PostgreSQL表分区简单介绍和操作方法
一、什么是表分区?它和分库分表有什么区别?
1.1 什么是表分区(Table Partitioning)?
表分区是数据库的一种物理设计技术,它将一个大表从逻辑上视为一个整体,但从物理上拆分成多个子表(分区),每个分区存储一部分数据。
- 逻辑上:你仍然像操作一张表一样查询它
- 物理上:数据分散在多个子表中,按规则存储
- ✅ 举个例子:
把jgpt_jzd_test按年份拆成p2023、p2024、p2025三个分区,查询时仍用SELECT * FROM jgpt_jzd_test,但数据库只扫描相关分区。
1.2 表分区 vs 分库分表:关键区别
| 对比项 | 表分区 | 分库分表 |
|---|---|---|
| 实现层级 | 数据库内部(单库) | 应用层或中间件(跨库) |
| 透明性 | 高(应用无感知) | 低(需改代码) |
| 管理复杂度 | 低(自动路由) | 高(需路由规则) |
| 事务支持 | 完整支持 | 跨库事务复杂 |
| 适用场景 | 单表过大(百万~亿级) | 数据量极大(TB级+) |
| 技术栈 | PostgreSQL、MySQL 8.0+ | ShardingSphere、MyCat |
✅ 简单说:
- 表分区是“数据库帮你拆”
- 分库分表是“你自己写代码拆”
二、表分区的优缺点与使用场景
✅ 优点
| 优势 | 说明 |
|---|---|
| 查询性能提升 | 分区剪枝(Partition Pruning)自动跳过无关分区 |
| 数据管理高效 | 删除旧数据从 DELETE 变为 DROP PARTITION(秒级) |
| 维护更方便 | 可对单个分区做 VACUUM、ANALYZE、备份 |
| I/O 分散 | 不同分区可分布到不同磁盘(高级用法) |
❌ 缺点
| 缺点 | 说明 |
|---|---|
| 全表扫描变慢 | 需扫描所有分区,元数据开销增加 |
| 分区键固定 | 一旦选定(如 gmt_create),不能更改 |
| 管理复杂度上升 | 需定期创建新分区 |
| 不支持主键跨分区 | 主键必须包含分区键 |
三、PostgreSQL 表分区的三种方式
PostgreSQL 支持三种分区策略:
1. Range 分区(按范围)
- 适用:时间、数值范围
- 示例:按
gmt_create按年/月分区 - 语法:
PARTITION BY RANGE (gmt_create)
2. List 分区(按枚举值)
- 适用:固定分类,如省份、状态
- 示例:按
province分区 - 语法:
PARTITION BY LIST (province)
3. Hash 分区(按哈希值)
- 适用:数据均匀分布,无明显查询模式
- 示例:按
id哈希分 4 份 - 语法:
PARTITION BY HASH (id)
四、实战:jgpt_jzd_test 表分区操作全流程
将 3000 万+ 的 jgpt_jzd_test 表改造为按年分区的分区表。
步骤 1:创建分区主表
-- 创建主表(逻辑表,不存数据)
CREATE TABLE jgpt_jzd_test_partitioned (id varchar(32),jzdbh varchar(255),xzb varchar(255),yzb varchar(255),htxxid varchar(255),gmt_create timestamp(6) NOT NULL, -- 必须 NOT NULLgmt_modified timestamp(6),del_flag varchar,created_user_id varchar(255),created_user varchar(255),last_modified_user_id varchar(255),last_modified_user varchar(255),dkh varchar(255),dkms varchar(255),batchnum varchar(255)
) PARTITION BY RANGE (gmt_create);步骤 2:创建子分区(按年)
-- 2023 年分区
CREATE TABLE jgpt_jzd_test_p2023 PARTITION OF jgpt_jzd_test_partitionedFOR VALUES FROM ('2023-01-01') TO ('2024-01-01');-- 2024 年分区
CREATE TABLE jgpt_jzd_test_p2024 PARTITION OF jgpt_jzd_test_partitionedFOR VALUES FROM ('2024-01-01') TO ('2025-01-01');-- 2025 年分区
CREATE TABLE jgpt_jzd_test_p2025 PARTITION OF jgpt_jzd_test_partitionedFOR VALUES FROM ('2025-01-01') TO ('2026-01-01');步骤 3:迁移数据
-- 从旧表插入到新分区表(自动路由)
INSERT INTO jgpt_jzd_test_partitioned
SELECT * FROM jgpt_jzd_test;步骤 4:创建索引
-- 在主表创建索引,所有分区自动继承
CREATE INDEX idx_jgpt_jzd_test_htxxid ON jgpt_jzd_test_partitioned (htxxid);
步骤 5:切换表名(原子操作)
-- 1. 备份原表
ALTER TABLE jgpt_jzd_test RENAME TO jgpt_jzd_test_backup;-- 2. 新表启用原名
ALTER TABLE jgpt_jzd_test_partitioned RENAME TO jgpt_jzd_test;✅ 至此,jgpt_jzd_test 已是分区表!
五、验证表分区是否成功
1. 查看分区结构
-- 查询系统表
SELECT inhrelid::regclass AS child_table,inhparent::regclass AS parent_table
FROM pg_inherits
WHERE inhparent = 'jgpt_jzd_test'::regclass;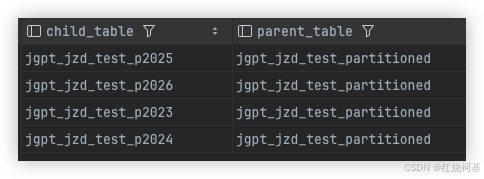
2. 验证分区剪枝是否生效
explain SELECT COUNT(*) FROM jgpt_jzd_test WHERE gmt_create >= '2025-01-01' AND gmt_create < '2026-01-01';

可以看到只查询了jgpt_jzd_test_p2025一张分区表
六、安全删除分区:DETACH vs DROP(关键区别)
在表分区的日常维护中,删除历史数据是一个高频操作。PostgreSQL 提供了两种方式来“移除”分区,但它们的安全性、可逆性和使用场景完全不同。
我们以 jgpt_jzd_test_p2024 分区为例,对比两种操作:
1. DETACH PARTITION —— 安全的“解绑”操作
ALTER TABLE jgpt_jzd_test_partitionedDETACH PARTITION jgpt_jzd_test_p2024;✅ 操作特点:
- 数据不会丢失!
jgpt_jzd_test_p2024表变成一个独立的普通表- 主表
jgpt_jzd_test_partitioned不再包含该分区的数据- 可随时对
jgpt_jzd_test_p2024进行查询、导出、备份或重新挂载
🎯 适用场景:
- 需要归档数据
- 删除前做审计或备份
- 不确定是否永久删除
-- 确认无误后,再删除
DROP TABLE jgpt_jzd_test_p2024;✅ 推荐做法:先 DETACH,再 DROP,避免误删。
2. DROP PARTITION —— 永久删除
ALTER TABLE jgpt_jzd_test_partitionedDROP PARTITION jgpt_jzd_test_p2024;❌ 操作特点:
- 数据立即永久丢失!无法通过
DROP回滚- 相当于执行了
DROP TABLE,文件被物理删除- 无法恢复(除非有数据库备份)
⚠️ 适用场景:
- 确认数据不再需要
- 紧急释放磁盘空间
- 自动化脚本中已确认安全
对比总结
| 操作 | 数据是否保留 | 是否可逆 | 安全性 | 推荐使用场景 |
|---|---|---|---|---|
DETACH PARTITION | ✅ 保留 | ✅ 可逆 | 高 | 所有删除操作的首选 |
DROP PARTITION | ❌ 丢失 | ❌ 不可逆 | 低 | 确认永久删除 |
七、自己的理解
1.表分区之后,你在datagrip或navicat里面看到的还是一张表,数据也都在这张表里,但实际上这张表是主表,没有存储数据。
2.数据实际存储在分区表里,例如jgpt_jzd_test_p2024,因此代码里面是可以直接调用这张表的
3.平时基本不用管分区表,正常使用主表就行了,比如你插入数据,直接往jgpt_jzd_test插入,数据库会根据你的gmt字段自动插入到相应的分区表里面,平时使用基本是无感的
✅ 总结:我的认知升级
| 旧认知 | 新认知 |
|---|---|
| 分区就是“拆表” | 分区是“逻辑统一,物理分离” |
| 数据存在主表 | 主表是“空壳”,数据在分区 |
| 只能查主表 | 可直查分区,性能更优 |
| 分区很复杂 | 日常使用完全无感 |