LinuxC++项目开发日志——基于正倒排索引的boost搜索引擎(4——通过jsoncpp库建立搜索模块)
基于正倒排索引的boost搜索引擎
- jsoncpp库
- jsonpp 库介绍
- 下载与安装
- 1. 包管理器安装(推荐)
- 2. 源码编译安装
- 常用用法示例
- 1. 解析 JSON 字符串
- 2. 生成 JSON 数据
- 3. 从文件读取和写入 JSON
- 4. 编译方法
- 注意事项
- 搜索模块实现流程
- 一、搜索模块的核心定位与工作流程
- 二、核心数据结构设计
- 1. 文档汇总结构:DocSumup_t
- 2. 搜索核心类:Search
- 三、关键功能实现详解
- 1. 初始化:索引实例的单例加载
- 2. 核心搜索接口:SearchBy ()
- 3. 文档摘要提取:ExtractDesc ()
- 四、Jsoncpp 的关键用法总结
- 五、模块测试与效果验证
- 1. 编译链接
- 2. 测试结果示例
- 六、模块代码
- 其它更新模块
- Index.hpp
- Util.hpp
- main.cc
jsoncpp库
jsonpp 库介绍
JSONCpp 是一个用于处理 JSON 数据的 C++ 开源库,它提供了解析、生成和操作 JSON 数据的功能。主要特点包括:
- 支持 JSON 数据的解析(从字符串或文件)
- 支持 JSON 数据的生成(到字符串或文件)
- 提供简洁的 API 用于操作 JSON 数据(增删改查)
- 跨平台,可在 Linux、Windows 等系统上使用
下载与安装
在 Linux 系统中,可以通过包管理器或源码编译两种方式安装:
1. 包管理器安装(推荐)
对于 Ubuntu/Debian 系统:
sudo apt-get update
sudo apt-get install libjsoncpp-dev
对于 Fedora/RHEL 系统:
sudo dnf install jsoncpp-devel
2. 源码编译安装
# 克隆源码仓库
git clone https://github.com/open-source-parsers/jsoncpp.git
cd jsoncpp# 创建构建目录
mkdir build && cd build# 编译安装
cmake ..
make
sudo make install
常用用法示例
下面是 JSONCpp 的一些常见用法示例:
1. 解析 JSON 字符串
#include <json/json.h>
#include <iostream>
#include <string>int main() {std::string jsonStr = "{\"name\":\"John\", \"age\":30, \"isStudent\":false}";// 创建解析器Json::Reader reader;Json::Value root;// 解析 JSON 字符串if (reader.parse(jsonStr, root)) {// 读取数据std::string name = root["name"].asString();int age = root["age"].asInt();bool isStudent = root["isStudent"].asBool();std::cout << "Name: " << name << std::endl;std::cout << "Age: " << age << std::endl;std::cout << "Is Student: " << std::boolalpha << isStudent << std::endl;} else {std::cerr << "Failed to parse JSON: " << reader.getFormattedErrorMessages() << std::endl;return 1;}return 0;
}
2. 生成 JSON 数据
#include <json/json.h>
#include <iostream>
#include <string>int main() {// 创建 JSON 对象Json::Value root;// 添加基本类型数据root["name"] = "Alice";root["age"] = 25;root["scores"] = Json::Value(Json::arrayValue);root["scores"].append(90);root["scores"].append(85);root["scores"].append(95);// 转换为字符串Json::StyledWriter writer; // 带格式的输出std::string jsonStr = writer.write(root);std::cout << "Generated JSON:" << std::endl;std::cout << jsonStr << std::endl;return 0;
}
3. 从文件读取和写入 JSON
#include <json/json.h>
#include <fstream>
#include <iostream>// 从文件读取 JSON
bool readJsonFromFile(const std::string& filename, Json::Value& root) {std::ifstream ifs(filename);if (!ifs.is_open()) {std::cerr << "Failed to open file: " << filename << std::endl;return false;}Json::Reader reader;if (!reader.parse(ifs, root)) {std::cerr << "Failed to parse JSON file: " << reader.getFormattedErrorMessages() << std::endl;return false;}return true;
}// 写入 JSON 到文件
bool writeJsonToFile(const std::string& filename, const Json::Value& root) {std::ofstream ofs(filename);if (!ofs.is_open()) {std::cerr << "Failed to open file: " << filename << std::endl;return false;}Json::StyledWriter writer;ofs << writer.write(root);return true;
}int main() {Json::Value data;// 构建JSON数据data["version"] = "1.0";data["settings"]["theme"] = "dark";data["settings"]["fontSize"] = 14;// 写入文件if (writeJsonToFile("config.json", data)) {std::cout << "JSON data written to config.json" << std::endl;}// 从文件读取Json::Value readData;if (readJsonFromFile("config.json", readData)) {std::cout << "Read from file - Theme: " << readData["settings"]["theme"].asString() << std::endl;}return 0;
}
4. 编译方法
编译使用 JSONCpp 的程序时,需要链接 jsoncpp 库:
g++ your_program.cpp -o your_program -ljsoncpp
注意事项
JSONCpp 有两种 API 风格:旧版的 Json::Reader/Json::Writer 和新版的 Json::CharReader/Json::StreamWriter
搜索模块实现流程
搜索模块是连接用户查询与索引数据的核心桥梁。它需要接收用户输入的关键词,借助之前构建的正倒排索引完成数据检索、权重排序,最终以友好的格式返回结果。本段将详细介绍如何基于 Jsoncpp 库,实现一个高效、可扩展的搜索模块,完成搜索引擎查询流程的闭环。
一、搜索模块的核心定位与工作流程
在整个 Boost 搜索引擎架构中,搜索模块的核心作用是 “翻译” 用户需求:将用户输入的自然语言关键词,转化为对索引数据的查询指令,再将查询到的原始数据(文档 ID、权重、内容等)封装成标准化的 JSON 格式返回。其完整工作流程可分为以下 5 个步骤:
- 关键词分词:调用分词工具(如 Jieba)将用户输入的长关键词拆分为多个独立的检索词(如 “boost 搜索引擎” 拆分为 “boost”“搜索引擎”);
- 倒排索引查询:根据每个检索词,查询倒排索引表,获取包含该词的所有文档 ID 及对应权重;
- 文档权重聚合:对同一文档的多个检索词权重进行累加,得到文档的总相关性权重;
- 结果排序:按总权重降序排序(权重相同则按文档 ID 升序),确保相关性最高的文档优先返回;
- 结果封装:通过 Jsoncpp 库将文档的 ID、权重、URL、标题、摘要等信息封装为 JSON 字符串,便于前端解析展示。
二、核心数据结构设计
为了高效管理检索过程中的中间数据和最终结果,设计了两个关键数据结构:DocSumup_t(文档汇总结构)和Search(搜索核心类),分别负责 “临时存储文档检索信息” 和 “实现完整搜索逻辑”。
1. 文档汇总结构:DocSumup_t
该结构体用于暂存单个文档的检索结果,包括文档 ID、总权重、包含的检索词列表,是连接倒排索引查询与结果排序的核心载体。
// 查找关键词文档归总
typedef struct DocSumup
{size_t doc_id_ = 0; // 文档唯一ID(与正排索引关联)size_t weight_ = 0; // 文档总权重(多个检索词权重累加)std::vector<std::string> words_; // 文档包含的所有检索词列表
} DocSumup_t;
2. 搜索核心类:Search
Search类是搜索模块的入口,通过组合正倒排索引实例(ns_index::Index),封装了从 “分词” 到 “JSON 返回” 的全流程逻辑。其核心成员与职责如下:
| 成员变量 | 类型 | 核心职责 |
|---|---|---|
| root | Json::Value | 存储最终 JSON 结果的根节点 |
| index | ns_index::Index* | 正倒排索引实例(单例模式,避免重复构建) |
| 成员函数 | 功能 | 核心职责 |
|---|---|---|
| Search() | 构造函数 | 初始化索引实例,加载正倒排索引数据 |
| SearchBy() | 核心搜索接口 | 实现分词、查询、排序、JSON 封装全流程 |
| ExtractDesc() | 私有辅助函数 | 从文档内容中提取包含检索词的摘要 |
三、关键功能实现详解
1. 初始化:索引实例的单例加载
在Search类的构造函数中,我们通过单例模式获取ns_index::Index实例,并调用BulidIndex()加载之前构建好的正倒排索引数据。
这样做的好处是避免重复加载索引(索引数据通常较大,重复加载会浪费内存和时间),确保整个程序生命周期内索引只加载一次。
Search() : index(ns_index::Index::GetInstance())
{index->BulidIndex(); // 加载正倒排索引(从磁盘或内存)
}
2. 核心搜索接口:SearchBy ()
SearchBy()是搜索模块的对外接口,接收用户关键词和输出 JSON 字符串的引用,返回 “是否查询成功” 的布尔值。其内部逻辑可拆解为 4 个关键步骤:
步骤 1:关键词分词
调用工具类ns_util::JiebaUtile的CutPhrase方法,将用户输入的关键词拆分为多个检索词。例如,用户输入 “linux jsoncpp 使用”,会被拆分为[“linux”, “jsoncpp”, “使用”]。
// 分词:将关键词拆分为独立检索词
std::vector<std::string> Segmentation;
ns_util::JiebaUtile::CutPhrase(keywords, Segmentation);
步骤 2:倒排索引查询与权重聚合
遍历每个检索词,通过index->QueryByWord(word)查询倒排索引表,获取包含该词的所有文档(InvertedElem)。随后用哈希表(doc_map)按文档 ID 聚合权重 —— 同一文档的多个检索词权重累加,同时记录文档包含的检索词。
这里使用哈希表的原因是快速按文档 ID 去重:哈希表的键为文档 ID,值为DocSumup_t,可确保同一文档只被处理一次,避免重复累加权重。
std::unordered_map<size_t, DocSumup_t> doc_map; // 按文档ID聚合结果
for(auto& word : Segmentation)
{// 查询当前检索词的倒排索引列表ns_index::InvertedList* list = index->QueryByWord(word);if(list == nullptr){Log(LogModule::DEBUG) << word << "-not find!"; // 检索词无匹配文档continue;}// 遍历倒排索引,聚合文档权重for(ns_index::InvertedElem e : *list){doc_map[e.doc_id_].doc_id_ = e.doc_id_; // 记录文档IDdoc_map[e.doc_id_].weight_ += e.weight_; // 累加权重doc_map[e.doc_id_].words_.push_back(e.word_); // 记录检索词}
}
步骤 3:结果排序
将哈希表中的DocSumup_t数据转移到向量(inverted_elem_all)中,再通过std::sort按 “权重降序、ID 升序” 排序。这样能确保相关性最高的文档排在最前面,同时避免权重相同时结果顺序混乱。
// 哈希表数据转移到向量(便于排序)
std::vector<DocSumup_t> inverted_elem_all;
for(auto& e : doc_map)
{inverted_elem_all.push_back(std::move(e.second)); // 移动语义,减少拷贝开销
}// 排序:权重降序,权重相同则ID升序
std::sort(inverted_elem_all.begin(), inverted_elem_all.end()
,[](DocSumup_t i1, DocSumup_t i2)-> bool{return i1.weight_ == i2.weight_ ? i1.doc_id_ < i2.doc_id_ : i1.weight_ > i2.weight_;
});
步骤 4:JSON 结果封装
1遍历排序后的文档列表,通过 Jsoncpp 库构建 JSON 结构:
对每个文档,创建Json::Value临时节点(tempvalue);
2调用index->QueryById(e.doc_id_)查询正排索引,获取文档的 URL、标题、内容;
3调用ExtractDesc()提取文档摘要(包含检索词的片段);
4将doc_id、weight、url、title、desc等字段存入临时节点,并添加到 JSON 根节点(root);
5最后通过Json::StyledWriter将根节点转换为格式化的 JSON 字符串,存入out参数返回。
// 写入json串
for(DocSumup_t& e : inverted_elem_all)
{Json::Value tempvalue;tempvalue["doc_id"] = e.doc_id_; // 文档IDtempvalue["weight"] = e.weight_; // 文档总权重// 查询正排索引,获取文档详细信息ns_index::Forword_t* ft = index->QueryById(e.doc_id_);if(!ft){Log(DEBUG) << e.doc_id_ << "-id not find!";continue;}tempvalue["url"] = ft->url_; // 文档URLtempvalue["title"] = ft->title_; // 文档标题tempvalue["desc"] = ExtractDesc(ft->content_, e.words_[0]); // 文档摘要root.append(tempvalue); // 临时节点添加到根节点
}// JSON格式化并输出
Json::StyledWriter writer;
out = writer.write(root);
3. 文档摘要提取:ExtractDesc ()
用户不需要查看完整文档内容,因此我们需要从文档中提取包含检索词的片段作为摘要,提升阅读效率。ExtractDesc()函数的实现逻辑如下:
忽略大小写查找检索词:使用std::search结合自定义谓词(tolower(a) == tolower(b)),在文档内容中找到检索词的位置; 控制摘要长度:以检索词为中心,向前截取 50 个字符、向后截取 100 个字符(避免摘要过长或过短);
边界处理:若检索词靠近文档开头 / 结尾,从文档起始 / 结尾开始截取,避免数组越界。
std::string ExtractDesc(std::string& content, std::string word)
{// 忽略大小写查找检索词auto it = std::search(content.begin(),content.end(),word.begin(),word.end(),[](char a, char b)->bool{return std::tolower(a) == std::tolower(b);});if(it == content.end()) // 未找到检索词(理论上不会发生){Log(LogModule::DEBUG) << "ExtractDesc fail!";return "NONE!";}const int pre_step = 50; // 向前截取长度const int back_step = 100;// 向后截取长度int pos = it - content.begin(); // 检索词在文档中的位置// 边界处理:避免起始位置为负数int start = pos - pre_step > 0 ? pos - pre_step : 0;// 边界处理:避免结束位置超过文档长度int end = pos + back_step >= content.size() ? content.size() - 1 : pos + back_step;return content.substr(start, end - start) + std::string("..."); // 拼接省略号
}
四、Jsoncpp 的关键用法总结
在本模块中,Jsoncpp 主要用于 “构建 JSON 结构” 和 “格式化 JSON 字符串”,核心 API 用法如下:
| 功能需求 | Jsoncpp API | 示例代码 |
|---|---|---|
| 创建 JSON 节点 | Json::Value | Json::Value tempvalue; |
| 为节点设置键值对 | 重载[]运算符 + 直接赋值 | tempvalue[“url”] = ft->url_; |
| 向数组节点添加元素 | Json::Value::append() | root.append(tempvalue); |
| 格式化 JSON 字符串(带缩进) | Json::StyledWriter::write() | out = writer.write(root); |
| 格式化 JSON 字符串(紧凑) | Json::FastWriter::write() | Json::FastWriter writer; out = writer.write(root); |
五、模块测试与效果验证
1. 编译链接
由于代码依赖 Jsoncpp 库,编译时需通过-ljsoncpp链接库文件,示例 Makefile 如下:
# 编译器设置
CXX := g++
CXXFLAGS := -std=c++17
LDFLAGS :=
LIBS := -lboost_filesystem -lboost_system -ljsoncpp# 目录设置
SRC_DIR := .
BUILD_DIR := build
TARGET := main# 自动查找源文件
SRCS := $(wildcard $(SRC_DIR)/*.cc)
OBJS := $(SRCS:$(SRC_DIR)/%.cc=$(BUILD_DIR)/%.o)
DEPS := $(OBJS:.o=.d)# 确保头文件依赖被包含
-include $(DEPS)# 默认目标
all: $(BUILD_DIR) $(TARGET)# 创建构建目录
$(BUILD_DIR):@mkdir -p $(BUILD_DIR)# 链接目标文件生成可执行文件
$(TARGET): $(OBJS)$(CXX) $(OBJS) -o $@ $(LDFLAGS) $(LIBS)@echo "✅ 构建完成: $(TARGET)"# 编译每个.cc文件为.o文件
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.cc$(CXX) $(CXXFLAGS) -MMD -MP -c $< -o $@# 清理构建文件
clean:rm -rf $(BUILD_DIR) $(TARGET)@echo "🧹 清理完成"# 重新构建
rebuild: clean all# 显示项目信息
info:@echo "📁 源文件: $(SRCS)"@echo "📦 目标文件: $(OBJS)"@echo "🎯 最终目标: $(TARGET)"# 伪目标
.PHONY: all clean rebuild info# 防止与同名文件冲突
.PRECIOUS: $(OBJS)
2. 测试结果示例
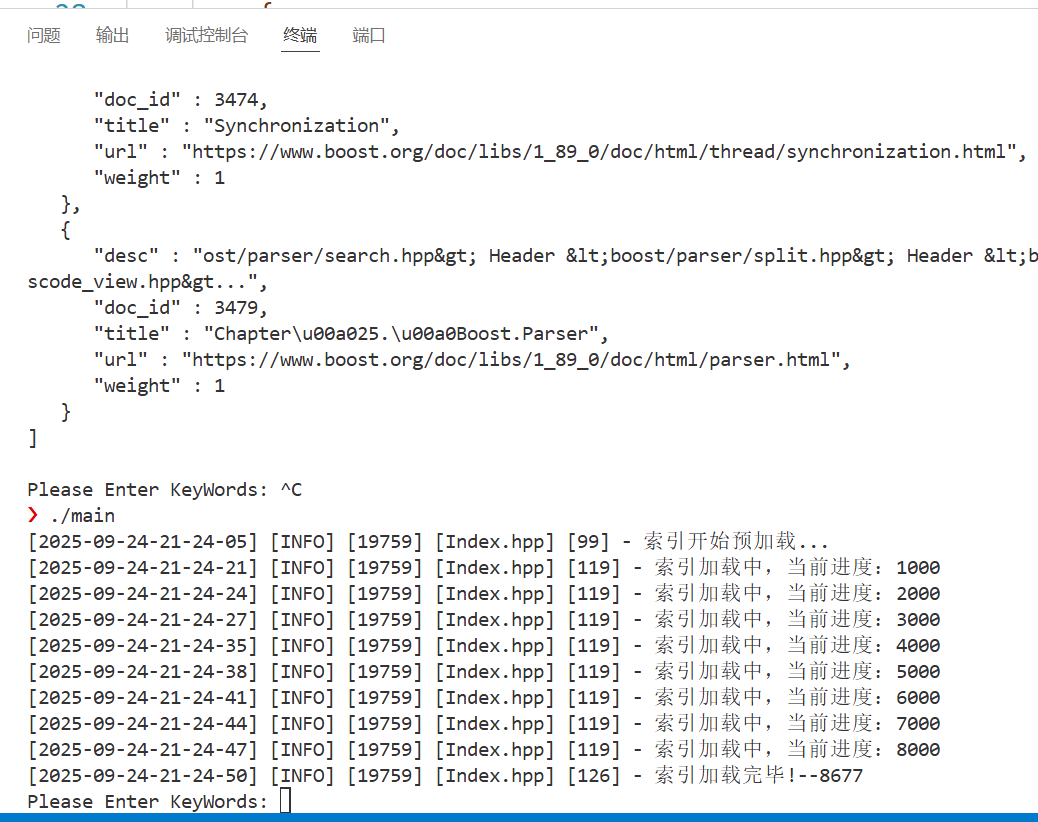
若用户输入关键词后,搜索模块返回的 JSON 结果如下(格式化后):
[{"desc" : "deadlock. Programs often deal with such issues by splitting different kinds of work between different executors. ...","doc_id" : 3474,"title" : "Synchronization","url" : "https://www.boost.org/doc/libs/1_89_0/doc/html/thread/synchronization.html","weight" : 1},{"desc" : "ost/parser/search.hpp> Header <boost/parser/split.hpp> Header <boost/parser/subrange.hpp> Header <boost/parser/transcode_view.hpp>...","doc_id" : 3479,"title" : "Chapter\u00a025.\u00a0Boost.Parser","url" : "https://www.boost.org/doc/libs/1_89_0/doc/html/parser.html","weight" : 1}
]
测试搜索模块:
六、模块代码
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include "Index.hpp"
#include <algorithm>
#include <cctype>
#include <cstddef>
#include <cstdio>
#include <ctime>
#include <jsoncpp/json/json.h>
#include <string>
#include <unistd.h>
#include <unordered_map>
#include <vector>namespace ns_search
{//查找关键词文档归总typedef struct DocSumup{size_t doc_id_ = 0;size_t weight_ = 0;std::vector<std::string> words_;}DocSumup_t;class Search : NonCopyable{public:Search() : index(ns_index::Index::GetInstance()){index->BulidIndex();}bool SearchBy(std::string keywords, std::string& out){//分词std::vector<std::string> Segmentation;ns_util::JiebaUtile::CutPhrase(keywords, Segmentation);//查找std::vector<DocSumup_t> inverted_elem_all;std::unordered_map<size_t, DocSumup_t> doc_map;//debug// for(auto& e : Segmentation)// {// cout << e << " - " ;// }cout << endl;//debugfor(auto& word : Segmentation){static size_t t = 0;ns_index::InvertedList* list = index->QueryByWord(word);if(list == nullptr){Log(LogModule::DEBUG) << word << "-not find!";//sleep(1);continue;}//cout << t << "次循环," << word << "-找到" << endl;for(ns_index::InvertedElem e : *list){doc_map[e.doc_id_].doc_id_ = e.doc_id_;doc_map[e.doc_id_].weight_ += e.weight_;doc_map[e.doc_id_].words_.push_back(e.word_);}}//哈稀表的内容插入整体数组for(auto& e : doc_map){inverted_elem_all.push_back(std::move(e.second));}//判断是否找到if(inverted_elem_all.empty()){Log(LogModule::INFO) << keywords << " Not Find!";return false;}//权重排序std::sort(inverted_elem_all.begin(), inverted_elem_all.end(),[](DocSumup_t i1, DocSumup_t i2)-> bool{return i1.weight_ == i2.weight_ ? i1.doc_id_ < i2.doc_id_ : i1.weight_ > i2.weight_;});//写入json串for(DocSumup_t& e : inverted_elem_all){Json::Value tempvalue;tempvalue["doc_id"] = e.doc_id_;tempvalue["weight"] = e.weight_;ns_index::Forword_t* ft = index->QueryById(e.doc_id_);if(!ft){Log(DEBUG) << e.doc_id_ << "-id not find!";//sleep(1);continue;}tempvalue["url"] = ft->url_;tempvalue["title"] = ft->title_;tempvalue["desc"] = ExtractDesc(ft->content_, e.words_[0]);root.append(tempvalue);}//写入字符串带出参数Json::StyledWriter writer;out = writer.write(root);return true;}private:std::string ExtractDesc(std::string& content, std::string word){auto it = std::search(content.begin(),content.end(),word.begin(),word.end(),[](char a, char b)->bool{return std::tolower(a) == std::tolower(b);});if(it == content.end()){Log(LogModule::DEBUG) << "ExtractDesc fail!";return "NONE!";}const int pre_step = 50;const int back_step = 100;int pos = it - content.begin();int start = pos - pre_step > 0 ? pos - pre_step : 0;int end = pos + back_step >= content.size() ? content.size() - 1 : pos + back_step;return content.substr(start, end - start) + std::string("...");}public:~Search() = default;private:Json::Value root;ns_index::Index* index;};
};
其它更新模块
Index.hpp
#pragma once
#include "Log.hpp"
#include "Util.hpp"
#include "common.h"
#include <boost/algorithm/string/case_conv.hpp>
#include <cstddef>
#include <cstring>
#include <fstream>
#include <string>
#include <unistd.h>
#include <unordered_map>
#include <utility>
#include <vector>namespace ns_index
{//正排索引typedef struct ForwordElem{std::string title_;std::string content_;std::string url_;size_t doc_id_ = 0;void Set(std::string title, std::string content, std::string url, size_t doc_id){title_ = title;content_ = content;url_ = url;doc_id_ = doc_id;}}Forword_t;typedef struct InvertedElem{size_t doc_id_ = 0;std::string word_;size_t weight_ = 0;void Set(size_t doc_id, std::string word, size_t weight){doc_id_ = doc_id;word_ = word;weight_ = weight;}}Inverted_t;typedef std::vector<Inverted_t> InvertedList;class Index : public NonCopyable{private:Index() = default;public:static Index* GetInstance(){static Index index;return &index;}public:Forword_t* QueryById(size_t id){if(id < 0 || id >= Forword_Index_.size()){Log(LogModule::DEBUG) << "id invalid!";return nullptr;}return &Forword_Index_[id];}InvertedList* QueryByWord(std::string word){auto it = Inverted_Index_.find(word);if(it == Inverted_Index_.end()){Log(LogModule::DEBUG) << word << " find fail!";return nullptr;}return &it->second;}size_t count = 0;bool BulidIndex(){if(isInit_)return false;size_t estimated_doc = 10000;size_t estimeted_words = 100000;Forword_Index_.reserve(estimated_doc);Inverted_Index_.reserve(estimeted_words);std::ifstream in(Tragetfile, std::ios::binary | std::ios::in);if(!in.is_open()){Log(LogModule::ERROR) << "Targetfile open fail!BulidIndex fail!";return false;}Log(LogModule::INFO) << "索引开始预加载...";std::string singlefile;while (std::getline(in, singlefile)){bool b = BuildForwordIndex(singlefile);if(!b){Log(LogModule::DEBUG) << "Build Forword Index Error!";continue;}b = BuildInvertedIndex(Forword_Index_.size() - 1);if(!b){Log(LogModule::DEBUG) << "Build Inverted Index Error!";continue;}count++;if(count % 1000 == 0){Log(LogModule::INFO) << "索引加载中,当前进度:" << count;//debug//break;}}in.close();isInit_ = true;Log(LogModule::INFO) << "索引加载完毕!--" << count;return true;}~Index() = default;private:typedef struct DocCount{size_t title_cnt_ = 0;size_t content_cnt_ = 0;}DocCount_t;bool BuildForwordIndex(std::string& singlefile){sepfile.clear();bool b = ns_util::JiebaUtile::CutDoc(singlefile, sepfile);if(!b)return false;// if(count == 764)// {// Log(LogModule::DEBUG) << "Index Url: " << sepfile[2]; // }if(sepfile.size() != 3){Log(LogModule::DEBUG) << "Segmentation fail!";return false;}Forword_t ft;ft.Set(std::move(sepfile[0]), std::move(sepfile[1]), std::move(sepfile[2]), Forword_Index_.size());// if(count == 764)// {// Log(LogModule::DEBUG) << "Index Url: " << ft.url_; // }Forword_Index_.push_back(std::move(ft));return true;}bool BuildInvertedIndex(size_t findex){Forword_t ft = Forword_Index_[findex];std::unordered_map<std::string, DocCount_t> map_s;titlesegmentation.clear();ns_util::JiebaUtile::CutPhrase(ft.title_, titlesegmentation);for(auto& s : titlesegmentation){boost::to_lower(s);map_s[s].title_cnt_++;}contentsegmentation.clear();ns_util::JiebaUtile::CutPhrase(ft.content_, contentsegmentation);for(auto& s : contentsegmentation){boost::to_lower(s);map_s[s].content_cnt_++;//cout << s << "--";// if(strcmp(s.c_str(), "people") == 0)// {// Log(LogModule::DEBUG) << "意外的people!";// cout << ft.content_ << "------------end!";// sleep(100);// }}const int X = 10;const int Y = 1;for(auto& p : map_s){Inverted_t it;it.Set(findex, p.first, p.second.title_cnt_ * X + p.second.content_cnt_ * Y);InvertedList& list = Inverted_Index_[p.first];list.push_back(std::move(it));}return true;}private:std::vector<Forword_t> Forword_Index_;std::unordered_map<std::string, InvertedList> Inverted_Index_;bool isInit_ = false;//内存复用,优化时间std::vector<std::string> sepfile;std::vector<std::string> titlesegmentation;std::vector<std::string> contentsegmentation;};
};
Util.hpp
#pragma once
#include "Log.hpp"
#include "common.h"
#include "cppjieba/Jieba.hpp"
#include <boost/algorithm/string/classification.hpp>
#include <boost/algorithm/string/split.hpp>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
namespace ns_util
{class FileUtil : public NonCopyable{public:static bool ReadFile(std::string path, std::string* out){std::fstream in(path, std::ios::binary | std::ios::in);if(!in.is_open()){Log(LogModule::DEBUG) << "file-" << path << "open fail!";return false;}std::stringstream ss;ss << in.rdbuf();*out = ss.str();in.close();return true;}};class JiebaUtile : public NonCopyable{public:static cppjieba::Jieba* GetInstace(){static cppjieba::Jieba jieba_(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);return &jieba_;}static bool CutPhrase(std::string& src, std::vector<std::string>& out){try{GetInstace()->CutForSearch(src, out, true);}catch (const std::exception& e){Log(LogModule::ERROR) << "CutString Error!" << e.what();return false;}catch (...){Log(ERROR) << "Unknow Error!";return false;}return true;}static bool CutDoc(std::string& filestr, std::vector<std::string>& out){try{boost::split(out, filestr, boost::is_any_of("\3"));}catch (const std::exception& e){Log(LogModule::ERROR) << "std Error-" << e.what();return false;} catch(...){Log(LogModule::ERROR) << "UnKnown Error!";return false;}return true;}private:JiebaUtile() = default;~JiebaUtile() = default;};};
main.cc
#include "Log.hpp"
#include "common.h"
#include "Parser.h"
#include "Search.hpp"
#include <cstdio>
#include <cstring>
#include <string>
const bool INIT = false;int main()
{if(INIT){Parser parser(Orignaldir, Tragetfile);parser.Init();}ns_search::Search search;while(true){char buffer[1024];std::string out;cout << "Please Enter KeyWords: ";std::fgets(buffer, sizeof(buffer)-1, stdin);if(strlen(buffer) > 0 && buffer[strlen(buffer) - 1] == '\n'){buffer[strlen(buffer) - 1] = '\0';}if(strcmp(buffer, "QUIT!") == 0){Log(LogModule::DEBUG) << "quit main!";break;}search.SearchBy(std::string(buffer), out);cout << out << endl;}return 0;
}