【不背八股】17.什么是Bert?
引言
2018 年,Google 提出了 BERT,成为了 NLP 领域代表性的工作之一。
BERT 首次成功地在大规模语料上进行深度双向预训练,并通过简单微调就能在多个任务上达到当时的最佳效果。
本文主要解读 BERT 这篇论文,看看它具体是怎么做的。
论文标题:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
论文地址:https://arxiv.org/pdf/1810.04805

1. 名称和动机
BERT 的全称是:Bidirectional Encoder Representations from Transformers
这个英文表述看上去是有点怪的,背后原因是在之前有一篇 ELMo 的工作,用的是《芝麻街》的角色名称,于是 BERT 想沿用这一习惯,凑成了另一个《芝麻街》的角色名称。
不难看出,BERT 的思想很大程度上来源于 ELMo,ELMo 是使用了双向 LSTM来生成上下文相关的词表示,但LSTM 的结构在捕捉长距离依赖上存在一定瓶颈,训练效率和扩展性也不如 Transformer。
于是,BERT 把 ELMo 双向的思想和 Transformer 一结合就形成了这篇工作。
2. BERT 核心思想
虽然 BERT 的动机很朴素,但它还是做了一些原创性的东西,具体来说有以下几点核心思想:
-
Transformer Encoder 架构
BERT 的目标不像是 Transformer 做句子翻译,它主要针对的是文本理解类的任务,因此它舍弃了 Transformer 的 Decoder,仅保留了Encoder 架构。 -
深度双向表示
BERT 通过 掩码语言模型(MLM, Masked Language Model) 和 (NSP,Next Sentence Prediction),使每一层 Transformer Encoder 都能基于全句信息进行建模,形成深度的双向交互。 -
预训练 + 微调的范式
在 BERT 之前 ULMFiT 首次提出预训练 + 微调的这套训练范式,BERT继续沿用,并将其发扬光大,目前这套范式基本被所有主流方法所采用。
3. 主要创新点
从 BERT 这篇文章标题就能看出,它主要的创新点作用于预训练的过程,通过 大规模无监督预训练,让模型习得通用的语言知识。
它设计了两个任务:Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。这两个任务分别让模型学会理解单句话的上下文和两句话之间的逻辑关系。
3.1 Masked Language Model (MLM)
思路
在传统的语言模型里,模型往往是单向的:只能预测下一个词(左到右),或只能预测前一个词(右到左)。这样做导致模型无法同时利用双向上下文。
BERT 引入 MLM,即“随机遮盖语言模型”:
-
在输入句子中随机选择 15% 的词进行遮盖。
-
遮盖方式:
- 80% 的概率用特殊标记
[MASK]替换(例如 “I went to the [MASK] yesterday”); - 10% 的概率换成一个随机词(例如 “I went to the cat yesterday”);
- 10% 的概率保持原词不变。
- 80% 的概率用特殊标记
-
模型训练时要根据上下文来预测被遮盖位置的真实词。
效果
- 这样设计避免了模型“偷看”目标词本身,同时保证训练与测试的分布尽量接近。
- 更重要的是,MLM 让模型必须利用 左右文信息 来推理缺失的词,从而学习到 深度双向表示。
3.2 Next Sentence Prediction (NSP)
思路
语言理解不仅仅是理解一句话,还要理解 句子之间的逻辑关系。为此,BERT 设计了 NSP 任务:
-
输入是两个句子 A 和 B。
-
模型需要预测:B 是否是 A 的下一句?
- 50% 的情况下,B 确实是 A 的下一句(标签:IsNext);
- 50% 的情况下,B 是从语料中随机挑选的(标签:NotNext)。
附录中给出了 IsNext 和 NotNext 的示例,里面的##less表示原句子原本是flight-less这个单词,但为了拆解成常用词组合,切成两个token。
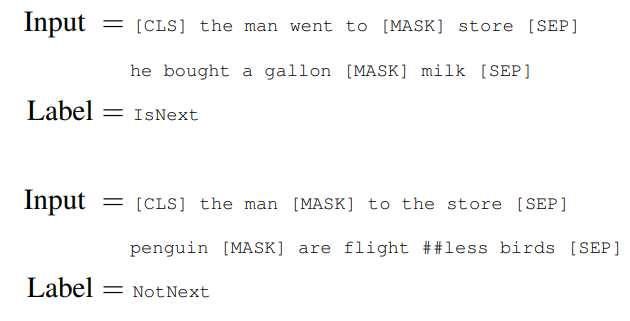
效果
- NSP 让模型学会判断句子之间是否连续,提升了对 段落结构、语义连贯性 的理解。
- 在诸如 问答 (QA)、自然语言推理 (NLI) 等任务中,NSP 特别有帮助,因为这些任务都涉及句子对之间的语义关系。
3.3 为什么这两个任务能让 BERT 更懂语言?
-
MLM 教会 BERT 如何在 单句话 内利用双向上下文理解语义,解决了词义消歧的问题。
- 例:在 “He went to the river bank” 和 “He deposited money in the bank” 中,预测 “bank” 时,模型必须利用上下文区分是“河岸”还是“银行”。
-
NSP 教会 BERT 如何在 句子之间 理解逻辑关系,从而更好地处理问答、推理等任务。
- 例:在 “I bought a new phone. It has a great camera.” 中,模型学会了“它”指代前一句的“phone”,而不是其他对象。
这两个任务结合起来,让 BERT 同时具备 句内理解 与 句间理解 的能力,从而在多种 NLP 任务上展现出强大的表现。
4. 模型结构
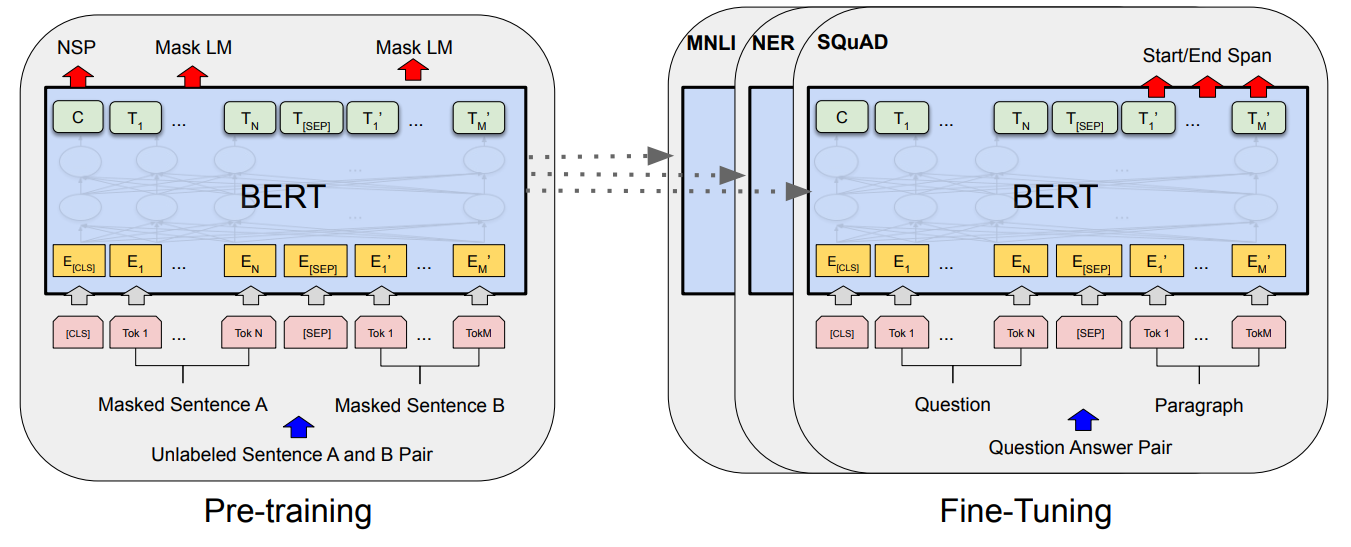
BERT 的结构如上图所示,左侧是预训练过程,右侧是微调过程。
4.1 模型型号
BERT 主要分为两个版本:BERT-BASE 和 BERT-LARGE,两个模型的规模如下:
-
BERTBASE
- 12 层 Transformer Encoder
- 隐藏层维度:768
- 自注意力头数:12
- 参数量:约 1.1 亿
-
BERTLARGE
- 24 层 Transformer Encoder
- 隐藏层维度:1024
- 自注意力头数:16
- 参数量:约 3.4 亿
4.2 输入表示
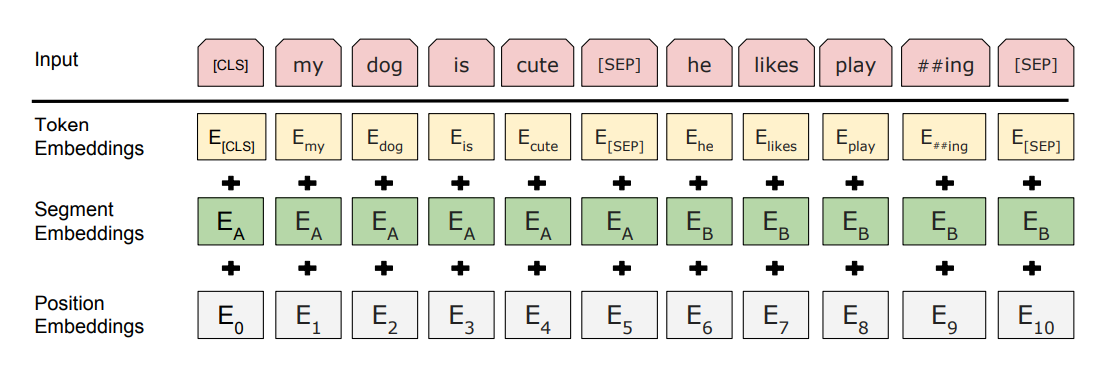
BERT 的输入不仅仅是词向量,还包含了三种 embedding:
-
Token Embedding
- 由 WordPiece 分词得到的子词单元。
- 例如 “playing” 会被拆分成 “play” + “##ing”。
- 每个 token 会被映射到一个固定维度的向量。
-
Segment Embedding
- 用来区分句子对中的两个句子。
- 句子 A 的 token 加上 Segment A embedding,句子 B 的 token 加上 Segment B embedding。
- 如果是单句任务,则所有 token 都属于 Segment A。
-
Position Embedding
- Transformer 本身不具备顺序信息,因此需要额外的位置信息。
- BERT 使用与 Transformer 原论文类似的位置编码,让模型知道每个 token 的位置。
最终,每个 token 的输入表示 = Token Embedding + Segment Embedding + Position Embedding。
4.3 统一处理单句、句对
BERT 设计了一个统一的输入格式,使它能同时处理单句任务和句对任务:
-
特殊标记
- 输入序列开头始终加一个 [CLS] 标记,对应的向量用于分类任务。
- 在句子 A 和句子 B 之间插入一个 [SEP] 标记。
- 每个输入序列末尾也会有一个 [SEP],方便句子边界识别。
-
单句任务
- 输入格式:
[CLS] 句子A [SEP] - Segment Embedding 全部标记为 A。
- [CLS] 的输出向量用于下游分类任务(如情感分类)。
- 输入格式:
-
句对任务
- 输入格式:
[CLS] 句子A [SEP] 句子B [SEP] - Segment Embedding 用 A/B 区分两句话。
- [CLS] 的输出向量用于判断句子对关系(如自然语言推理、问答的起点)。
- 输入格式:
这种统一设计,使得 BERT 可以在不改变主体架构的前提下,处理多种不同任务。
5. 微调多任务
BERT 采用了 “预训练一次,微调用于多任务” 的范式:
- 预训练阶段,模型学习了通用的语言规律;
- 微调阶段,只需在顶层加一个简单的任务特定层(如分类器或 span 预测头),即可在不同任务上达到很强的表现。
5.1 句子级任务
句子级任务的目标是对整个句子或句子对进行分类。
-
文本分类
- 任务:判断一句话的情感(积极/消极)、主题类别等。
- 用法:输入格式
[CLS] 句子 [SEP],取[CLS]的向量接一个 softmax 分类层,即可完成。
-
自然语言推理 (NLI)
- 任务:判断两句话的逻辑关系(蕴含、矛盾、中立)。
- 用法:输入格式
[CLS] 句子A [SEP] 句子B [SEP],取[CLS]的向量接分类层,输出三分类结果。
5.2 词级任务
词级任务的目标是对句子中每个词进行标注或定位。
-
命名实体识别 (NER)
- 任务:识别人名、地名、机构名等。
- 用法:输入
[CLS] 句子 [SEP],BERT 输出每个 token 的向量,在其上接一个 token-level 的分类层(如 BIO 标注)。
-
问答 (QA, SQuAD)
- 任务:给定一段文本和一个问题,找出答案所在的片段。
- 用法:输入
[CLS] 问题 [SEP] 段落 [SEP],BERT 输出每个 token 的向量;在其上加两个分类器,分别预测答案的起始位置和结束位置。
相比过去需要为每个任务单独设计模型的方式,BERT 极大降低了任务定制的复杂度。
同时,微调所花费的资源成本是比较少的,根据论文描述,所有微调可在一张谷歌云的TPU 一小时或者一张 GPU 几小时完成。
微调之后的模型在GLUE、SQuAD、SWAG 等多个基准测试中刷新纪录。
6. 总结
总体来看,Bert的思想不复杂,一句话概括就是“双向完形填空+句子顺序判别”,整篇文章也基本没有难点。
虽然 Bert 的性能不错,但它也是有局限性的,它仅保留了Transformer Encoder的结构,因此在翻译、写作、对话等需要自然语言生成的任务中无法适用,其更多用于分类、抽取、匹配等理解类任务。
一篇好的工作,往往不局限于一个领域,Bert显然做到了辐射多个领域的特点,这也是它影响力巨大的重要原因。