Flash Attention学习笔记

fast可以增加模型训练速度,memory efficient 显存高效的,exact:和标准attention得到的结果完全一致,并不降低attention精度。IO-Awareness:通过对IO感知的方式来进行训练的整个算法是以改进IO效率达到的。
首先传统的transformer计算过程:
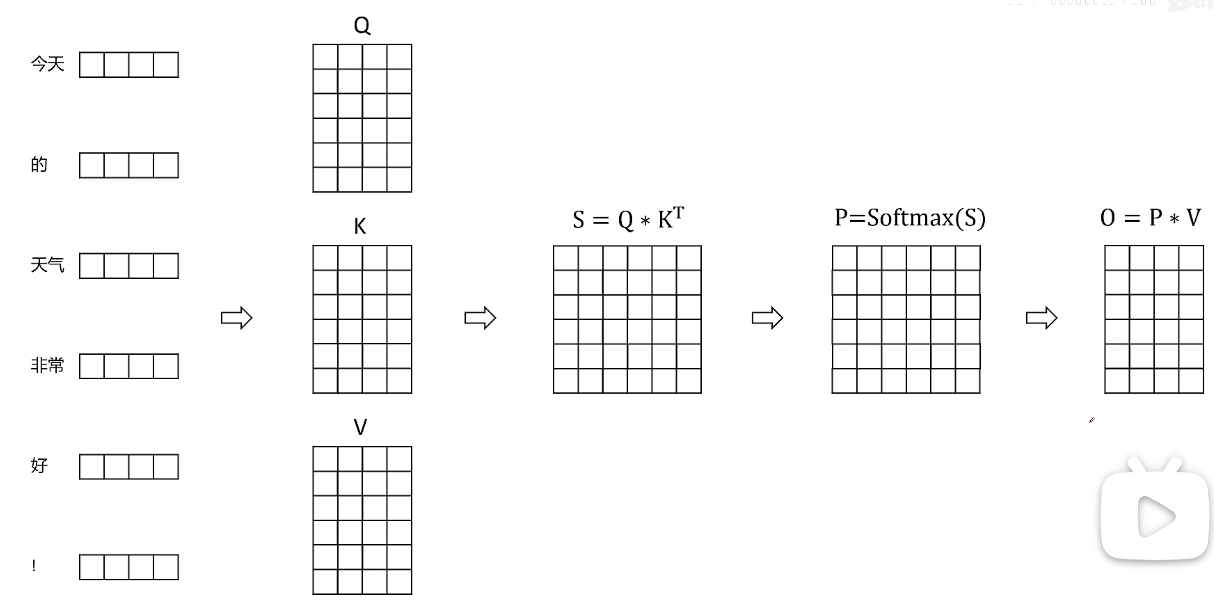
pytorch写的代码在实际显卡上的attention是如何计算的呢。
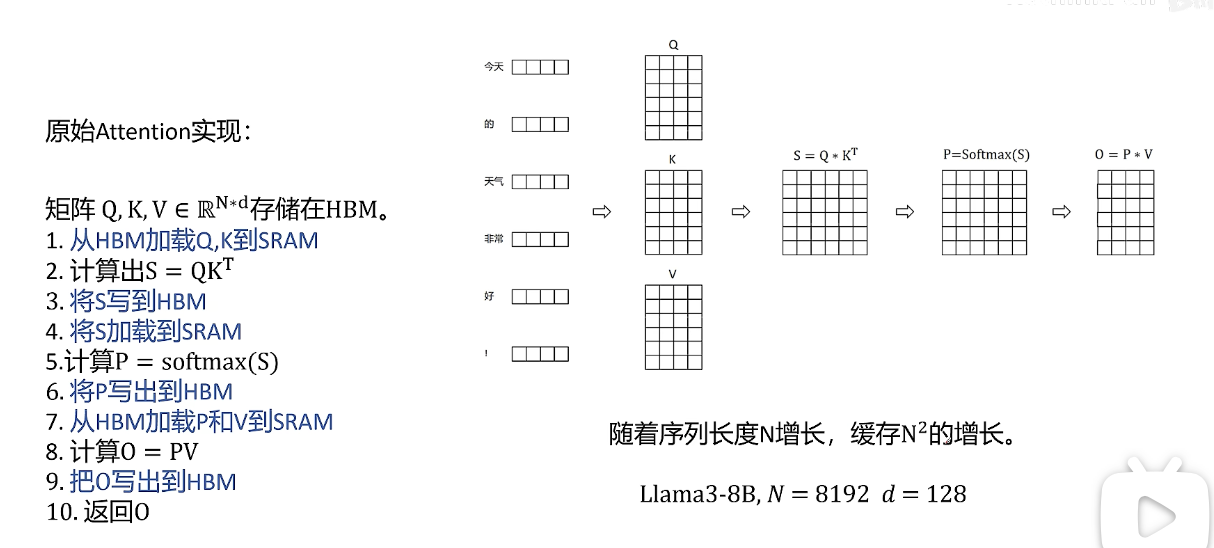
SRAM:特点是极快,但容量小、成本高、占地方。它主要用在处理器芯片内部,作为缓存。
HBM:特点是带宽极高,但成本非常高。它主要用在高端GPU和AI加速卡上,作为主内存,为大规模并行计算提供海量数据吞吐。
由于权重矩阵和输入数据量非常大,它们通常存储在HBM中
一旦数据被加载到SRAM上,计算核心就会高速访问SRAM,执行密集的矩阵乘法运算
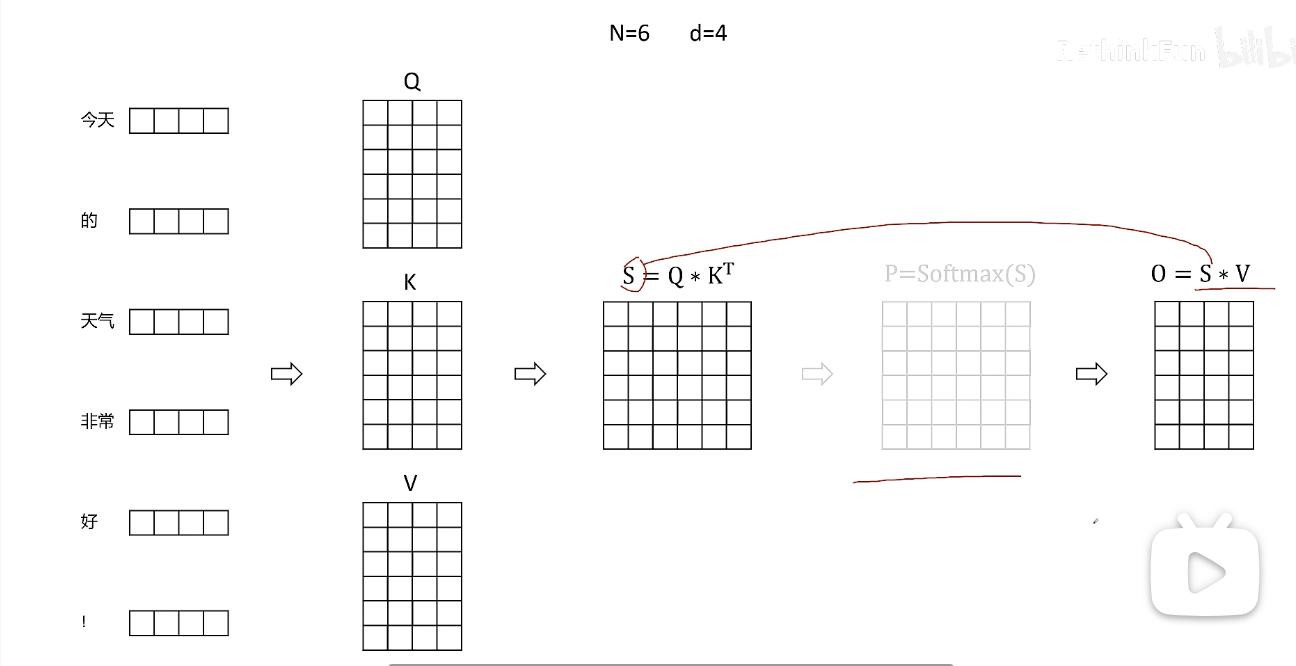
1. 从HBM加载Q,K到SRAM
2. 计算出S= QK^T
3. 将S写到HBM
4. 将S加载到SRAM
5. 计算P=softmax(S)
6. 将P写出到HBM
7. 从HBM加载P和V到SRAM
8. 计算O = PV
9. 把0 写出到HBM矩阵Q,K,V维度都是N*d,N是序列长度,d是特征维度。
可以看出中间有很多临时变量的读写,比如S和P矩阵,他们大小都是随着序列长度的平方增长的。中间临时矩阵占用的显存非常大。比如保留中间结果比如SP会占用显存但是还是需要的,因为反向传播需要他们来计算梯度。在模型训练时制约训练速度有两种情况。
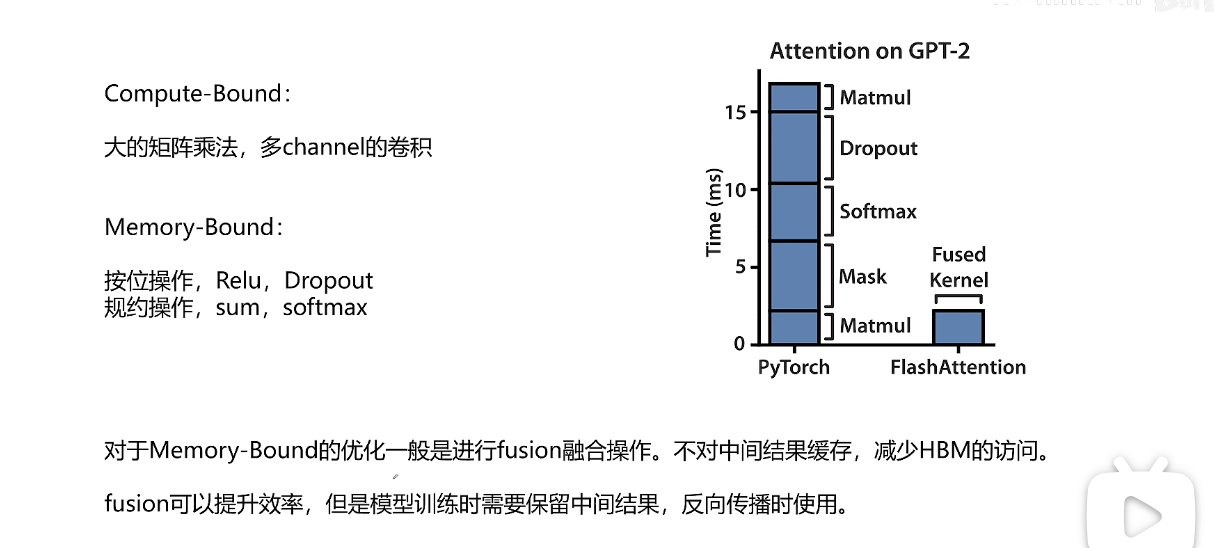
在模型训练时制约训练速度有两种情况。
一种情况是compute-Bound,训练速度的瓶颈在于运算,比如对于大的矩阵乘法还有多channel的卷积操作。这些操作都是需要的数据量不大但是计算很复杂。
第二种情况是memory-bound,训练速度的瓶颈在于对HBM数据的读取速度。
从HBM读取数据的速度跟不上运算的速度,算力在等待数据。主要操作有两类:一位是按位的操作比如relu和dropout,还有一类是规约操作比如sum, softmax这些操作都是需要数据很多但是计算相对简单。
attention计算操作主要是memory bound的计算。
上面右侧的图可以看到compute bound的操作比如矩阵乘法占用的时间很短,但是memory bound占据了很长时间。对于memory bound的优化主要通过融合多个操作。
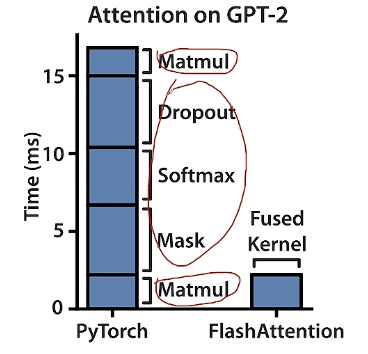
对于Memory-Bound的优化一般是进行fusion融合操作。不对中间结果缓存,减少HBM访问,节约了原来多个操作之间要存取HBM的时间,让多个操作只要存取一次HBM。我们不保存中间结果在反向传播中重新计算。
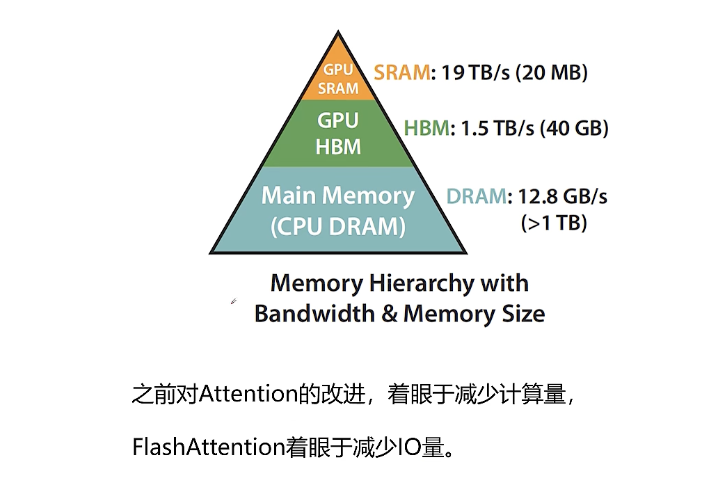
显存中的存储是分级的,有芯片内的缓存SRAM(缓存容量小但是访问快),还有芯片外的HBM缓存(容量大但是访问慢),所以对于优化来说应该尽可能让计算访问芯片内的缓存,尽可能减少访问芯片外HBM的显存。
flash attention 着眼于减少IO量。以及通过访问芯片内缓存而加快IO的速度。
当Q和K矩阵很大时,不分块的传统方法会把大部分时间浪费在等待数据从HBM搬运到SRAM上,GPU强大的计算单元大部分时间在“饿着肚子”等数据。
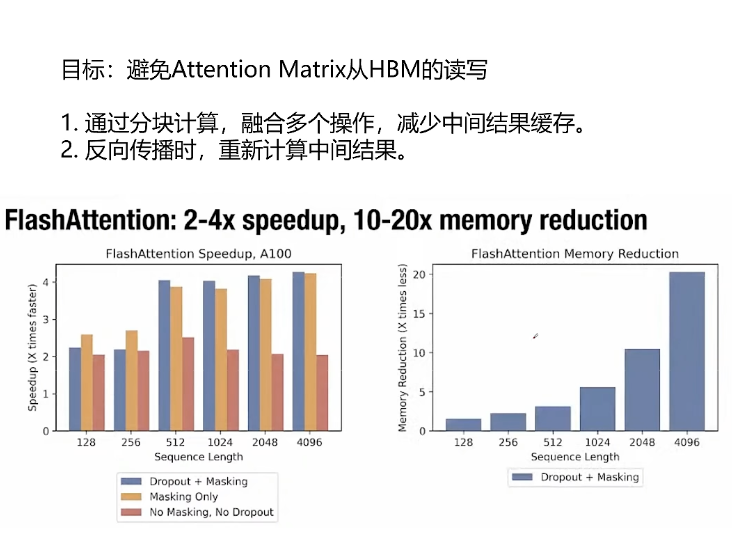
为了实现避免attention matrix从HBM读写通过以下两点实现的:
1. 通过分块计算,融合多个操作,减少中间结果缓存(到HBM)
2. 反向传播时, 重新计算中间结果。
实现了2-4倍速度提升,10-20倍显存占用的节省(从原来的随序列长度平方增长减小到随序列长度线性增长)。
下面我们来看如何通过矩阵分块和融合多个计算来减少对HBM的访问。
暂时先跳过softmax的操作比较特殊后面单独讨论。
1. 从HBM中读取Q的前两行、K转置的前三列、V的前三行,然后传入到SRAM上对他们进行计算。
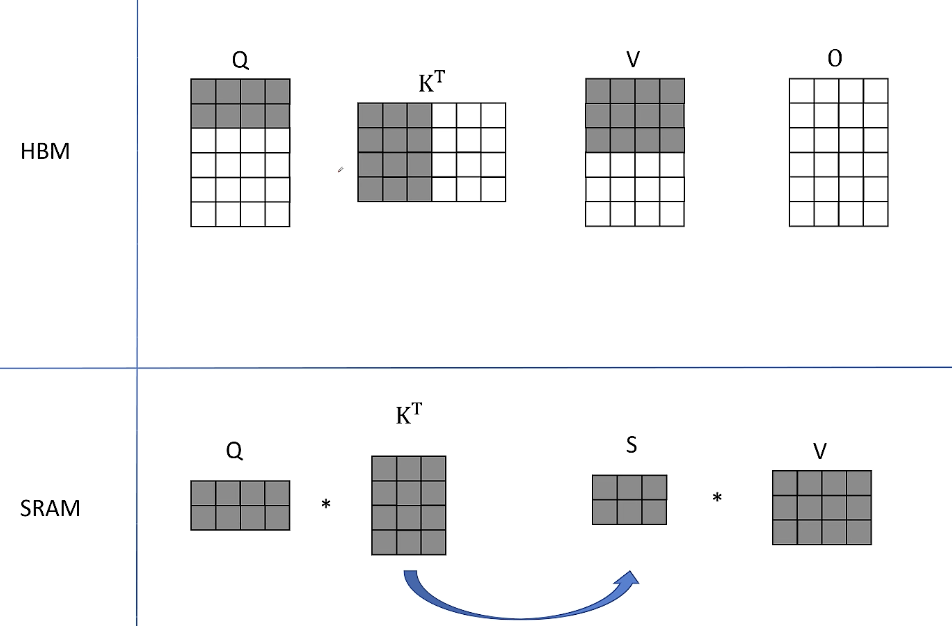
在SRAM中Q和K的转置得到S并不存入HBM,直接和V的分块进行计算。得到了O的前两行:
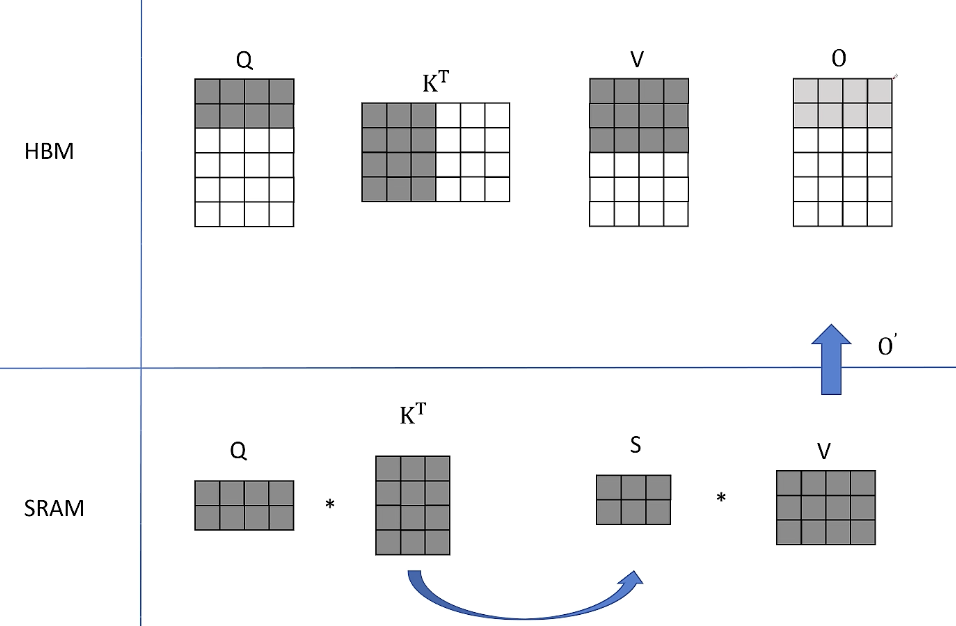
因为O是对所有V的一个加权平均,目前得到的结果就是对V的前三行进行加权平均。O用浅色表示因为还只是一个中间结果,后面还需要更新。
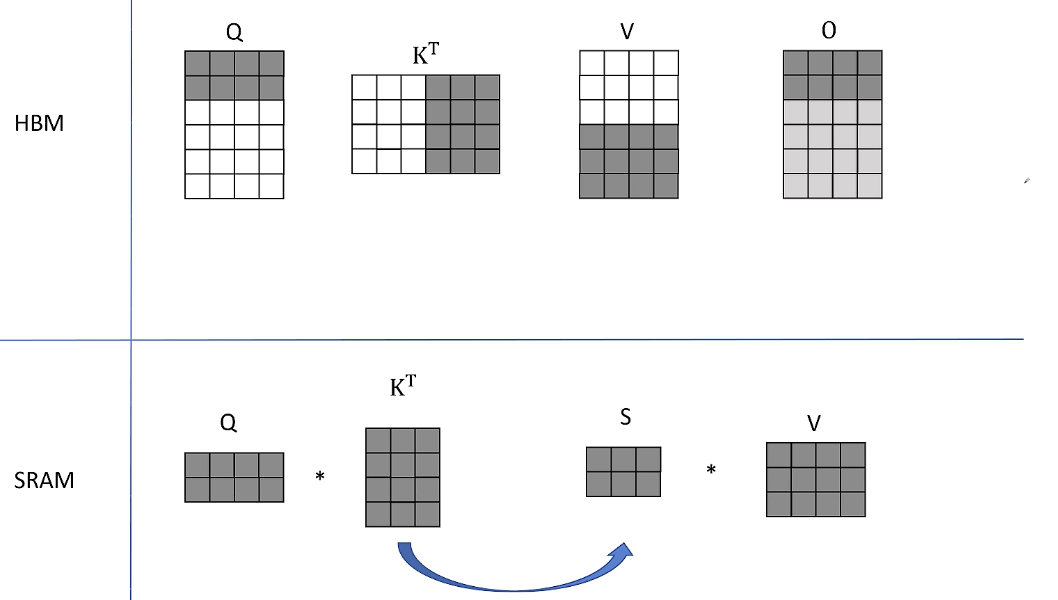
2. 接下来K和V的分块还保留在SRAM里,从HBM里读取Q的中间两行,经过同样的计算得到O的第三行和第四行的中间结果。
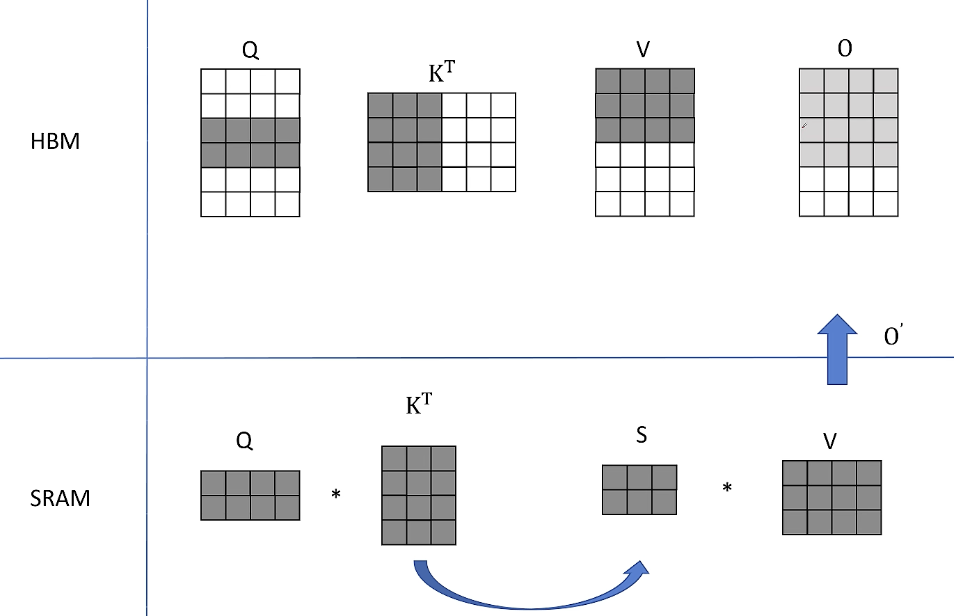
然后仍然保留K和V的分块在SRAM里
3, 从HBM中读取Q的最后两行经过同样的计算得到O的最后两行的结果
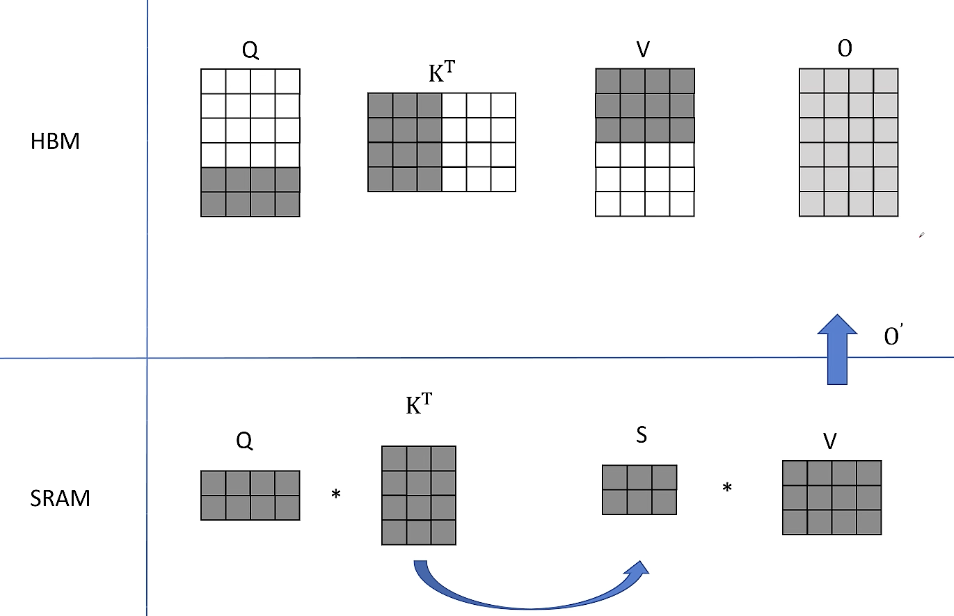
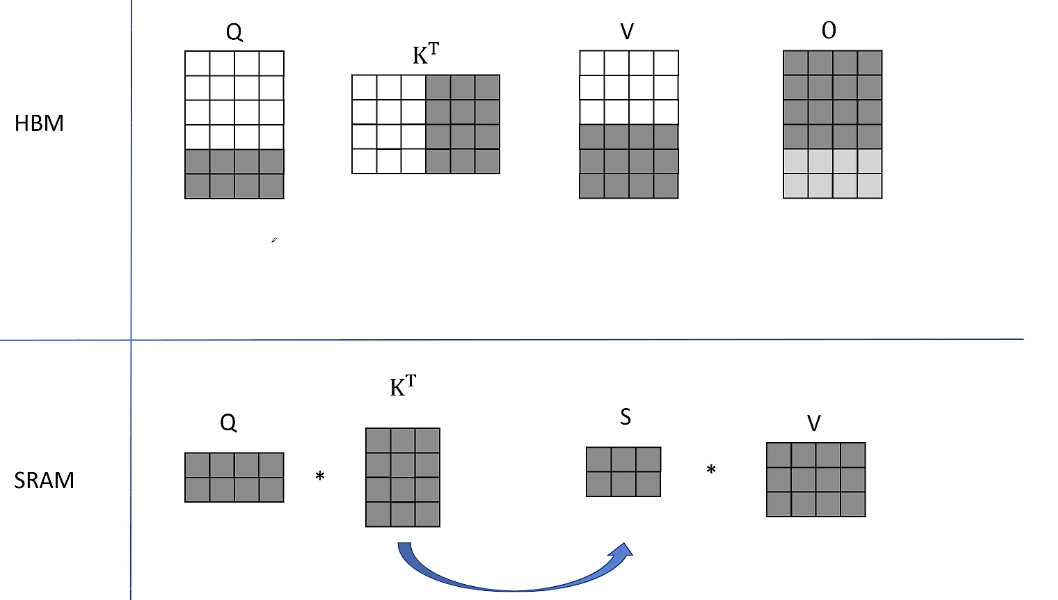
4. 接下来读取K转置的后三列,V的后三行, Q的前两行,得到结果S之后再凑个HBM里读取O之前的保存结果,也就是对V的前三行的加权平均值进行加和。
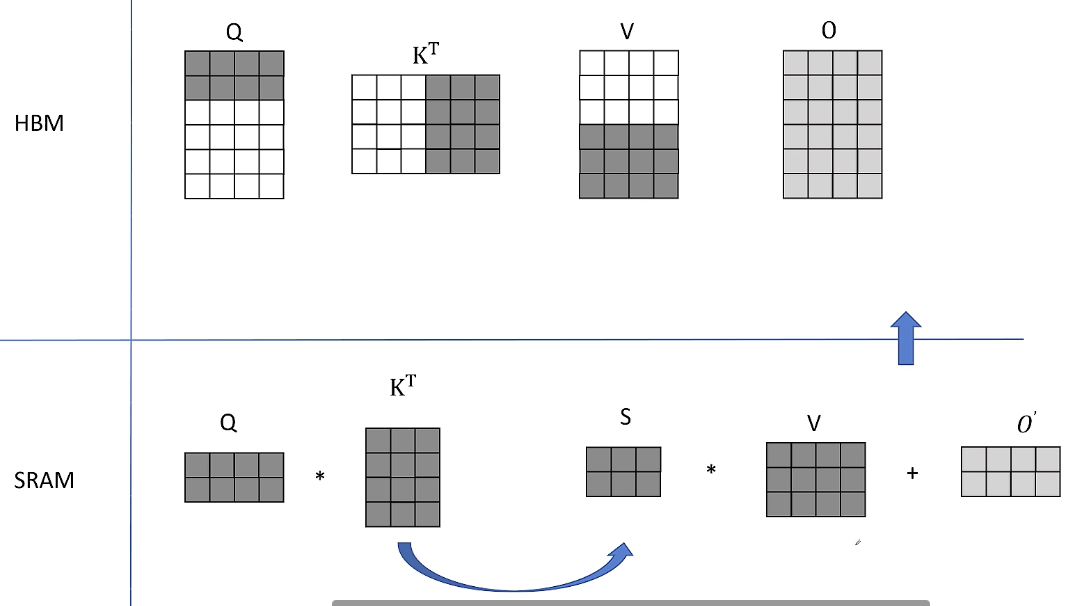
得到了O前两行的最终结果。
同样保持K和V分块不变,从HBM里读取下一个分块的Q进行计算,从HBM里读取之前的计算中间结果O和更新后存入HBM。最后继续保持SRAM里的K和V分块不变。最后从HBM里读取Q的最后两行进行计算,继续保持SRAM里面的K和V分块不变。加和更新最终存入HBM。
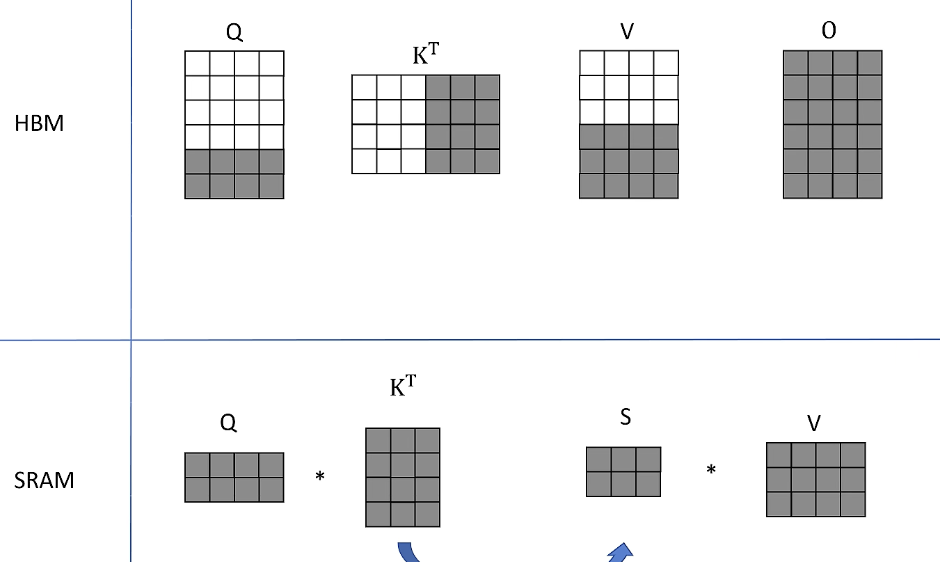
以上完成了attention计算。
通过将矩阵分块以及将多步计算进行融合,中途没有将中间计算结果S存入HBM。大大减少了IO的时间。
接下来看softmax:
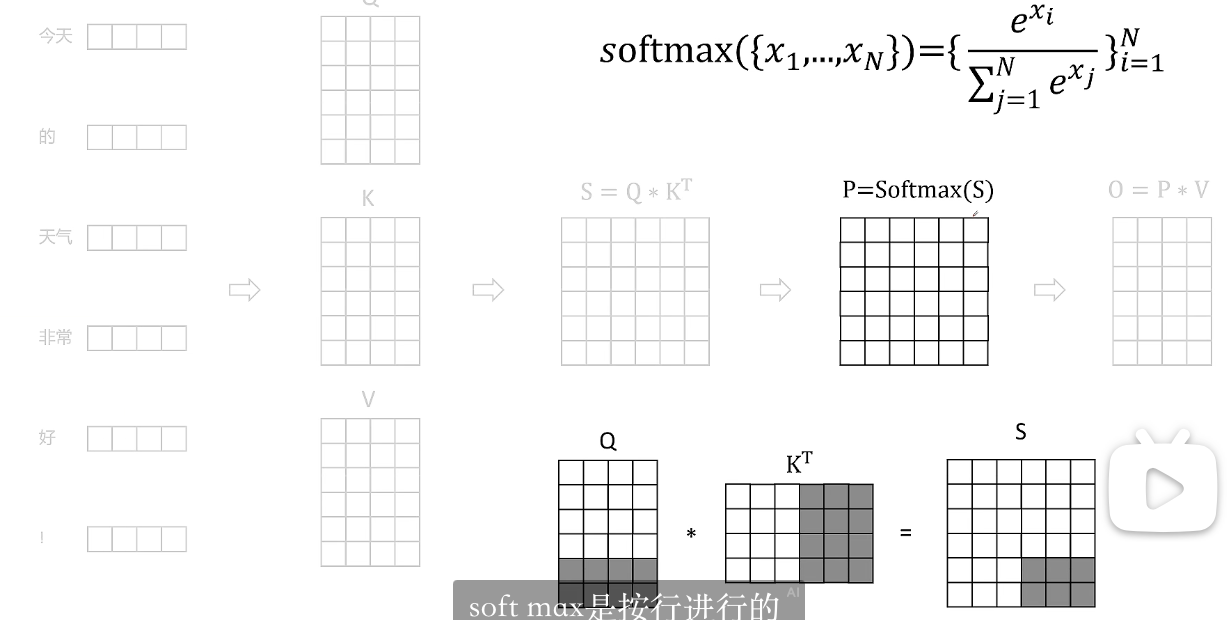
softmax是按行进行的,只有一行所有的数据都计算完成后才能进行这里的求和计算。所以我们想要让我们之前的矩阵分块对attention多步进行融合计算得以进行的前提必须解决softmax分块计算问题。
softmax的分块计算:
现在我们训练都是混合精度,在FP16下进行,如果X= 12,则E的X次方就大于FP16所能表示的最大的数了。

为了解决这个数值溢出的问题,人们提出了一种叫做safe softmax的算法。
首先找出从X1到Xn里最大的值m,然后将softmax的分子和分母同时除以E的m次方,softmax结果不变,得到的式子中可以看出e的指数部分就都小于等于0了,这时候用fp16表示就不会有数值溢出的问题了。
在看一下safe softmax的过程:
有一组X通过max(x)求出X里的最大值,通过p(x)将x变化成e的(xi-m(x)),如下图
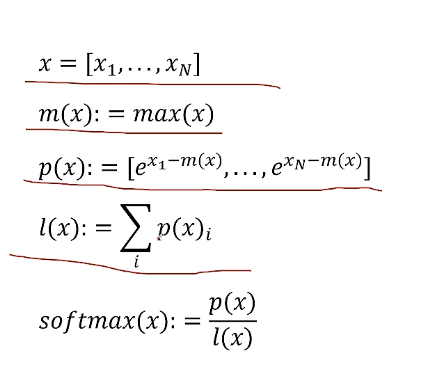

对于原始2N个X的正确的softmax的值如上图右侧计算过程。
其中p(x)拼接起来的公式是![]()
需要分别给和
一个系数。因为m(x)是
和
的最大值,所以m(x)肯定等于其中一个。假设m(x)=
那么后面e的指数项就等于0,那么
因为分块计算的时候减去就是全局最大值,所以此时不需要再进行调整。
在分块计算的时候减去的是局部最大值不是全局最大值,那么它和全局最大值比少了多少呢?就是这里的
给他补回来。
所以softmax也可以通过分块来计算了,只是我们需要额外补充几个变量。

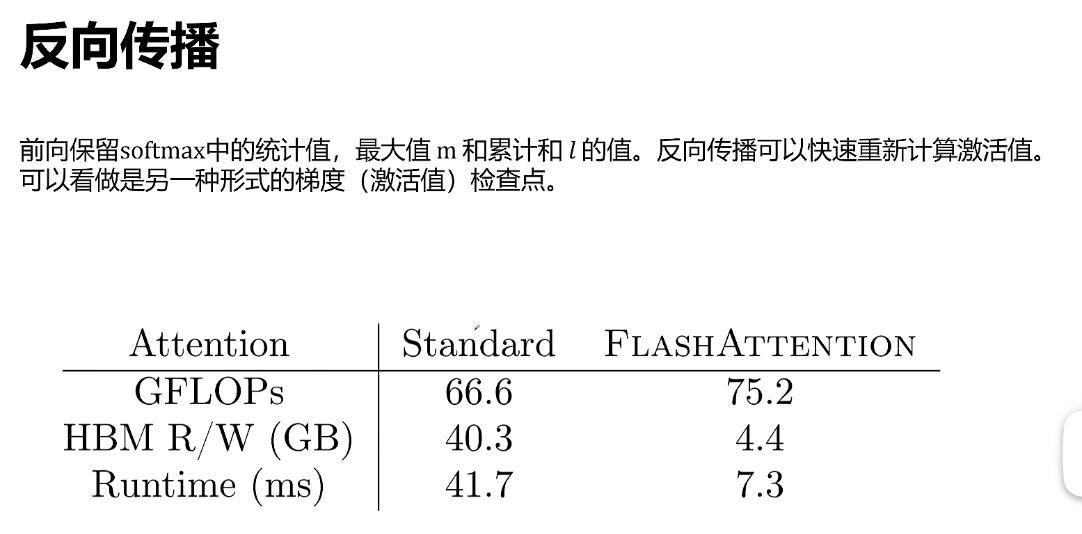
可以看到flash attention计算量增加了 但是对HBM访问量大幅度减小,训练时间也是大幅度减小。
flash attention2大致思想相似增加了一些工程优化,

如果只看单次传输,把一大块数据分成很多小块传输,总的数据量不变,总的理论带宽时间应该是一样的。但是,Flash Attention 分块计算能极大减少 IO 时间的根本原因在于:它通过巧妙的分块,避免了将整个庞大的中间结果矩阵反复从慢速内存(如 HBM)读取和写入