【数据结构】链表 --- 单链表
单链表
- 一、链表
- 1.链表
- 2.单向链表
- 二、单向链表的核心概念
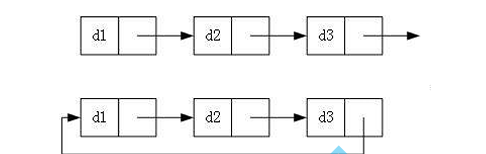
- 2.1 两种基础结构对比
- 2.2 节点的本质:链表的“最小单元”
- 三、单向链表的核心操作实现
- 3.1 插入操作:优先绑定后链,避免断链
- (1)头插法:在链表头部插入节点
- (2)尾插法:在链表尾部插入节点
- (3)任意位置插入:指定下标插入节点
- 3.2 删除操作:找到前驱节点,跳过待删节点
- (1)删除第一次出现的指定值节点
- (2)删除所有值为指定值的节点
- 3.3 其他常用操作
- (1)查找节点:判断值是否存在
- (2)清空链表:释放所有节点引用
- (3)遍历打印:输出链表所有数据
- 3.4 测试用例:
- 四、单向链表的常见问题与优化
- 4.1 核心问题:遍历循环条件的选择
- 4.2 不带头链表的缺陷与优化
- 4.3 时间复杂度分析
- 五、总结
一、链表
1.链表
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的
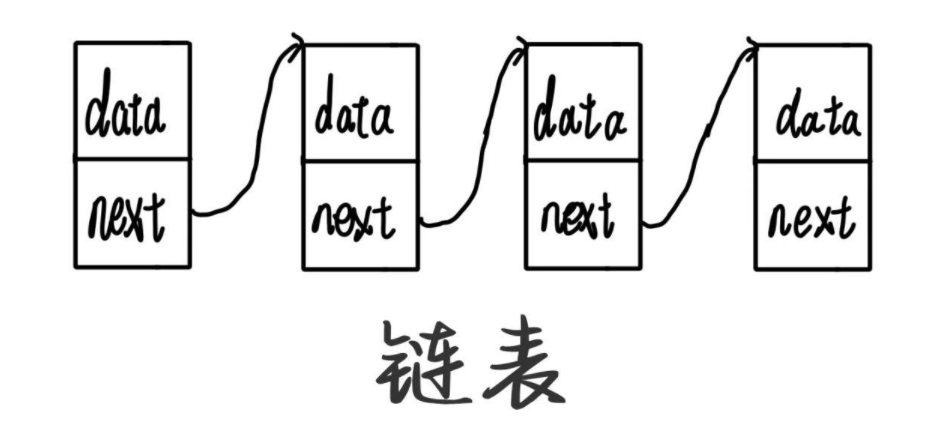
我们可以从图上看到:
- 链式结构再逻辑上是连续的,但是在物理上不一定是连续的
- 现实的节点一般都是从堆上申请出来的
- 所以那么在其申请出的空间,是按照一定的策略来进行分配的,两次的申请的空间也可能连续,也可能不连续的
但是实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
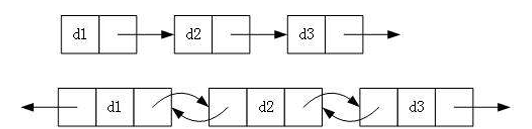
1.单向或双向
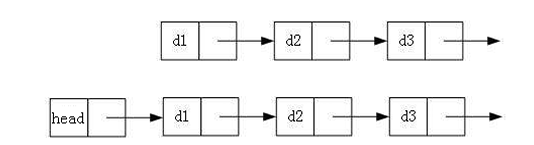
2.带头或者不带头
3.循环或者非循环
但是虽然有这么多的链表结构,但是我们重点掌握两种:
-
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多
-
无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表
2.单向链表
这期内容,我们优先重点讲述单向链表。
在 Java 数据结构体系中,链表是与数组互补的重要线性结构。相较于数组的连续内存存储,链表通过节点间的引用关系实现数据逻辑排序,尤其在频繁插入、删除场景中展现出更高效率
二、单向链表的核心概念
单向链表是由多个“节点”组成的线性结构,每个节点仅包含数据域和一个引用域(next),next 指向链表中的下一个节点,尾节点的 next 始终为 null。根据是否包含“头节点”,单向链表可分为两种常见类型:
2.1 两种基础结构对比
单向链表的核心差异在于是否存在“哨兵节点”(头节点),两种结构的特性对后续增删查改操作影响极大,具体对比如下:
| 结构类型 | 核心特点 | 头引用(head)作用 | 适用场景 |
|---|---|---|---|
| 不带头非循环链表 | 无专门头节点,第一个节点直接存储数据 | 指向首元节点(第一个数据节点),插入/删除首元节点时需修改 head 指向 | 作为复杂结构的子结构(如哈希桶、图的邻接表),笔试面试高频考点 |
| 带头非循环链表 | 有专门“头节点”(不存储数据),首元节点是头节点的 next | 始终指向头节点,插入/删除时无需修改 head,仅操作头节点的 next | 需频繁在头部操作的场景,代码实现更稳定(避免 head 空指针问题) |
2.2 节点的本质:链表的“最小单元”
节点是链表的基础组成单元,本质是一个封装了数据和引用的 Java 类,而链表是由多个节点组成,所以创建一个节点类来执行链表的增删查改,而节点是链表的最小单元,只不过这个最小的单元使用类进行封装起来的,而其中的引用域的成员变量是让节点形成链表的关键。
那么它的设计直接决定了链表能否正确串联,核心要点如下:
- 数据域:存储具体业务数据(如
int、String或自定义对象); - 引用域(next):存储下一个节点的地址,是节点间“串联”的关键;
- 实现方式:
- 内部类实现:节点类作为链表类的内部类,可直接访问链表的私有成员,代码紧凑,适合单一链表场景;
- 独立类实现:节点类单独定义,可被多个数据结构复用(如不同链表共享同一节点类),灵活性更高。
节点类代码示例(内部类实现):
// 链表类
public class SingleLinkedList {// 节点内部类:封装数据和next引用static class ListNode {int val; // 数据域ListNode next; // 引用域:指向下一个节点// 节点构造方法public ListNode(int val) {this.val = val;}}public ListNode head; // 链表的头引用:指向首元节点(不带头)或头节点(带头)// 链表构造方法:初始化空链表public SingleLinkedList() {this.head = null; // 不带头链表:初始head为null// 若为带头链表,需初始化头节点:this.head = new ListNode(0);(数据无意义)}
}
三、单向链表的核心操作实现
单向链表的操作围绕“节点引用的修改”展开,核心是避免断链。以下以“不带头非循环链表”为例,实现常用操作(带头链表仅需调整头节点相关逻辑,原理一致)。
//无头单向非循环链表实现方法接口
public interface IList {//头插法void addFirst(int data);//尾插法void addLast(int data);//任意位置插入void addIndex(int index,int data);//查找是否含有关键字key是否在单链表中boolean contains(int key);//删除第一次出现的关键字为key的节点void remove(int key);//删除所有值为key的节点void removeAllKey(int key);//得到单链表的长度int size();//清空单链表的所有长度void clear();//打印单链表void dispaly();
}
3.1 插入操作:优先绑定后链,避免断链
插入的核心原则:先连接新节点与后续节点,再修改前驱节点的next。若先修改前驱节点的next,会导致后续节点地址丢失,造成断链。
(1)头插法:在链表头部插入节点
- 场景:快速在链表开头添加数据(如栈的“压栈”操作);
- 步骤:
- 创建新节点
newNode; - 新节点的 next 指向原首元节点(
head); - 头引用
head指向新节点; - 链表长度
size加 1。
- 创建新节点
代码实现:
/*** 头插法:在链表头部插入数据* @param data 待插入的数据*/
public void addFirst(int data) {ListNode newNode = new ListNode(data);// 新节点的next指向原首元节点(即使原链表为空,head为null,也不影响)newNode.next = head;// head更新为新节点,成为新的首元节点head = newNode;
}
(2)尾插法:在链表尾部插入节点
- 场景:按顺序添加数据;
- 步骤:
- 创建新节点
newNode; - 若链表为空(
head == null),直接让head指向新节点; - 若链表非空,遍历找到尾节点(
cur.next == null的节点); - 尾节点的 next 指向新节点;
- 创建新节点
代码实现:
/*** 尾插法:在链表尾部插入数据* @param data 待插入的数据*/
public void addLast(int data) {ListNode newNode = new ListNode(data);// 情况1:链表为空,直接让head指向新节点if (head == null) {head = newNode;return;}// 情况2:链表非空,遍历找到尾节点ListNode cur = head;while (cur.next != null) { // 循环条件:cur不是尾节点cur = cur.next;}// 尾节点的next指向新节点cur.next = newNode;
}
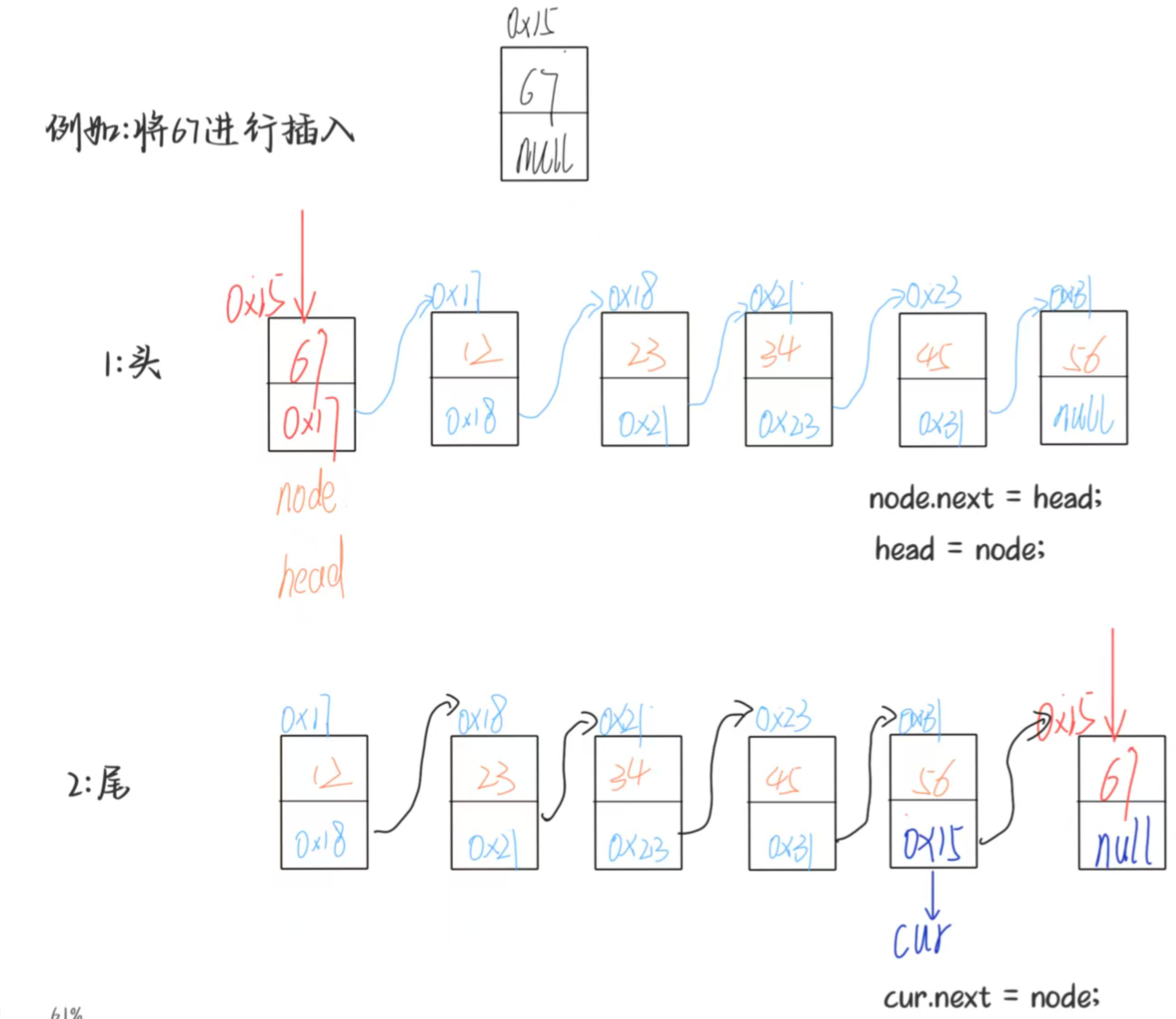
(3)任意位置插入:指定下标插入节点
- 场景:在链表的第
index个位置插入数据(下标从 0 开始,0 为头节点,size为尾节点后); - 前置检查:
index需满足0 ≤ index ≤ size,如果index > 0 || index > size,那么便抛出非法参数异常; - 步骤:
- 若
index == 0,直接调用头插法; - 若
index == size,直接调用尾插法; - 否则,遍历找到第
index-1个节点(前驱节点); - 新节点的 next 指向前驱节点的 next(后续节点);
- 前驱节点的 next 指向新节点。
- 若
代码实现:
/*** 任意位置插入:在第index个位置插入数据(下标从0开始)* @param index 插入位置* @param data 待插入的数据* @throws IndexIlegal 若index非法,抛出异常*/public void addIndex(int index, int data) {try {//前置检查,判断下标:checkIndex(index);//1.当插入位置为0(头部):if (index == 0){addFirst(data);return;}//2.当插入位置为末尾:if (index == size()){addLast(data);return;}//3.中间位置的插入:ListNode node = new ListNode(data);ListNode cur = head;while(index - 1 != 0){//判断链表元素插入的位置cur = cur.next;index--;//当index自动-1,直到与条件成假时,证明要到了插入了的链表的位置}/*// 找到前驱节点(index-1)也可以使用for循环ListNode cur = head;for (int i = 0; i < index - 1; i++) {cur = cur.next;}*//*cur.next = node;node.next = cur.next;这么操作不可以,链表是根据引用来进行操作的,而不是去依靠其他的,所以先绑定了前链,而插入位置的后链会发生断链,由于是引用的丢失*/// 先连后链,再连前链node.next = cur.next;cur.next = node;}catch (IndexIlegal e){System.out.println("插入位置不合法");e.printStackTrace();}}
public class IndexIlegal extends RuntimeException{public IndexIlegal() {super();}public IndexIlegal(String message) {super(message);}
}
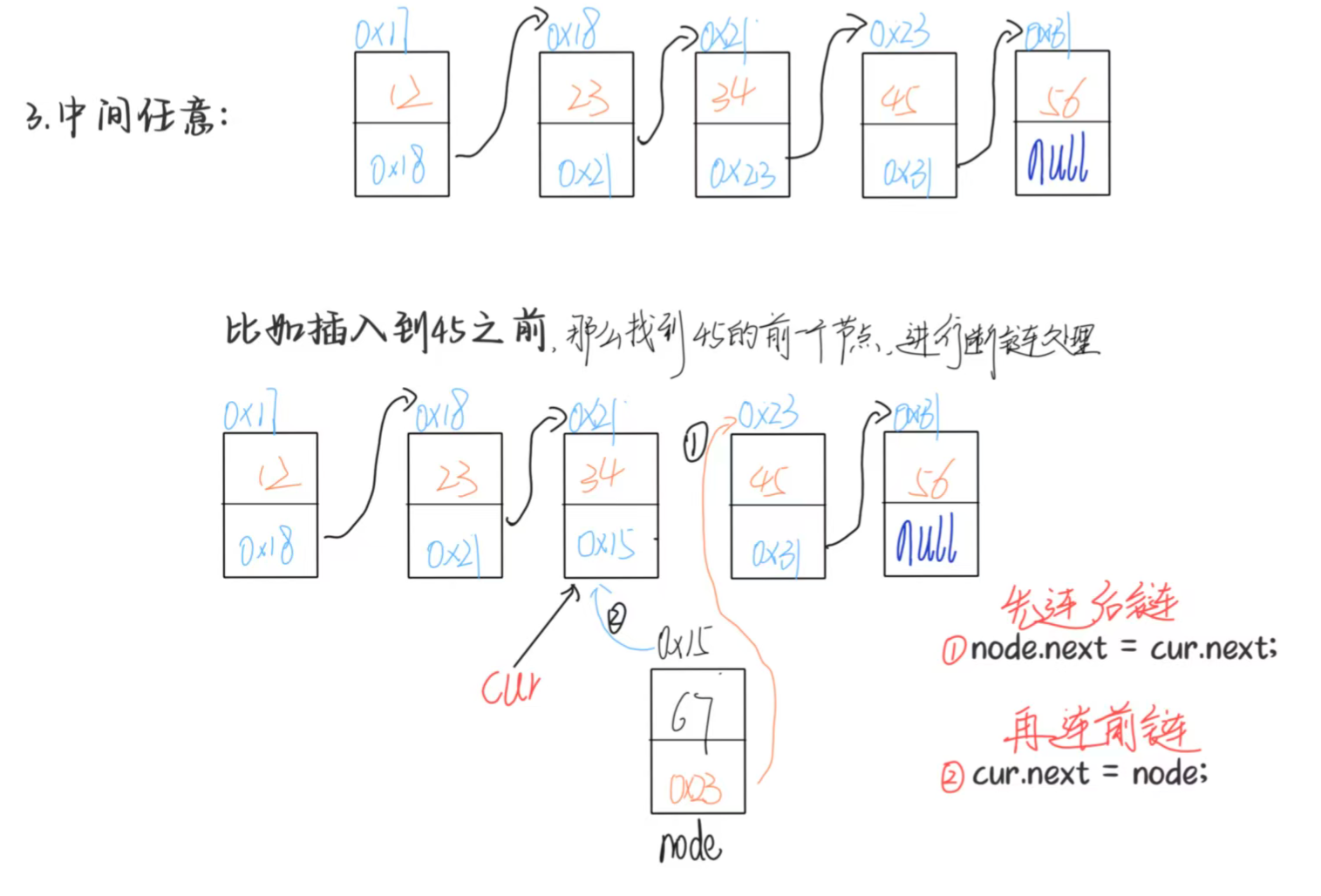
3.2 删除操作:找到前驱节点,跳过待删节点
删除的核心逻辑:找到待删节点的前驱节点,让前驱节点的 next 指向待删节点的 next,待删节点因失去引用会被 Java 垃圾回收机制回收,俗称就是断链重连。
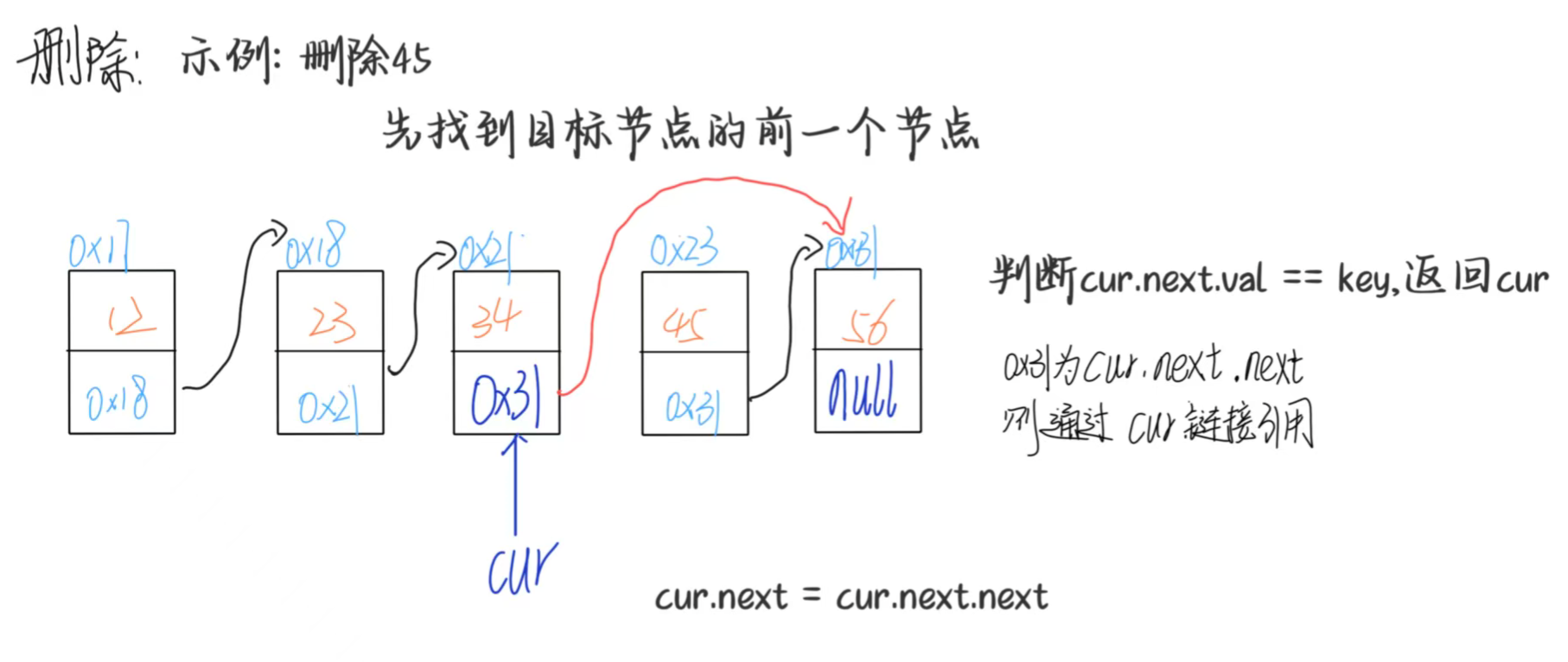
(1)删除第一次出现的指定值节点
- 场景:删除链表中第一个值为
key的节点; - 步骤:
- 若链表为空,直接返回(无节点可删);
- 若首元节点的值为
key,直接让head指向head.next(删除首元节点); - 否则,遍历找到前驱节点(
prev.next.val == key的节点); - 若未找到
key,返回(无该节点); - 前驱节点的 next 指向待删节点的 next。
代码实现:
/*** 删除第一次出现值为key的节点* @param key 待删除节点的值*/public void remove(int key) {// 情况1:判断链表为空if(head == null) {return;}// 情况2:头节点就是待删节点if(head.val == key) {head = head.next;return;}// 情况3:中间位置删除;待删节点在中间或尾部,找到前驱节点curListNode cur = findNodeOfKey(key);//查找key位置前一个元素curif(cur == null) {return;}// 跳过待删节点:cur.next指向待删节点的下一个节点ListNode del = cur.next;cur.next = del.next;}
//查找key位置前一个元素curprivate ListNode findNodeOfKey(int key) {ListNode cur = head;// 循环条件:cur的下一个节点不是null,且值不等于keywhile (cur.next != null) {if(cur.next.val == key) {
// 循环结束后:要么cur.next为null(未找到key),要么cur.next.val == key(找到)return cur;}cur = cur.next;}return null;}
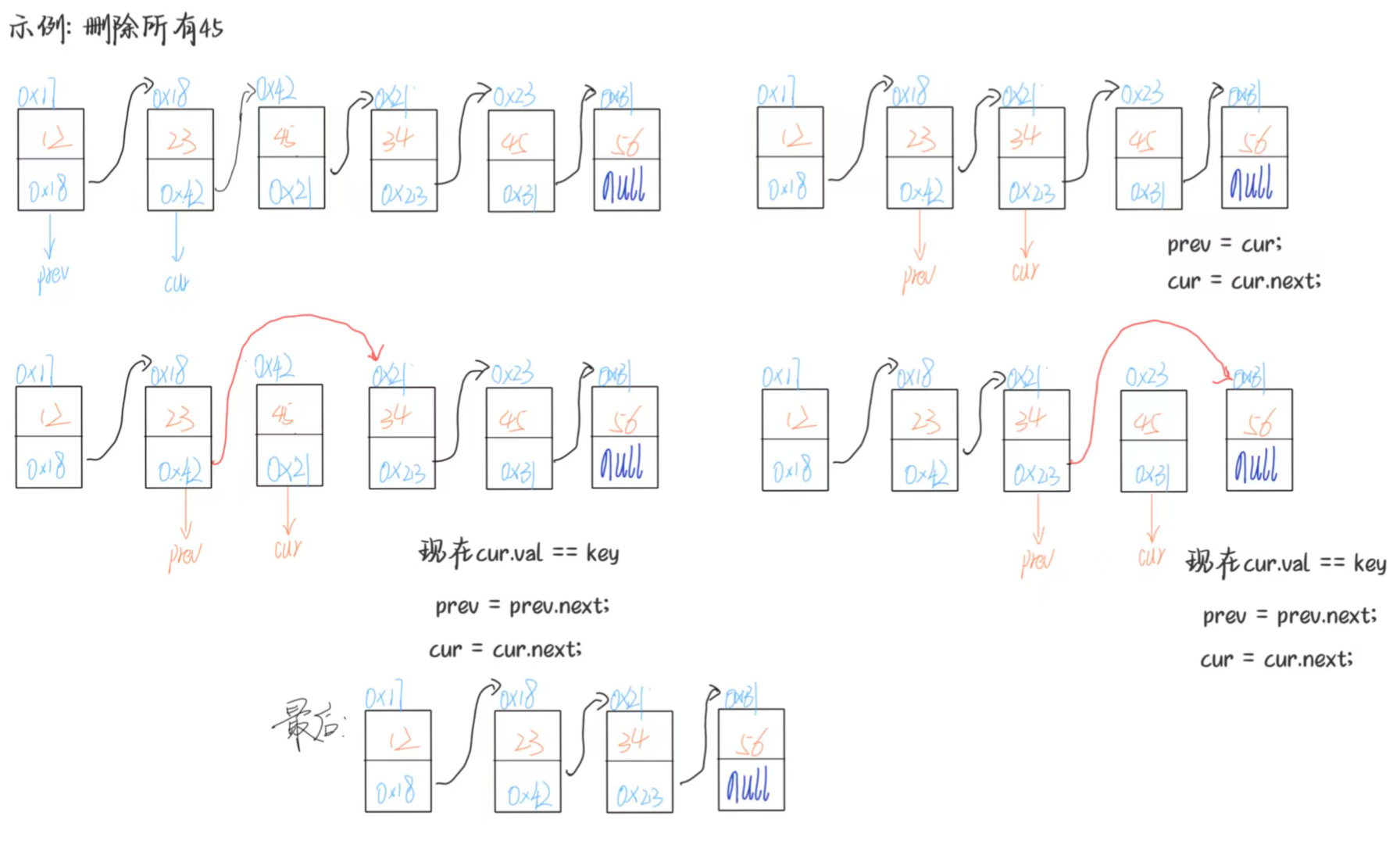
(2)删除所有值为指定值的节点
- 场景:删除链表中所有值为
key的节点(如清理重复数据); - 技巧:使用“快慢指针”(
prev为慢指针,cur为快指针),cur遍历链表,prev维护非key节点的尾部; - 步骤:
- 若链表为空,直接返回;
- 初始化
prev = head,cur = head.next; - 遍历
cur:- 若
cur.val == key,prev.next = cur.next(删除cur),cur后移; - 若
cur.val != key,prev和cur均后移;
- 若
- 遍历结束后,检查首元节点是否为
key(若首元节点是key,需单独删除)。
代码实现:
/*** 删除所有值为key的节点* @param key 待删除节点的值*/
public void removeAllKey(int key) {// 情况1:链表为空if (head == null) {return;}// 步骤1:删除中间和尾部的key节点(头节点暂不处理)ListNode prev = head;ListNode cur = head.next;while (cur != null) {if (cur.val == key) {prev.next = cur.next; // 删除curcur = cur.next;} else {prev = cur; // 只有当cur不是key时,prev才后移cur = cur.next;}//cur = cur.next;// cur始终后移,可以这么写,因为if和else都具有这个语句}// 步骤2:检查头节点是否为key(若为key,单独删除)if (head.val == key) {head = head.next;}
}
提示:
- 在删除头节点的时候,需要注意当头节点和下一个节点,都是为值key的节点,如果我们先直接用head来进行断链操作,不论是否有return,会造成节点的删除缺少,所以我们需要把这个头节点的删除的放在循环体的最后
- 最后删除头节点,是因为或许会有头和第二个节点都是具有相同的值,那么在处理的时候,会无法删除头节点,所以在我们把第二个到最后的节点进行遍历一遍后,那么再去单独判断头节点进而去删除
3.3 其他常用操作
(1)查找节点:判断值是否存在
/*** 判断链表中是否包含值为key的节点* @param key 待查找的值* @return 存在返回true,否则返回false*/
public boolean contains(int key) {ListNode cur = head;while (cur != null) {if (cur.val == key) {return true;}cur = cur.next;}return false;
}
(2)清空链表:释放所有节点引用
- 注意:不能直接
head = null(会导致中间节点引用未释放,垃圾回收无法回收),需逐个置空next; - 步骤:
- 遍历链表,记录当前节点的下一个节点;
- 将当前节点的
next置为null; - 最后将
head置为null,size置为 0。
/*** 清空链表:释放所有节点引用*/
public void clear() {ListNode cur = head;while (cur != null) {//如果先修改置为空,那么不能链接引用了,//所以我们先定义一个值来进行保存起来,便于链接引用ListNode curN = cur.next; // 先记录下一个节点cur.next = null; // 置空当前节点的nextcur = curN; // 移到下一个节点}head = null; // 头引用置空,链表为空
//所有的除了头节点的地址之外均置为空,然后我们手动对头节点来进行置空处理
}
注意:单向链表无法从后置空
(3)遍历打印:输出链表所有数据
/*** 遍历链表,打印所有节点的值*/
public void display() {ListNode cur = head;while (cur != null) {System.out.print(cur.val + " ");cur = cur.next;}System.out.println();
}
3.4 测试用例:
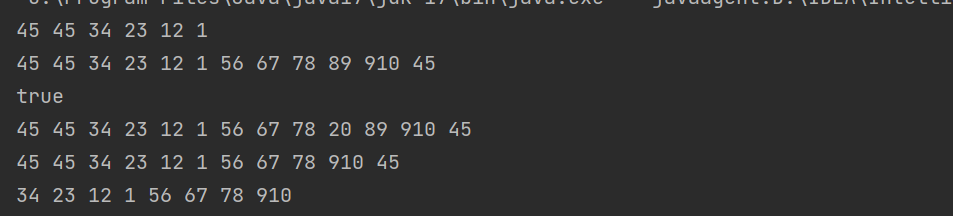
public static void main(String[] args) {MySingleLinkedList list = new MySingleLinkedList();list.addFirst(01);list.addFirst(12);list.addFirst(23);list.addFirst(34);list.addFirst(45);list.addFirst(45);list.display();list.addLast(56);list.addLast(67);list.addLast(78);list.addLast(89);list.addLast(910);list.addLast(45);list.display();System.out.println(list.contains(1));list.addIndex(9,20);list.display();list.remove(20);list.remove(89);list.display();list.removeAllKey(45);list.display();}
四、单向链表的常见问题与优化
4.1 核心问题:遍历循环条件的选择
遍历链表时,cur 和 cur.next 的选择直接影响逻辑正确性,需根据场景区分:
- 用
cur != null:遍历所有节点(如查找、打印、清空),此时cur会访问到尾节点的下一个节点,即是null; - 用
cur.next != null:需找到尾节点的前驱(如尾插、删除尾部节点),cur没有进入循环体中,所以此时cur最终指向尾节点。
错误示例:尾插时用 cur != null 循环,会导致 cur 指向 null,无法执行 cur.next = newNode(空指针异常)。
4.2 不带头链表的缺陷与优化
不带头链表在删除/插入首元节点时,需修改 head 引用,容易出现空指针问题。优化方案:
- 改用带头链表:初始化一个不存储数据的头节点,
head始终指向头节点,所有操作均围绕头节点的next展开,避免head频繁修改; - 示例:带头链表的头插法:
// 带头链表初始化:head指向头节点(数据无意义)public SingleLinkedList() {this.head = new ListNode(0); // 头节点this.size = 0;}// 带头链表头插法:无需修改head,只需操作head.nextpublic void addFirst(int data) {ListNode newNode = new ListNode(data);newNode.next = head.next;head.next = newNode;size++;}
4.3 时间复杂度分析
单向链表的操作效率与节点位置相关,具体如下:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 头插/头删 | O(1) | 仅需修改head或头节点的next |
| 尾插/尾删 | O(n) | 需遍历到尾节点 |
| 任意位置插入 | O(n) | 需遍历到指定位置的前驱 |
| 查找节点 | O(n) | 需遍历所有节点(最坏情况) |
五、总结
单向链表是 Java 中最基础的链表结构,其核心是节点引用的正确维护。通过本文的学习,你需要掌握:
- 两种结构差异:不带头链表(灵活,适合子结构)与带头链表(稳定,适合独立使用);
- 核心操作逻辑:插入优先绑定后链,删除找到前驱节点,避免断链;
- 常见问题解决:遍历循环条件选择、空指针预防、效率优化。
这期内容我们讲述了链表的基础单向链表,下一节的内容为大家讲述的Java的双向链表LinkedList,这将为后续的复杂数据结构(如哈希表、图)的学习打下基础;那么这期的内容就先到这里了,如果有什么细节上的不足和缺陷,欢迎大家可以在评论区中指正和批评!谢谢大家!