SpringBoot 整合机器学习框架 Weka 实战操作详解
目录
一、前言
二、Java对接使用的机器学习技术方案
2.1 Weka 介绍
2.1.1 Weka 主要特点
2.1.2 Weka 核心功能模块
2.1.3 Weka 支持的算法类型
2.1.4 Weka 应用场景
2.2 Apache Spark MLlib 介绍
2.2.1 核心模块介绍
2.2.2 核心功能介绍
2.2.3 技术优势
2.2.4 适用场景
2.3 EasyRec 介绍
2.3.1 技术亮点
2.3.2 技术核心模块架构
2.3.3 技术优势
2.3.4 适用场景
三、基于Weka 实现货品推荐上架操作案例
3.1 案例需求
3.2 前置准备
3.2.1 数据准备
3.2.2 导入核心依赖
3.3 基于本地样本数据实现方案
3.3.1 导入核心依赖
3.3.2 添加本地样本数据
3.3.3 完整的实现代码
3.4 基于数据库的样本数据实现方案
3.4.1 添加一张测试样本表
3.4.2 导入依赖
3.4.3 完整的实现代码
3.5 基于AI大模型实现方案
3.5.1 添加配置信息
3.5.2 添加测试接口
3.5.3 效果测试
四、写在文末
一、前言
在微服务开发中,经常会遇到需要进行推荐的场景,比如在电商场景中,需要基于用户的过往购买历史,选品喜欢,轨迹等指标信息进行选品推荐,再比如在社交应用中,需要根据用户的操作历史、个人标签等推荐一些功能从而展示给用户。尽管这样的推荐操作可以结合一些大数据、机器学习等推荐算法来做,但是对一些小型的系统来说,考虑到对接成本、学习成本和维护成本等因素,本篇将详细介绍下在微服务应用中如何对接第三方的机器学习框架,从而实现特定场景下的业务推荐。
二、Java对接使用的机器学习技术方案
接下来介绍几种适合Java开发语言模式下的机器学习框架技术方案。
2.1 Weka 介绍
Weka(Waikato Environment for Knowledge Analysis)是一款由新西兰怀卡托大学开发的开源机器学习与数据挖掘软件,以其易用性、丰富的算法库和可视化界面闻名。它支持从数据预处理到模型评估的全流程,适合教学、研究和快速原型开发。官网:https://ml.cms.waikato.ac.nz/weka/
Weka,是一款免费、非商业化、基于Java的开源的机器学习与数据挖掘软件,并提供了maven依赖,拥有丰富的Java API。
Github 地址:Weka Wiki
2.1.1 Weka 主要特点
Weka 具备如下特点:
-
开源免费:基于GNU通用公共许可证,用户可自由使用、修改和分发。
-
跨平台支持:基于Java开发,可在Windows、macOS、Linux等系统运行。
-
图形用户界面(GUI):提供直观的可视化操作,无需编程即可完成数据挖掘任务。
-
命令行接口:支持通过脚本自动化处理大规模数据或批量任务。
-
丰富的算法库:集成数百种机器学习算法,涵盖分类、回归、聚类、关联规则挖掘等。
2.1.2 Weka 核心功能模块
Weka通过不同界面模块实现数据挖掘流程:
-
Explorer:主界面,包含以下子面板:
-
Preprocess:数据清洗、特征选择、离散化、标准化等。
-
Classify:分类算法(如决策树、SVM、神经网络)训练与评估。
-
Cluster:聚类分析(如K-Means、DBSCAN)。
-
Associate:关联规则挖掘(如Apriori算法)。
-
Select attributes:特征选择与降维。
-
Visualize:数据可视化(散点图、箱线图等)。
-
-
Experimenter:设计对比实验,评估不同算法性能。
-
Knowledge Flow:通过拖拽组件构建数据处理流程图,支持复杂工作流。
-
Simple CLI:命令行交互,适合快速测试或脚本调用。
2.1.3 Weka 支持的算法类型
Weka 支持如下算法类型
-
分类:决策树(J48/C4.5)、随机森林、朴素贝叶斯、SVM、逻辑回归、神经网络等。
-
回归:线性回归、M5规则树、支持向量回归(SVR)。
-
聚类:K-Means、EM、DBSCAN、层次聚类。
-
关联规则:Apriori、FP-Growth。
-
特征选择:信息增益、卡方检验、ReliefF、主成分分析(PCA)。
2.1.4 Weka 应用场景
Weka 在下面的一些场景中可以考虑选择使用:
-
学术研究:算法验证、教学演示(如机器学习课程实验)。
-
快速原型开发:测试不同算法对数据的适应性。
-
小规模数据挖掘:适合处理GB级以下数据(大数据需结合Hadoop/Spark扩展)。
-
工业应用:客户分群、欺诈检测、文本分类等(需结合业务逻辑优化)。
2.2 Apache Spark MLlib 介绍
Apache Spark MLlib 是一个专为大规模数据处理设计的分布式机器学习库,作为 Apache Spark 生态系统的核心组件,它通过利用 Spark 的分布式计算框架,能够高效处理海量数据,并加速模型的训练和预测过程。官网:MLlib | Apache Spark
2.2.1 核心模块介绍
MLlib 的架构由多个核心模块组成,协同工作以简化大规模数据处理中的机器学习任务复杂性:
-
算法库:提供丰富的监督学习(如逻辑回归、决策树、随机森林)和无监督学习(如 K-Means 聚类、高斯混合模型)算法,支持分类、回归、聚类、降维等任务,并涵盖推荐系统(如基于交替最小二乘法的协同过滤)和特征工程功能。
-
管道机制(Pipelines):通过串联多个
Transformer(数据转换组件,如标准化、归一化)和Estimator(可训练模型,如逻辑回归、决策树),构建模块化的机器学习工作流,简化任务流程并支持复用。 -
数据类型:基于 Spark 的核心数据结构
RDD(弹性分布式数据集,提供容错和并行计算能力)和DataFrame(类似 SQL 表的高层次数据类型,支持模式化数据结构和 SQL 查询),其中DataFrame是当前主要支持的数据类型,能更好地与 Spark SQL 集成。
2.2.2 核心功能介绍
MLlib 核心功能如下:
-
算法支持:
-
分类:支持二分类和多分类任务,如逻辑回归、决策树、随机森林、朴素贝叶斯等。
-
回归:支持线性回归、岭回归、Lasso 回归等,用于预测连续值。
-
聚类:如 K-Means、高斯混合模型等,用于发现数据中的模式和相似性。
-
推荐系统:如基于交替最小二乘法的协同过滤算法,用于为用户推荐商品或内容。
-
降维:如主成分分析(PCA)、奇异值分解(SVD)等,用于降低数据维度。
-
-
特征处理:提供多种特征提取和转换方法,如 TF-IDF、Word2Vec、PCA 等,将原始数据转换为机器学习算法可处理的特征表示。
-
模型评估:提供丰富的评估指标工具,支持不同类型模型的性能评估:
-
分类模型:精度、召回率、F1 值、ROC 曲线等。
-
回归模型:均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。
-
聚类模型:轮廓系数、簇间距离等。
-
2.2.3 技术优势
MLlib 具备如下技术优势:
-
分布式计算能力:基于 Spark 的分布式计算框架,充分利用集群资源进行并行计算,大幅提升计算效率,尤其适合大规模数据集。
-
简洁易用的 API:提供简洁的 API 接口,支持 Scala、Java、Python 和 R 等多种编程语言,降低用户使用门槛。
-
可扩展性:用户可根据需求自定义算法和模型,并通过 Spark 的扩展机制将其集成到 MLlib 中。
-
与 Spark 生态无缝集成:与 Spark SQL、Spark Streaming 等组件无缝协作,支持复杂的数据处理和分析流程。
2.2.4 适用场景
在下面的一些场景中可以考虑使用MLlib :
-
分类任务:如垃圾邮件检测、情感分析、图像识别等。
-
回归任务:如房价预测、股票价格预测等。
-
聚类任务:如客户分群、市场细分、图像分割等。
-
推荐系统:如电商平台的个性化商品推荐、音视频网站的内容推荐等。
-
特征工程:如特征选择、特征提取、数据标准化等
2.3 EasyRec 介绍
EasyRec 是阿里巴巴开源的推荐系统框架,基于 TensorFlow 和 PyTorch 构建,提供模块化设计、分布式训练和在线预测等功能,适用于电商、音乐等领域,旨在简化推荐系统开发并提升推荐效果。
2.3.1 技术亮点
-
模块化设计:EasyRec 将推荐系统拆分为数据处理、特征工程、模型训练和在线预测等多个独立模块,用户可根据业务需求自由组合,减少代码复用,提升开发效率。
-
兼容主流深度学习框架:支持 TensorFlow 和 PyTorch 两大主流深度学习框架,满足不同开发者的技术偏好,降低技术切换成本。
-
高性能分布式训练:通过 horovod、TF-Replicator 等工具,EasyRec 提供高性能的分布式训练能力,支持大规模数据集和复杂模型训练,加速模型收敛,降低实验周期。
-
在线预测服务:EasyRec 内置在线预测服务,能够无缝对接到生产环境,提供低延迟的实时推荐,平滑从模型研发到业务上线的流程。
2.3.2 技术核心模块架构
EasyRec 核心模块架构如下:
-
数据处理层:支持多种数据输入方式,包括 MaxCompute、HDFS、CSV 文件等,满足不同数据源的需求。
-
特征工程层:提供丰富的特征类型支持,包括 IdFeature、RawFeature、TagFeature、SequenceFeature 以及 ComboFeature 等,满足不同业务场景的特征需求。
-
模型训练层:集成 DeepFM、DIN、MultiTower 及 DSSM 等经典推荐排序和召回算法,支持多任务学习、图神经网络等高级功能,满足不同业务场景的模型需求。
-
在线预测层:提供高性能的在线预测服务,支持模型增量更新、特征埋点等功能,满足实时推荐的需求。
2.3.3 技术优势
EasyRec 具备如下优势:
-
易用性:通过简洁的 API 设计,让推荐系统的开发变得简单,降低推荐系统开发的门槛。
-
灵活性:支持 TensorFlow 和 PyTorch,可按需选择,且模块化设计方便定制,满足不同业务场景的需求。
-
高效性:提供分布式训练和在线预测服务,加快模型迭代速度,提升推荐系统的性能。
-
全面性:覆盖推荐系统的全生命周期,从数据预处理到模型部署,提供一站式的解决方案。
2.3.4 适用场景
EasyRec 可广泛应用于电商、音乐、视频、新闻等各类需要个性化推荐的场景,无论是商品推荐、内容推送还是广告定向,都能帮助提升用户体验和业务转化率。
EasyRec 已经在阿里巴巴集团内部多个业务场景中得到广泛应用,如淘宝、天猫、优酷等,取得了显著的业务效果。同时,EasyRec 也积极与社区合作,推动推荐系统技术的发展和应用。
三、基于Weka 实现货品推荐上架操作案例
接下来将通过一个实际案例,适用Weka实现一个货品的推荐上架案例。
3.1 案例需求
完整的需求描述如下:
-
仓库有大货架,中型货架,还有小货架,三种货架类型;
-
每种货架能够容纳的货品尺寸,体积,重量各不相同;
-
对于需要上架的货品根据其尺寸、重量完成上架推荐;
3.2 前置准备
3.2.1 数据准备
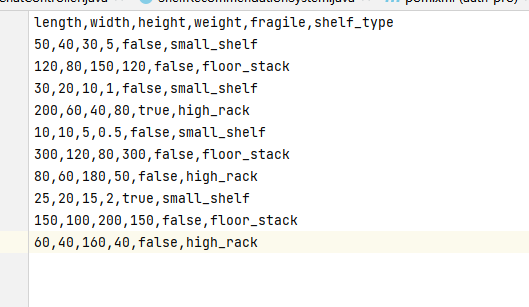
使用Weka 框架最后进行推荐的使用,需要导入样本数据,构建决策树,配合上述的需求,在本地提前准备一个CSV文件,里面有如下样本数据:
length,width,height,weight,fragile,shelf_type
50,40,30,5,false,small_shelf
120,80,150,120,false,floor_stack
30,20,10,1,false,small_shelf
200,60,40,80,true,high_rack
10,10,5,0.5,false,small_shelf
300,120,80,300,false,floor_stack
80,60,180,50,false,high_rack
25,20,15,2,true,small_shelf
150,100,200,150,false,floor_stack
60,40,160,40,false,high_rack3.2.2 导入核心依赖
创建一个springboot 工程,导入如下核心依赖:
<properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><satoken.version>1.37.0</satoken.version><spring-ai.version>1.0.0-M6</spring-ai.version><spring-ai-alibaba.version>1.0.0-M6.1</spring-ai-alibaba.version>
</properties><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.2</version><relativePath/>
</parent><dependencies><!-- For handling CSV files --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-csv</artifactId><version>1.9.0</version></dependency><dependency><groupId>nz.ac.waikato.cms.weka</groupId><artifactId>weka-stable</artifactId><version>3.8.6</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.83</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- MySQL连接驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>${spring-ai-alibaba.version}</version></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement><repositories><repository><name>Central Portal Snapshots</name><id>central-portal-snapshots</id><url>https://central.sonatype.com/repository/maven-snapshots/</url><releases><enabled>false</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>false</enabled></releases></repository>
</repositories>3.3 基于本地样本数据实现方案
基于上述的本地样本数据,完成一个基于Weka 机器学习框架的推荐上架的案例实现。
3.3.1 导入核心依赖
pom中导入Weka的依赖
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-csv</artifactId><version>1.9.0</version>
</dependency><dependency><groupId>nz.ac.waikato.cms.weka</groupId><artifactId>weka-stable</artifactId><version>3.8.6</version>
</dependency>3.3.2 添加本地样本数据
在本地的resources 目录下增加一个csv 样本文件,样本的数据如下:
3.3.3 完整的实现代码
完整的实现代码如下:
package com.congge.command.v3;import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;/*** 基于本地的训练文件样本数据进行预测*/
public class ShelfRecommendationSystemV3 {private J48 decisionTree;private Instances dataStructure;/*** 加载训练数据并构建模型*/public void trainModel(String csvFilePath) throws Exception {// 1. 加载CSV数据DataSource source = new DataSource(csvFilePath);Instances data = source.getDataSet();// 2. 设置类别属性(货架类型)if (data.classIndex() == -1) {data.setClassIndex(data.numAttributes() - 1);}// 3. 保存数据结构用于后续预测this.dataStructure = new Instances(data, 0);// 4. 构建决策树模型decisionTree = new J48();decisionTree.buildClassifier(data);System.out.println("模型训练完成!");}/*** 预测新货物的推荐货架类型*/public String predictShelfType(double length, double width, double height,double weight, boolean fragile) throws Exception {if (decisionTree == null || dataStructure == null) {throw new IllegalStateException("模型尚未训练,请先调用trainModel方法");}// 创建新实例weka.core.Instance instance = new weka.core.DenseInstance(6);instance.setDataset(dataStructure);// 设置属性值instance.setValue(0, length);instance.setValue(1, width);instance.setValue(2, height);instance.setValue(3, weight);instance.setValue(4, fragile ? "true" : "false");// 进行预测double prediction = decisionTree.classifyInstance(instance);return dataStructure.classAttribute().value((int) prediction);}/*** 评估模型准确率(使用训练数据简单评估)*/public void evaluateModel(String csvFilePath) throws Exception {DataSource source = new DataSource(csvFilePath);Instances data = source.getDataSet();if (data.classIndex() == -1) {data.setClassIndex(data.numAttributes() - 1);}// 简单评估(实际应用中应该使用交叉验证)weka.classifiers.Evaluation eval = new weka.classifiers.Evaluation(data);eval.evaluateModel(decisionTree, data);System.out.println("\n模型评估结果:");System.out.println(eval.toSummaryString());System.out.println(eval.toClassDetailsString());System.out.println(eval.toMatrixString());}public static void main(String[] args) {ShelfRecommendationSystemV3 system = new ShelfRecommendationSystemV3();try {// 1. 训练模型String csvPath = "data/shelf_data.csv";system.trainModel(csvPath);// 2. 评估模型(可选)system.evaluateModel(csvPath);// 3. 测试预测System.out.println("\n测试预测:");// 测试用例1: 小而轻的货物String recommendation1 = system.predictShelfType(30, 20, 10, 1, false);System.out.printf("货物(30x20x10cm, 1kg, 非易碎) 推荐货架: %s%n", recommendation1);// 测试用例2: 大而重的货物String recommendation2 = system.predictShelfType(200, 100, 180, 200, false);System.out.printf("货物(200x100x180cm, 200kg, 非易碎) 推荐货架: %s%n", recommendation2);// 测试用例3: 易碎的中等大小货物String recommendation3 = system.predictShelfType(60, 40, 30, 5, true);System.out.printf("货物(60x40x30cm, 5kg, 易碎) 推荐货架: %s%n", recommendation3);} catch (Exception e) {e.printStackTrace();}}
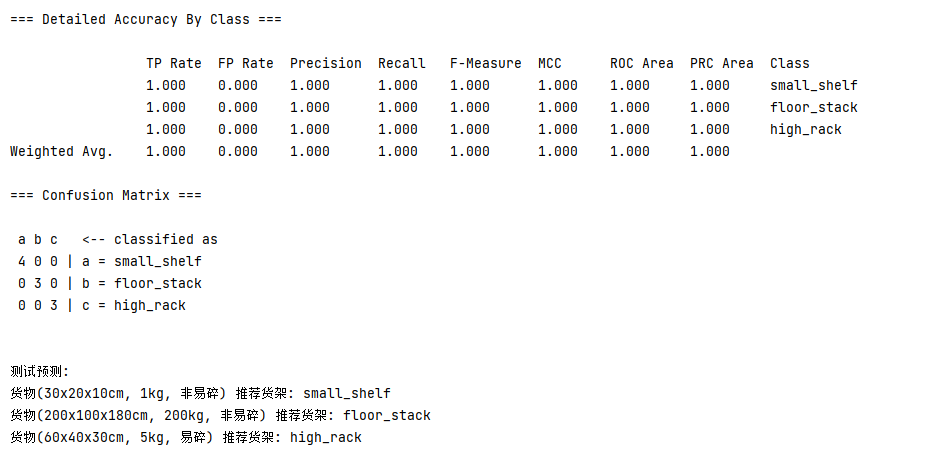
}运行一下,效果如下:
-
在控制台中,输出了完整的决策树结构;
-
同时结合样本数据,也给出了基于3组测试数据的推荐上架库位;
3.4 基于数据库的样本数据实现方案
仍然是基于Weka 机器学习框架,假如我们的样本数据存储在数据库的表中,下面看具体的实现
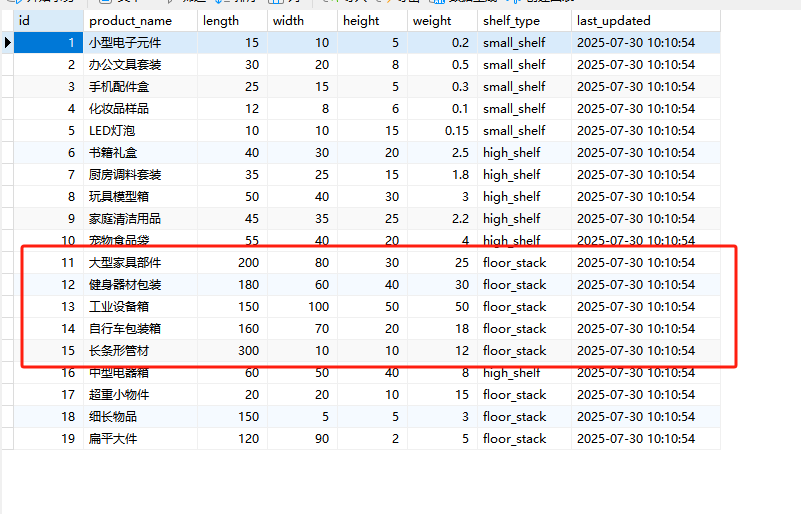
3.4.1 添加一张测试样本表
增加如下的样本数据测试表,并添加一些初始化数据
CREATE TABLE product_shelf_mapping (id INT AUTO_INCREMENT PRIMARY KEY,product_name VARCHAR(100),length DOUBLE NOT NULL COMMENT '长度(cm)',width DOUBLE NOT NULL COMMENT '宽度(cm)',height DOUBLE NOT NULL COMMENT '高度(cm)',weight DOUBLE NOT NULL COMMENT '重量(kg)',shelf_type ENUM('small_shelf', 'high_shelf', 'floor_stack') NOT NULL COMMENT '货架类型',last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;-- 清空表(测试时使用,生产环境请移除)
TRUNCATE TABLE product_shelf_mapping;-- 插入测试数据
INSERT INTO product_shelf_mapping (product_name, length, width, height, weight, shelf_type) VALUES
-- 小货架(体积小、重量轻)
('小型电子元件', 15, 10, 5, 0.2, 'small_shelf'),
('办公文具套装', 30, 20, 8, 0.5, 'small_shelf'),
('手机配件盒', 25, 15, 5, 0.3, 'small_shelf'),
('化妆品样品', 12, 8, 6, 0.1, 'small_shelf'),
('LED灯泡', 10, 10, 15, 0.15, 'small_shelf'),-- 高位货架(中等体积、中等重量,可堆叠)
('书籍礼盒', 40, 30, 20, 2.5, 'high_shelf'),
('厨房调料套装', 35, 25, 15, 1.8, 'high_shelf'),
('玩具模型箱', 50, 40, 30, 3.0, 'high_shelf'),
('家庭清洁用品', 45, 35, 25, 2.2, 'high_shelf'),
('宠物食品袋', 55, 40, 20, 4.0, 'high_shelf'),-- 地堆货架(超长、超重或异形货物)
('大型家具部件', 200, 80, 30, 25.0, 'floor_stack'),
('健身器材包装', 180, 60, 40, 30.0, 'floor_stack'),
('工业设备箱', 150, 100, 50, 50.0, 'floor_stack'),
('自行车包装箱', 160, 70, 20, 18.0, 'floor_stack'),
('长条形管材', 300, 10, 10, 12.0, 'floor_stack'),-- 边界值测试(接近分类阈值的货物)
('中型电器箱', 60, 50, 40, 8.0, 'high_shelf'), -- 接近地堆但重量稍轻
('超重小物件', 20, 20, 10, 15.0, 'floor_stack'), -- 重量大但体积小
('细长物品', 150, 5, 5, 3.0, 'floor_stack'), -- 超长但重量轻
('扁平大件', 120, 90, 2, 5.0, 'floor_stack'); -- 面积大但高度低3.4.2 导入依赖
除了上面的Weka 框架库,还需要引入mysql依赖
<!-- MySQL连接驱动 -->
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version>
</dependency>3.4.3 完整的实现代码
下面是基于mysql表作为样本数据的完整代码
package com.congge.command.v2;import lombok.Data;
import weka.classifiers.trees.J48;
import weka.core.*;import java.sql.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;/*** 基于数据库的样本数据进行预测*/
public class ShelfRecommendationSystem {// MySQL数据库配置private static final String DB_URL = "jdbc:mysql://rm-bp15bb46ti34x4glgdo.mysql.rds.aliyuncs.com:3306/gh_log";private static final String DB_USER = "root";private static final String DB_PASSWORD = "Dkf5381200";public static void main(String[] args) {try {// 1. 从MySQL加载训练数据List<Product> trainingData = loadTrainingDataFromMySQL();// 2. 转换为Weka Instances格式Instances instances = createInstances(trainingData);// 3. 训练决策树模型J48 tree = trainDecisionTree(instances);// 4. 测试模型testModel(tree, instances);// 5. 示例:对新产品进行货架推荐Product newProduct = new Product();newProduct.setLength(120);newProduct.setWidth(80);newProduct.setHeight(30);newProduct.setWeight(25);String recommendedShelf = recommendShelf(tree, newProduct);System.out.println("\n推荐货架类型: " + recommendedShelf);} catch (Exception e) {e.printStackTrace();}}/*** 从MySQL数据库加载训练数据*/private static List<Product> loadTrainingDataFromMySQL() throws SQLException {List<Product> products = new ArrayList<>();try (Connection conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD)) {String query = "SELECT length, width, height, weight, shelf_type FROM product_shelf_mapping";try (Statement stmt = conn.createStatement();ResultSet rs = stmt.executeQuery(query)) {while (rs.next()) {Product product = new Product();product.setLength(rs.getDouble("length"));product.setWidth(rs.getDouble("width"));product.setHeight(rs.getDouble("height"));product.setWeight(rs.getDouble("weight"));product.setShelfType(rs.getString("shelf_type"));products.add(product);}}}System.out.println("从MySQL加载了 " + products.size() + " 条训练数据");return products;}/*** 创建Weka Instances对象*/private static Instances createInstances(List<Product> products) {// 定义属性ArrayList<Attribute> attributes = new ArrayList<>();// 数值型属性:长、宽、高、重attributes.add(new Attribute("length"));attributes.add(new Attribute("width"));attributes.add(new Attribute("height"));attributes.add(new Attribute("weight"));// nominal属性:货架类型ArrayList<String> shelfTypes = new ArrayList<>();shelfTypes.add("small_shelf");shelfTypes.add("high_shelf");shelfTypes.add("floor_stack");attributes.add(new Attribute("shelf_type", shelfTypes));// 创建Instances对象Instances instances = new Instances("ProductShelfRelation", attributes, 0);instances.setClassIndex(instances.numAttributes() - 1); // 设置分类属性// 添加数据for (Product product : products) {double[] values = new double[instances.numAttributes()];values[0] = product.getLength();values[1] = product.getWidth();values[2] = product.getHeight();values[3] = product.getWeight();// 设置分类属性值switch (product.getShelfType()) {case "small_shelf": values[4] = 0; break;case "high_shelf": values[4] = 1; break;case "floor_stack": values[4] = 2; break;//default: values[4] = Instance.missingValue();default: values[4] = Utils.missingValue();}instances.add(new DenseInstance(1.0, values));}return instances;}/*** 训练决策树模型*/private static J48 trainDecisionTree(Instances instances) throws Exception {// 设置分类器选项String[] options = new String[1];options[0] = "-U"; // 使用未修剪的树J48 tree = new J48();tree.setOptions(options);// 训练模型tree.buildClassifier(instances);// 输出模型System.out.println("\n训练好的决策树模型:");System.out.println(tree);return tree;}/*** 测试模型准确率*/private static void testModel(J48 tree, Instances instances) throws Exception {// 随机划分训练集和测试集 (70%训练, 30%测试)instances.randomize(new Random(0));int trainSize = (int) Math.round(instances.numInstances() * 0.7);int testSize = instances.numInstances() - trainSize;Instances train = new Instances(instances, 0, trainSize);Instances test = new Instances(instances, trainSize, testSize);// 重新训练模型tree.buildClassifier(train);// 测试模型int correct = 0;for (int i = 0; i < test.numInstances(); i++) {Instance inst = test.instance(i);double predicted = tree.classifyInstance(inst);double actual = inst.classValue();if (predicted == actual) {correct++;}}double accuracy = (double) correct / test.numInstances() * 100;System.out.printf("\n模型准确率: %.2f%% (%d/%d)\n", accuracy, correct, test.numInstances());}/*** 为新产品推荐货架类型*/public static String recommendShelf(J48 tree, Product product) throws Exception {// 创建属性列表 (必须与训练数据相同)ArrayList<Attribute> attributes = new ArrayList<>();attributes.add(new Attribute("length"));attributes.add(new Attribute("width"));attributes.add(new Attribute("height"));attributes.add(new Attribute("weight"));ArrayList<String> shelfTypes = new ArrayList<>();shelfTypes.add("small_shelf");shelfTypes.add("high_shelf");shelfTypes.add("floor_stack");attributes.add(new Attribute("shelf_type", shelfTypes));// 创建Instances对象Instances instances = new Instances("Temp", attributes, 0);instances.setClassIndex(instances.numAttributes() - 1);// 创建新产品实例double[] values = new double[instances.numAttributes()];values[0] = product.getLength();values[1] = product.getWidth();values[2] = product.getHeight();values[3] = product.getWeight();//values[4] = Instance.missingValue(); // 分类属性设为缺失值values[4] = Utils.missingValue();instances.add(new DenseInstance(1.0, values));// 进行预测double prediction = tree.classifyInstance(instances.instance(0));// 返回预测结果return shelfTypes.get((int) prediction);}
}@Data
class Product {private double length;private double width;private double height;private double weight;private String shelfType;
}运行上面的代码做一下测试
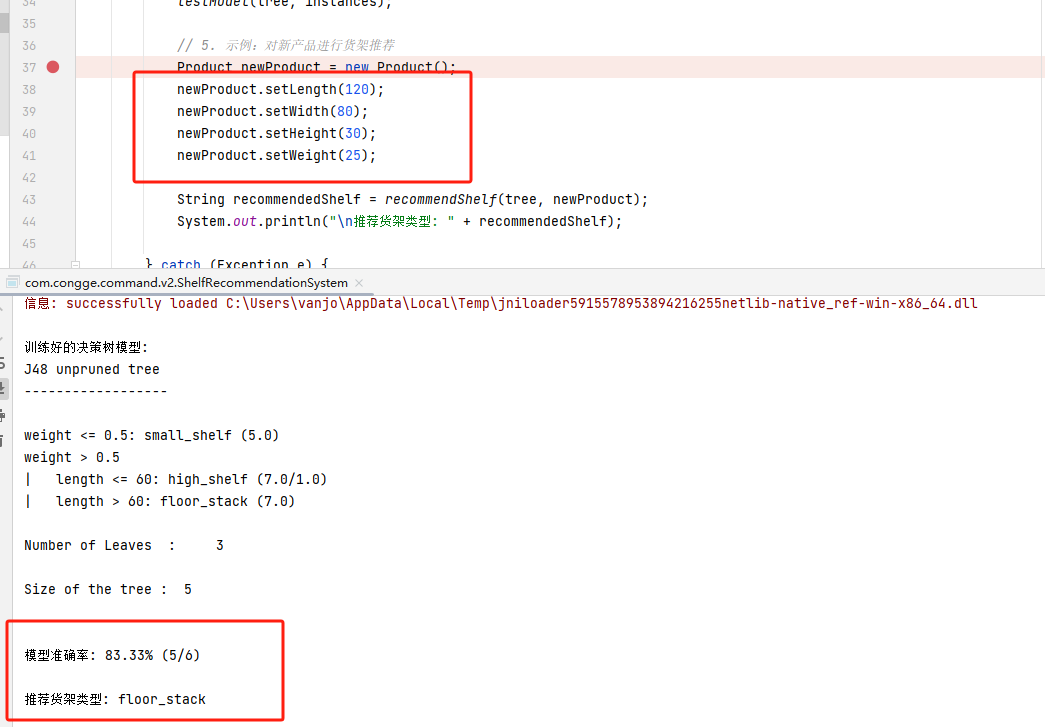
3.5 基于AI大模型实现方案
核心实现思路:
-
定义系统提示词
-
提示词中,参考的货架类型,需要提前根据实际业务需求+经验判断拟定;
-
体积+重量一起判断;
-
体积 = 长*宽*高
-
-
将用户的问题,代入到提示词中,让大模型给出推荐
3.5.1 添加配置信息
在配置文件中增加如下AI相关的配置信息
spring:# 增加ai的配置ai:dashscope:api-key: 个人apikeychat:options:model: qwen-max3.5.2 添加测试接口
增加一个测试接口,便于查看效果
package com.congge.command.v5;import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/client/ai")
public class ChatController {private final ChatClient chatClient;public ChatController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}//localhost:8082/client/ai/chat?message=今天北京的天气如何//localhost:8082/client/ai/chat?message=你是谁//localhost:8082/client/ai/chat?message=当前时间是多少@PostMapping("/chat")public String chat(@RequestBody Product product){Prompt prompt = new Prompt(new UserMessage(buildPrompt(product)));String content = chatClient.prompt(prompt).call().content();return content;}private static String buildPrompt(Product product) {return String.format("""你是一名仓库管理专家,需要根据商品尺寸和重量推荐合适的货架类型。货架类型定义:1. small_shelf: 体积小于5000cm³且重量小于1kg的商品2. high_shelf: 体积5000-60000cm³且重量1-10kg的商品3. floor_stack: 体积大于60000cm³或重量大于10kg或形状特殊的商品(如超长、超宽)商品信息:名称: %s尺寸: %.1fcm x %.1fcm x %.1fcm重量: %.2fkg体积: %.1fcm³密度: %.2fg/cm³请根据以上信息,只返回推荐货架类型,格式为:推荐货架类型: [类型]""",product.getProductName(),product.getLength(),product.getWidth(),product.getHeight(),product.getWeight(),product.getVolume(),product.getDensity());}}Product 实体类
package com.congge.command.v5;import lombok.Data;@Data
public class Product {private Long id;private String productName;private double length;private double width;private double height;private double weight;private String shelfType;// 计算体积public double getVolume() {return length * width * height;}// 计算密度public double getDensity() {return weight / getVolume();}
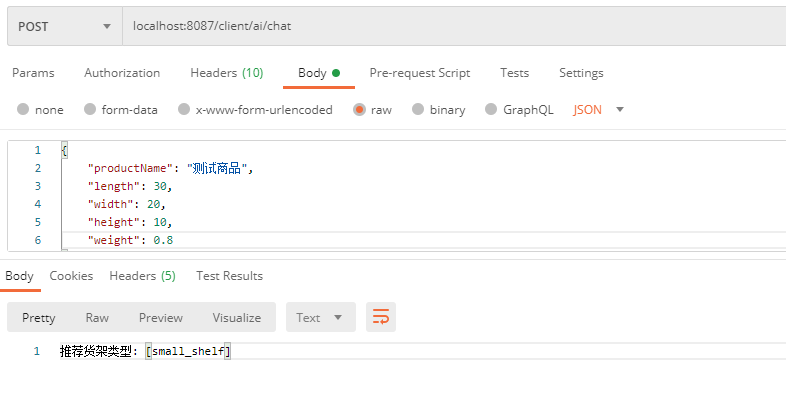
}3.5.3 效果测试
启动工程后,调用下接口,这里随机给一组产品的长宽高进行测试,结果如下:
四、写在文末
本文通过较大的篇幅详细介绍了基于Java技术栈,整合机器学习算法框架Weka结合一个实际案例实现一个货品上架的功能,希望对看到的同学有用哦,本篇到此结束,感谢观看。