AI 时代火山引擎对象存储:为数据松绑,让算力起飞
资料来源:火山引擎-开发者社区
痛点直击:谁在拖慢智能化进程?
在 AI 浪潮下,无论是追求技术突破的 AI 算法公司,还是致力于自动驾驶的研发团队,都面临同一"隐形杀手"——存储带宽瓶颈。这个看似不起眼的问题,却可能让你的智能化项目功亏一篑。
AI 训练 / 推理:“数据堵在路上,算力闲在机房”
AI 业务对数据传输的“爆发性”与“连续性”有着极高要求,带宽不足会使研发效率断崖式下降:
- 大模型训练:在千亿参数大模型训练时,需向 GPU 集群传输百万级别的样本(单轮数据量超 10TB)。若带宽传输与算力读取速度不匹配,GPU 利用率将从 90% 骤降至 30% 以下,原本计划 7 天完成的训练周期会被迫延长至 20 天,成本大幅增加。
- 推理服务峰值:AI 图像识别、智能客服等业务高峰时,需从对象存储实时调取模型参数与推理样本。若带宽未及时扩容,会导致推理延迟从 50ms 飙升至 500ms,严重影响用户体验。
汽车智驾:“多系统抢带宽,核心功能掉链子”
智能汽车的感知、决策、控制等系统共用存储,缺乏带宽管控会引发近“安全级”风险:
多系统资源争抢:以智驾仿真推理为例,流程包含数据拉取、仿真推理、评测任务、及持久化结果文件等环节。在未实施带宽管控时,低优先级业务可能占用 90% 带宽,挤压高优先级业务资源,导致 GPU 等待超时甚至任务失败。
TOS 让性能“跟得上算力”,也“配得好系统”
针对 AI 与智能驾驶场景的挑战,对象存储 TOS 推出两项创新:突发带宽与流量策略(QosPolicy),为智能时代定制存储解决方案。
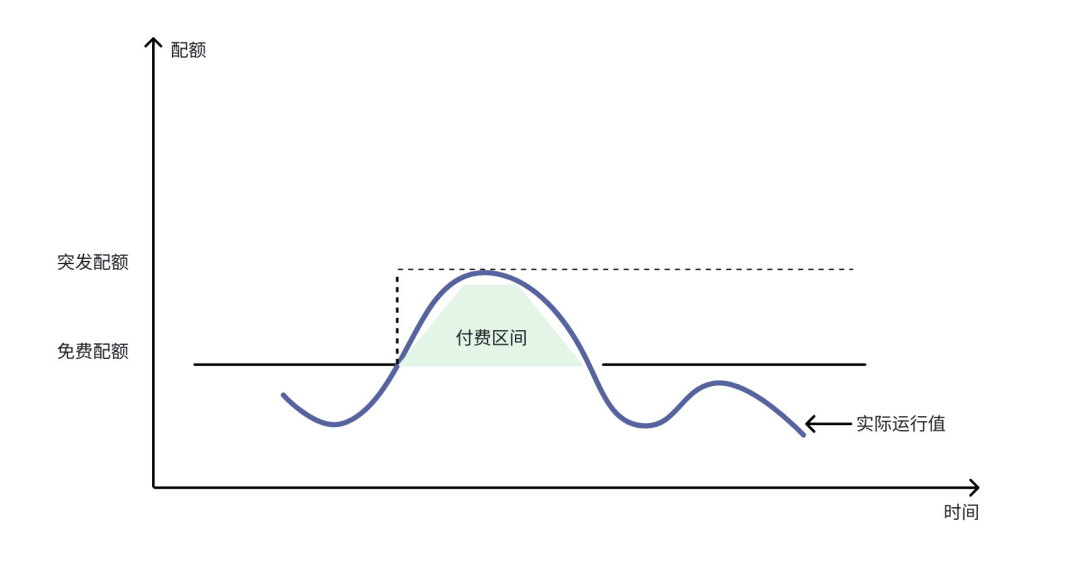
突发带宽:训练数据“喂饱算力” ,智驾峰值 “秒级响应”
TOS 突发带宽具备实时自动触发、无冷却期、无时长限制等特点,可在预设上限内按负载弹性扩展,适用于流量剧烈波动或峰值不可预测场景,有效缓解 “算力闲置” 与 “峰值卡顿” 问题:
- 算力不等人,带宽弹性伸缩:GPU 集群大规模读取时,带宽随负载自动扩展,保持数据吞吐与算力同步。
- 按使用付费,成本精打细算:采用 “基础带宽 + 突发带宽” 混合计费模式,仅在训练、推理峰值时支付突发带宽费用。避免传统预购导致的 90% 资源闲置。
流控策略:AI 数据 “有序调度”,智驾系统 “优先置顶”
如果说突发带宽解决了"不够用"的问题,那流控策略就是解决"用不好"的难题。TOS 流控策略就像给高速公路划分专属车道,确保不同优先级的业务互不干扰。
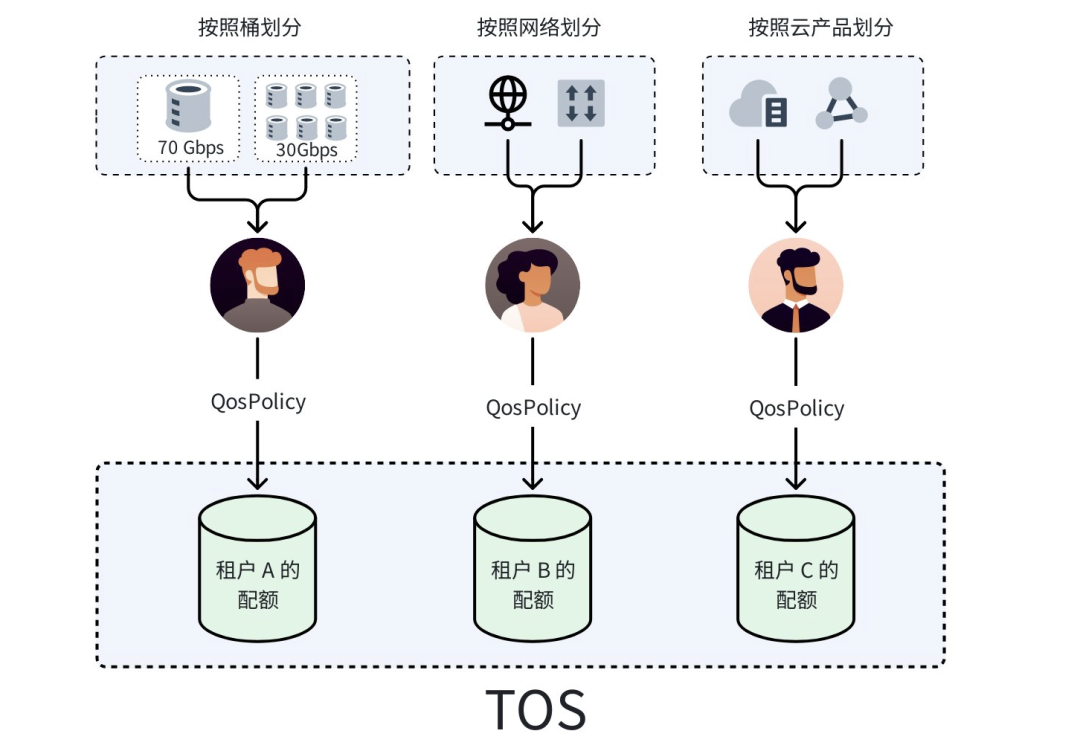
- 多维度管控,精准 “划清边界”:TOS 支持按不同访问来源(账号、用户、角色)为不同资源(存储桶、数据前缀)设置精确的 QoS 限制,实现业务隔离。
- 优先级调度,核心 “绝不掉队”:为业务设置带宽优先级(如 AI 训练>推理>日志备份;智驾感知>决策数据>娱乐数据),当总带宽接近上限时,自动优先保障高优先级业务。
典型案例
租户 A 在华北 2 拥有 7 个存储桶,需确保核心桶 bucket-a 获得 70% 带宽(该租户总写带宽上限为 100Gbps)。通过配置其他 6 个桶的写带宽上限为 30Gbps,使 bucket-a 独占 70Gbps,从而完成业务的性能管理。
配置语法:
{ "Sid": "策略配置名", "Quota": { "WritesQps": "", "ReadsQps": "", "ListQps": "", "WritesRate": "30000", // 写带宽 30Gbps "ReadsRate": "" }, "Principal": [ "*" ], "NotResource": "trn:tos:::bucket-a/*" }
技术内核:分布式架构如何支撑“弹性”与“管控”双重能力
TOS 采用经典的分布式系统架构,自上而下分为接入层、协议层、元数据层和存储层。
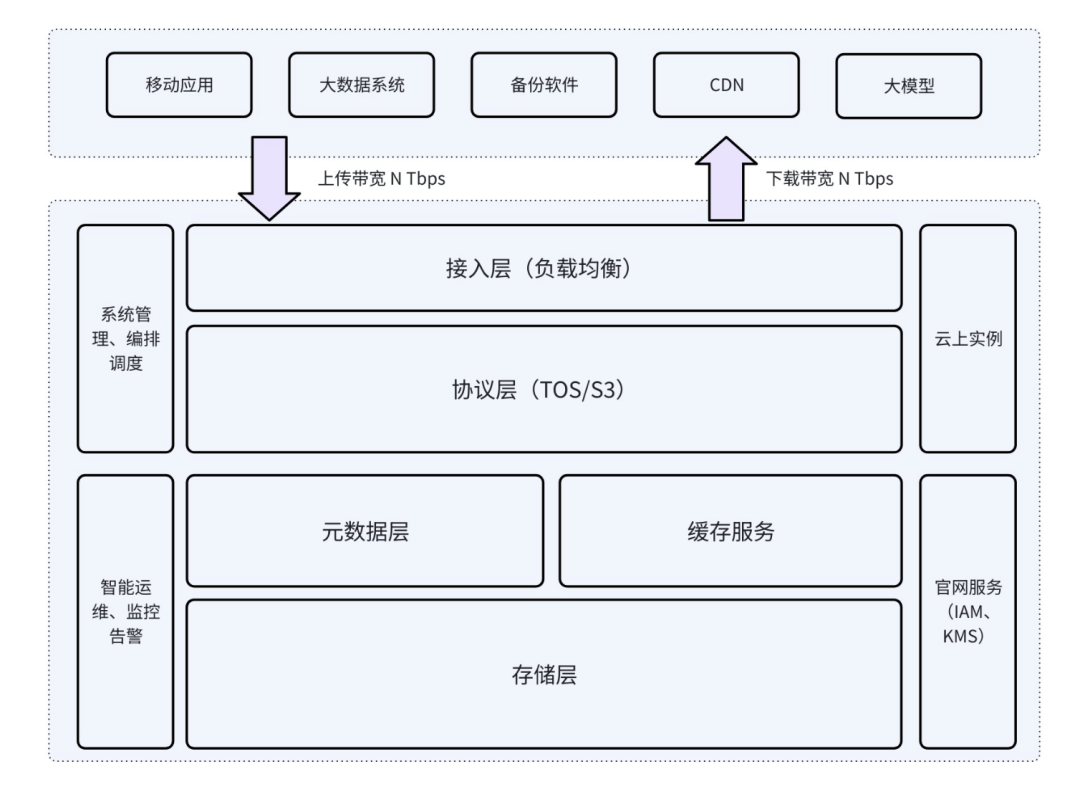
每层由多个系统单元构成,每个单元都有特定规格。这些规格从内而外,最终使系统呈现为一个容量和性能可线性扩展的存储系统。
从稳定性角度,我们不追求超级单体——若单实例运行速率达到 1 Tbps,一旦出现故障,损失同样是 1 Tbps。因此我们需合理划分运行单元,控制承载压力。
从系统角度,当用户 1 Tbps 带宽请求进入系统后,被拆分至多个系统单元承接。接入层、协议层、元数据层和存储层均是如此。确保每个单元安全的基础上,进行层层抽象,规划上层能力。可以说,若无单元的流控规格,系统便无法真正实现高效运行。
流控基本原理
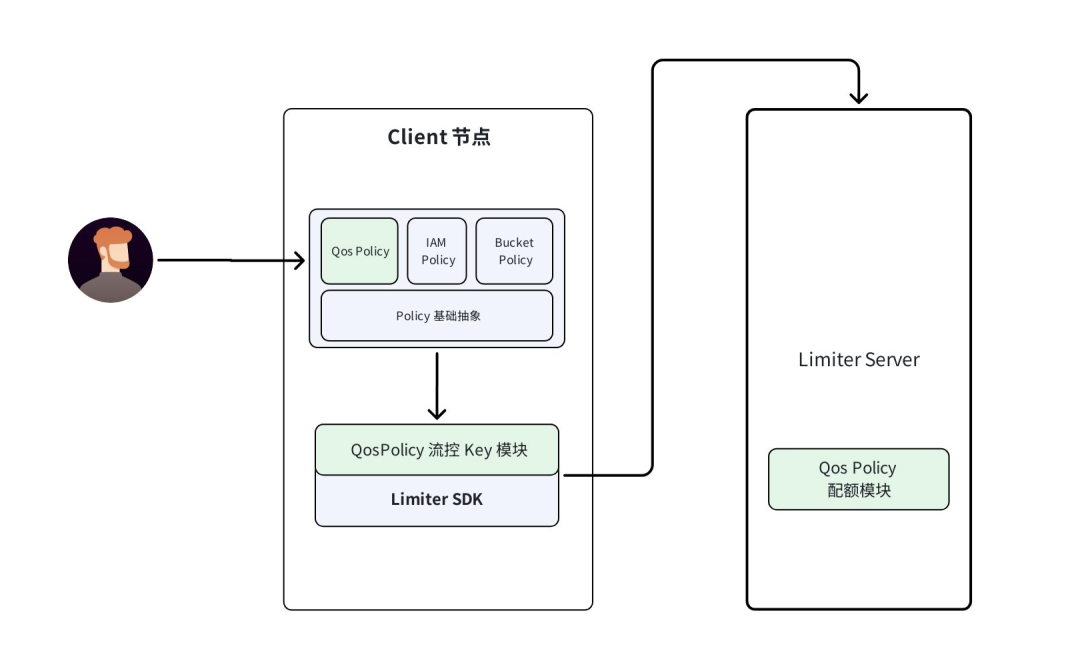
流控机制是 TOS 实现精准带宽管控的核心技术。其基本原理基于令牌桶算法,但 TOS 在此基础上进行了深度优化。其核心思想是借助令牌的生成与消耗来控制请求的处理速率。以下是我们 Limiter SDK - Limiter Server 的模块图:
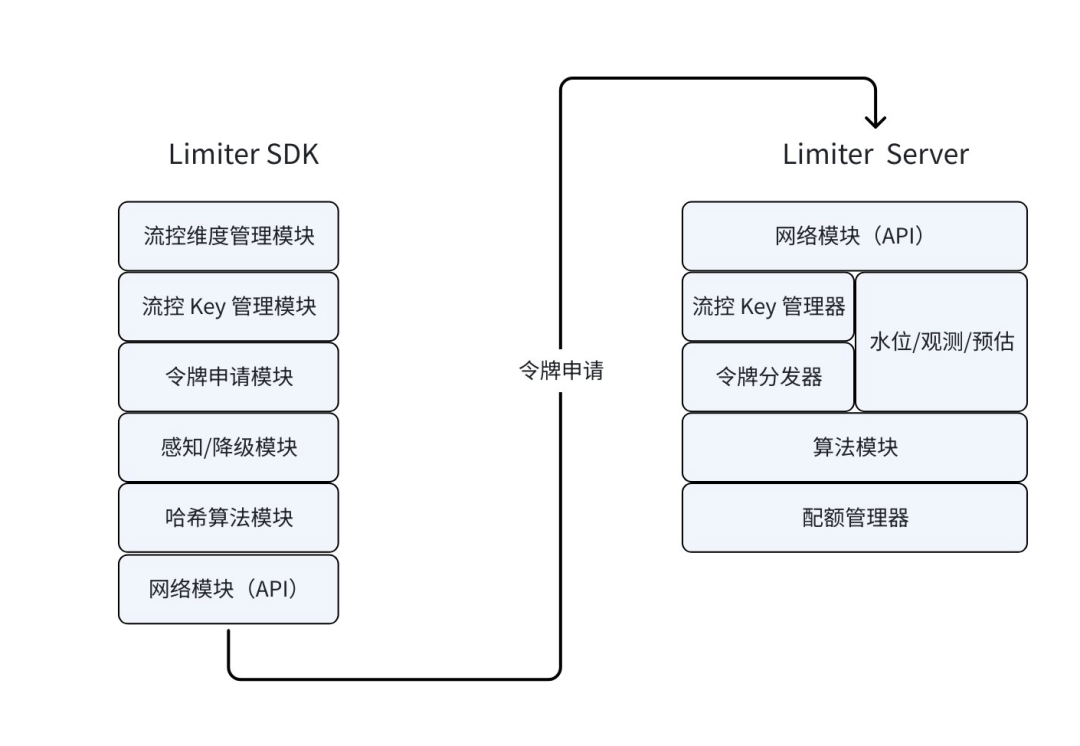
架构层面
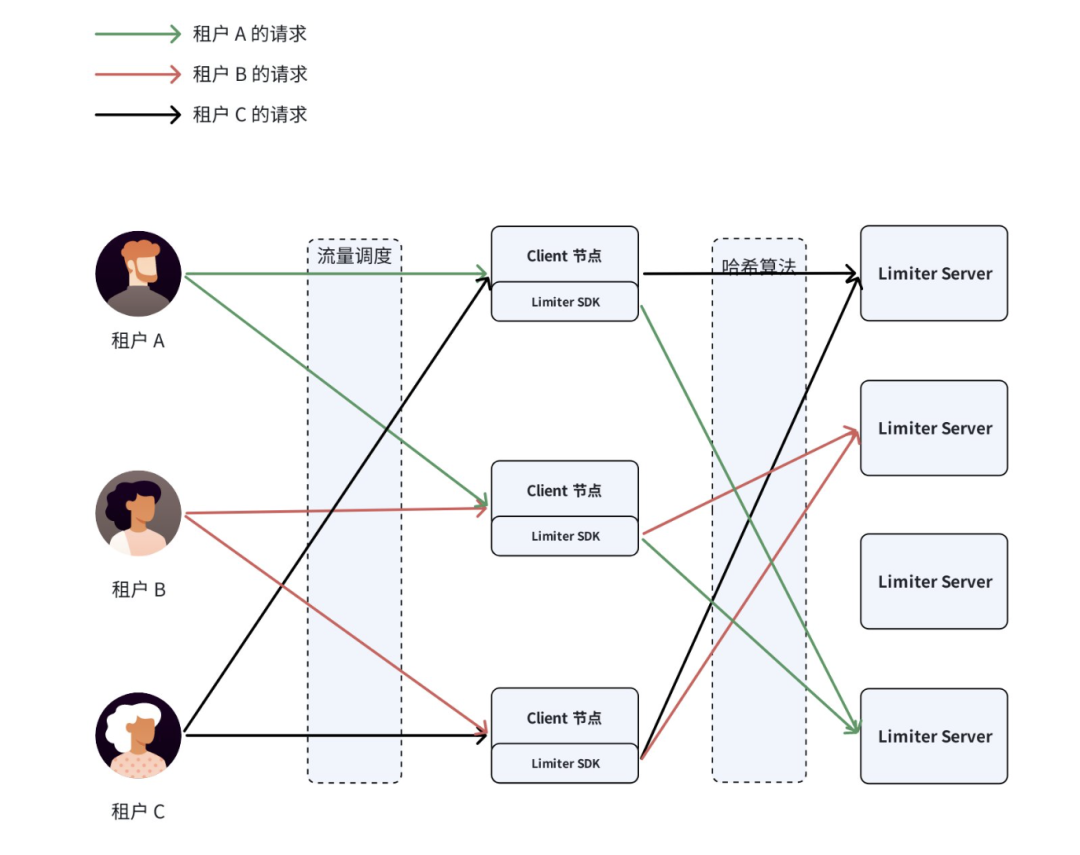
在分布式环境下,最大的挑战是节点频繁变化导致的"哈希雪崩"。TOS 通过优化一致性哈希算法,确保同一流控项的所有 Client 精准指向同一 Limiter Server,在保证映射一致性的同时,具备强大的节点变化容错能力。另外 TOS 自主研发的 Limiter Server,具备低消耗、高 QPS 以及灵活的定制化能力。
业界常见的一种实现方式是将令牌的分配状态存储于 Redis 中。
配额管理
我们系统内部有成千上万的流控项,如何做到租户之间相互隔离,不同的维度之间互不干扰?
关键点是,每个流控项对应一个流控 Key,每个流控 Key 对应一个令牌分发器。一个 Limiter Server 上有多个令牌分发器。
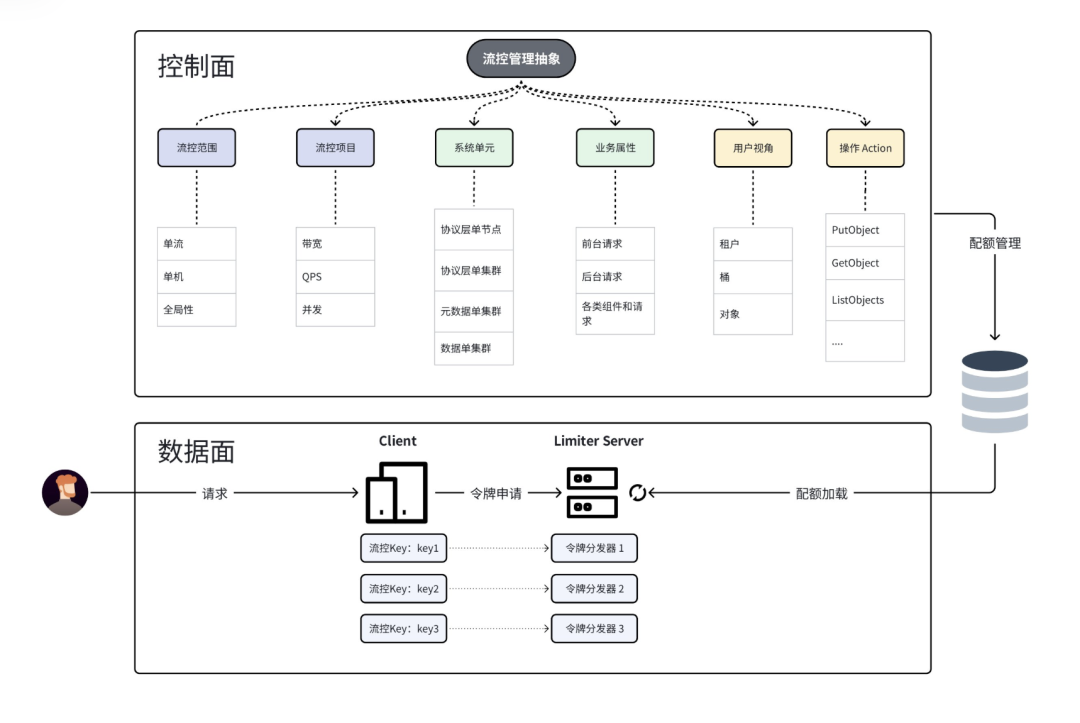
我们为每个租户的每个流控项分配独立的流控 Key,这对控制面的设计有很大的挑战。为此我们研发了统一的抽象机制,使得一个流控项进行增、删、改时,仅需最小改动,复用全部基础体系。
体验方面:带宽流控时,为了减少客户端异常处理,我们提供“降速不失败”能力。降速中持续观测用户 IO 模型,自动调整策略,并在合适的时候,切换为直接返回 429。且降速场景提供“单流保活”,防止连接被“饿死”,进一步提升体验。
全链路异步化
在海量数据(EiB 级)和超大带宽(Tbps 级)背景下,单对象对应数次 IO 操作,每次 IO 均需消耗令牌,导致 Limiter Server 需承载极高请求量。单地域 Limiter Server 需支撑上百万 QPS 吞吐(微秒 / 纳秒级时延),这对硬件算力、请求链路的技术挑战极大 。在突发场景下,流量突发导致令牌瞬时耗尽,导致业务体验的剧烈波动,一会快,一会卡。基于这些挑战,我们实现了流控全链路的异步化和智能化:
- 异步预取机制:Client 节点异步申请令牌,基于历史流量预估预取资源,削峰填谷保障业务连续性。
- 请求聚合处理:对发往 Limiter Server 的请求进行无损聚合,提升整体吞吐效率。
- 细粒度时间分片:将秒级时间切片控制流量,实现平滑整形。
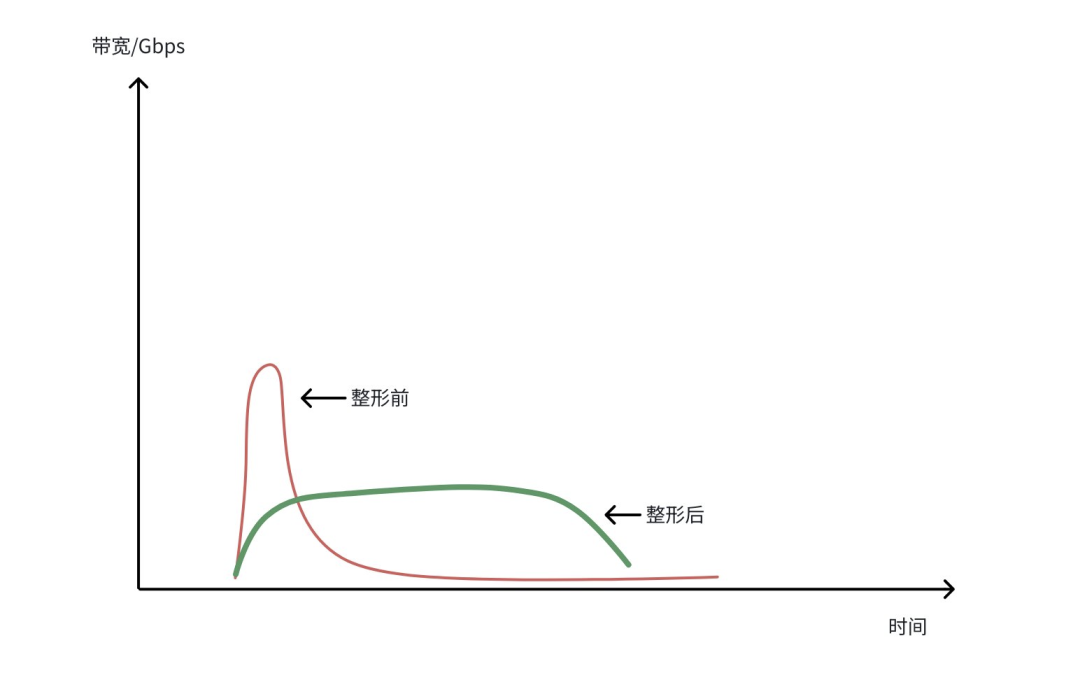
该方案打破了令牌获取压力与业务流量的线性关联,轻松支撑十万至百万级 QPS,通过 “削峰填谷” 平衡了流量控制精度与业务响应效率。
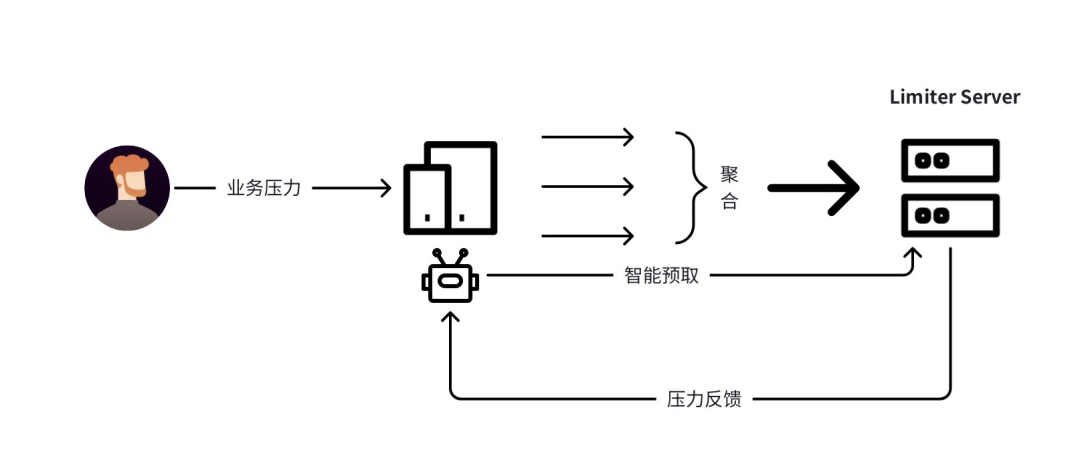
在分布式系统中,网络异常是常见问题。当无法连接 Limiter Server 时,需要在“不控带来风险”与“过控损伤体验”之间取得平衡。为保障业务连续性与流量稳定性,我们设计了三层降级机制。
1.智能化学习历史数据:基于数据惯性特征,若历史流量稳定,故障时沿用近期流量阈值(如 A 节点 10Gbps),通过平滑过渡算法维持服务质量。
2.单节点配额的预估:针对无历史数据或突发流量场景(如长时间未访问的用户突发请求),主动推送动态配额至客户端节点,通过定期智能分析实现配额预分配,从而实现本地流控。
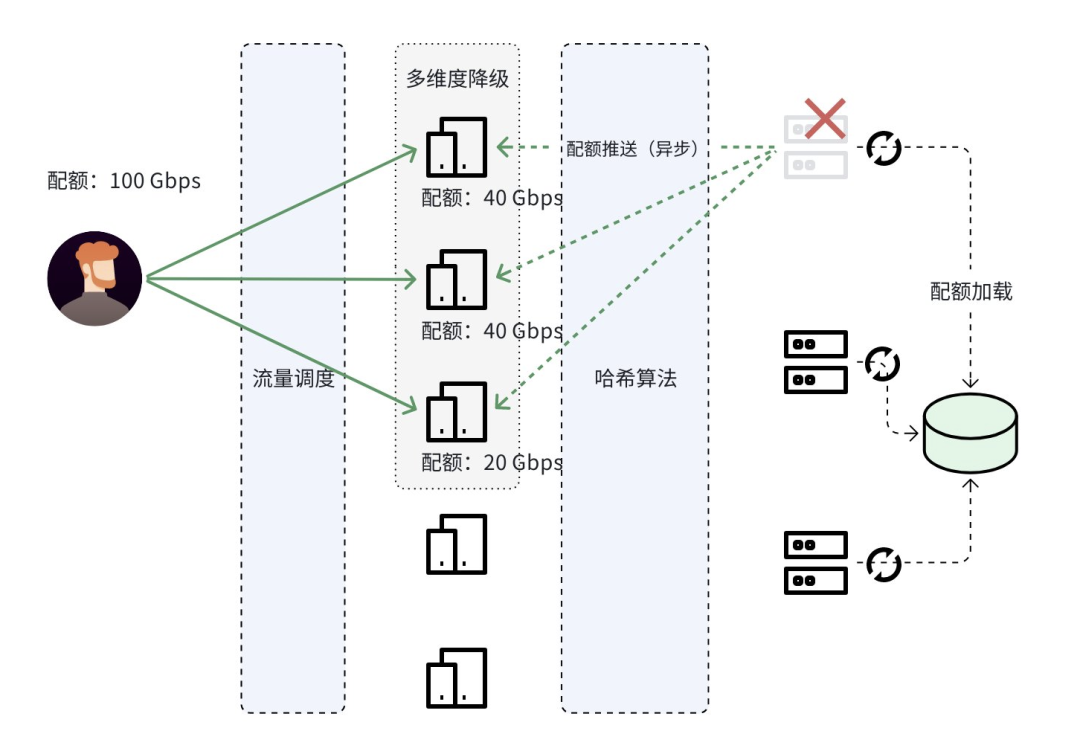
3.默认限制:作为兜底策略,在极端情况下触发系统级默认限流,确保整体服务不崩溃,覆盖前两层未处理的异常场景。
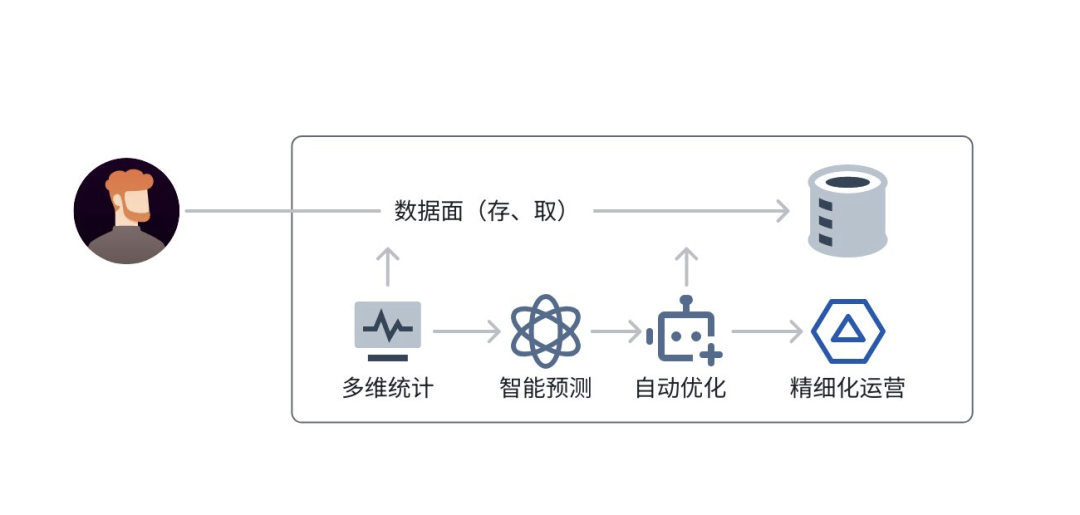
多维度流量统计
TOS 构建了全方位的观测体系,对流量(公网、内网)、QPS、时延、连接数、容量、单节点、单集群等各个维度进行实时监控。基于这些丰富的数据输入,运用智能化算法分析,能够迅速察觉用户流量异动和系统水位状况。同时,会计算得出每个单元的稳定性系数,为精细化运营和系统优化提供精确依据。
此外,这些数据输入还用于分析用户的 I/O 模型,以便为用户匹配更优的性能配置,进一步提升用户体验。
自动化性能规格拟合
在对象存储场景中,常需解决两类核心问题:
1.支撑用户 1Tbps 带宽需多少资源?
2.1000 台存储服务器可承载的多少读写带宽、QPS ?能否满足用户需求?
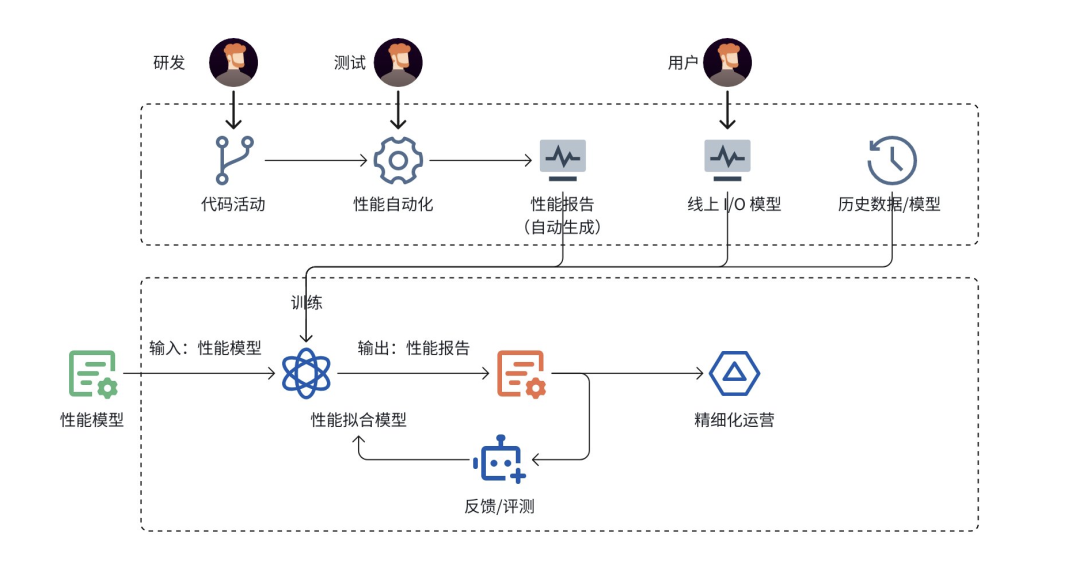
纯 IO 模型评估相对简单,但实际用户场景多为读、写、删、列举等操作的混合模型,难以通过理论推导直接解答,传统依赖对等测试验证,存在成本高、周期长的痛点。
为此,TOS 构建了性能规格自动拟合体系:通过常态化采集各类典型混合 IO 测试数据,输入智能化分析系统,利用拟合算法实现线上资源在混合场景下的规格量化与水位评估。核心包括多维度数据采集、自动化性能体系构建、精准拟合算法及反馈评估机制。
例如,用户输入 5Tbps 带宽的 IO 模型需求,系统可自动计算资源承载能力及所需存储规模,大幅提升运营运维效率。
性能仓储智能化
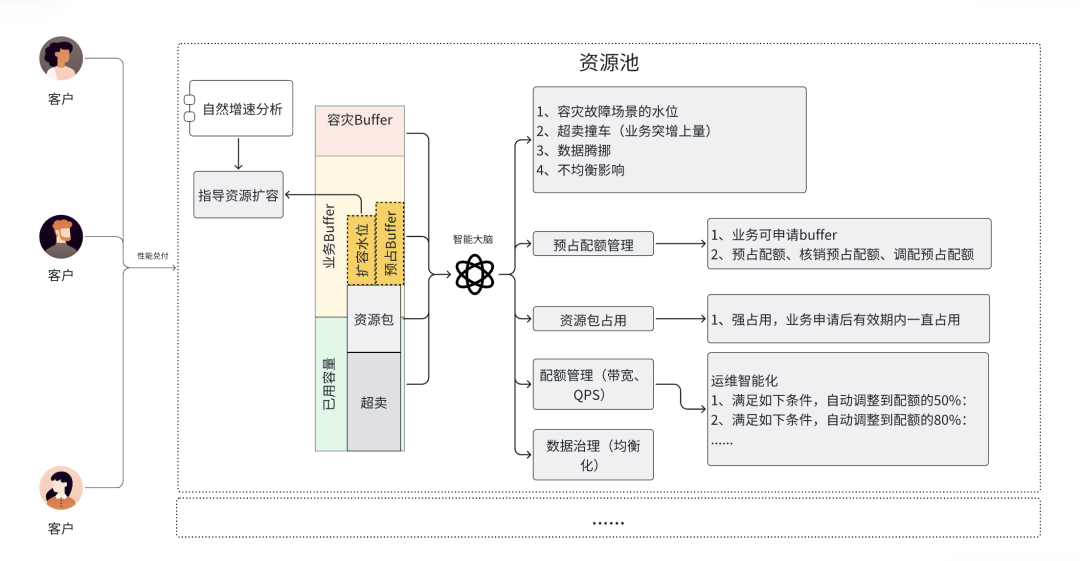
当具备分布式流控以及多维度的实际统计,并配合自动化拟合能力时,为每个单元赋予了规格。这些举措推动构建了智能化性能仓储管理。
结合用户的实际运行状况,能够得出运行水位。通过智能化分析与精细化运营,对水位和实际售卖的性能配额展开分析,进而得出系统稳定性指数,以此指导运营工作。这也为对外提供性能售卖提供了基本依据。
QoSPolicy
QoSPolicy 是 TOS 率先推出的高级流控能力。在 QoS 协议中,将流控配置抽象为:针对特定主体(Principal)的特定资源(Resource)在特定条件下(Condition)实施特定控制(Quota)。这一思路与权限 Policy 高度契合,使每个用户都能凭借丰富的 Policy 语法成为流控配置专家。
其核心技术实现在于协议解析,将所有 Policy 的解析抽象为统一模块,结合流控控制面的管理,为用户提供自主操作流控的能力。
结语
火山引擎对象存储 TOS 突发带宽与流控策略,针对 AI 的 “高并发数据传输” 和智驾系统的 “多模块资源竞争”,提供了 “按需伸缩” 与 “精准管控” 的一体化解决方案 —— 既让数据“喂饱”AI 算力 ,加速模型迭代;又让智驾核心功能 “独占” 关键带宽,保障行驶安全。
以某头部 AI 大模型公司为例,在训练千亿参数对话模型时,借助 TOS 流控策略及突发带宽功能,达成训练角色访问的数据带宽独占,不存在被其他业务流程抢占的风险,保障业务训练的安全运行;同时,带宽能够从日常的 100Gbps 依据业务负载自动提升至 600Gbps,15TB 训练样本(包含文本、图像、语音混合数据)的传输时长从原本的 20 分钟缩减至 3 分钟,帮助企业训练业务节省约千万成本。
现在,登录火山引擎控制台,即可一键开启 TOS 突发带宽与流控策略配置,让对象存储真正成为 AI 与智能汽车业务的 “硬核底座”,助力企业在智能时代抢占先机!