PCI或PCIe协议进行通信。在物理设备上的最小单位通常称为扇区,常见的扇区大小为512B,但在操作系统或文件系统中最小使用单位为块,一个块通常为几个扇区(例如XV6中块大小为1024B,为2个扇区)。CPU和磁盘的通信也是根据块编号进行读写通信的。
buffer cache(块缓存) VS icache(inode缓存)
日志记录不必多说,接下来是两个缓存,块缓存是对物理硬盘上的块(无论是数据块还是inode所在的索引块)进行缓存,inode缓存是对实实在在的inode进行缓存。两者位于不同的层次,inode节点重点在于提供文件信息以及提供文件数据所在的位置,而块缓存实际上更多的是物理的扇区到操作系统的块之间的一种抽象。两者都能极大的提升文件系统的效率,但所在的层次不同。
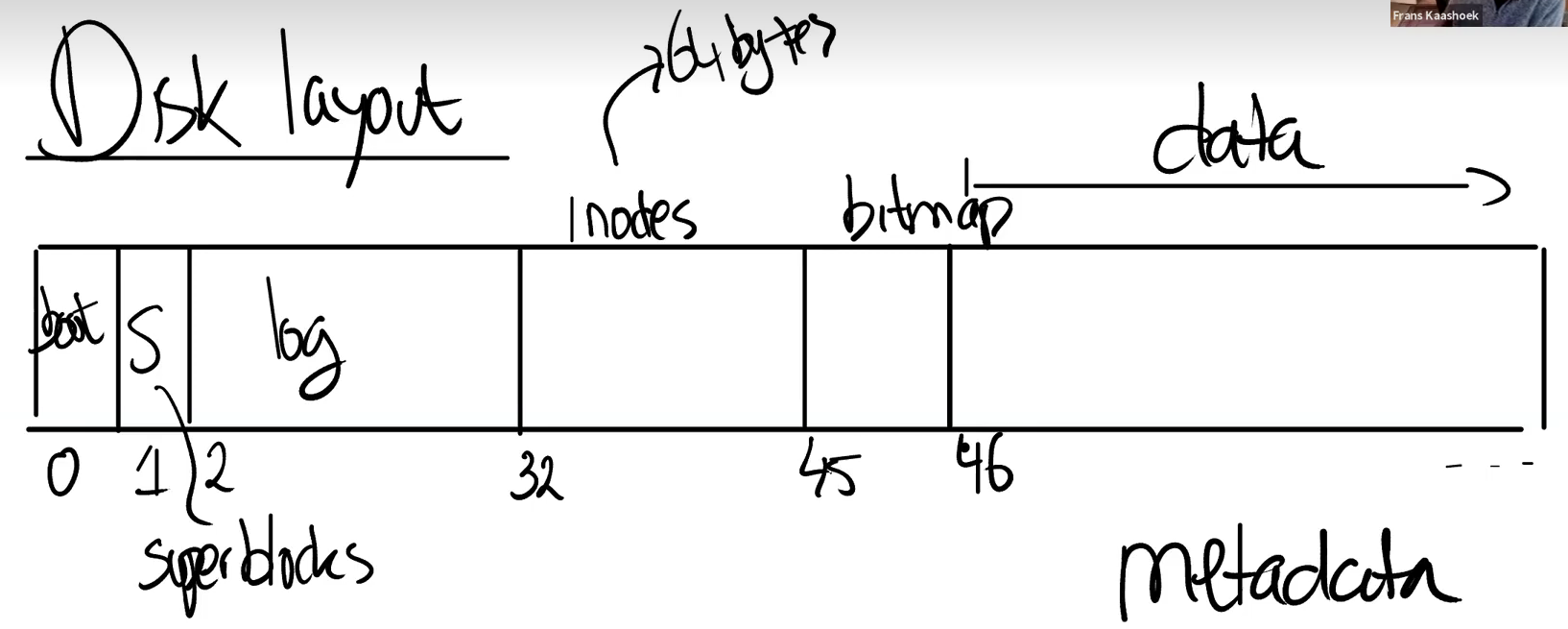
块的分布情况
块的分布情况如下图所示,如XV6这种简单的操作系统就是一个巨大的块的数组,在其他操作系统中可能有更加复杂的结构(树结构等)。一般而言第一块都是boot块,也就是操作系统的启动块,每次开机后都会执行该块中的内容。第二块称为“super block”,他主要存储关于文件系统的信息,比如文件系统采用的架构,大小,结构等。之后的2-31块称为log日志块,存储日志信息。接下来的32-44,存放所有的inode节点,这里每个inode是64B,则每个块包含16个inode节点。随后的45块表示bitmap块(位图块),其中每一位仅用0/1表示数据块/inode节点的占用信息。46块之后的都是数据块,即实际存储文件数据的地方。
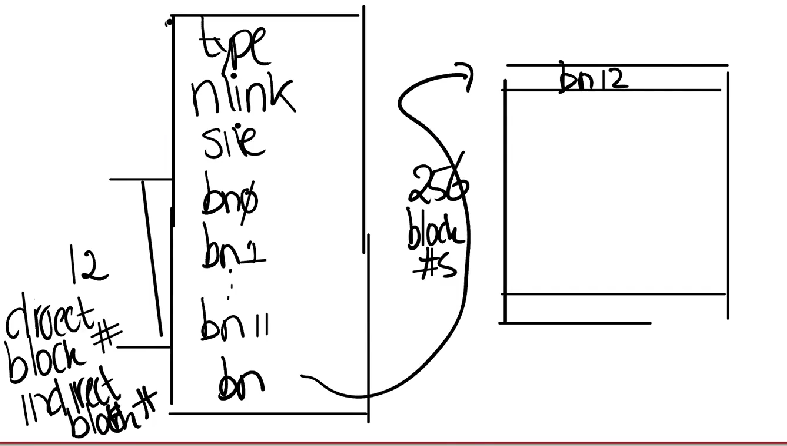
inode
inode(Index Node)也叫索引节点,其主要作用用于存储文件的元数据而不是文件本身的数据。元数据含义是存储数据的数据,例如文件类型(目录/文件)、文件大小,存储该文件的数据块的指针等信息。在文件系统中,inode和真正的文件(本质不同)一一对应,也就是当inode用完时,文件系统不可再创建新的文件了。
在xv6中inode节点的信息如下,包括类型type,nlink链接个数,size文件大小,以及bn0-bn11这12个直接块编号分别指向该文件的数据块,以及一个间接索引块,其指向了一个索引块,索引块中包含了256个快编号,所以一个inode节点最大的文件大小是(256+12)*1024B=268KB。
目录
在Unix操作系统中有一个“一切皆文件”的概念,大概意思是说操作系统把所有输入/输出资源都抽象成”文件“接口,这样同一的抽象处理使得程序员大大方便了很多,这里目录也不例外。
目录也是有inode节点存储,其中type类型为目录,其数据块中存储的是一个个目录项,在xv6中目录项如下图所示,一个目录项有16字节,前2个字节存储对应的inode编号,后14个字节存储文件名称,所以一个数据块中最多包含1024/16=64个目录项。
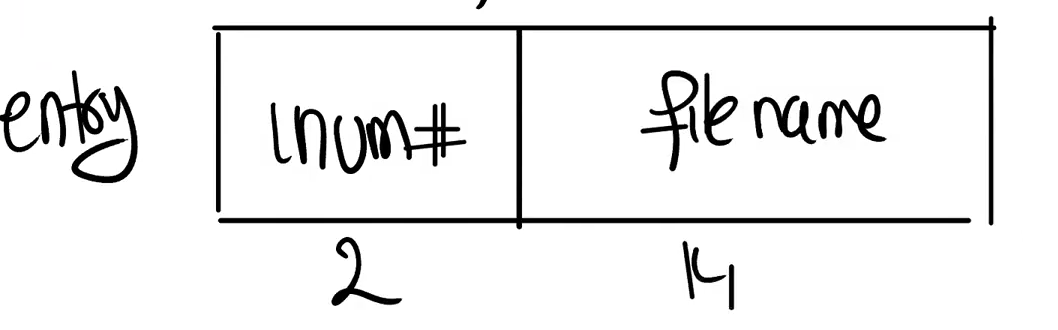
这里举一个查找文件的例子,比如要抄找“/y/x”文件,则首先先寻找根目录inode编号(一般固定在inode块的第二个,第一个通常保存文件系统的坏块列表),这个是提前固定好的,之后根据此inode节点中找到其数据块,其是目录,数据块中存放的全是目录项,朝朝filename为‘y’的,找到之后返回其inode编号,之后再根据此inode编号找到其inode节点,根据数据块找到filename为‘x’的inode编号,此时就找到了x的inode节点编号。(相对路径查询则直接从当前目录出发查找,流程类似)。
XV6文件系统的实践
首先在启动qemu后,可以看到文件系统的初始化,如下图所示,白色的是提前创建好的文件,下方则是对文件系统的说明,46个块包含1个boot块,一个super块,30个log块,13个inode 块以及1个bitmap块,最后的是954个数据块,一共1000个块,是一个很小的文件系统了。

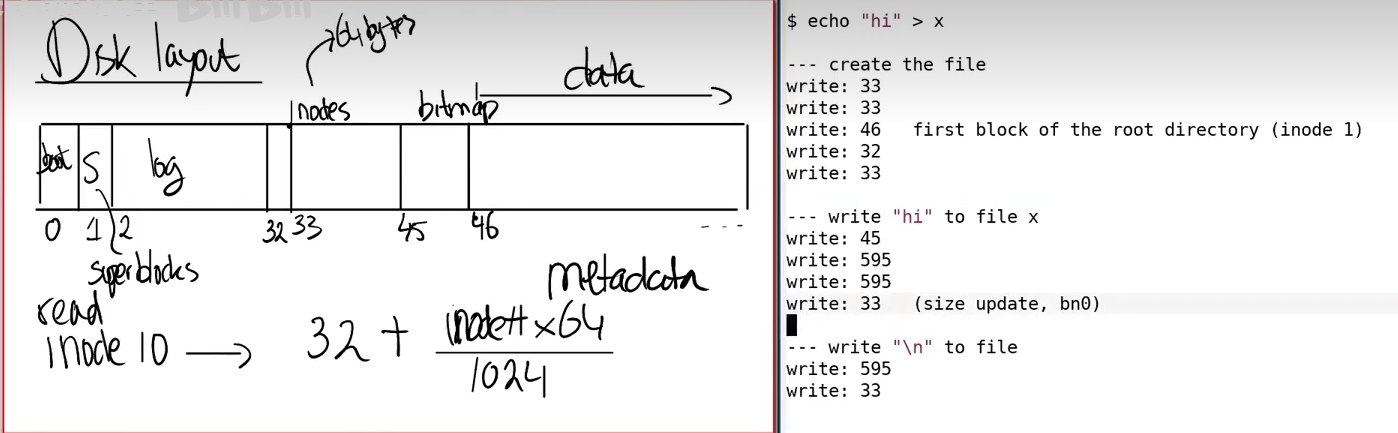
接下来,看一下执行echo hi > x指令,涉及到的块来体会文件系统具体的工作流程,如下图所示。
首先是创建文件x,第一次到块33是找一个空闲的inode编号,之后第二个33是在inode节点中修改信息,之后的块46是根目录的数据块,要增加一个目录项,随后回到块32,修改根目录inode的size属性,最后块33暂且不提。之后是写“hi”到数据块中,首先在bitmap块中将inode节点编号和块编号都改为1,表示已用,随后找到空闲数据块595,先后写下‘h’和‘i’,最后回到块33也就是文件x所在inode节点修改size。最后写'\n'为文件结束符,同样先后经过595和33.
之后我们结合xv6中的代码来看一下他具体的流程,以下是echo的用户程序:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"int
main(int argc, char *argv[])
{int i;for(i = 1; i < argc; i++){write(1, argv[i], strlen(argv[i]));if(i + 1 < argc){write(1, " ", 1);} else {write(1, "\n", 1);}}exit(0);
}
就是按照argv的输入进行输出,最后会补上换行符。
考虑在shell命令行输入echo “hi” > x,首先在shell程序中,会解析到重定向符>,和文件名x,则他首先做的事情就是创建或清空文件x,调用的是以下的sys_open系统调用,如下:
uint64
sys_open(void)
{char path[MAXPATH];int fd, omode;struct file *f;struct inode *ip;int n;if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)return -1;begin_op();if(omode & O_CREATE){ip = create(path, T_FILE, 0, 0);if(ip == 0){end_op();return -1;}} else {if((ip = namei(path)) == 0){end_op();return -1;}ilock(ip);if(ip->type == T_DIR && omode != O_RDONLY){iunlockput(ip);end_op();return -1;}}if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){iunlockput(ip);end_op();return -1;}if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){if(f)fileclose(f);iunlockput(ip);end_op();return -1;}if(ip->type == T_DEVICE){f->type = FD_DEVICE;f->major = ip->major;} else {f->type = FD_INODE;f->off = 0;}f->ip = ip;f->readable = !(omode & O_WRONLY);f->writable = (omode & O_WRONLY) || (omode & O_RDWR);if((omode & O_TRUNC) && ip->type == T_FILE){itrunc(ip);}iunlock(ip);end_op();return fd;
}不需要懂太多,我们关注到他会调用create函数去返回一个inode节点,如下为create函数:
static struct inode*
create(char *path, short type, short major, short minor)
{struct inode *ip, *dp;char name[DIRSIZ];if((dp = nameiparent(path, name)) == 0)return 0;ilock(dp);if((ip = dirlookup(dp, name, 0)) != 0){iunlockput(dp);ilock(ip);if(type == T_FILE && (ip->type == T_FILE || ip->type == T_DEVICE))return ip;iunlockput(ip);return 0;}if((ip = ialloc(dp->dev, type)) == 0)panic("create: ialloc");ilock(ip);ip->major = major;ip->minor = minor;ip->nlink = 1;iupdate(ip);if(type == T_DIR){ // Create . and .. entries.dp->nlink++; // for ".."iupdate(dp);// No ip->nlink++ for ".": avoid cyclic ref count.if(dirlink(ip, ".", ip->inum) < 0 || dirlink(ip, "..", dp->inum) < 0)panic("create dots");}if(dirlink(dp, name, ip->inum) < 0)panic("create: dirlink");iunlockput(dp);return ip;
}从代码里得知会调用一个ialloc函数去寻找一个空闲的inode节点去返回,如下为ialloc函数:
// Allocate an inode on device dev.
// Mark it as allocated by giving it type type.
// Returns an unlocked but allocated and referenced inode.
struct inode*
ialloc(uint dev, short type)
{int inum;struct buf *bp;struct dinode *dip;for(inum = 1; inum < sb.ninodes; inum++){bp = bread(dev, IBLOCK(inum, sb));dip = (struct dinode*)bp->data + inum%IPB;if(dip->type == 0){ // a free inodememset(dip, 0, sizeof(*dip));dip->type = type;log_write(bp); // mark it allocated on the diskbrelse(bp);return iget(dev, inum);}brelse(bp);}panic("ialloc: no inodes");
}这里考虑如果多核多个进程同时进入ialloc函数会如何,不用担心这个问题,这里有快缓存的bread分配,上次实验做过,这个快缓存存在锁管理,所以不会有不正确性问题。
至此在log_write(bp)处,会打印我们第一次的块号,也就是33。
实验Lab
Large files
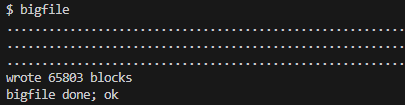
题目的大概意思就是说目前的一个inode最多索引268数据块,对于一个文件而言还是太小了,需要修改一个直接索引块改成2级简介索引块,将能够索引到的数据块增加为256*256+256+11=65803块。
首先我们看以下原本inode的结构和索引示意图:
// On-disk inode structure
struct dinode {short type; // File typeshort major; // Major device number (T_DEVICE only)short minor; // Minor device number (T_DEVICE only)short nlink; // Number of links to inode in file systemuint size; // Size of file (bytes)uint addrs[NDIRECT+1]; // Data block addresses
};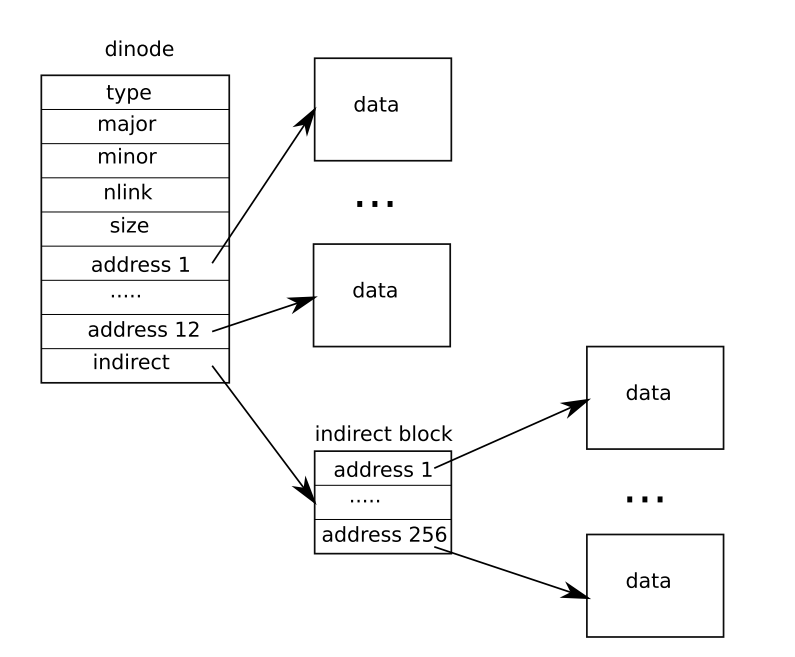
这里不认识的只有major和minor,这两个只有在当type为设备文件时才起作用,设备文件也就意味着是硬件接口,major表示主设备号指定设备类型,minor表示次设备号指定具体设备实例。这里的NDIRECT=12,即addrs0-addrs11都是直接索引,addrs12表示间接索引。
接下来是比较重要的函数bmap,传入两个参数一个是inode节点(注意这个和上个不同,上面的是物理层面的直接inode节点,这里这个是icache中的内容,即inode节点在内存中的缓存,在原本dinode节点的基础上添加了一些信息。),一个是逻辑块号,返回实际数据块地址,具体代码如下:
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
static uint
bmap(struct inode *ip, uint bn) //bn范围在0-267上,一共268个
{uint addr, *a;struct buf *bp;if(bn < NDIRECT){ //首先判断bn是否在直接数据块内if((addr = ip->addrs[bn]) == 0) //若未分配则直接分配一个数据块ip->addrs[bn] = addr = balloc(ip->dev);return addr;}bn -= NDIRECT; //在间接索引块内,减去12个直接索引块if(bn < NINDIRECT){ //判断是否在简介索引范围内// Load indirect block, allocating if necessary. if((addr = ip->addrs[NDIRECT]) == 0) //判断间接索引块是否分配,非数据块ip->addrs[NDIRECT] = addr = balloc(ip->dev); //分配简介索引块bp = bread(ip->dev, addr); //现在要读取该块中内容,先把该索引块加载到块缓存中a = (uint*)bp->data; //获取数据部分内容if((addr = a[bn]) == 0){ //判断第bn个数据块是否存在a[bn] = addr = balloc(ip->dev); //不存在直接分配log_write(bp); //因为索引块修改了,所以要日志记录}brelse(bp); //这里释放索引块的缓存return addr;}panic("bmap: out of range"); //不在范围内,报错
}我们要做的首先就是更改一些常量,将NDIRECT改为11,同时保证inode和dinode的数组还是12,就将他们数组改为NDIRECT+2,注意他们的一致性如下:
#define NDIRECT 11
#define NINDIRECT (BSIZE / sizeof(uint)) //256个
#define N2INDIRECT (NINDIRECT * NINDIRECT) //256*256二级索引块的总数目
#define MAXFILE (NDIRECT + NINDIRECT + N2INDIRECT) //总数目也记得修改// On-disk inode structure
struct dinode {short type; // File typeshort major; // Major device number (T_DEVICE only)short minor; // Minor device number (T_DEVICE only)short nlink; // Number of links to inode in file systemuint size; // Size of file (bytes)uint addrs[NDIRECT+2]; // Data block addresses
};struct inode {uint dev; // Device numberuint inum; // Inode numberint ref; // Reference countstruct sleeplock lock; // protects everything below hereint valid; // inode has been read from disk?short type; // copy of disk inodeshort major;short minor;short nlink;uint size;uint addrs[NDIRECT+2];
};之后修改bmap,修改代码如下:
//三级索引,bn->[0,10]直接数据块,b11->[11-266]一级索引,b12->[267,65802]二级索引
static uint
bmap(struct inode *ip, uint bn)
{uint addr, *a;struct buf *bp;if(bn < NDIRECT){ //首先判断bn是否在直接数据块内if((addr = ip->addrs[bn]) == 0) //若未分配则直接分配一个数据块ip->addrs[bn] = addr = balloc(ip->dev);return addr;}bn -= NDIRECT; //在间接索引块内,减去11个直接索引块if(bn < NINDIRECT){ //判断是否在一级索引范围内// Load indirect block, allocating if necessary. if((addr = ip->addrs[NDIRECT]) == 0) //判断间接索引块是否分配,非数据块ip->addrs[NDIRECT] = addr = balloc(ip->dev); //分配间接索引块bp = bread(ip->dev, addr); //现在要读取该块中内容,先把该索引块加载到块缓存中a = (uint*)bp->data; //获取数据部分内容if((addr = a[bn]) == 0){ //判断第bn个数据块是否存在a[bn] = addr = balloc(ip->dev); //不存在直接分配log_write(bp); //因为索引块修改了,所以要日志记录}brelse(bp); //这里释放索引块的缓存return addr;}bn -= NINDIRECT; //再减去256个一级索引块if(bn < N2INDIRECT) //判断是否在2级索引块的范围内{if((addr = ip->addrs[NDIRECT + 1]) == 0) //首先判断第一层索引块是否存在ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev); //不在则分配,bp = bread(ip->dev, addr); a = (uint*)bp->data; uint bnum = bn / NINDIRECT; //这里查找在第一层索引块中的哪一个if((addr = a[bnum]) == 0) {a[bnum] = addr = balloc(ip->dev); //这里分配log_write(bp); }brelse(bp); //释放第一层索引块bn %= NINDIRECT; //这里找在第二层索引块的位置bp = bread(ip->dev, addr); //这里获取第二层索引块的缓存a = (uint*)bp->data;if((addr = a[bn]) == 0) //这里查找数据块是否存在{a[bn] = addr = balloc(ip->dev);log_write(bp);}brelse(bp); //释放第二层索引块return addr;}panic("bmap: out of range"); //不在范围内,报错
}同时根据提示修改itrunc函数,释放所有的2级索引块,代码修改如下:
// Truncate inode (discard contents).
// Caller must hold ip->lock.
void
itrunc(struct inode *ip)
{int i, j;struct buf *bp;uint *a;//释放所有直接数据块for(i = 0; i < NDIRECT; i++){if(ip->addrs[i]){bfree(ip->dev, ip->addrs[i]);ip->addrs[i] = 0;}}//释放所有1级索引块if(ip->addrs[NDIRECT]){bp = bread(ip->dev, ip->addrs[NDIRECT]);a = (uint*)bp->data;for(j = 0; j < NINDIRECT; j++){if(a[j])bfree(ip->dev, a[j]);}brelse(bp);bfree(ip->dev, ip->addrs[NDIRECT]);ip->addrs[NDIRECT] = 0;}//释放所有2级索引块if(ip->addrs[NDIRECT + 1]){bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);a = (uint*)bp->data;for(j = 0; j < NINDIRECT; j++) //在第一层索引块中遍历{if(a[j]) //存在第二层索引块{struct buf *b2p = bread(ip->dev, a[j]); //获取第二层索引块的缓存uint *a2 = (uint*)b2p->data;uint k;for(k = 0; k < NINDIRECT; k++) //在第二层索引块中查找数据块{if(a2[k]) //存在直接释放数据块bfree(ip->dev, a2[k]);}brelse(b2p); //这里释放第二层索引块的缓存并释放改第二层索引块bfree(ip->dev, a[j]);}}brelse(bp);bfree(ip->dev, ip->addrs[NDIRECT + 1]); //释放第一次索引块}ip->size = 0;iupdate(ip);
}
最终结果图如下:
Symbolic links
这个实验的意思就是实现软链接,简要比较一下软链接和硬链接。
硬链接的本质就是同一个inode节点,不同的文件名。多个文件名共享同一个inode节点,inode节点记录引用次数,也就是说引用次数就是硬链接的个数。当你删除某个文件时,只是减少了该文件inode节点的引用次数,当inode节点的引用次数归零时才真正的删除改文件数据。由于不同设备(C盘、D盘等)的inode编号都是从0开始的,所以只给定一个inode编号不能知道是哪个设备上的inode节点,故硬链接不可跨设备。
软链接也叫符合链接,他就是一个文件,单独占一个inode节点,这个文件存储的内容是另一个文件的地址,当操作系统打开软链接的文件时,会直接打开以该存储内容为地址的文件。当你删除源文件时,存储源文件地址的软链接文件也无法打开。但由于存放的只是地址,所以可以跨设备。
其实总体思路也比较简单,symlink系统调用要做的就是创建这个软链接文件,并把目标文件的路径写到其数据块中,而还要修改的点是open节点,这里根据提示在open打开时会权限控制符,添加软链接的控制符,当发现open的path是软链接时并且需要跟随打开最终文件时(因为软链接本身也是一个正常文件,可以按照正常文件操作),只需要不断的取inode节点,读取数据块的内容,然后令inode节点修改为该内容中的path,直到遇到最终文件(因为可能软链接文件存的地址中的文件也是软链接文件),将其打开即可。
比较麻烦的是文件操作中的事务(感觉类似于锁),这点还没看后面的课,求助大模型了,之后补吧。。。
sys_symlink代码:
uint64 sys_symlink(void)
{ char target[MAXPATH], path[MAXPATH];struct inode *ip;//先获取target和pathif(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)return -1;// 开始一个文件系统操作事务,确保原子性(例如涉及日志时)begin_op();ip = create(path, T_SYMLINK, 0, 0);if(ip == 0){end_op();return -1;}uint64 tarlen = strlen(target);if(writei(ip, 0, (uint64)target, 0, tarlen) != tarlen){iunlockput(ip); //释放ipend_op(); //return -1;}iunlockput(ip); //释放ipend_op(); //关闭事务return 0;
}sys_open代码:
uint64
sys_open(void)
{char path[MAXPATH];int fd, omode;struct file *f;struct inode *ip;int n;if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)return -1;begin_op();if(omode & O_CREATE){ip = create(path, T_FILE, 0, 0);if(ip == 0){end_op();return -1;}} else {if((ip = namei(path)) == 0){end_op();return -1;}ilock(ip);if(ip->type == T_DIR && omode != O_RDONLY){iunlockput(ip);end_op();return -1;}}//如果文件类型是符号链接并且没有设置O_NOFOLLOW,说明是软链接if(ip->type == T_SYMLINK && !(omode&O_NOFOLLOW) ){uint depth = 0; //设置查找深度阈值char target[MAXPATH]; //记录当前目标文件的路径//循环查找目标路径while(ip->type == T_SYMLINK && depth < 10){depth++;if(readi(ip, 0, (uint64)target, 0, ip->size) != ip->size){iunlockput(ip);end_op();return -1;}target[ip->size] = '\0';//添加终止符iunlockput(ip);//释放当前软链接的inodeif((ip = namei(target)) == 0){end_op();return -1;}ilock(ip); //找到新锁定的ilock}//如果深度太大可能是循环链接if(depth >= 10){iunlockput(ip);end_op();return -1;}}if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){iunlockput(ip);end_op();return -1;}if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){if(f)fileclose(f);iunlockput(ip);end_op();return -1;}if(ip->type == T_DEVICE){f->type = FD_DEVICE;f->major = ip->major;} else {f->type = FD_INODE;f->off = 0;}f->ip = ip;f->readable = !(omode & O_WRONLY);f->writable = (omode & O_WRONLY) || (omode & O_RDWR);if((omode & O_TRUNC) && ip->type == T_FILE){itrunc(ip);}iunlock(ip);end_op();return fd;
}至于其他的都是系统调用的常规操作,以及根据题目提示做的一些标志即可,这里就不再赘述了。
完结撒花!!!最后测评结果如下:
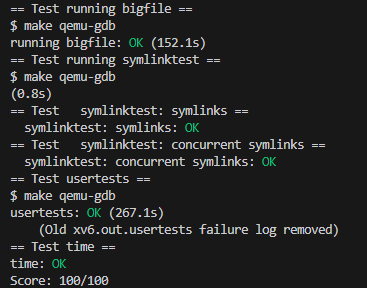
实验总结
文件操作由于inode的抽象,所以总体还是比较简单。可能xv6文件系统只是一个“巨大的数组”,所以显得比较好理解和操作。这也是我第一次没有看任何题解,仅在文件的事务上不懂求助了大模型,完成的实验,想想还是挺让人激动的。随着动手次数增多,可以明显的感觉到,更加敢于去独立思考和打代码了,也不再那么害怕报错了(其实还是很害怕的。。)。