项目实战:RAG论文阅读助理系统性能测试
最近为了社招准备了一个全栈项目,是一个帮助论文阅读的RAG系统,可以基于论文内容,回答用户的问题。项目地址为:paper-pro: 一个AI阅读论文工具 。前期已完成该项目的介绍,见:项目实战:RAG论文阅读助理-CSDN博客,现在对系统进行性能测试,希望能保佑我社招顺利![]() (虔诚)。
(虔诚)。
聊天记录列表QPS
考虑到获取聊天记录是高频操作,另外获取助理列表、会话列表和文件列表都与它的方式类似,而且获取列表都没有使用redis缓存。这里以获取聊天记录作为示例进行分析,其他数据库操作的分析方式与此类似。
我们先获取相关服务 chat-api、chat-rpc、MongoDB docker容器下的 cpu 分配情况:
> docker inspect paper-chat-rpcsvc | findstr /i "Cpu"
"CpuShares": 0,
"NanoCpus": 0,
"CpuPeriod": 0,
"CpuQuota": 0,
"CpuRealtimePeriod": 0,
"CpuRealtimeRuntime": 0,
"CpusetCpus": "",
"CpusetMems": "",
"CpuCount": 0,
"CpuPercent": 0,
即我使用的是默认值。 chat-api 同理。监控资源时,我将直接使用windows的任务管理器查看硬件资源性能。
在测试前,我们还要在看板配几个监控指标,我选择了以下几个:
histogram_quantile(0.95, sum(rate(http_server_requests_duration_ms_bucket{code="200", path=~"/chat/.*/msgs/list"}[1m])) by (le))
histogram_quantile(0.99, sum(rate(http_server_requests_duration_ms_bucket{code="200", path=~"/chat/.*/msgs/list"}[1m])) by (le))
histogram_quantile(0.95, sum(rate(http_server_requests_duration_ms_bucket{path=~"/chat/.*/msgs/list"}[1m])) by (le))
histogram_quantile(0.99, sum(rate(http_server_requests_duration_ms_bucket{path=~"/chat/.*/msgs/list"}[1m])) by (le))
sum(irate(http_server_requests_code_total{path=~"/chat/.*/msgs/list"}[1m]))
sum(irate(http_server_requests_code_total{path=~"/chat/.*/msgs/list", code="200"}[1m])) by (path, code)
sum(irate(http_server_requests_code_total{path=~"/chat/.*/msgs/list", code="503"}[1m])) by (path, code)
以上指标来自go-zero,分别统计百分位请求延时和请求响应成功的数量。
最后,我们在前端打桩一些代码,获取请求url和token以及获取到的响应聊天数量(位于list_chat_msgs方法):
> url: /api/v1/chat/68b05b0199ad680391d76b39/msgs/list
> token: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODk0Mzg5ODAsImlhdCI6MTc1NzkwMjk4MCwiand0VXNlcklkIjoxfQ.5TCxhCRE997gHbJfne4Qma7zCrkYl26xhjCWYgluMlU
> len(msgs): 16
顺便也用前端开发工具看了这条响应的时间大概是14ms:
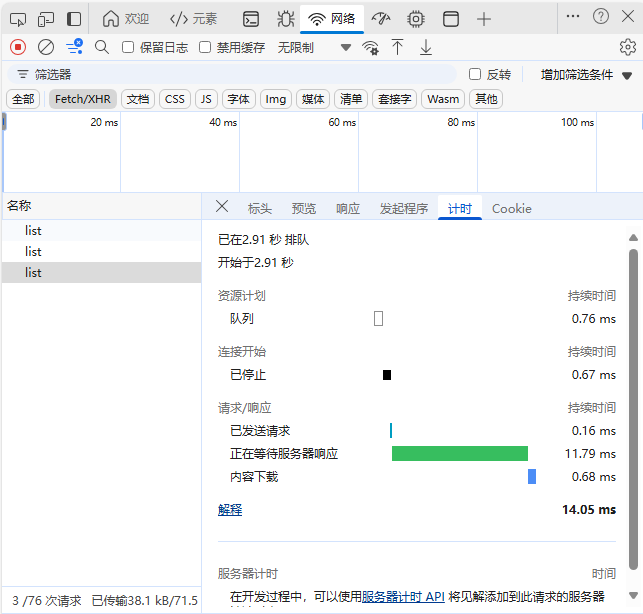
下面,我们首先用 hey 测试 10 个并发,100条请求的场景,来获得一个基准:
hey -c 10 -n 100 -H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODk0Mzg5ODAsImlhdCI6MTc1NzkwMjk4MCwiand0VXNlcklkIjoxfQ.5TCxhCRE997gHbJfne4Qma7zCrkYl26xhjCWYgluMlU" "http://localhost:8000/api/v1/chat/68b05b0199ad680391d76b39/msgs/list"
Summary:
Total: 0.1361 secs
Slowest: 0.0466 secs
Fastest: 0.0025 secs
Average: 0.0124 secs
Requests/sec: 734.4894
Response time histogram:
0.002 [1] |■
0.007 [27] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.011 [35] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.016 [15] |■■■■■■■■■■■■■■■■■
0.020 [7] |■■■■■■■■
0.025 [3] |■■■
0.029 [6] |■■■■■■■
0.033 [2] |■■
0.038 [2] |■■
0.042 [0] |
0.047 [2] |■■
Latency distribution:
10% in 0.0044 secs
25% in 0.0064 secs
50% in 0.0097 secs
75% in 0.0152 secs
90% in 0.0269 secs
95% in 0.0326 secs
99% in 0.0466 secsDetails (average, fastest, slowest):
DNS+dialup: 0.0005 secs, 0.0025 secs, 0.0466 secs
DNS-lookup: 0.0004 secs, 0.0000 secs, 0.0043 secs
req write: 0.0000 secs, 0.0000 secs, 0.0003 secs
resp wait: 0.0113 secs, 0.0023 secs, 0.0465 secs
resp read: 0.0006 secs, 0.0000 secs, 0.0083 secsStatus code distribution:
[200] 100 responses
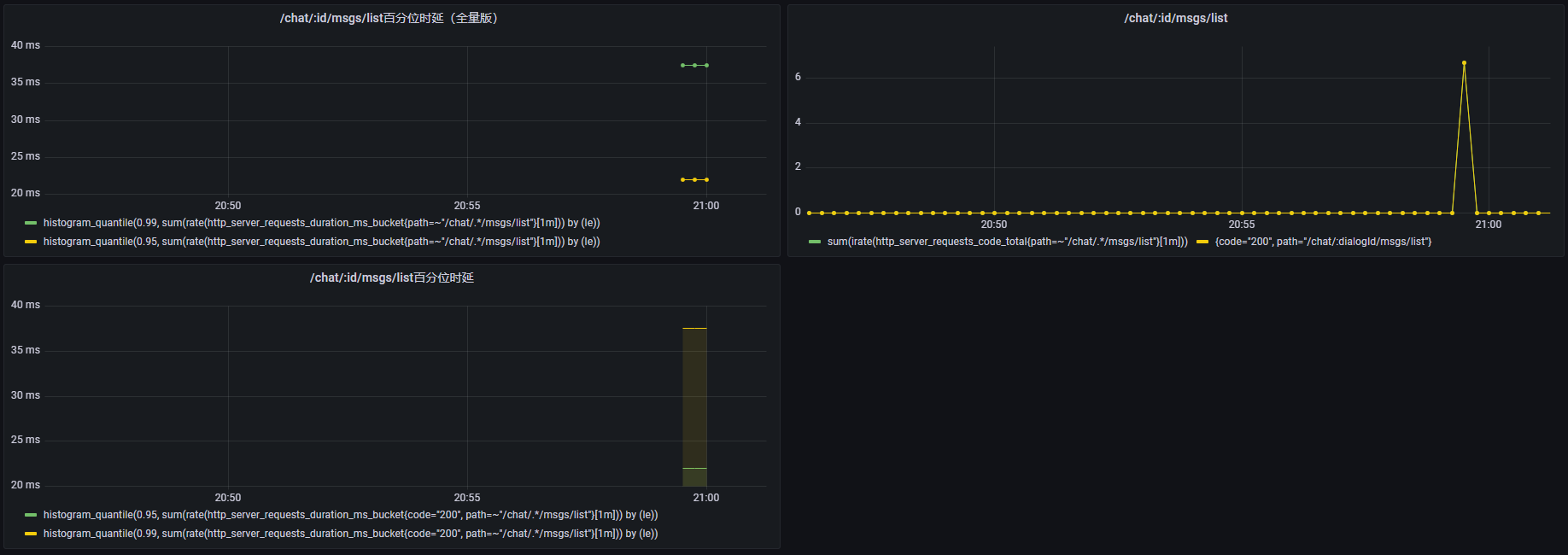
下面我们逐步增加并发量,每次测10min,来得到该类接口开发环境单机部署版的QPS:
> hey -c 10 -z 10m -H "Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODk0Mzg5ODAsImlhdCI6MTc1NzkwMjk4MCwiand0VXNlcklkIjoxfQ.5TCxhCRE997gHbJfne4Qma7zCrkYl26xhjCWYgluMlU" "http://localhost:8000/api/v1/chat/68b05b0199ad680391d76b39/msgs/list"
| 并发数 | 压测时长 | QPS | 平均响应时间 | 95% 响应时间 | 成功率 | 是否符合阈值(≥99.9%) |
|---|---|---|---|---|---|---|
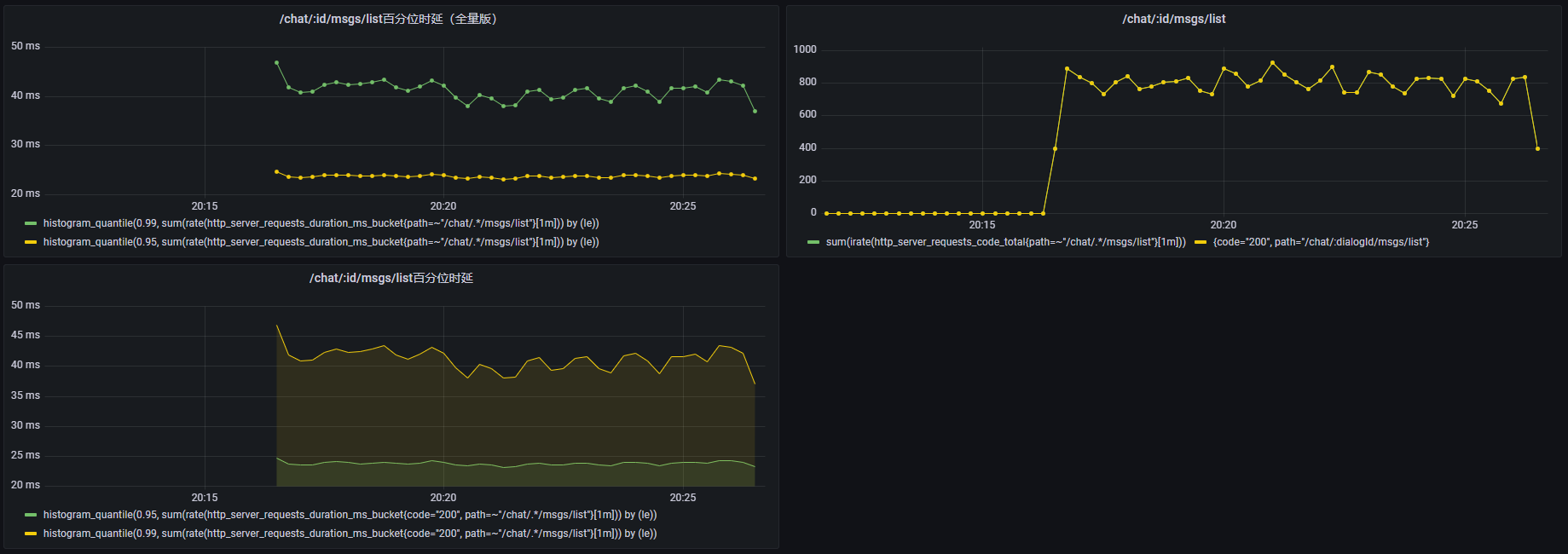
| 10 | 10min | 772.0261 | 13.0ms | 27.9ms | 100% | 是 |
| 20 | 10min | 786.1233 | 25.4ms | 53.7ms | 100% | 是 |
| 100 | 10min | ? | ||||
| 150 | 10min | ? |
并发数10:
并发数20:
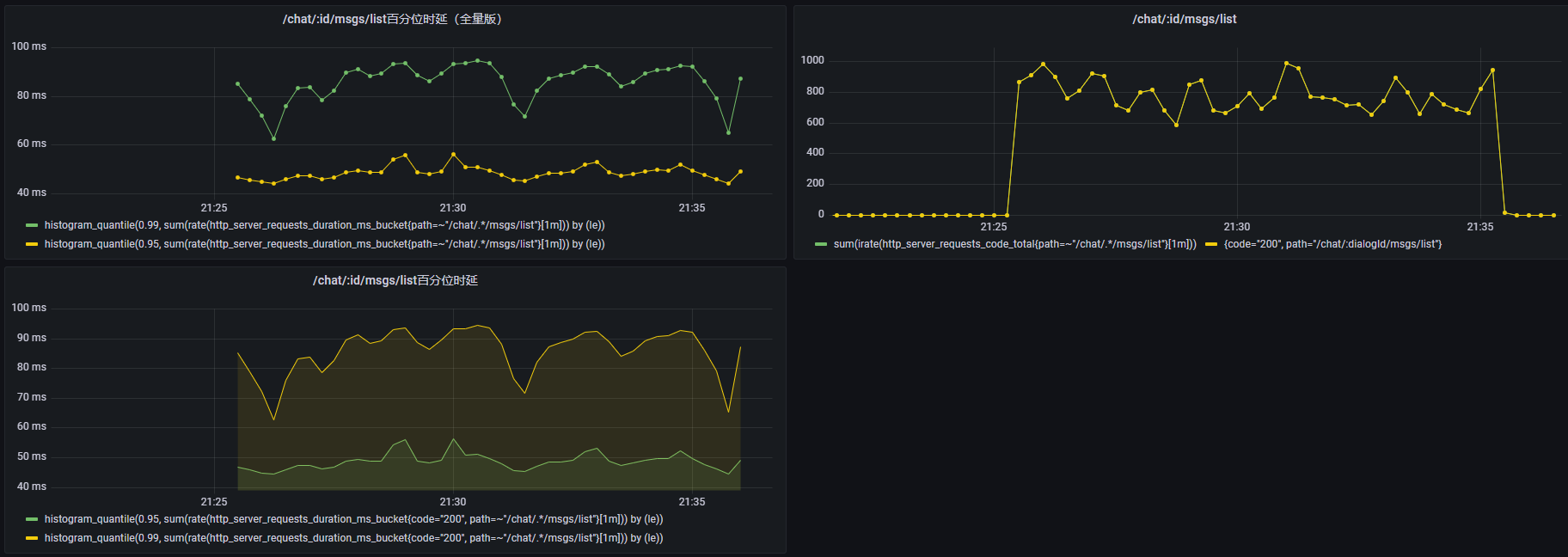
可以看到在并发量 20 时,时延也跟着翻倍。但是这里有一个很奇怪的现象,qps并没有随着并发量的上升而上升,这说明系统已经出现了瓶颈。我们看一下硬件系统的监测(20并发量下):
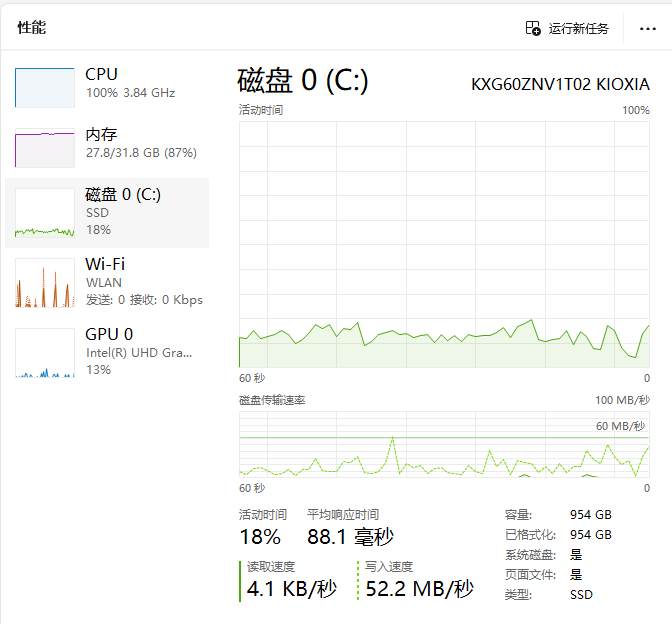
对于一个读IO的接口来说,居然是CPU干满了,磁盘IO和并发量10时的占用差不多,这说明当前的瓶颈出现在CPU上。不过这也好理解,因为我设备有限,测试和后端系统都部署在同一台电脑上,这些并发测试都在不停地用CPU。我们可以看看 chat 服务容器的CPU分配:
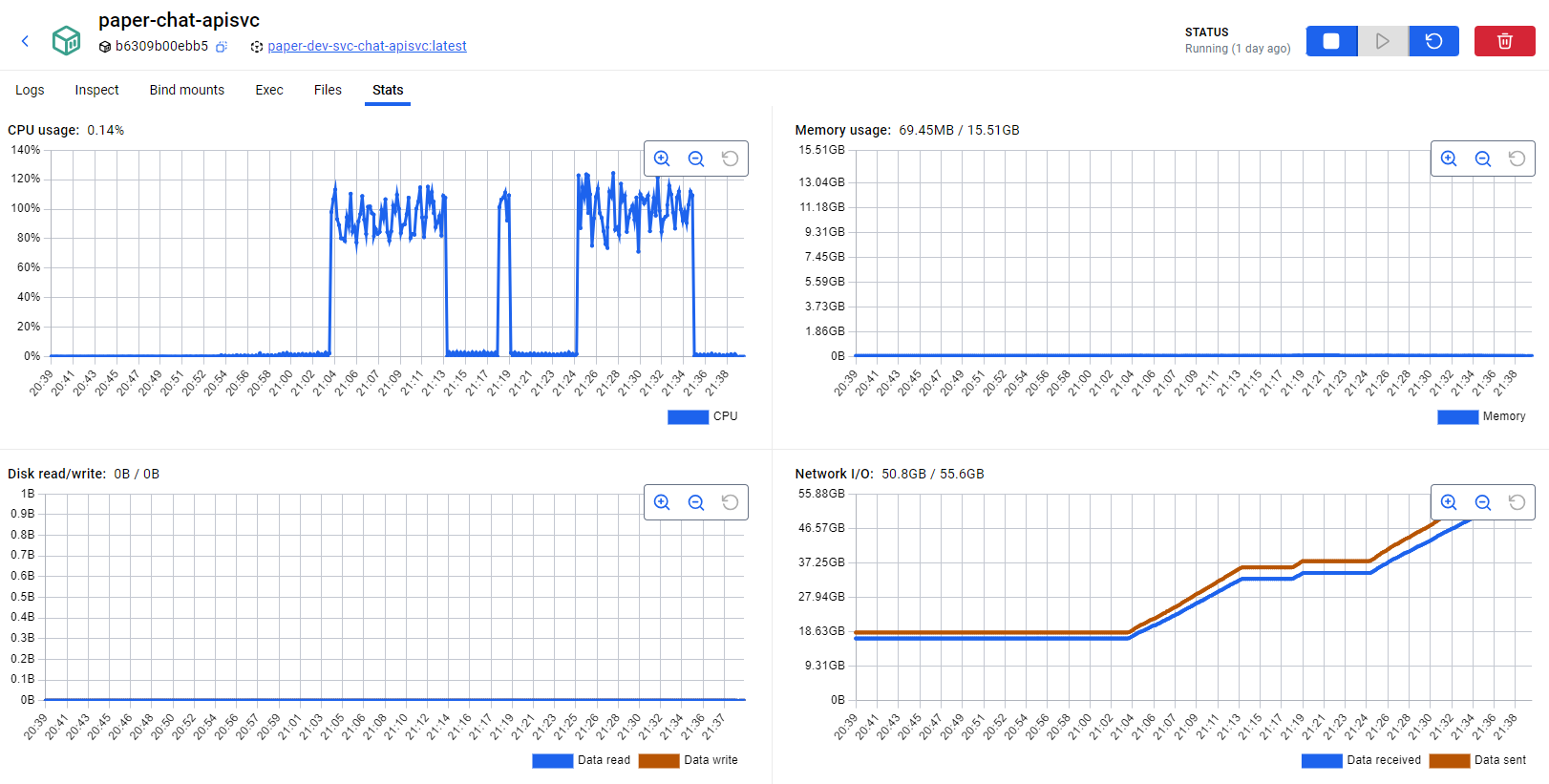
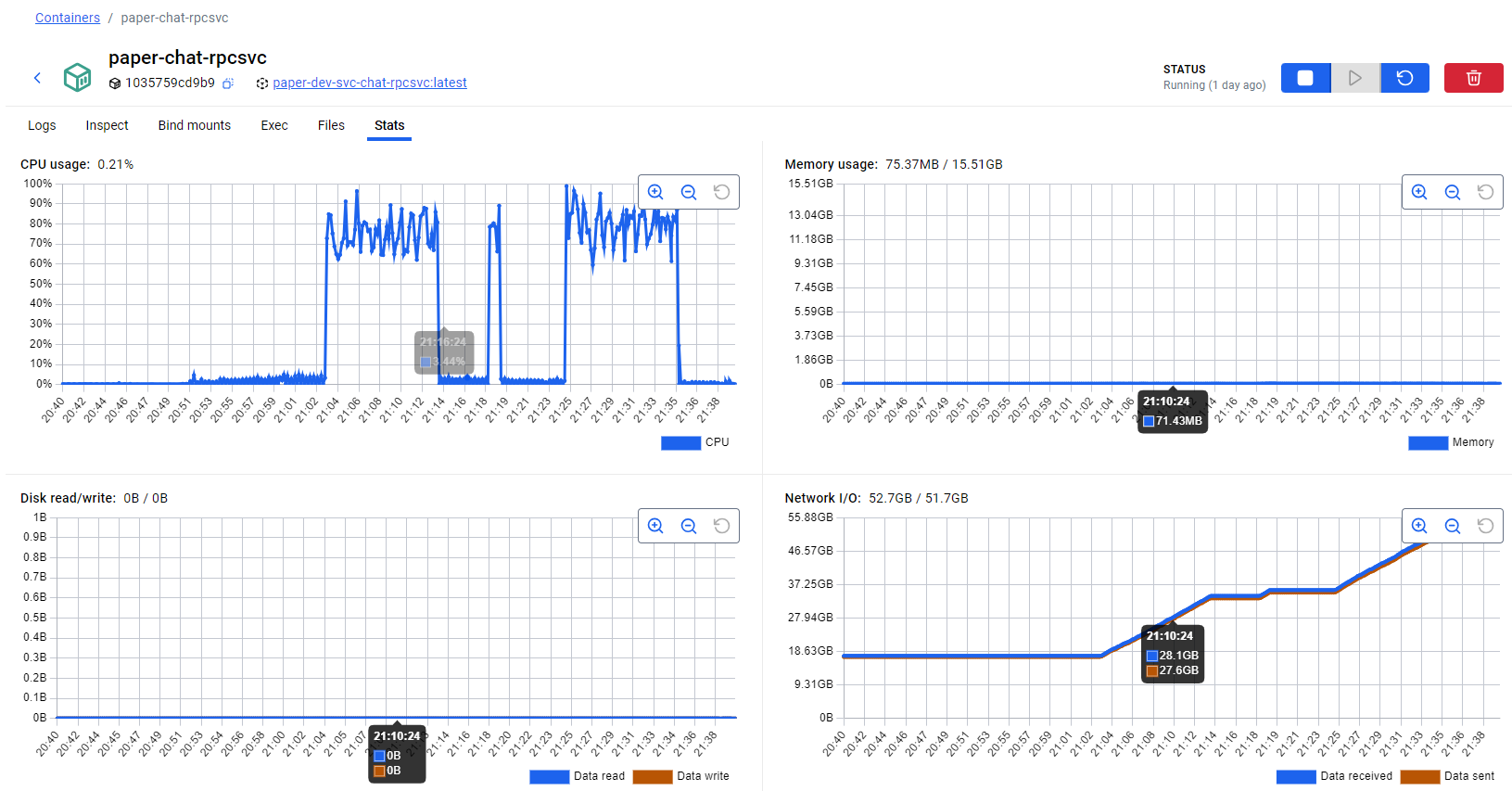
可以看到,对于一个8核的计算机,服务并没有打满cpu。这样,我们的测试也就只能止步于此了。不过,最后我们可以做一个简单的估算,如果预计性能瓶颈出现在磁盘上,最大 qps 至少应该是当前值乘以 5,也就是 3900 ~ 4000,当然,这只是我的主观推测,实际可能还会受其他因素限制,例如网络带宽,应以测试为准。
RAG聊天功能性能测试
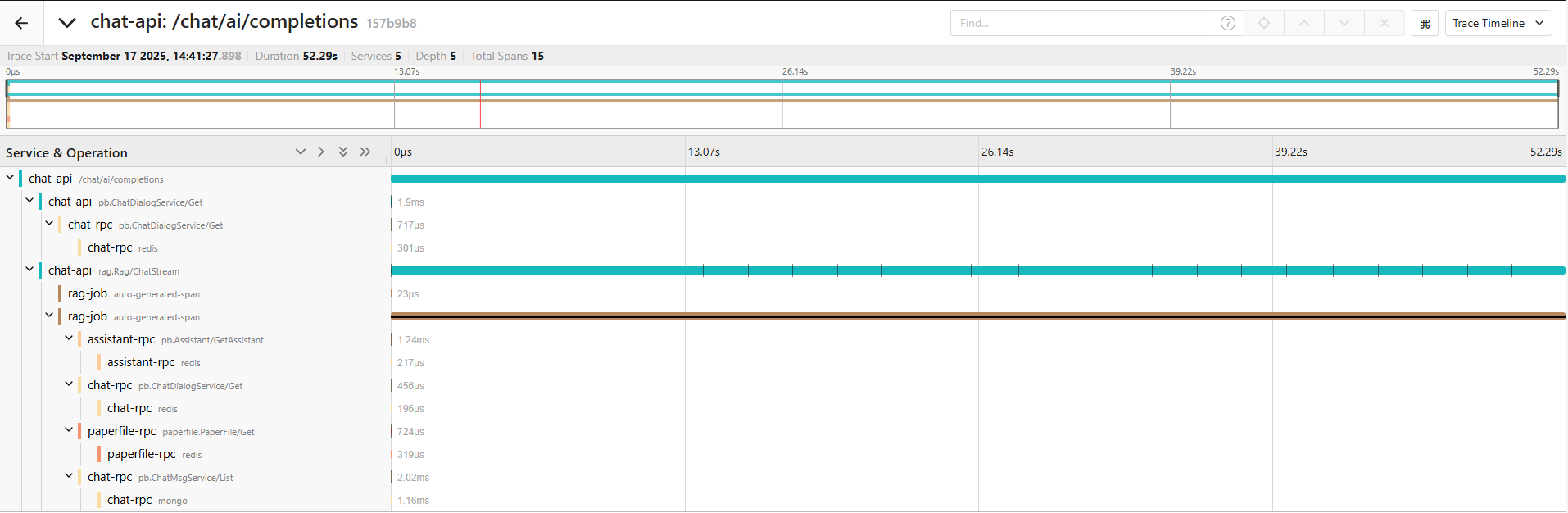
首先我们分析单个测试的时延。这里我使用的测试论文是《StableAvatar Infinite-Length Audio-Driven Avatar Video Generation》(一篇比较新的论文),我向助理询问“用更通俗移动的方式,向我介绍下StableAvatar的原理,以及为什么会有效果”。以下是它的调用链路:
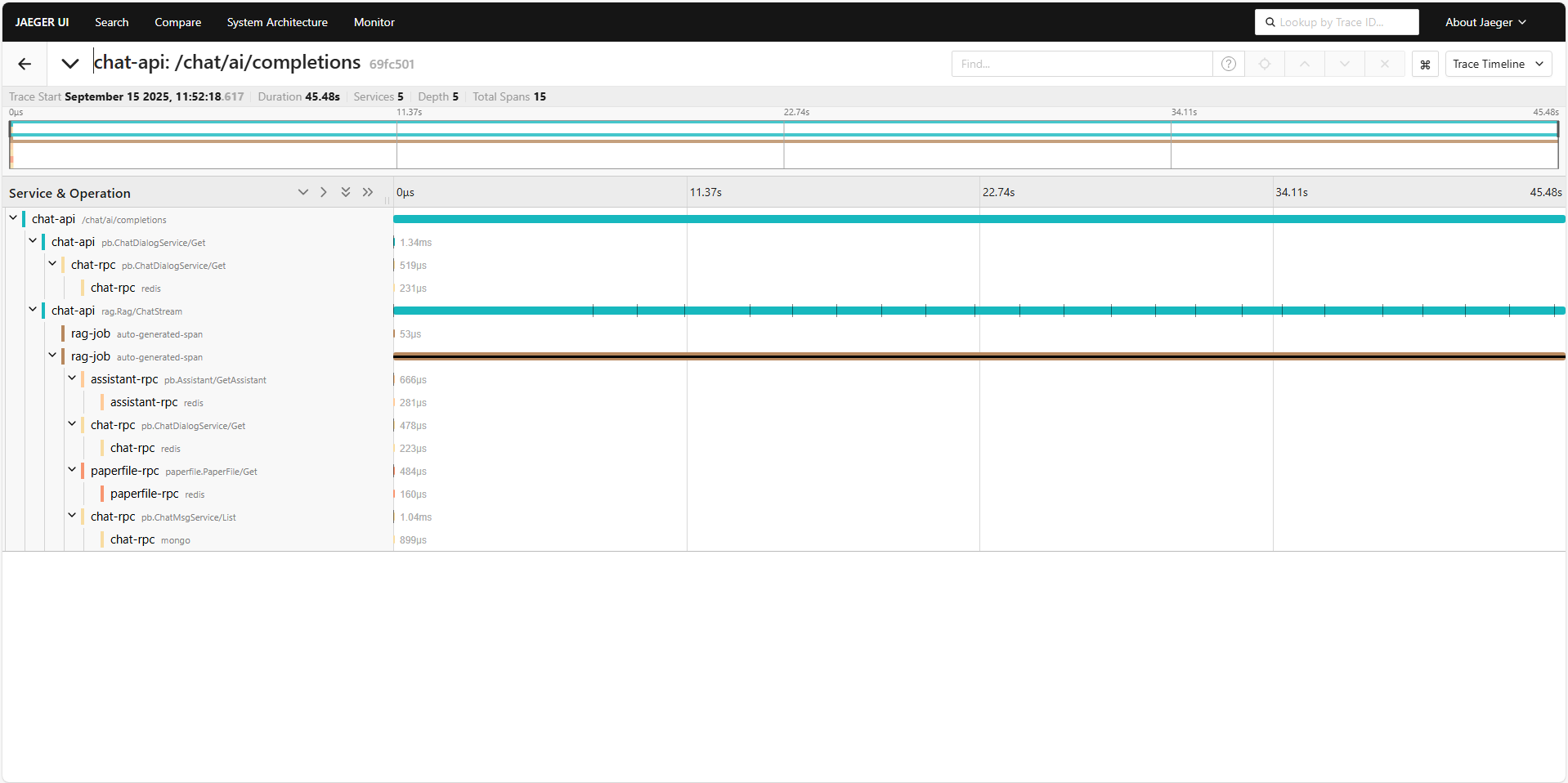
整条调用链路长达 45.48s,但考虑到大语言模型生成 token 的方式(马尔科夫链),这个时间也较为合理。不过从实际使用的感受来看,从发出问题到收到第一条响应的时间较久,我们下面来看看具体是哪而造成了延迟,以及是否有优化空间。下面是SSE返回数据的时间点(实际是 chat-api调用 rag.Rag/ChatStream 接口的接收到数据的时刻,对应于图中 chat-api 那条链路上画黑竖线的部分):
1.96ms:
- event=message
- message.id=1
- message.type=SENT
- message.uncompressed_size=153
7.73s:
- event=message
- message.id=1
- message.type=RECEIVED
- message.uncompressed_size=0
9.45s:
- event=message
- message.id=2
- message.type=RECEIVED
- message.uncompressed_size=0
11.26s:
- event=message
- message.id=3
- message.type=RECEIVED
- message.uncompressed_size=0
13.79s:
- event=message
- message.id=4
- message.type=RECEIVED
- message.uncompressed_size=203
15.49s:
- event=message
- message.id=5
- message.type=RECEIVED
- message.uncompressed_size=267
17.19s:
- event=message
- message.id=6
- message.type=RECEIVED
- message.uncompressed_size=235
18.94s:
- event=message
- message.id=7
- message.type=RECEIVED
- message.uncompressed_size=234
20.61s:
- event=message
- message.id=8
- message.type=RECEIVED
- message.uncompressed_size=297
22.54s:
- event=message
- message.id=9
- message.type=RECEIVED
- message.uncompressed_size=268
24.26s:
- event=message
- message.id=10
- message.type=RECEIVED
- message.uncompressed_size=236
26.04s:
- event=message
- message.id=11
- message.type=RECEIVED
- message.uncompressed_size=265
27.88s:
- event=message
- message.id=12
- message.type=RECEIVED
- message.uncompressed_size=224
29.56s:
- event=message
- message.id=13
- message.type=RECEIVED
- message.uncompressed_size=164
31.14s:
- event=message
- message.id=14
- message.type=RECEIVED
- message.uncompressed_size=301
32.9s:
- event=message
- message.id=15
- message.type=RECEIVED
- message.uncompressed_size=260
34.5s:
- event=message
- message.id=16
- message.type=RECEIVED
- message.uncompressed_size=256
36.09s:
- event=message
- message.id=17
- message.type=RECEIVED
- message.uncompressed_size=255
38.39s:
- event=message
- message.id=18
- message.type=RECEIVED
- message.uncompressed_size=227
39.91s:
- event=message
- message.id=19
- message.type=RECEIVED
- message.uncompressed_size=225
41.61s:
- event=message
- message.id=20
- message.type=RECEIVED
- message.uncompressed_size=273
43.3s:
- event=message
- message.id=21
- message.type=RECEIVED
- message.uncompressed_size=209
45.02s:
- event=message
- message.id=22
- message.type=RECEIVED
- message.uncompressed_size=302
45.48s:
- event=message
- message.id=23
- message.type=RECEIVED
- message.uncompressed_size=47
从上面的响应日志中,可以看到 chat api 服务在 1.96 ms 时就已向 rag rpc 服务发送请求,在api阶段的处理其实还好(当前所有节点都部署在一台计算机节点上,实际部署时,MongoDB、chat-rpc、chat-api不在一个位置,会多出网络延迟)。但是,在发送请求后收到第一条响应时,花了大约7s,但是这时收到的响应是没有数据的(message.uncompressed_size=0),直到第 13s 才收到第 1 条有数据的消息,也就是说,从发送请求到收到ai的流式回答,总共花了 13s 中。
下面我们看看具体是哪些部分造成了如此长的延迟。首先,我们看 rag 服务的调用链路,可以看到它串行调用了好几个其他服务的接口,但是总体上看消耗不大,都是毫秒级,和秒级的延迟相比显得九牛一毛。接下来,就正式走到了 AI 流程里面(AI流程可见我对项目介绍的那篇帖子),考虑到服务内部没有链路,我使用日志记录调用时间:
@timestamp
Sep 15, 2025 @ 11:52:18.619
content
172.16.0.8:39258 - /pb.ChatDialogService/Get - {"Id":"68b05b0199ad680391d76b39","UserId":1}
duration
0.4ms
。。。。。。
@timestamp
Sep 15, 2025 @ 11:52:23.918
content:
HTTP Request: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
@timestamp
Sep 15, 2025 @ 11:52:23.937
content
process {'module': 'app.rag.internal.logic.rag_graph', 'class': 'RagGraph', 'function': '_think'}
duration
5297.2ms
@timestamp
Sep 15, 2025 @ 11:52:24.184
content
process {'module': 'app.rag.internal.logic.rag_graph', 'class': 'RagGraph', 'function': '_retrieve'}
duration
245.6ms
@timestamp
Sep 15, 2025 @ 11:52:25.014
content
HTTP Request: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
@timestamp
Sep 15, 2025 @ 11:53:04.097
content
process {'module': 'app.rag.internal.logic.rag_graph', 'class': 'RagGraph', 'function': '_generate'}
duration
39912.4ms
@timestamp
Sep 15, 2025 @ 11:53:04.099
content
process {'module': 'app.rag.internal.server.ragserver', 'class': 'RagServer', 'function': 'ChatStream'}
duration
45478.2ms
上面截取的日志中,第一条日志 /pb.ChatDialogService/Get 接口的调用和返回,可以近似理解为整个链路开始的时刻(毫秒级误差),下一条日志则是对阿里模型API接口调用的访问,这个访问对应于我 RAG 流程里的 think 阶段,可以看到以供耗时 5.3s,之后 RAG 检索(retrieve 阶段)花费了约 0.25s,最后又过了约 1s 收到了另一条对阿里模型API接口的调用,这个调用对应于 generate 阶段调用大模型的 stream 接口。从以上流程可以看出,前 7s 的延迟,主要来自于 AI 阶段的前置工作。那么为什么要到 13s 用户才收到第 1 条回答呢?我猜想,是因为大模型需要一个 k-v cache的预热阶段,我在 generate 阶段发送的数据有相当多的内容,包括摘要提取信息,包括历史的2段对话,还有论文检索的文章片段,这些内容拷贝到 gpu 显存,并且计算 k-v cache 都需要时间,因此大模型的流式接口在这期间,会不停发送 0 字节的消息防止连接超时断连。
虽然RAG聊天功能,作为核心功能,测量并发量等非常有意义,但是我使用的是三方模型,这种测试很贵,不过我们可以模拟。
从上面的时延分析中,可以获取到一段对话的典型过程为:首先调用其他服务多段链路,确保相关信息存在;然后,输入问题,并将论文摘要信息从数据库取出来,输入 AI 流程;在AI流程think阶段阻塞 5s,调用大模型服务,将结果保存到内存;下一阶段 retrieve 继续检索向量数据库,将结果保存到内存;最后在 generate 阶段,调用大模型API服务,先阻塞 3 个 2s,期间发送空数据,之后每隔 2s 发送约 250 字节("I'm so handsome!"*16=256),共发送 20 次。我们将上面所有需要大模型的部分全部替换成sleep+生成一个字符串的方式来进行替换,同时注释掉 chat-api 中异步存储聊天记录的部分(这个反正是异步的,分别测试,留到后面做):
@decorator.log_time_handler()
def _think(self, state: State, config: RunnableConfig):"RAG前思考步骤"......# resp = self._thinker_llm.invoke([# {# "role": "system",# "content": thinker_system_msg,# },{# "role": "user",# "content": user_content,# }# ])# json_res = json.loads(resp.content)time.sleep(5)s = '{"question":"StableAvatar 的原理及其为何有效?","thinking":"用户希望了解 StableAvatar 的基本原理和其有效性的原因。首先,需要解释 StableAvatar 的核心方法:Time-step-aware Audio Adapter、Audio Native Guidance Mechanism 和 Dynamic Weighted Sliding-window Strategy。然后分析这些技术如何解决音频驱动虚拟人视频生成中的关键问题,如长视频生成时的身份一致性、音频同步性与视频流畅性。回答应尽量通俗,避免过多术语,并结合实际应用场景(如电影制作或虚拟助手)说明其价值。","need_rag":"YES","rag_sentence":"StableAvatar 通过引入时间感知音频适配器和动态加权滑动窗口策略,解决了长视频中身份一致性和音频同步性的问题。"}'resp = s.encode('utf-8').decode('utf-8') # 强制拷贝json_res = json.loads(resp)print(f'\n_think:\nthinker_question: {json_res["question"]}\nthinker_tip: {json_res["thinking"]}\n'f'need_rag: {json_res["need_rag"]}\nrag_sentence: {json_res["rag_sentence"]}\n', file=sys.stderr)return {"thinker_question": json_res["question"],"thinker_tip": json_res["thinking"],"need_rag": json_res["need_rag"], "rag_sentence": json_res["rag_sentence"]}@decorator.log_time_handler()
def _retrieve(self, state: State, config: RunnableConfig):"""RAG检索步骤"""if state["need_rag"] == "NO":print(f'\n_retrieve:\ndoc_context: 未检索\n', file=sys.stderr)return {"doc_context": "未检索"}time.sleep(0.2)# vec = self._svcCtx.embeddings.embed_query(state["rag_sentence"])vec = # 手动生成一个user_id = config["configurable"]["user_id"]file_id = config["configurable"]["file_id"]res = self._svcCtx.paper_segment_model.search_by(user_id, file_id, vec)retrieved_docs = res[0]if len(retrieved_docs) == 0:print(f'\n_retrieve:\ndoc_context: 未找到相关内容\n', file=sys.stderr)return {"doc_context": "未找到相关内容"}doc_context = doc_combiner_factory(retrieved_docs[0]["splitter_id"]).combine(retrieved_docs)print(f'\n_retrieve:\ndoc_context: {doc_context}\n', file=sys.stderr)return {"doc_context": doc_context}@decorator.log_time_handler()
def _generate(self, state: State, config: RunnableConfig):"""RAG生成文本"""......# resp = llm.stream(messages)# writer = get_stream_writer()# for chunk in resp:# writer({"reply_chunk": chunk})writer = get_stream_writer()time.sleep(1)for _ in range(3):time.sleep(2)writer({"reply_chunk": ""})for _ in range(20):for _ in range(16):time.sleep(0.125)writer({"reply_chunk": "I'm so handsome!".encode('utf-8').decode('utf-8')})return {}修改完毕后,我们先用一个并发量进行测试。这里我准备了一个js测试脚本,如下所示(在进行这个测试的时候,顺便发现了一个原程序的bug,原来返回聊天记录,我是会在api服务侧做一个收集,将ai所有的回复返回给前端,但是测试中发现,如果字串过长,sse会进行一个截断,导致返回消息不是一个完整的json,前端会解析失败):
import { CODE } from "./constants.js";
import { catch_error_resp } from "./request.js";/** 测试脚本执行方法:* 1. 终端进入脚本所在文件夹,执行 `npm init -y`(快速生成 package.json)* 2. 打开 package.json,添加 `"type": "module"`(关键配置),示例:* {* "name": "sse-test",* "version": "1.0.0",* "type": "module", // 必须添加,否则 import 报错* "main": "当前脚本文件名.js" // 替换为实际脚本名(如 sse-test.js)* }* 3. node sse-test.js*/const concurrency = 1000
const test_times = 1const url = "http://localhost:8000/api/v1/chat/ai/completions"
const chatDialog = { // 从数据库随便拷一个"id": "68c573f58af546d70967c123","name": "test1","lastActiveAt": 0,"assistantId": "68c573d3b4857c17c23fab9a","userId": 1,"requestId": "8f6e67c4-fc42-4918-b3e6-36ef1797d01e"
}
const chatMsg = "用更通俗移动的方式,向我介绍下StableAvatar的原理,以及为什么会有效果"
const token = {'Authorization': "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODk0Mzg5ODAsImlhdCI6MTc1NzkwMjk4MCwiand0VXNlcklkIjoxfQ.5TCxhCRE997gHbJfne4Qma7zCrkYl26xhjCWYgluMlU"}class MockChatStream {#url;#controller;// 新增 promise 用于追踪请求完成状态#requestPromise;constructor(url) {this.#url = url;this.#controller = null;this.onMessage = () => {};this.onFinish = () => {};this.onError = (error) => {console.error(`[请求失败]`, error);};}async send({ chatMsg, chatDialog }) {// 返回 promise 并赋值给 #requestPromise,用于外部追踪状态this.#requestPromise = new Promise(async (resolve, reject) => {this.#controller = new AbortController();let reader;try {const response = await fetch(this.#url, {method: "POST",headers: {"Content-Type": "application/json","Accept": "text/event-stream",// 修复 token 传递格式:取对象的 Authorization 属性值"Authorization": token.Authorization},body: JSON.stringify({"chatMsg": chatMsg,"chatDialog": chatDialog,"isNew": false,}),signal: this.#controller.signal});// 检查响应状态码,非 200 直接视为错误if (!response.ok) {throw new Error(`HTTP 错误: ${response.status} ${response.statusText}`);}reader = response.body.getReader();const decoder = new TextDecoder();while (true) {const { done, value } = await reader.read();if (done) {this.onFinish();resolve("请求正常完成"); // 标记请求成功break;}const chunk = decoder.decode(value);chunk.split('\n\n').forEach(event => {if (event.startsWith('data:')) {const data = event.replace('data:', '').trim();this.onMessage(data);}});}} catch (err) {if (err.name === "AbortError") {reject("请求被主动中断");return;}this.abort()let error_resp;if (err instanceof SyntaxError) {console.error("ChatStream send: 解析失败:", err);error_resp = { code: CODE.SERVER_COMMON_ERROR, msg: `解析后端返回数据格式失败` };} else {error_resp = catch_error_resp(err) || { code: CODE.SERVER_COMMON_ERROR, msg: err.message };}this.onError(error_resp);reject(error_resp); // 标记请求失败} finally {reader?.releaseLock();this.#controller = null;}});// 返回 promise,允许外部 awaitreturn this.#requestPromise;}isChating() {return this.#controller !== null}abort() {if(this.isChating()) {this.#controller.abort();}}// 新增:获取请求的 promise,用于等待请求完成getRequestPromise() {return this.#requestPromise;}
}// 3. 核心测试函数(支持并行、时间统计、等待所有请求完成)
async function runSSETests() {console.log(`[测试开始] 并行数: ${concurrency}, 接口: ${url}`);const startTime = Date.now(); // 记录开始时间const testPromises = []; // 存储所有请求的 promise,用于等待全部完成try {// 创建并行请求for (let i = 0; i < concurrency; i++) {// 发起请求并将 promise 加入数组const test_loop = async () => {const chater = new MockChatStream(url);// 自定义当前请求的回调(可选,便于区分不同并行请求)// chater.onMessage = (data) => {// console.log(`[并行请求 ${i + 1}/${concurrency}] 接收消息`, data);// };// chater.onFinish = () => {// console.log(`[并行请求 ${i + 1}/${concurrency}] 完成`);// };chater.onError = (error) => {console.error(`[并行请求 ${i + 1}/${concurrency}] 失败:`, error);};for (let j = 0; j < test_times; j++) {await chater.send({chatMsg: {id: `my-test ${i}-${j}`,content: chatMsg,role: 'user',chatAt: Math.floor(Date.now() / 1000),dialogID: chatDialog.id,requestId: "123",},chatDialog: chatDialog});}}const requestPromise = test_loop()testPromises.push(requestPromise);}// 等待所有并行请求完成(无论成功/失败,用 Promise.allSettled)const results = await Promise.allSettled(testPromises);// 统计结果const successCount = results.filter(res => res.status === "fulfilled").length;const failCount = results.filter(res => res.status === "rejected").length;const endTime = Date.now();const totalTime = (endTime - startTime) / 1000; // 转换为秒// 打印最终统计信息console.log("\n" + "=".repeat(50));console.log(`[测试结束] 总耗时: ${totalTime.toFixed(2)} 秒`);console.log(`[结果统计] 成功: ${successCount} 个, 失败: ${failCount} 个`);console.log("=".repeat(50));// 若有失败,打印失败详情if (failCount > 0) {console.log("\n[失败详情]");results.forEach((res, index) => {if (res.status === "rejected") {console.log(`请求 ${index + 1}:`, res.reason);}});}} catch (globalErr) {// 捕获全局异常(如创建实例失败)console.error(`[全局错误] 测试执行异常:`, globalErr);const endTime = Date.now();const totalTime = (endTime - startTime) / 1000;console.log(`[测试中断] 总耗时: ${totalTime.toFixed(2)} 秒`);}
}// 4. 执行测试(调用入口)
await runSSETests(); // 等待所有测试完成(SSE 连接、数据接收、结果统计)
console.log("所有测试已完全结束,脚本退出");一个并发量的测试结果如下:
> node sse-test.js
[测试开始] 并行数: 1, 接口: http://localhost:8000/api/v1/chat/ai/completions==================================================
[测试结束] 总耗时: 52.56 秒
[结果统计] 成功: 1 个, 失败: 0 个
==================================================
所有测试已完全结束,脚本退出
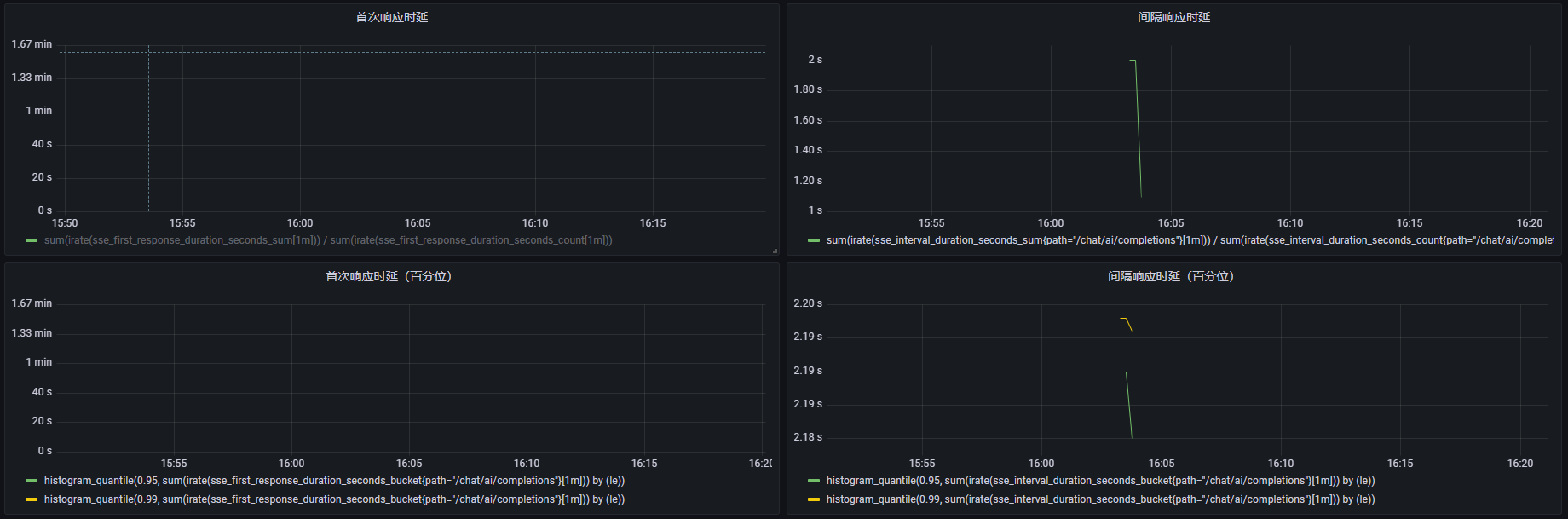
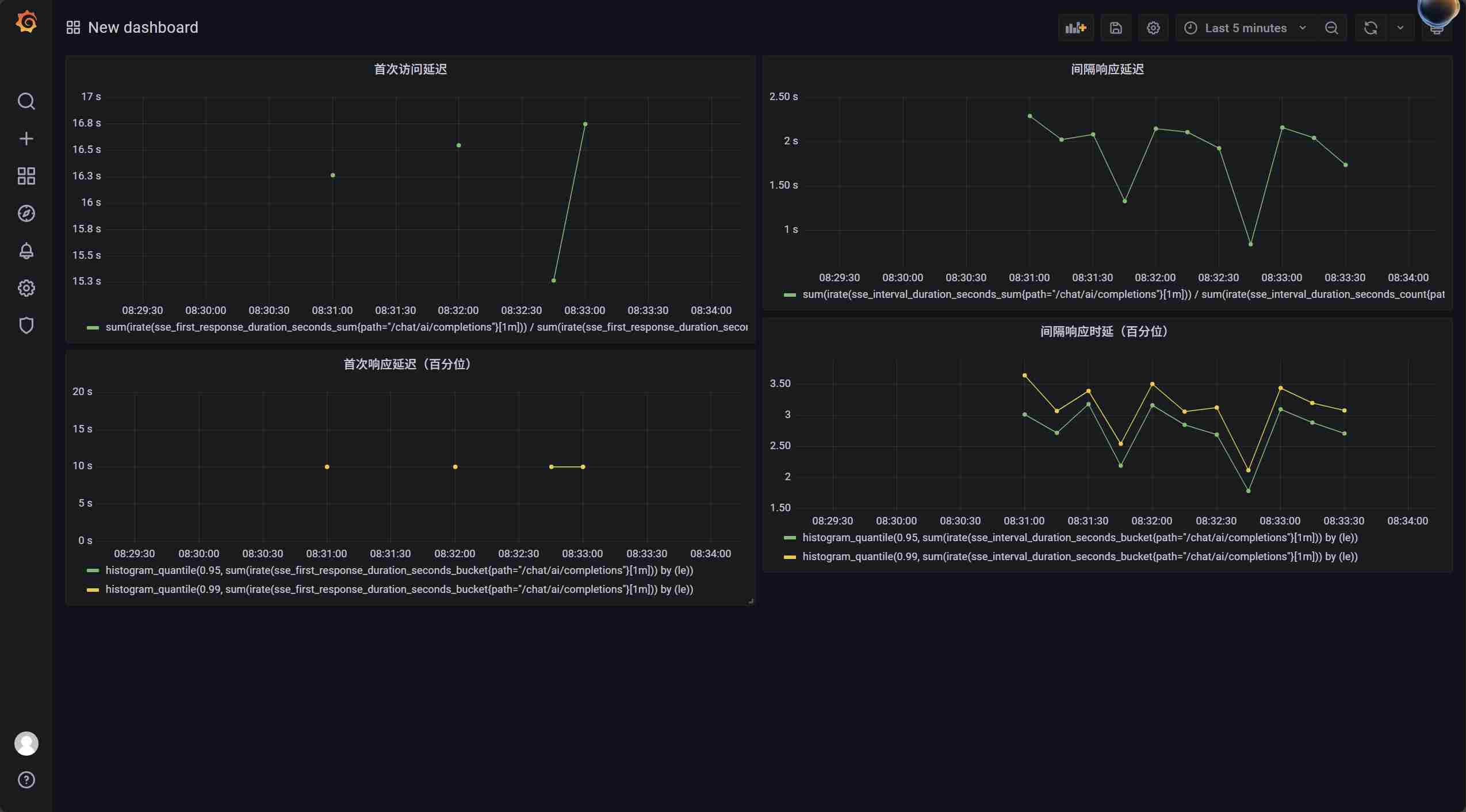
可以看到时延基本和我们写的差不多,首次时延 13s,间隔时延 2s,当然下面的统计面板中首次时延没有,因为只有一条数据吗。
考虑到 AI 聊天的性质,我认为应该看两个指标,一个是首次响应用户的时延,另一个就是与上一次发送相差的时延,这里我们加一下这个指标:
// 手动生成SSEFirstResponseDuration的桶:从5s开始,每200ms一个间隔
// 5s, 5.2s, 5.4s, ..., 直到需要的范围(这里示例到10s)
var sseFirstResponseBuckets = func() []float64 {var buckets []float64// 从5秒开始start := 5.0// 步长200msstep := 0.2// 生成25个桶,直到10秒(5 + 25*0.2 = 10)for i := 0; i <= 25; i++ {buckets = append(buckets, start+float64(i)*step)}return buckets
}()// 手动生成SSEIntervalDuration的桶:从1s开始,每200ms一个间隔,直到5s
var sseIntervalBuckets = func() []float64 {var buckets []float64// 从1秒开始start := 1.0// 步长200msstep := 0.2// 生成21个桶,直到5秒(1 + 20*0.2 = 5)for i := 0; i <= 20; i++ {buckets = append(buckets, start+float64(i)*step)}return buckets
}()// 定义指标
var (// 首次响应时延直方图SSEFirstResponseDuration = promauto.NewHistogramVec(prometheus.HistogramOpts{Name: "sse_first_response_duration_seconds",Help: "SSE first response duration in seconds",Buckets: sseFirstResponseBuckets,}, []string{"path"}) // 按路径标签区分// 响应间隔时延直方图SSEIntervalDuration = promauto.NewHistogramVec(prometheus.HistogramOpts{Name: "sse_interval_duration_seconds",Help: "SSE response interval duration in seconds",Buckets: sseIntervalBuckets,}, []string{"path"})
)在业务响应逻辑里添加:
// 记录请求开始时间
startTime := time.Now()
path := r.URL.Path
firstResponse := true
lastResponseTime := time.Time{}
for {// 收到响应if firstResponse {duration := time.Since(startTime).Seconds()metrics.SSEFirstResponseDuration.WithLabelValues(path).Observe(duration)firstResponse = falselastResponseTime = time.Now()} else {// 计算并记录响应间隔时间duration := time.Since(lastResponseTime).Seconds()metrics.SSEIntervalDuration.WithLabelValues(path).Observe(duration)lastResponseTime = time.Now()}
}然后在 grafana 上配一下:
sum(irate(sse_first_response_duration_seconds_sum{path="/chat/ai/completions"}[1m])) / sum(irate(sse_first_response_duration_seconds_count{path="/chat/ai/completions"}[1m]))
sum(irate(sse_interval_duration_seconds_sum{path="/chat/ai/completions"}[1m])) / sum(irate(sse_interval_duration_seconds_count{path="/chat/ai/completions"}[1m]))
histogram_quantile(0.95, sum(irate(sse_first_response_duration_seconds_bucket{path="/chat/ai/completions"}[1m])) by (le))
histogram_quantile(0.99, sum(irate(sse_first_response_duration_seconds_bucket{path="/chat/ai/completions"}[1m])) by (le))histogram_quantile(0.95, sum(irate(sse_interval_duration_seconds_bucket{path="/chat/ai/completions"}[1m])) by (le))
histogram_quantile(0.99, sum(irate(sse_interval_duration_seconds_bucket{path="/chat/ai/completions"}[1m])) by (le))
接下来,我们开始进行测试。测试中,我主要关注并发量,即同时能承载多少个请求,满足时延不会恶化。每个并发连接循环利用3次,理论上应该花费一个并发量1次测试的3倍,即150~160s。考虑到之前测出的QPS是大约800,这里我们直接上并发量1000,在测之前,记得把rag.yaml文件的MaxWorkers参数也配置成1000,即rag rpc服务使用1000个线程:
> node .\sse-test.js
[测试开始] 并行数: 1000, 接口: http://localhost:8000/api/v1/chat/ai/completions==================================================
[测试结束] 总耗时: 177.85 秒
[结果统计] 成功: 1000 个, 失败: 0 个
==================================================
所有测试已完全结束,脚本退出
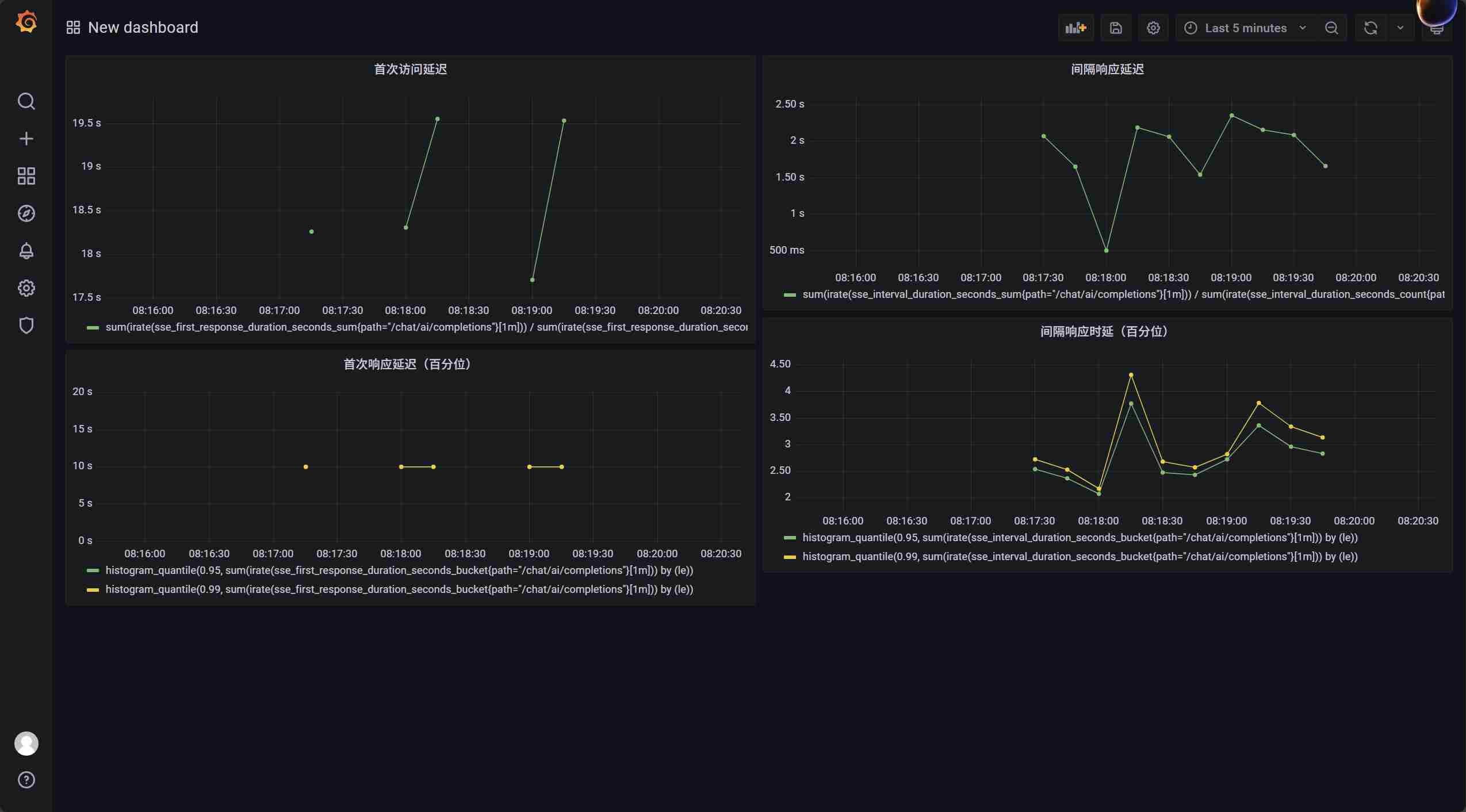
可以看到,不论是首次时延还是间隔时延,在每次1000个请求到来时,都会出现激增的情况。是有什么原因导致的呢?查看硬件资源,可以看到当请求到来的一瞬间,会出现cpu使用率的飙升:
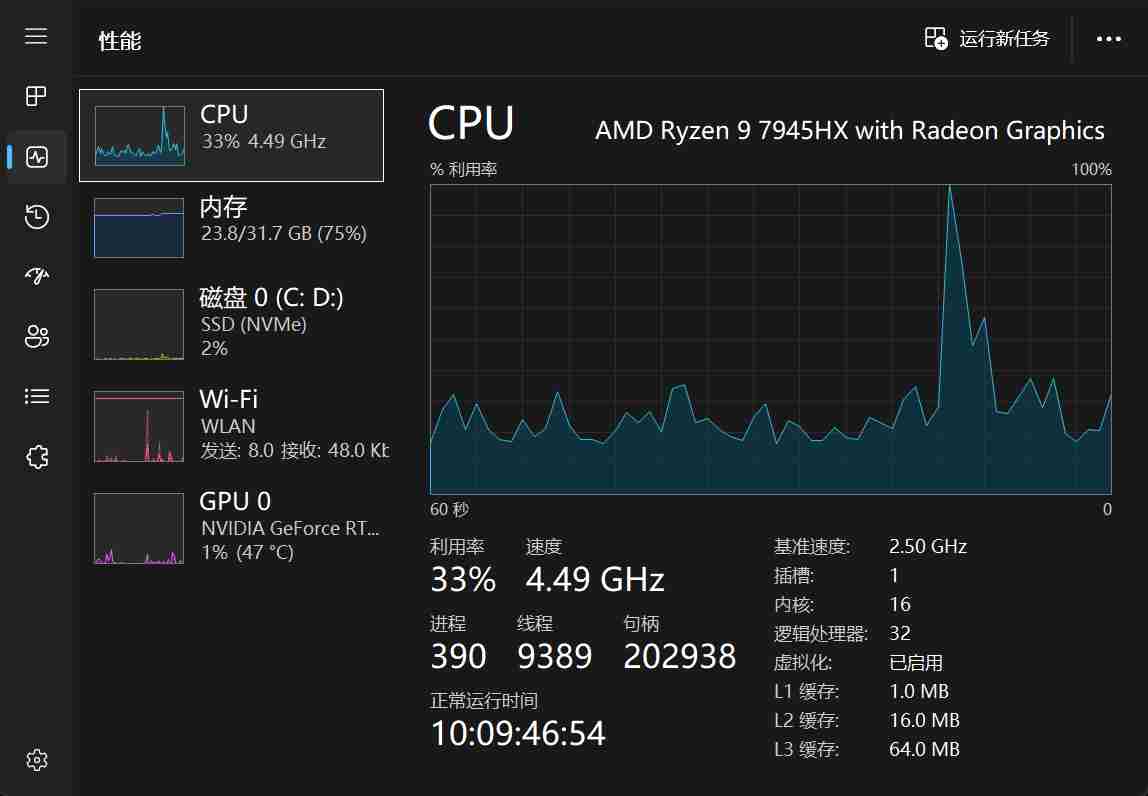
更能具体的,服务飙升来自于rag rpc服务:
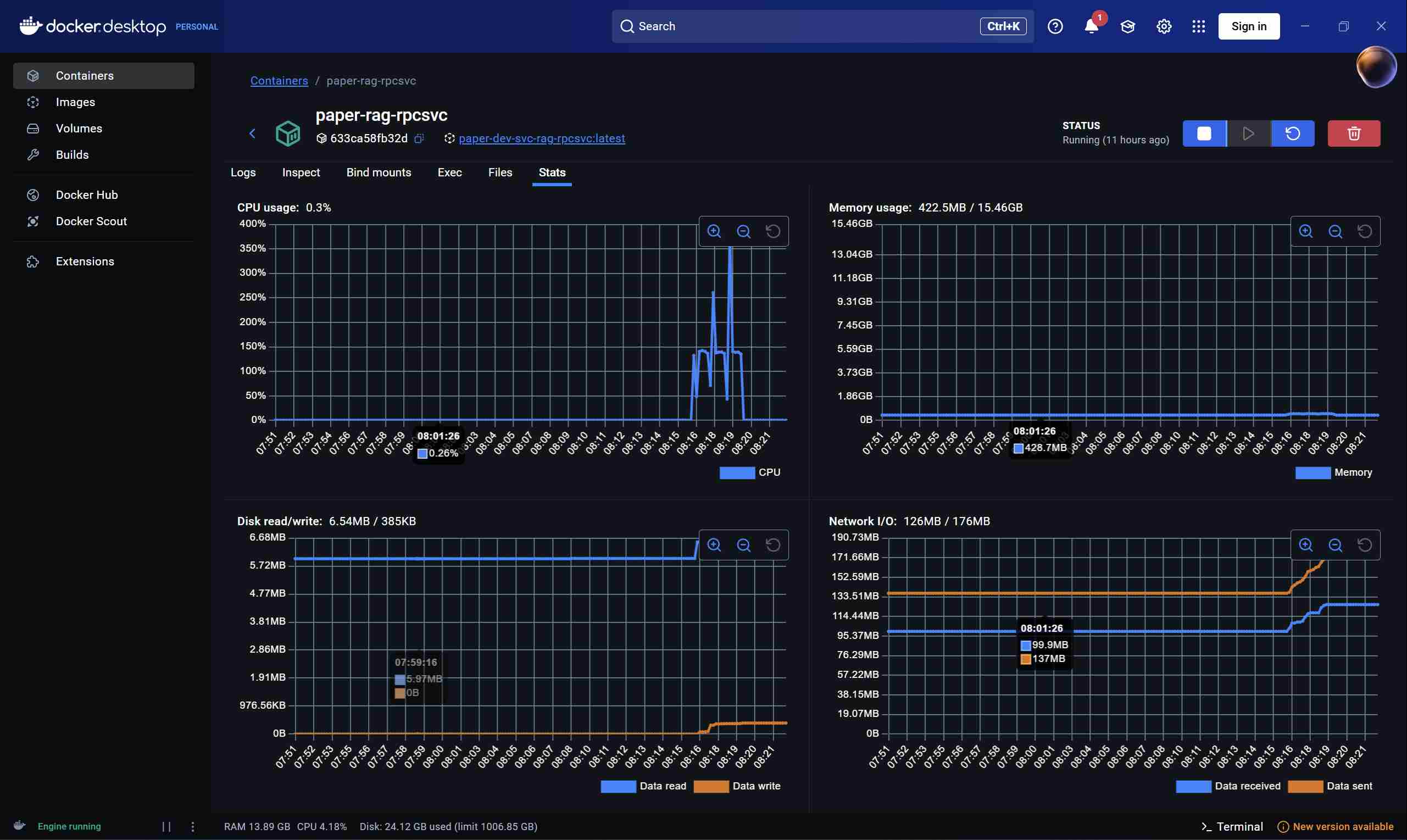
下面再测一次800并发量的,可以看到这时延迟会好一些:
> node .\sse-test.js
[测试开始] 并行数: 800, 接口: http://localhost:8000/api/v1/chat/ai/completions==================================================
[测试结束] 总耗时: 174.76 秒
[结果统计] 成功: 800 个, 失败: 0 个
==================================================
所有测试已完全结束,脚本退出
如果要更具体的分析是那一块导致的cpu使用率飙升,我们可以进到这个容器里面。首先安装ps工具,找出我们的进程是哪一个:
$ docker exec -it paper-rag-rpcsvc /bin/bash
# apt-get update
# apt-get install -y procps
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 2680 1536 ? Ss 06:20 0:00 sh -c python ${PY_ENTRY}
root 7 14.1 2.6 26767916 422616 ? Sl 06:20 21:44 python main.py
root 35311 0.0 0.0 4332 3584 pts/0 Ss 08:46 0:00 /bin/bash
root 35426 0.0 0.0 6396 3584 pts/0 R+ 08:54 0:00 ps aux
从上面的命令可以知道,进程id是7。下面我们使用top -c命令,抓出程序响应请求期间的cpu使用链表情况:
# top -c
top - 08:57:54 up 1 day, 4:37, 0 users, load average: 2.22, 2.04, 2.06
Tasks: 4 total, 1 running, 3 sleeping, 0 stopped, 0 zombie
%Cpu(s): 4.7 us, 3.9 sy, 0.0 ni, 91.1 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 15830.1 total, 271.8 free, 12418.0 used, 3393.1 buff/cache
MiB Swap: 4096.0 total, 4088.7 free, 7.3 used. 3412.1 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7 root 20 0 38.0g 474560 35840 S 135.2 2.9 23:31.55 python main.py
37069 root 20 0 7388 4864 2816 R 0.3 0.0 0:00.03 top -c
1 root 20 0 2680 1536 1536 S 0.0 0.0 0:00.04 sh -c python ${PY_ENTRY}
35311 root 20 0 4332 3584 3072 S 0.0 0.0 0:00.05 /bin/bash
在我测试过程中,进程7显示cpu使用率一直在100~200间,会有瞬时激增的情况,要么有可能是请求到来时线程在创建,要么时调度有较大的性能消耗,当然,程序本身也有可能有问题。我们看一下线程创建的情况:
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
1055
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
1054
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
root@633ca58fb32d:/paper-pro/app/rag# ps -L -p 7 | wc -l
2654
我这边显示,一开始线程数量大约为1000,符合我预先的指定,但是随着800个请求的到来,线程数开始激增,每个请求新创建了2个。再进一步分析就得用Python工具了,这里因为我还没学,分析就到此为止了。
最后,当我设置 MaxWorkers 参数也配置成 1000,但是请求打进来了2000个,会发生什么呢?由于rag rpc服务目前使用的是多线程,而且没有使用多路复用,导致只有1000个线程能被处理,而剩下的1000个线程则得排队,我在网关配了60s超时,一次会话很容易就超过这个时间,导致剩下的1000个请求全部超时。
聊天记录批量收集存储测试
前面我们分析了聊天记录的批量收集和存储功能,地址在项目实战:批量插入聊天记录方案及性能分析-CSDN博客
之前的性能测试中,我们测得每条聊天记录的平均插入时间约为17.8微妙,即能支持每秒大约5万条消息。不过之前我们用的是阉割版本,这里我们从kafka推送任务开始测,并观察一下批量收集存储的效果。
首先我们准备一个简单的生产者:
package testimport ("context""encoding/json""sync""testing""time"kqtypes "paper-pro/app/chat/jobs/types""github.com/google/uuid""github.com/zeromicro/go-queue/kq"
)var KqPusherClient *kq.Pusherfunc kqChatMsg(role string) []byte {kqMsg := kqtypes.KqChatMsg{Content: "test content",Role: role,ChatAt: time.Now().Unix(),DialogId: "68c573f58af546d70967c123",UserId: 1,RequestId: uuid.New().String(),}msgBytes, _ := json.Marshal(kqMsg)return msgBytes
}func TestMain(m *testing.M) {KqPusherClient = kq.NewPusher([]string{"127.0.0.1:9094"}, "chat-msgs-insert")defer KqPusherClient.Close()m.Run()
}func BenchmarkPushKq(b *testing.B) {taskCh := make(chan struct{}, 5)var wg sync.WaitGroupfor i := 0; i < 5; i++ {wg.Add(1)go func() {defer wg.Done()for {_, ok := <-taskChif !ok {return}msg1, msg2 := kqChatMsg("user"), kqChatMsg("ai")ctx, cancel := context.WithTimeout(context.Background(), time.Second*3)if err := KqPusherClient.Push(ctx, string(msg1)); err != nil {b.Errorf("push err: %+v", err)}if err := KqPusherClient.Push(ctx, string(msg2)); err != nil {b.Errorf("push err: %+v", err)}cancel()}}()}b.ResetTimer()for i := 0; i < b.N; i++ {taskCh <- struct{}{}}close(taskCh)wg.Wait()b.StopTimer()
}
执行测试,同时测试性能(当然,目前只开了一个分区,如果是分布式环境下有多个分区,吞吐量会更大):
> go test -bench ^BenchmarkPushKq$ -benchtime 10000x -count 2
goos: windows
goarch: amd64
pkg: paper-pro/app/chat/test
cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
BenchmarkPushKq-8 10000 202923 ns/op
BenchmarkPushKq-8 10000 304458 ns/op
PASS
ok paper-pro/app/chat/test 5.558s
上面的方法,相当于在5.5s内,我一口气向kafka插入了4万条俩天记录。查看期间kafka消息堆积情况:
$ ./kafka-consumer-groups.sh --bootstrap-server paper-kafka:9092 --group ChatMsgConsumer --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
ChatMsgConsumer chat-msgs-insert 0 500557 501842 1285 main@6278afc95d9e (github.com/segmentio/kafka-go)-db6f35fb-c946-449a-b724-27248f469068 /172.16.0.25 main@6278afc95d9e (github.com/segmentio/kafka-go)$ ./kafka-consumer-groups.sh --bootstrap-server paper-kafka:9092 --group ChatMsgConsumer --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
ChatMsgConsumer chat-msgs-insert 0 515561 515561 0 main@6278afc95d9e (github.com/segmentio/kafka-go)-db6f35fb-c946-449a-b724-27248f469068 /172.16.0.25 main@6278afc95d9e (github.com/segmentio/kafka-go)
可以看到,执行期间略有堆积,不过还是很快就消费完了。当然和之前仅仅是插入一条聊天记录的简单情况不同,在实际服务中,我们还会做很多事,比如要从kafka拉取数据,比如要对数据解码json格式变成go的结构体,比如插入数据时,同时需要插入索引,以及我还会更新会话数据库中的时间。
文件上传功能性能测试
因为我在文件上传中加了限速,所以上传速度这个性能没啥好测的,当然,也可以不断提高限速看看服务器到底支持多高的限速。这里我更关注的是内存,我在项目中做了优化,从paperfile-api到paperfile-rpc到minio数据库全程用的都是流式数据,也就是说按理不会出现太多的内存拷贝操作,我们下面来实际测测看看效果怎么样。
首先将限速放开至10M/s(原来是1M/s),同时将后面的解析任务推到 kafka 队列的部分给注释掉,同时也将对用户限制并发量的中间件也去掉,如果出现超时,将上传文件接口的超时也加一下。下面我们准备一个脚本,上传100个Attention Is All You Need.pdf文件,该文件约2.11M,也就是说在我的限速下,大约21s能上传完:
import os
import time
import argparse
import asyncio
import aiohttp
from concurrent.futures import ThreadPoolExecutor
from aiohttp import FormData
from tqdm import tqdm
import random"""
使用方法:
1. pip install aiohttp tqdm
2. 运行脚本,例如:100个总请求,使用10个线程:python test_upload.py "C:/Users/yuk/Desktop/Attention Is All You Need.pdf" http://127.0.0.1:8000//api/v1/paper/file/upload "your-auth-token" -t 100 -th 10
"""# 全局进度条和计数器
progress_bar = None
total_success = 0
total_fail = 0async def upload_single_file(session, file_path, upload_url, headers, index):"""单个文件上传的异步任务"""global total_success, total_failtry:# 读取文件内容with open(file_path, 'rb') as f:file_content = f.read()# 准备表单数据data = FormData()data.add_field('file', file_content,filename=f"{random.randint(1, 65535)}-"+os.path.basename(file_path),content_type='application/pdf')# 发送POST请求async with session.post(upload_url, headers=headers, data=data, timeout=60) as response:# 读取响应内容response_text = await response.text()# 检查状态码if response.status == 200:try:# 尝试解析JSON响应result = await response.json()if result.get('code') == 200:total_success += 1progress_bar.update(1)return (index, True, "上传成功")else:total_fail += 1progress_bar.update(1)print(f"服务器返回错误: {result.get('msg', '未知错误')}")return (index, False, f"服务器返回错误: {result.get('msg', '未知错误')}")except:total_fail += 1progress_bar.update(1)print(f"服务器返回非JSON响应: {response_text[:100]}")return (index, False, f"服务器返回非JSON响应: {response_text[:100]}")else:total_fail += 1progress_bar.update(1)print(f"HTTP状态码错误: {response.status}, 响应: {response_text[:100]}")return (index, False, f"HTTP状态码错误: {response.status}, 响应: {response_text[:100]}")except Exception as e:total_fail += 1progress_bar.update(1)print(f"上传发生异常: {str(e)}")return (index, False, f"上传发生异常: {str(e)}")async def async_task(file_path, upload_url, headers, tasks_per_thread):"""每个线程执行的异步任务"""async with aiohttp.ClientSession() as session:# 为当前线程创建指定数量的任务tasks = [upload_single_file(session, file_path, upload_url, headers, i)for i in range(tasks_per_thread)]await asyncio.gather(*tasks)def thread_worker(file_path, upload_url, headers, tasks_per_thread):"""线程工作函数,运行异步事件循环"""asyncio.run(async_task(file_path, upload_url, headers, tasks_per_thread))def multithread_async_upload(file_path, upload_url, auth_token, total_requests, thread_count):"""多线程结合异步的上传函数"""# 检查文件是否存在if not os.path.exists(file_path):print(f"错误: 文件 {file_path} 不存在")return# 检查文件是否为PDFif not file_path.lower().endswith('.pdf'):print(f"错误: {file_path} 不是PDF文件")return# 设置请求头headers = {'Authorization': f'Bearer {auth_token}','Accept': 'application/json'}global progress_bar, total_success, total_failtotal_success = 0total_fail = 0print(f"开始多线程异步上传测试...")print(f"总请求数: {total_requests}, 线程数: {thread_count}")# 计算每个线程需要处理的任务数tasks_per_thread = total_requests // thread_countremaining_tasks = total_requests % thread_count # 分配剩余的任务# 创建进度条progress_bar = tqdm(total=total_requests, desc="上传进度")start_time, end_time = None, None# 创建线程池with ThreadPoolExecutor(max_workers=thread_count) as executor:# 记录开始时间start_time = time.time()# 提交任务到线程池futures = []for i in range(thread_count):# 为最后几个线程分配剩余的任务tasks = tasks_per_thread + (1 if i < remaining_tasks else 0)futures.append(executor.submit(thread_worker, file_path, upload_url, headers, tasks))# 等待所有线程完成for future in futures:future.result()end_time = time.time()# 计算总耗时total_duration = end_time - start_time# 关闭进度条progress_bar.close()# 输出统计信息print("\n上传测试完成!")print(f"总请求数: {total_requests}")print(f"成功数: {total_success}")print(f"失败数: {total_fail}")print(f"成功率: {total_success/total_requests*100:.2f}%")print(f"总耗时: {total_duration:.2f} 秒")print(f"平均每秒处理: {total_requests/total_duration:.2f} 个请求")print(f"平均每个请求耗时: {total_duration/total_requests:.4f} 秒")if __name__ == "__main__":# 解析命令行参数parser = argparse.ArgumentParser(description='多线程结合异步的PDF高并发上传测试工具')parser.add_argument('file_path', help='PDF文件的本地路径')parser.add_argument('upload_url', help='服务器上传接口的URL')parser.add_argument('auth_token', help='用于认证的令牌')parser.add_argument('-t', '--total', type=int, default=100, help='总请求数量,默认100次')parser.add_argument('-th', '--threads', type=int, default=5, help='线程数量,默认5个线程')args = parser.parse_args()# 运行多线程异步上传任务multithread_async_upload(file_path=args.file_path,upload_url=args.upload_url,auth_token=args.auth_token,total_requests=args.total,thread_count=args.threads)执行脚本前先抓取一下内存(在这这之前,先在paperfile-api和paperfile-rpc服务加一下pprof监听):
> curl http://127.0.0.1:6061/debug/pprof/heap?gc=1 -o heap6061-1.out
> curl http://127.0.0.1:6062/debug/pprof/heap?gc=1 -o heap6062-1.out
然后启动测试,测试期间抓取内存:
> python test_upload.py "C:/Users/yuk/Desktop/Attention Is All You Need.pdf" http://127.0.0.1:8000//api/v1/paper/file/upload eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODk0Mzg5ODAsImlhdCI6MTc1NzkwMjk4MCwiand0VXNlcklkIjoxfQ.5TCxhCRE997gHbJfne4Qma7zCrkYl26xhjCWYgluMlU -t 100 -th 10
开始多线程异步上传测试...
总请求数: 100, 线程数: 10
上传进度: 100%|██████████████████████████████████████████████████████████| 100/100 [00:22<00:00, 4.51it/s]上传测试完成!
总请求数: 100
成功数: 100
失败数: 0
成功率: 100.00%
总耗时: 22.19 秒
平均每秒处理: 4.51 个请求
平均每个请求耗时: 0.2219 秒
可以看到,执行时间还是和我们之前估计得差不多的。在期间抓取内存:
curl http://127.0.0.1:6061/debug/pprof/heap -o heap6061-2.out
curl http://127.0.0.1:6062/debug/pprof/heap -o heap6062-2.out
最后对比执行前和执行期间的内存增加:
> go tool pprof -base heap6061-1.out heap6061-2.out
File: main
Build ID: 22984244ec26e098d64ee7ed392d167ad4225880
Type: inuse_space
Time: 2025-09-23 15:58:30 CST
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 17061.29kB, 88.98% of 19175.09kB total
Showing top 10 nodes out of 46
flat flat% sum% cum cum%
16579.84kB 86.47% 86.47% 17604.19kB 91.81% paper-pro/app/paperfile/api/internal/logic/paperfile.(*UploadLogic).Upload
-544.67kB 2.84% 83.63% -544.67kB 2.84% compress/flate.(*compressor).initDeflate (inline)
514kB 2.68% 86.31% 514kB 2.68% bufio.NewReaderSize
512.25kB 2.67% 88.98% 512.25kB 2.67% go.opentelemetry.io/otel/sdk/trace.(*evictedQueue).add (inline)
-512.23kB 2.67% 86.31% -512.23kB 2.67% compress/flate.newHuffmanBitWriter (inline)
512.10kB 2.67% 88.98% 512.10kB 2.67% google.golang.org/grpc.(*clientStream).newAttemptLocked
0 0% 88.98% -1056.90kB 5.51% bufio.(*Writer).Flush
0 0% 88.98% -1056.90kB 5.51% compress/flate.(*compressor).init
0 0% 88.98% -1056.90kB 5.51% compress/flate.NewWriter (inline)
0 0% 88.98% -1056.90kB 5.51% compress/gzip.(*Writer).Write
可以看到,api服务中主要的增长正是来自于paperfile.(*UploadLogic).Upload方法,约有16M,考虑到每个请求我都会准备一个1M的缓存,并且令牌桶限流器的最大同行速率是10M的2倍即20M,我认为这个结果也合理,可以进一步看看内存的分配情况:
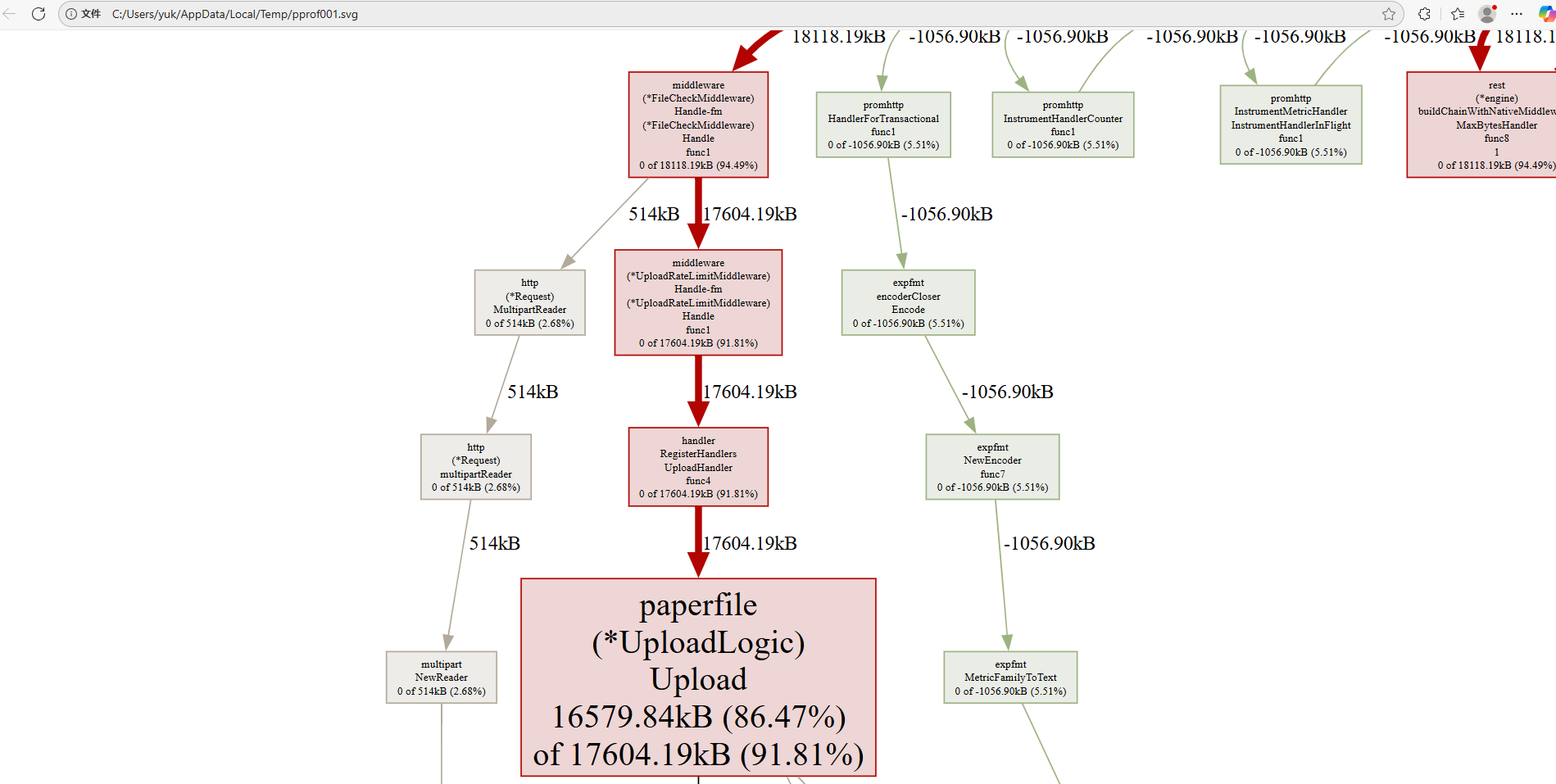
可以看到,有514k分配到了文件检查中间件中,这个中间件要读取512k的内容,用于校验文件魔数,所以这个内存分配合理,剩下的内存则都集中在了Upload方法中,如我们前面的分析所示。
下面我们再来看看rpc服务的情况:
> go tool pprof -base heap6062-1.out heap6062-2.out
File: main
Build ID: 45b4b101ed735e0458880f5521efaf03bf82b636
Type: inuse_space
Time: 2025-09-23 15:58:40 CST
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 2.06GB, 99.79% of 2.07GB total
Dropped 46 nodes (cum <= 0.01GB)
Showing top 10 nodes out of 21
flat flat% sum% cum cum%
2.06GB 99.79% 99.79% 2.06GB 99.81% github.com/minio/minio-go/v7.(*Client).putObjectMultipartStreamNoLength
0 0% 99.79% 2.06GB 99.81% github.com/minio/minio-go/v7.(*Client).PutObject
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.(*circuitBreaker).DoWithAcceptable
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.(*googleBreaker).doReq
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.DoWithAcceptable
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.DoWithAcceptable.func1 (inline)
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.do (inline)
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/core/breaker.loggedThrottle.doReq
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/zrpc/internal/serverinterceptors.StreamBreakerInterceptor
0 0% 99.79% 2.06GB 99.83% github.com/zeromicro/go-zero/zrpc/internal/serverinterceptors.StreamBreakerInterceptor.func1
可以看到,运行期间内存至少多出了惊人的2.06G,是 2.11M*100的10倍,并显示多出的方法在putObjectMultipartStreamNoLength。其余的地方都为0,这说明我们的流式传输几乎是没有造成什么消耗。不过还是不能排除我使用方式有错误的可能。
考虑到这里内存大的可怕,为了排除内存泄漏的可能,我们当执行完后,强制gc再抓一次内存:
> go tool pprof heap6062-3.out
File: main
Build ID: 45b4b101ed735e0458880f5521efaf03bf82b636
Type: inuse_space
Time: 2025-09-23 16:38:20 CST
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 7677.90kB, 71.41% of 10751.54kB total
Showing top 10 nodes out of 121
flat flat% sum% cum cum%
1539kB 14.31% 14.31% 1539kB 14.31% runtime.allocm
1536.28kB 14.29% 28.60% 1536.28kB 14.29% go.opentelemetry.io/otel/trace.attributeOption.applyEvent
902.59kB 8.39% 37.00% 1451.43kB 13.50% compress/flate.NewWriter
548.84kB 5.10% 42.10% 548.84kB 5.10% compress/flate.(*compressor).initDeflate (inline)
532.26kB 4.95% 47.05% 532.26kB 4.95% github.com/gogo/protobuf/proto.RegisterType
532.26kB 4.95% 52.00% 532.26kB 4.95% github.com/xdg-go/stringprep.map.init.2
532.26kB 4.95% 56.95% 532.26kB 4.95% google.golang.org/protobuf/reflect/protoregistry.(*Types).register
522.70kB 4.86% 61.82% 522.70kB 4.86% github.com/google/gnostic-models/openapiv2.init
517.33kB 4.81% 66.63% 517.33kB 4.81% go.opentelemetry.io/otel/sdk/trace.(*recordingSpan).interfaceArrayToEventArray
514.38kB 4.78% 71.41% 514.38kB 4.78% runtime/metrics.runtime_readMetrics
可以看到内存最终还是释放了。如果要进一步排查这里的内存异常,可能得深入到minio的go客户端框架,这里因为时间关系,我就不再继续分析了。