【读代码】Qwen3-VL多模态大模型的架构、训练与应用
阿里最近开源疯了,一个接一个[狗头]
1. 项目简介
Qwen3-VL 是由阿里云开源的多模态大语言模型,支持文本、图像、文档、表格等多种输入,具备强大的视觉理解与生成能力。Qwen3-VL 继承了 Qwen3 系列的高效 Transformer 架构,并针对多模态任务进行了深度优化。其开源地址为:https://github.com/QwenLM/Qwen3-VL。
Qwen3-VL 支持多种推理模式,适用于问答、内容生成、视觉定位、表格理解等场景,在各大榜单上取得亮眼的成绩。
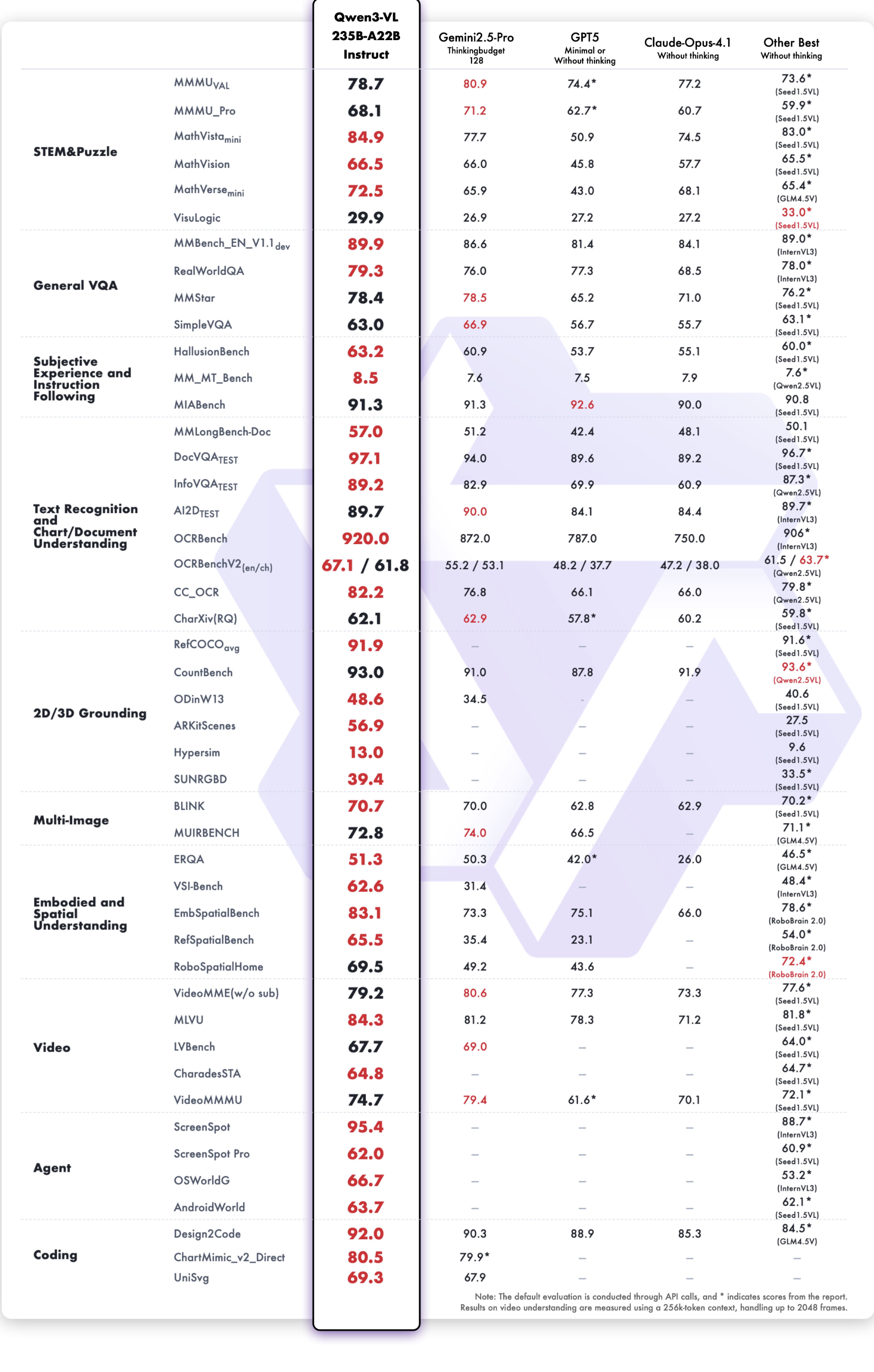
2. Qwen3-VL 模型结构详解
2.1 总体架构
Qwen3-VL 采用了 Encoder-Decoder 架构,核心由以下部分组成:
- 视觉编码器(Vision Encoder):负责将图像、文档等视觉信息编码为高维特征。
- 文本编码器(Text Encoder):基于 Qwen3 的 Transformer 架构,处理文本输入。
- 多模态融合模块(Multimodal Fusion):将视觉与文本特征进行融合,实现跨模态理解。
- 输出头(Output Head):根据任务类型输出文本、定位框、表格结构等结果。
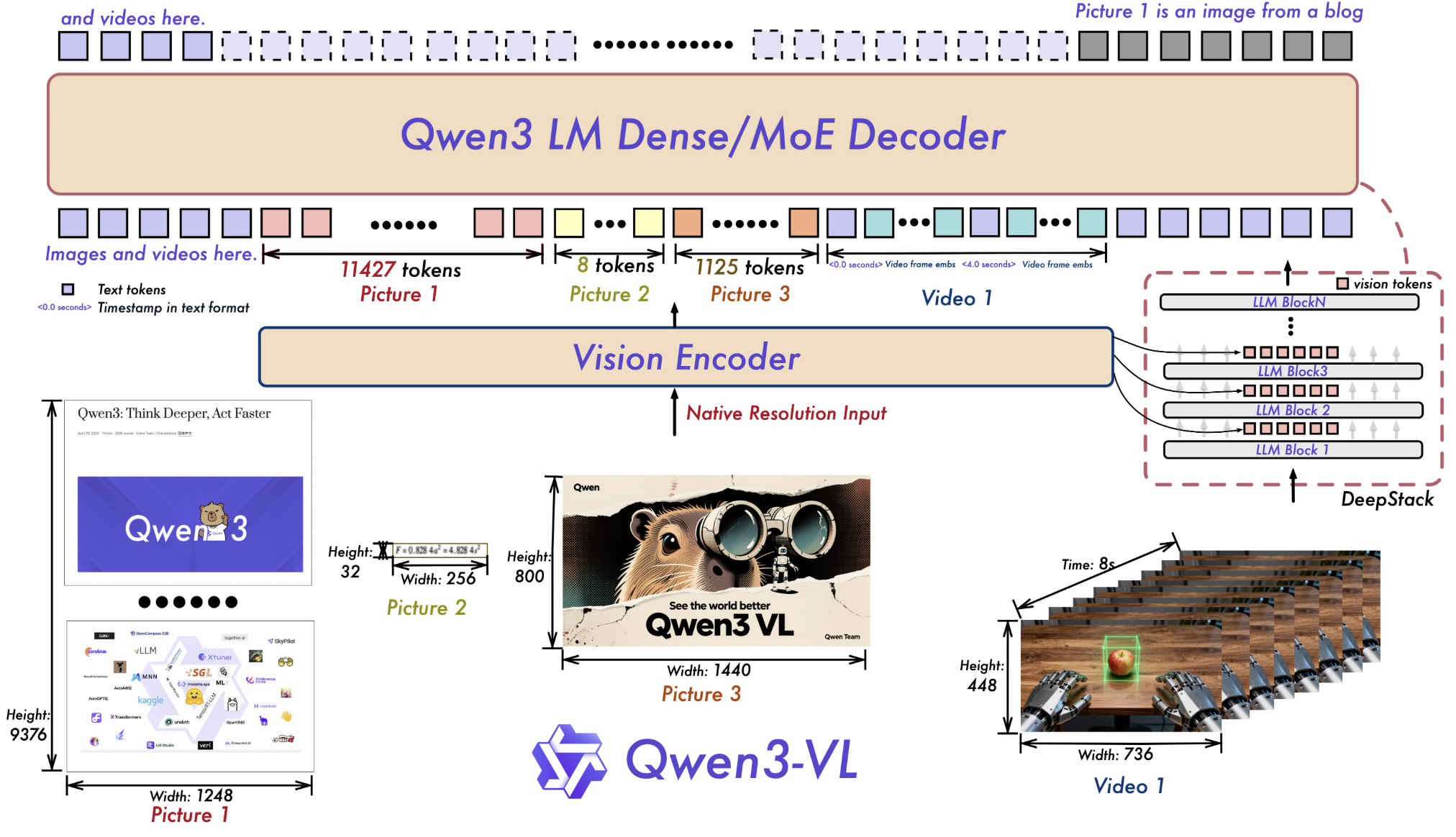
2.2 视觉编码器细节
视觉编码器采用了 ViT(Vision Transformer)变体,支持高分辨率图像输入。其结构如下:
class VisionEncoder(nn.Module):def __init__(self, ...):super().__init__()self.patch_embed = PatchEmbedding(...)self.transformer = TransformerEncoder(...)def forward(self, images):x = self.patch_embed(images)x = self.transformer(x)return x
- Patch Embedding:将图像分割为小块,嵌入为向量。
- Transformer Encoder:多层自注意力机制,捕捉全局视觉信息。
2.3 文本编码器细节
文本编码器基于 Qwen3 的高效 Transformer,支持长文本输入,具备强大的语言理解能力。
class TextEncoder(nn.Module