C++11部分
文章目录
- 简介
- 统一的列表初始化
- 基本语法
- 优势
- auto
- 基本语法
- 典型应用场景
- 注意事项
- decltype
- 基本语法
- 核心规则
- 典型应用场景
- nullptr
- 历史问题
- C++11引入 `nullptr`
- 优势
- 范围for
- 工作原理
- 值/引用/常量引用
- 右值引用和移动构造
- 什么是左值和右值
- 左值
- 右值
- 左值引用与右值引用
- 左值引用
- 左值引用的缺陷
- 右值引用
- 移动语义和移动构造
- 为什么需要移动语义
- 移动构造
- 移动赋值
- 现代编译器优化
- 万能引用
- 定义
- 完美转发
简介
C++11 是 C++ 标准十年来最重要的一次升级,被称为“现代 C++ 的起点”。它不仅引入了 auto、Lambda 表达式、右值引用、智能指针等实用特性,还首次提供了语言级别的多线程支持。C++11 让代码更简洁、更安全、更高效,也为后续的 C++14/17/20 奠定了基础。本文将带你全面认识这一代标准的核心特性。
统一的列表初始化
C++11 引入了 花括号 {} 初始化,把各种初始化方式统一起来。它可以用于 内置类型、数组、结构体、类对象、容器 等。
基本语法
int a{5}; // 内置类型
double b{3.14}; // 内置类型
int arr[3]{1, 2, 3}; // 数组
struct Point { int x, y; };
Point p{10, 20}; // 结构体
vector<int> v{1, 2, 3, 4}; // 容器
优势
- 统一性
无论是什么类型,花括号都能使用 - 防止窄化转换
编译器会禁止可能丢失精度的隐式转换:
int x{3.14}; // ❌ 错误,不能把 double 隐式缩窄成 int
int y = 3.14; // ✅ 允许(传统初始化可能丢失精度)
- 与
std::initializer_list协同
C++11 新增的std::initializer_list构造函数 让类可以直接用{}初始化:
class MyClass {
public:MyClass(std::initializer_list<int> lst) {for (auto x : lst) cout << x << " ";}
};MyClass m{1, 2, 3, 4}; // 输出 1 2 3 4
这就是为什么 vector<int> v{1,2,3}; 能直接写的原因。
简单来说使用初始化列表可以一对花括号走天下,初始化更安全、更统一、更现代。
auto
在 C++98/03 中,很多变量类型写起来非常繁琐,尤其是迭代器、模板推导结果、或者很长的函数返回类型:
map<string, vector<int>>::iterator it = m.begin();
而事实上,这些类型编译器是知道的,我们只是被迫重复一遍。 C++11 引入了 auto,让编译器自动推导变量的类型,减少重复和冗余。
基本语法
auto 变量名 = 表达式;
编译器会根据 初始化表达式的类型 推导出变量的类型。
示例:
auto x = 10; // int
auto y = 3.14; // double
auto s = "hello"; // const char*
注意:auto 必须有初始化值,不能像 int a; 那样省略。
典型应用场景
- 简化迭代器声明
map<string, vector<int>> m;
for (auto it = m.begin(); it != m.end(); ++it) {cout << it->first << endl;
}
不需要写 map<string, vector<int>>::iterator 这么长的类型。
2. 配合范围for循环
vector<int> v{1,2,3,4};
for (auto x : v) {cout << x << endl;
}
- 处理复杂返回类型
比如lambda或 `decltyp 返回类型很复杂时:
auto f = [](int a, int b) { return a + b; };
cout << f(3, 4) << endl; // 自动推导 f 是 lambda 类型
后面会介绍lambda 和 `decltyp
4. 在C++14中甚至返回值直接用auto
auto add(int x, int y) {return x + y; // 返回类型自动推导
}
在实际工程项目中非常不建议使用auto返回值!!!
注意事项
- 与引用/指针结合时需小心
int a = 10;
int& r = a;
auto x = r; // x 是 int,不是 int&
auto& y = r; // y 才是 int&
- 与const结合
const int ci = 42;
auto x = ci; // x 是 int(顶层 const 被忽略)
const auto y = ci; // y 是 const int
decltype
在 C++98/03 中,获取一个表达式的类型 很麻烦:
- 我们只能靠
typedef或template的显式指定。 - 遇到复杂的模板表达式时尤其痛苦。
举例:
int a = 1;
double b = 2.5;
// 我想知道 a+b 的类型?(是 double)
在旧标准里,我们只能自己“脑补”,没法交给编译器。
C++11 引入 decltype,专门用来 获取表达式的类型。
基本语法
decltype(表达式) 变量名 = 初值;
编译器会根据 表达式的类型 推导出变量的声明类型。与 typeid(expr).name() 仅能在运行时获取类型信息不同,decltype 的结果可以直接用于 定义变量或声明类型,从而在编译期就完成类型推导。
示例:
int a = 1;
double b = 2.5;decltype(a) x = a; // x 是 int
decltype(a+b) y = a+b; // y 是 double
核心规则
decltype 的行为要分情况
- 普通变量名
int a = 0;
decltype(a) x = 1; // x 是 int
- 变量名如果是引用
int a = 0;
int& r = a;
decltype(r) y = a; // y 是 int&(保持引用)
- 表达式是左值(结果带引用)
int a = 0;
decltype((a)) z = a; // z 是 int&,因为 (a) 是左值表达式
- 表达式是右值 (右值后边会介绍)
int a = 0;
decltype(a+1) w = 5; // w 是 int
典型应用场景
- 配合auto推导函数返回类型
template<typename T, typename U>
auto add(T t, U u) -> decltype(t+u) {return t+u;
}
- 用于泛型编程
template<typename Container>
decltype(Container().begin()) begin(Container& c) {return c.begin();
}
- 声明复杂类型
map<string, vector<int>> m;
decltype(m.begin()) it = m.begin(); // 推导出迭代器类型
decltype用来获取表达式的类型,常用于 模板编程 和 函数返回类型推导。和 auto搭配使用,基本可以覆盖大多数类型推导需求。
nullptr
历史问题
在 C++98/03 中,空指针通常用 宏 NULL 或者字面量 0 表示:
int* p = NULL;
int* q = 0;
但是这样会产生两个问题:
NULL实际上是0
在很多实现里,#define NULL 0,这会导致空指针和整数 0 混淆。- 函数重载歧义
void func(int x)
{cout << "int" << endl;
}void func(void* p)
{cout << "void *" << endl;
}int main()
{func(NULL);
}
在这个例子中,期望func(NULL)调用void func(void* p),但实际上编译器可能会有
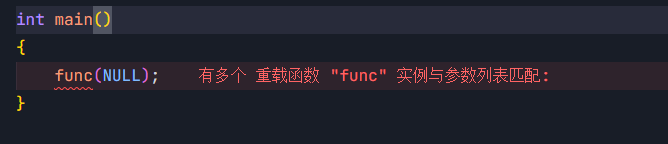
这说明用NULL表示空指针不够完全
C++11引入 nullptr
C++11 专门引入了一个新的关键字:nullptr
它是一个 字面量常量,类型为 std::nullptr_t,专门用来表示空指针。
示例:
int* p = nullptr; // 安全明确
优势
- 不会与整数混淆
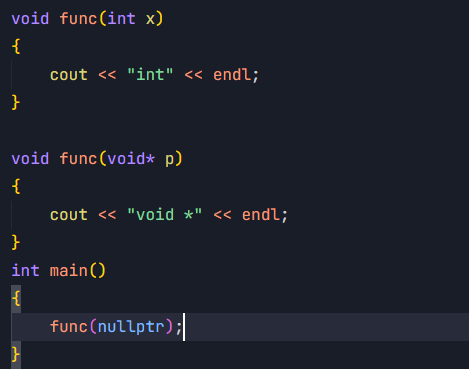
可以看出nullptr匹配了正确的函数调用 - 类型安全
nullptr的类型是std::nullptr_t,它可以隐式转换成任意指针类型,但不能转换成整数类型:
int* p = nullptr; // OK
double* q = nullptr; // OK
int x = nullptr; // ❌ 错误,不能当作 int
范围for
在 C++98/03 里,如果要遍历数组或容器,需要写很多样板代码:
vector<int> v{1, 2, 3, 4};
// 旧式写法
for (vector<int>::iterator it = v.begin(); it != v.end(); ++it) {cout << *it << " ";
}
或者:
for (size_t i = 0; i < v.size(); ++i) {cout << v[i] << " ";
}
这种写法既繁琐,又容易出错(比如 i < v.size() 写错)。
C++11 引入了 范围 for 循环,语法更简洁:
for (声明 : 容器/数组) {// 使用声明的变量
}
示例:
vector<int> v{1, 2, 3, 4};// C++11 范围 for
for (auto x : v) {cout << x << " ";
}
工作原理
范围 for 背后,其实是编译器帮你生成了 迭代器遍历 的代码:
for (auto it = v.begin(); it != v.end(); ++it) {auto x = *it;...
}
所以它适用于:
- 所有数组(C 风格数组)。
- 所有提供
begin()和end()的容器(STL 容器、自定义容器)。
值/引用/常量引用
范围 for 默认是 复制 元素:
for (auto x : v) { // x 是 v 元素的副本x += 1; // 不会修改 v
}
如果需要修改容器元素,应该用 引用:
for (auto& x : v) { // x 是元素的引用x += 1; // 修改 v
}
如果只读,不希望复制,可以用 常量引用:
for (const auto& x : v) {cout << x << " ";
}
右值引用和移动构造
什么是左值和右值
左值
左值(locator value)可以简单理解为:
有名字、可寻址、能在表达式结束后继续存在的对象。
左值是一个表达式。
典型特征:
- 能够被取地址
& - 有持久存储位置(栈,堆,全局区)
示例:
int x = 10; // x 是左值x = 20; // 左值可以出现在赋值号左边int* p = &x; // 左值能取地址&(*p); //这是一个表达式左值
右值
右值(read value)一般是:
没有名字、不可寻址、临时存在的值。
右值也是一个表达式
典型特征:
- 通常是表达式计算出来的结果,生命周期很短。
- 不能直接取地址。
- 常出现在赋值号右边。
示例:
int y = 10 + 20; // 10+20 是右值
int z = 5;
z = y + 3; // (y+3) 是右值
int* p = &(y+1); // 错误,右值不能取地址
左值引用与右值引用
左值引用
语法:T&
- 可以绑定到左值(有名字、能取地址的对象)。
- 不能绑定到右值(临时值)。
示例:
int a = 10;
int& ref = a; // 可以绑定左值
ref = 20; // 通过引用修改 a
错误示例:
int& r = 10; // 错误,不能把左值引用直接绑定到字面量右值
用途:
- 常用于函数参数,避免拷贝:
void foo(int& x) { x += 1; }
int a = 5;
foo(a); // 左值传入参数,避免拷贝
foo(10); // ,10 是右值,不能传
左值引用的缺陷
将左值引用用作函数参数可以有效减少拷贝开销。但在需要函数返回较大对象的场景下,往往不能简单地通过左值引用返回,因为这样很容易返回局部对象的引用,从而导致悬垂引用问题,带来严重的错误风险。
例如:
std::string& getName() {std::string name = "Tom"; // 局部变量,函数结束后被销毁return name; // ❌ 返回悬垂引用
}
调用此函数后,返回的引用指向的对象已被销毁,造成 未定义行为。这类错误往往隐蔽且难以排查,但一旦触发会带来严重后果。
从另一方面来看,如果完全避免使用引用,而是选择直接按值返回对象,则会遇到另一个问题:在缺乏编译器优化(如返回值优化 RVO/NRVO)的情况下,返回值可能会引入额外的拷贝构造,造成明显的性能损耗。对于字符串、容器、图像缓冲区等大对象,这种代价尤为高昂。
因此,传统的左值引用机制在“减少拷贝”与“安全返回对象”之间陷入了两难
为了既能安全返回对象,又能避免额外的拷贝,C++11 引入了 右值引用 和 移动语义)。实现避免拷贝,直接“偷资源”
右值引用
语法:T&&
- 只能绑定到右值(临时对象、字面量、将亡值)。
- 无法直接绑定左值(除非用
std::move转换成右值)。
示例:
int&& r1 = 10; // 右值引用绑定字面量
int&& r2 = 5 + 3; // 右值引用绑定临时结果int a = 42;
// int&& r3 = a; // 错误,a 是左值
int&& r4 = std::move(a); // std::move 把左值转成右值
用途:
- 移动语义(本质上是从别的对象那里夺取资源)
std::string s1 = "hello";
std::string s2 = std::move(s1); // s2 移动构造,接管 s1 的资源
注意:这里s1的资源已经被s2取走,后续不应该继续使用s1
补充:
在C++11中,“右值引用类型”的变量本身其实是一个左值,前面提到过左值是可以取地址的,右值是不能取到地址的
举例:
void foo(int&& x) {// x 的类型是 int&&(右值引用类型)// 但是表达式 "x" 是一个左值int& y = x; // 合法,能用左值引用绑定int&& z = x; // 错误,右值引用不能直接绑定左值
}
从这个例子可以清楚地看出:虽然 x 的类型是右值引用,但作为变量,它依然是一个左值。
移动语义和移动构造
为什么需要移动语义
在 C++98/03 中,如果一个对象需要“转交资源”,只能通过 拷贝构造:
std::string s1 = "hello";
std::string s2 = s1; // 这里会分配一块新内存,把内容逐字复制
但是问题是:
- 对于临时对象(如函数返回值
return std::string("hello")),我们明明知道它马上就要销毁,却还要做一次“昂贵的拷贝”,太浪费了。 - 对于独占资源(如
std::unique_ptr、文件句柄),拷贝根本没有意义。
C++11 的目标:既然对象马上销毁,不如直接把资源“搬走”。
移动构造
定义:
ClassName(ClassName&& other) noexcept;
参数是 右值引用(T&&),意味着它只能接收临时对象或被 std::move 转换的对象。
行为:
- 接管
other的资源(比如内存、文件句柄)。 - 把
other置为空状态(防止析构时二次释放)。
示例:
class Buffer {int* data;size_t size;
public:Buffer(size_t n) : size(n), data(new int[n]) {}~Buffer() { delete[] data; }// 移动构造Buffer(Buffer&& other) noexcept : data(other.data), size(other.size) {other.data = nullptr; // 让出资源other.size = 0;}
};int main()
{Buffer b1(100);Buffer b2 = std::move(b1); // 触发移动构造
}
此时:
b2接管了b1的资源。b1进入“已移动状态”,此时b1不能被使用,因为没有资源了
移动赋值
除了构造,赋值也有移动版本
ClassName& operator=(ClassName&& other) noexcept;
示例:
Buffer& operator=(Buffer&& other) noexcept {if (this != &other) {delete[] data; // 释放旧资源data = other.data; // 接管新资源size = other.size;other.data = nullptr;other.size = 0;}return *this;
}
当你这样写:
Buffer b1(100), b2(200);
b2 = std::move(b1); // 移动赋值
就不会触发拷贝,而是“资源转移”
现代编译器优化
按照前文所述,在函数返回局部对象时,直观的做法是通过 移动构造 来避免拷贝,例如:
vector<int> f()
{vector<int> v = { 1,2,3,4,5,6 };return move(v);
}
int main()
{vector<int> vt = f();
}
然而在实际开发中,这种写法往往是多余的。现代编译器普遍支持 返回值优化(RVO, Return Value Optimization)。当编译器检测到返回的对象会直接用于初始化外部变量时,它会跳过拷贝和移动的过程,直接在目标内存上构造对象。
优化过程大致如下:
- 编译器在
main的栈帧中为vt分配空间。 - 调用
f时,编译器直接在vt的内存上构造返回对象。 - 整个过程中既没有拷贝,也没有移动。
这就是 RVO。因此,如果在返回时显式写上move(v),反而会使编译器无法应用 RVO,从而多一次移动构造,性能上甚至比不写move更差。
因此在现代编译器下,可以直接传值返回
万能引用
定义
当你在函数模板里写参数形如:
template <typename T>
void func(T&& t);
这里的 T&& 并不总是“右值引用”。它会根据 类型推导(type deduction) 的结果,表现出不同的含义:
- 如果传入右值:
T被推导成具体类型,T&&就是“右值引用”。 - 如果传入左值:
T被推导成“左值引用类型”,而T&&会发生 引用折叠,最终变成T&。
所以T&&在模板里既能接收左值,又能接收右值,因此称为 万能引用
例子:
template <typename T>
void f(T&& x) {// ...
}int main() {int a = 10;f(a); // a 是左值 -> T 推导成 int& -> 参数类型变成 int& && 折叠为 int&f(10); // 10 是右值 -> T 推导成 int -> 参数类型就是 int&&
}
完美转发
在编写泛型函数时,我们常常希望 将参数“原封不动”地传递给另一个函数,即既保留它的类型信息,又不丢失它的值类别(左值/右值)。
需要注意的是:虽然右值引用类型的变量可以绑定右值,但这个变量本身依然是一个左值。如果直接把它传给其他函数,它会被当作左值处理,从而失去原有的“右值特性”。
为了避免这种信息丢失,C++11 提供了 std::forward。它会根据模板参数的推导结果,选择性地将参数转换回原始的值类别:
- 如果实参是左值,
std::forward会返回左值引用; - 如果实参是右值,
std::forward会返回右值引用。
例子:
template <typename T>
void wrapper(T&& arg) {process(std::move(arg)); // 会把所有参数当右值process(std::forward<T>(arg)); // 保留原始值类别
}