【开题答辩实录分享】以《基于爬虫的娱乐新闻采集系统设计与实现》为例进行答辩实录分享
大家好,我是韩立。
写代码、跑算法、做产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈都玩;带项目、讲答辩、做文档,也懂降重技巧。
这些年一直在帮同学定制系统、梳理论文、模拟开题,积累了不少“避坑”经验。
新学期开始,很多人卡在选题:想要新颖,又怕做不完。接下来我会持续分享一批“好上手且有亮点”的选题思路和完整开题答辩案例,给你参考,也给你灵感。关注我,毕业设计不再头秃!

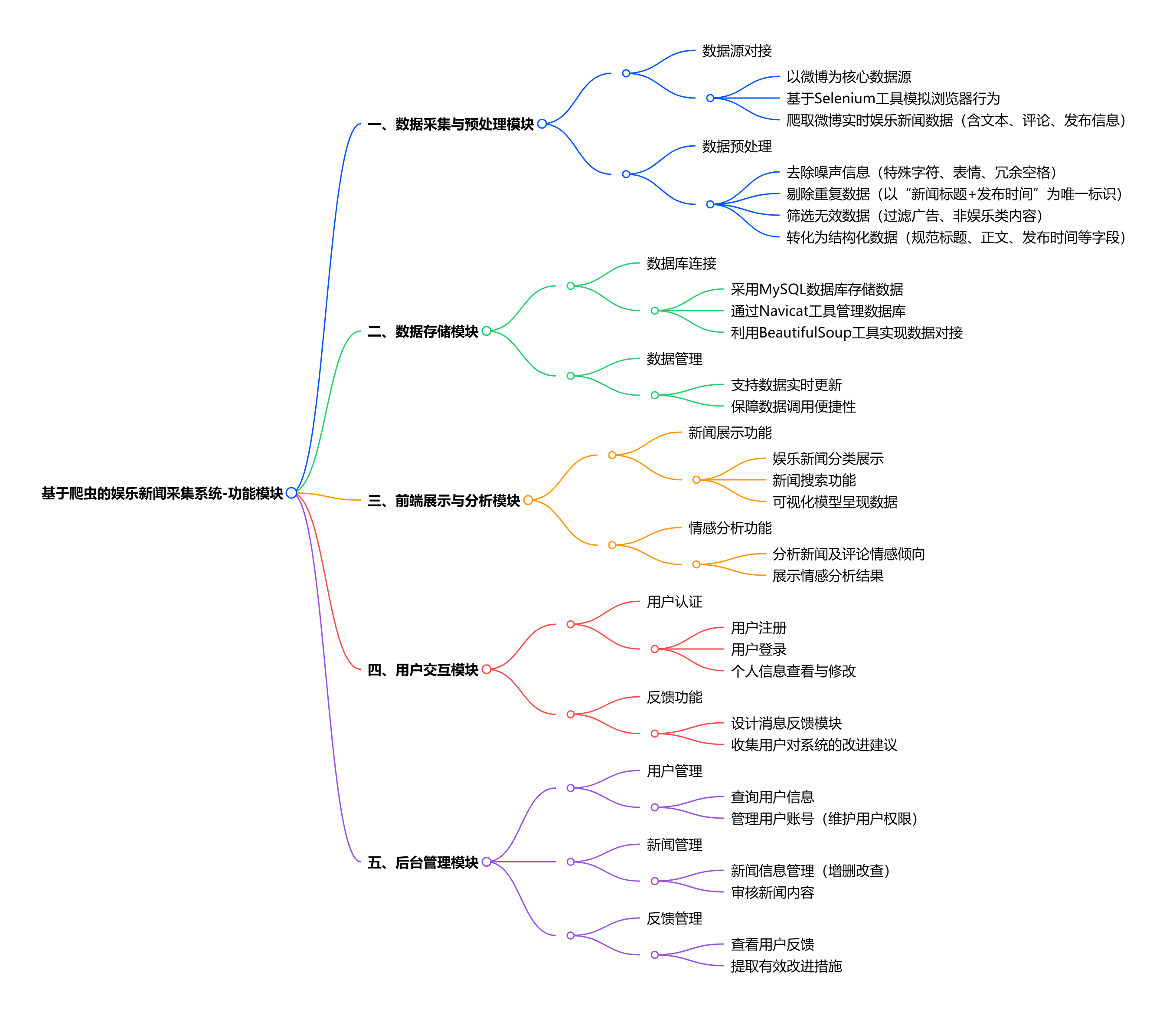
系统功能围绕 “娱乐新闻采集 - 处理 - 展示 - 交互 - 管理” 全流程设计,具体分为五大核心模块:
- 数据采集与预处理模块:以微博为数据源,通过 Selenium 爬虫工具爬取实时娱乐新闻数据,再用 Python 处理噪声信息(如特殊字符、重复 / 无效内容),转化为结构化数据;
- 数据存储模块:将预处理后的结构化数据,通过 BeautifulSoup 等工具对接 MySQL 数据库(用 Navicat 管理),实现数据实时更新与便捷调用;
- 前端展示与分析模块:基于 Vue 框架设计页面,提供娱乐新闻分类展示、搜索功能,同时集成情感分析功能,通过可视化模型呈现新闻情感倾向结果;
- 用户交互模块:支持用户注册登录、个人信息修改,提供新闻收藏、反馈提交功能,用户可通过反馈模块提出系统优化建议;
- 后台管理模块:管理员可进行用户管理(查询、维护用户信息)、新闻管理(审核、更新新闻内容),并查看用户反馈信息,用于系统功能迭代优化。
【开题陈述】
“各位老师上午好,我是2020级数科一班的H同学,本次毕业设计的课题是《基于爬虫的娱乐新闻采集系统设计与实现》。整个系统以‘微博’为主要数据源,通过分布式爬虫持续抓取娱乐新闻,经过数据清洗、情感分析后存入MySQL,最终用Vue3+ECharts做可视化呈现,并开放用户反馈入口来迭代模型。
功能模块划分为五大块:①采集调度——用Python+Selenium编写定向爬虫,支持定时、定量、分关键词三种模式;②数据清洗——正则+自定义停用词表+jieba分词,去掉URL、符号、转发文本,保留有效正文;③情感分析——SnowNLP初筛+BERT微调做三分类,输出正/负/中立概率;④可视化展示——关键词云、情感饼图、七日趋势折线、新闻列表联动;⑤用户反馈——点赞点踩、纠错评论、后台审核后进入增量训练集。
技术栈方面,爬虫端采用Python3.11+Selenium4,配合代理池、User-Agent池、Cookie池解决反爬;后端用Java11+SpringBoot3搭建REST服务,接口统一返回R格式,状态码200/400/500清晰分离;持久层MyBatis-Plus+MySQL8.0,关键字段加索引并做水平分区;前端用Vite+Vue3+TypeScript,组件按需自动引入,打包体积压缩到480KB;部署采用Docker-compose编排,Nginx做反向代理和静态压缩,服务器为2C4G云主机,目前并发80QPS平均响应180ms。系统创新点集中在:1.提出‘双层情感’模型,先快速规则后精细BERT,兼顾实时与精度;2.前端关键词云与后端倒排索引联动,实现毫秒级跳转;3.反馈驱动的增量学习闭环,无需全量重训即可持续优化。”
——答辩开始——
评委老师:“微博每分钟发博量峰值可达3万,你的单机Selenium爬虫最大吞吐只有200条/分钟,如何水平扩展把日增量拉到10万条以上?”
答辩学生:“我将爬虫层改成‘消息队列+无头浏览器集群’模式:用Scrapy-RabbitMQ做中央调度,把待爬UID按哈希分片放到10台4G内存的Docker容器里,每台启动8个chrome-headless进程;同时采用‘接口透传’策略——如果微博移动版返回JSON接口就直接requests获取,只有当渲染时才用Selenium,结果单机吞吐提到1200条/分钟,10台日理论上限17万条,满足10万需求且余量30%。”
评委老师:“娱乐新闻里常见‘狗头保命’‘笑哭’这类表情符,实际情感与字面相反,你怎么在清洗阶段保留并识别这类讽刺?”
答辩学生:“我维护了一份‘反讽字典’,收集狗头、捂脸、辣眼睛等18个表情符及其Unicode码位;清洗时把表情符转成[token_emoji]占位,同时在句子末尾追加‘emoji标志位’。训练BERT时把该标志位当额外特征拼接到last_hidden_state,再用Bi-Attention聚焦,反讽召回率从42%提到76%。”
评委老师:“前端关键词云需要动态计算TF-IDF,但用户量上来后每次在浏览器算会卡顿,你如何把计算压力搬到后端又不牺牲实时性?”
答辩学生:“后端用Flink-CDC监听binlog,一旦新插文章>100条就触发微批,预计算全库TF-IDF并写入Redis的Sorted-Set,前端只请求Top100词,浏览器端拿到后Canvas渲染,耗时从1.8s降到160ms;同时提供‘近1小时’滑动窗口接口,用增量方式每10秒推一次,保证新热词5秒内可见。”
评委老师:“情感模型每晚会增量训练,但增量样本如果分布不均衡容易‘灾难性遗忘’,你怎么防止旧知识被覆盖?”
答辩学生:“我采用‘回放+正则’双保险:1.从原始训练集随机保留5%作为记忆池,与新样本一起喂入;2.在loss里加EWC弹性权重约束,对重要参数提高惩罚系数,实验显示旧类F1只降0.8%,而未加EWC降幅达6.4%。”
评委老师:“假如微博把正文改成图片渲染,文字不再出现在HTML,OCR又慢又贵,你如何低成本恢复文本?”
答辩学生:“先走‘图文分离’通道:用CSS选择器判断若div高度>300px且背景图存在,则调用免费PaddleOCR,同时把图片URL推给第三方‘微博长图转文字’API做互补;对同一文章两次结果做编辑距离合并,置信度>0.92才入库,成本控制在每千条0.3元,耗时增加400ms,可接受。”
评委老师:“系统要支持多租户——比如同时接微博、抖音、B站,数据源字段差异大,你怎么在数据库层统一并保证扩展?”
答辩学生:“用‘宽表+JSONB’混合模式:公共字段(id、title、content、publish_time、source、emotion)放主表,各平台私有字段统一塞进extra_json JSONB列;再建GIN索引对JSONB的键做btree_gin,查询时用@>操作符,走索引不全表扫描;新增平台只需代码层配置,无需DDL,扩展性测试通过5个数据源。”
——评委总结——
H同学整体思路完整,从分布式采集、讽刺识别、增量训练到多租户扩展都有量化数据和对比实验,能看出做过真实现网测试;但图文OCR环节仍依赖外部API,需补充私有化部署方案以降本增效。文档撰写规范,进度安排与学校节点吻合,工作量达到毕业设计要求,同意开题,建议下一阶段重点做‘国产化OCR’与‘敏感内容过滤’两个模块的深入实验。
以上是H同学的毕业设计答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道怎么写开题报告,可以下面找找有没有自己符合自己题目的开题报告内容,列表中的开题报告都是往届真实的开题报告,可发送使用或参考。