【论文阅读 | WACV 2025 | MCOR:通过跨模态信息互补和余弦相似性通道重采样模块增强的多光谱目标检测】
论文阅读 | WACV 2025 | MCOR:通过跨模态信息互补和余弦相似性通道重采样模块增强的多光谱目标检测
- 1&&2. 摘要&&引言
- 3.方法
- 3.1. 问题定义
- 3.2. 框架概述
- 3.3. 跨模态信息互补(CIC)模块
- 3.4. 余弦相似性通道重采样(CSCR)模块
- 4. 实验
- 4.1. 实现细节
- 4.2. 数据集
- 4.3. 评估指标
- 4.4. 定量结果
- 4.5. 定性结果
- 4.6. 消融研究
- 5. 结论

题目:Multispectral Object Detection Enhanced by Cross-modal Information
Complementary and Cosine Similarity Channel Resampling Modules
期刊:WACV(IEEE/CVF Winter Conference on Applications of Computer Vision)
论文:paper
代码:未开源
年份:2025
1&&2. 摘要&&引言
从不同模态获取的图像可以通过互补可见光(RGB)和红外(IR)图像中的专有信息,有效提高检测模型的准确性和可靠性。然而,整合多模态信息面临以下挑战:
- RGB和IR图像的不同特性导致模态不平衡问题;
- 融合多模态信息会极大地影响检测精度,因为在整合过程中每个模态提供的一些独特信息会丢失;
- RGB和IR图像在融合时保留了各自模态的噪声。
为了解决这些问题,我们提出了一种新颖的多光谱目标检测网络,其主要包含两个组件:
- 跨模态信息互补(CIC)模块,
- 余弦相似性通道重采样(CSCR)模块。
所提出的方法解决了模态不平衡问题,并在特征级别高效地融合了RGB和IR图像。
本文的主要贡献可以总结如下:
- 引入了多光谱互补对象加权重采样(MCOR)模块,它使用跨模态信息互补(CIC)和余弦相似性通道重采样(CSCR)模块有效结合特征,以克服多光谱融合挑战。
- 在多个基准多光谱目标检测数据集和模型上进行了定性和定量评估。所提出的技术比现有方法效果更好。
3.方法
3.1. 问题定义
为了揭示输入之间的关系,研究人员使用复杂的融合模块来充分利用两个模态的信息[1,11,35,40,42]。多光谱目标检测涉及三种融合策略:像素级[2,7,22,26,38]、决策级[3,9,20]和特征级[20,26,29,30,39,44,49]。
在多光谱目标检测中结合RGB和IR传感器利用了不同的光谱信息,增强了检测性能。然而,传统的融合策略如线性组合或直接连接面临挑战。这些方法通常无法区分有价值的信息和噪声,导致对RGB和IR数据的次优使用。传统方法平等对待两个模态的特征,不加区分地合并信息性数据和噪声数据,导致两个主要问题:
- 互补信息融合效率低下,限制了利用不同模态特性来改善检测结果的有效整合。
- 噪声对检测性能的影响加剧,特别是在高干扰环境中。
此外,融入多个模态显著增加了目标检测模型的计算复杂度。虽然使用像特征加法这样的简单操作来减少计算需求,但它们引入了诸如信号干扰、信息丢失和处理复杂背景困难等挑战。这些挑战损害了模型准确识别和分类对象的能力,特别是当背景特征模糊了关键对象信息或对象特征干扰背景时。
为了克服这些问题,我们提出了一种新颖的融合策略,该策略促进了两个模态之间的交互,并有效提取不一致的信息,从而提高了多光谱目标检测的准确性并最小化了噪声的影响。这项工作的目标是通过超越简单加法操作的融合机制,减少信号干扰、信息丢失和背景复杂性对目标检测性能的负面影响。
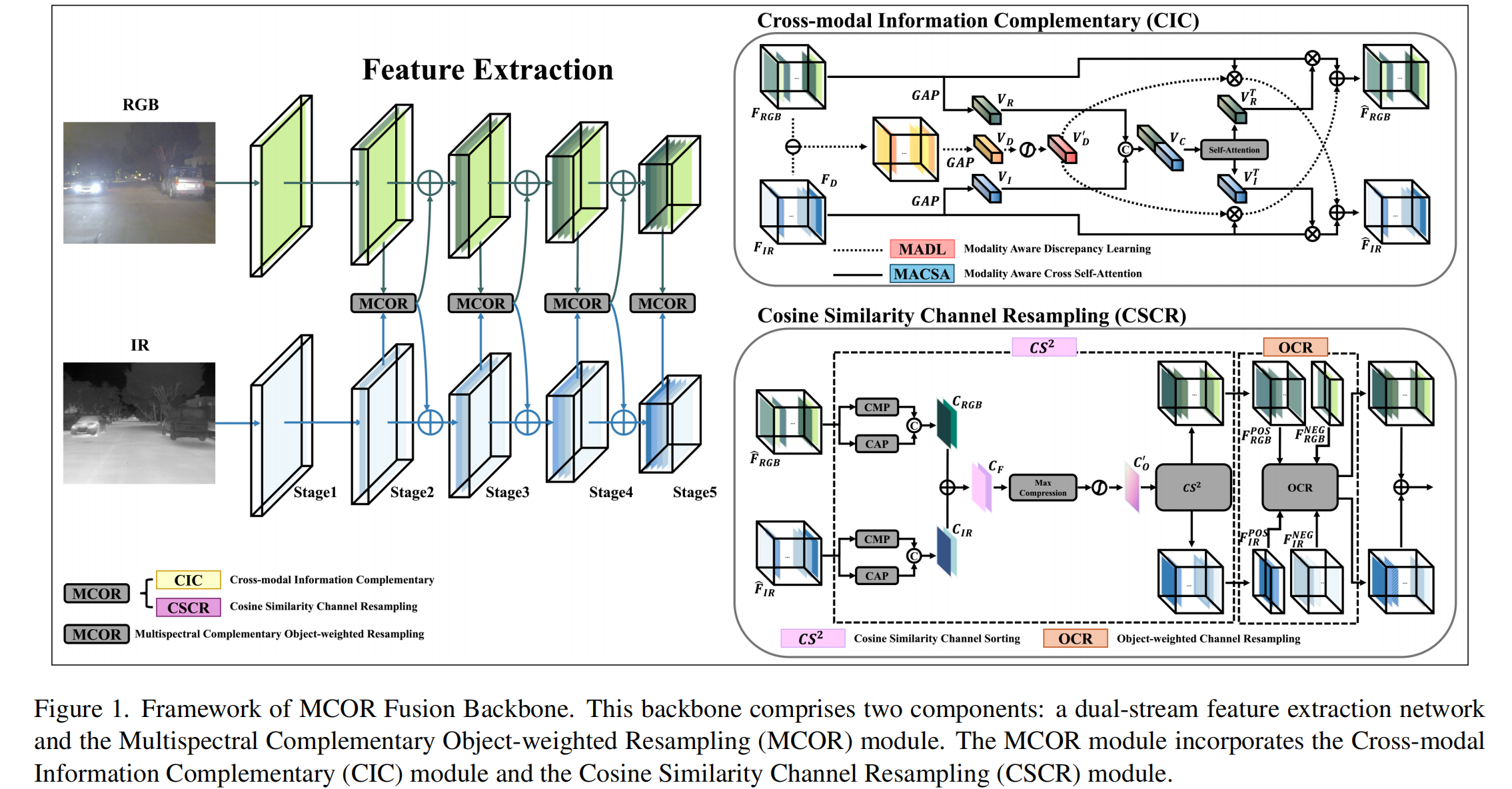
3.2. 框架概述
在本文中,我们利用YOLOv5[5],一个单阶段检测器,通过每帧高速识别多个目标来实现实时目标检测。如图1所示,模型将IR和RGB图像作为输入。主干由两个CSPDarknets53组成,每个有五个阶段。我们使用两个子模块融合每个阶段生成的特征图:跨模态信息互补(CIC)模块和余弦相似性通道重采样(CSCR)模块。CIC模块在保留其独立信息的同时处理每个模态的特征,增强了模型对其独特重要性和相互关系的理解。CSCR模块为每个模态引入了对象加权和背景加权的特征图,保留了关键信息,并为缺乏对象加权图的模态提供了额外见解。融合的特征图是通过聚合两个模态的特征生成的。
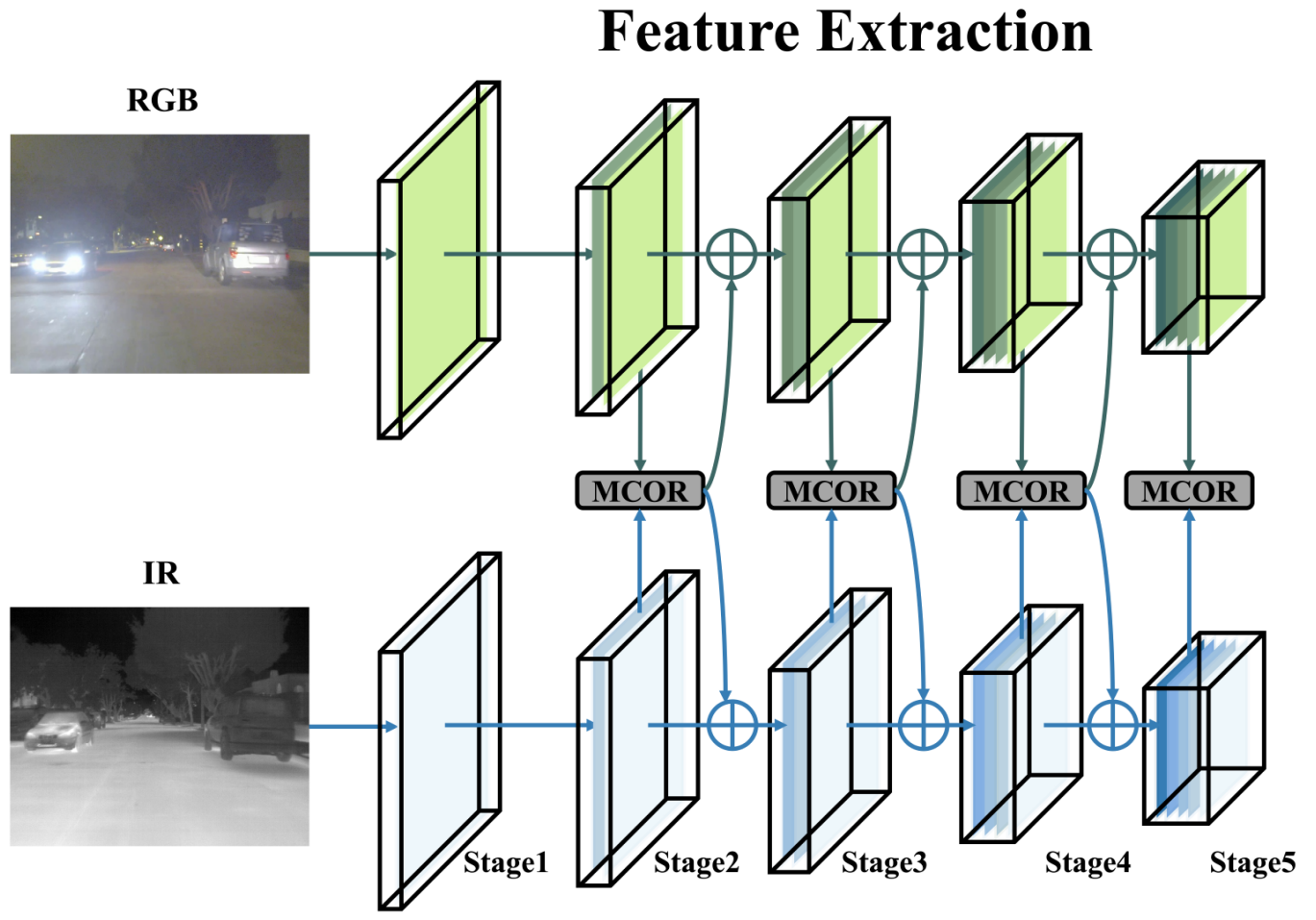
3.3. 跨模态信息互补(CIC)模块
为了解决第3.1节中提到的挑战并有效整合来自两个模态的互补信息,我们提出了一个跨模态信息互补(CIC)模块。该模块利用模态间的交互,通过应用通道注意力和自注意力来捕捉差异,以补充具有不同信息的单模态特征。CIC模块可以分为两个子模块:1) 模态感知差异学习(MADL)模块和 2) 模态感知交叉自注意力(MACSA)模块。
模态感知差异学习(MADL)模块. MADL模块通过强调两个模态特征之间的差异来提取它们的独特信息。这个过程包括减去模态特征以夸大差异,并有选择地融入来自另一模态的互补特征。
模态差异的显式建模增强了网络有效学习和利用互补特征的能力。MADL模块的结构如图1所示。
具体来说,MADL模块将可见光特征 FRGBF_{RGB}FRGB 和IR特征 FIRF_{IR}FIR 作为输入。然后计算 FRGBF_{RGB}FRGB 和 FIRF_{IR}FIR 之间的差异以获得差异特征 FDF_{D}FD。FDF_{D}FD 通过全局平均池化(GAP)[23]进一步编码为全局差异向量 VDV_{D}VD,它代表了跨通道的两个模态之间的差异。MADL模块利用 VDV_{D}VD 通过通道乘法和Sigmoid激活函数对原始特征 FRGBF_{RGB}FRGB 和 FIRF_{IR}FIR 进行加权。这产生了差分放大的模态特征 FRGBMADLF_{RGB}^{MADL}FRGBMADL 和 FIRMADLF_{IR}^{MADL}FIRMADL。最后,FRGBMADLF_{RGB}^{MADL}FRGBMADL 与 FIRF_{IR}FIR 结合以补充 FRGBF_{RGB}FRGB,并且 FIRMADLF_{IR}^{MADL}FIRMADL 与 FRGBF_{RGB}FRGB 结合以补充 FIRF_{IR}FIR。这种自适应学习方法使MADL模块能够有效捕捉跨数据集的通道间依赖关系,从而增强网络的泛化性能。通过融入加权特征,MADL模块确保来自RGB和IR模态的互补信息被适当地放大和整合,有助于网络的整体鲁棒性和性能。
模态感知交叉自注意力(MACSA)模块. MACSA模块通过采用自注意力来整合来自两个模态的信息,使网络能够理解两个光谱之间的交互并捕捉互补信息。此外,它有助于优先处理重要特征同时过滤掉不必要的信息,MACSA模块的结构如图1所示。
具体来说,MACSA模块将可见光特征 FRGBF_{RGB}FRGB 和IR特征 FIRF_{IR}FIR 作为输入。然后,FRGBF_{RGB}FRGB 和 FIRF_{IR}FIR 分别通过GAP编码为向量 VRV_{R}VR 和向量 VIV_{I}VI。接着,VRV_{R}VR 和 VIV_{I}VI 被连接起来,结果向量通过自注意力学习它们之间的交互,产生向量 VCTV_{C}^{T}VCT。VCTV_{C}^{T}VCT 然后沿通道切片以获得 VRTV_{R}^{T}VRT 和 VITV_{I}^{T}VIT,使它们恢复到每个模态现有向量的大小。MACSA模块可以有效地利用 VRTV_{R}^{T}VRT 和 VITV_{I}^{T}VIT 分别对来自 FRGBMADLF_{RGB}^{MADL}FRGBMADL 和 FIRMADLF_{IR}^{MADL}FIRMADL 的特征进行加权,通过通道乘法实现。这产生了差分放大的模态特征 FRGBMACSAF_{RGB}^{MACSA}FRGBMACSA 和 FIRMACSAF_{IR}^{MACSA}FIRMACSA。最后,FRGBMADLF_{RGB}^{MADL}FRGBMADL 与 FRGBMACSAF_{RGB}^{MACSA}FRGBMACSA 互补,并且 FIRMADLF_{IR}^{MADL}FIRMADL 与 FIRMACSAF_{IR}^{MACSA}FIRMACSA 互补。MACSA模块中自注意力的利用有效地利用了数据集中多个光谱的独特特征,从而产生了更复杂的特征表示。通过分别用 VRTV_{R}^{T}VRT 和 VITV_{I}^{T}VIT 加权 FRGBMADLF_{RGB}^{MADL}FRGBMADL 和 FIRMADLF_{IR}^{MADL}FIRMADL,该模块确保了互补信息的适当放大和整合,有助于网络在捕捉RGB和IR图像之间复杂关系方面的整体有效性。
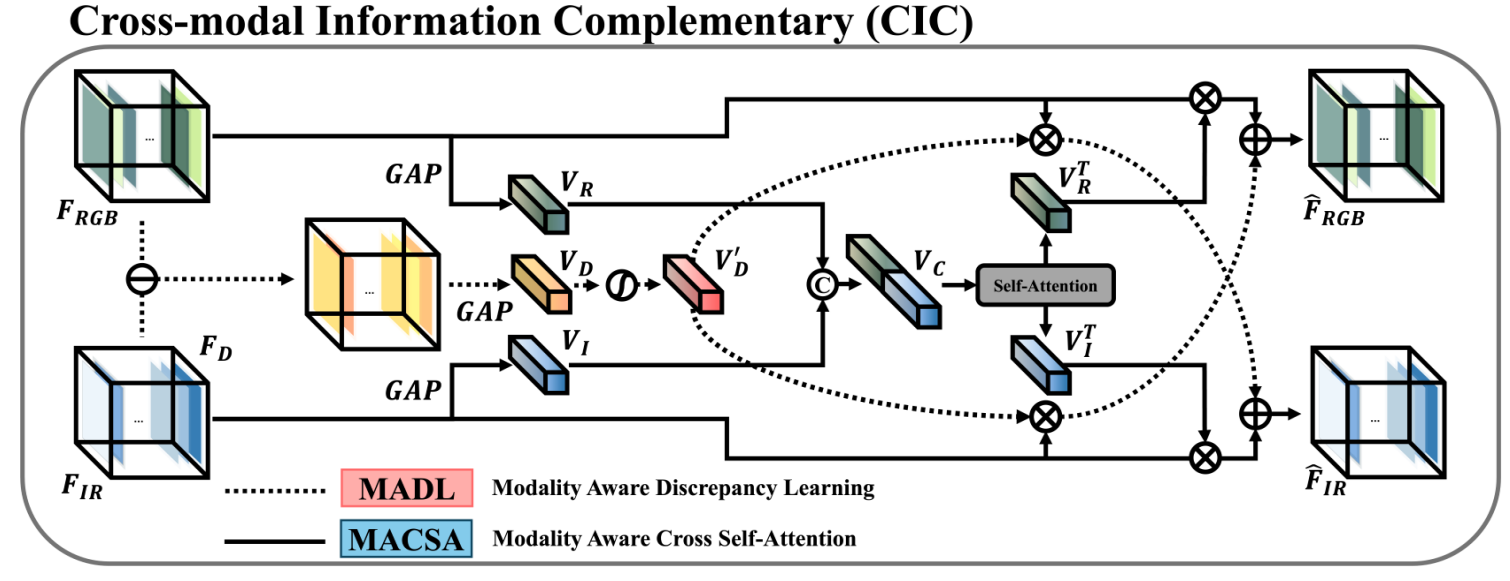
3.4. 余弦相似性通道重采样(CSCR)模块
余弦相似性通道重采样(CSCR)模块应用余弦相似性和最大压缩[16]来基于以对象为中心的特征图对齐通道,并为缺乏对象信息的模态补充特征。CSCR模块可以分为两个子模块:1) 基于余弦相似性的通道排序(CS²)模块和 2) 对象加权通道重采样(OCR)模块。
基于余弦相似性的通道排序(CS²)模块. CS²模块首先创建一个以对象为中心的特征图,作为后续操作的参考。这个以对象为中心的特征图对于计算每个模态每个通道的余弦相似度并根据它们与以对象为中心的特征图的相似性对通道进行排序至关重要。CS²模块的结构如图1所示。具体来说,CS²模块将 F^RGB\widehat{F}_{RGB}FRGB 和 F^IR\widehat{F}_{IR}FIR 作为输入,这些输入来自本文提出的CIC模块。然后,对每个模态信息执行通道最大池化(CMP)和通道平均池化(CAP)操作,以获得 FRGBCAPF_{RGB}^{CAP}FRGBCAP, FRGBCMPF_{RGB}^{CMP}FRGBCMP, FIRCAPF_{IR}^{CAP}FIRCAP, 和 FIRCMPF_{IR}^{CMP}FIRCMP。每个模态的信息使用 CRGBC_{RGB}CRGB 和 CIRC_{IR}CIR 进行连接,得到 CFC_{F}CF,并应用最大压缩将两个通道压缩为一个通道,得到 COC_{O}CO,它代表以对象为中心的通道,并馈入Sigmoid函数以获得 CO′C_{O}^{'}CO′。
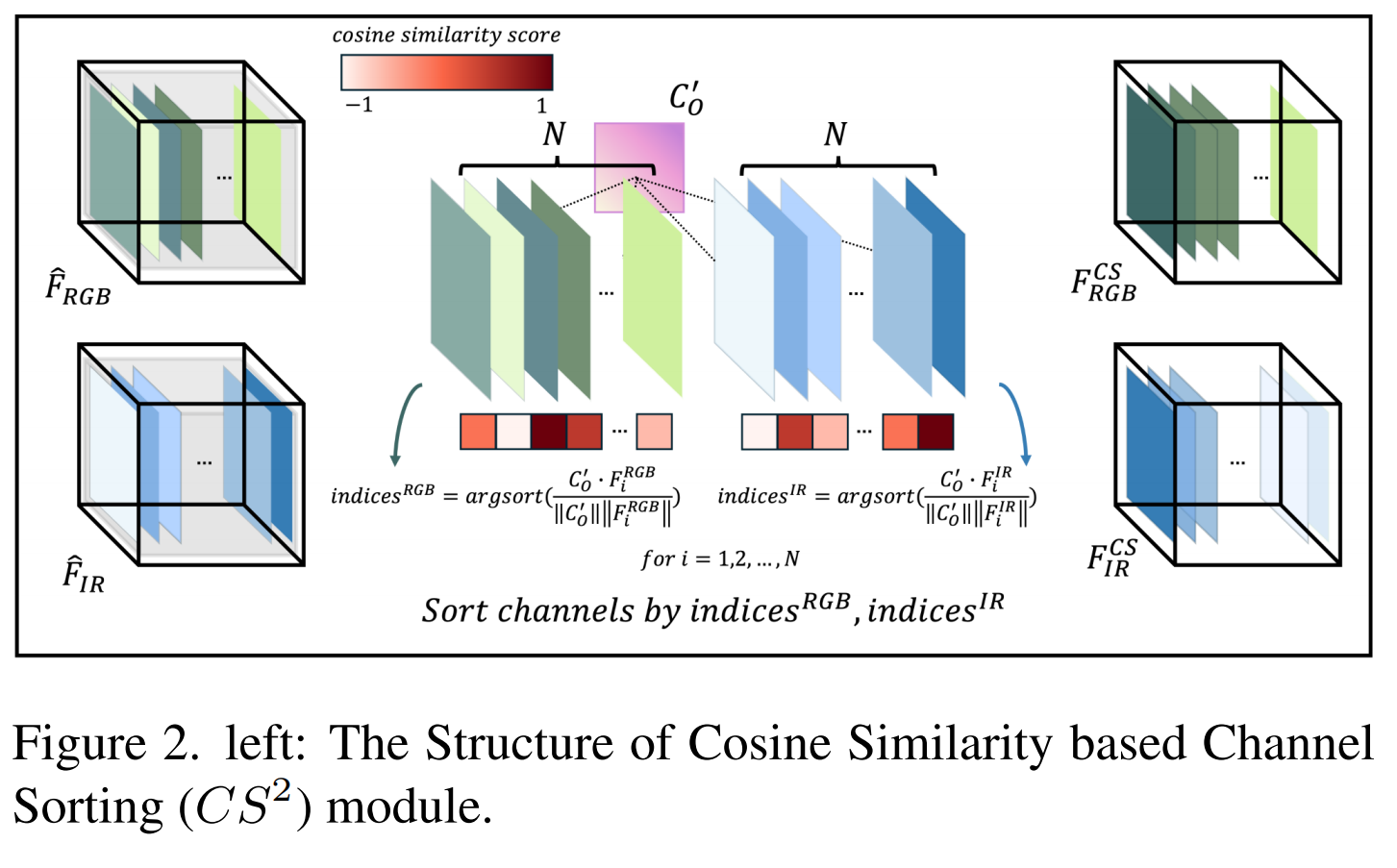
图2显示了基于余弦相似性的排序机制,从最高值开始。排序后,每个模态的特征图被组织成前面的以对象为中心的特征图。这确保了在两个模态的加法操作过程中,以对象为中心的特征图相互贡献,强调重要信息同时排除不相关的特征和噪声。具体来说,它计算 CO′C_{O}^{'}CO′ 和 Fi{RGB,IR}F_{i}^{\{R G B, I R\}}Fi{RGB,IR} (对于每个 i=1,2,…,Ni=1,2,\ldots, Ni=1,2,…,N)之间的余弦相似度,获得基于余弦相似性对齐的特征图 FRGBCSF_{R G B}^{C S}FRGBCS 和 FIRCSF_{I R}^{C S}FIRCS。
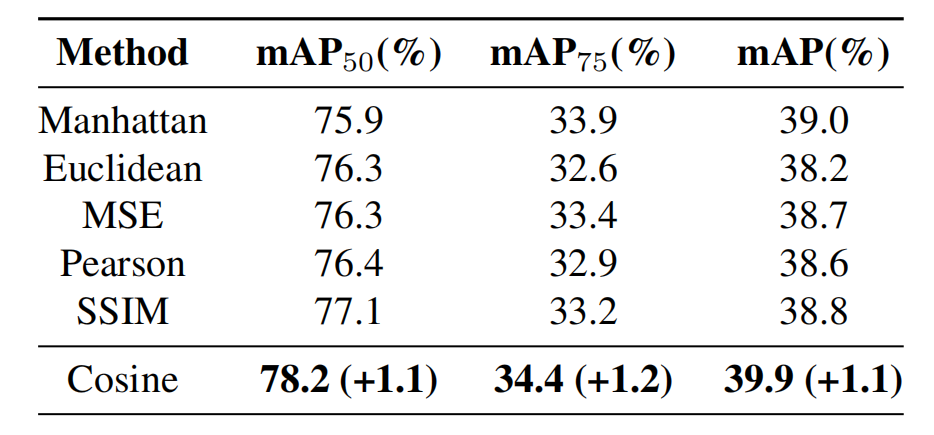
表1. 使用FLIR数据集,在各种基于相似性的方法下的性能比较,指标为 mAP50,mAP75mAP_{50}, mAP_{75}mAP50,mAP75 和 mAP。
为什么使用余弦相似性? 余弦相似度测量两个非零向量之间的角度,强调结构和方向特征而不是强度或大小。通过归一化向量,它确保了比较独立于光照或尺度,使其对成像条件的变化具有鲁棒性。这种对向量方向的关注突出了几何模式,使其在比较图像形状方面非常有效。
定量评估表明,余弦相似性在所提出的模型中优于其他方法,将 mAP50,mAP75mAP_{50}, mAP_{75}mAP50,mAP75 和 mAP 指标分别提高了 1.1%p,1.2%p1.1\% p, 1.2\% p1.1%p,1.2%p 和 1.1%p1.1\% p1.1%p。其鲁棒性和准确性使其成为CS²模块最可靠的度量标准。
对象加权通道重采样(OCR). 引入OCR模块是为了解决每个模态的特征图在经过主干网络后,其以对象为中心和以背景为中心的特征数量可变的问题。目的是增强对象的识别和分类,特别是在复杂背景或多个对象重叠的场景中。图3中所示的OCR模块的结构由以下公式定义。
OCR模块接收两个模态特征图 FRGBCSF_{R G B}^{C S}FRGBCS 和 FIRCSF_{I R}^{C S}FIRCS,它们的通道基于余弦相似性对齐。FRGBCSF_{R G B}^{C S}FRGBCS 和 FIRCSF_{I R}^{C S}FIRCS 根据余弦相似性是否大于零被划分为正样本(FRGBposF_{R G B}^{p o s}FRGBpos, FIRposF_{I R}^{\text{pos}}FIRpos) 和负样本(FRGBneg,FIRnegF_{R G B}^{\text{neg}}, F_{I R}^{\text{neg}}FRGBneg,FIRneg)。为了确定每个模态的正样本数量 NRGBN_{R G B}NRGB 和 NIRN_{I R}NIR,我们利用 1(⋅)1(\cdot)1(⋅) 函数,该函数针对 CO′C_{O}^{'}CO′ 和 FRGB,IRCSF_{R G B, I R}^{C S}FRGB,IRCS 之间的每个给定余弦相似性分数 SRGBS_{R G B}SRGB 和 SIRS_{I R}SIR 识别大于零的值。
为了匹配每个模态的正负样本数量,它以两个模态的正样本 FRGBposF_{R G B}^{\text{pos}}FRGBpos 和 FIRposF_{I R}^{\text{pos}}FIRpos 作为输入。使用 NRGBN_{R G B}NRGB 和 NIRN_{I R}NIR 来寻找差异 Nextra=∣NRGB−NIR∣N_{\text{extra}}=\left|N_{R G B}-N_{I R}\right|Nextra=∣NRGB−NIR∣。如果 NextraN_{\text{extra}}Nextra 非零,则使用最大压缩技术为两个模态 FRGBposF_{RGB}^{pos}FRGBpos 和 FIRposF_{IR}^{pos}FIRpos 生成不匹配的以对象为导向的特征图 FFextraF_{F}^{\text{extra}}FFextra,数量为缺失的通道数。然后将 FextraF_{extra}Fextra 连接到正样本特征图不足的模态上,并且在负样本中丢弃余弦相似性为零的通道,数量为添加的通道数。
CSCR模块强调以对象为中心的特征图,移除不必要的特征图,并有效增强对象和背景之间的清晰度,同时减少噪声。通过整合来自两个模态的信息并强调以对象为中心的特征图,所提出的CSCR模块有助于提高多光谱目标检测的准确性。
4. 实验
4.1. 实现细节
我们所有的网络都是使用Python开发的,源代码和预训练模型均可公开获取。在训练阶段的每个周期,我们保留10%的训练图像用于验证。我们使用了原始YOLOv5相同的超参数设置。所有模型最多训练100个周期,批量大小为16,输入图像尺寸为640x640。性能评估在单个NVIDIA GTX 3090 GPU上进行。这种方法保证了与先前最先进方法的公平比较。
4.2. 数据集
LLVIP LLVIP数据集对多光谱目标检测很重要,包含来自26个地点监控摄像头的15,488对RGB和IR图像,大多在弱光条件下。它包括12,025对用于训练,3,463对用于测试,重点关注“行人”类别,用于城市安全和监控。
FLIR FLIR数据集广泛用于多光谱目标检测,包含5,142对齐的RGB-IR图像对,从汽车驾驶员视角拍摄,涵盖白天和夜间场景。它包括4,129对用于训练,1,013对用于测试,聚焦于三种对象类型:人、汽车和自行车(排除了狗类别)。
M3FD M3FD数据集包括8,400张图像,其中4,200对RGB和IR图像用于融合和检测任务,另外600张图像仅用于融合。它包含34,407个标注实例,涵盖六个类别:人、汽车、公共汽车、摩托车、灯和卡车。
VEDAI 航空影像中的车辆检测(VEDAI)数据集包含1,268对RGB-红外图像中的超过3,700个标注目标,对车辆进行分类,如汽车、卡车、飞机和船只。图像标准化为1024x1024分辨率,标注为水平框。
KAIST KAIST数据集包括95,328对可见光和红外图像,带有103,128个边界框,标识了1,182名行人。由于初始标注存在问题,训练使用了改进的标注[26,46],增强了数据可靠性和模型准确性。测试集有2,252帧,从每20个视频帧中选取,包含1,455张白天图像和797张夜间图像,以根据一天中的时间评估算法性能。
4.3. 评估指标
目标检测模型的评估通过平均精度(mAP)来衡量,它评估检测准确性。真正例(TP)是正确识别且交并比(IoU)高于阈值的对象,而假正例(FP)是错误检测,假负例(FN)是漏检。mAP涉及精确度(正确预测对象与所有预测的比率)和召回率(检测到的实际对象的比例)。使用特定的IoU阈值,如mAP.5, mAP.75和mAP(在0.5到0.95的IoU阈值上平均精度),用于LLVIP、FLIR、M3FD和VEDAI等数据集。
对于KAIST数据集,我们使用对数平均漏检率(MR⁻²)来衡量行人检测性能[12]。MR⁻²在[10⁻², 10⁰]范围内均匀分布在对数空间中的九个每图像误报数(FPPI)上平均漏检率。
4.4. 定量结果
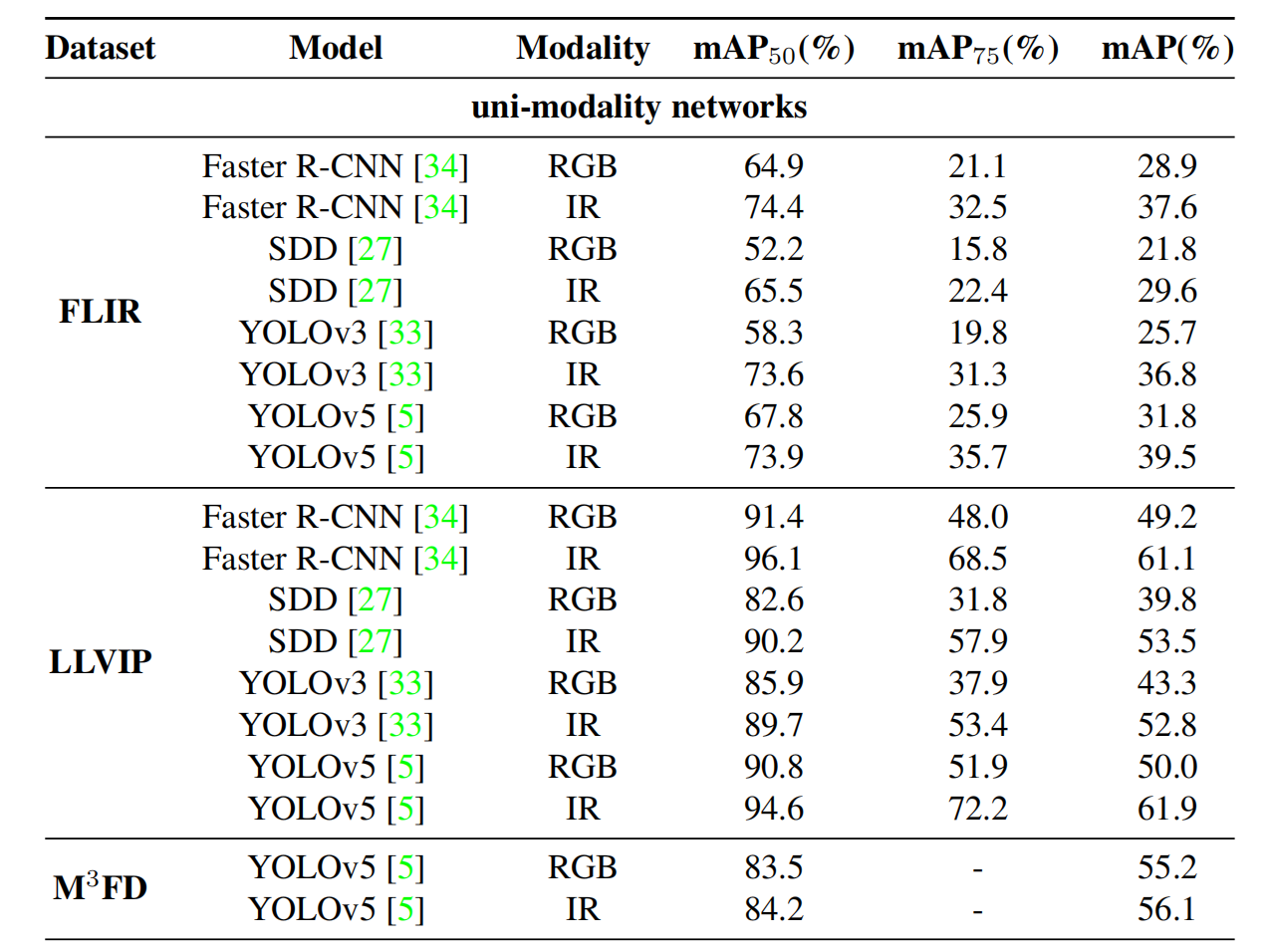
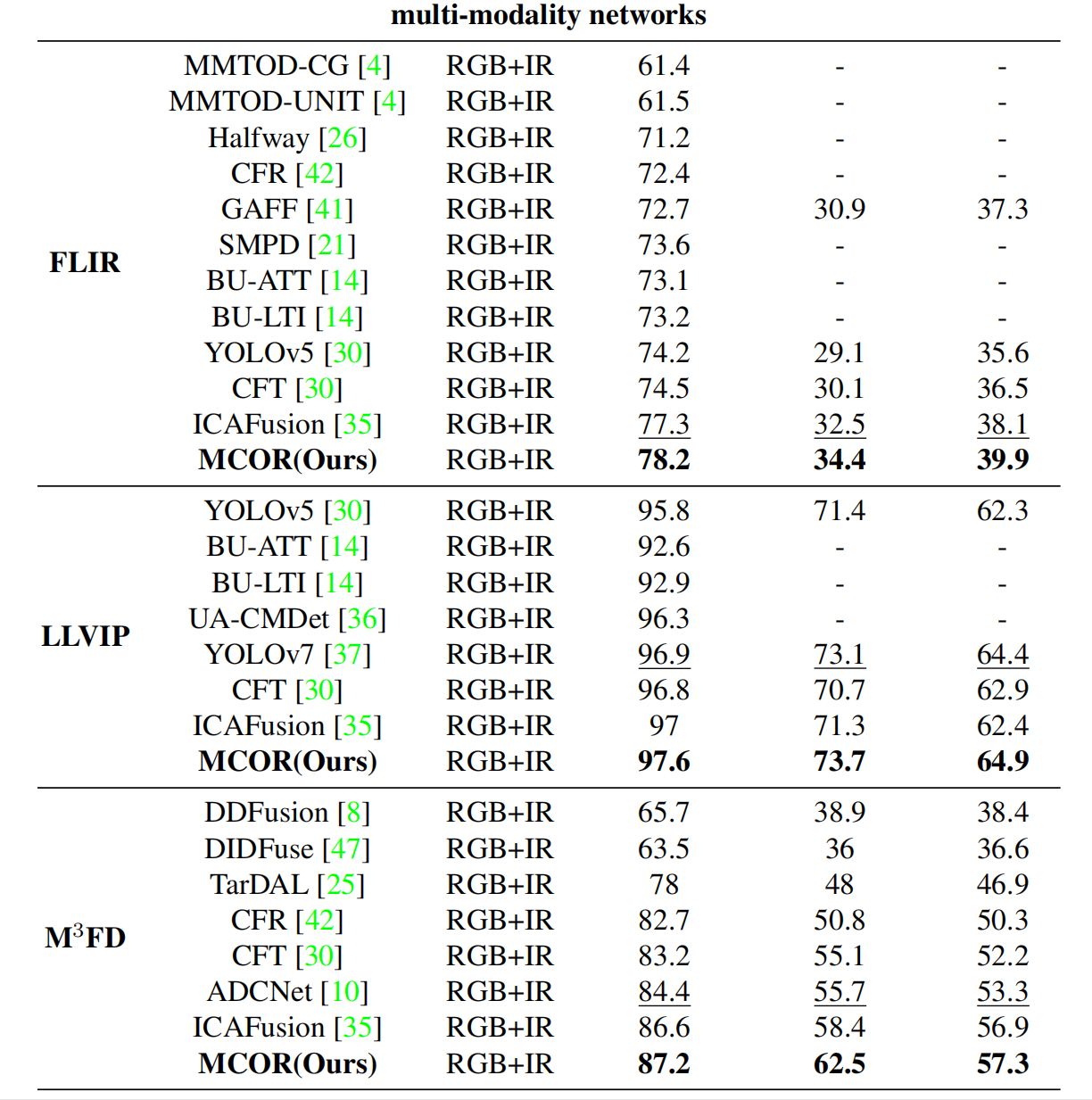
表2展示了使用FLIR、LLVIP和M3FD数据集的最先进(SOTA)模型的比较分析。提出的MCOR方法在AP50指标上优于基线网络YOLOv5(RGB),在FLIR上提高了9.5%p,在LLVIP上提高了6.8%p,在M3FD上提高了3.7%p。它也比YOLOv5(IR)在FLIR上高出3.4%p,在LLVIP和M3FD数据集上高出3.0%p。这些结果证明了MCOR在整合两个模态的信息、提高检测准确性方面的有效性。
与多模态模型相比,MCOR在AP50上超过了基于YOLOv5的简单融合模型,在FLIR上高出3.1%p,在LLVIP上高出1.8%p,在M3FD上高出3.4%p。这一改进归因于模态间的有效交互、不一致信息的有效提取以及噪声的减少。
MCOR在其他SOTA多模态模型上也表现出色,在所有数据集的AP50、AP75和mAP上均取得了优异的结果。具体来说,在FLIR数据集上,MCOR超过了GAFF 4.6%p和CFT 3.2%p。在LLVIP上,它超过了UA-CMDet 1.3%p和CFT 0.8%p。在M3FD上,它的表现优于CFT 4%p和ADCNet 2.8%p。这些结果强调了MCOR在各种数据集上的强大泛化能力和SOTA性能。
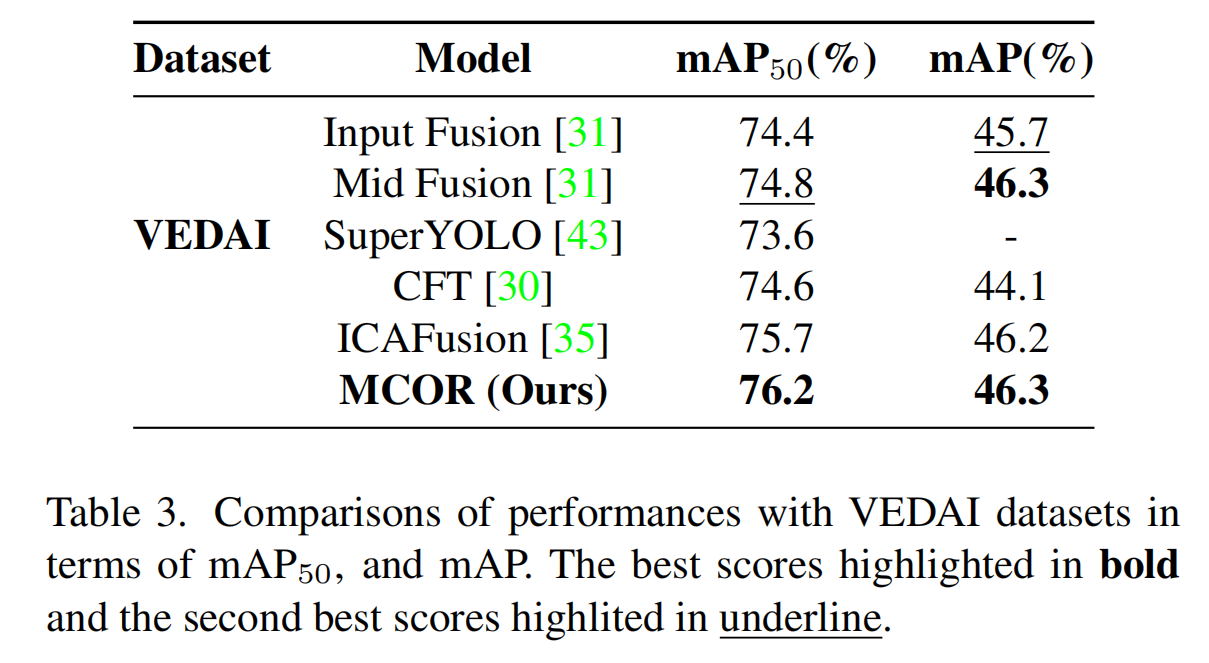
如表3所示,MCOR在VEDAI数据集上实现了最高的mAP50,达到76.2%,优于输入融合(Input Fusion)、中间融合(Mid Fusion)、SuperYOLO和CFT等模型。在IoU阈值为0.5时,这种卓越的检测精度突出了MCOR在该指标上的领先地位。它相对于中间融合(Mid Fusion)等模型的优势证明了MCOR在高精度场景中的强大能力,确认了其在需要严格准确性的目标检测中的顶级解决方案地位。
我们通过将提出的MCOR与CIAN[45]、MSDS-RCNN[18]、ARCNN[46]、MBNet[48]和MLPD[15]在KAIST测试集上进行比较来评估它。图4显示了在合理设置下以漏检率(MR)为指标的结果比较。评估说明了在每图像误报数下的漏检率性能,分为所有条件、白天和夜间。MCOR模型在所有条件下都表现出漏检率的显著降低:分别为7.41%、7.83%和6.76%。与ARCNN和CIAN等方法相比,这种持续的优秀表现(它们显示出更高的漏检率)强调了MCOR的有效性。在白天,虽然CIAN的漏检率较高,为14.78%,但MCOR保持了较低的7.83%的漏检率。在夜间,MCOR实现了最低的漏检率,突出了其在低光环境下的鲁棒性,这对行人检测具有挑战性。
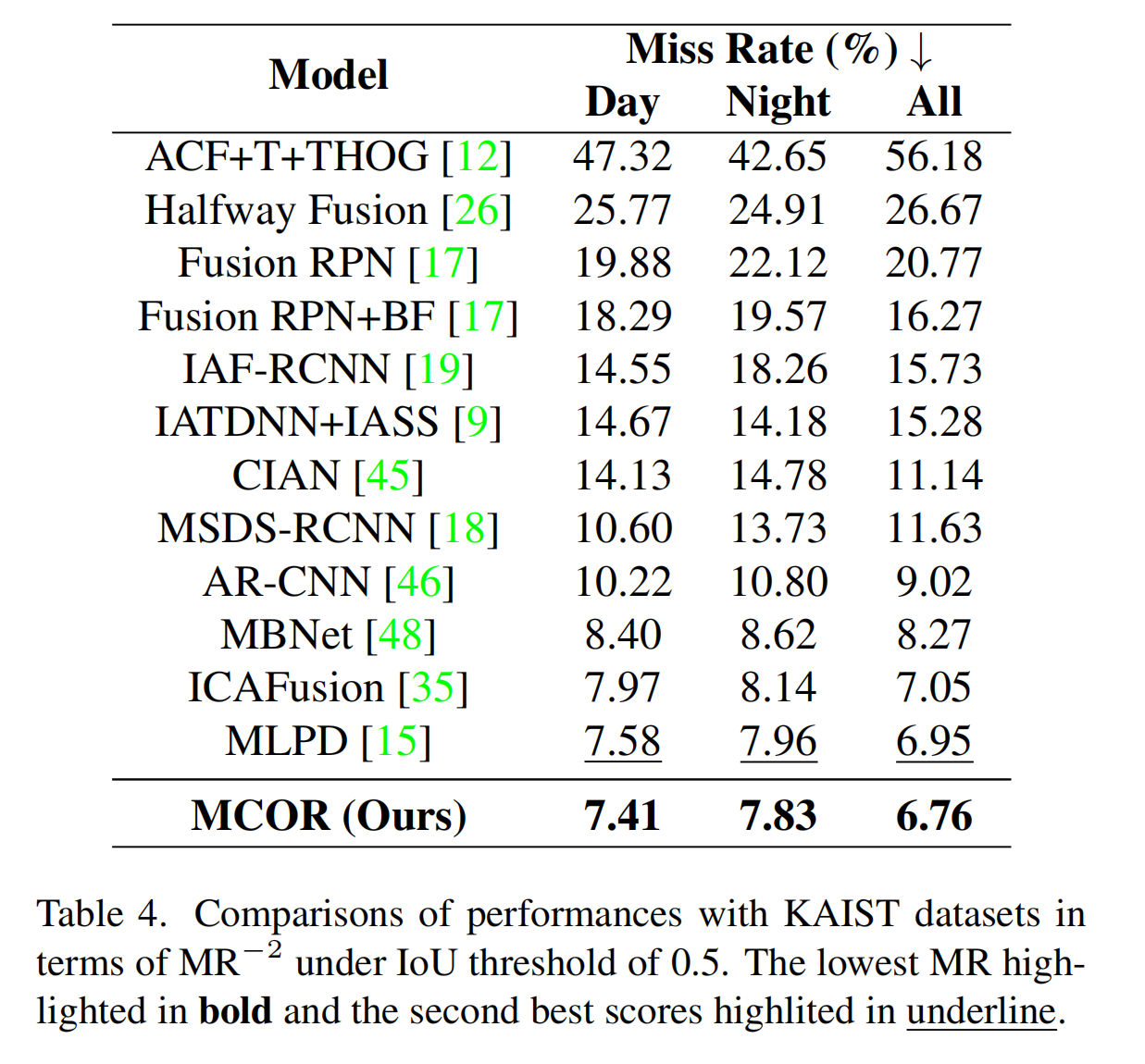
表4展示了使用KAIST数据集的单模态和多模态最先进(SOTA)模型之间的性能比较分析。MCOR优于大多数SOTA模型,在IoU阈值为0.5的情况下,对于白天、夜间和全天子集,分别实现了漏检率(MR)降低7.41%、7.83%和6.76%。这些结果证明了MCOR在无缝整合来自两个模态的信息并强调对象以提高检测准确性方面的有效性。
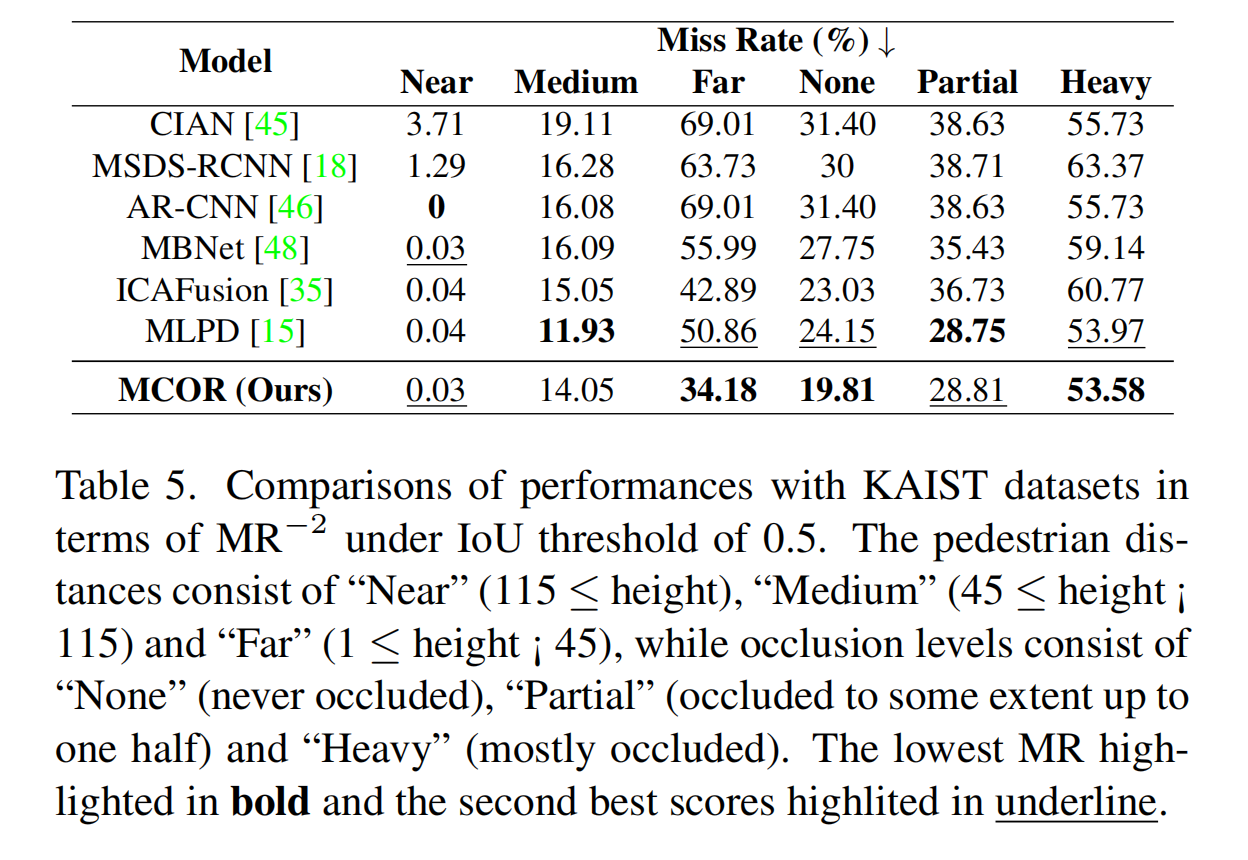
如表5所示,MCOR模块使用KAIST数据集显著改善了在不同距离和遮挡水平下的行人检测。它在检测远处行人方面表现优异,实现了最低的漏检率34.18%,突出了模型准确识别远离传感器的行人的能力,这对城市环境中的安全至关重要。
此外,所提出的方法在不同遮挡水平下表现良好,在“无”和“严重”遮挡场景中分别实现了最低的漏检率19.81%和53.58%。这种在清晰和遮挡条件下的可靠性对于实际应用(如拥挤的城市场景)至关重要。
4.5. 定性结果

使用FLIR数据集的定性评估如图5所示。这些结果突出了红外和RGB图像的互补性。红外检测器由于细微的温度差异而难以捕捉自行车,而RGB图像捕捉纹理和颜色细节,使YOLOv5(RGB)能够精确检测。相反,RGB检测器在检测行人方面与红外检测器相比存在局限性。
多模态检测器显示出增加的误报率。然而,我们的方法实现了比CFT更低的误报率。MCOR保留了每个模态的相关细节,增强了对每个模态的理解。同时,CSCR模块保留了对象和背景信息,并强调了对象加权的特征图,导致在三个模型中具有最低的误报率。
4.6. 消融研究
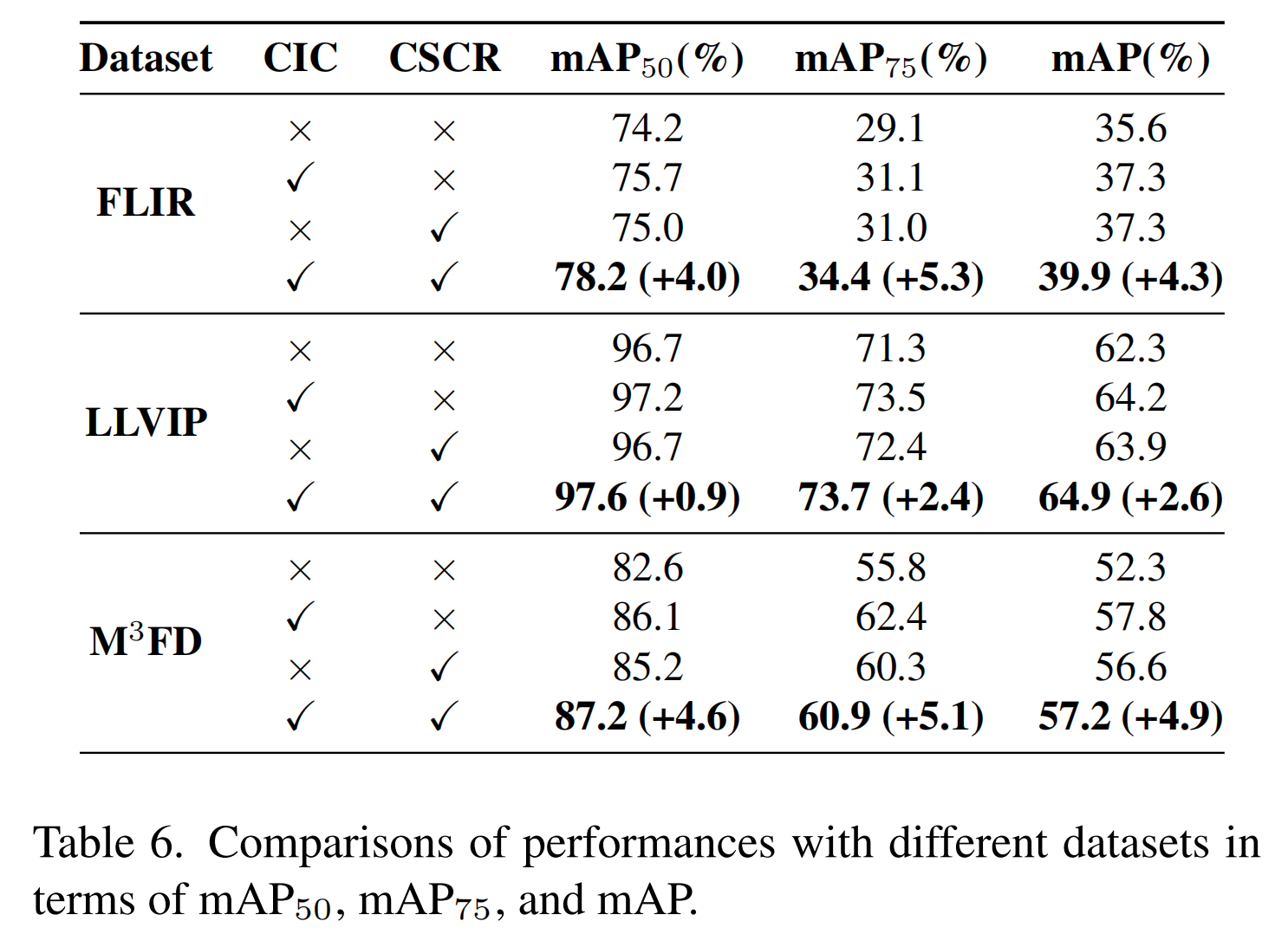
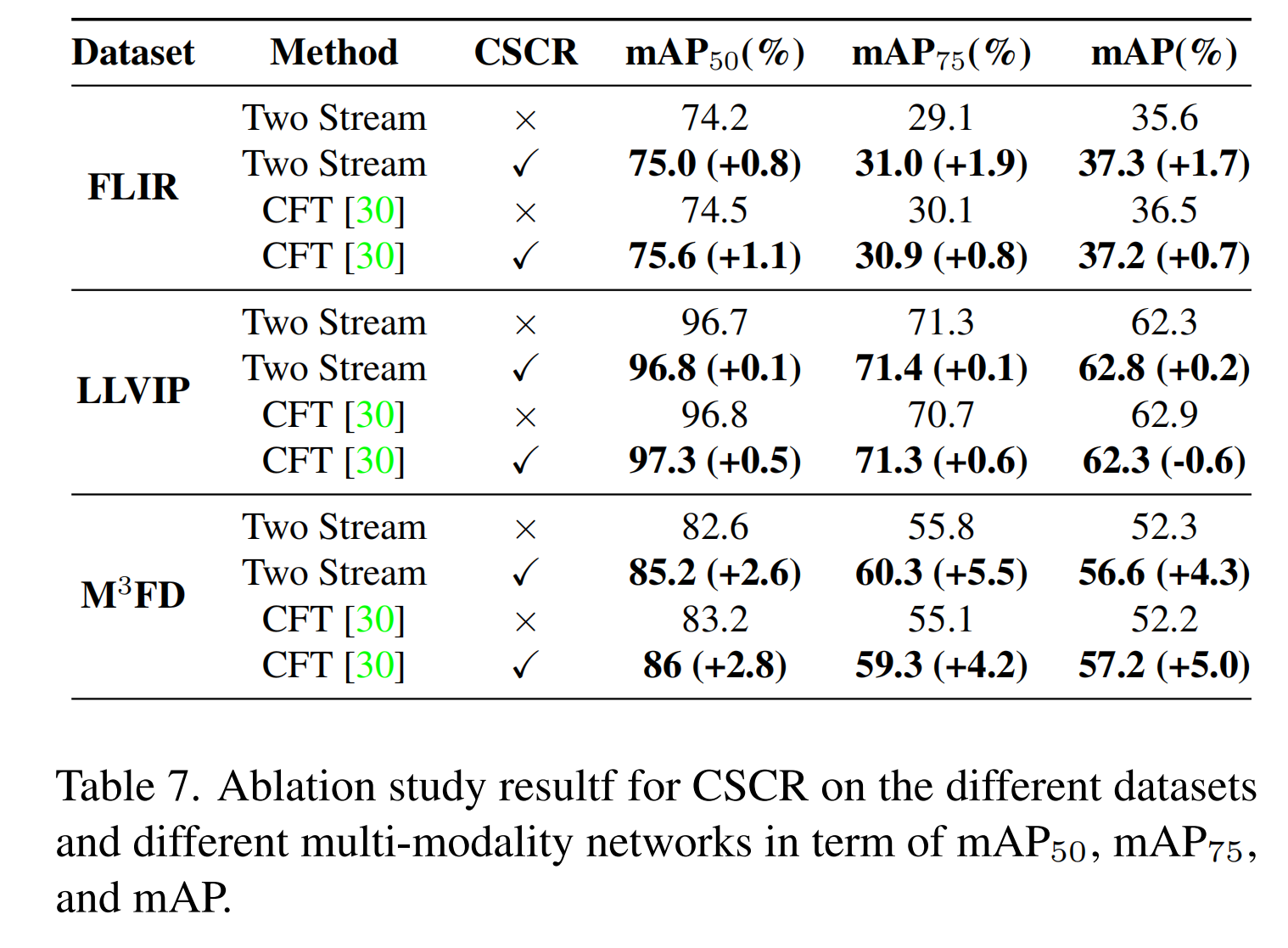
表6和表7展示了在FLIR、LLVIP和M3FD数据集上测试的所提出方法中CIC和CSCR模块各自贡献的比较分析。结果表明,与表2中提到的单模态目标检测器相比,两个子块都能有效提高预测准确性。在表7中,当与其他多模态目标检测模型结合实验时,CSCR模块也被证明能有效提高预测准确性。我们得出结论,CIC模块保留了两个模态的有价值信息,增强了对每个模态的理解。同时,CSCR模块有效保留了对象和背景信息,同时强调了对象加权的特征图。因此,这两个模块相互补充,进一步提高了整体性能。
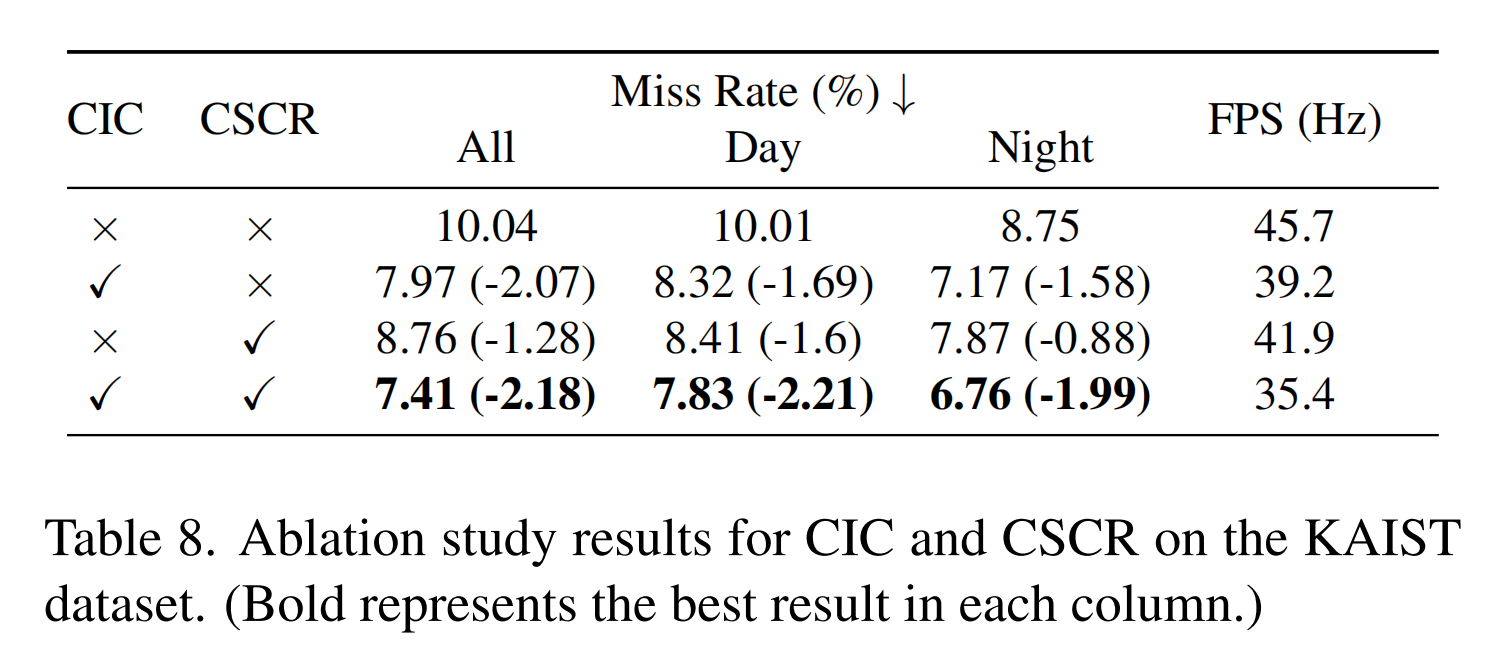
表8比较了我们的方法中CIC和CSCR模块在KAIST数据集上的贡献。将CIC模块添加到YOLOv5中,将漏检率(MR)从10.04%降低到7.97%,提高了2.07%p。CSCR模块将MR从10.04%降低到8.76%,提高了1.28%p。这些改进在不同时间保持一致;使用CIC模块,白天MR从10.01%下降到8.32%,夜间MR从8.75%下降到7.17%。CSCR模块将白天MR降低到8.41%,夜间MR降低到7.87%。
CIC模块通过保留跨模态的关键信息来增强理解,而CSCR模块维护对象和背景特征,强调目标检测中的上下文。如表8所示,我们的方法在RTX 3090上达到35.4 FPS,突出了其在需要高检测速度和准确性的场景中的实用性。
5. 结论
在本文中,我们提出了MCOR框架来解决模态不平衡问题,并整合来自RGB和IR模态的信息以进行多模态目标检测。MCOR框架展示了与其他方法相比卓越的信息捕获能力。CIC模块利用互补信息增强单模态特征,促进RGB和IR模态的平衡贡献。CSCR模块使用以对象为中心的特征图来加权对象并补偿模态错位。我们的结果表明,当两个模块都被使用时,预测准确性得到提高。此外,该框架能很好地适应不同的模型,展示了强大的泛化能力。