Linux编程笔记2-控制数组指针函数动态内存构造类型Makefile
控制流程
If-else只与附近的if相匹配
如:
if(a==b)If(b==c)Printf(“a==b==c\n”);ElsePrintf(“a!=b\n”);输出a!=b
用位运算来进行进制转换:十进制转二进制——245转11110101???
unsigned char n = 245;
for (int i = 7; i >= 0; i--) {putchar(((n >> i) & 1) + '0');
}Char str[N]=”abc”;此可以改其数据吗?那种指向”abc”的地址的是什么样的?
答:char *str_ptr = "abc"; 字符串存储在程序的只读数据段里
数组:
部分元素赋值,其他元素自动默认赋为0值
数组名:是表示地址的常量,起始地址——数组[i]本身就是一个指针的操作a[i]=&(a+i),所以实际上是指针的操作,编译器不会报错(一般的,现在的会主动报错)。
排序
冒泡排序:
最多n-1,
#include<stdio.h>
#include<stdlib.h>
int main(void) {int arr[] = { 2,5,1,3,7,4 };int len = sizeof(arr) / sizeof(arr[0]);int i, j, temp;for (i = 0; i < len - 1; i++) {for (j = 0; j < len - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}for (int i = 0; i < len; i++) {printf("[%s]:%d\n", __FUNCTION__, arr[i]);}return 0;
}选择排序:
确定一个最小值/最大值,依次遍历,最多n-1的排序
#include<stdio.h>
#include<stdlib.h>
int main(void) {int arr[] = { 2,5,1,3,7,4 };int len = sizeof(arr) / sizeof(arr[0]);int i, j, temp, obj;for (i = 0; i < len - 1; i++) {obj = i;for (j = i + 1; j < len; j++) {if (arr[j] < arr[obj]) {obj = j;}}if (i != obj) {temp = arr[i];arr[i] = arr[obj];arr[obj] = temp;}}for (int i = 0; i < len; i++) {printf("[%s]:%d\n", __FUNCTION__, arr[i]);}return 0;
}快速排序:
我们以数组 [5, 2, 8, 3, 1, 6, 4] 为例,目标是排成升序 [1, 2, 3, 4, 5, 6, 8]。
第一步:选择基准和分区
选择最右边元素 4 作为基准pivot。
初始数组: [5, 2, 8, 3, 1, 6, 4] (pivot=4)
分区过程:
j=0: 5 > 4,不移动,i不动
j=1: 2 <= 4,i++ (i=0),交换 arr[0]和arr[1] → [2, 5, 8, 3, 1, 6, 4]
j=2: 8 > 4,不移动
j=3: 3 <= 4,i++ (i=1),交换 arr[1]和arr[3] → [2, 3, 8, 5, 1, 6, 4]
j=4: 1 <= 4,i++ (i=2),交换 arr[2]和arr[4] → [2, 3, 1, 5, 8, 6, 4]
j=5: 6 > 4,不移动
分区完成后,交换基准到正确位置:
交换 arr[i+1] (arr[3]=5) 和 arr[high] (arr[6]=4) → [2, 3, 1, 4, 8, 6, 5]
此时基准4已经在最终正确位置
第二步:递归排序左右子数组
现在递归排序左边 [2, 3, 1] 和右边 [8, 6, 5]
排序左边 [2, 3, 1] (pivot=1):
分区后:所有元素都>=1,i保持-1
交换后:[1, 3, 2] → 基准1已在正确位置
继续排序 [3, 2]...
排序右边 [8, 6, 5] (pivot=5):
分区后:[5, 6, 8] → 基准5已在正确位置
继续排序 [6, 8]...
最终整个数组变为:[1, 2, 3, 4, 5, 6, 8]
#include<stdio.h>
#include<stdlib.h>// 分区函数-确保基准找到正确位置
int partion(int arr[], int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j <= high - 1; j++) {if (arr[j] <= pivot) {i++;int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// 把基准放到正确位置int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return i + 1;
}// 快速排序主函数
void quicksort(int arr[], int low, int high) {if (low < high) {int p = partion(arr, low, high); // 确定基准的最终位置quicksort(arr, low, p - 1); // 递归排序小于基准元素quicksort(arr, p + 1, high); // 递归排序大于基准元素}
}int main(void) {int arr[] = { 2,5,1,3,7,4 };int len = sizeof(arr) / sizeof(arr[0]);quicksort(arr, 0, len - 1);for (int i = 0; i < len; i++) {printf("[%s]:%d\n", __FUNCTION__, arr[i]);}return 0;
}
二维数组:
只有行可以省略arr[][M]=0;
A[0]表示:a[0][1]、a[0][2]、a[0][3]
字符数组:
Char str[N]={‘a’,’b’,’’c};
Char str[N]=”abc”;
存在结束标识符’\0’
Scanf(遇到分隔符会直接截断)——gets——fgets:输入字符串函数
Strlen&sizeof
Strlen不会包含’\0’,以’\0’为结束标志位,返回值为int
Sizeof会包含
Strcpy&Strncpy:拷贝时也要把’\0’拷贝走
Strcpy(目标,源);
Strncpy(目标,源,拷贝数量);
Strcat&Strncat:连接
Strcat(目标,追加的源字符串);
Strncat(目标,追加的源字符串,最多从源字符串 src 中追加的字符数);
Strcmp&Strncmp:比较:比较ASCII码,返回值是int:如果 A>B:则返回1,相等返回0;反之则为负值
Strcmp(目标,源);
Strncmp(目标,源,比较字母的数量);
1.#if #else #endif——与注释有什么区别?
答:注释本来是对代码进行说明的,#if是对代码进行预处理的;一个是增强代码可读性,做描述或临时屏蔽代码部分(不要依赖);另一个是根据不同环境、平台、配置选择编译不同代码,面向开发与调试需求。
2.段错误是什么?
答:是计算机程序运行时常见的错误,通常发生在程序试图访问未被允许访问的内存区域,或者以不允许的方式访问内存时。
3.qsort函数使用???
答:
void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void*));
- base:指向要排序的数组的首地址(void* 类型,可接受任意类型数组)。
- nitems:数组中元素的数量。
- size:每个元素的字节大小(例如 int 是 sizeof(int))。
- compar:比较函数的指针,用于定义排序规则,返回值:
负数:第一个参数应排在第二个参数前面——正序
0:两个参数相等
正数:第二个参数应排在第一个参数前面
#include<stdio.h> #include<stdlib.h>int compare_int(const void* a, const void* b) {return (*(int*)a - *(int*)b); }int main(void) {int arr[] = { 2,5,1,3,7,4 };int n = sizeof(arr) / sizeof(arr[0]);//升序排序qsort(arr, n, sizeof(int), compare_int);for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0; }
指针
变量与地址
指针与指针变量 +多级指针
Int i=1;Int *p=&i;Int **q=&p;I——》1&i——》0x2000P——》&i&p——》0x3000*p——》*(0x2000)——》1*q——》*(&p)——》p——》&i**q——》*(*q)——》*(&i)——》1指针在解引用时会根据自身的类型进行读取数据,int为4B,若用char *ch;来读取则会截断2B的数据,导致失真;
指针与数组的关系:
二维数组:
*(a+i)+j,*(*(a+i)+j)
P=&a[0][0];——一般的这种p指针只能在列移动
所以 for(ini i=0;i<6;i++,p++){
Printf[(“%d”,*p);
}
数组指针
Int (*q)[3]=a ==int a[2][3]
字符数组
Char str[]=”hello”;
Char *str=”hello”;
Const与指针
Const修饰:const int a;和int const a; ——变量一直保持常量值
Const int *p; 和int const *p; Int *const p;
常量指针和指针常量:
常量指针:指针的指向可以发生变化,但指针指向的值不能发生变化
指针常量:反之
Const int *const p;
指针数组和数组指针
Int (*q)[3];——》type name——》int[3] *p
int *arr[3];——》name type——》int *[3] arr
函数
函数与数组:
二维数组:
Myprintf(&a[0][0],M*N)——将二维数组变为一个大数组来处理
Myprintf(*a,M*N)——转列解引用
Myprintf(a,M*N)——数组指针——》Myprintf(int(*p)[N],int m,int n)
p[num][i] ≡ *(p[num] + i) ≡ *(*(p + num) + i)
函数与指针:
指针函数:int *fun(int);——return *(int);需要返回值为地址
函数指针:(*指针名)(形参):int (*p)(int)——指针指向函数:int(*funcp)(int,int)
函数指针数组:int(*arr[N])(int);——int(*funcp[2])(int,int)
构造函数:
结构体
类型声明是不占空间的
Struct name{
Type 成员1;
......
};
单独设置成员struct stu S={S.math=59};
存储存在偏移量:_attribute_(packed)使用此宏让其不偏移
函数传参:一般都使用指针来进行传参;
结构体成员之间可以直接用等于代替
共用体
Union 共用体名{
数据类型 成员名1;
.......
};
多个成员共用一个空间,按类型最大的进行确定大小;其应用的方式与结构体相同;
位域:
char a:1;
char b:2;
char c:1;
数值存入会被以补码形式来看待,所以需要对其进行格式处理
动态内存管理
原则:谁申请谁释放
malloc
calloc
raelloc
Free

1.Typedefine和define的区别???
答:
// 使用 typedef typedef int INTEGER; typedef char* STRING;// 使用 define #define INT int #define CHAR_PTR char*2. #ifndef __Sqlist_H #define __Sqlist_H 和#ifndef Sqlist_H_ #define Sqlist_H_
的区别???
答:
__Sqlist_H根据C标准:
以双下划线开头的标识符是实现保留的
编译器或标准库可能使用类似名称,可能产生冲突
示例:
__FILE__,__LINE__,__DATE__等都是编译器预定义的
Sqlist_H_(推荐)
使用单下划线结尾,避免与保留标识符冲突
更清晰易读:
Sqlist_H_明显表示"Sqlist头文件的保护宏"符合现代编程规范
3,fprintf的用法
答:
int fprintf(FILE *stream, const char *format, ...);
stream:文件指针,指定要写入的文件
format:格式化字符串,与printf类似
...:可变参数,根据格式化字符串提供数据返回值:成功返回写入的字符数,失败返回负值(printf同理)
4.预定义宏(__LINE__)
答:
宏名称 说明 示例值 __LINE__当前行号(整数) 25__FILE__当前文件名(字符串) "main.c"__DATE__编译日期(字符串) "Sep 25 2024"__TIME__编译时间(字符串) "14:30:25"__func__当前函数名(C99) "main"__FUNCTION__当前函数名(GCC扩展) "main"__cplusplusC++版本号(C++中) 199711L__STDC__标准C编译器标识 1
Makefile:
进行分析在文件工程中的依赖和被依赖的关系,形成这样的脚本
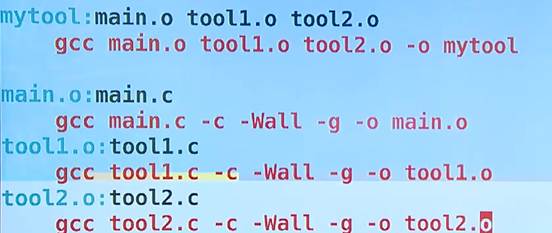
解释:

Main.c
#include<stdio.h>#include"tool1.h"#include"tool2.h"int main(void){mytool1();mytool2();return 0;}a.out依赖于main.o tool1.o tool2,o
Main.o依赖于main.c tool1.c tool2.c
Tool1.o依赖于tool1.c
Tool2.o依赖于tool2.c
Makefile:OBJS=main.o tool1.o tool2.oCC=gccCFLAGS+=-c -Wall -gmytool:$(OBJS)//$(CC) $(OBJS) -o mytool$(CC) $^ -o $@main.o:main.c//$(CC) main.c $(CFALGS) -o main.o$(CC) $^ $(CFALGS) -o $@tool1.o:tool1.c//$(CC) tool1.c $(CFALGS)-o tool1.o$(CC) $^ $(CFALGS)-o $@tool2.o:tool2.c//$(CC) tool2.c $(CFALGS) -o tool2.o$(CC) $^ $(CFALGS) -o $@clean:rm *.o mytool -rf
![]()

=