架构师成长之路06:缓存设计收官篇,缓存该放哪?写缓存怎么用?这篇讲透最后两个核心问题
文章目录
- 前言
- 一、先搞懂:缓存的位置,决定了性能收益的大小
- 1.1 从CPU三级缓存,看缓存位置的核心逻辑
- 1.2 级联系统中,缓存位置越靠前,收益越大
- 二、缓存的4个核心位置:从客户端到数据库,各有各的用法
- 2.1 客户端缓存:把计算和数据“搬”到用户设备上
- 2.2 静态缓存:与用户无关的通用数据,直接静态化
- 2.3 服务端缓存:服务间的“中间缓存”,减少重复计算
- 2.4 数据库缓存:数据库自己的“加速手段”
- 三、写缓存:被忽略的“用户体验神器”
- 3.1 写缓存是什么?不是“写数据到缓存”,而是“缓冲写请求”
- 3.2 写缓存 vs 读缓存:本质区别是什么?
- 3.3 写缓存的收益与成本:要不要用,看这两点
- 3.4 写缓存的3个经典案例
- 四、缓存系列总结:3个核心原则,覆盖90%场景
- 总结:缓存不是“银弹”,而是“平衡的艺术”
前言
前面的文章我们搞定了缓存的更新、清理和风险防控,但还有两个高频疑问没解决:为什么微信、淘宝的安装包越来越大?为什么订机票时会显示“订单处理中”,但钱已经扣了?这两个问题,其实都和“缓存的位置”与“写缓存”有关——这也是缓存系列最后要攻克的核心知识点。
作为缓存系列的最后一篇文章,我们会从“缓存该放系统的哪个环节”讲到“很少被提及但超实用的写缓存”,帮你把缓存的“全链路设计”闭环。看完这篇,你不仅能解释“安装包变大”的原因,还能在高并发写场景(比如秒杀下单、消息推送)中设计出用户体验更好的缓存方案。
一、先搞懂:缓存的位置,决定了性能收益的大小
很多人觉得“缓存随便放就行”,但实际上,缓存放的位置越靠前,能屏蔽的后方压力越大,性能收益也越高。我们先从计算机底层的CPU缓存说起,理解“位置决定收益”的本质。
1.1 从CPU三级缓存,看缓存位置的核心逻辑
缓存的设计思路,最早源于“CPU和内存的速度不匹配”:CPU每秒能处理几十亿次指令,而内存读取一次要几十纳秒,CPU等待内存的时间里,本来能做更多事。于是就有了CPU三级缓存(L1、L2、L3),越靠近CPU,速度越快、容量越小:
- L1缓存:最靠近CPU,容量只有几十KB,速度最快(纳秒级),每个核心独立拥有,分“数据缓存(L1d)”和“指令缓存(L1i)”;
- L2缓存:容量几百KB,速度比L1慢一点,同样每个核心独立;
- L3缓存:容量几兆到几十兆,速度最慢,多个核心共享。
读取数据时,CPU会先查L1,没找到查L2,再没找到查L3,最后查内存——每多查一级,耗时就多一点。这个逻辑和我们系统中的缓存完全一致:越靠近“请求发起方”的缓存,能越早拦截请求,减少后方系统的压力。
1.2 级联系统中,缓存位置越靠前,收益越大
我们的系统大多是“级联调用”的(A调用B,B调用C,C调用D…),就像“北京市→海淀区→中关村”的层级关系。在这种系统中,缓存放的位置不同,能节省的调用次数天差地别。
举个例子:假设系统调用链是「A→B→C→D→E→F」,我们在不同位置放缓存,收益如下:
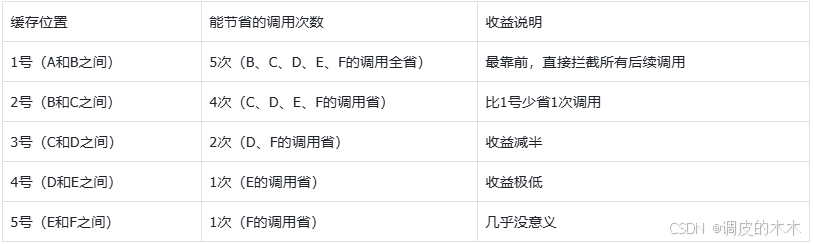
核心结论:缓存位置越靠前,能屏蔽的后方系统调用越多,性能收益越大。比如1号位置的缓存,能让A系统不用调用B、C、D等所有下游,直接返回结果;而5号位置的缓存,只能省掉对F的调用,意义不大。
但实际项目中,不会在“两个系统之间单独加缓存”,而是要么放在“调用方”(比如A系统里加缓存),要么放在“提供方”(比如B系统里加缓存)——前者省掉调用耗时,后者省掉提供方的计算耗时,具体看业务需求。
二、缓存的4个核心位置:从客户端到数据库,各有各的用法
知道“位置靠前收益大”后,我们具体看系统中最常用的4个缓存位置,每个位置都有明确的适用场景和实操案例。
2.1 客户端缓存:把计算和数据“搬”到用户设备上
客户端是请求的“起点”,在这里加缓存,能直接减少对服务端的请求,是成本最低的优化方式。比如微信、淘宝的安装包越来越大,就是因为用了“胖客户端”——把部分计算和数据放在客户端,减轻服务端压力。
客户端缓存的3种常见形式:

实操案例:网约车的“预估价格”
网约车APP会把“计价规则”(每公里多少钱、每分钟多少钱)缓存到客户端。当用户输入“从A到B”时,客户端直接用缓存的规则计算预估价格,不用请求服务端——既减少了服务端的计算压力,又让用户瞬间看到价格,体验更好。
核心原则:客户端缓存只存“轻量、通用、不常变”的数据,避免占用用户设备过多空间。
2.2 静态缓存:与用户无关的通用数据,直接静态化
静态缓存不是“某一个位置”,而是“一类数据的缓存方式”——只要数据“与用户无关、所有用户看到都一样”,就可以静态化,放在CDN、客户端或服务端,甚至直接嵌入代码。
什么是静态数据?
不是“从数据库查出来的就是动态数据”,而是看“是否与用户个体绑定”:
- 是静态数据:餐厅评分(4.9分)、省市区列表、商品分类、新闻详情页;
- 不是静态数据:用户的订单列表、个性化推荐(每个人看到的商品不同)。
实操案例:新闻详情页的静态化
很多CMS系统(内容管理系统)会把新闻页面“静态化”:
- 用户第一次访问某条新闻时,系统动态生成HTML页面,同时存入静态缓存(比如CDN或服务器磁盘);
- 后续用户访问这条新闻,直接返回静态HTML,不用再查数据库、渲染页面;
- 当新闻需要更新时,直接删除旧的静态页面,下次访问时重新生成——这就是前面学的“Cache-Aside”更新机制。
静态缓存的优势:
- 性能极致:静态文件(HTML、图片、CSS)可以通过CDN分发到全国节点,用户就近访问,速度比动态接口快10倍以上;
- 服务端压力小:不用处理数据库查询和页面渲染,只需要返回静态文件。
2.3 服务端缓存:服务间的“中间缓存”,减少重复计算
在分布式系统中,一个请求往往需要多个服务协作(比如订单服务调用用户服务、商品服务)。如果每个服务的结果都能缓存,就能减少下游服务的重复调用。
核心逻辑:缓存“服务的输出结果”
比如订单服务需要调用“用户服务”获取用户等级,调用“商品服务”获取商品库存:
- 把用户服务返回的“用户等级”缓存到订单服务中,下次再查同一个用户,不用再调用用户服务;
- 把商品服务返回的“库存”缓存到订单服务中,10分钟内重复查询不用再调用商品服务。
实操案例:电商下单流程,用户下单时,订单服务需要:
- 查用户等级(是否VIP,有无折扣);
- 查商品库存(是否有货);
- 查优惠券(用户是否有可用券)。
如果把“用户等级”(1小时内不变)、“商品库存”(5分钟内不变)缓存到订单服务,就能减少对用户服务、商品服务的调用,整个下单流程从500ms缩短到200ms。
2.4 数据库缓存:数据库自己的“加速手段”
很多人以为“数据库缓存就是Redis”,但其实数据库自身也有缓存机制,能减少磁盘I/O,提升查询速度。
数据库缓存的3种形式:
- 查询缓存(Query Cache):
- 原理:缓存SQL语句和对应的查询结果,下次执行相同SQL时,直接返回结果,不用解析SQL、扫描表;
- 注意:MySQL 8.0及以上版本已经移除了查询缓存(因为频繁更新的表会导致缓存频繁失效,收益低),8.0以下版本可使用;
- 坑点:SQL语句大小写不同会被认为是不同SQL(比如SELECT * FROM user和select * from user),缓存无法共享,所以团队要统一SQL规范。
- 缓冲池(Buffer Pool):
- 原理:InnoDB引擎会把常用的数据和索引加载到内存缓冲池,下次查询时直接从内存读,不用读磁盘;
- 优势:所有查询都能受益,是MySQL性能优化的核心手段(比如把缓冲池调大到服务器内存的70%)。
- 冗余字段/中间表:
- 原理:通过“空间换时间”,提前存储计算结果或关联数据,避免复杂查询;
- 例子:订单表中冗余“用户名”“商家名”(原本需要关联用户表、商家表查询),查订单时不用关联,直接读冗余字段;
- 中间表:统计“近30天订单量”时,不用每天扫描全表计算,而是提前把结果存到中间表,查询时直接读中间表。
三、写缓存:被忽略的“用户体验神器”
前面我们讲的缓存,几乎都是“读缓存”(加速读操作),但还有一种缓存——“写缓存”,它不加速读,而是解决“写操作的用户等待”问题。
3.1 写缓存是什么?不是“写数据到缓存”,而是“缓冲写请求”
很多人把“写缓存”理解成“把数据写到Redis”,其实不对。写缓存的核心是:在“调用方”和“数据处理方”之间加一个缓冲,让调用方不用等待处理方完成,直接返回,后续由缓存异步同步给处理方。
比如订机票时的“订单处理中”:
- 用户点击“提交订单”,钱扣了,但系统提示“订单处理中”;
- 此时用户的请求其实是写到了“写缓存”(比如MQ或Redis),并没有直接调用航空公司的接口;
- 后台系统异步从写缓存中读取订单,调用航空公司接口确认座位,完成后续流程;
- 流程完成后,再通过短信通知用户“订单成功”。
3.2 写缓存 vs 读缓存:本质区别是什么?
很多人混淆两者,其实它们的核心目标完全不同:
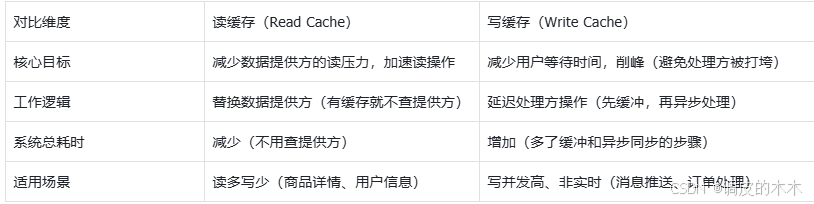
3.3 写缓存的收益与成本:要不要用,看这两点
写缓存能提升用户体验,但也会增加系统复杂度,用之前要算清“账”。
收益:用户响应快,体验好
- 比如消息推送系统:某APP发推送时,1分钟内有10万用户点击“查看”,如果实时调用后端接口,接口会被打垮;
- 用写缓存(比如Redis或MQ):用户点击后,请求先写到写缓存,直接返回“已查看”,后端异步处理点击数据;
- 用户等待时间从1秒缩短到100ms,后端也不会被高并发打垮。
成本:系统复杂度上升,有数据不一致风险
- 系统总耗时增加:原本直接调用处理方需要10秒,用写缓存后,用户等待3秒,但系统总耗时变成3秒(写缓存)+10秒(异步处理)+1秒(同步数据)=14秒;
- 数据不一致风险:如果写缓存同步到处理方时失败(比如网络波动),就会出现“用户看到成功,实际处理失败”的情况(比如订机票时用户看到“处理中”,但后台调用航空公司接口失败,需要退款);
- 维护成本高:需要处理写缓存的失败重试、数据对账(比如每天核对写缓存和处理方的数据是否一致)。
3.4 写缓存的3个经典案例
案例1:网约车的预估价格
网约车APP会把“计价规则”(每公里2元、每分钟1元)缓存到客户端(写缓存的一种),用户输入目的地后,客户端直接计算预估价格,不用请求服务端——既减少了服务端压力,又让用户瞬间看到价格。
案例2:消息推送系统
当有10万条推送消息需要发送时,直接调用推送接口会导致接口超时;用MQ作为写缓存:
- 业务系统把推送消息写到MQ;
- 推送系统从MQ异步拉取消息,慢慢发送;
- 业务系统不用等待推送完成,直接返回“推送成功”。
案例3:订机票的“处理中”
用户订机票时,系统流程:
- 用户点击“提交订单”,钱扣了,请求写到写缓存(Redis);
- 系统返回“订单处理中”,用户不用等待;
- 后台服务从Redis读取订单,调用航空公司接口确认座位;
- 确认成功后,更新订单状态,发短信通知用户;确认失败,自动退款。
四、缓存系列总结:3个核心原则,覆盖90%场景
到这里,缓存系列的4篇内容已经全部讲完。从缓存的概述、Key/Value设计,到更新/清理机制、风险防控,再到今天的缓存位置和写缓存,核心原则只有3个:
- 缓存位置:越靠前,收益越大
- 优先在客户端、CDN等“靠前”的位置加缓存,能最大程度减少后方系统的压力;
- 判断标准:数据是否“通用、可复用”(通用数据适合靠前缓存,个性化数据适合靠后缓存)。
- 读缓存:核心是“命中率”
- 选对数据:读多写少、源查询耗时久的场景(比如商品详情、用户等级);
- 更新机制:大部分场景用“Cache-Aside”(先更DB再删缓存),强一致场景用“Read-Write Through”;
- 清理机制:用“LRU+时效清理”,平衡命中率和内存占用。
- 写缓存:核心是“非实时”
- 用在“写并发高、用户能容忍延迟”的场景(比如消息推送、订单处理);
- 不用在“强实时”场景(比如金融转账,必须实时确认是否成功);
- 做好兜底:处理失败重试、数据对账,避免“用户看到成功,实际失败”的问题。
总结:缓存不是“银弹”,而是“平衡的艺术”
很多人觉得“加缓存就能解决所有性能问题”,但实际不是——缓存会增加系统复杂度,带来数据一致性风险。优秀的缓存设计,不是“用最复杂的方案”,而是“用最合适的方案”:
- 小项目:用“本地缓存(Caffeine)+ 数据库”就够了,不用上Redis集群;
- 中大型项目:用“客户端缓存+CDN+Redis+数据库缓存”,全链路优化;
- 金融项目:慎用写缓存,优先保证数据一致性,性能问题靠分库分表、读写分离解决。
缓存系列到这里就收官了,关注我,继续搞定架构师必备技能~