JVM(六)-- StringTable
目录
一、String的基本特性
1. 特性
2. String的内存分配编辑
3. 字符串拼接操作
二、intren()的使用
一、String的基本特性
1. 特性
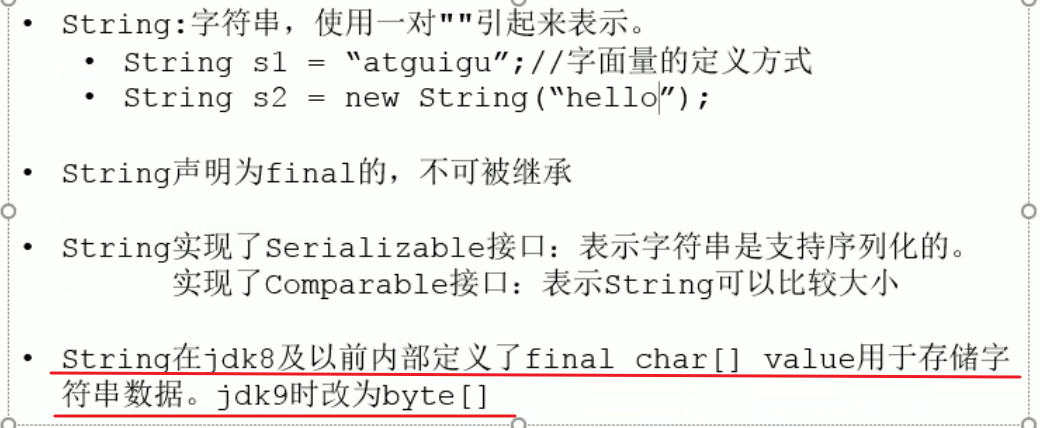
JDK9改为byte类型的目的是为了节省内存。


字符串常量池(String Constant Pool)中存储的是 字符串对象本身的引用(在 Java 7 及之后版本)。更准确地说:
-
在 Java 6 及之前,字符串常量池位于方法区(永久代),池中存储的是 字符串对象本身。
-
从 Java 7 开始,字符串常量池被移到了 堆内存 中。并且,池中存储的是字符串对象的引用,这些引用指向堆中创建的字符串对象实例。
2. String的内存分配

Java6及以前,字符串常量池存放在永久代当中。
Java7中,字符串常量池的位置调整到Java堆中。之后字符串常量池都在堆中。
StringTable为什么要进行调整?
永久代默认比较小;永久代的垃圾回收频率很低,容易报OOM异常。
3. 字符串拼接操作

看下面的两个例子:
因为s1是常量的拼接,所以它与s2指向的是常量池中的同一个位置。

s4是变量进行拼接的,所以和s3指向的就不是同一个地址,所以答案是false。s4指向的对象在堆中,s3指向的地址在字符串常量池中。

二、intren()的使用
当使用intern方法的时候,intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池当中。
intern是一个方法调用,它的核心作用就是主动将堆中的这个字符串对象“放入”字符串常量池,并返回池中的引用。如果池中已经存在内容相等的字符串,则直接返回池中那个字符串的引用。如果池中没有,则不会在常量池中再创建一个副本,而是会将堆中这个对象的引用记录在常量池中,并返回这个引用。
看下面的这个例子:
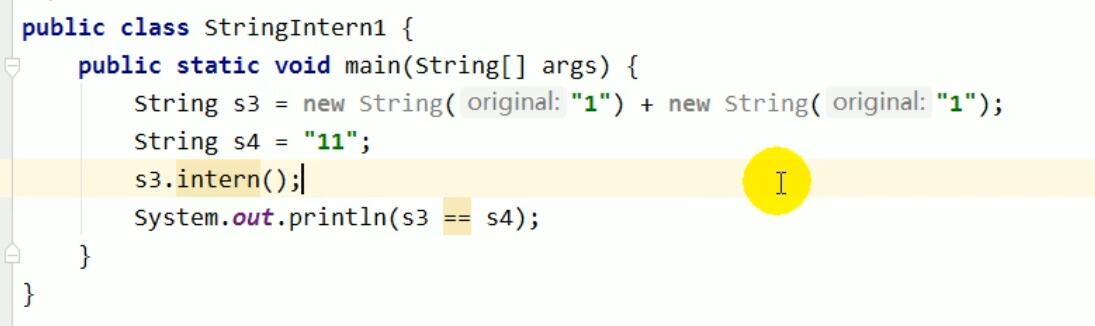
1. 首先,第一行代码就相当于是String s3 = new String("11");第一行代码执行完之后,内存中会存在四个字符串对象。
对象A(常量池中):由于使用了字面量 "1",在类加载时,JVM会确保字符串常量池中已经存在内容为 "1"的字符串对象。
对象B、C(堆中):new关键字会在堆内存中创建一个全新的、独立的 String对象,其内容也是 "1"。
对象D(堆中):new关键字会在堆内存中创建一个全新的、独立的 String对象,其内容是 "11"。
2. 第二行代码,String s4 = "11",因为此时字符串常量池中并没有“11”这个字符串,因此会在字符串常量池中创建一个对象E,内容为“11”。
3. 第三行代码。s3.intern()。因为常量池中已存在内容为 "11"的对象E,所以 intern()方法会返回对象E的引用。但是! 这里有一个非常重要的细节:代码是 s3.intern();而不是 s3 = s3.intern();。这意味着虽然 intern()方法返回了常量池的引用,但这个返回值并没有被任何变量接收。变量 s3仍然指向堆中的对象D,它的指向没有发生任何改变。
所以,上述代码的结果返回是false。
如果我们把上述代码顺序调换一下,如下图:
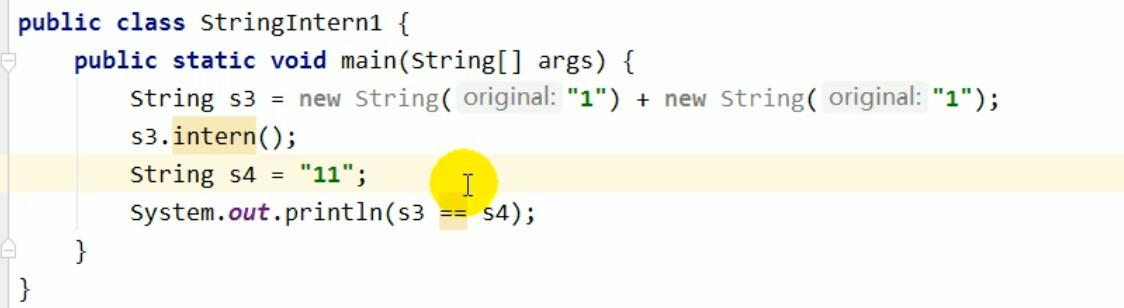
1. 首先,第一行代码就相当于是String s3 = new String("11");第一行代码执行完之后,内存中会存在四个字符串对象。
对象A(常量池中):由于使用了字面量 "1",在类加载时,JVM会确保字符串常量池中已经存在内容为 "1"的字符串对象。
对象B、C(堆中):new关键字会在堆内存中创建一个全新的、独立的 String对象,其内容也是 "1"。
对象D(堆中):new关键字会在堆内存中创建一个全新的、独立的 String对象,其内容是 "11"。
2. 第二行代码。s2.intern(),因为此时字符串常量池中并没有内容为“11”的字符串对象。所以,并不会在常量池中再创建一个副本,而是会将堆中这个对象的引用记录在常量池中,并返回这个引用(称为引用P)。
3. 第三行代码。String s4 = "11"。因为字符串常量池中已经有了“11”这个字符串的引用P,所以会直接将引用P赋值给s4,又因为引用P指向的是s3的地址空间,所以就相当于s4直接指向了s3的地址空间。因此结果就是true。
值得注意的是String s = "1"这个代码,并不是直接在字符串常量池中存储“1”这个字符串。而是编译器在堆中创建了一个字符串对象,内容为“1”。字符串常量池中存储的是该对象的引用而已。String s = new String("1"),是创建了两个对象,一个对象在常量池中有引用,另一个则没有。
总结:
