【Redis】分布式集群
深入剖析Redis:从分布式锁到高性能架构
Redis 作为一个高性能的键值数据库,在现代分布式系统中扮演着至关重要的角色,常用于缓存、会话存储、消息队列和分布式锁等场景。要真正驾驭 Redis,必须深入理解其核心工作机制。本文将从分布式锁、主从复制、哨兵模式、集群脑裂、分片集群、数据读写规则以及其高性能秘诀等多个方面进行详细解析。
一、Redis 分布式锁 (Distributed Lock)
分布式锁是控制分布式系统之间同步访问共享资源的一种机制。
1. 核心要求: 一个合格的分布式锁需要满足:
- 互斥性:在任意时刻,只有一个客户端能持有锁。
- 防死锁:即使持有锁的客户端崩溃或发生网络分区,锁也能被自动释放,避免资源被永久锁定。
- 容错性:只要大部分 Redis 节点正常运行,客户端就能获取和释放锁。
- 身份安全:加锁和解锁的必须是同一个客户端,不能解他人之锁。
2. 实现方式:
- SETNX + EXPIRE (基础版):
SETNX lock_key unique_value # 如果key不存在则设置成功(获取锁)EXPIRE lock_key 30 # 给锁设置一个过期时间**缺陷**:`SETNX` 和 `EXPIRE` 是两个命令,非原子操作。如果在执行完 `SETNX` 后客户端崩溃,将导致锁无法过期,其他客户端永远无法获取锁。
- SET 命令扩展参数 (推荐版): Redis 2.6.12 后,
SET命令增加了 NX(Not eXists)和 EX/PX(过期时间)选项,完美解决了原子性问题。
SET lock_key unique_value NX PX 30000 # 原子性地尝试获取一个30秒后过期的锁**释放锁**:通过 Lua 脚本保证原子性,先校验 `unique_value`(如 UUID),再删除 key。
if redis.call("get", KEYS[1]) == ARGV[1] thenreturn redis.call("del", KEYS[1])elsereturn 0end使用 Lua 脚本可以避免误删其他客户端的锁。
- RedLock 算法 (分布式环境版): 在 Redis 主从架构中,主节点获取锁后若在数据同步到从节点前发生故障,从节点升级为主节点可能导致锁丢失,出现多个客户端同时持有锁的情况。 RedLock 算法试图解决此问题,其核心思想是向多个独立的 Redis 实例(通常是奇数个,如 5)依次尝试获取锁。当且仅当客户端从超过半数(N/2+1) 的实例上获取到锁,并且总耗时小于锁的过期时间,才认为获取锁成功。
3. 如何控制锁时长
- 根据业务逻辑处理
- watchDog续期
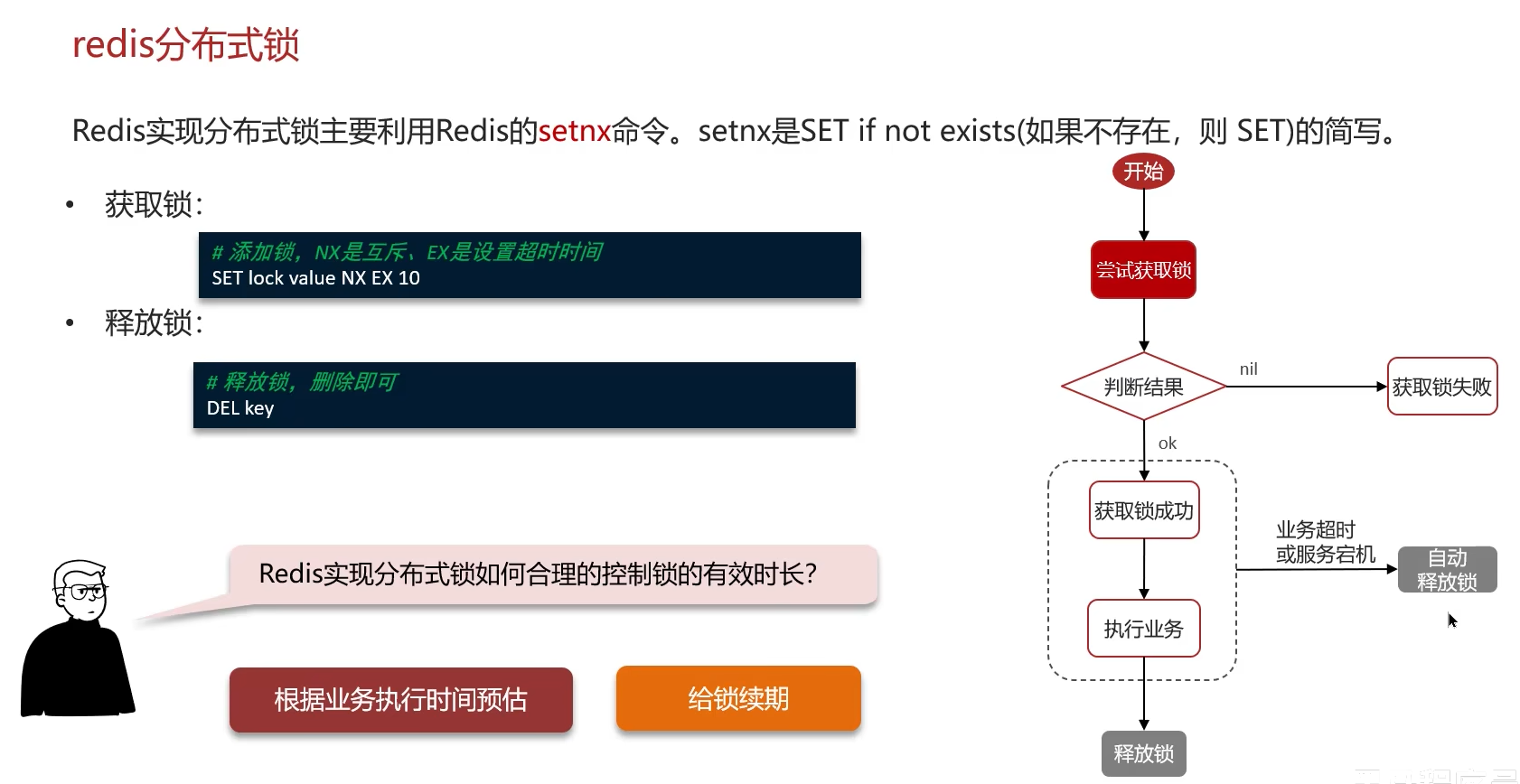
可重入性:同一线程可重入

结论:对于要求不高的场景,单节点 Redis 锁(SET NX PX + Lua)足矣。对一致性要求极高的金融场景,可考虑 RedLock,但其实现复杂、性能较低,需谨慎评估。对于一致性要求高的建议采用zookeeper实现分布式锁。

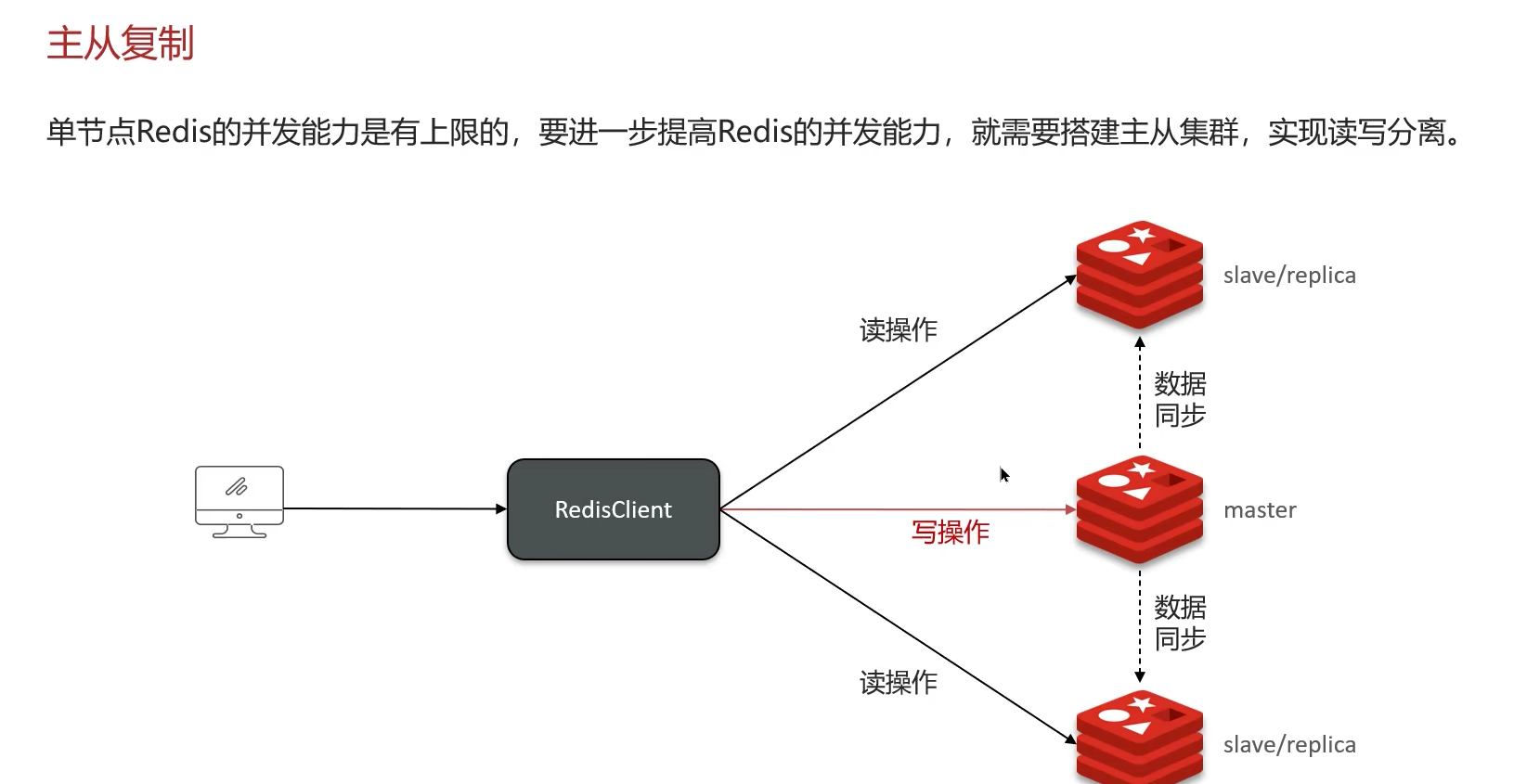
二、主从同步流程 (Replication)
Redis 提供主从复制功能,数据可以从一个主节点复制到多个从节点,实现数据冗余、读写分离和故障恢复。主节点负责写操作,从节点负责读操作。
同步流程主要分为全量同步和增量同步:
全量同步 (Full Resynchronization):
- 建立连接:从节点启动或重连后,向主节点发送
PSYNC命令。 - 生成 RDB:主节点接收到全量同步请求后,执行
BGSAVE在后台生成一个 RDB 快照文件。 - 发送 RDB:主节点将 RDB 文件发送给从节点。从节点会清空自身旧数据,然后加载接收到的 RDB 文件来恢复数据。
- 发送缓冲写命令:在生成和发送 RDB 期间,主节点新的写命令会存入一个名为 复制缓冲区 (Replication Buffer) 的内存区域。
- 同步缓冲命令:RDB 传输完成后,主节点会将复制缓冲区中的写命令发送给从节点执行,从而保证数据最终一致性。
- 建立连接:从节点启动或重连后,向主节点发送

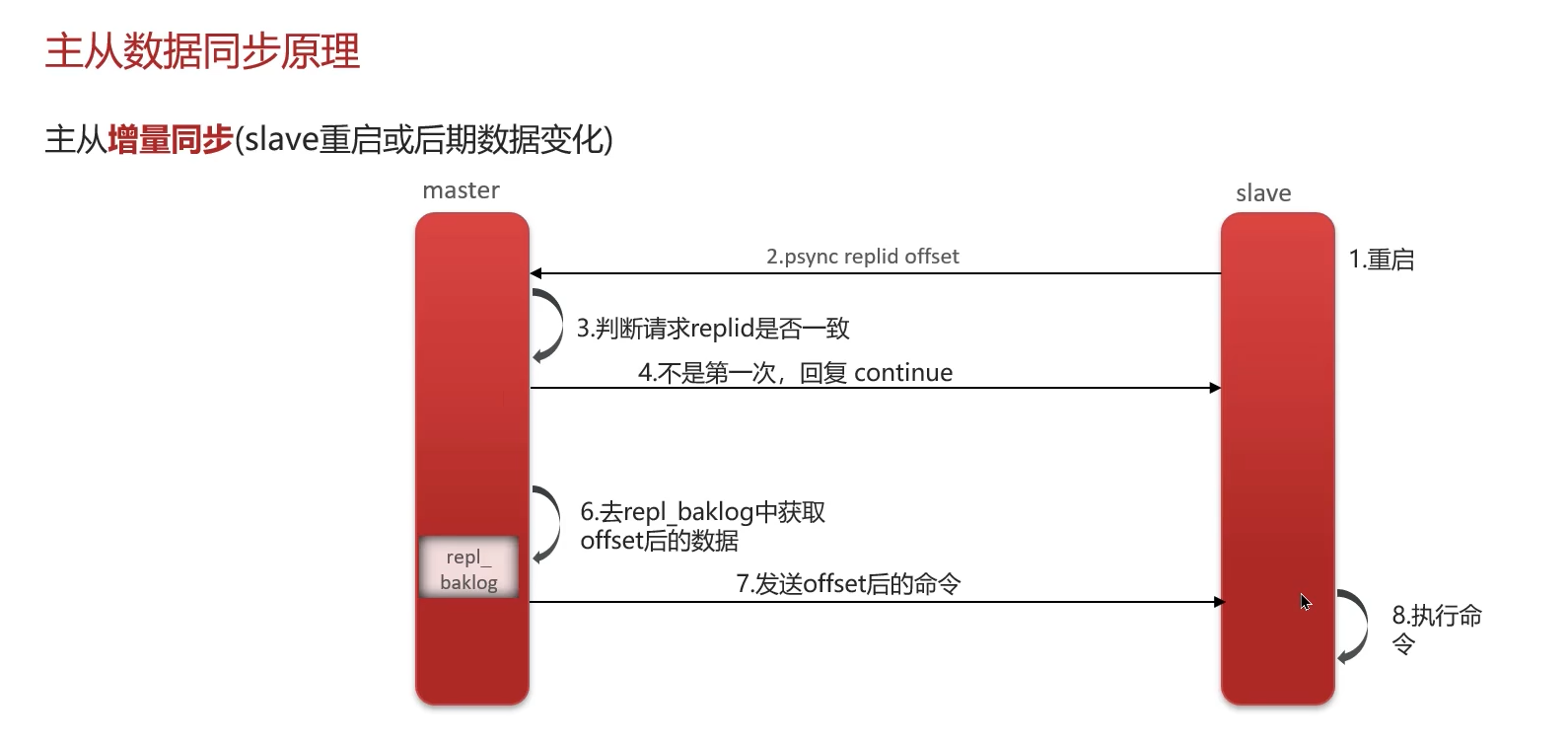
2 增量同步 (Partial Resynchronization): 如果从节点短暂断开连接后重连,它会尝试进行增量同步。
- 复制偏移量:主从节点各自维护一个复制偏移量(offset),主节点每次向从节点传播 N 个字节的数据,offset 就增加 N。
- 复制积压缓冲区 (Replication Backlog):主节点内部维护一个固定大小的环形队列(复制积压缓冲区)。它会记录最近一段时间的主节点写命令。
- PSYNC:从节点重连后,将自己的 offset 发给主节点。如果主节点发现这个 offset 之后的数据还在 Backlog 中,就会将 offset 之后的命令发送给从节点,完成同步。如果找不到,则触发全量同步。
总结主从模式

三、哨兵模式 (Sentinel)
主从模式不具备自动故障转移能力。哨兵模式是 Redis 的高可用性 (High Availability) 解决方案。
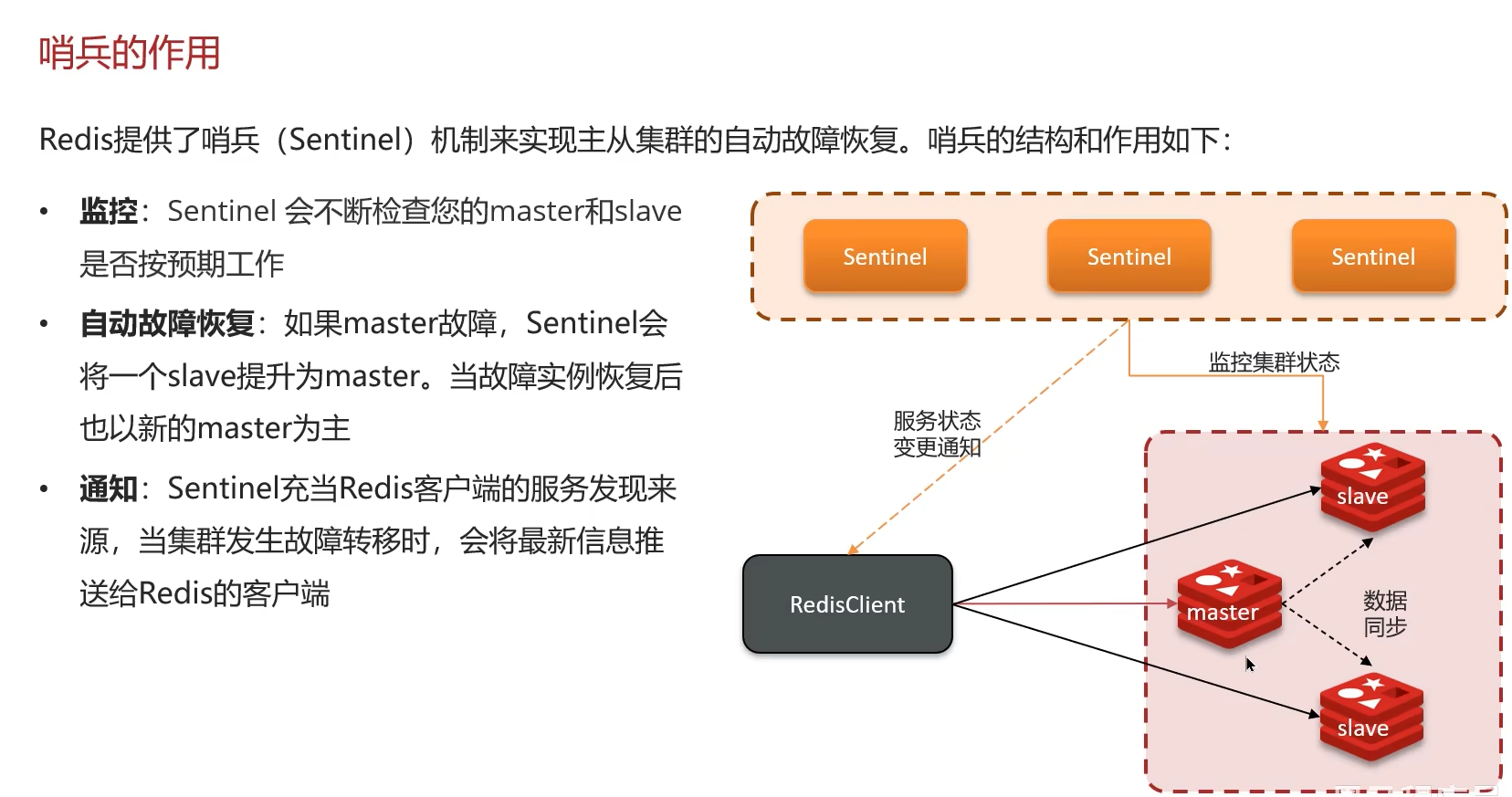
1. 核心功能:
- 监控 (Monitoring):哨兵节点会定期检查主节点和从节点是否正常运行。
- 自动故障转移 (Automatic Failover):当主节点被判定为故障时,哨兵会自动将一个从节点晋升为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供 (Configuration Provider):客户端应用不再直接连接 Redis 节点,而是连接哨兵集群,由哨兵告知当前的主节点地址。

2. 工作流程:
- 主观下线 (SDOWN):一个哨兵实例自己 Ping 不通主节点,就会将其标记为“主观下线”。
- 客观下线 (ODOWN):当足够数量(由配置决定) 的哨兵实例都认为主节点不可达时,主节点被标记为“客观下线”,随后触发故障转移流程。
- 选举领导者哨兵:所有哨兵节点会通过 Raft 算法选举出一个领导者哨兵,由它来负责具体的故障转移操作。
- 故障转移:领导者哨兵在从节点中挑选一个(根据优先级、复制偏移量等规则)作为新的主节点,然后通知其他从节点和客户端。
四、集群脑裂 (Split-Brain)
脑裂是指在网络分区发生时,集群中被分隔的节点各自认为自己是主节点并同时对外提供服务,导致数据不一致。
1. Redis 中的脑裂场景: 假设一个主从架构,主节点(A)和它的从节点(B、C)以及哨兵集群之间网络断开。哨兵集群认为 A 失联,遂选举 B 为新的主节点。此时,客户端 Client-1 仍能连接到旧主 A(可能通过不同的网络路由),而 Client-2 连接到了新主 B。 结果:Client-1 向 A 写入数据,Client-2 向 B 写入数据。当网络恢复后,A 作为 B 的从节点进行同步,会用自己的数据覆盖 B 的数据(或触发全量同步),导致 Client-2 的写入数据丢失。
2. Redis 的应对策略:
- min-slaves-to-write:主节点必须至少有 N 个从节点连接正常,才能接受写请求。
min-slaves-to-write 1在上述脑裂场景中,A 节点与所有从节点断开,`min-slaves-to-write 1` 条件不满足,A 会拒绝 Client-1 的写请求,将其变为**只读状态**,从而避免了数据不一致。
- min-slaves-max-lag:配合上述参数,定义“连接正常”的标准(从节点最后一次有效复制延迟不能超过多少秒)。
通过合理配置这两个参数,可以最大限度地降低脑裂带来的数据丢失风险。

五、分片集群 (Cluster)
当数据量巨大或写并发极高时,单机或主从模式无法满足需求。Redis Cluster 是官方提供的分布式(Sharding) 解决方案。这样就代替的哨兵的功能,就不用再搭建哨兵集群了。
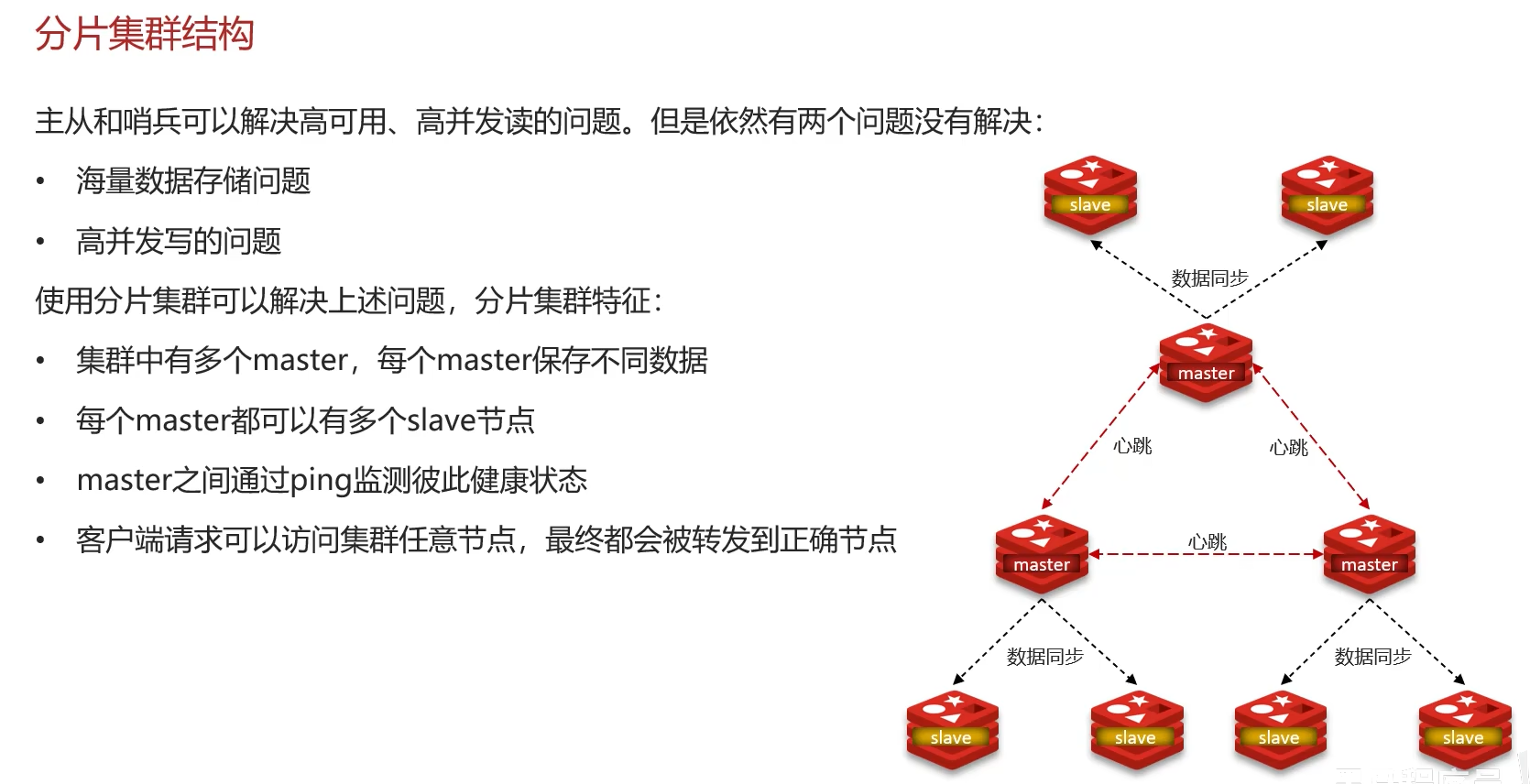
1. 核心特性:
- 数据分片:数据被自动分割到 16384 个槽(slot)中,每个节点负责一部分槽位。
- 去中心化:节点之间通过 Gossip 协议通信,无需额外的代理或配置服务器。
- 高可用:每个分片实际上是一个主从单元,主节点故障时,从节点会自动提升为主节点。
2. 键的寻址规则:
- 通过对 key 进行 CRC16 运算,再对 16384 取模,得到对应的槽位号:
slot = CRC16(key) % 16384。 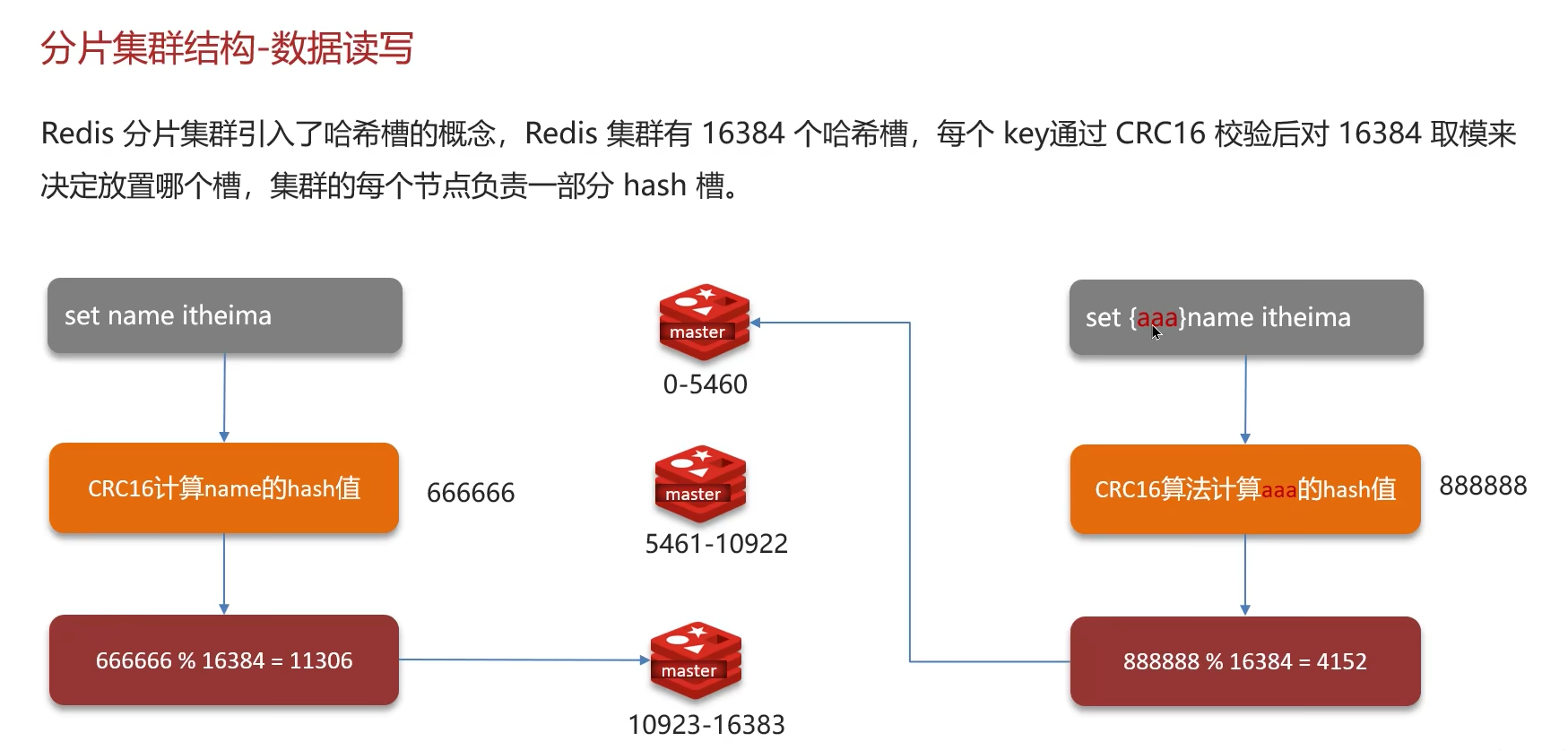

- 客户端可以缓存槽位映射表,直接路由到正确的节点。如果请求到了错误的节点,该节点会返回 MOVED 错误并告知正确地址,客户端会更新本地缓存。
六、数据读写规则
主从模式 (读写分离):
- 写操作:只能发送到主节点。主节点将写操作同步给从节点。
- 读操作:可以发送到主节点或任何从节点。通过读写分离可以大幅提升系统的读吞吐量。
集群模式:
- 读写操作都必须发送到负责对应 key 所在槽位的节点上。
- 如果请求了一个错误的节点,该节点会返回
-MOVED重定向错误,指引客户端连接正确的节点。
七、Redis 为什么这么快?
Redis 的极致性能源于其精巧的架构设计,主要体现在以下几个方面:
基于内存的数据存储:数据完全存放在内存中,避免了磁盘 I/O 这一传统数据库的最大瓶颈。内存的访问速度是纳秒级别。
高效的数据结构:Redis 不仅是简单的 Key-Value 存储,它为不同场景优化了数据结构(SDS、Hash、ZipList、QuickList、SkipList等),在时间和空间上做到了极致的平衡。
单线程事件循环模型 (I/O Multiplexing):
- 核心工作线程是单线程处理所有网络 I/O 和命令请求。这避免了多线程上下文切换和竞争带来的性能消耗和复杂性。
- 使用 I/O 多路复用技术 非阻塞I/O(Linux 下默认为
epoll),单线程可以高效地监听大量的客户端连接,当连接可读或可写时再进行操作,极大地提升了网络的吞吐能力。 - 注意:Redis 6.0 引入了多线程 I/O,但命令的执行仍然是单线程的。多线程只用于处理网络数据的读写和解析,这进一步提升了超大流量下的性能,但其核心的串行命令处理机制保证了原子性。
优化的网络模型:基于 Reactor 模式的事件处理器,将连接、读写、应答等操作转化为事件,由事件分发器统一处理,非常高效。
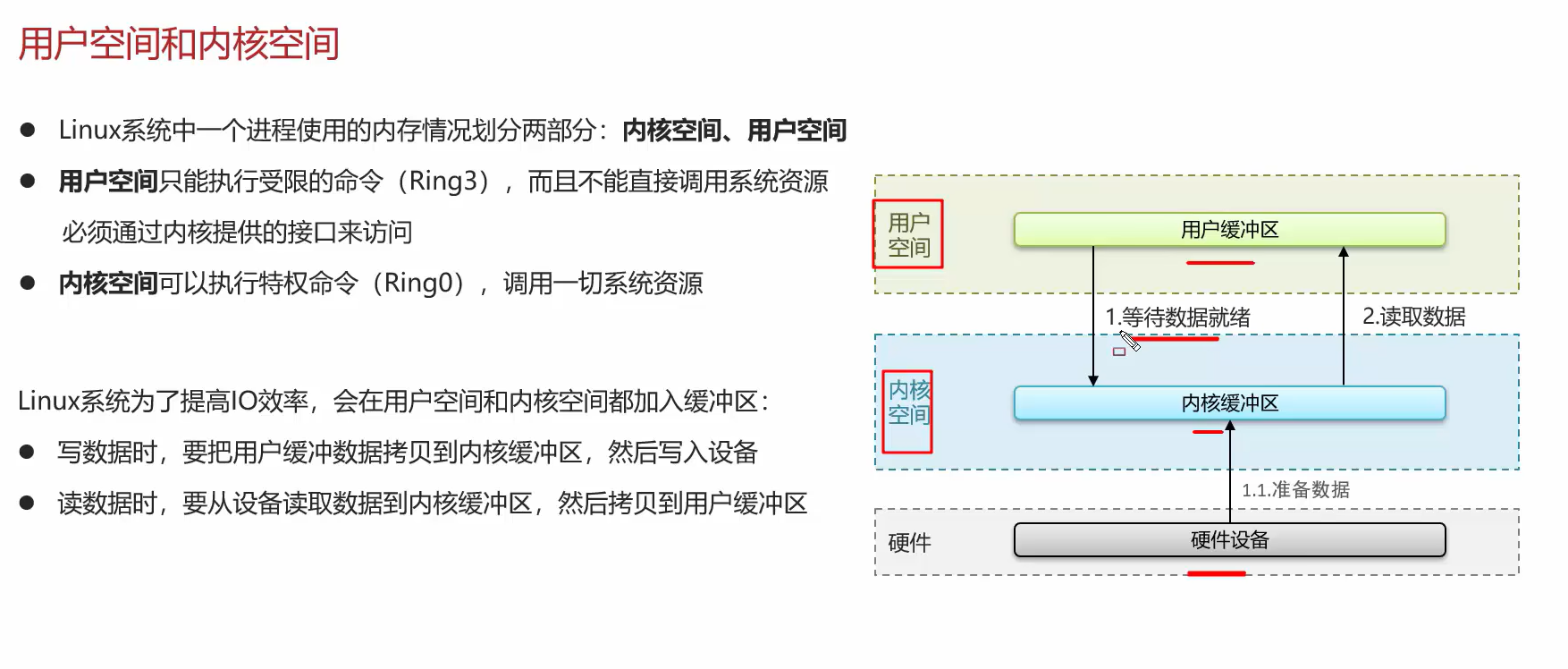
八、内存结构
要了解 I/O 多路复用技术需要先了解Linux进程使用的内存情况:
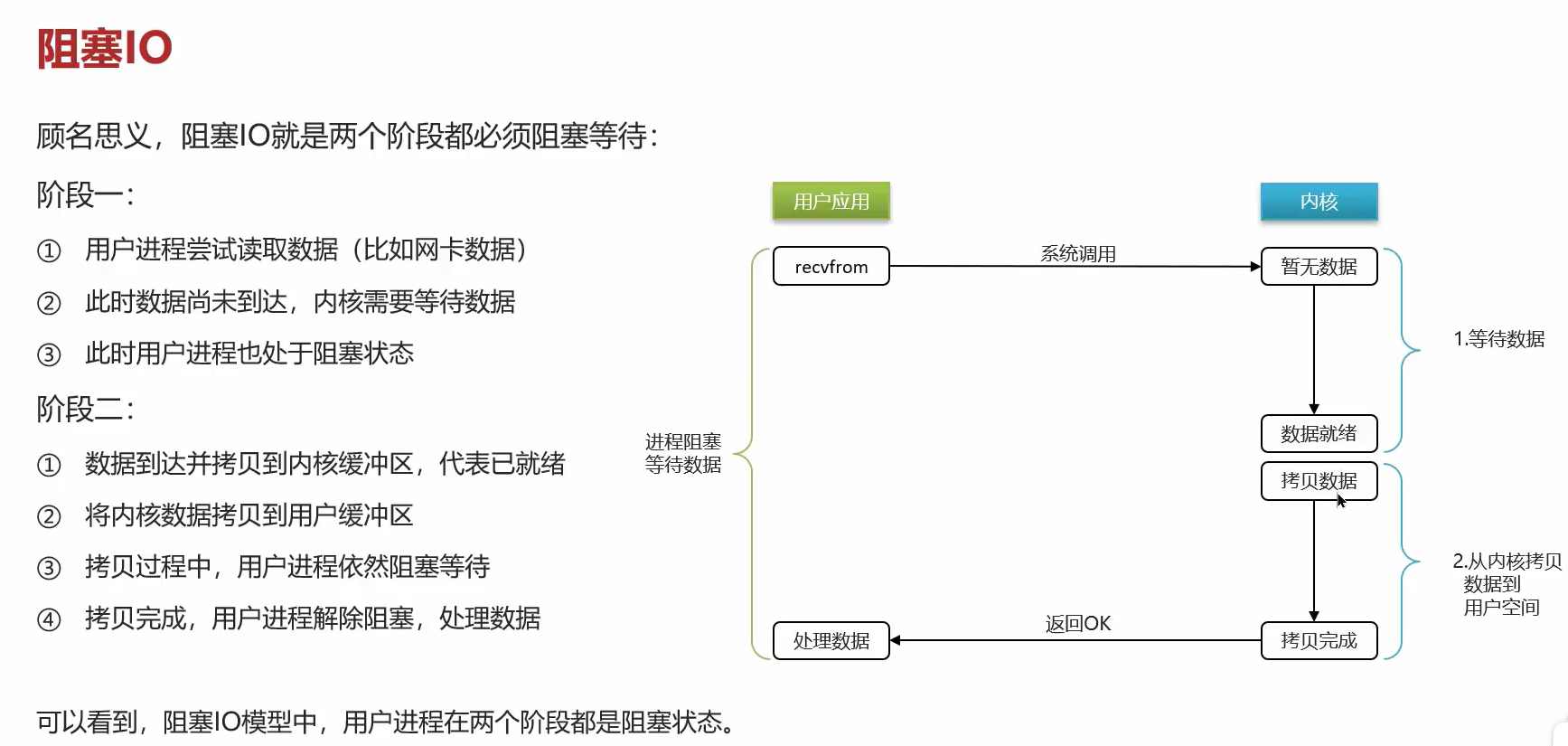
什么是阻塞型IO:
非阻塞IO介绍:
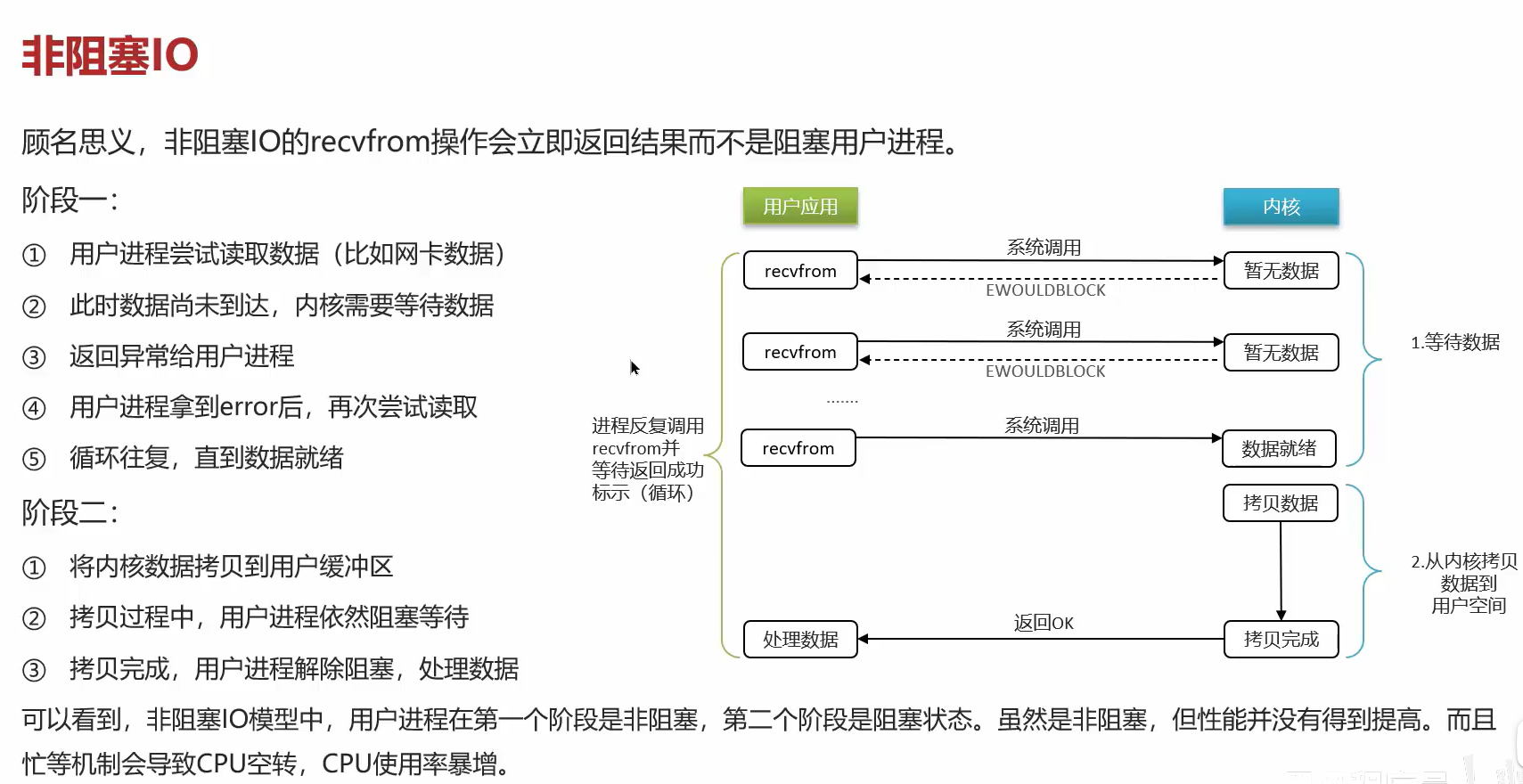
无论是阻塞型还是非阻塞型性能都不会有太大提高,二IO多路复用则可以解决这个问题:
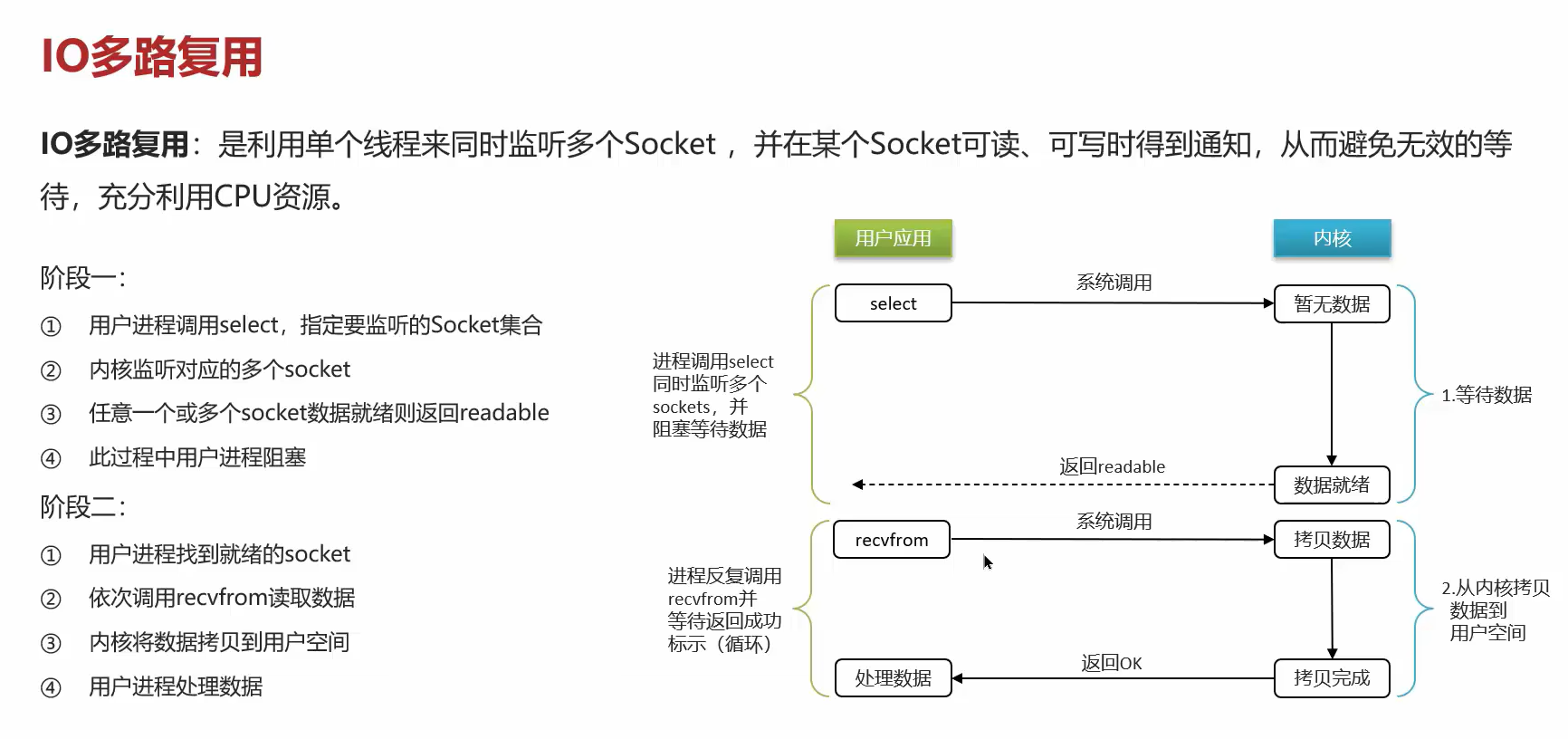
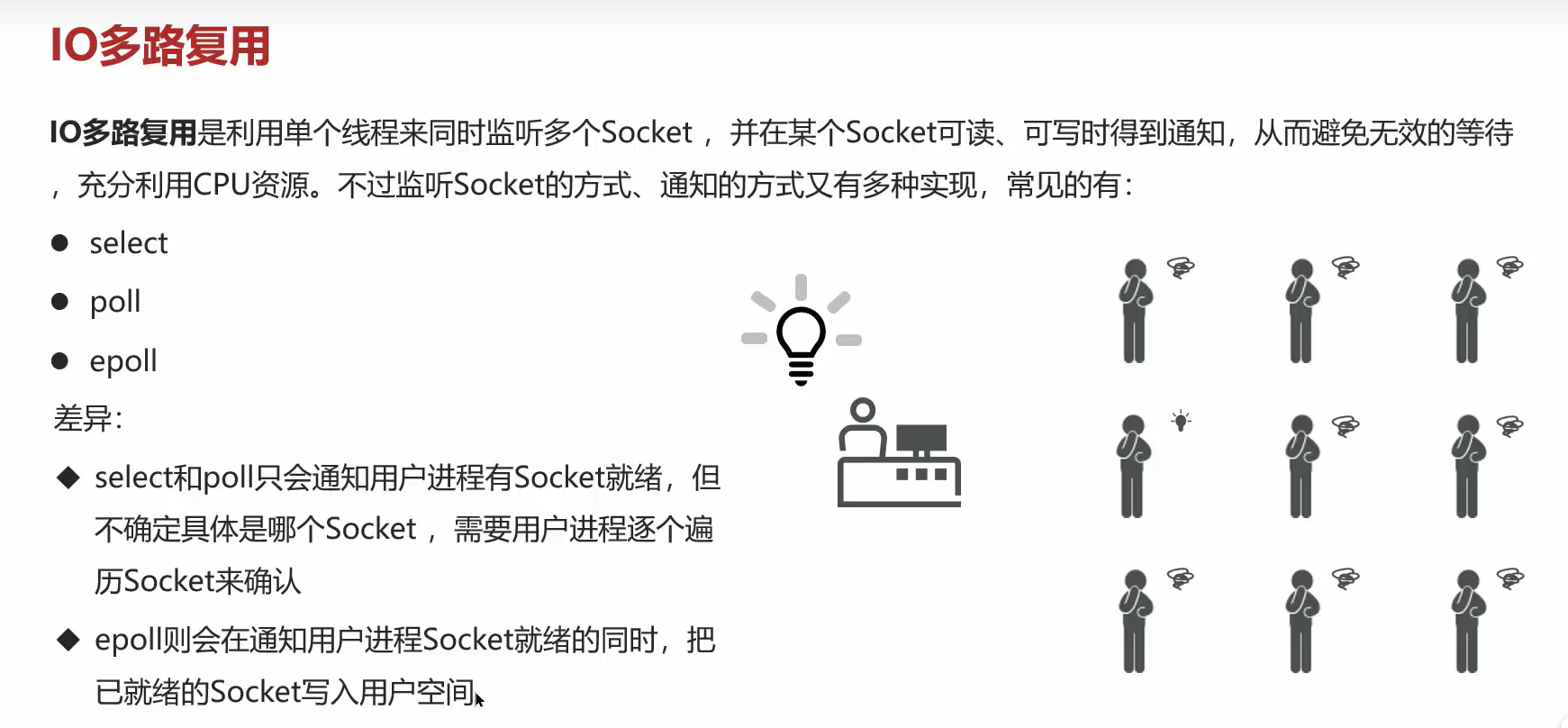
IO多路复用有三种类型,epoll是最好用的
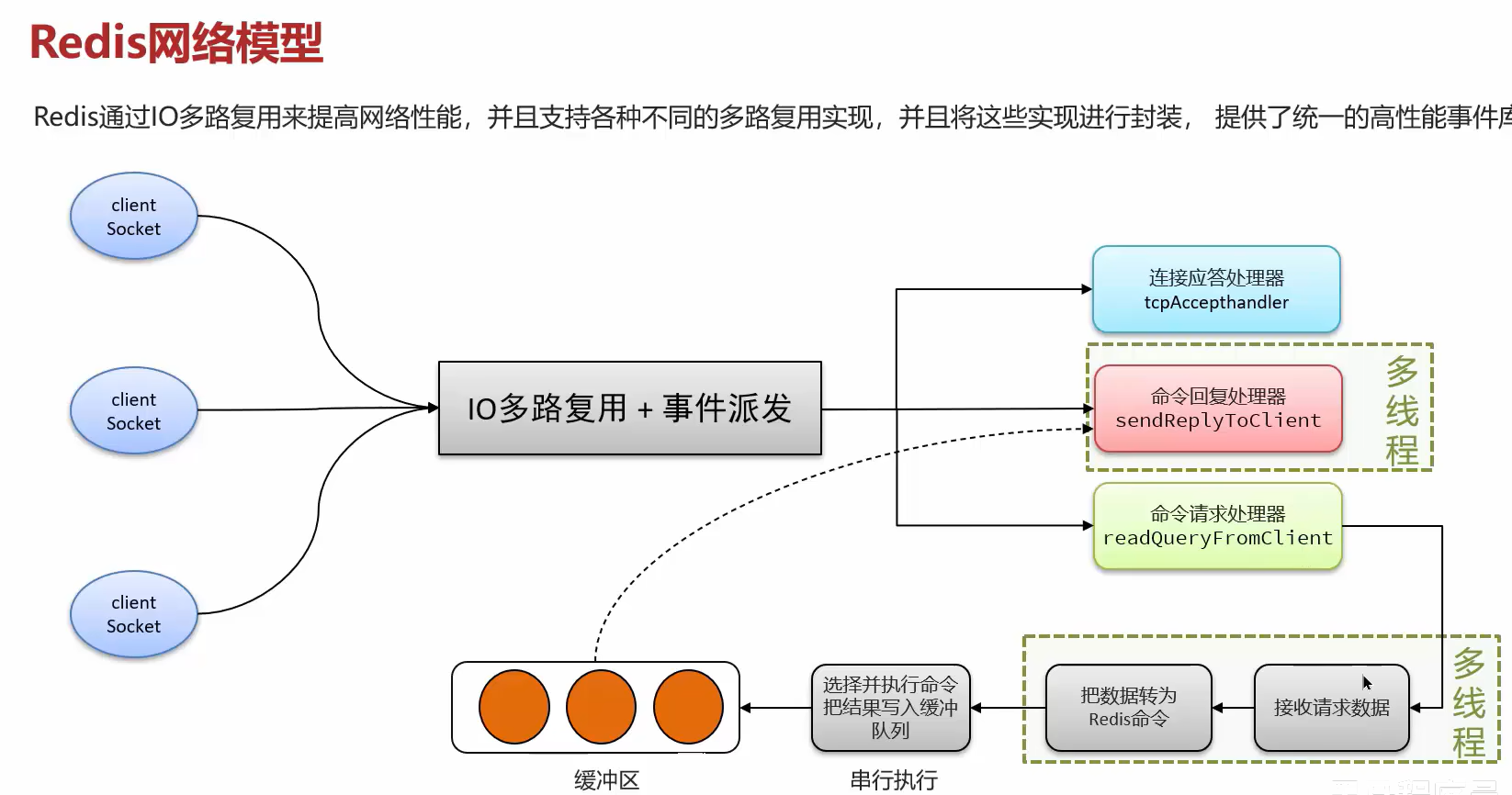
九、Redis网路模型
Redis的性能重点不在多路复用,也不在事件派发,影响效率的始终是IO。

总结
Redis 的强大远不止于其简单的 API。从保证数据一致的分布式锁,到保障服务高可用的主从复制与哨兵机制,再到应对海量数据与高并发的分片集群,Redis 提供了一整套成熟的分布式解决方案。而其令人惊叹的性能,则是内存存储、精巧数据结构与单线程事件模型完美结合的成果。深入理解这些底层机制,将有助于我们更好地在设计系统时发挥 Redis 的优势,并规避其潜在的风险。