【Linux】网络部分——网络基础(Socket 编程预备)
32.网络基础——Socket 编程预备
文章目录
- 32.网络基础——Socket 编程预备
- 端口号
- 端口号与进程ID
- 传输层的典型代表——TCP与UDP
- 字节流与数据报的通信模型对比
- 网络字节序
- 计算机数据存储的大小端问题
- socket接口编程
- struct sockaddr
- sockaddr 结构
- socket编程常用API
端口号
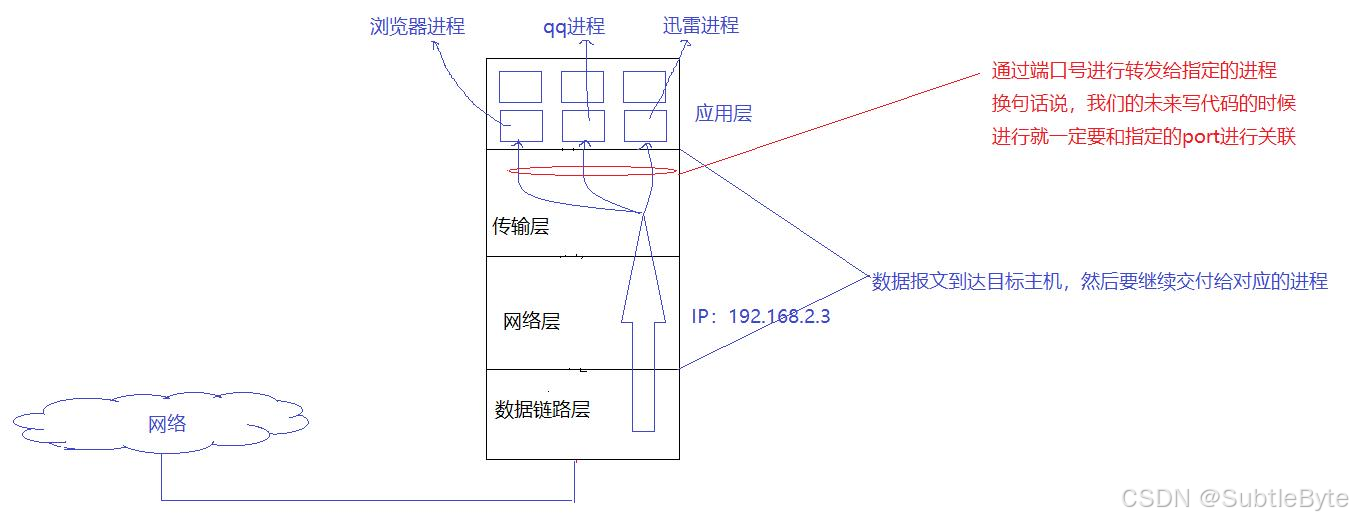
IP地址用于标识主机的唯一性,但数据传输到目标主机并非最终目的,真正的目的是将数据交付给主机内的特定进程。在网络通信中,进程是用户在系统中的代表,数据必须交付给特定进程才算完成通信任务。操作系统中的传输层和网络层虽然只有一套,但上层进程可能有多个,因此需要端口号来标识特定进程。
- 端口号是传输层的内容,是一个16位的整数,用于告诉操作系统将数据交付给哪个进程处理。
- IP地址标识全网唯一主机,端口号标识主机内唯一进程,两者结合可以唯一标识网络中的特定进程。IP地址和端口号在网络通信中扮演着不同但互补的角色。IP地址用于标识网络中唯一的主机,而端口号则用于标识主机内唯一的进程。每个网络进程启动时都需要从传输层申请一个端口号与之关联。
- 端口号的划分:
- 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的端口号都是固定的
- 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的
- 网络通信的本质是进程间的通信,而非简单的主机间数据传输。网络通信中数据传输到目标主机只是手段,真正的目的是将数据交付给特定进程。在操作系统中,用户的所有行为最终都会转化为进程或线程的执行。当用户进行网络通信时,实际上是用户进程将数据交给网络,经过操作系统各层的处理后,最终由目标主机的操作系统将数据交付给目标进程。网络通信遵循端到端原则,即通信的起点和终点都是应用层的进程。
- 端口号与IP地址的组合形成了网络通信的完整地址标识,即套接字(socket)
端口号与进程ID
端口号的存在是为了在网络层独立标识进程的唯一性,而不依赖于操作系统的进程管理机制(如PID)。虽然PID可以唯一标识进程,但将其引入网络层会导致网络模块与进程管理模块的强耦合。端口号的设计使得网络协议栈能够独立于进程管理运行,提高系统的解耦性。
传输层的典型代表——TCP与UDP
传输层有两个典型协议,tcp和udp。tcp协议(Transmission Control Protocol)提供有连接和可靠传输服务,通信前需要建立连接,保证数据传输的可靠性,如数据丢包重传、报文去重和乱序重排。udp协议(User Datagram Protocol)提供无连接和不可靠传输服务,直接通信,不保证数据传输的可靠性。tcp和udp在代码实现上的区别主要体现在连接建立和传输可靠性上。tcp适用于需要可靠传输的场景,如文件传输、网页浏览等;udp适用于实时性要求高、允许少量数据丢失的场景,如视频流、在线游戏等。
| TCP | UDP |
|---|---|
| 传输层协议 | 传输层协议 |
| 有连接 | 无连接 |
| 可靠传输 | 不可靠传输 |
| 面向字节流 | 面向数据报 |
字节流与数据报的通信模型对比
字节流通信类似自来水供应,数据无边界,接收方可按需读取(如文件写入后读取困难);数据报则像快递包裹,收发边界严格对应(如UDP报文)。字节流由用户层解释内容(如管道一次读取多次写入的数据),数据报则需按发送格式解析。这种差异影响协议设计:TCP基于字节流,UDP基于数据报。
网络字节序
计算机数据存储的大小端问题
-
多字节数据存储存在大小端之分:小端模式将低权位数据存于低地址(如
0x123344e1中e1存于起始地址),大端模式反之。 -
在网络通信中,不同主机可能存在大小端不一致的问题,导致数据解释错误。小端主机发送数据到大端主机时,数据会被错误解释。为了解决这个问题,有人提出通过软件方案,在报文中使用一个字节标识大小端,但这种方案无法解决根本问题,因为无法确定哪个字节是标识字节。也有人建议统一硬件厂商的大小端标准,但实施难度大,涉及已售硬件和兼容性问题。最终解决方案是网络规定所有数据采用大端序列,小端主机发送数据前需转换为大端,接收时再转换回小端。操作系统会自动处理这些转换,确保通信正确。
-
网络通信中,操作系统提供主机转网络和网络转主机的接口,如
htons和htonl,用于处理端口号和IP地址的大小端转换。IP地址在网络中以32位数字形式传输,而非字符串形式,以提高传输效率。字符串形式的IP地址(点分十进制)可转换为32位网络格式,反之亦然。通过指针和结构体操作,可以方便地进行这种转换。 -
网络数据发送时,主机从发送缓冲区按内存地址从低到高的顺序发送数据,先发送低地址数据,后发送高地址数据。接收端主机将收到的字节按同样顺序保存到缓冲区。报文头通常位于高权值位,便于先获取报头信息再处理数据。
socket接口编程
网络通信中使用的套接字编程种类较多,最常见的有三种类型:网络套接字(network socket)、本地套接字(local socket,也称为Unix域套接字或Unix domain socket)以及原始套接字(raw socket)。
- 网络套接字既可以用于本地通信,也可以用于网络通信,是网络通信中的最终解决方案。
- 本地套接字仅用于本地通信,类似于网络版本的管道,这里不做说明。
- 原始套接字通常用于编写网络工具,与业务开发无关。
struct sockaddr
操作系统设计者在设计套接字接口时,考虑到不同种类的套接字可能导致接口数量激增且相似性高,对用户不友好,因此决定统一接口。为了实现接口的统一性,操作系统内部定义了一种通用的数据结构,即struct sockaddr,用于封装不同种类的套接字通信参数。无论是网络通信还是本地通信,用户都需要向操作系统传递参数,而操作系统通过统一的接口处理这些参数。网络通信需要传递IP地址和端口号,本地通信则通过文件路径标识通信双方。由于C语言不支持函数重载,操作系统设计了一种通用的接口struct sockaddr,用户在实际使用时需要进行强制类型转换。
- 实际通信时可能需要使用更具体的结构体,如
struct sockaddr_in(用于网络通信)或struct sockaddr_un(用于本地通信)。用户在调用接口时,需要将具体结构体的地址强制转换为struct sockaddr类型。操作系统内部通过结构体中的前16位字段(地址类型或协议族)区分通信类型,例如AF_INET表示网络通信,AF_UNIX表示本地通信。这种设计类似于多态的思想,即统一接口但内部实现不同。
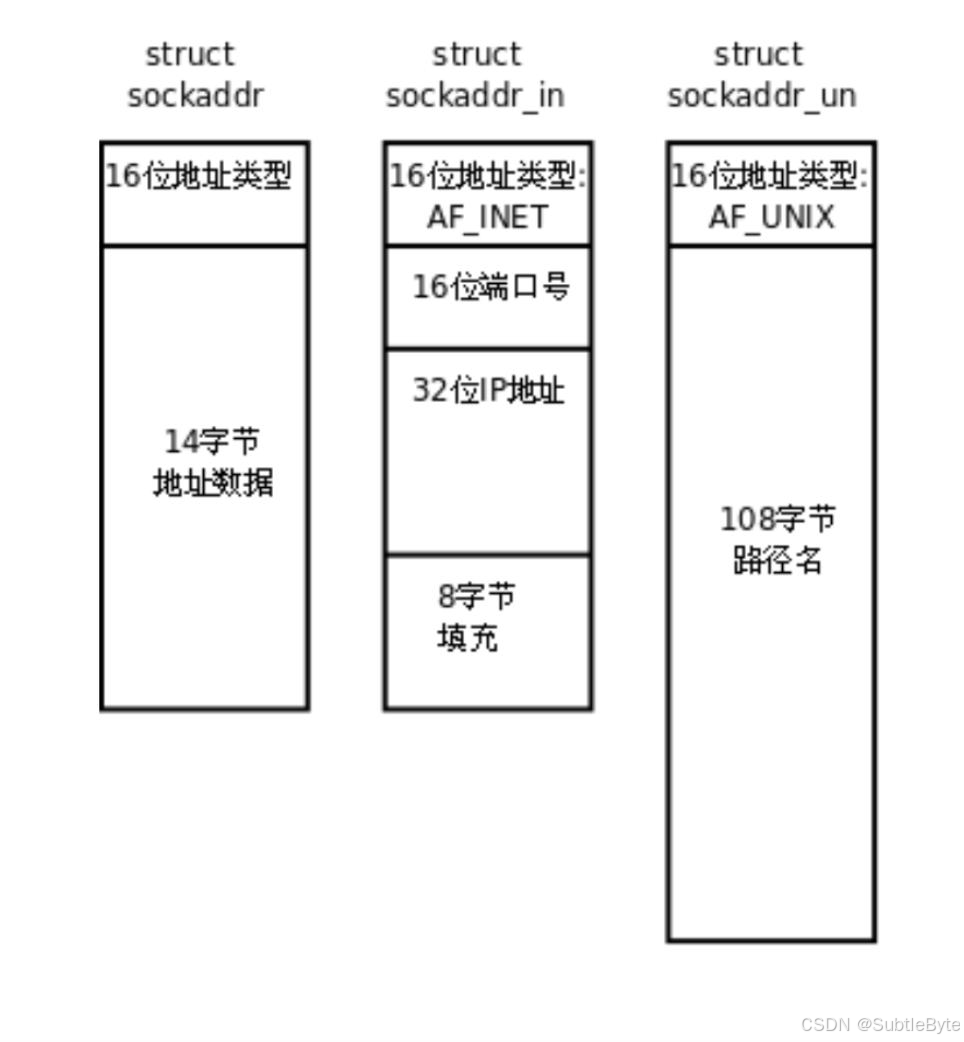
sockaddr 结构
struct sockaddr{__SOCKADDR_COMMON (sa_); /* Common data: address family and length. */char sa_data[14]; /* Address data. */};struct sockaddr_in{__SOCKADDR_COMMON (sin_);in_port_t sin_port; /* Port number. */struct in_addr sin_addr; /* Internet address. *//* Pad to size of `struct sockaddr'. */unsigned char sin_zero[sizeof (struct sockaddr)- __SOCKADDR_COMMON_SIZE- sizeof (in_port_t)- sizeof (struct in_addr)];};
其他结构:
typedef uint16_t in_port_t;typedef uint32_t in_addr_t;
struct in_addr{in_addr_t s_addr;};
in_addr 用来表示一个 IPv4 的 IP 地址. 其实就是一个 32 位的整数;
socket编程常用API
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address, socklen_t address_len);
// 开始监听 socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address, socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);