【无标题】SceneSplat:基于视觉-语言预训练的3DGS场景理解
标题:<SceneSplat: Gaussian Splatting-based Scene Understanding with Vision-Language Pretraining>
来源:阿姆斯特丹大学计算机视觉实验室、苏黎世联邦理工学院、索菲亚大学圣克利门特·奥赫里德斯基学院、南京航空航天大学、比萨大学、特伦托大学
主页:https://github.com/unique1i/SceneSplat
文章目录
- 一、摘要
- 二、准备知识:3DGS-MCMC(NeurIPS 2024 SPOTLIGHT)
- 2.1 Langevin 动力学
- 2.2 随机梯度 Langevin 动力学(SGLD)
- 2.3 使用SGLD更新3DGS(增加一个噪声项)
- 2.4 用"relocate" 替代 "split"、"clone"操作
- 三、准备知识:Occam’s LGS(语言GS)
- 3.1 最大似然特征的Uplifting
- 3.3 通过前向渲染实现
- 3.4 过滤噪声高斯
- 四、SceneSplat 数据集
- 三、3DGS 语言标签收集
- 3.1 3DGS 语言标签的获取
- 3.2 Vision-Language 3DGS 预训练
- 3.3 自监督预训练
- 四、实验
- 4.1 视觉-语言 预训练
- 4.2 无标签的3DGS预训练
- 5.3 更多实验
一、摘要
二、准备知识:3DGS-MCMC(NeurIPS 2024 SPOTLIGHT)
2.1 Langevin 动力学
Langevin 动力学是描述粒子在外部势能场中随机运动的方程。对于一个粒子,Langevin动力学的更新方程可以表示为:


这个更新规则包括两个部分:
-
第一部分是 梯度下降 (−η▽θL(θt))(-η\bigtriangledown_θL(θ_t))(−η▽θL(θt)) ,用于优化模型参数 ,使得损失函数尽量减小;
-
第二部分是 噪声项 2ηN(0,I)\sqrt{2η}N(0,I)2ηN(0,I) ,模拟了粒子在外部环境中的随机扰动,加入随机扰动使得算法具有一定的随机性,从而避免陷入局部最小值,并使得参数采样更接近目标后验分布
2.2 随机梯度 Langevin 动力学(SGLD)
Stochastic Gradient Langevin Dynamics (SGLD) 算法是一种基于随机梯度的马尔科夫链蒙特卡罗(MCMC)方法,常用于从高维概率分布中采样,尤其是在深度学习中进行贝叶斯推断时。在贝叶斯统计中,我们常常需要从后验分布中采样以进行推断。然而,对于高维复杂的后验分布,精确采样通常是难以实现的。传统的马尔可夫链蒙特卡罗(MCMC)方法,如 Metropolis - Hastings 算法,计算成本高且在高维空间中混合速度慢。 SGLD结合了梯度下降的高效性与Langevin动力学的随机性,从而在优化过程中引入噪声 ,使得该方法能够进行贝叶斯采样,并且比传统的梯度下降方法更具探索性。
在SGLD中,损失函数 L(θ)L(θ)L(θ) 通常是基于数据集的负对数似然。由于真实数据集通常非常大,计算完整梯度会非常耗时,因此SGLD采用随机梯度下降(SGD)来近似梯度,从而加速计算。 ▽θL(θt)\bigtriangledown_θL(θ_t)▽θL(θt) 替换为▽θL(θt;ξt)\bigtriangledown_θL(θ_t;\xi_t)▽θL(θt;ξt),基于单个或少量样本计算梯度,用以近似目标损失函数的真实梯度。
2.3 使用SGLD更新3DGS(增加一个噪声项)


其中,ηηη ~N(0,I)N(0,I)N(0,I),σσσ表示sigmoid函数(由超参kkk和ttt控制,本文设置k=100k= 100k=100,t=(1−0.005)t=(1-0.005)t=(1−0.005)以生成一个从0到1的陡峭转换函数)以3DGS对高斯透明度值的默认裁剪阈值为中心。简而言之, 上述公式用各向异性噪声扰动高斯函数,其各向异性分布 ∑∑∑ 与高斯函数相同,而sigmoid项降低了噪声对不透明高斯函数的影响。
2.4 用"relocate" 替代 “split”、"clone"操作
原始的3DGS方法通过"split"、“clone”、"prune"操作来增加或减少场景中的高斯球数量,会破坏高斯球的分布。3DGS-MCMC将这些修改描述为从一个样本状态 goldg^{old}gold 转移到另一个样本状态 gnewg^{new}gnew ,保持移动前后样本状态的分布概率一致,具体将"dead" Guassians( α<0.005α<0.005α<0.005 )移动到 “alive” Guassians:

简单来说就是,使用高斯的不透明度判断其应该被克隆的概率,并使用一种保证克隆前后所在区域分布一致的方法来增加高斯数量。

上述公式仅对不透明度以及形状(协方差矩阵)参数进行了更改 ,实际上没有改变位置以及颜色。理论上想要实现作者提出的状态转移前后分布近似一致的要求,颜色参数显然不能忽略,不过加入SH系数后推导出一个状态转移公式会十分复杂。
这个稠密化方法也有缺点。 首先,克隆后的两个高斯实际上是重叠的,其颜色参数也是相同的,那么它们接收到的梯度就是近似相同,导致有一定概率使得这两个高斯无法有效被分别优化,这个缺点实际上被SGLD缓解了,因为两个高斯被添加的噪声肯定是不同的。这个问题最直观的结果就是SGLD添加的噪声低了之后训练会崩塌。其次是判断高斯是否需要被克隆的依据居然是其不透明度,这实在是太过于随意了,直接的影响就是对于那些初始化不足的区域(高斯数量少),该致密化策略无法生效,因为这些区域实际需要的高斯点数量与初始化数量之间的差距实在是过大,需要反复致密化才能满足重建需求。如果对远景细节有要求,还是推荐使用AbsGS的方法来判断是否需要致密化。
作者还引入了两个正则化项,对高斯的不透明度和尺寸进行约束。 在原始3DGS中,这种约束并没有什么实际意义:要求高斯的平均不透明度变低会导致渲染队列拉长,会显著拖累渲染速度,在能够高质量重建外观的情况下,高斯的不透明度越高越好(比如mini-splatting这篇工作最后的场景中高斯的平均不透明度就非常高,使得其渲染速度变得非常快);对于尺寸进行约束也没有作用,因为3DGS针对大高斯采用的分裂操作自然而然就削减了高斯的尺寸,但是3DGS-MCMC仅有克隆操作,所以需要对尺寸进行约束不然无法消除重建模糊。

作者提到不使用不透明度正则化时需要增加噪声的幅度,否则训练会坍塌,这应该也是仅采用克隆操作的影响,因为3DGS并不存在这个问题。
三、准备知识:Occam’s LGS(语言GS)
其他3DGS分割方法,从多个二维视角聚合语言特征,往往依赖繁琐的技术流程,导致计算成本高昂且训练周期冗长。Occam’s LGS无需复杂处理流程,采用概率化建模框架,运用奥卡姆剃刀原则优化算法,开发出高效的加权多视角特征聚合技术。
对于一条射线上的第iii个高斯函数,其对像素p的贡献度定义为αi=oiGi(xi′)α_i=o_iG_i(x'_i)αi=oiGi(xi′),表示其影响程度。在对时,像素ppp的颜色是通过加权混合所有相关高斯函数的投影得到(ψc()ψ_c()ψc()是颜色渲染函数):

为了将多视角的2D特征提升到3D,赋予每个高斯一个高维语义特征向量f∈Rdf∈R^df∈Rd。类似于颜色混合,像素ppp的语义特征通过alpha加权混合计算(ψfψ_fψf是特征渲染函数):

相较于公式(2)中的颜色渲染,公式(5) 渲染语义信息在内存占用和计算成本方面都更为昂贵。这主要源于特征维度显著增加(d>>3),导致GPU无法将所有必需数据存入 shader L1 cache
3.1 最大似然特征的Uplifting
基于3DGS前向渲染过程,将特征提升问题建模为最大后验概率(MAP)估计问题。给定二维特征图 F2DF^{2D}F2D,三维特征 fff 的MAP估计器表达式:

对于语言3DGS,当语言特征 p(f)p(f)p(f)采用均匀分布时(假设CLIP的高效特征空间满足),估计器可简化为最大似然(ML)公式 arg maxfp(F2D∣f)_fp(F^{2D}|f)fp(F2D∣f)。在高斯噪声模型 ϵp,vϵ_{p,v}ϵp,v下,考虑到语言特征和像素间的条件独立性,视图vvv中像素ppp渲染的二维特征表示为:

这就产生了每个GS的3D特征加权聚合公式:

SiS_iSi表示可以看到高斯基元 iii的视图集合,wisw_i^swis代表高斯iii在视图sss中心投影处的贡献度(alpha混合权重),fisf_i^sfis则是高斯iii在视图sss中心投影像素的二维特征。根据高斯在视图中的影响力对每个视图的贡献度进行加权处理,从而有效应对噪声或部分遮挡视角带来的挑战。(补充材料提供了完整的分步推导)。
3.3 通过前向渲染实现
加权聚合公式直接对应前向渲染流程,无需复杂的反向投影或迭代优化。给定训练好的3DGS,针对每个基元,步骤为:
- 1.确定高斯GiG_iGi 的可见视图集合SiS_iSi(视锥体范围内)
- 2.在每个视图sss中确定高斯中心投影像素位置 pis=⌊xi′⌋p^s_i =\lfloor x'_i \rfloorpis=⌊xi′⌋。
- 3.记录各中心投影像素的alpha混合权重wisw^s_iwis,并提取对应的二维特征fisf^s_ifis。
- 4.根据公式7计算加权平均值。
前向特征集合方法具有三大核心优势 :首先,特征uplift仅需单次视图前向遍历即可完成,计算效率显著提升;其次,视锥体剔除与tiles排序机制能自然处理被遮挡的高斯,确保仅处理可见特征;最后,通过渲染过程中显式记录投影位置,建立了2D特征与3DGS之间的直接精确对应关系,彻底摒弃了昂贵的反向投影或迭代优化方法。
3.4 过滤噪声高斯
在完成正向渲染后,我们会识别并过滤掉那些在所有视角中都无贡献的高斯基元。这种筛选机制不仅能有效降低噪声,还能大幅减少高斯分布的数量。此外,这种统计异常值剔除方法与我们的概率框架高度契合——因为可见性极低的高斯分布其特征估计必然存在较大不确定性。通过这一流程,我们最终获得精炼的语义高斯分布集合gs=g^s=gs={GisG^s_iGis}i=1M^M_{i=1}i=1M(其中M≪N表示维度),表示仅保留对场景语义表征具有实质贡献的高斯。
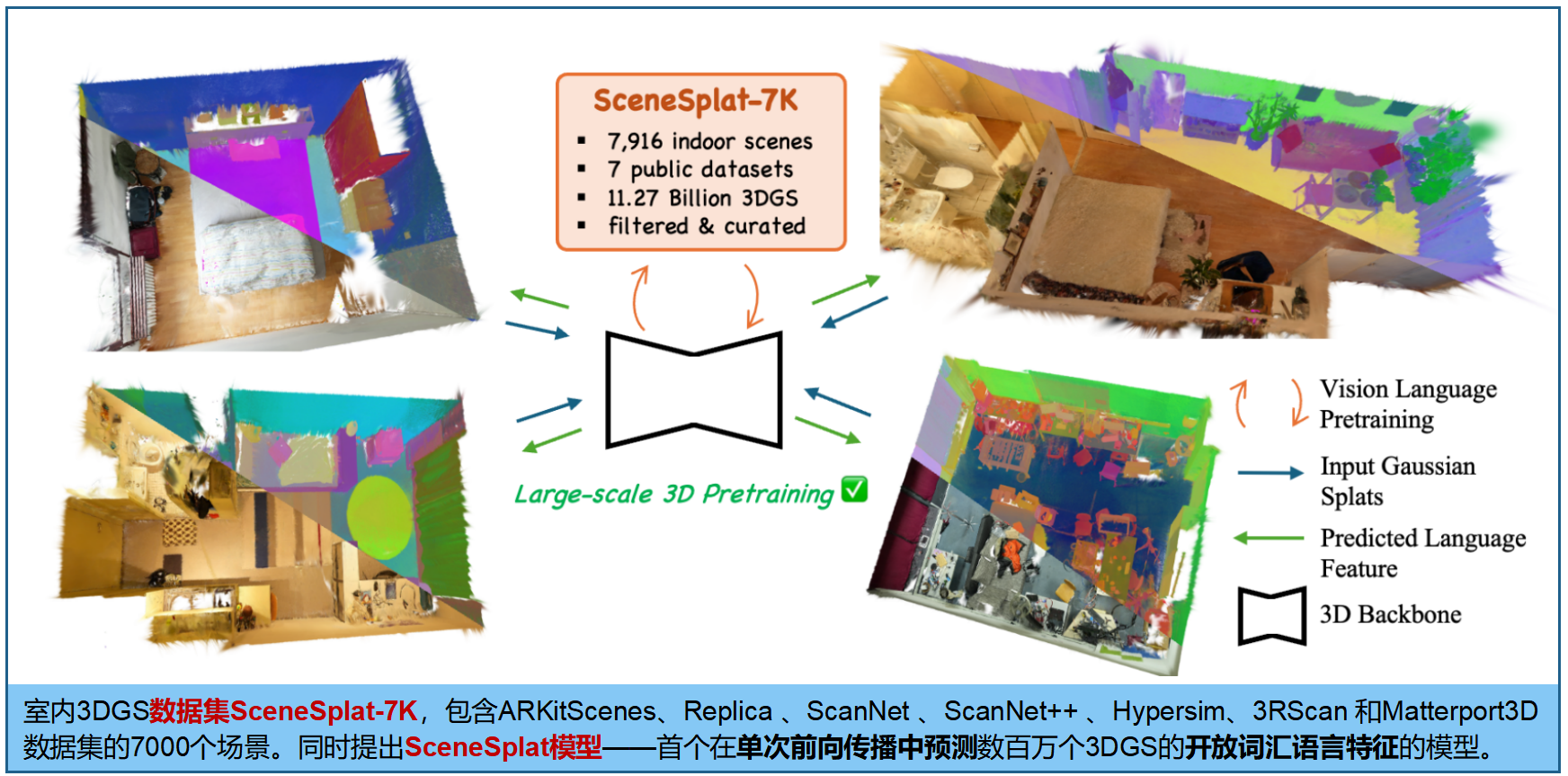
四、SceneSplat 数据集
推出 SceneSplat-7K,专为 3DGS 的室内场景理解任务,包含七千个真实场景与合成环境。其详细统计见表1 (即将公布)
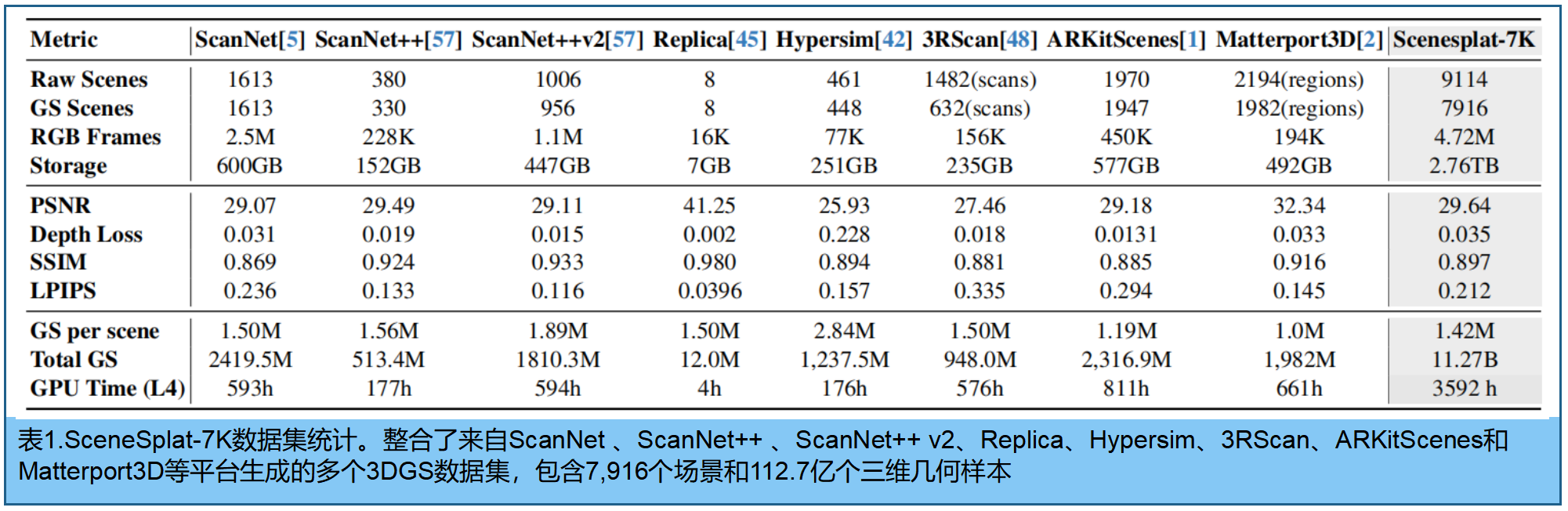
在3DGS优化之前、期间和之后应用多种措施,以确保高质量的3DGS场景。在训练场景选择方面,我们优先选取至少包含400帧的镜头以确保多视角覆盖。通过采用拉普拉斯方差作为锐度指标来剔除模糊帧。三维几何场景优化采用gsplat [56]算法。对于具备深度信息的场景,我们施加深度损失以提升几何建模精度。为实现高效压缩,我们采用马尔可夫链蒙特卡洛策略[18]并结合不透明度与尺度正则化。优化完成后,基于PSNR指标对三维几何场景进行筛选,最终将其作为预训练输入。
SceneSplat-7K数据集整合了来自ScanNet [5]、ScanNet++ [57]、ScanNet++ v2、Replica [45]、Hypersim [42]、3RScan [48]、ARKitScenes [1]和Matterport3D [2]等平台生成的各类3DGS数据集,包含约9,000个原始场景。该数据集经过处理后共生成7,916个高斯样条场景,每个场景平均包含142万个三维高斯样本,总计约112.7亿个高斯样本,从中精选出4,114个高质量场景用于预训练。数据集覆盖472万帧RGB图像,呈现出高保真外观效果和优异的重建质量,其平均PSNR达29.64分贝,平均深度损失为0.035米,平均SSIM值为0.897,平均LPIPS值为0.212。构建该数据集耗时相当于在NVIDIA L4 GPU上运行150天的计算量。
三、3DGS 语言标签收集
语言标签收集旨在通过将每个3DGS基元GiG_iGi与视觉语言模型(VLM)的image embedding 空间的语义特征Fi∈RdF_i∈R^dFi∈Rd 相关联,保留丰富的潜在语义信息。其避免了特定场景压缩[Langsplat]——这种技术会限制模型的可扩展性和泛化能力。
3.1 3DGS 语言标签的获取
如下面的算法1,采用SAMv2 [39]进行目标级分割,并使用SigLIP2 [46]进行特征提取。随后通过 Occam’s LGS [4],无需额外优化即可将 二维特征图 提升为3DGS特征场 。在多个数据集上生成完整的3DGS的特征对 {(Gi,Fi)(G_i,F_i)(Gi,Fi)}i=1N^N_{i=1}i=1N。

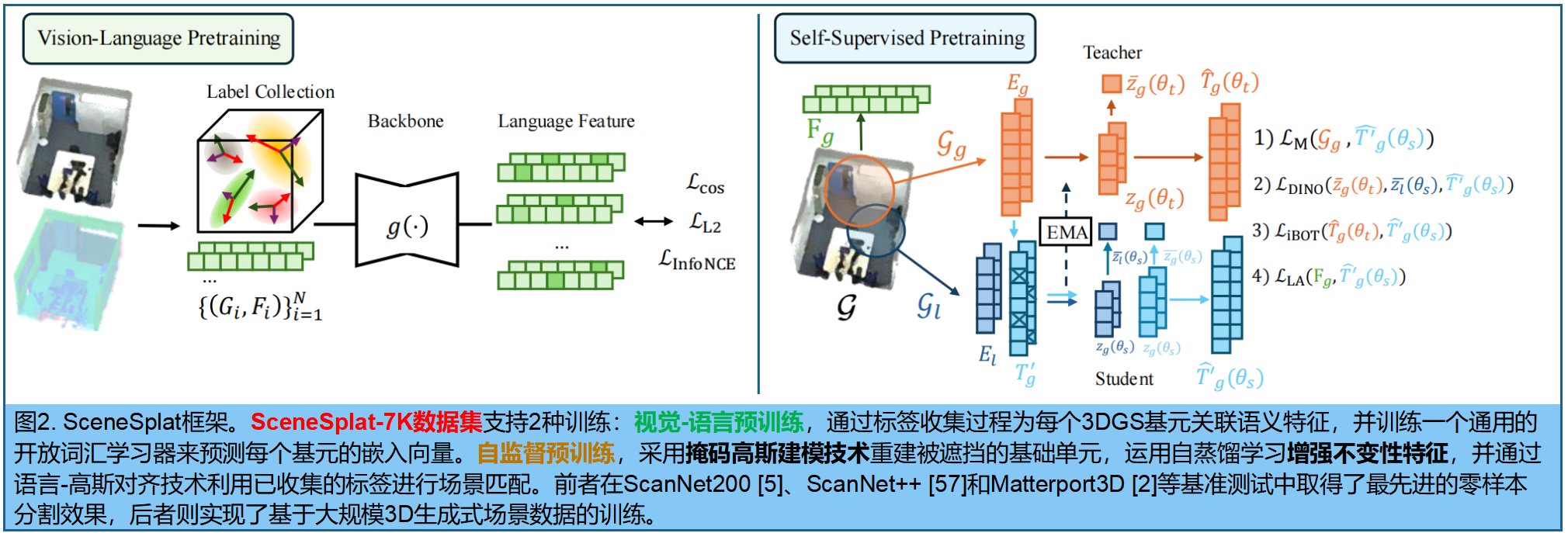
3.2 Vision-Language 3DGS 预训练
首先将 Transformer改进,以预测(3DGS语言标签相对应的)高维的基元特征(F^∈RN×d\hat{F} ∈ R^{N×d}F^∈RN×d):

整体监督损失:
Ltotal=λcosLcos+λL2L2+λconLcontrastL_{total} = λ_{cos}L_{cos} + λ_{L2}L_2 + λ_{con}L_{contrast}Ltotal=λcosLcos+λL2L2+λconLcontrast
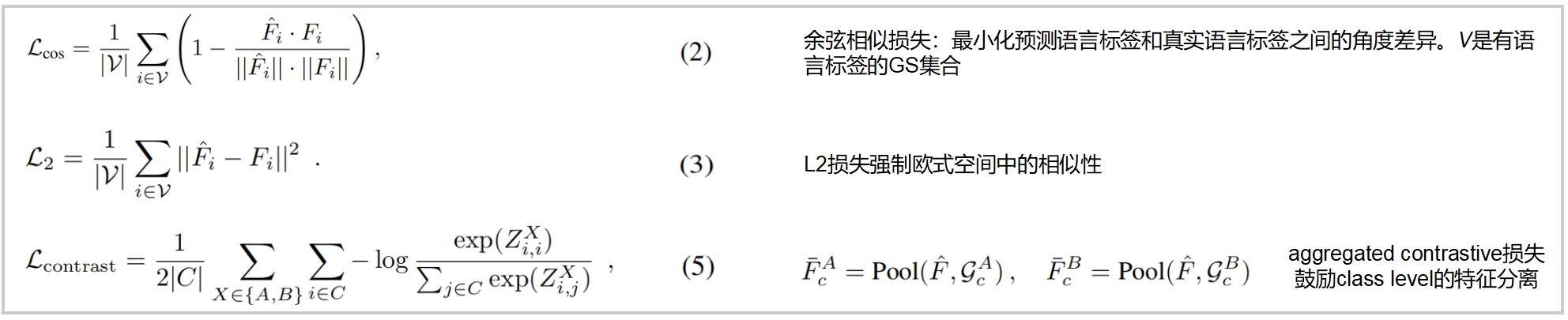
公式5:aggregated contrastive loss :不同于逐个对比GS特征(大型场景中计算量过大),SceneSplat 采用 class-wise mean pooling。对于语义类别 ccc(包含足够的3DGS),将其特征随机划分为两个互不相交的集合GcAG_c^AGcA和GcBG_c^BGcB,并计算池化特征 FˉcA,\bar{F}_c^A,FˉcA,FˉcB\bar{F}_c^BFˉcB。
首先将 FˉcA,\bar{F}_c^A,FˉcA,FˉcB\bar{F}_c^BFˉcB归一化为单位长度;ZA=FˉA(FˉB)⊤/τZ^A=\bar{F}^ A(\bar{F}^B)^⊤/τZA=FˉA(FˉB)⊤/τ 和ZB=FˉB(FˉB)⊤/τZ^B=\bar{F}^ B(\bar{F}^B)^⊤/τZB=FˉB(FˉB)⊤/τ ,其中FˉA\bar{F}^AFˉA或FˉB\bar{F}^BFˉB的每一行是不同的语义类别。ZAZ^AZA和ZBZ^BZB的对角线元素表示正向匹配。
3.3 自监督预训练
如图2(右):高斯自监督学习方法(GaussianSSL),将不同目标损失函数整合到SceneSplat的大规模预训练模型中。
mask 高斯建模。用于监督模型预测被mask掉的高斯基元:给定由3DGS场景G=G=G={GiG_iGi}i=1N^N_{i=1}i=1N,Gi∈R59G_i∈R^{59}Gi∈R59),流程如下
- (1) 使用大小为S的密集网格采样,从G中抽取子集 {GiG_iGi}i=1N′^{N'}_{i=1}i=1N′
- (2) 通过嵌入函数PPP投影到潜在空间,得到token E=P(E = P(E=P({GiG_iGi}i=1N′^{N'}_{i=1}i=1N′)∈RN′×de)∈R^{N'×de})∈RN′×de,ded_ede为嵌入维度。
- (3) 使用可学习的 mask tokent∈Rdet∈R^{de}t∈Rde以比例 r∈[0,1]r∈[0,1]r∈[0,1]随机替换N′⋅rN'·rN′⋅r个token,生成Tm∈RN′×deT_m∈R^{N'×de}Tm∈RN′×de。
- (4) 通过神经网络 gθ(⋅)g_θ(·)gθ(⋅) 处理 mask token TmT_mTm,得到重构token T^m=hϕ(fφ(Tm))\hat{T}_m=h_ϕ(f_φ(T_m))T^m=hϕ(fφ(Tm)), fφf_φfφ为编码器,hφh_φhφ 为解码器。
- (5) 通过重构投影算子G^m=Φ(Tm)RN′×F\hat{G}_m=Φ(T_m)R^{N'×F}G^m=Φ(Tm)RN′×F,将输出标记T^m\hat{T}_mT^m映射回输入的高斯空间。
- (6) 最后用预测的 masked GS 与原始3DGS之间的L2重构损失进行评估:LMGM=EGj∼G[∥Gm−G^m∥22i]L_{MGM}=E_{G_j∼G}[∥G_m−\hat{G}_m∥^2_2 i]LMGM=EGj∼G[∥Gm−G^m∥22i]。
自蒸馏表征学习 。自蒸馏:将学生网络θsθ_sθs的预测与EMA更新的教师θtθ_tθt [3]对齐,学习增强不变性表征。对于高斯场景{GnG_nGn}n=1B^B_{n=1}n=1B(全局/局部视图GgbG^b_gGgb,GlbG^b_lGlb)的批量数据,提取token化的bottleneck特征z∈RM×dez∈R^{M×de}z∈RM×de,通过均值池化计算全局表征 zˉ\bar{z}zˉ,并使用余弦相似度损失LsimL_{sim}Lsim [52]对师生输出进行对齐。特征多样性通过编码率项 LcrL_{cr}Lcr [23,52]进行正则化,从而得到LDINO = ωsimLsim + ωcrLcr及其对应权重。学生网络还通过LiBOT使用余弦相似度预测与教师对齐的掩码特征。我们提出采用多任务重构LMGM来缓解解码器坍缩问题,因为编码率正则化仅能稳定层级编码器。重构过程仅限于弱增强视图以避免性能下降。
语言-高斯对齐。预计算的语言特征能够有效实现知识蒸馏。这些语言特征的高维度(维度N×dL )会显著增加监督计算的能耗。为此,采用autoencoder[19]学习的压缩表示替代原始特征,在保留语义信息的同时大幅降低内存开销。与LMGM类似,我们通过公式(2)和(3)采用LLA方法训练网络,使其能够从未遮蔽的邻近节点预测低维语言特征。
四、实验
4.1 视觉-语言 预训练
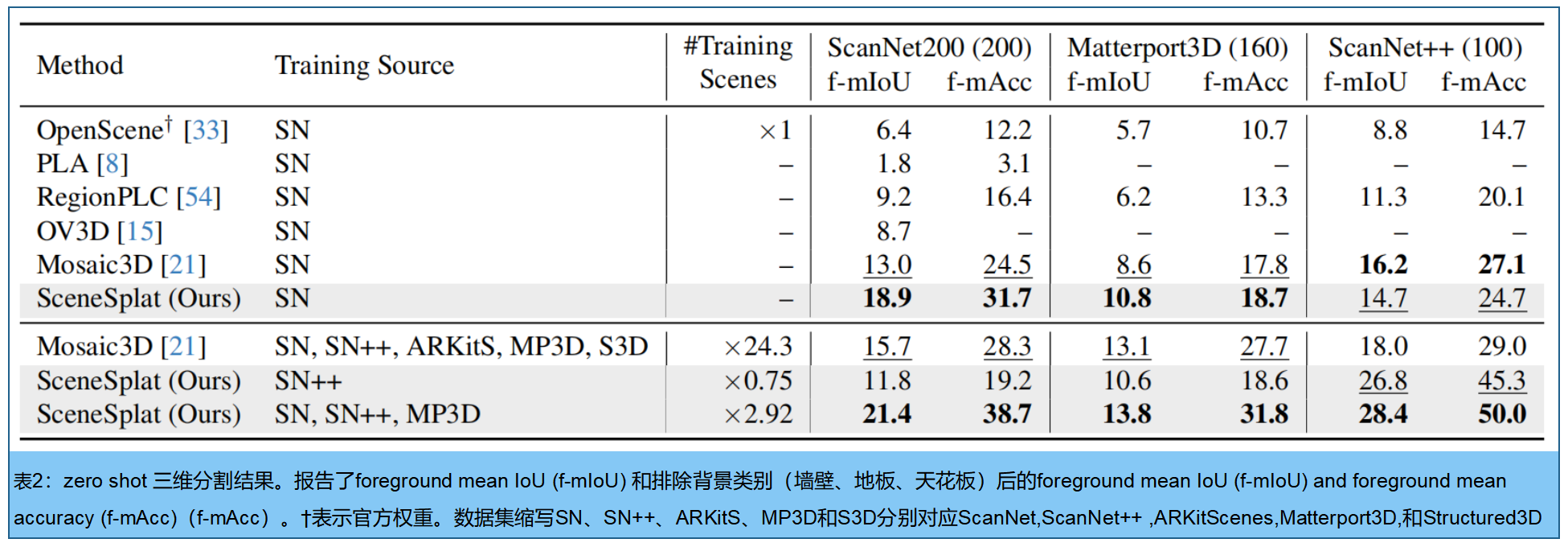
表2展示了零样本三维语义分割在细粒度基准数据集上的实验结果:ScanNet++(100类)[57]、Matterport3D (160类)[2]和ScanNet200(200类)

图3展示了零样本分割在评估场景中的效果。SceneSplat不仅实现了具有竞争力的分割性能,还准确标注了缺失的语义标签(例如上文展示的书桌)。图4基于文本的查询方式,对预测语言特征的推理结果进行了验证。我们的视觉语言预训练方法能够有效定位场景中的复杂物体。
4.2 无标签的3DGS预训练
高斯SSL vs 其他方法 对比实验。表3展示了分割结果。我们的方法在ScanNet20数据集上比纯监督基线模型提升了+0.1%,在ScanNet200数据集上提升+0.5%。
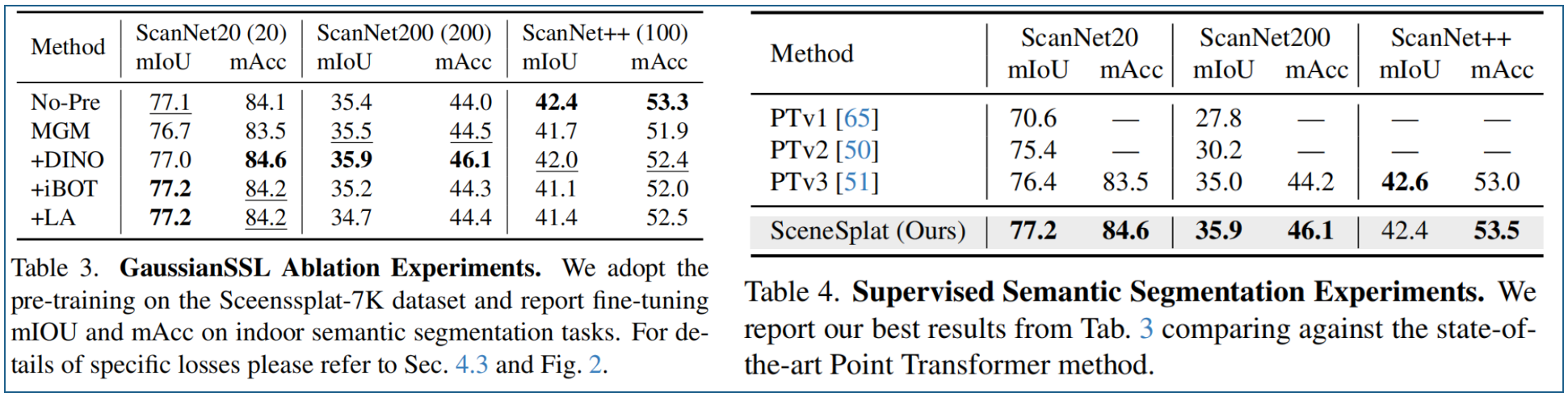
5.3 更多实验
表5对比了 SceneSplat推理特征的性能 vs 收集的语言标签。在ScanNet++数据集上,本方法以4.2%的f-mIoU提升超越了标签结果。尽管收集的标签并非完美,但大规模预训练可以过滤噪声并学习到有意义的模式。

图5:3DGS场景的PSNR对OpenVocabulary分割性能的影响。基于Matterport3D测试集(包含370个场景)的研究表明,3DGS场景的PSNR与最终零样本mIoU性能之间正向关联。低PSNR通常源于输入图像模糊、高斯中心优化效果欠佳以及场景覆盖不足等问题,而这些问题正是3DGS参数难以有效解析的。
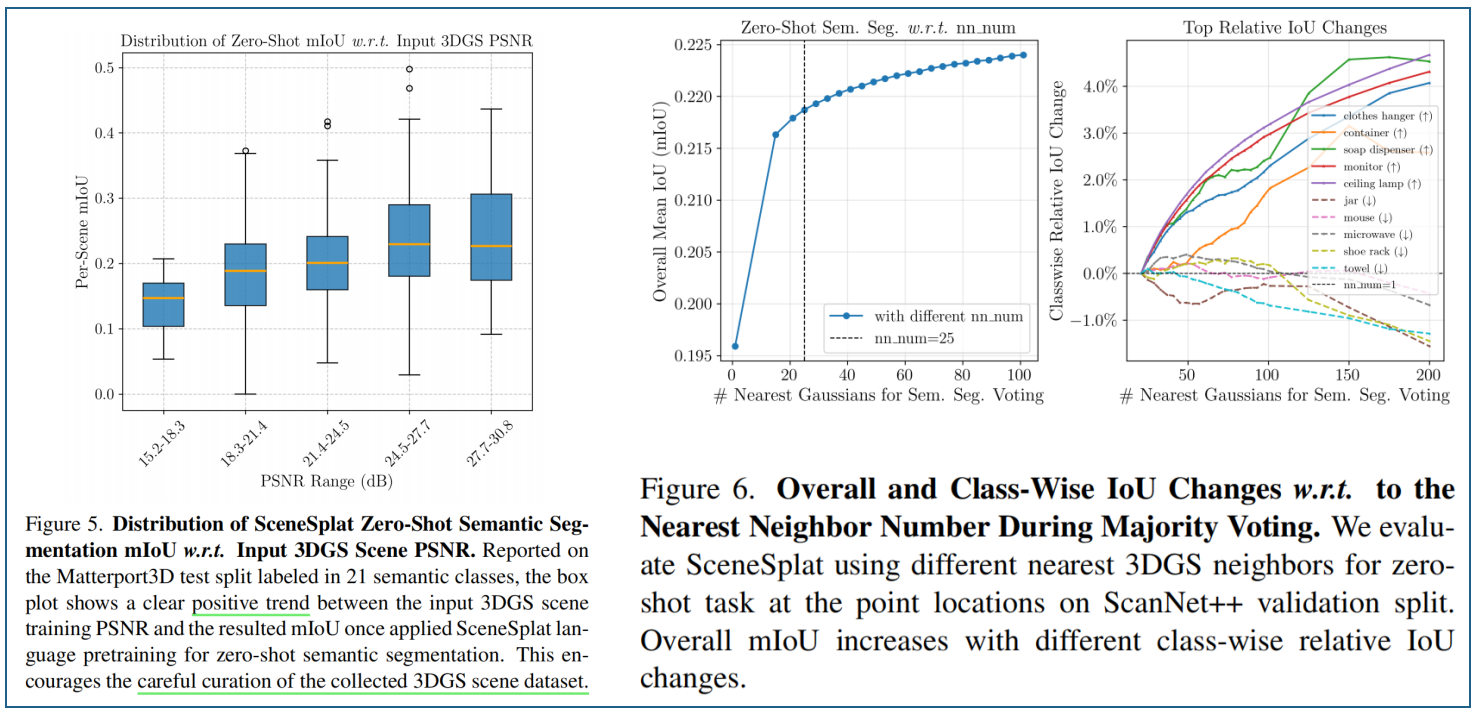
图6展示了ScanNet++上,零样本实验中的最近邻投票结果。输入3DGS的中心点与语义预测评估的点位置不同;因此,我们需要汇总来自最近邻高斯分布的预测。我们为每个评估位置使用最近的3DGS进行多数投票。mIoU值随最近邻数量增加的整体趋势,并列出了相对变化幅度最大的类别。为平衡性能与推理速度,最终选取25个最近邻进行投票决策
视觉-语言预训练中采用3DGS与点云的有效性对比。为验证3DGS参数在场景理解中的有效性,我们对点属性(颜色和法线)进行了相同的视觉-语言预训练。如表6所示,当模型以点属性作为输入时,其性能始终优于采用3DGS参数的SceneSplat方法。
视觉语言预训练中对比损失的消融实验。表7展示了视觉语言预训练过程中应用对比损失的效果消融,其中在训练后期引入对比损失的表现优于其他变体。

运行时间与逐场景级语言GS对比。得益于视觉语言预训练后的前馈能力,如表8所示,SceneSplat方法比最先进的语言嵌入式高斯样条方法快445.8×次,因为无需进行二维特征提取与融合。
#pic_center =80%x80%
d\sqrt{d}d 18\frac {1}{8}81 xˉ\bar{x}xˉ D^\hat{D}D^ I~\tilde{I}I~ ϵ\epsilonϵ
ϕ\phiϕ ∏\prod∏ abc\sqrt{abc}abc ∑abc\sum{abc}∑abc
/ $$