大模型微调——LoRA微调
一、定义
在了解LoRA微调的概念之前,我们先来了解一下什么是全量微调:
全量微调是传统且直观的微调方法,他需要更新预训练模型的所有参数,一次微调需要消耗大量的资源,并且会造成知识遗忘,模型可能会为了学好新任务而忘记在原来预训练过程中学到的知识。
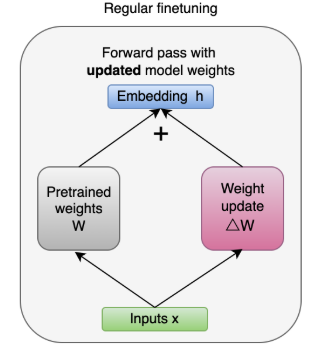
而LoRA微调回冻结原来预训练的模型参数,保持预训练模型的原始参数 W 不变,只对低秩矩阵 A 和 B 进行训练,在原始预训练语言模型(Pre - trained Language Model,简称 PLM)旁添加一条旁路,进行一次降维再升维的操作,以此来模拟所谓的内在秩(intrinsic rank)
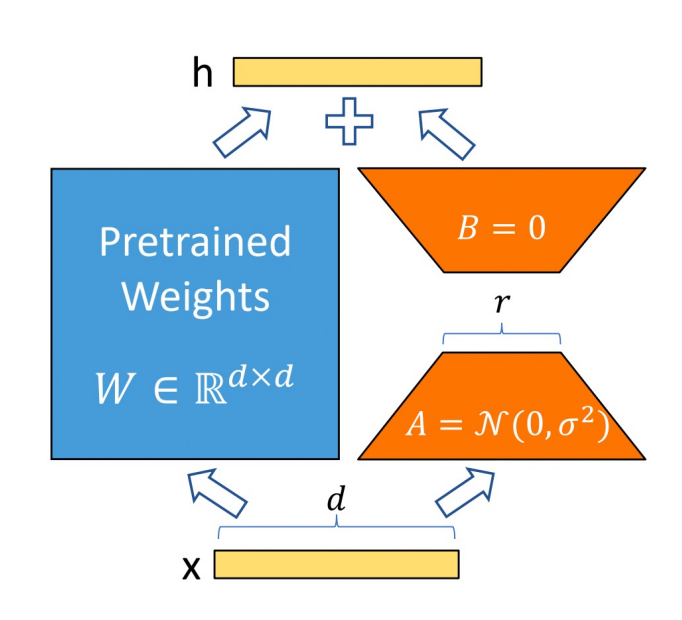
对于预训练权重矩阵 W∈Rd×kW∈Rd×k,LoRA 的更新为:
h =Wx + ΔWx = Wx + BAx
如果大模型是一个复杂的数学函数:
传统:
y = f(x)重新定义整个 f(x)LoRA:
y = f(x) + 小调整,只调整最后的小部分
二、LoRA 微调参数
1. task_type - 任务类型
# 可选的任务类型:
task_type=TaskType.SEQ_CLS # 序列分类(如情感分析)
task_type=TaskType.TOKEN_CLS # 令牌分类(如命名实体识别)
task_type=TaskType.QUESTION_ANS # 问答任务
task_type=TaskType.CAUSAL_LM # 因果语言建模(文本生成)
task_type=TaskType.SEQ_2_SEQ_LM # 序列到序列(如翻译)
task_type=TaskType.FEATURE_EXTRACTION # 特征提取2. r - 秩 Rank
每个线性层LoRA的参数 = (input_dim × r) + (r × output_dim),r越大,可以训练的参数越多,拟合能力越强
r=4 # 最小配置,参数最少,可能欠拟合
r=8 # 平衡配置(最常用)
r=16 # 较强表达能力
r=32 # 高表达能力,接近全参数微调效果
r=64 # 最大配置,参数较多3. lora-alpha 缩放因子
# 控制 LoRA 调整量的缩放大小
lora_alpha=16 # 常用配置:通常是 r 的 2-4 倍
lora_alpha=32 # 标准配置
lora_alpha=64 # 较大的调整幅度4. lora-dropout - Dropout率
只在训练的时候生效,预测时自动关闭
# 防止过拟合,随机丢弃部分神经元
lora_dropout=0.0 # 无dropout(小数据集可能过拟合)
lora_dropout=0.1 # 常用配置
lora_dropout=0.2 # 较强的正则化
lora_dropout=0.3 # 很强的正则化(大数据集)5. target_modules - 目标模块
指定在哪些神经网络层用LoRA、
# 指定在哪些神经网络层应用 LoRA# 对于 Transformer 模型(BERT、GPT等):
target_modules=["query", "key", "value"] # 只改注意力机制
target_modules=["query", "key", "value", "dense"] # 注意力+前馈网络
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"] # LLaMA/GPT风格
target_modules=[".*"] 6. bias - 偏置处理
bias="none" # 不训练偏置项(最常用)
bias="all" # 训练所有偏置项
bias="lora_only" # 只训练LoRA层的偏置7. modules_to_save - 额外训练层
modules_to_save=["classifier"] # 分类头(分类任务必选)
modules_to_save=["score"] # 评分头
modules_to_save=["lm_head"] # 语言模型头(生成任务)三、应用举例
例如我们想要用lora训练实现情感分类
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
from datasets import Dataset# 数据准备,可以直接建一个数据的文档,这里简单举例
texts = ["I love this movie!", # 正面"This is great!", # 正面 "I hate this film.", # 负面"This is terrible.", # 负面"Amazing performance!", # 正面"Boring and bad.", # 负面
]labels = [1, 1, 0, 0, 1, 0]# 加载模型
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)# 设置LoRA
lora-config = LoraConfig(# 任务类型,自回归语言建模task_type=TaskType.SEQ_CLS,# 对什么层次进行高效微调target_modules=["query", "value"],inference_mode=False,r=8,# 缩放因子lora_alpha=32,lora_dropout=0.1)lora_model = get_peft_model(model, lora_config)def tokenize_function(examples):return tokenizer(examples["text"], truncation=True, padding=True, max_length=128)dataset = Dataset.from_dict({"text": texts, "label": labels})
dataset = dataset.map(tokenize_function, batched=True)training_args = TrainingArguments(output_dir="./simple_lora",per_device_train_batch_size=2,num_train_epochs=3,learning_rate=1e-3,
)trainer = Trainer(model=lora_model,args=training_args,train_dataset=dataset,tokenizer=tokenizer,
)print("开始训练...")
trainer.train()test_texts = ["This is awesome!", "I don't like it."]
for text in test_texts:inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)with torch.no_grad():outputs = lora_model(**inputs)prediction = torch.argmax(outputs.logits, dim=1).item()sentiment = "正面" if prediction == 1 else "负面"print(f"文本: '{text}' → 情感: {sentiment}")