Java之链表
1.什么是链表
所谓的链表指的就是物理存储结构上非连续的结构,但逻辑上是连续的结构。就好像一辆火车连接着不同的车厢。它是通过节点与节点相互连接
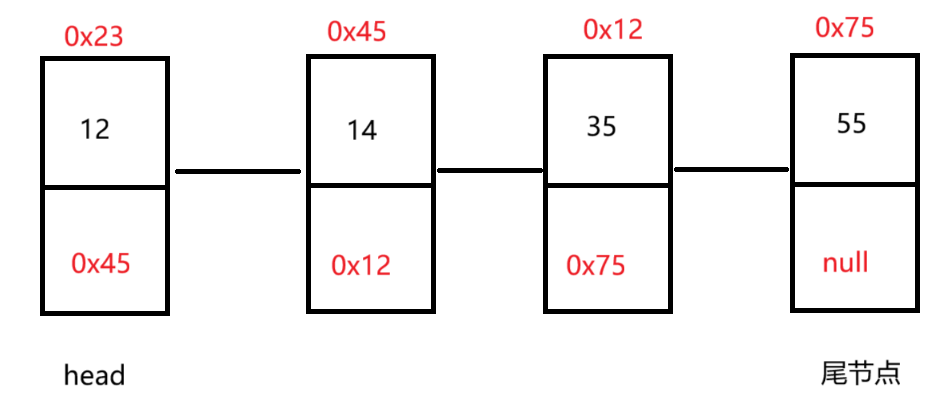
2.链表的创建
2.1定义节点
因为链表是由多个节点所构成的,又因为内部类是能对外隐藏,所以我们通过内部类的方式来进行构建节点。在这里面我们需要定义一个节点的引用和val变量来存放值。
public class MySingleList {static class ListNode{public int val;public ListNode next;public ListNode(int val){this.val = val;}}public ListNode head;
}
2.2 创建链表
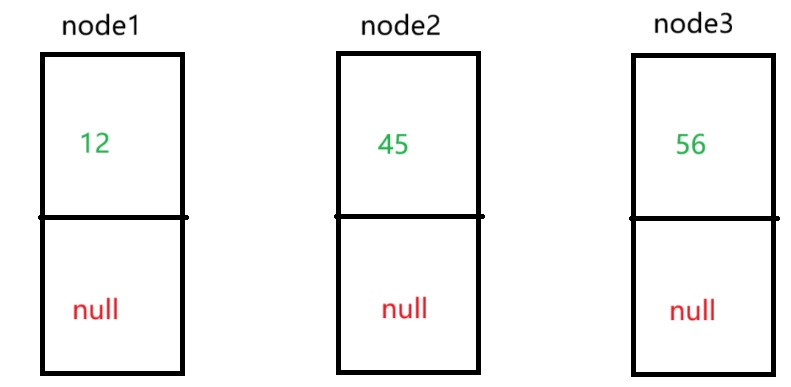
接下来我们通过实例ListNode对象来创建多个节点后,再进行连接(当然后续可能不会以这样的方式创建,此处只是为了更好的演示)
public class MySingleList {static class ListNode{public int val;public ListNode next;public ListNode(int val){this.val = val;}}public static void main(String[] args) {ListNode node1 = new ListNode(12);ListNode node2 = new ListNode(45);ListNode node3 = new ListNode(56);node1.next = node2;node2.next = node3;head = node1;}
}
接下来,肯定会有不少人产生疑问,这个node1.next = node2具体是什么意思啊?其实很简单,他就是起到连接的作用。在我们创建出节点,但还没有连接的时候如下图所示:
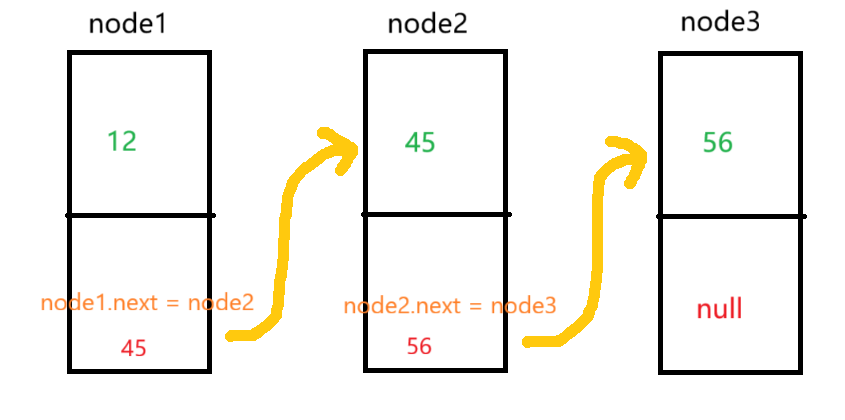
当我们代码执行到node1.next = node2时,相当于创建了一个为null的新成员变量,然后再让他等于node2的值。以此类推,直到node3停下(因为后面没有节点了),如图所示:
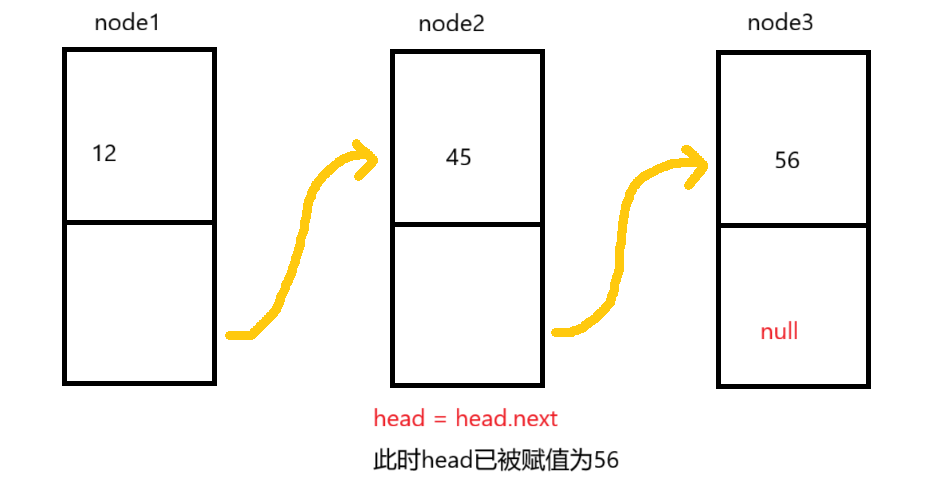
接着再让head变量等于node1,创建出头节点。此时我们便成功创建出一个链表
3.链表的实现
首先我们先搞一个接口,便于后面功能的修改,然后再让MyLinkedList实现
public interface ILinkedList {//头插法void addFirst(int data);//尾插法void addLast(int data);//任意位置插入,第一个数据节点为0号下标void addIndex(int index,int data);//查找是否包含关键字key是否在单链表当中boolean contains(int key);//删除第一次出现关键字为key的节点void remove(int key);//用于删除指定下标的节点void removePos(int key);//删除所有值为key的节点void removeAllKey(int key);//得到单链表的长度int size();void clear();void display();
}3.1display功能
要想遍历链表,我们就要利用head节点,让他一直循环往后即可。注意:这里的结束条件是head != null。其原因如图所示:
就是如果是head.next != null的话,那么当遍历完node2之后,按照代码head会进行往后赋值,到遍历node3时,需要进行判断。此时如果是用head.next进行判断的话,就等于是判断node3下一个节点是否不为空。这显然不符。因此,不能进入循环,少打印一个值
并且,如果这里直接用head进行打印的话,就会导致head为空,这个链表销毁。为了避免这种发生,我们一般会定义一个cur来代替head向前移动的步骤,这样既保留了链表,又能让链表进行打印
这是这个方法的代码:
@Overridepublic void display() {ListNode cur = this.head;while(cur != null){System.out.print(cur.val + " ");cur = cur.next;}}3.2size功能
这个功能是用于统计链表内部有多少个元素,不难想出,这个与上面display方法又异曲同工之妙,不过这里是要进行统计,而非打印
@Overridepublic int size() {int count = 0;ListNode cur = this.head;while(cur != null){count++;cur = cur.next;}return count;}3.3contains方法
这个方法是用来查照链表是否有某个元素,如果有的话,就返回true,没有就返回false。原理同上,只不过是在遍历的过程中进行比较
@Overridepublic boolean contains(int key) {ListNode cur = this.head;while(cur != null){if(cur.val == key){return true;}cur = cur.next;}return false;}3.4addFirst方法
这个是头插法,它是用于在链表的头节点前插入一个新的数据,并且让它成为这个链表的新头节点
想要头插一个数据,我们就需要创建多一个节点,如图所示:
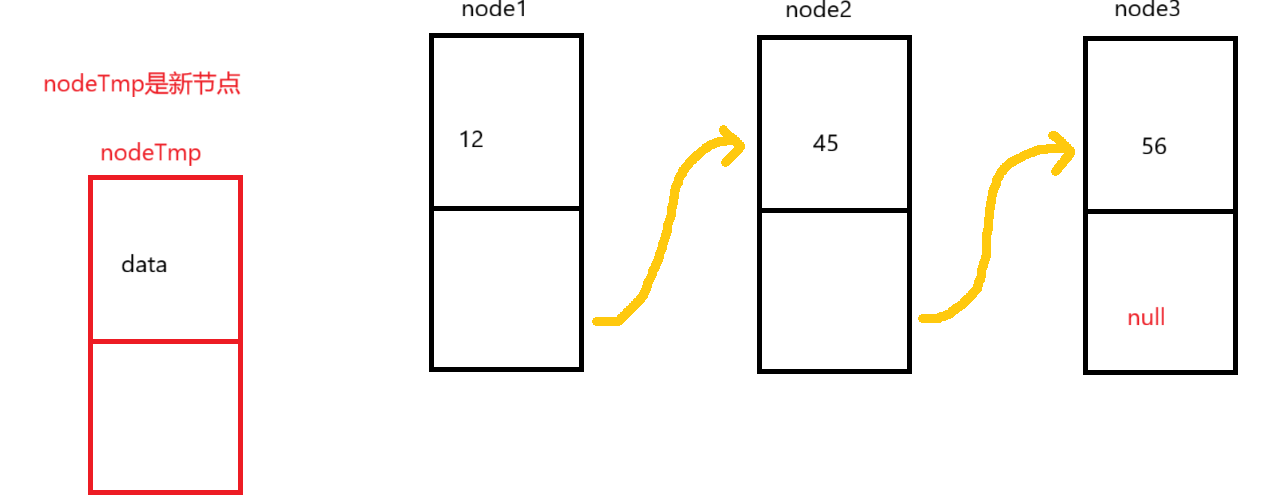
因为现在刚创建完的节点是没有连接的,所以nodeTmp.next是为空,所以我们要让它等于head节点,来构成联系
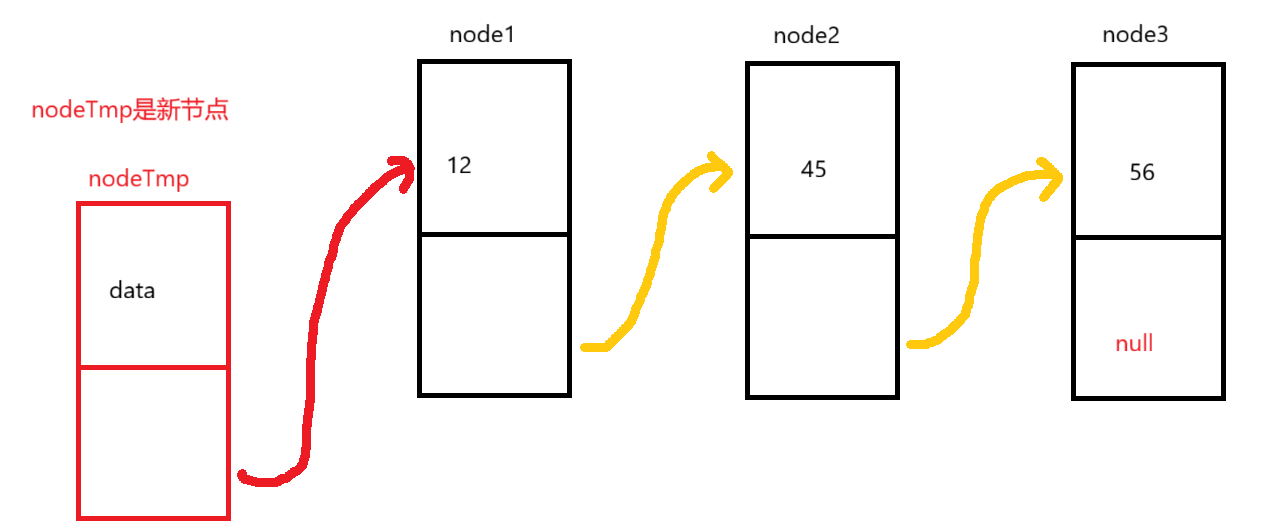
下面是实现代码:
@Overridepublic void addFirst(int data) {ListNode nodeTmp = new ListNode(data);nodeTmp.next = this.head;head = nodeTmp;}
3.5addLat方法
这个是尾插法,顾名思义,就是从后面插入一个新节点
那这里的原理和头插法相似,首先我们要创建一个新的节点
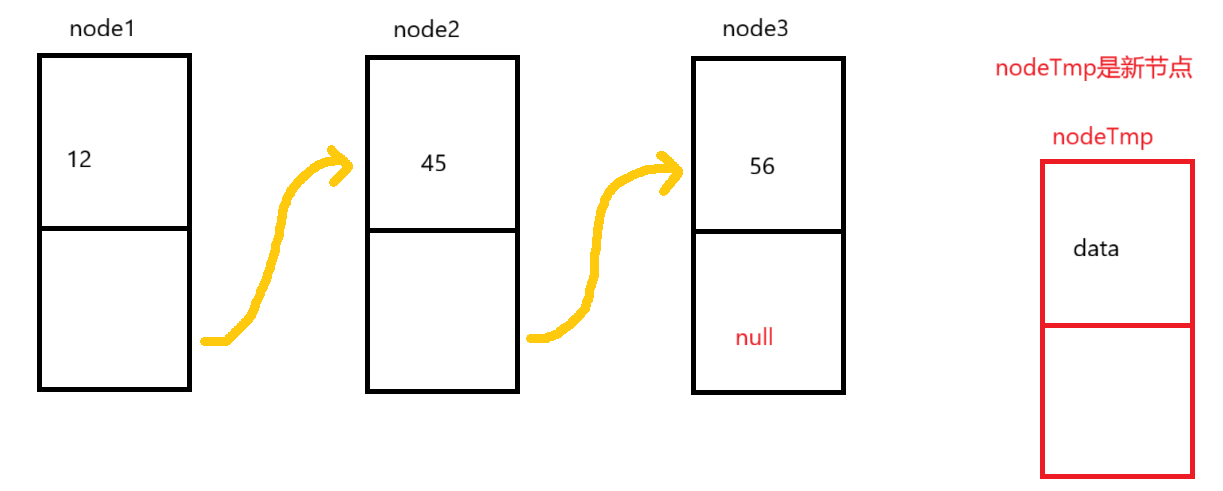 创建完之后,就要对它与node3进行连接。首先,我们可以通过遍历,让它到最后节点那,然后再进行连接。不过值得注意的是,这里遍历的条件是cur.next != null,原因如下:
创建完之后,就要对它与node3进行连接。首先,我们可以通过遍历,让它到最后节点那,然后再进行连接。不过值得注意的是,这里遍历的条件是cur.next != null,原因如下:
如果是cur != null的话,当cur遍历到node2时,此时cur不为空,符合条件,继续往后遍历。在node3时,再次进行判断,依旧可以往后走,但是这是cur已经为null了。所以在后续再想连接时,就会报错

但如果是cur.next != null的话,当在node2时,符合条件,往后遍历。来到node3时,cur.next为空。不满足,退出循环。这时的cur不为空,所以可以让它连接后面新节点。
这里的代码如下:
@Overridepublic void addLast(int data) {ListNode nodeTmp = new ListNode(data);ListNode cur = head;while(cur.next != null){cur = cur.next;}cur.next = nodeTmp;}3.6addIndex方法
这个是指定位置来进行插入新节点
想要指定位置插入,那需要我们创建一个新节点。待完成后,我们要指定相应下标进行连接,以下图为例:
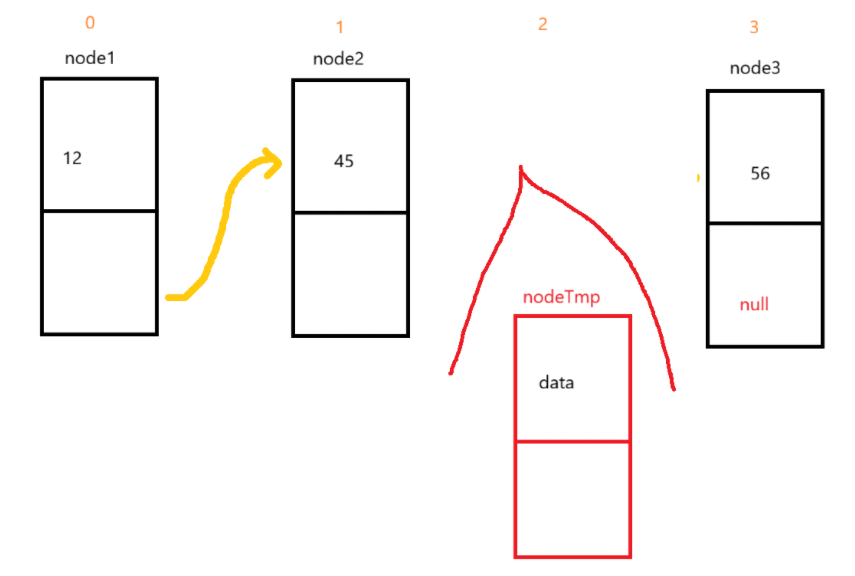
这里我们选择插入下标2,那就代表原本链表的下标2的节点要变成下标3。所以,我们首先创建多一个寻找下标的方法findIndex,让cur遍历到插入下标的前一位,这里也就是1。
private ListNode findIndex(int index){ListNode cur = head;int count = 0;while(count != index - 1){cur = cur.next;count++;}return cur;}已知原来cur.next = node3,为了连接,我们让nodeTmp.next = cur.next。也就是让新节点等于node3,然后再让cur.next指向新节点nodeTmp。
nodeTmp.next = cur.next;cur.next = nodeTmp;为了避免出现下标越界的情况,我们还要对下标的合法性进行一个判断,因此创建了check方法和自定义了异常
public class CheckPosException extends RuntimeException{public CheckPosException(String message) {super(message);}public CheckPosException() {}
}
private void check(int index){if (index < 0 || index > size()){throw new CheckPosException("下标不正确");}}又因为当下标是首或尾时,我们能直接调用头插、尾插法。因此,下面是这方法的代码:
@Overridepublic void addIndex(int index, int data) {ListNode nodeTmp = new ListNode(data);check(index);if(index == 0){addFirst(data);return;}if(index == (size())){addLast(data);return;}ListNode cur = findIndex(index);nodeTmp.next = cur.next;cur.next = nodeTmp;}3.7removePos方法
这个方法是用于删除某个指定下标节点的方法,它相当于是addIndex方法的逆序版
所以,我们可以使用上面的findIndex方法,来寻找对应下标的前一个位置,以删除下标2为例,让cur到node2,把cur.next = nodeTmp变成cur.next = cur.next.next,也就是等于node3,就像下图:
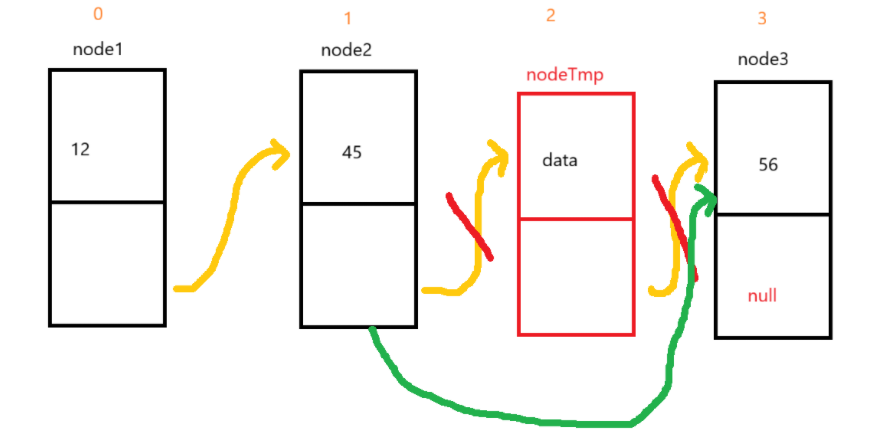
当key等于零时,我们可以直接让head节点等于head的下个节点,即head = head.next。并且,我们还要重写一个check方法来判断下标的合法性,但区别于上面check方法的条件,下标的值不能大于等于 size 的值。不仅这样,按我们还需判断该链表是否为null,如果是null,那么就直接返回即可
代码如下:
private void check2(int key) {if (key < 0 || key >= size()){throw new CheckPosException("下标不正确");}}@Overridepublic void removePos(int key) {if(head == null){System.out.println("链表为空");return;}check2(key);if(key == 0){head = head.next;return;}ListNode cur = findIndex(key);cur.next = cur.next.next;return;}
3.8remove方法
这个方法用于寻找指定的值,然后再进行删除。原理和上面removePos类似,只不过是加了判断条件而已
因此,创建了一个search方法,用于查找对应的值,而且为了增加效率,我们让判断条件变成cur.next.val == key。以下图为例:
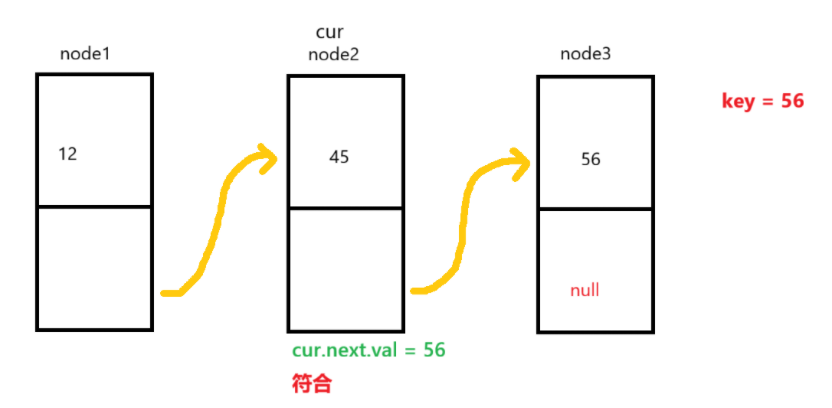
cur来到node2处,我们的key值为56。当下一轮循环开始时,首先判断cur不为空,进入循环后,再用当前cur.next的值查看,发现相同,退出循环。这时,当前的cur就保持在node2,让后续删除节点操作更高效
以下是代码:
private ListNode search(int key){ListNode cur = head;while(cur != null){if(cur.next.val == key){break;}cur = cur.next;}return cur;}@Overridepublic void remove(int key) {if(head == null){return;}ListNode cur = search(key);cur.next = cur.next.next;}3.9removeAll方法
这个方法用于删除所有符合key的值的节点,以下图的为例,需要移除的元素为34:
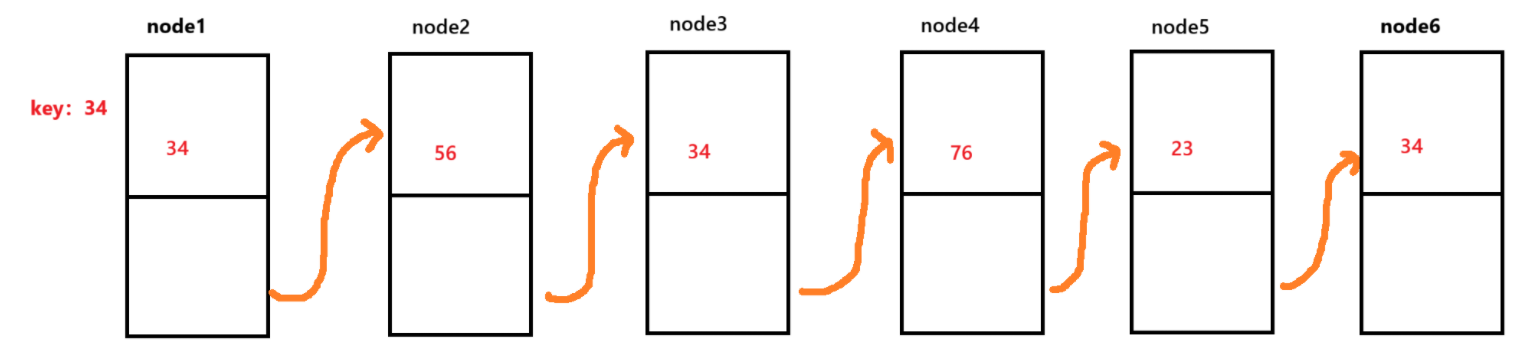
首先为了效率,我们首选一次遍历就能删除所有符合条件的节点。因此,我们定义两个变量cur和pre。我们以cur为前驱,让pre为cur的后驱。
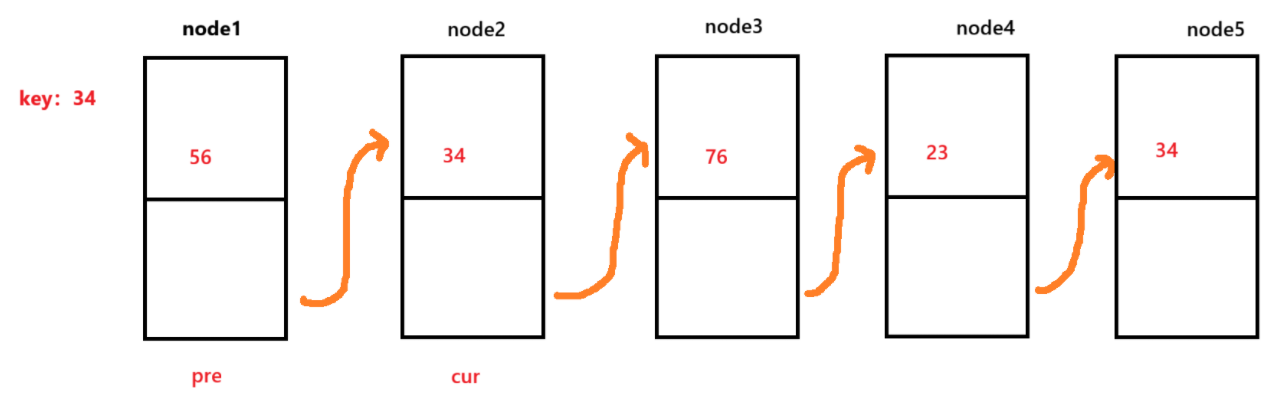
这时,我们就发现cur所在的位置的元素需要移除,因此就要cur = cur.next,pre.next = cur,这代表cur向后移动到node3,并让pre的节点连接到cur上。
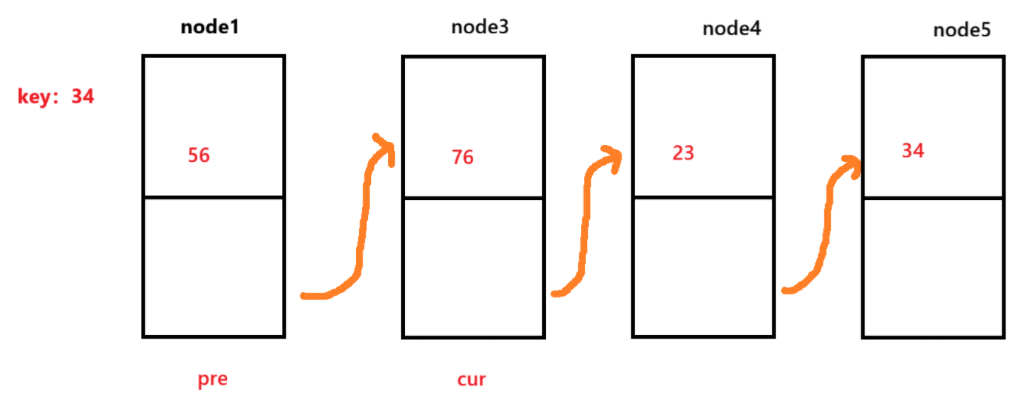 当cur不符合时,就让pre = cur,cur = cur.next。也就是说让pre和cur同时向前走。因此,构成一个循环,直到cur == null才停止
当cur不符合时,就让pre = cur,cur = cur.next。也就是说让pre和cur同时向前走。因此,构成一个循环,直到cur == null才停止
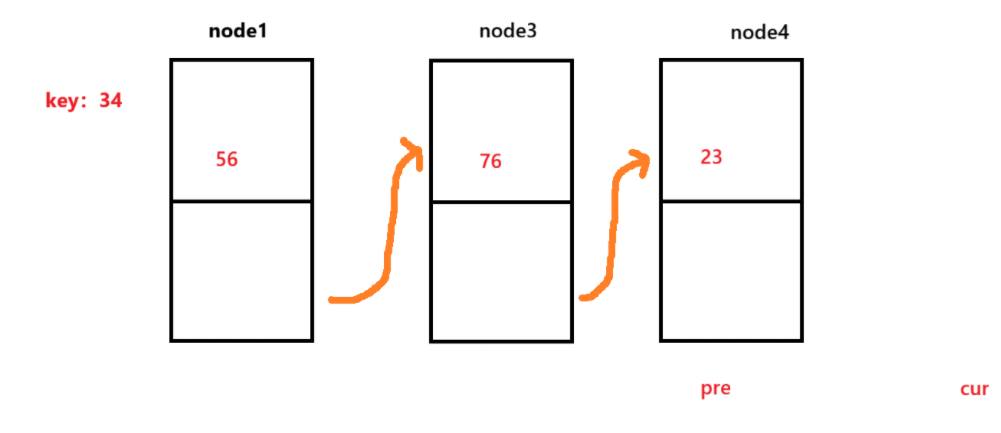 不过,如果链表是这样的话
不过,如果链表是这样的话
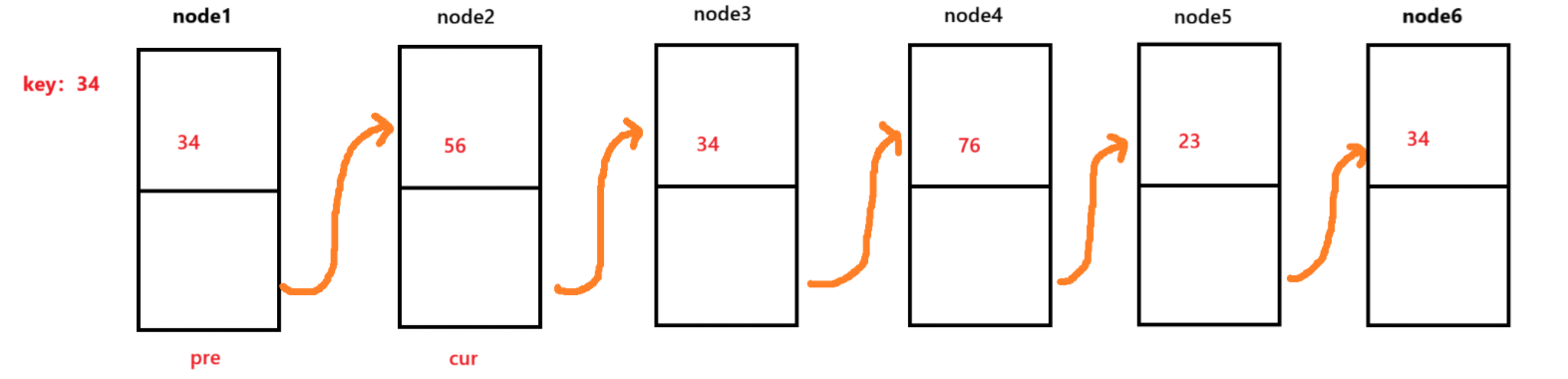 那么我们就会遗漏首元素的情况,因此我们需要加多一个循环,用head节点进行判断是否相同,如果相同,那么就直接让head往后移动。不同则退出循环,综上所述,最终的代码如下:
那么我们就会遗漏首元素的情况,因此我们需要加多一个循环,用head节点进行判断是否相同,如果相同,那么就直接让head往后移动。不同则退出循环,综上所述,最终的代码如下:
@Overridepublic void removeAllKey(int key) {ListNode pre = head;ListNode cur = head.next;while(head.val == key){head = head.next;}while(cur != null){if(cur.val == key){pre.next = cur.next;cur = cur.next;}else{pre = cur;cur = cur.next;}}}3.10clear方法
这个方法是用来清除所有的节点的,因此我们只用把头节点变为空,那么后面的链表就自动被销毁
@Overridepublic void clear() {this.head = null;}