临床研究三千问——临床研究体系的5库(10)
嗨~各位同仁又见面啦,在我们系统性地探讨了“一个好问题”、“三大维度”和“四大核心”之后,“1345-10战策”的框架已然清晰。今天,我们将进入知识储备,厚积薄发的“5”,即支撑研究者持续产出、不断进化的五大基础库:文献库、数据库、变量库、写作库、回修库。
这“五库”并非前沿高深的学术理论,而是每一位临床科研者,最应沉下心来构建的基础设施。它们决定了你的研究能否“有米下锅”、能否“精准烹饪”、能否“色香味俱全”、能否“经得起推敲”。其建设水平会清晰地体现在你文章的每一个细节中。
文献库 (Literature Library) —— 研究的“私房菜谱集”
文献库不是你电脑里那个塞满PDF的“Download”文件夹,而是一个经过系统分类、精准标签、并内化吸收的知识管理体系。它基本长这样(如下图)
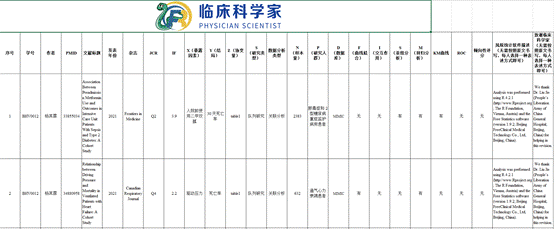
主要包括:文献标题、发表年份、杂志名称、JCR分区 、影响因子(IF)、暴露因素(X)、
结局(Y)、协变量(Z)、研究类型(S)、数据分析类型、样本量(N)、研究人群(P)、数据库(D)、曲线拟合(F)、交互作用(I)、亚组分析(S)、回归分析(M)、KM曲线、ROC、倾向性评分
如何建库?
1. 工具:使用Zotero, EndNote, 小绿鲸等文献管理软件,这是现代科研的标配。
2. 分类:不应仅按杂志或时间分类,更应按暴露因素(X)、结局(Y)、研究类型(S)、研究人群(P)、数据库(D)分类。例如:“NHANES(D)-烟酸摄入(X)-偏头痛(Y)”。这样方便快速找到选题相关的参考文献
3. 内化:在读文献中做好笔记,记录核心创新点、研究设计亮点、统计方法、经典句式。“记笔记”的过程,就是最好的学习过程。
为什么建立文献库呢?
- 避免重复:站在巨人肩上模仿,而非闭门造车。
- 启发思路:从“文献库”中寻找“临床问题”的灵感。例如,你看到多篇文献研究营养素A、B与疾病X的关系,那么营养素C是否也可能有关?这就是新假设的来源。
- 提供方法依据:当你想做剂量反应关系时,立马能找出范文《Association between Dietary Niacin Intake and Migraine...》学习其RCS和阈值效应分析;当你想写引言时,能找到一系列高引文献来论述研究背景。
对一篇优秀SCI论文的“前言”与“讨论”两部分的精准把握,恰恰源于“文献库”的深度和广度。
数据库 (Database Library) —— 研究的“中央厨房与食材仓库”
这是研究数据来源,也是一切分析的根基。它可分为两类:
1. 公共数据库:如NHANES、SEER、MIMIC、UK Biobank等。其特点是样本量大、设计规范、免费获取,是快速产出成果的宝地。
2. 自建数据库:如单中心的临床病历数据库、生物样本库、前瞻性队列数据。其特点是更贴近你的临床实践、变量定义更自主、具有长期性和独特性。
如何建库?
- 公共数据库:关键在于熟悉其数据结构。以NHANES为例,你必须清楚所需变量分布在哪些年份(cycle)、哪些表单(DEMO, DIQ, BMX等)中,以及变量编码的含义(如:RIAGENDR:1=男,2=女)。熟练掌握NHANES的合并与加权技巧,是高效利用它的关键。临床科学家有关于NHNAES变量搜索的网页版NHANES Variables

- 自建数据库:关键在于前瞻性设计和规范化。建议使用EDC等专业工具构建,而非Excel。要预先定义好所有变量的类型、单位和取值范围,确保数据录入的准确性和一致性。一个混乱的自建数据库,其价值为零。风锐EDC系统链接工作台

为何重要?
1. 公共库让你能快速验证想法、产生假设、发表文章。看看临床科学家同学文献库里的成果,绝大部分都源于对NHANES、SEER等公共数据的深度挖掘。
2. 自建库是你的核心竞争力和学术护城河。它是探索真正原创性问题的根本。
变量库 (Variable Library) —— 研究的“食材处理手册”
这是“数据库”的元数据,是一本关于数据的“字典”和“说明书”。它清晰地定义了每一个变量的来龙去脉。
如何建库?
这是为你使用的每一个数据库(尤其是自建库)建立这样一个变量库:
变量名:原始变量名是什么?
变量含义:它代表什么临床或生物学意义?
来源:来自哪个表单、哪个问卷问题或哪个检测指标?
类型:是连续变量还是分类变量?
单位:单位是什么?(切记!)
编码规则:分类变量如何编码?(如:1=是,2=否;1=男性,2=女性)
处理说明:是否进行了转换?(如:肌酐单位换算,计算eGFR,生成复合指标等)

一个好的变量库可以做到事半功倍:
确保可重复性:一年后,你还能看懂自己当时的数据处理吗?变量库确保了研究的可重复性。
提高协作效率:当与统计学家或团队成员合作时,一份清晰的变量库能减少大量沟通成本。
避免低级错误:最大的错误往往源于对变量的误解,如弄错单位、搞反编码。
写作库 (Writing Library) —— 研究的“招牌菜话术”
这是一个积累优质学术表达的语料库。是从大量优质文献中提炼出的“金句”集合。这个过程一般在阅读文献时建立
在阅读文献(构建文献库)时,有意识地收集:
1.引言句型:如何优雅地论述研究背景和选题创新?
2.方法描述:如何规范地描述统计方法?
3.结果陈述:如何准确、客观地报告结果?(例如:如何报告OR值、HR值及其CI和P值)
4.讨论逻辑:如何解释结果、与既往研究对比、阐述局限性?
5.图表标题:学习顶级期刊如何为图表命名和注释。
这样的模仿学习可以帮我们做到:
1.摆脱中式英语:直接模仿顶刊的地道表达,是提升论文语言质量的最快路径。
2.规范学术写作:让我们的写作符合国际规范,更易被审稿人接受。
3.提升写作效率:当拥有一个丰富的语料库,写作便不再是“从零造句”,而是“高级拼图”,事半功倍。
回修库 (Revise Library) —— 研究的“食客反馈与改良日志”
这是一个收集审稿人意见及其回复策略的数据库。小黑屋的“回修库”正是此意。
如何建库?
1. 记录:完整记录每次投稿后收到的审稿人意见(包括那些刻薄的、难以回答的)。这一点可以关注“临床科学家”公众号“朝花夕拾”系列,汇聚了各种回修模版。
2. 归档:按意见类型分类归档,如:“统计方法质疑”、“创新性不足”、“语言问题”、“补充实验要求”等。
3. 总结:记录自己或其他同学是如何成功回复这些意见的,保存优秀的回复信范例。
好的回修库可以做到:
1.预判审稿:通过回顾历史,你能预判审稿人可能从哪些角度提问,从而在研究和写作阶段就提前规避。
2.精修回复:回复审稿人是一门艺术。学习如何保持礼貌、逐点回复、有理有据、必要时妥协的技巧,能极大提高投稿成功率。
3.传承经验:对于临床科学家同学们而言,这是一个宝贵的共享知识库,能让大家快速成长。
总之“五库”的建设,非一日之功,它是一个日积月累、持续迭代的过程。但其回报是巨大的:
文献库用以谋篇定向,
数据库用以备足粮仓,
变量库用以筑基立梁,
写作库用以叙事成章,
回修库用以功成圆满。
真正的高手,正是在这些看似枯燥的基础工作中,拉开了与平庸者的差距。
科研,是一场马拉松。而“五库”,就是你一路上的能量补给站。加油,行动起来吧~
下一期,我们将进入“1345-10战策”的最后实战环节,10个步骤手把手带你写SCI。敬请期待。