基于机器学习的智能贫血分析预测系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
贫血是一种常见的健康问题,影响全球数亿人的生活质量。早期识别和预防贫血对于减少其对健康的负面影响至关重要。传统的贫血诊断方法通常依赖于实验室检测结果(如血红蛋白水平),这种方法虽然准确但耗时较长且成本较高。近年来,随着机器学习技术的发展,利用先进的算法对患者的健康数据进行预测已成为可能。
本项目旨在开发一个基于机器学习的智能贫血分析预测系统,利用数据挖掘和机器学习技术对患者的健康数据进行分析,提前预测潜在的贫血风险,并提供相应的干预建议。该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为医疗保健机构和个人用户提供一个全面的贫血预警平台。通过该系统,用户可以更方便地了解自己的贫血风险,并采取适当的预防措施。
2. 关键技术点
- Python:用于后端逻辑处理和API接口开发。
- Pandas:用于数据清洗、特征提取和预处理操作。
- NumPy:用于数值计算,提高数据处理效率。
- Matplotlib/Seaborn:用于数据可视化,帮助用户直观地了解数据分布和特征。
- Scikit-learn/XGBoost:用于传统机器学习算法和梯度提升树模型的实现。
- Flask:轻量级Web应用框架,用于构建后端服务。
- Bootstrap:前端框架,用于构建响应式的网页布局。
3. 贫血分析预测建模
3.1 数据来源与特征
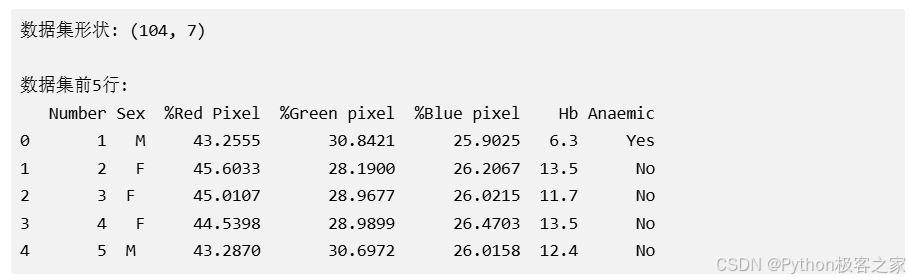
我们使用的数据集包含104个样本,每个样本包含以下特征:
- Number: 样本编号
- Sex: 性别(M/F)
- %Red Pixel: 红色像素百分比
- %Green pixel: 绿色像素百分比
- %Blue pixel: 蓝色像素百分比
- Hb: 血红蛋白水平(g/dL)
- Anaemic: 贫血状态(Yes/No)
3.2 数据质量检查
# 检查缺失值
print("缺失值统计:")
print(df.isnull().sum())# 检查重复值
print(f"\n重复行数量: {df.duplicated().sum()}")# 检查目标变量分布
print("\n贫血分布:")
print(df['Anaemic'].value_counts())
print("\n贫血比例:")
print(df['Anaemic'].value_counts(normalize=True))可以发现,数据集无缺失值,质量良好,无重复样本,目标变量分布:75%正常,25%贫血(轻微不平衡)。
3.3 探索性数据分析(EDA)
3.3.1 目标变量分布可视化
# 创建目标变量分布图
fig, axes = plt.subplots(1, 2, figsize=(15, 6))# 贫血分布饼图
anaemic_counts = df['Anaemic'].value_counts()
colors = ['#ff9999', '#66b3ff']
axes[0].pie(anaemic_counts.values, labels=anaemic_counts.index, autopct='%1.1f%%', colors=colors, startangle=90)
axes[0].set_title('贫血分布', fontsize=14, fontweight='bold')# 贫血分布柱状图
sns.countplot(data=df, x='Anaemic', palette=['#ff9999', '#66b3ff'], ax=axes[1])
axes[1].set_title('贫血样本数量', fontsize=14, fontweight='bold')
axes[1].set_xlabel('贫血状态')
axes[1].set_ylabel('样本数量')plt.tight_layout()
plt.show()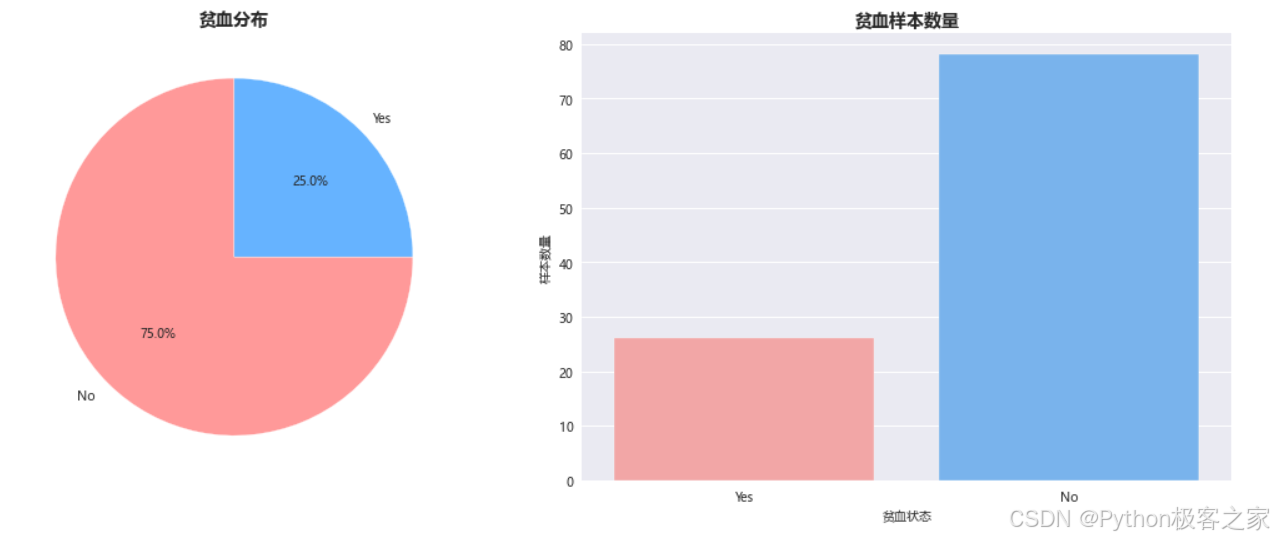
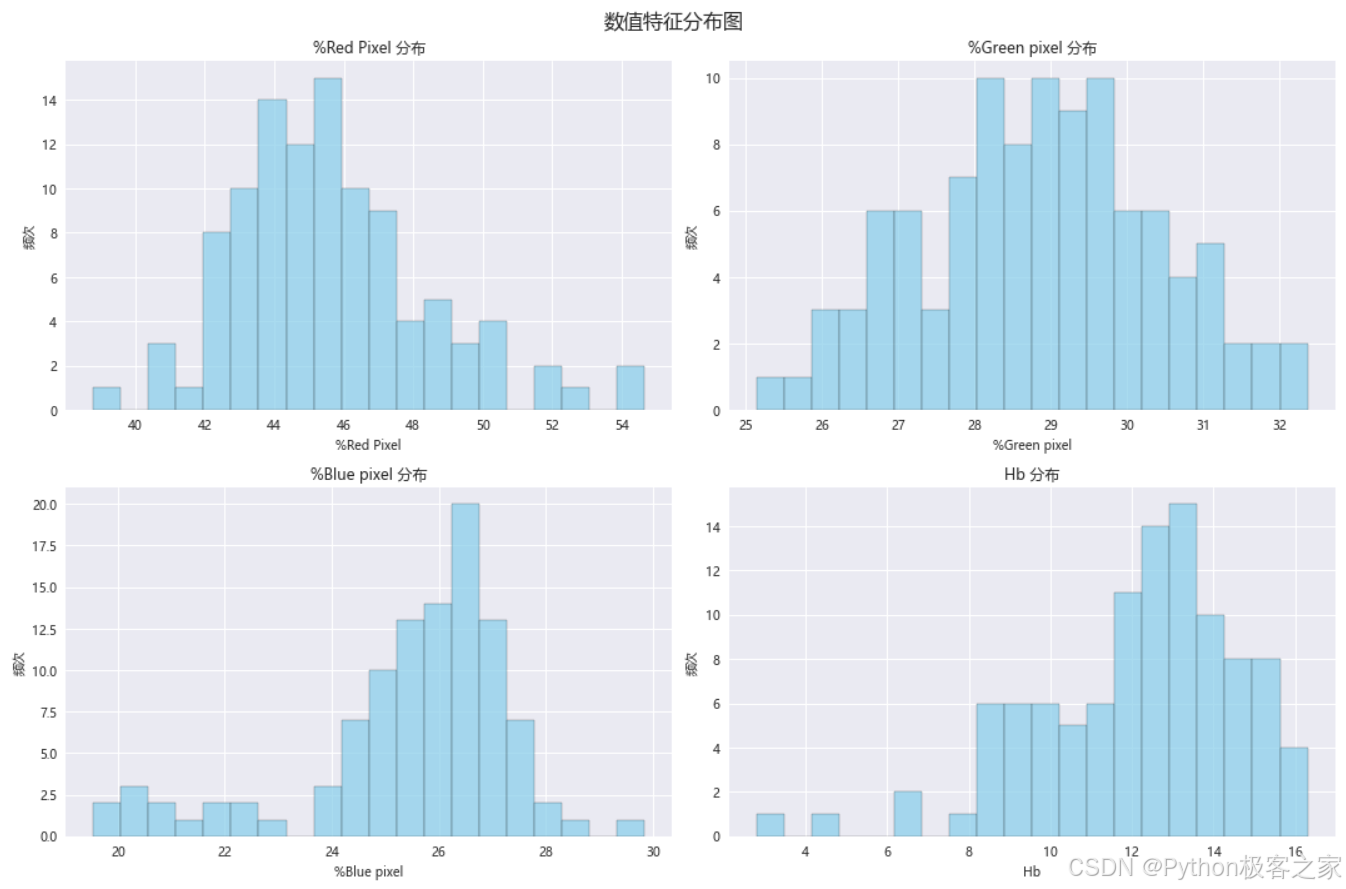
3.3.2 特征分布分析
数值特征的分布图:
按贫血状态分组的特征分布:
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
fig.suptitle('按贫血状态分组的特征分布', fontsize=16)for i, feature in enumerate(numeric_features):row = i // 2col = i % 2# 箱线图sns.boxplot(data=df, x='Anaemic', y=feature, ax=axes[row, col])axes[row, col].set_title(f'{feature} vs 贫血状态')plt.tight_layout()
plt.show()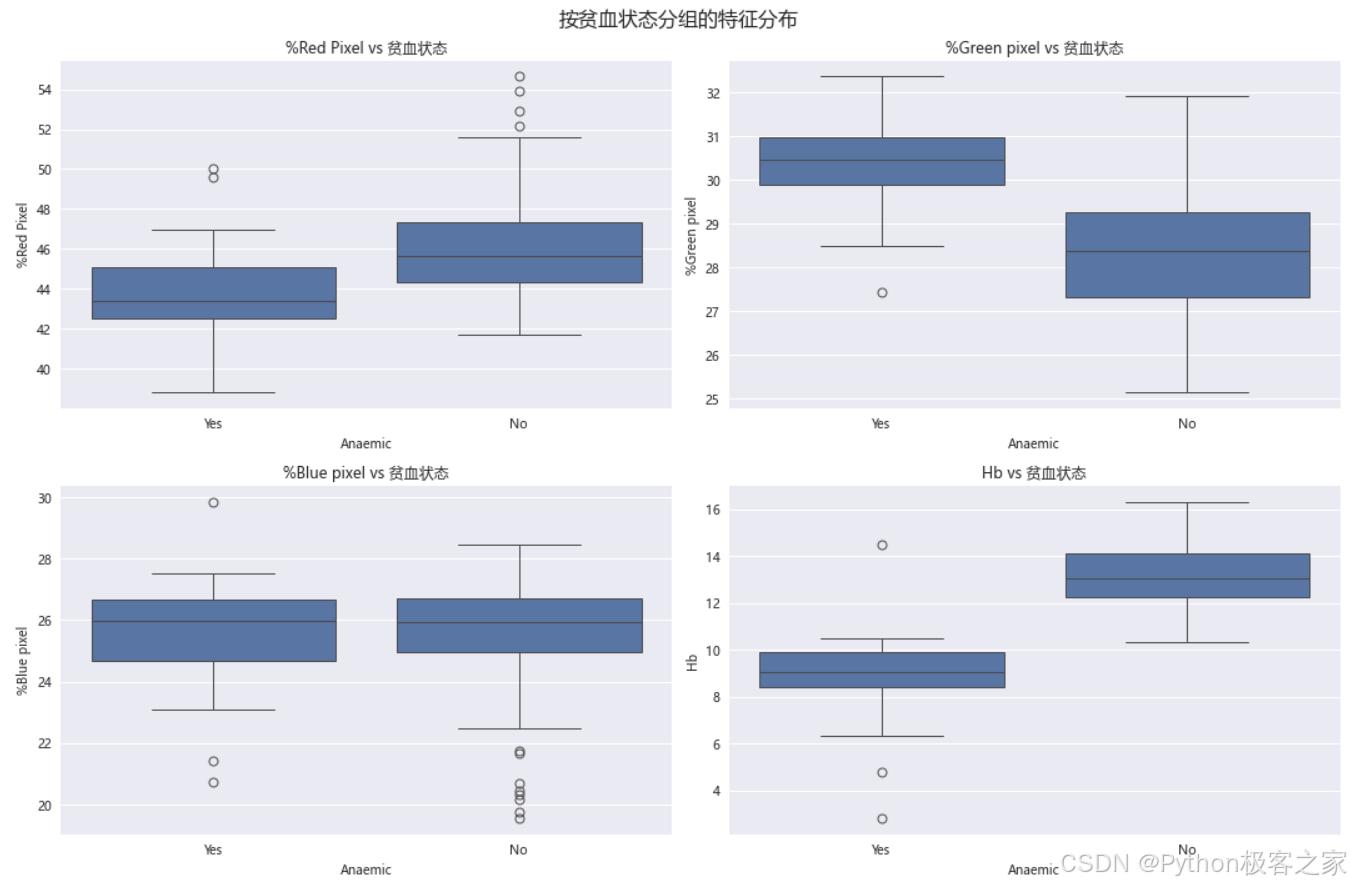
3.3.3 特征相关性分析
# 创建数值数据的相关性矩阵
correlation_matrix = df[numeric_features].corr()plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0, square=True, linewidths=0.5)
plt.title('特征相关性热力图')
plt.show()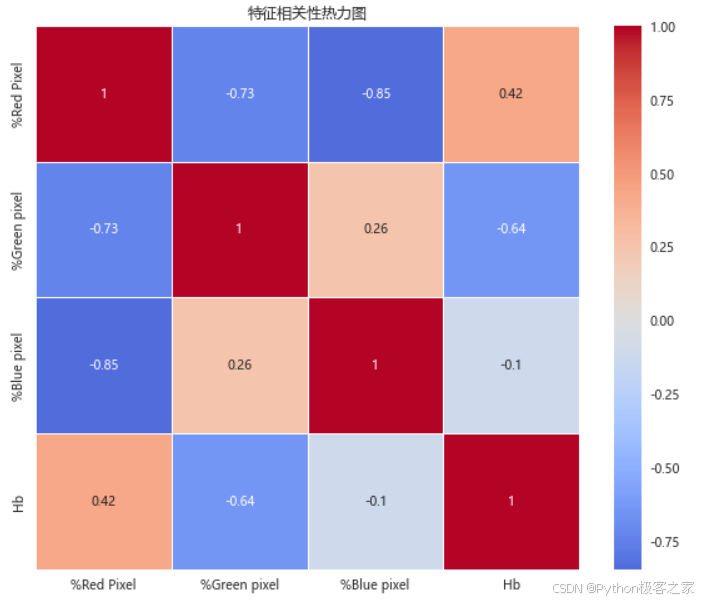
3.3.4 性别与贫血的关系分析
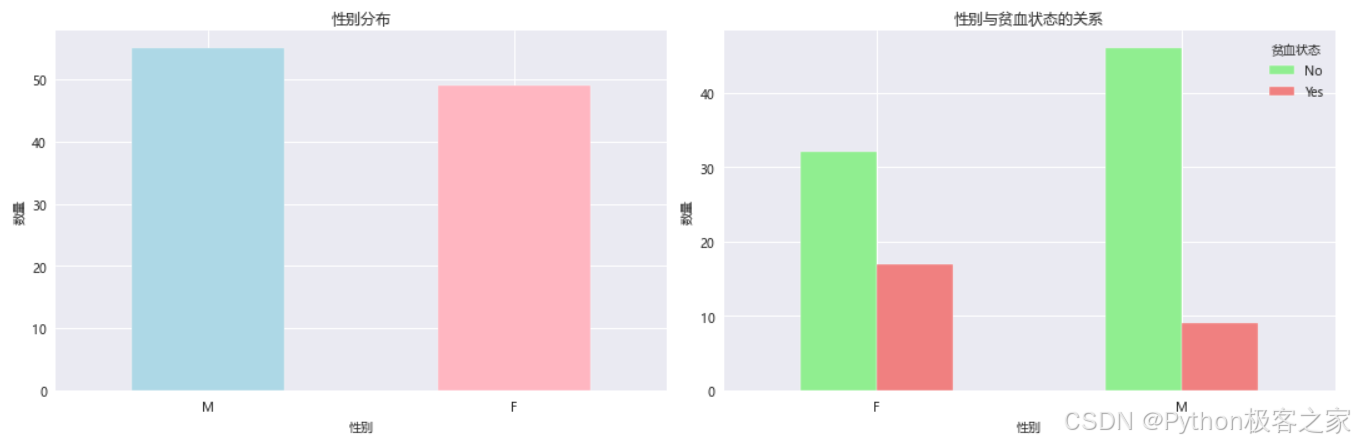
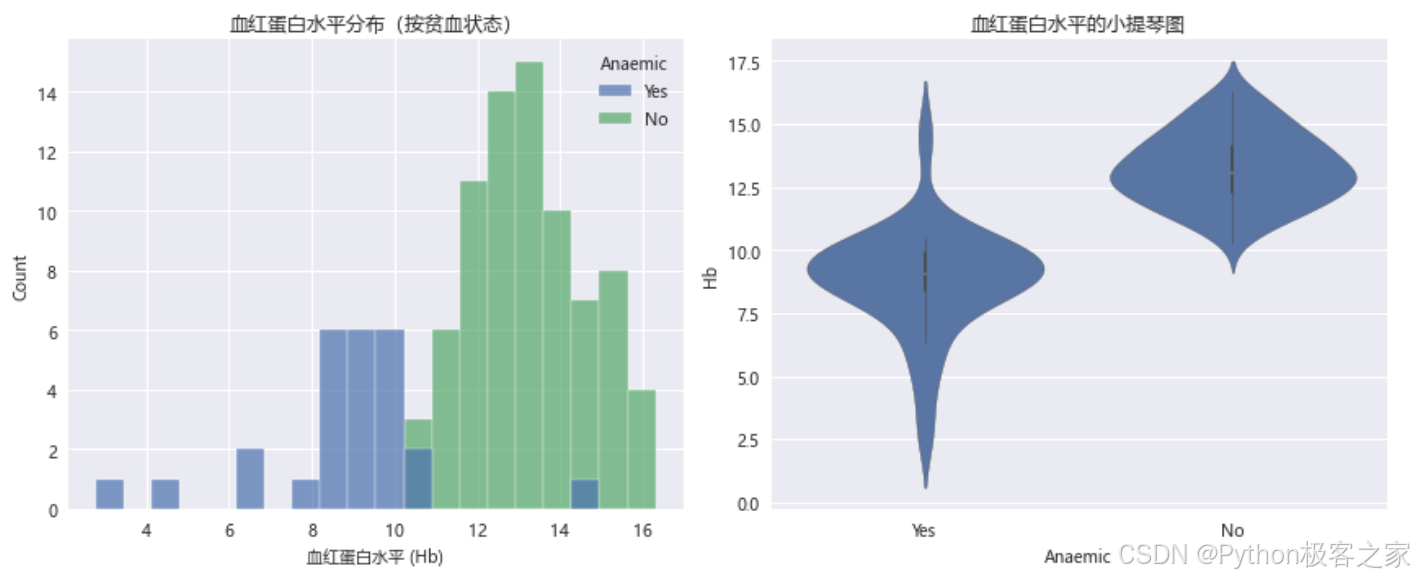
3.3.5 血红蛋白水平分析
3.4 数据预处理与特征工程
# 对性别进行编码
le_sex = LabelEncoder()
df_processed['Sex_encoded'] = le_sex.fit_transform(df_processed['Sex'])# 对目标变量进行编码
le_anaemic = LabelEncoder()
df_processed['Anaemic_encoded'] = le_anaemic.fit_transform(df_processed['Anaemic'])# 创建新特征
df_processed['RGB_ratio'] = df_processed['%Red Pixel'] / (df_processed['%Green pixel'] + df_processed['%Blue pixel'])
df_processed['RG_ratio'] = df_processed['%Red Pixel'] / df_processed['%Green pixel']......print("特征工程后的数据形状:", df_processed.shape)
print("\n新增特征:")
print(df_processed[['RGB_ratio', 'RG_ratio', 'Total_RGB']].head())3.5 模型训练与优化
# 创建XGBoost分类器
xgb_model = xgb.XGBClassifier(objective='binary:logistic',random_state=42,eval_metric='logloss'
)# 训练模型
xgb_model.fit(X_train, y_train)# 预测
y_pred = xgb_model.predict(X_test)
y_pred_proba = xgb_model.predict_proba(X_test)[:, 1]# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
auc_score = roc_auc_score(y_test, y_pred_proba)print(f"测试集准确率: {accuracy:.4f}")
print(f"AUC得分: {auc_score:.4f}")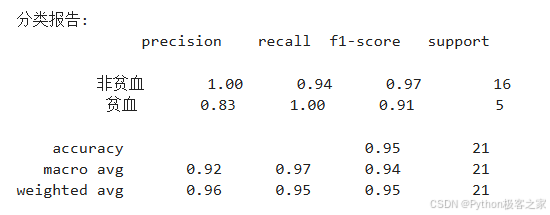
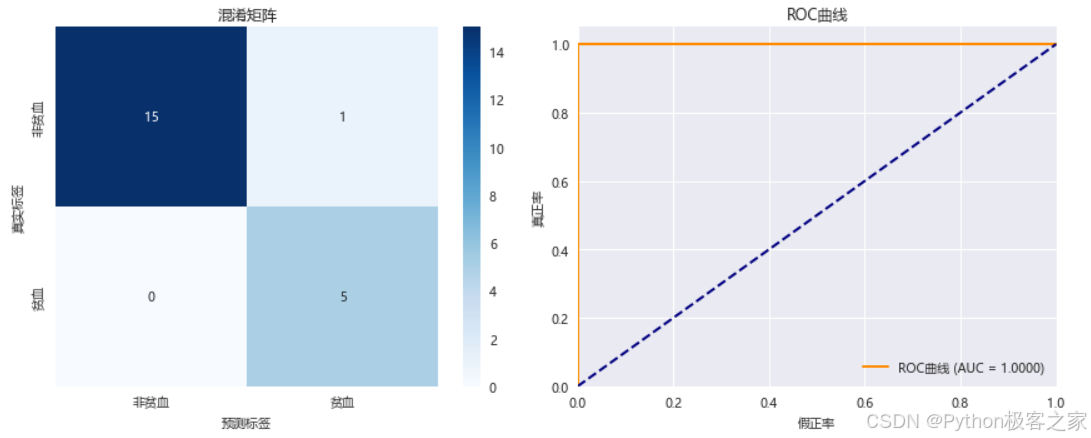
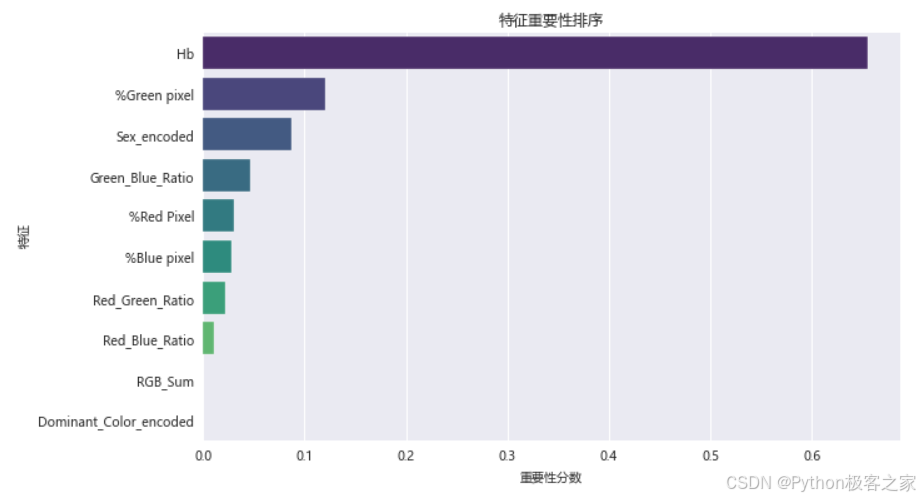
根据模型分析,各特征的重要性排序为:
- 血红蛋白水平 (Hb): 最重要的预测因子
- 红色像素百分比: 与贫血状态密切相关
- RGB比值特征: 新构造的特征提供了额外的预测能力
- 性别: 在贫血预测中起到一定作用
4. 基于机器学习的智能贫血分析预测系统
4.1 首页
系统首页展示贫血预测功能,支持用户注册登录,提供智能算法与精准分析服务。
4.2 用户注册
用户注册页面提供账号创建功能,支持填写用户名、邮箱和密码,确保信息安全合规。
4.3 用户登录
用户登录页面支持账号密码登录,提供安全提示与演示账户,方便快速体验系统功能。
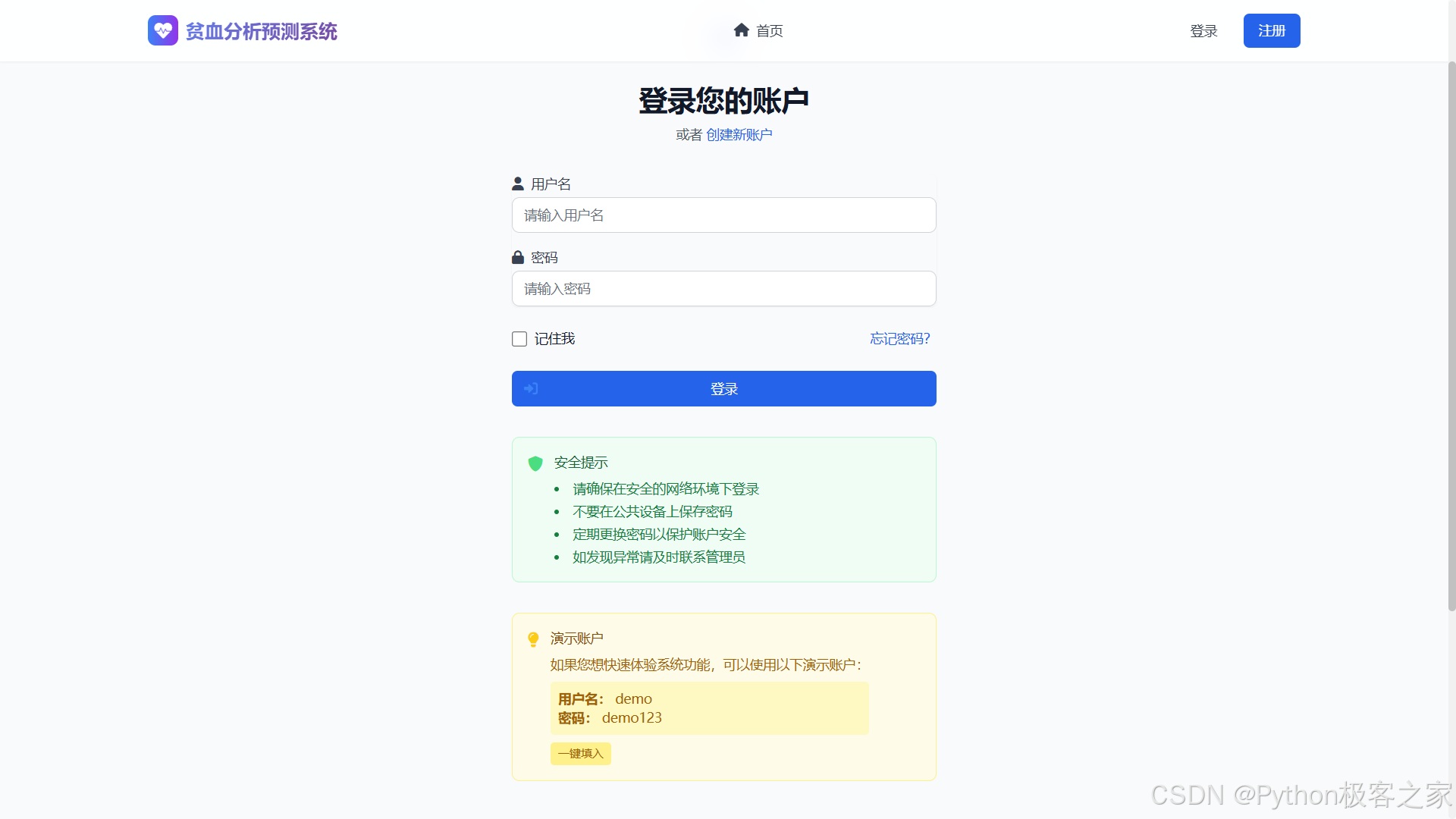
4.4 个人中心仪表盘
个人仪表盘展示预测历史、健康建议与系统状态,支持快速开始新预测和查看分析结果。
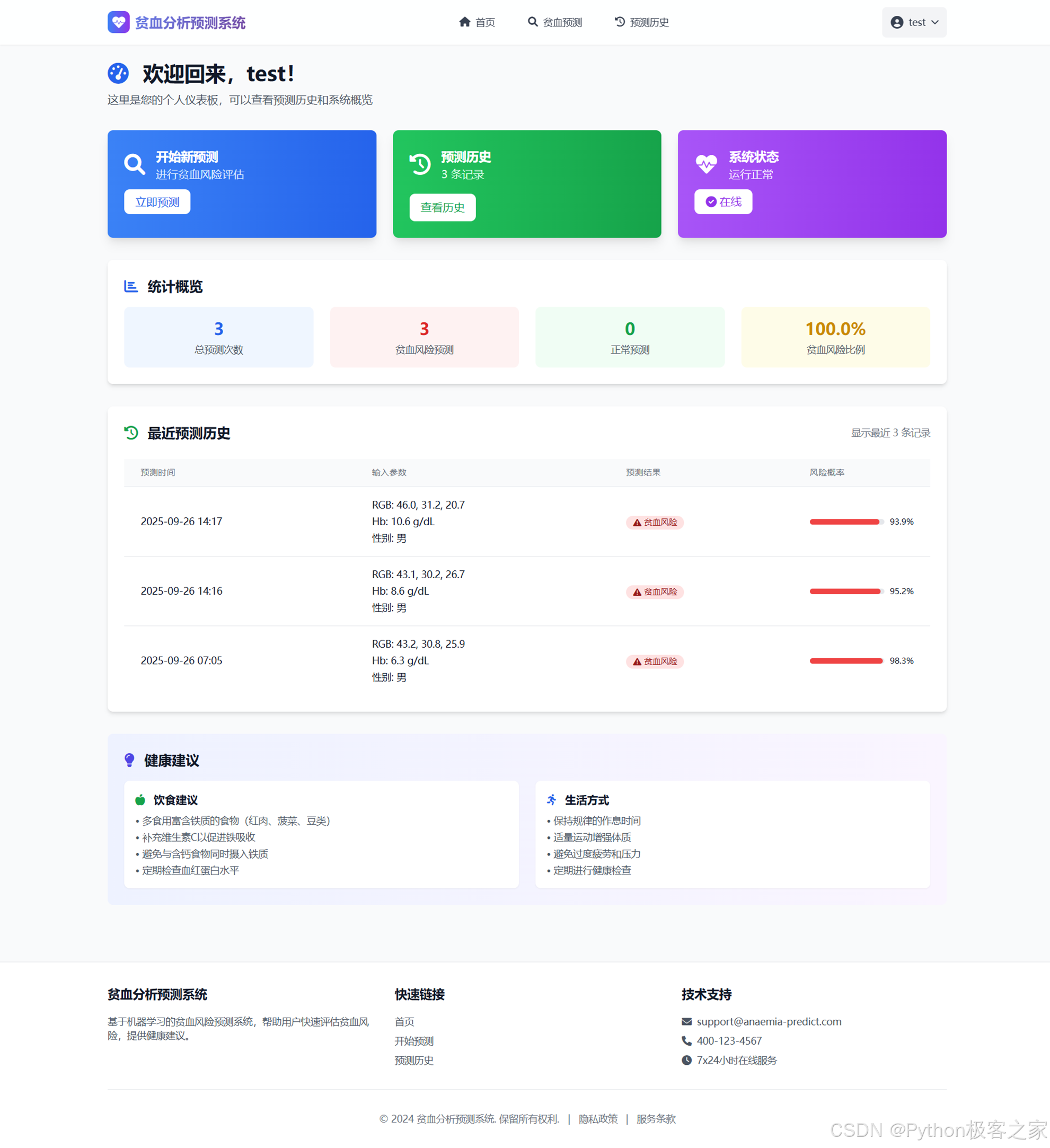
4.5 贫血风险预测
输入RGB值、血红蛋白及性别,系统智能分析贫血风险并提供医疗建议。
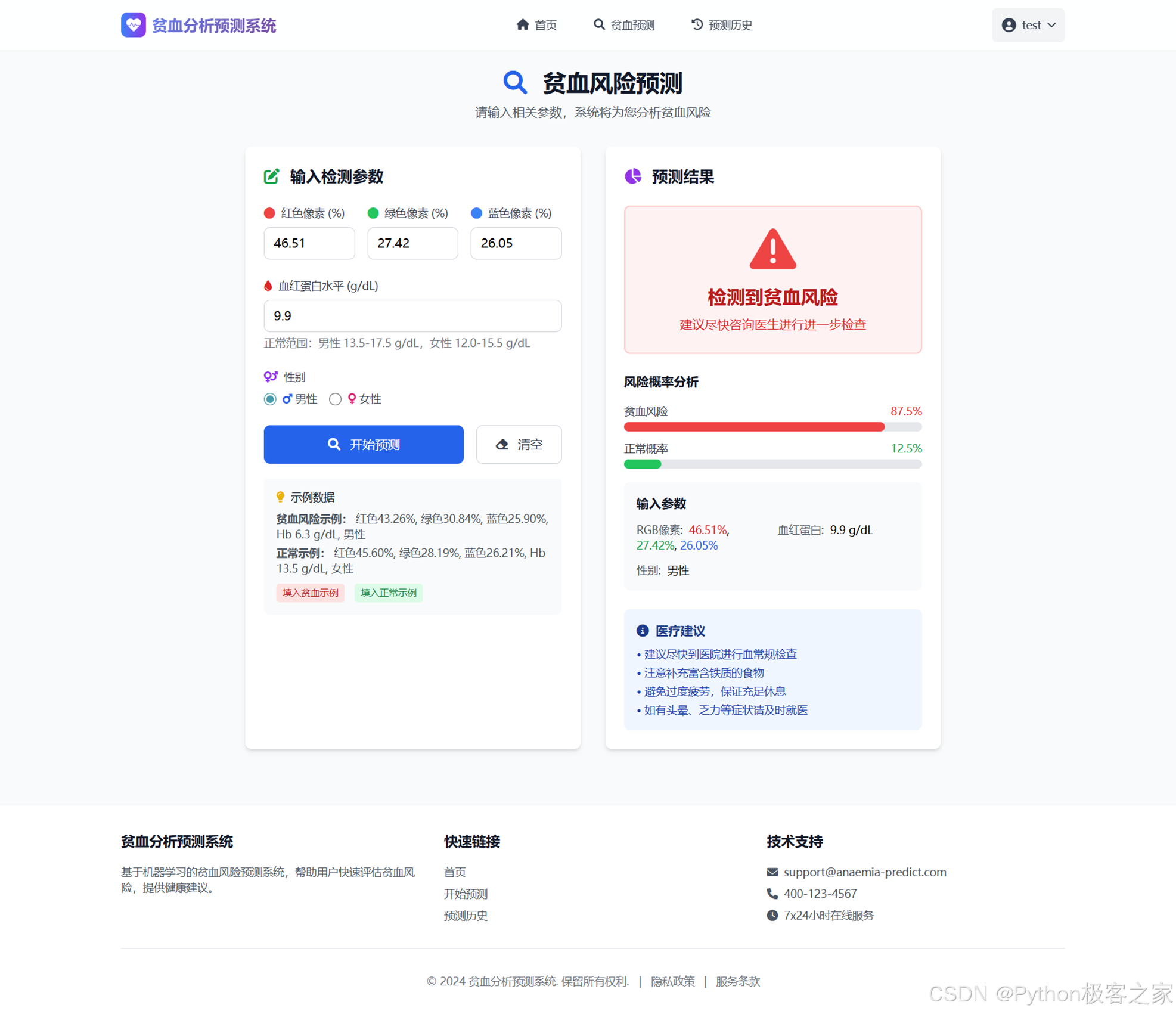
4.6 预测历史记录
展示用户全部预测记录,支持筛选、导出与删除,便于健康数据追踪与管理。
5. 代码框架
6. 总结
本项目旨在开发一个基于机器学习的智能贫血分析预测系统,利用数据挖掘和机器学习技术对患者的健康数据进行分析,提前预测潜在的贫血风险,并提供相应的干预建议。该系统将涵盖数据收集、预处理、特征工程、模型训练、预测和结果展示等多个环节,旨在为医疗保健机构和个人用户提供一个全面的贫血预警平台。通过该系统,用户可以更方便地了解自己的贫血风险,并采取适当的预防措施。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python 精品项目—数据挖掘篇
2. Python 精品项目—深度学习篇
3. Python 精品项目—管理系统篇
