视觉大模型:Qwen-VL 技术报告解读
原文:<<Qwen-VL: AVersatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond>>, arXiv引用:(13 Oct 2023, Cited by 4493)
效果如图:

传统 LLM(如 GPT 系列、Qwen-LM)虽然在文本生成和理解上表现强大,但局限于纯文本世界,无法处理视觉、语音、视频等多模态信息。可将视觉感知能力融入 LLM,实现VLM, 但现有开源 LVLMs 普遍存在优化不充分,性能落后于闭源模型,且缺乏对 细粒度视觉理解,如目标定位、光学字符识别(OCR-Optical Character Recognition)的支持。
Qwen-VL在 Qwen-7B 基础上扩展视觉能力,构建高性能、多用途的视觉语言基础模型,集成多种能力 (captioning, VQA, OCR, document understanding, grounding),在多样化任务上取得强性能(涌现能力),弥补开源 VLMs 在精细理解和任务泛化上的不足。
Qwen-VL 可以归纳为三部分:
- 多任务通用视觉语言模型 (Multi-task Generalist Models): 把不同视觉语言任务统一到一个框架里。
- 视觉-语言表示学习 (Vision-Language Representation Models): 学到强大的跨模态表示,能迁移到下游任务, 这里主要指CLIP。
- 基于 LLM 的视觉模型,VLMs (Large Vision-Language Models with LLMs)
- 涌现能力
“涌现能力”(emergent abilities):是近年来在讨论大规模人工智能模型(尤其是大语言模型 LLMs)时常用的一个概念。当模型规模(参数量、训练数据量等)足够大时,会出现一些在小规模模型上 没有显现,但在大模型上 突然表现出来 的能力。这些能力不是直接通过训练目标“显式教会”的,而是随着模型容量和数据量的增长 自发涌现 出来的。
- 算术能力
小模型几乎无法做两位数加减法,但大模型在训练目标并没有“专门教算术”的情况下,突然能稳定地做多位数运算。
- 逻辑推理
小模型生成的逻辑链条很混乱,而大模型在一定规模后能生成看似连贯的推理步骤。
- 翻译/跨语言能力
即便没有专门对某种语言进行大量训练,大模型也能学会基本的跨语言翻译。
- 指令遵循(instruction following)
小模型往往只能模仿文本,大模型却能理解用户意图并按照指令调整回答。
学术观点:
* 复杂性理论视角:能力并不是线性增长的,而是当模型规模超过某个临界点,参数空间和数据表达能力足以支持新行为时,能力会突然“跳出来”。
* 信息压缩/泛化能力:模型在大规模训练下学到更通用的表示,当这些表示的丰富度到达一定程度,新的任务能力就能自然浮现。
* 分布外泛化:大模型能从训练数据中提炼模式,外推到训练时没显式出现过的任务。
- 模型结构
模型有三个子模块:
- 大语言模型 (LLM): 为 Qwen-7B 预训练权重,负责处理文本输入与视觉-文本特征对齐后的综合token推理。- 视觉编码器 (Visual Encoder):用预训练CLIP的ViT-bigG,采用 patch 分块(步长 14),将图像转化为特征序列,输入图像统一缩放到固定分辨率。- 位置感知的视觉-语言适配器 (Position-aware Vision-Language Adapter): * 压缩机制:单层 cross-attention,一组可训练的向量(queries),通过交叉注意力机制,将视觉编码器输出的长序列图像特征(keys)压缩成一个固定长度(256)的较短序列,随后被送入大语言模型进行进一步处理。* 位置信息: 为了避免在压缩过程中丢失重要的空间位置信息,交叉注意力机制中加入<2D绝对位置编码>,实现精细图像理解。
-
规模参数 (原文Table 1)
-
视觉编码器:1.9B 参数
-
VL 适配器:0.08B 参数
-
LLM (Qwen-7B):7.7B 参数
-
总计:约 9.6B 参数
- 训练过程
Qwen-VL 的训练分为 三阶段:
- 预训练(Pre-training)
- 多任务预训练(Multi-task Pre-training)
- 监督微调(Instruction Fine-tuning)
如图: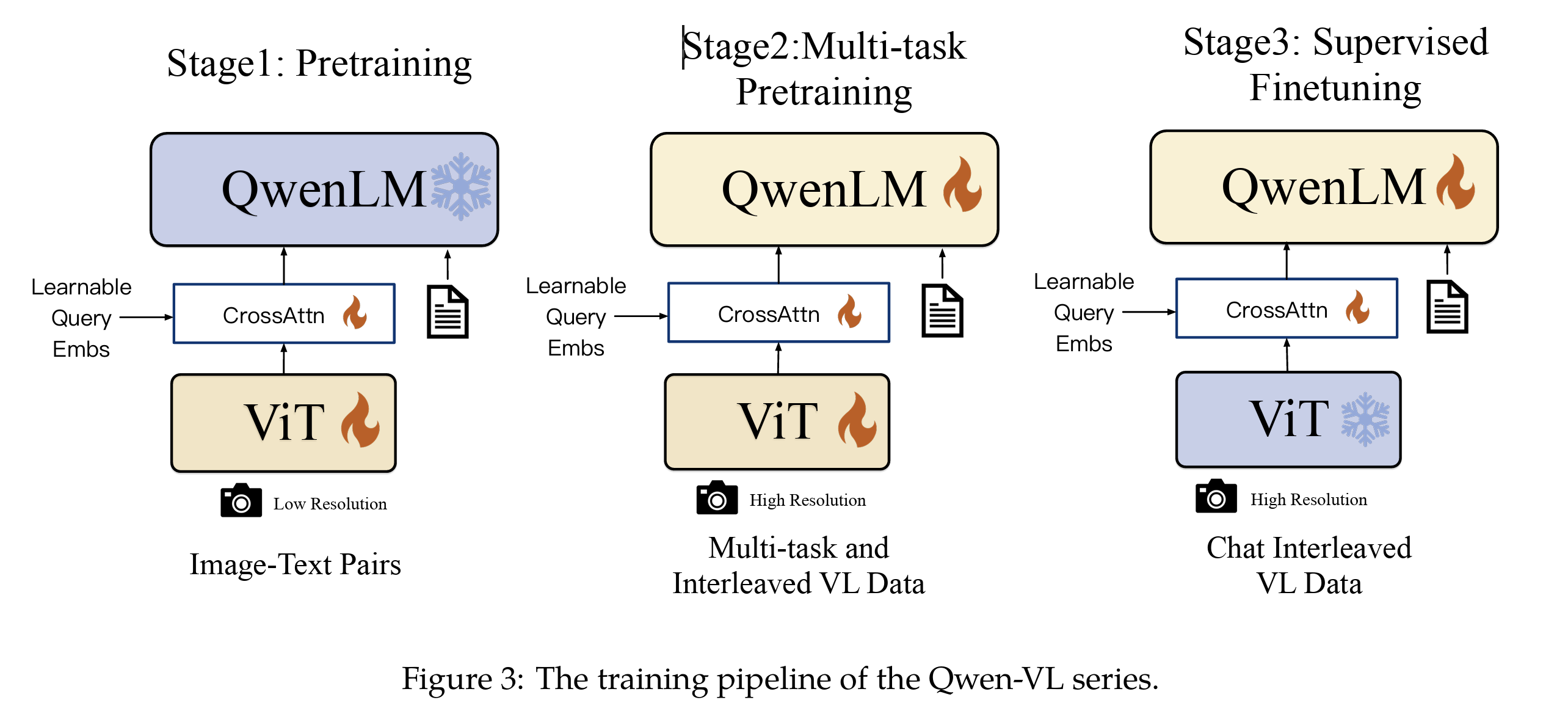
1. 第一阶段:预训练(Pre-training)
-
数据: 大规模、弱标注的图像-文本对
- 大规模开放集:LAION-en、LAION-zh、LAION-COCO、DataComp、Coyo。
- 学术数据:CC12M、CC3M、SBU、COCO Caption。
- 自建数据:In-house
数据清洗: 原始数据集总计约 50 亿对,经过清洗后,保留了 14 亿对(1.4B, 约28*),其中 77.3% 是英文,22.7% 是中文,去除不合适的模式和内容。具体如下:
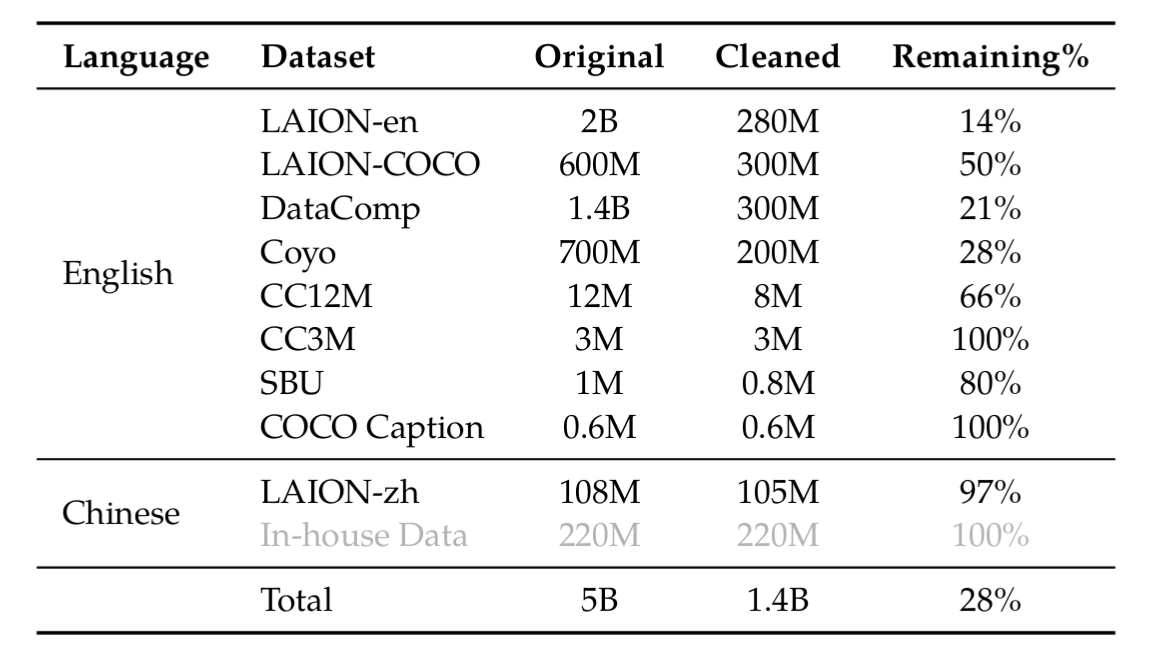
-
训练目标:
- 冻结: LLM,优化:VL 适配器,视觉编码器。
- 分辨率: 输入图像被调整为 224×224 像素。
- 学习目标: 最小化文本标记的交叉熵。
- 学习率:2e-4;batch size = 30,720;训练 50k 步,约 1.5B 图文-文本样本。
-
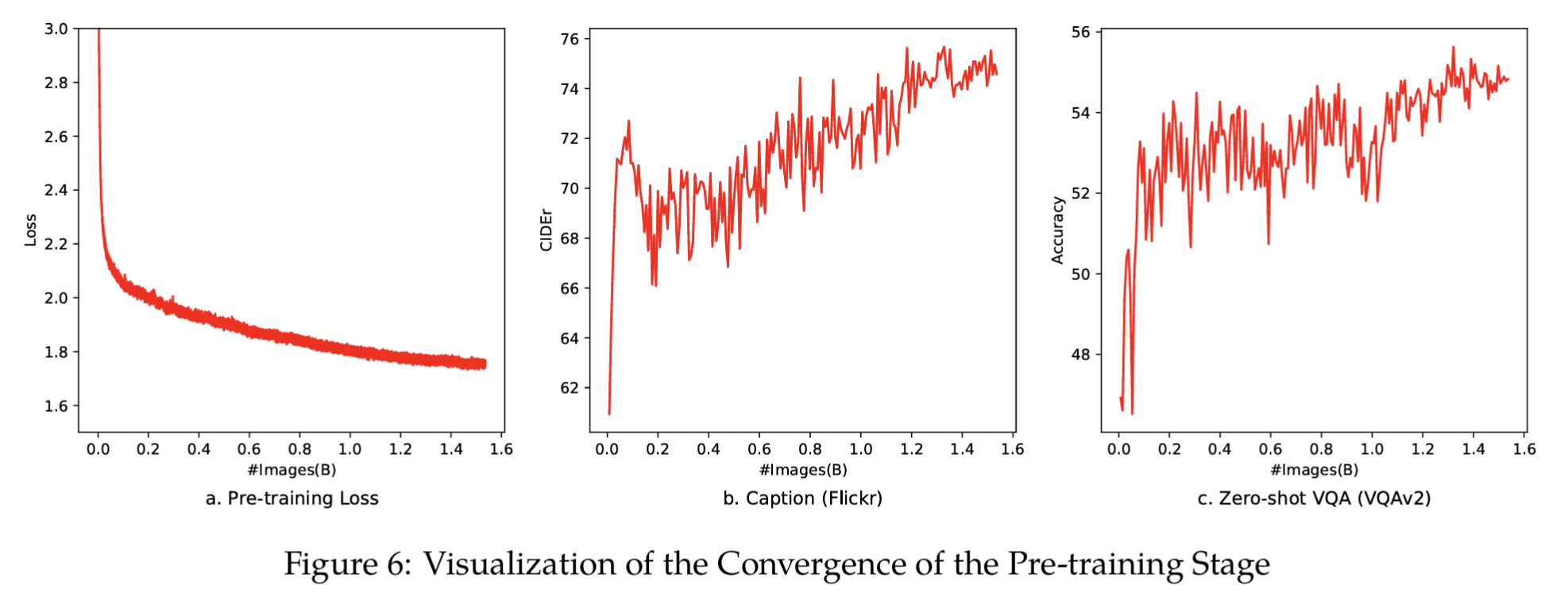
收敛性观察
- loss 随训练样本数单调下降 → 表明数据质量足够支撑大规模收敛。
- Caption 任务(Flickr CIDEr 指标)也稳步提升。
- 训练没有使用 VQA 数据,但 Zero-shot VQA 准确率在训练中上升
这表明通过大规模图像-文本对的学习,模型可掌握图像-文本关联性,具备初步问答能力, 即涌现能力。
2. 第二阶段:多任务预训练(Multi-task Pre-training)
多任务精调 (multi-task pre-training),引入更高质量、更细粒度的标注数据,让模型学会更复杂的视觉-语言(VL)任务。
2.1 训练:
* 三个子模块,全参训练
* 高分辨率: 输入图像的分辨率提高到 448×448,以减少下采样带来的信息损失。
* 输入序列长度 2048,支持交错图文输入。
* 学习目标: 学习目标与第一阶段相同, 都是预训练Qwen-VL。
2.2 VIT消融实验
作者测试了WindowAttention 与 Global Attention 在 两个448 × 448 (196 patch) or 896 × 896 (784 patch) 分辨率下的实验。
VIT是16x16一个patch(类似文本的一个token)
其计算消耗如下:
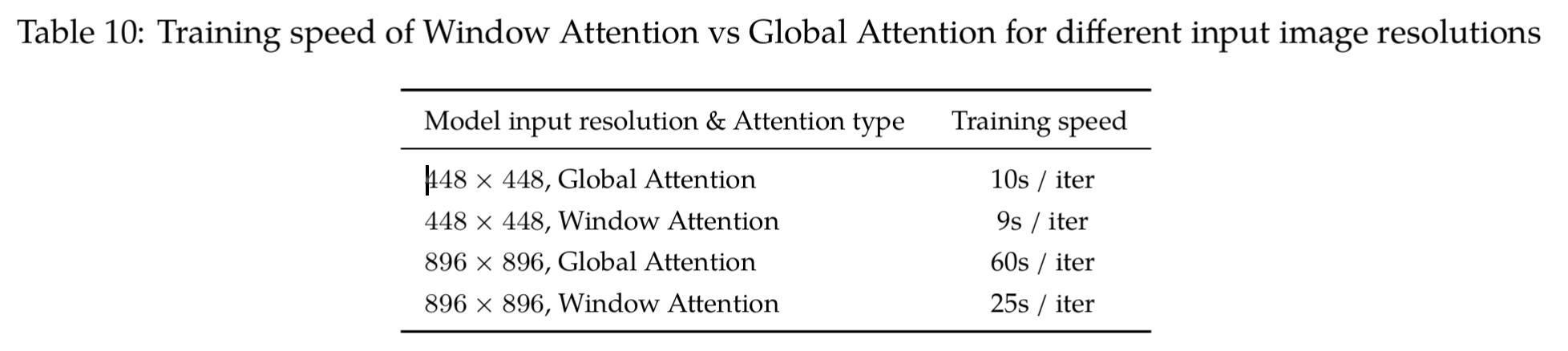
其他的loss对比:
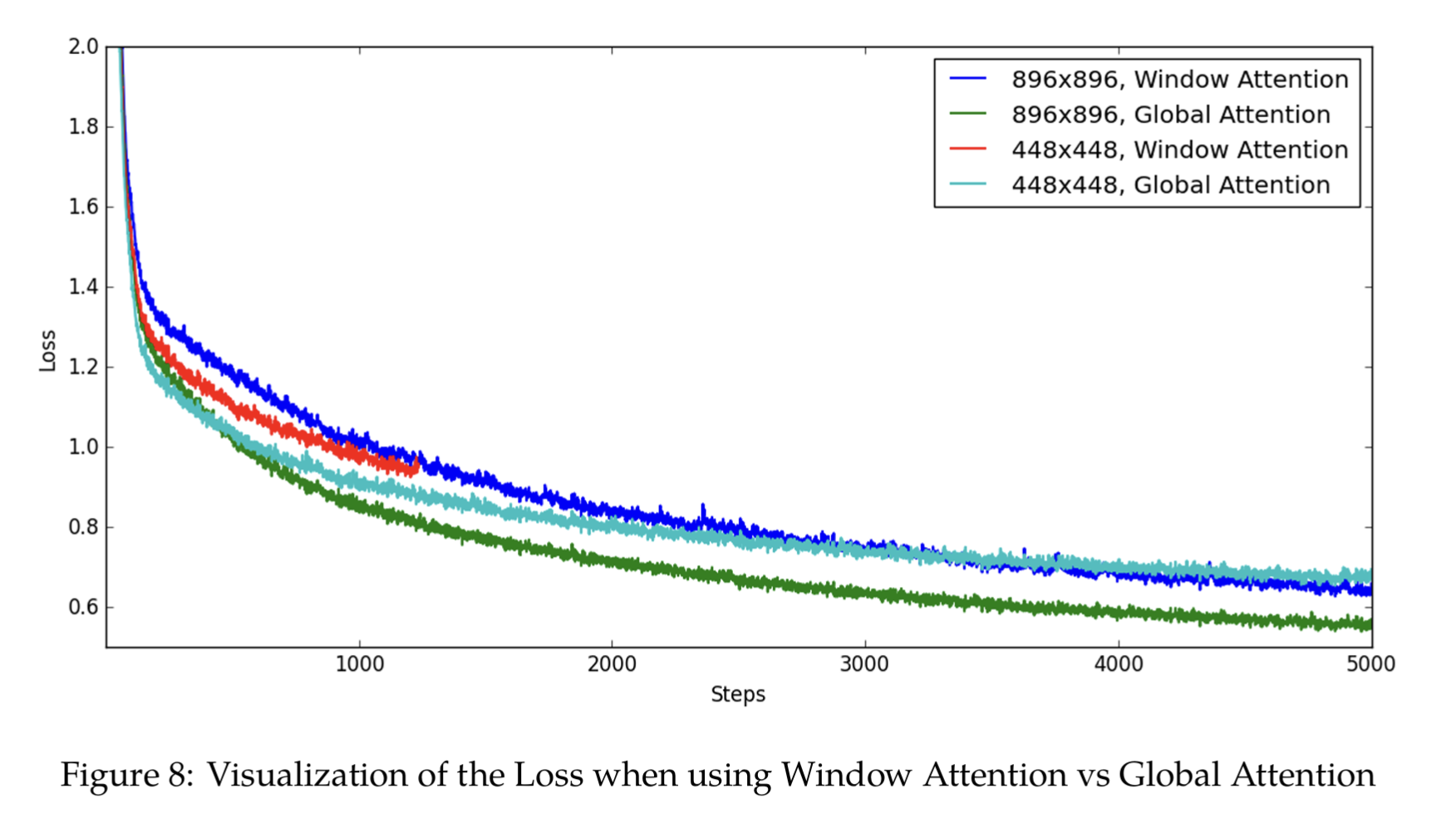
考虑到896 × 896 较大的计算开销,且global性能要好于window,因此作者选择448x448分辨率图像作为输入,选择global attention作为模型attention layer。
2.2 数据
该阶段引入了高质量、精细标注的视觉语言数据,并支持图文交错的数据格式。
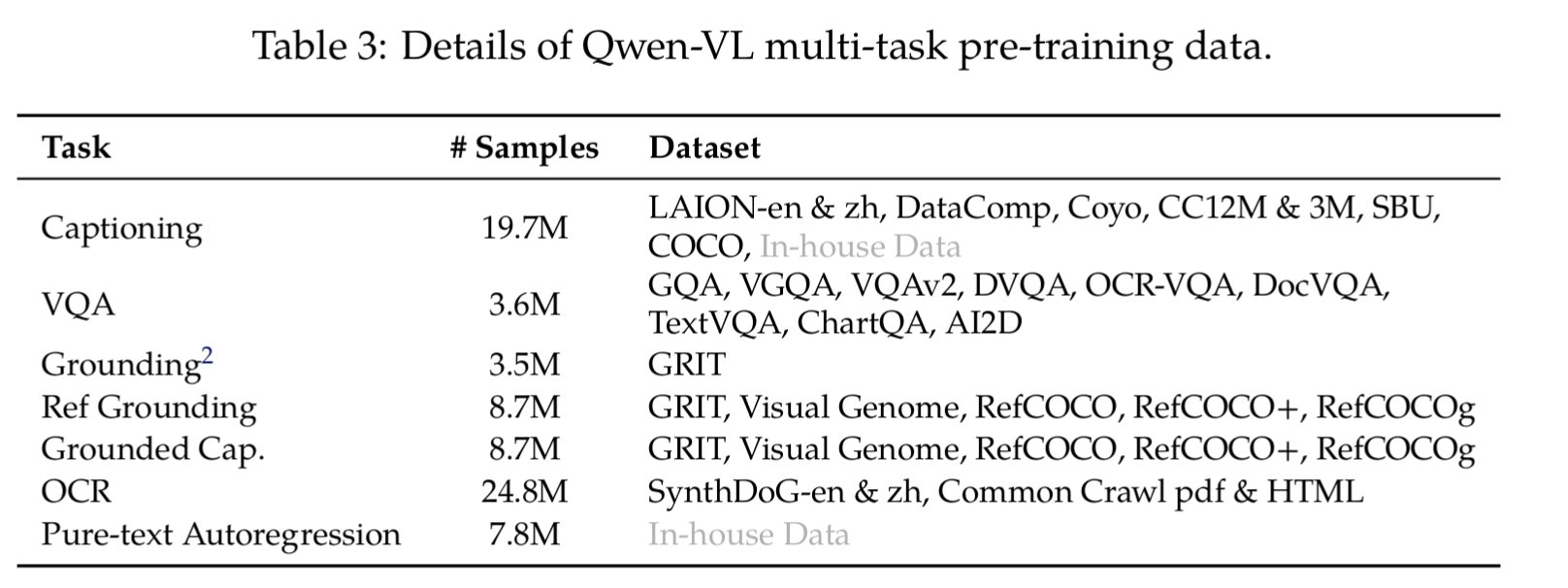
同时训练来完成如下任务,约 76.8M 样本,具体任务数据包括:
-
纯文本自回归 (Pure-text Autoregression)
使用自有数据,目的是在多模态训练中 保持大型语言模型(LLM)的语言能力,防止其退化。
-
图像描述 (Captioning)
与第一阶段相似但样本数量更少的高质量数据集COCO。
-
视觉问答 (VQA)
混合多个公开VQA数据集,用于训练模型回答关于图像内容的问题。
GQA、VGQA、VQAv2、DVQA、OCR-VQA、DocVQA、TextVQA、ChartQA、AI2D -
定位 (Grounding) / 参考定位 (Reference Grounding) / 定位描述 (Grounded Captioning)
教会模型识别和定位图像中的特定物体。
RefCOCO、RefCOCO+、RefCOCOg、Visual Genome
定位的三种输入-输出格式:- Grounding
- 输入:文本片段(word/phrase) + 图像
- 输出: 边界框
- Reference Grounding
- 输入:referring expression(一句话,如 “the man in the red shirt holding a cup” ) + 图像
- 输出: 边界框
- Grounded Captioning
- 输入:图像
- 输出:caption + 对应区域的 bounding box
- Grounding
-
光学字符识别 (OCR)
收集 PDF/HTML 数据并合成 OCR 数据,旨在提高模型对图像中文字的识别和理解能力。
- SynthDoG-en/zh,Common Crawl PDF/HTML
- 输入:图片(自然场景 / 文档截图),
- 输出:转录的文本(可能带 标签),
- 扩展:有时附带 bounding box + 文本对齐,用 和坐标表示:
<box>(120,80),(240,110)</box> Deep<box>(250,80),(400,110)</box> Learning…
- SynthDoG-en/zh,Common Crawl PDF/HTML
-
交错式图像-文本数据 (Interleaved image-text data):
将同一任务的数据打包成序列(长度为2048),以训练模型处理更复杂的、多图-文混排的场景。
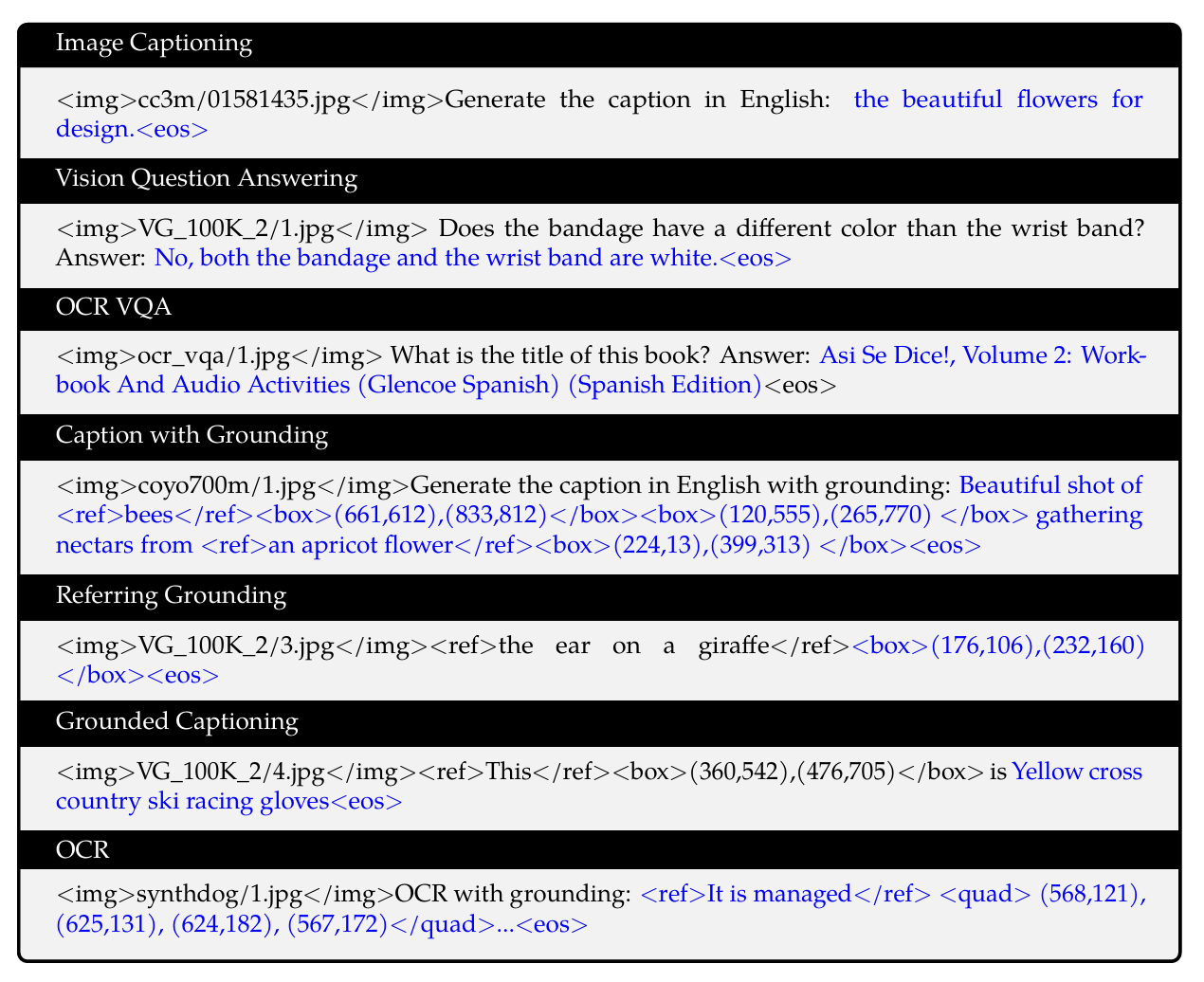
2.3 数据格式
-
所有任务(7种)都被组织成类似「指令 + 输入 + 输出」的序列。
-
自回归目标:predict next token,只在蓝色部分计算 loss,保持语言建模的方式。
-
文本部分则分为两种颜色,以字符串直接作为文本 token 处理,无需额外的 positional vocabulary:
- 黑色文字 → 前缀(prefix),模型只读,不计算 loss。
- 蓝色文字 → ground truth label,模型需要预测,计算 loss。
·
- 特殊标记设计,含区域级(region-level)描述、检测任务:
- 图像用 <img>path</img> 形式标记,作为视觉输入。显式区分 图像特征 与 文本特征。
- 和 :用于关联边界框与对应的文本描述,实现区域与语言的显式对齐。
- 和 :用于标识边界框字符串,区分于普通文本。边界框表示:
- 坐标归一化到区间 [0,1000)。
- 转化为字符串格式 “(X_topleft, Y_topleft), (X_bottomright, Y_bottomright)”。
如图:
2.4 多模态处理
<img>cc3m/01581435.jpg</img> 只是占位符, 其处理过程如下:
-
读取图像:从路径 cc3m/01581435.jpg 加载图像,即像素矩阵。
-
调整大小 & 预处理:将图像缩放到固定分辨率 448×448,归一化到 [0,1] 或标准化到 [−1,1]。
-
切分 Patch:以 16×16 = 1 patch,则448 ÷ 16 = 28 → 总共 28×28 = 784 个 patch。
-
每个 patch 展平后形成向量(长度 16×16×3 = 768)。
-
线性映射:每个 patch 通过一个 线性层 投影到固定维度(如 768 或 1024)。
-
2D 位置编码(告诉模型每个 patch 在图像中的位置),结果是一串 embedding,形状大约是 [784, d]。
-
进入视觉编码器 (Vision Transformer, ViT-bigG)
- 784 个向量作为输入 token 序列,经过多层自注意力和 MLP 处理。
- 输出的embedding 向量表示整张图像的信息。
.
-
和文本 token 融合
- 加一对 <img> <\img>来作为图像整体表征。
- 图像输入(patch embedding)与文本输入(token embedding)拼接,形成一个统一序列。
- 一起送进Qwen ( LLM backbone ) 输出文本。
3. 第三阶段:监督微调(Supervised Fine-tuning)
- 目标: 生成具有对话能力的模型 Qwen-VL-Chat,以增强其指令遵循和对话交互能力。
- 训练目标: 冻结视觉编码器,优化 LLM 和 adapter。
3.1 数据(约 350k):
- 来自图像描述和通过 LLM 自我指令生成的对话数据,caption/dialogue。
- 加入人工标注 + 模型生成 + 策略拼接,扩展到 定位(grounding)和多图像对话。
- 训练数据中还混合了多模态和纯文本对话数据,确保模型对话泛化能力。
- 处理方式
- 角色标记: 每个对话轮次都用 <im_start> 和 <im_end> 特殊标记进行封装,清晰地界定用户(user)和助手(assistant)的发言。
- 多图像输入: 为了处理多张图像,每张图片前都加上了 Picture id: 标签,例如 Picture 1: <img>…</img>和 Picture 2: <img>…</img>。这使得模型可以轻松地区分和关联对话中提到的不同图片。
如图,蓝色部分为预测即参与损失计算部分:

4.评测(Evaluation)
4.1 整体性能
如图:
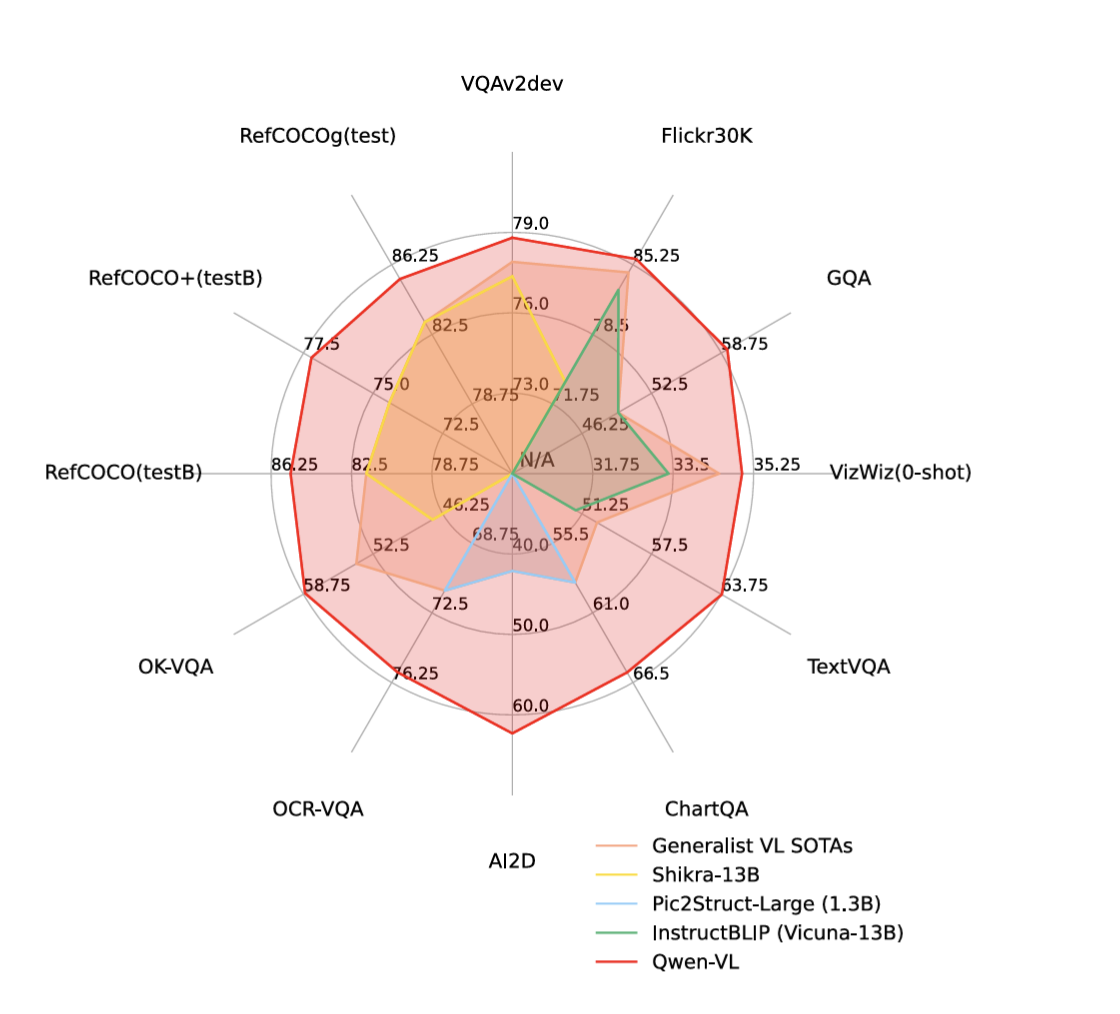
综合性能好于同期模型,其中指标解析:
4.2 Caption 与 VQA
4.2.1 任务定义
- Image Captioning:给定一张图片,生成英文描述。
- General VQA(视觉问答):给定图片+问题,生成答案。
- Text-oriented VQA:回答图像中与<文本相关>的问题,如识别图表、文档、书本或海报上的文字。
4.2.2 评测结果
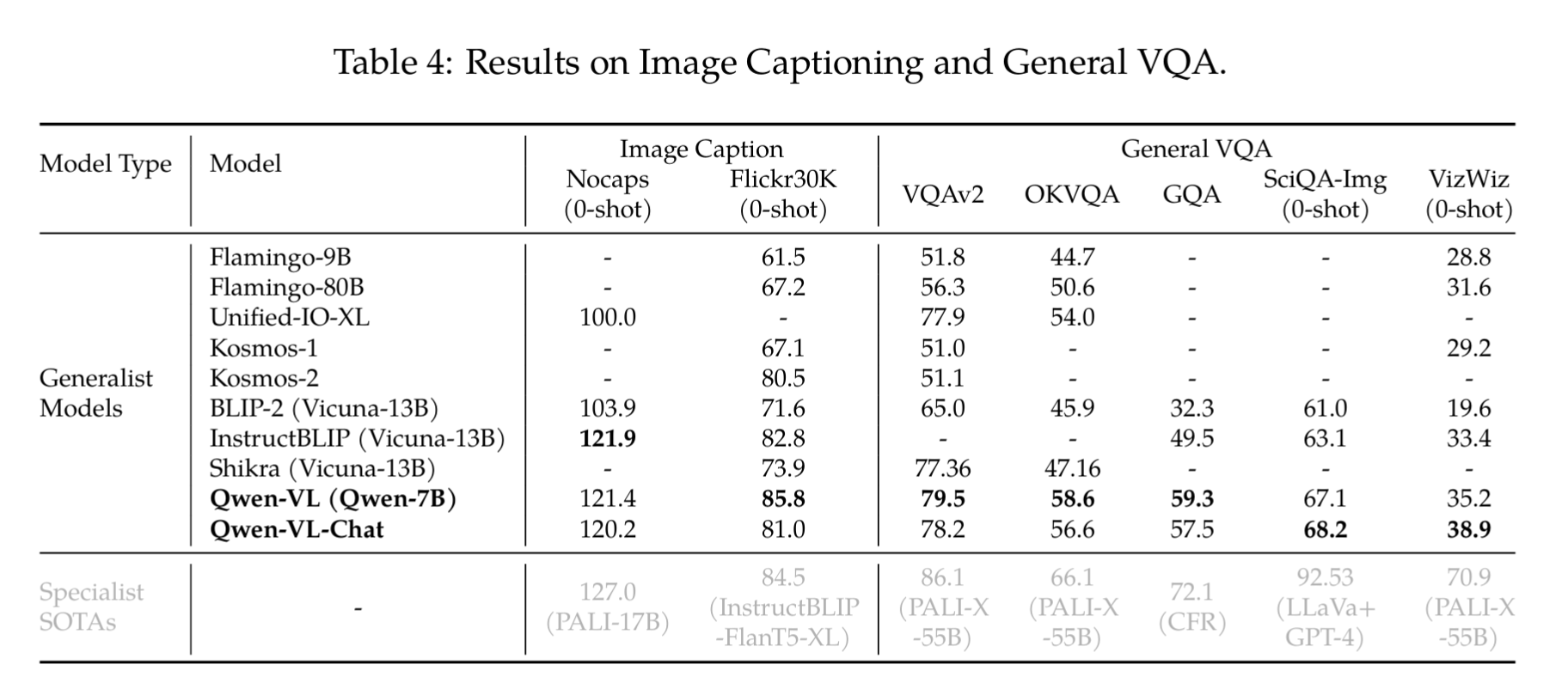
- 图像描述 (Image Captioning ):
- NoCaps 基准(零样本): 评估模型对未见过场景的描述能力。
- Flickr30K 基准(零样本): 评估模型在更通用的图像集上的描述能力。
结论:Qwen-VL 表现突出: 在 Flickr30K 数据集上取得了 85.8 的 CIDEr 分数,显著优于所有对比的通用模型,包括参数量更大的 Flamingo-80B。
- 通用视觉问答 (General VQA):
- 基准VQAv2, OKVQA, GQA: 评估模型对常见视觉场景的理解和问答能力。
- 基准ScienceQA-Img: 评估模型在科学图表和概念上的推理能力。
- 基准VizWiz: 评估模型在低质量、有缺陷的真实世界图像上的问答能力。
结论:
- Qwen-VL 在 VQAv2、OKVQA 和 GQA 上都取得了显著优于其他近期 LVLM(大型视觉语言模型)的性能。
- 强大的零样本能力: 在 ScienceQA 和 VizWiz 这两个极具挑战性的数据集上
- 模型差异: Qwen-VL 在 VQA 任务上通常比 Qwen-VL-Chat 表现更好。这是因为 Qwen-VL 是一个预训练模型,在 VQA 这种标准任务上经过了专门的训练和优化。而 Qwen-VL-Chat 是一个微调模型,其微调目标是对话,这可能导致其在标准 VQA 任务上的表现略有下降。
- 面向文本的视觉问答 (Text-oriented VQA)
- 评测基准: TextVQA、DocVQA、ChartQA、AI2Diagram、OCR-VQA。
结论:Qwen-VL 在大多数面向文本的 VQA 任务上都明显优于之前的通用模型,这得益于其第二阶段的多任务预训练(特别是 OCR 任务),强化了模型对图像中文字的理解能力。
4.3 指称理解 (Refer Expression Comprehension)
-
任务定义:给定一张图像和一段描述性文字,识别出文字所指代的物体,并输出其边界框(bounding box)。
-
评测数据集:
- RefCOCO, RefCOCO+, RefCOCOg:这些是标准的指称理解数据集,包含各种描述类型,从简单到复杂(例如,RefCOCOg 的描述通常更模糊或更通用)。
- GRIT:一个更具挑战性的数据集,用于评估模型在更细粒度的视觉和语言理解上的能力。
-
实验设置
- 模型输入:图像 + 文字描述
- 模型输出:目标框(bounding box)位置或对应区域标记
- 评价指标:精度或 IoU 等标准定位指标(表中数值一般为百分比,越高越好)
全面领先:Qwen-VL在所有四个基准测试(RefCOCO, RefCOCO+, RefCOCOg 和 GRIT)上都取得了顶尖(top-tier) 的结果。
显著优势:与之前的通用模型(如 VisionLLM, Shikra)相比,Qwen-VL 的表现有明显优势。例如,在 RefCOCO test-A 上,Qwen-VL-7B 的准确率达到92.26%,高于 Shikra-7B 的90.61%。
与专家模型的差距:尽管Qwen-VL表现出色,但与专门为指称理解任务设计的专家模型(如 UNINEXT 和 ONE-PEACE)相比,仍存在一些差距。这表明Qwen-VL作为通用模型,在多任务预训练中获得了强大的定位能力,但与为特定任务进行高度优化的模型相比,仍有提升空间。
结论:
相比其他模型,Qwen-VL 在所有 REC benchmark 上都是 top-tier,说明其通用模型也能具备较强定位能力,其中:
- 精细化理解能力强:Qwen-VL 能够根据文字描述精确定位目标,说明多任务预训练 + 微调能提升多模态语义理解能力。
- 对话微调影响小:Qwen-VL-Chat 在 REC 表现略低,但仍优秀,说明加入对话能力不会严重损害定位能力。
- 与专门为指称理解任务设计的专家模型(如 UNINEXT 和 ONE-PEACE)相比,仍存在一些差距,仍有提升空间。
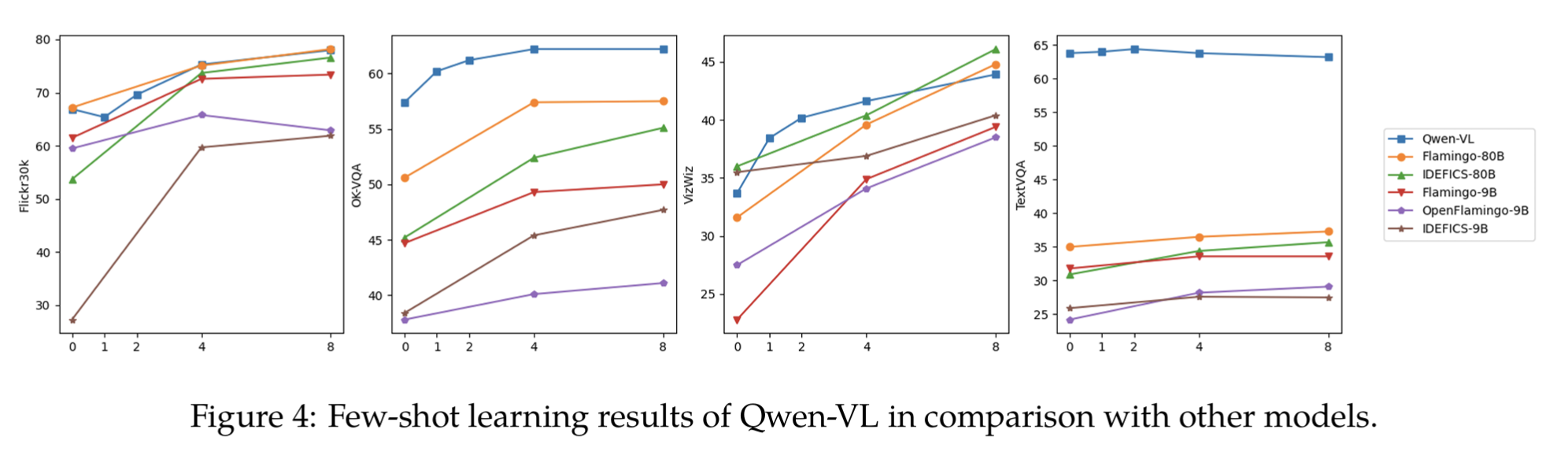
4.4 少样本学习 (Few-shot Learning on Vision-Language Tasks)
该部分评测Qwen-VL,任务包括Image Captioning和VQA:
-
少样本学习定义:给出少数几个示例(exemplars),让模型完成新任务。即不进行梯度更新,只利用上下文信息预测。
-
评测基准:
-
Flickr30K:图像描述(Image Captioning)基准,用于衡量模型能否将视觉信息准确地转化为流畅的自然语言。其图片质量高,内容丰富,涵盖了各种日常场景和人物互动。
-
OKVQA: 评估认知能力。视觉常识和开放域知识推理,即否能像人类一样,将图像信息与脑海中的知识库联系起来,进行推理和回答。例如,一张图片是艾菲尔铁塔,问题可能是:“这座建筑在哪里?” 模型需要知道艾菲尔铁塔在巴黎。
-
VizWiz:评估真实世界不完美视觉挑战。在像质量差,低质量、有缺陷的图像上进行视觉问答。图片可能模糊、光线不足、角度倾斜或不完整。
-
TextVQA:评估跨模态能力。识别图像中的文字并进行问答。比如广告牌、路标、菜单或书本封面上的文字。模型需要先进行光学字符识别(OCR),然后理解这些文字来回答问题,看它能否同时处理视觉信息(图像)和其中的语言信息(文字),并将两者结合起来解决任务。
结果:
-
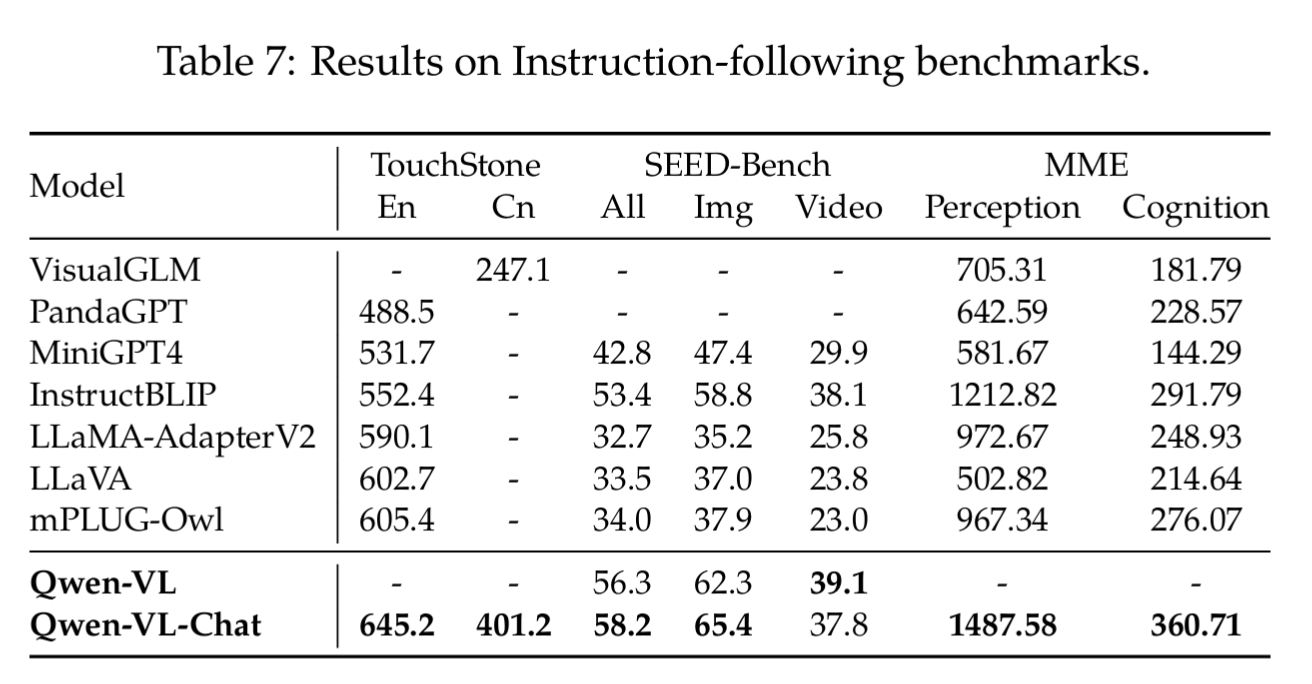
4.5 指令遵循能力-真实用户场景 (Instruction Following in Real-world User Behavior)
该部分主要评测Qwen-VL-Chat,基准如下:
* TouchStone:综合指令遵循能力* Qwen-VL-Chat 在该基准上取得了 645.2 的最高分数,明显高于其他所有模型。这表明 Qwen-VL-Chat 在理解和执行开放式指令方面表现最佳。* 值得注意的是,表格还给出了中文(Cn)分数 401.2,这在很大程度上解释了其在 TouchStone 上的优势,因为其他大多数模型主要以英文为主,或中文能力较弱。* SEED-Bench:视频与多模态理解* Qwen-VL-Chat 在 SEED-Bench 的总分(58.2)上再次领先,特别是在中文(65.4)表现上,这再次凸显了其强大的多语言能力。* 印证了文章提到的一个重要发现:Qwen-VL-Chat 可以通过简单地对视频进行帧采样,有效将其视觉能力迁移到视频任务上。* MME:感知与认知能力* MME 基准将能力分为感知(Perception) 和认知(Cognition) 两大类。* Qwen-VL-Chat 在感知(1487.58)和认知(360.71)的总分上都取得了最高分。这表明模型不仅能识别图像中的物体和细节(感知),还能进行更深层次的分析、推理和问答(认知)。
结果如图:
4.6 纯文本任务表现(Performance on Pure-text Tasks)
研究Qwen-VL 在加入视觉信息后,是否会降低原有的文本理解能力(即 catastrophic forgetting)。
-
评估目的: 探讨多模态训练是否会损害模型的纯文本能力。这是一种常见的担忧,因为引入新的数据格式(图像)可能会导致模型“遗忘”(即 catastrophic forgetting) 其在文本上学到的知识。
-
模型基础: Qwen-VL与Qwen开发周期同步,因此其使用 Qwen-7B 的一个中间版本作为其语言模型的初始化。这很重要,因为它意味着 Qwen-VL 的纯文本能力基线是那个中间版本的 Qwen-7B,而不是最终发布的版本。
-
数据策略: 为了防止灾难性遗忘,研究团队在多任务训练和监督微调(SFT)阶段,除了视觉-语言数据,还特意加入了纯文本数据进行训练。
-
评测基准:
- MMLU:大规模多任务语言理解。
- CMMLU:中文大规模多任务语言理解。
- C-Eval:中文评估基准。
结果如表11:
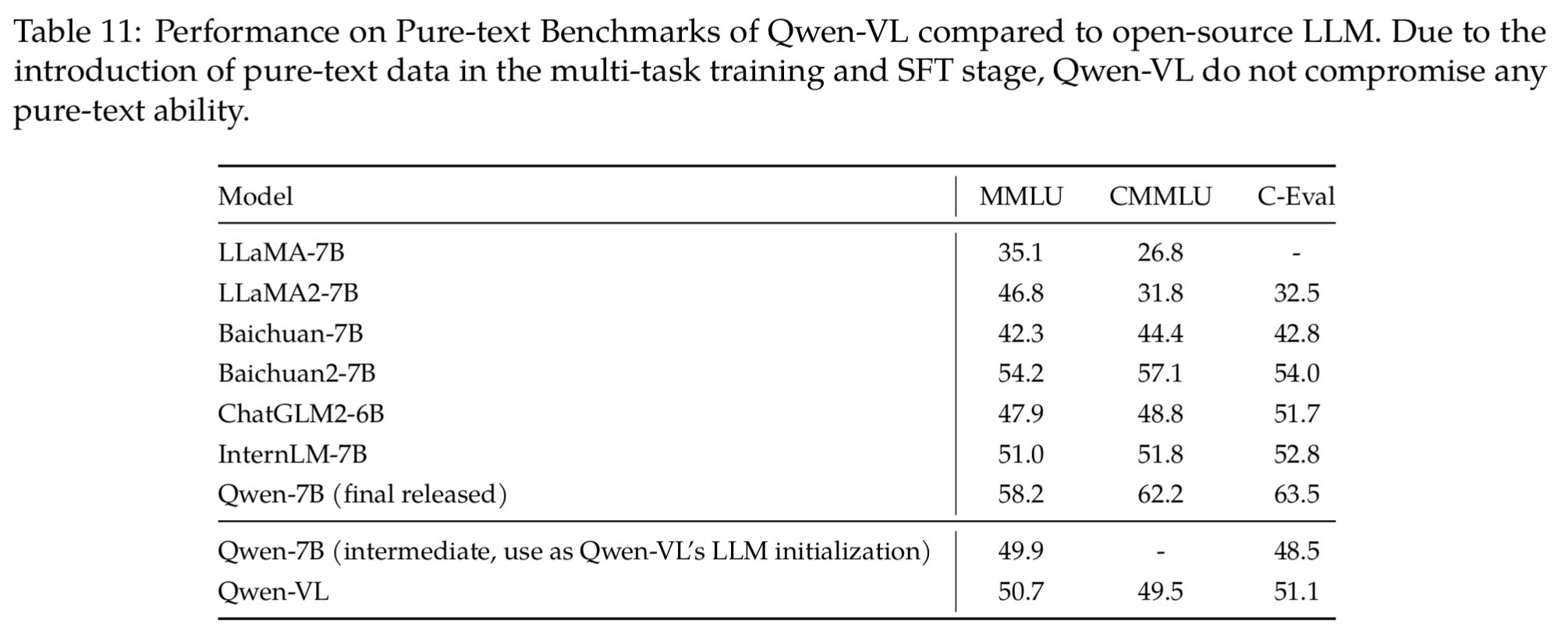
结论:
- 无性能下降:从 Table 11 可以看出,Qwen-VL 在所有三个纯文本基准测试上的分数(MMLU 51.1,CMMLU 62.2,C-Eval 54.0)都高于其初始化的 Qwen-7B 中间版本(MMLU 48.5,CMMLU 49.9,C-Eval 51.7)。
- 甚至有所提升:这个结果表明,多模态训练不仅没有导致纯文本能力的妥协,反而通过整合多模态和纯文本数据,增强了模型的语言理解能力,尤其是在 MMLU 和 CMMLU 上,提升非常明显。
5. 模型细节
5.1 模型参数配置
- 视觉编码器:ViT-G/14 (来自 CLIP-bigG)
- LLM:Qwen-7B
- VL Adapter init: 一个随机化参数的Cross-Attention
5.2 三个训练阶段
-
Pre-training(第一阶段预训练)
- 目标:节省算力,快速预训练。用大规模 image-text pair 学到基础的视觉—语言对齐能力
- 视觉输入:224×224 图像分辨率 → ViT 输出 256 个 token
- LLM 输入:最大序列长度 512
- Adapter:256 个 learnable queries(视觉压缩 token)
- 训练配置:
- AdamW(β1=0.9, β2=0.98, eps=1e−6)
- 学习率 2e−4 → 1e−6,cosine decay,warmup 500 steps
- ViT 用 layer-wise learning rate decay = 0.95(靠近输入层的更新更小)
- batch size = 30720(超大批次)
- steps = 50k,相当于用 15 亿 image-text pair / 5000 亿 token
- 一阶段仅训练了一轮epoch多一点:
- batch size= 30720
- iteration:50k step
- training samples = 30720×50000 = 1.536B
- 训练数据总量=1.4B,即epoch = 1.536/1.4 = 1.0972 epoch
- 作用:训练一个基础的 VL 对齐模型,先把图文 embedding 对齐好。
-
Multi-task Pre-training(第二阶段多任务预训练)
- 目标:高分辨率输入,保留更多视觉细节。在多模态任务上进一步提升泛化能力
- 视觉输入:分辨率升级到 448×448 → ViT 输出 1024 个 token
- LLM 输入:最大序列长度 2048(更长上下文)
- Adapter:256 个 learnable queries(压缩 1024 → 256)
- 训练配置:
- AdamW(同上)
- 学习率 5e−5 → 1e−5,cosine decay,warmup 400 steps
- batch size = 4096
- steps = 19k
- 使用 model parallelism(分别在 ViT 和 LLM 上做并行)
- 作用:解锁整个 LLM + ViT 一起训,全面提升跨模态能力。
-
Supervised Fine-tuning(第三阶段监督微调 / 指令微调)
- 目标:通过指令数据(Instruction tuning)提升对话式和任务式能力
- 视觉输入:448×448
- LLM 输入:2048
- Adapter:256 queries
- 训练配置:
- AdamW(同上)
- 学习率 1e−5 → 1e−6,warmup 3k steps(更长预热)
- batch size = 128(小批次)
- steps = 8k
- 作用:对齐人类指令,变成 Chat 模型。
总结:
第一阶段Pre-train :粗调,低分辨率,短序列,最大数据量,学习率最大 (2e−4)
第二阶段Multi-task:高分辨率,长序列,适中 batch,较小学习率(5e−5)
第三阶段指令微调(SFT):高分辨率,长序列,小 batch,最小学习率(1e−5, 避免灾难性遗忘)
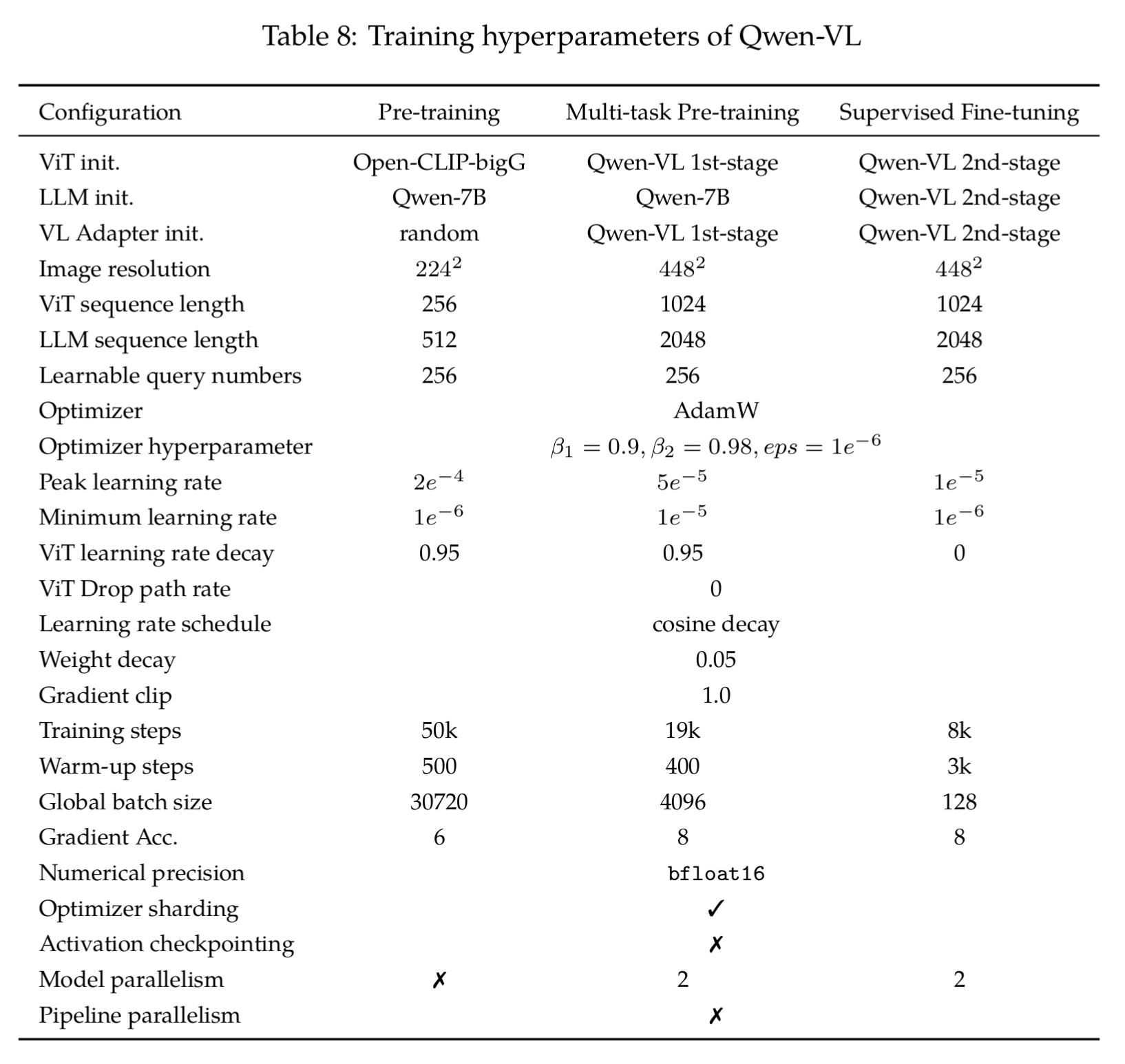
参数解释:
- 初始化
- Qwen-VL 1st-stage = 得到的 checkpoint
- Qwen-VL 2nd-stage = 第二阶段(多任务预训练)得到的 checkpoint
- Qwen-VL-Chat 是 在 Qwen-VL 2nd-stage 上做 SFT 微调得到的最终对话模型
5.3适配器(Vision-Language Adapter):
这里是一个单层 cross-attention,一组可训练的向量(queries)。本节介绍为何通过交叉注意力机制,将视觉编码器输出的长序列图像特征(keys)压缩成一个固定长度(256)的较短序列,方便被进LLM进行处理。
5.3.1 压缩图像
第一阶段使用 ViT-L/14,用于跨模态表征
- patch 大小是 14×14
- 输入分辨率是 224×224
- 图像被分割为 224×224 / 14×14 = 256个patch embedding(即token)
假设每个token的维度是 768,则patch_embedding.shape = (256, 768)
5.3.2 压缩token
- Learnable queries
Learnable queries 数量 = 压缩后的视觉 token 数
直接把 256 个视觉 token 全部交给语言模型,会导致输入太长,计算量大,而且和语言 token 的融合不一定高效。
这里设计 N 个 Learnable queries(比如 L=64, 144, 256, 400), 作为「信息槽位」,即压缩。
L数量的分析如下:
- L = 64 → 压缩成 64 个 token,信息更少但更轻量, 压缩到很精炼,但可能会丢失很多重要细节。
- L = 256 -> 和原始token数量一样多,无压缩,即不丢失信息。
- L =400 → 扩展成 400 个 token
这比原始token数量还多,能保留更多细节,也可能导致信息冗余抓不到重点,且计算量大,收敛慢
5.2.3 Learnable queries实验分析
L数量通过实验分析, 如表:
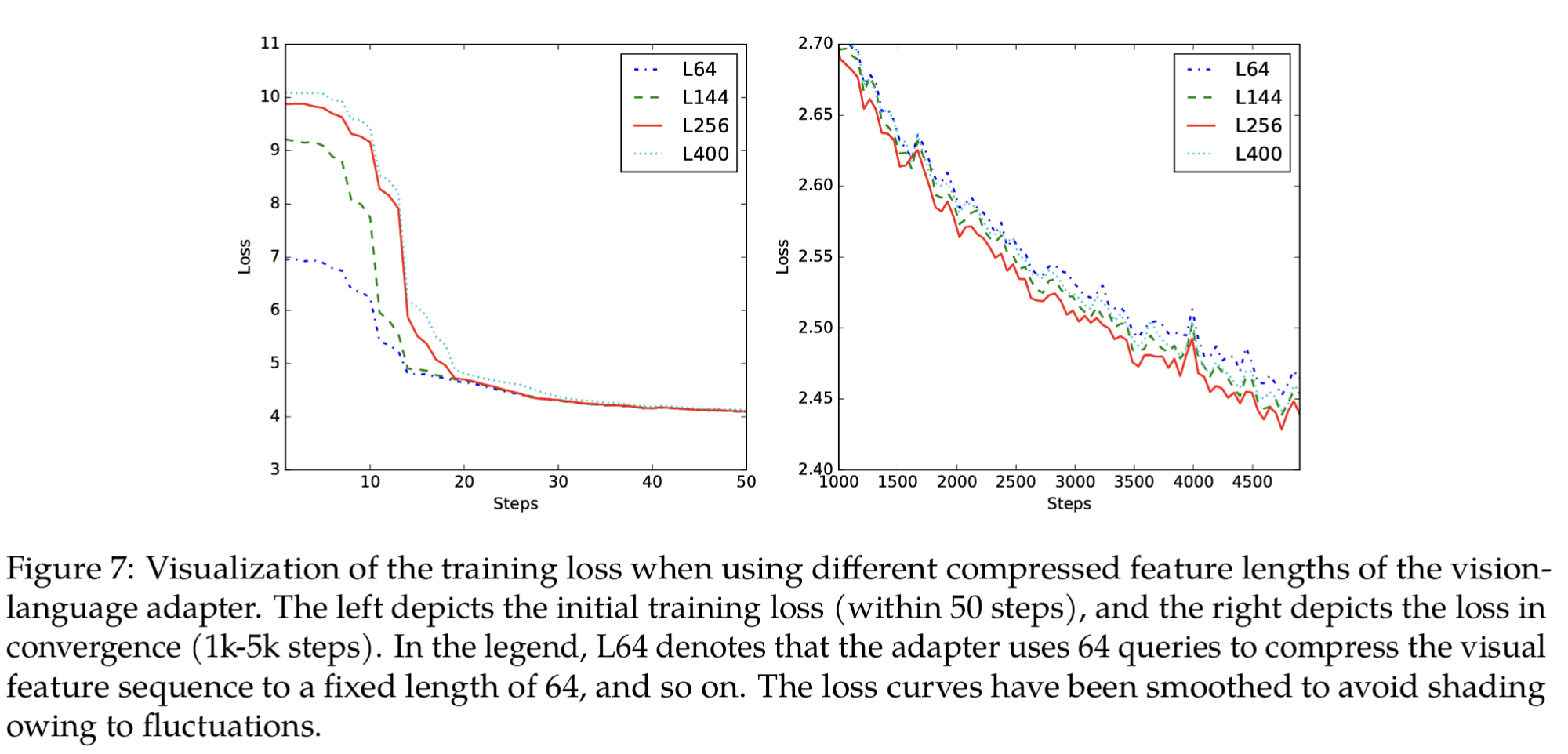
- 结果分析:
- 初始训练阶段(前 50 steps)
- queries 越少,初始 loss 越低(模型更快下降)。可能因为更少query意味着更少的参数,更容易在训练初期快速收敛。
- 说明压缩得狠一点,模型在早期更容易优化
- 收敛阶段(1k–5k steps)
- queries 太少或太多 → 收敛更慢, 而L256 的损失曲线最终收敛得最好,损失值最低。查询过多或过少导致收敛速度变慢。
- 说明信息丢失(queries 太少)或优化难度(queries 太多)都会阻碍收敛
- 更高分辨率情况
- 在第二阶段多任务预训练时,分辨率提升到 448×448
- 输出序列长度 = (448/14)² = 1024
- 如果 queries 太少(比如 L64),会丢失更多信息 → 表现不佳
- 初始训练阶段(前 50 steps)
结论:折中考虑,初始优化难度,收敛速度,信息保留,最终选用 L256(即 256 个 learnable queries)作为 Qwen-VL 的 vision-language adapter 默认配置。
6.未来工作
1.融入语音、视频 → 从“图文”跨向更广的多模态世界。2.模型更大(scaling law),训练数据更丰富,输入图像分辨率更高。可处理更复杂、更细腻的多模态关系。3.不只“理解” → 还要能 生成高质量图像、生成流利语音,走向 全面多模态生成。
参考文献
- <<Qwen-VL: AVersatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond>>
https://github.com/QwenLM/Qwen-VL/tree/master
https://arxiv.org/abs/2308.12966
- < Qwen Technical Report>>
https://github.com/QwenLM/Qwen
https://arxiv.org/abs/2309.16609