vLLM PD分离推理服务配置指南
目录
1 运行 vLLM 分布式推理服务
环境变量配置
2 PyNcclConnector模式
2.1 启动预填充服务 (kv_producer)
2.2 启动解码服务 (kv_consumer)
3 SharedStorageConnector模式
3.1 启动预填充服务 (kv_producer)
3.2 启动解码服务 (kv_consumer)
4 启动代理服务
4.1 下载辅助脚本
4.2 安装依赖
4.3 测试验证
vLLM 目前支持 5 种类型的连接器:
- SharedStorageConnector, 通过共享存储路径进行 KV Cache 共享
- LMCacheConnectorV1,结合 LMCache 缓存和 NIXL 传输 KV Cache
- NixlConnector,基于 NIXL 传输 KV Cache
- PyNcclConnector,利用 NVIDIA NCCL 进行 KV Cache 传输,高版本叫 P2pNcclConnector
- MultiConnector,多种连接器组合
参考 https://docs.vllm.ai/en/latest/features/disagg_prefill.html?h=prefill#why-disaggregated-prefilling
https://docs.vllm.com.cn/en/latest/features/disagg_prefill.html#why-disaggregated-prefilling
1 运行 vLLM 分布式推理服务
以下命令用于启动一个 vLLM 容器,配置分布式推理环境。该配置涉及两个角色:kv_producer(预填充阶段)和 kv_consumer(解码阶段)。GPU 支持需要宿主机已经安装 NVIDIA 驱动和 nvidia-docker 运行时
docker run -t -d \--name="vllm" \--ipc=host \--cap-add=SYS_PTRACE \--network=host \--gpus all \--privileged \--ulimit memlock=-1 \--ulimit stack=67108864 \-v /data:/data \registry.cn-hangzhou.aliyuncs.com/lky-deploy/llm:vllm-server-0.7.2#SharedStorageConnector类型使用下面这个镜像
#registry.cn-hangzhou.aliyuncs.com/lky-deploy/llm:vllm-server-0.8.5-pytorch2.7-cu128
环境变量配置
在容器内设置网络接口和 CUDA 设备可见性:
export GLOO_SOCKET_IFNAME=eth0
export NCCL_SOCKET_IFNAME=eth0
这里使用 PyNcclConnector 和 SharedStorageConnector 进行演示;模型选择deepseek7B小模型方便测试
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir /data/dp7b
2 PyNcclConnector模式
2.1 启动预填充服务 (kv_producer)
#kv_ip换成实际的
#kv_parallel_size表示服务总数,如果启动服务个数不满足数量会一直等待直到失败
#kv_rank每个节点编号不能重复
#如果需要2个prefill则通过ray添加参数 --pipeline-parallel-size 2,--tensor-parallel-size设置为两个节点一共的gpu卡数量,ray具体可参考 https://likaiyuan00.github.io/2025/09/23/vllm/?highlight=ray
mode=/data/dp7b/
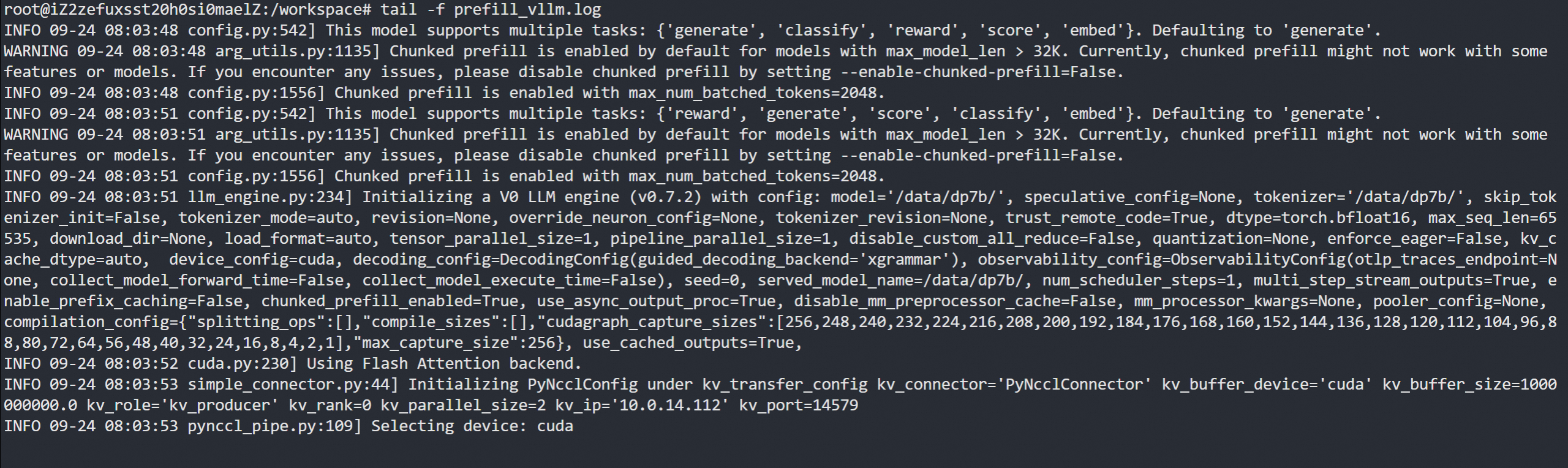
CUDA_VISIBLE_DEVICES=0 vllm serve $mode \--port 8100 \--max-model-len 65535 \--gpu-memory-utilization 0.9 \--trust-remote-code \--tensor-parallel-size 1 \--kv-transfer-config '{"kv_connector": "PyNcclConnector","kv_role": "kv_producer","kv_rank": 0,"kv_parallel_size": 2,"kv_ip": "10.0.14.112","kv_port": 14579}' &> prefill_vllm.log &
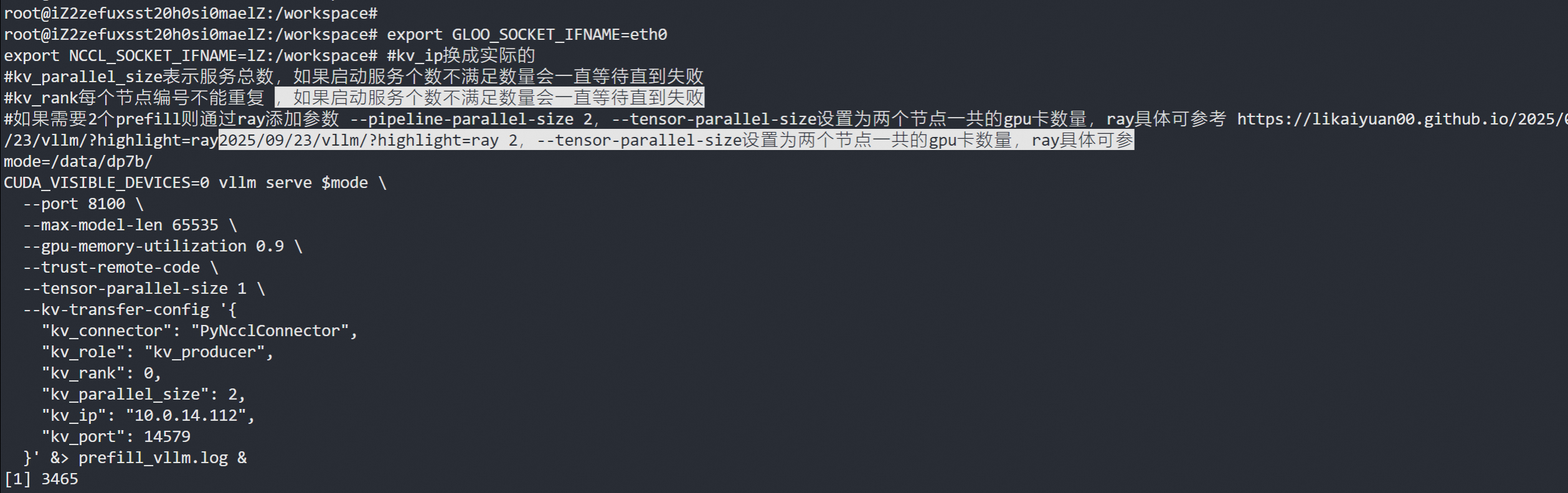
会一直等待节点加入,因为"kv_parallel_size": 2
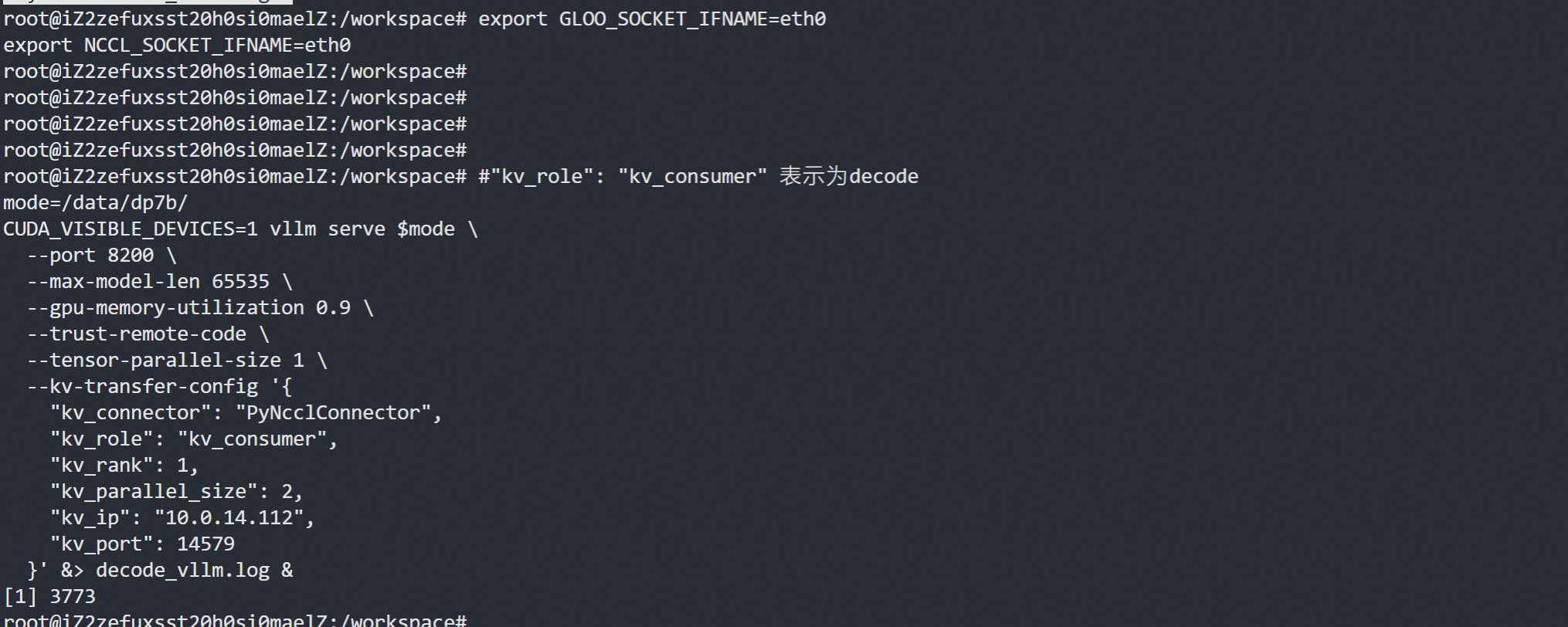
2.2 启动解码服务 (kv_consumer)
#"kv_role": "kv_consumer" 表示为decode
mode=/data/dp7b/
CUDA_VISIBLE_DEVICES=1 vllm serve $mode \--port 8200 \--max-model-len 65535 \--gpu-memory-utilization 0.9 \--trust-remote-code \--tensor-parallel-size 1 \--kv-transfer-config '{"kv_connector": "PyNcclConnector","kv_role": "kv_consumer","kv_rank": 1,"kv_parallel_size": 2,"kv_ip": "10.0.14.112","kv_port": 14579}' &> decode_vllm.log &
3 SharedStorageConnector模式
这个模式建议在vllm0.85以上版本使用,低版本亲测跑不起来
使用 registry.cn-hangzhou.aliyuncs.com/lky-deploy/llm:vllm-server-0.8.5-pytorch2.7-cu128
https://github.com/vllm-project/vllm/issues/14636
3.1 启动预填充服务 (kv_producer)
mode=/data/dp7b/
export GLOO_SOCKET_IFNAME=eth0
export NCCL_SOCKET_IFNAME=eth0
CUDA_VISIBLE_DEVICES=0 vllm serve $mode --port 8100 --max-model-len 4096 \
--gpu-memory-utilization 0.8 --trust-remote-code \
--kv-transfer-config '{
"kv_connector":"SharedStorageConnector",
"kv_role":"kv_producer",
"kv_connector_extra_config":{"shared_storage_path":"/data/models/pd_local_storage"}
}' &> prefill_vllm.log &当前模式下不会等待,会直接启动服务
3.2 启动解码服务 (kv_consumer)
mode=/data/dp7b/
export GLOO_SOCKET_IFNAME=eth0
export NCCL_SOCKET_IFNAME=eth0
CUDA_VISIBLE_DEVICES=1 vllm serve $mode --port 8200 --max-model-len 4096 \
--gpu-memory-utilization 0.8 --trust-remote-code \
--kv-transfer-config '{
"kv_connector":"SharedStorageConnector",
"kv_role":"kv_consumer",
"kv_connector_extra_config":{"shared_storage_path":"/data/models/pd_local_storage"}
}' &> decode_vllm.log &
4 启动代理服务
4.1 下载辅助脚本
获取分布式基准测试所需的 Python 脚本:
#如果无法下载可以去 https://github.com/likaiyuan00/vllm/blob/main/benchmarks/disagg_benchmarks/disagg_prefill_proxy_server.py 获取wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/disagg_prefill_proxy_server.py -O disagg_prefill_proxy_server.py
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/rate_limiter.py -O rate_limiter.py
wget https://raw.githubusercontent.com/vllm-project/vllm/refs/heads/main/benchmarks/disagg_benchmarks/request_queue.py -O request_queue.py#这个代理支持多个参数
#https://github.com/vllm-project/vllm/blob/main/examples/online_serving/disaggregated_serving/disagg_proxy_demo.py4.2 安装依赖
安装必要的 Python 包:
python3 -m pip install --ignore-installed blinker quart
python3 disagg_prefill_proxy_server.py
disagg_prefill_proxy_server.py 默认参数就是8100和8200所以可以不用指定
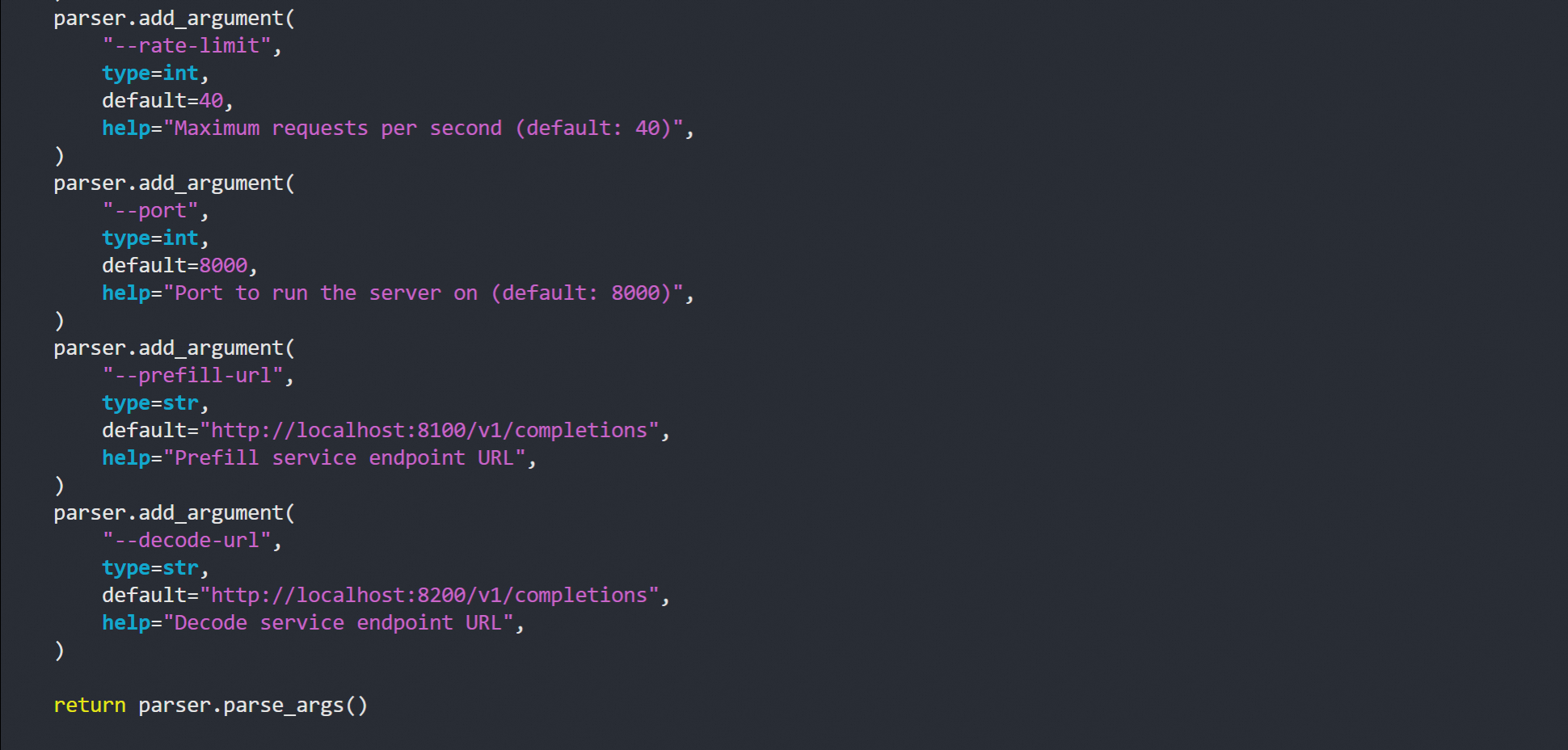
4.3 测试验证
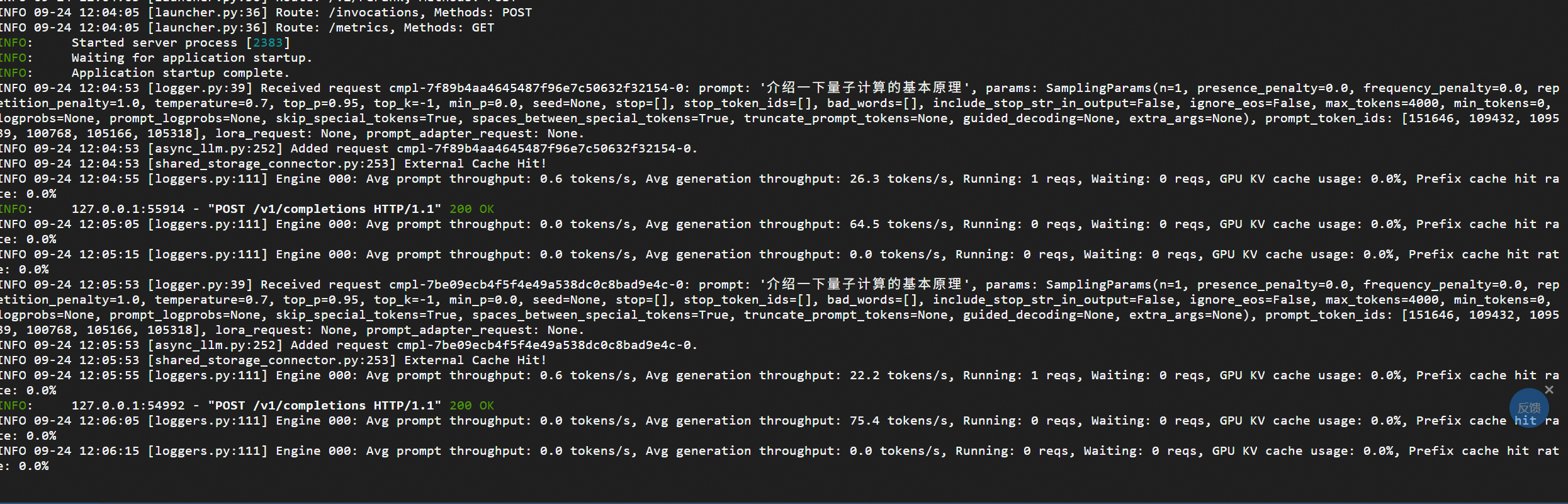
curl -X POST "http://127.0.0.1:8000/v1/completions" \-H "Content-Type: application/json" \-d '{"model": "/data/dp7b/","prompt": "介绍一下量子计算的基本原理","temperature": 0.7,"max_tokens": 500}'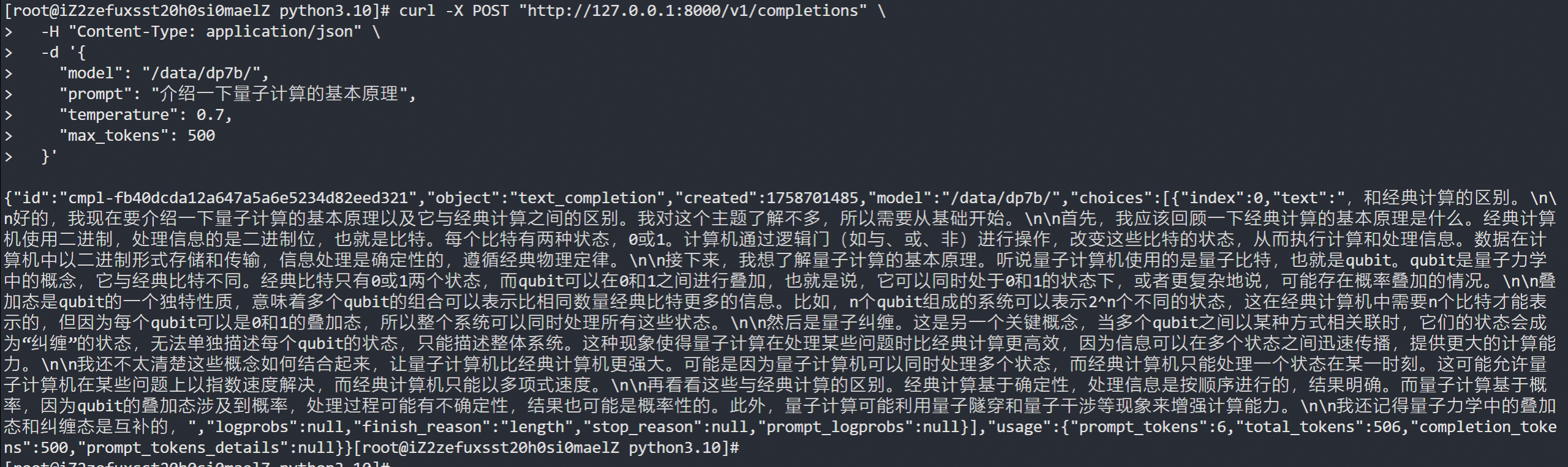
prefill可以看到负责 prompt token
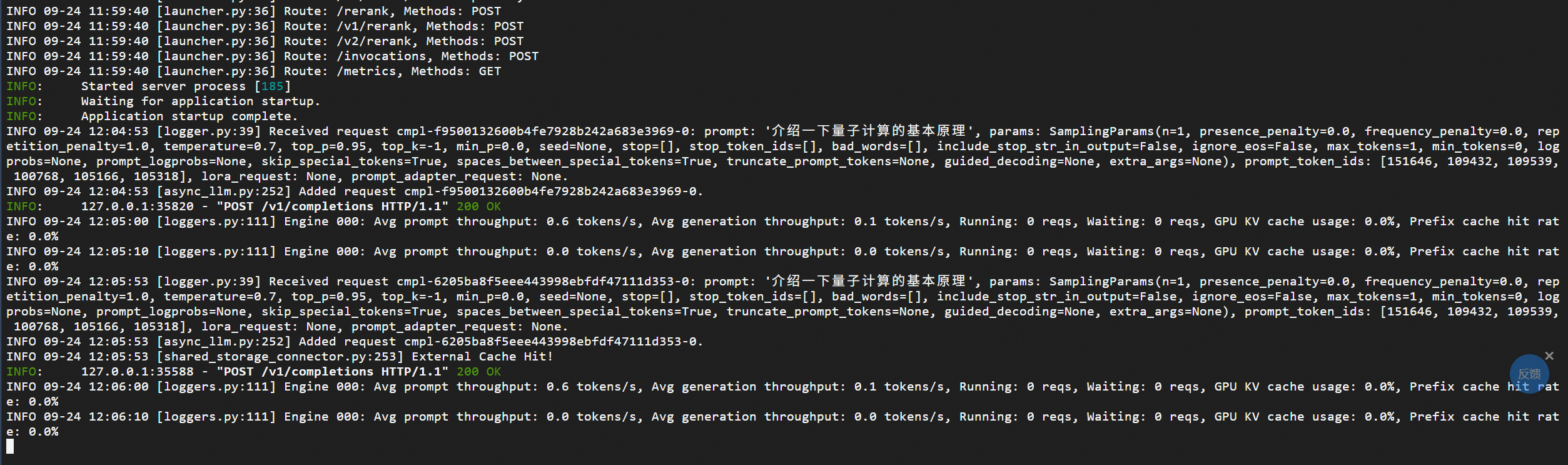
decode负责 generation throughput token 数量明显不一样