机器学习之损失函数
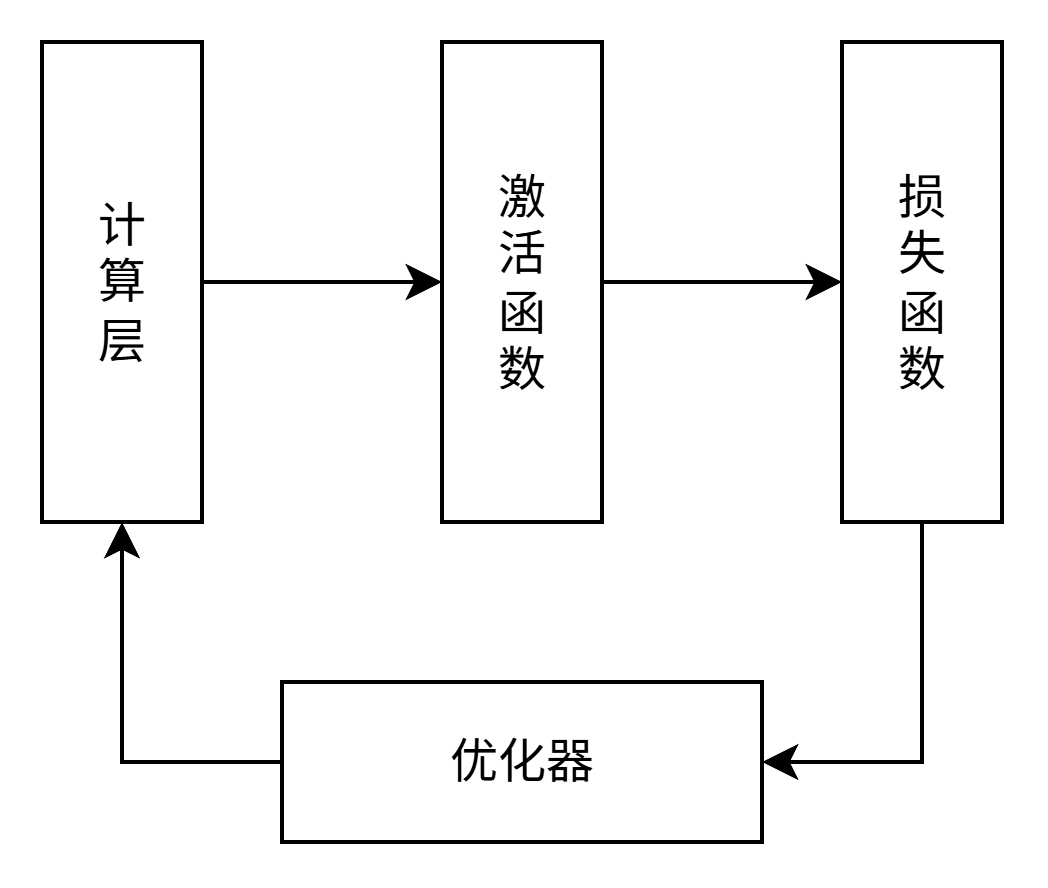
在训练过程中,神经网络模型可以简化为上图中的4部分,今天的主角是损失函数。损失函数的作用是量化模型预测值与真实值之间的差别,也就是负责告诉优化器模型错没错,错的有多离谱。优化器再根据损失函数的结果调整模型参数,模型训练的过程很像是一个负反馈网络。
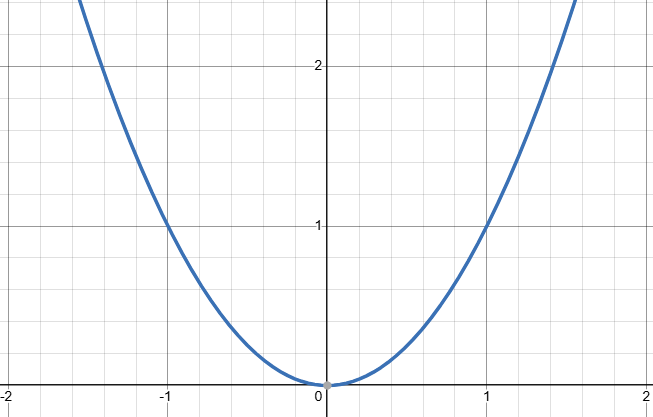
严格来说,优化器利用的不是损失函数的结果,而是它的导数,也就是梯度。因此损失函数不一定具有零点,但是一定要有最低点(最小值),也就是它的梯度一定要有零点。其次是它必须可导,这样才能求梯度。我们学到的第一个二次函数 y=x2y=x^2y=x2 就是这样的函数。
为了方便描述,先对后面要用到的符号做一个说明:
| 符号 | 含义 |
|---|---|
| YYY | 真实值(向量) |
| YiY_iYi | 真实值(向量)的第 iii 个值 |
| yyy | 模型预测值(向量) |
| yiy_iyi | 模型预测值(向量)的第 iii 个值 |
| LLL | 损失函数 |
MAE及其变种
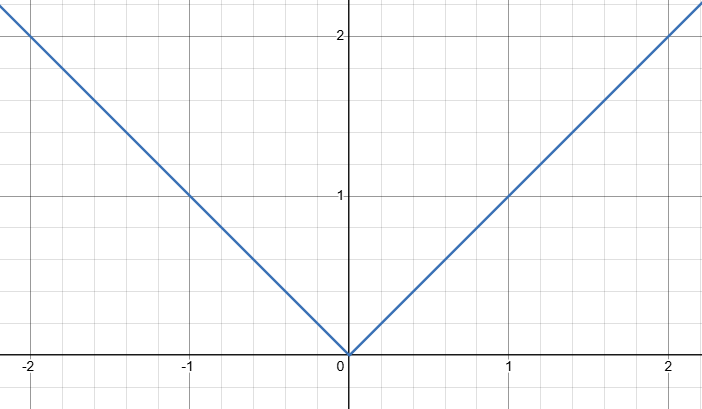
我们能想到的最简单的误差计算公式就是做减法,∣Yi−yi∣|Y_i-y_i|∣Yi−yi∣ 这就是误差,它的函数图像如下。
L=1n∑i=0n∣Yi−yi∣L=\frac{1}{n}\sum_{i=0}^{n}{|Y_i-y_i|}L=n1i=0∑n∣Yi−yi∣
这叫平均绝对误差(Mean Absolute Error),俗称 MAE,也有叫它L1损失函数的。虽然它具有最小值,但是它在最小值处不可导。于是就衍生出了一些 MAE 的变体,它们都是分段函数,主要就是为了解决 MAE 零点不可导问题,比如Smooth L1损失函数。
L={12(Y−y)2∣Yi−yi∣<1∣Y−y∣−12otherL=\begin{dcases} \frac{1}{2}(Y-y)^2 & |Y_i-y_i|<1 \\ |Y-y|-\frac{1}{2} & other \end{dcases}L=⎩⎨⎧21(Y−y)2∣Y−y∣−21∣Yi−yi∣<1other
再比如Huber Loss:
L={12(Y−y)2∣Yi−yi∣<δδ(∣Y−y∣−12δ)otherL=\begin{dcases} \frac{1}{2}(Y-y)^2 & |Y_i-y_i|<\delta \\ \delta(|Y-y|-\frac{1}{2}\delta) & other \end{dcases}L=⎩⎨⎧21(Y−y)2δ(∣Y−y∣−21δ)∣Yi−yi∣<δother
它们的核心都是通过分段函数解决MAE零点附近不可导的问题,其他地方还是MAE。
MSE
MSE 叫做均方差,Mean Square Error。它是对误差的平方求和取平均,也被叫做L2损失函数。
L=1n∑i=0n(Yi−yi)2L=\frac{1}{n}\sum_{i=0}^{n}{(Y_i-y_i)^2}L=n1i=0∑n(Yi−yi)2
在线性回归中,常用它来拟合函数。它不经具有最小值,而且处处可导。
交叉熵
交叉熵是一种熵,一种什么样的熵呢?一种交叉的熵,什么是交叉的熵呢?首先要理解熵。物理学和信息论里都有熵的概率,这里是信息论中的熵。它的定义是:无损编码事件信息的最小平均编码长度。
关键词:最小,长度。
假设事件A出现的概率为 ppp,采用二级制编码,需要的长度为:n=−log2pn=-\log_2{p}n=−log2p。这也很好理解,所谓编码就是给样本空间中的每一个事件一个编号,事件A出现的概率为 ppp,要让事件A出现一次,需要的样本数量就是 1p\frac{1}{p}p1,而 nnn 比特二进制所能表示的总可能性是 2n2^n2n,于是就有:
2n=1plog22n=log21pn=−log2p\begin{aligned} 2^n&=\frac{1}{p} \\ \log_2{2^n}&=\log_2\frac{1}{p} \\ n&=-\log_2{p} \end{aligned}2nlog22nn=p1=log2p1=−log2p
熵其实就是所有事件编码长度的期望:
E=−∑i=0npilog2piE=-\sum_{i=0}^n{p_i\log_2{p_i}}E=−i=0∑npilog2pi
记住这个结果是最小的,如果我们把模型输出结果也看作是一种概率分布,假设 pip_ipi 表示真实分布概率,而 qiq_iqi 表示模型预测的概率分布,将上面公式中后面的 pip_ipi 换成 qiq_iqi,于是得到:
Ec=−∑i=0npilog2qiE_c = -\sum_{i=0}^n{p_i\log_2{q_i}}Ec=−i=0∑npilog2qi
这就是交叉熵!所谓交叉就是把 pip_ipi 换成 qiq_iqi,前面我们说了熵是最小的长度,那么一定有 Ec≥EE_c \geq EEc≥E,当且仅当 qi=piq_i=p_iqi=pi 时取等号。如果我们将 EcE_cEc 做为损失函数,它也具有最小值,而且可导,这就是交叉熵损失函数。
KL散度
KL是两个人名,库尔贝克和莱布里埃。理解了交叉熵之后,其实KL散度就是交叉熵与熵的差!
EKL=Ec−E=−∑i=0npilog2qi+∑i=0npilog2pi=∑i=0npilog21qi+∑i=0npilog2pi=∑i=0npilog2piqi\begin{aligned} E_{KL}&=E_c-E\\ &= -\sum_{i=0}^n{p_i\log_2{q_i}}+\sum_{i=0}^n{p_i\log_2{p_i}} \\ &= \sum_{i=0}^n{p_i\log_2{\frac{1}{q_i}}}+\sum_{i=0}^n{p_i\log_2{p_i}} \\ &=\sum_{i=0}^n{p_i\log_2{\frac{p_i}{q_i}}} \end{aligned} EKL=Ec−E=−i=0∑npilog2qi+i=0∑npilog2pi=i=0∑npilog2qi1+i=0∑npilog2pi=i=0∑npilog2qipi
因为Ec≥EE_c \geq EEc≥E,所以 EKL≥0E_{KL} \geq 0EKL≥0。它也具有最小值,而且可导。
以两个变量为例,我们可以通过 desmos 在线工具绘制出交叉熵和KL散度的函数图像。

红色是交叉熵,绿色是KL散度,它们的图像非常相似,唯一的区别是最小值是否为零,但是损失函数只要求梯度具有零值,它们都是符合损失函数要求的。