Python高效合并Excel多Sheet工作表,告别繁琐手动操作
Python高效合并Excel多Sheet工作表,告别繁琐手动操作
在日常办公中,我们经常会遇到一个Excel文件里包含多个工作表的情况,比如按日期、按部门分类的数据。如果要对这些数据进行汇总分析,手动复制粘贴不仅耗时,还容易出现疏漏。
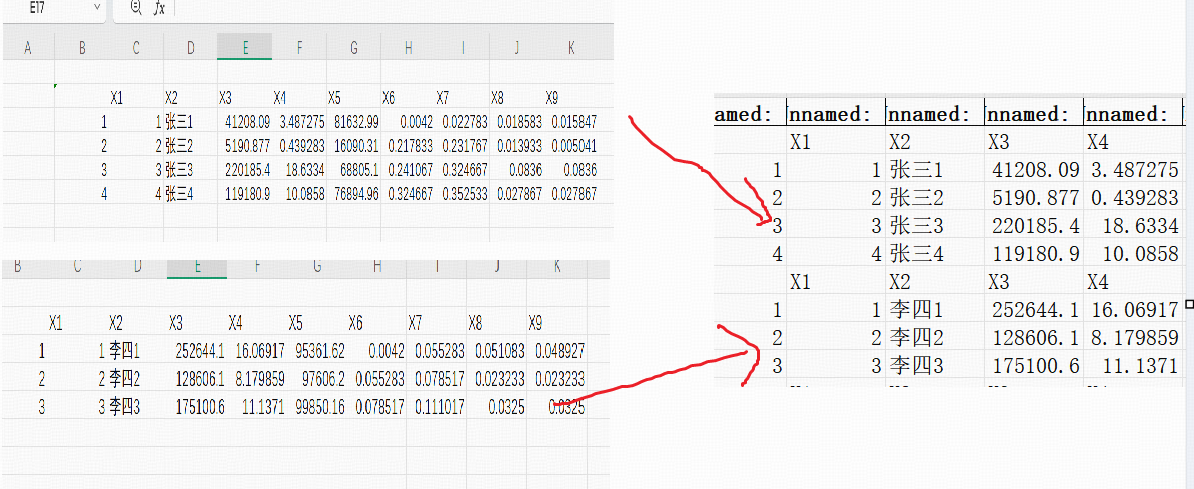
今天就给大家分享一个实用的Python代码,能一键合并Excel中的所有工作表,让数据处理效率大幅提升。
完整代码
以下是实现该功能的完整代码,大家可以直接复制使用:
import pandas as pd
import osdef merge_excel_sheets(excel_file_path, output_file_path=None):"""读取 Excel 文件中的所有 sheet 页数据并汇总到一个 DataFrame 中参数:excel_file_path: Excel 文件路径output_file_path: 输出的 Excel 文件路径,默认为 None (不输出到文件)返回:汇总后的 DataFrame"""# 读取 Excel 文件中的所有 sheetxls = pd.ExcelFile(excel_file_path)sheet_names = xls.sheet_names# 创建一个空的 DataFrame 列表,用于存储每个 sheet 的数据dfs = []# 遍历每个 sheetfor sheet_name in sheet_names:# 读取当前 sheet 的数据df = pd.read_excel(excel_file_path, sheet_name=sheet_name)# 添加一列标识数据来源的 sheet 名称df['Sheet_Name'] = sheet_name# 将当前 sheet 的 DataFrame 添加到列表中dfs.append(df)# 将所有 DataFrame 合并成一个merged_df = pd.concat(dfs, ignore_index=True)# 如果指定了输出路径,则保存到文件if output_file_path:merged_df.to_excel(output_file_path, index=False)print(f"已将汇总数据保存到: {output_file_path}")return merged_df# 使用示例
if __name__ == "__main__":# 替换为你的 Excel 文件路径input_file = "范例1.xlsx"output_file = "merged_data.xlsx"# 确保输入文件存在if os.path.exists(input_file):# 汇总数据并保存到新文件result_df = merge_excel_sheets(input_file, output_file)# 打印汇总结果的前几行print("汇总数据预览:")print(result_df.head())# 打印每个 sheet 的行数统计print("\n各 Sheet 数据行数:")sheet_counts = result_df['Sheet_Name'].value_counts()for sheet, count in sheet_counts.items():print(f"{sheet}: {count} 行")print(f"\n总计: {len(result_df)} 行数据")else:print(f"文件不存在: {input_file}")
代码解析
1. 依赖库导入
代码开头导入了两个必要的库:
pandas:强大的数据处理库,用于读取Excel文件和处理数据os:用于进行文件路径相关的操作,这里主要用来检查输入文件是否存在
2. 核心函数:merge_excel_sheets
这是实现数据合并的核心函数,我们来逐步解析其工作流程:
步骤1:获取所有工作表名称xls = pd.ExcelFile(excel_file_path)
sheet_names = xls.sheet_names通过pd.ExcelFile方法读取Excel文件,再通过sheet_names属性获取该文件中所有工作表的名称,为后续遍历做准备。
步骤2:遍历处理每个工作表for sheet_name in sheet_names:
df = pd.read_excel(excel_file_path, sheet_name=sheet_name)df['Sheet_Name'] = sheet_namedfs.append(df)- 循环遍历每个工作表名称,使用`pd.read_excel`读取对应工作表的数据,得到一个DataFrame
- 为当前DataFrame添加一个
Sheet_Name列,记录该数据来自哪个工作表,方便后续溯源 - 将处理好的DataFrame添加到列表
dfs中暂存
步骤3:合并所有数据
merged_df = pd.concat(dfs, ignore_index=True)
使用`pd.concat`方法将列表中所有的DataFrame合并成一个,`ignore_index=True`表示合并后重新生成索引,避免索引重复。
步骤4:保存合并结果(可选)if output_file_path:
merged_df.to_excel(output_file_path, index=False)print(f"已将汇总数据保存到: {output_file_path}")如果指定了输出文件路径,就将合并后的DataFrame保存为Excel文件,`index=False`表示不保存索引列。
3. 使用示例
代码最后部分是使用示例,主要做了这些事:
- 定义输入文件和输出文件的路径
- 检查输入文件是否存在,避免报错
- 调用合并函数进行数据处理
- 输出合并结果的预览、各工作表数据行数统计和总数据量
如何使用该代码
-
安装依赖库:首先确保安装了pandas库,如果没有安装,可运行以下命令:
pip install pandas openpyxl(
openpyxl是pandas处理xlsx格式文件所需的依赖) -
准备Excel文件:将需要合并的Excel文件准备好,记住其路径。
-
修改文件路径:在代码的
if __name__ == "__main__":部分,将input_file和output_file替换为实际的文件路径,例如:input_file = "C:/data/各部门数据.xlsx" output_file = "C:/data/全公司数据汇总.xlsx" -
运行代码:执行Python脚本,等待程序运行完成。运行成功后,会在控制台输出汇总数据预览和统计信息,同时在指定路径生成合并后的Excel文件。
有了这个代码,再也不用手动一个个复制粘贴工作表数据了,尤其适合需要经常处理多工作表Excel文件的办公人士。如果在使用过程中遇到问题,欢迎在评论区留言交流~