YOLO入门教程(四):搭建YOLOv1网络
- 学习教案:https://zhuanlan.zhihu.com/p/365788432
- 作者:Kissrabbit
- 作者书籍:《YOLO目标检测》
股市可以停止涨,但是学习不能停!
0、序言
在上一节中,我们讲解了我们所要搭建的YOLOv1,不同于原版的YOLOv1,我们在不偏离原版的大部分核心理念的前提下,做了更加符合当下的设计理念的修改,包括使用更好的Backbone、添加Neck模块、修改检测头等。
有点搞忘了原本的什么样子了,复习一下
-
使用更好的 Backbone:
- 原始 YOLOv1: 使用的是基于 GoogLeNet (Inception-v1) 的自定义 Backbone,包含 24 个卷积层和 2 个全连接层。这个网络在 2016 年是不错的,但以今天的标准来看,效率较低,特征提取能力相对较弱。
- 改进: 用更现代、更强大、更高效的卷积神经网络架构替换原始的 Backbone。常见的现代 Backbone 包括:
- ResNet (Residual Networks): 通过引入残差连接解决了深层网络训练困难的问题,允许构建更深、更强大的网络(如 ResNet-18, ResNet-34, ResNet-50 等)。它能提取更丰富、更深层次的特征。
- MobileNet: 专门为移动和嵌入式设备设计,使用深度可分离卷积来大幅减少计算量和参数数量,同时保持较好的精度。适合追求速度的场景。
- EfficientNet: 通过复合缩放方法(同时缩放网络深度、宽度和输入分辨率)在计算资源受限的情况下达到最优的性能。
- DarkNet (YOLO 后续版本使用的): YOLOv2/v3 作者提出的 Backbone,也是高效且强大的选择。
- 目的: 提升特征提取能力,使网络能从输入图像中学习到更鲁棒、更具判别性的特征,从而提高检测精度和/或速度。
-
添加 Neck 模块:
- 原始 YOLOv1: 没有明确的 Neck 模块。Backbone 提取的特征图直接传递给了检测头(Head)。
- 改进: 在 Backbone 和 Head 之间增加一个 Neck 模块。Neck 的主要作用是特征融合和特征增强。常见的 Neck 结构包括:
- FPN (Feature Pyramid Network): 这是最常用的 Neck 之一。它通过自顶向下和横向连接,将 Backbone 不同层(不同尺度)的特征图融合起来,构建一个特征金字塔。这使得后续的检测头能够利用不同尺度的特征信息:深层特征语义信息强但分辨率低(适合大目标),浅层特征位置信息精确但语义信息弱(适合小目标)。添加 FPN 能显著提升模型(尤其是小目标)的检测性能。
- PANet (Path Aggregation Network): 在 FPN 基础上增加了自底向上的路径增强,进一步优化了特征融合过程。
- BiFPN (Bidirectional Feature Pyramid Network): 在 EfficientDet 中提出,通过双向(自顶向下+自底向上)的跨尺度连接和加权特征融合,更高效地融合多尺度特征。
- 目的: 融合不同层次的特征信息,特别是增强对小目标的检测能力(这是原始 YOLOv1 的一个主要弱点),并提升整体检测精度。
-
修改检测头 (Head):
- 原始 YOLOv1 Head:
- 输入是 Backbone 输出的单一尺度的特征图(例如
7x7)。 - 结构:两个全连接层。
- 输出:一个
S x S x (B * 5 + C)的张量。S x S: 将图像划分为S x S个网格。B: 每个网格预测的边界框数量(原始 YOLOv1 中B=2)。5: 每个边界框的预测值 (x, y, w, h, confidence)。C: 目标类别的数量(每个网格预测一组类别概率)。
- 输入是 Backbone 输出的单一尺度的特征图(例如
- 改进: 对 Head 进行现代化改造,可能包括:
- 用卷积层替代全连接层: 全连接层会破坏空间信息且参数量巨大。现代检测器普遍使用卷积层(通常是
1x1卷积)来构建检测头,这样能保留空间信息,参数更少,更灵活。 - 多尺度预测 (Multi-scale Prediction): 虽然原始 YOLOv1 是单尺度预测,但现代改进可能会利用 Neck(如 FPN)输出的多个尺度的特征图进行预测。不同尺度的特征图负责预测不同大小的目标(大特征图预测小目标,小特征图预测大目标),这显著提升了检测能力,尤其是对小目标。
- Anchor Boxes: 虽然原始 YOLOv1 没有使用 Anchor Boxes(它直接预测相对于网格的偏移量),但后续的 YOLO 版本引入了这个概念。可能会引入 Anchor Boxes 到 Head 设计中,让 Head 预测相对于预定义 Anchor 的偏移量和类别概率。这通常能提升定位精度。但请注意,目标是“不偏离原版的大部分核心理念”,而原始 YOLOv1 的核心之一是“无 Anchor”。所以也可能选择保留无 Anchor 的设计,而用其他方式改进 Head(如更好的损失函数设计、更合理的输出表示等)。
- 更精细的输出表示: 可能对边界框坐标 (
x, y, w, h)、置信度或类别概率的预测方式进行优化。
- 用卷积层替代全连接层: 全连接层会破坏空间信息且参数量巨大。现代检测器普遍使用卷积层(通常是
- 目的: 提高定位精度 (
x, y, w, h),提高分类精度,提升模型对不同尺度目标的鲁棒性,同时保持或提升效率。
- 原始 YOLOv1 Head:
总结:
对原始 YOLOv1 的改进是将其核心思想(将检测视为回归问题、划分网格预测)与现代目标检测的最佳实践相结合:
- 更强壮的 Backbone: 提供更好的基础特征。
- 添加 Neck (如 FPN): 融合多尺度特征,解决小目标检测难题。
- 现代化的 Head: 用卷积替代全连接,可能引入多尺度预测或优化输出表示,提升精度和鲁棒性。
这些修改旨在克服原始 YOLOv1 的已知缺点(如定位不准、小目标检测差、召回率相对较低),使其在保持 YOLO 系列“快速”特点的同时,达到更接近现代检测器的精度水平。当阅读博客后续的代码实现部分时,咱们得重点关注观察作者具体选择了哪种 Backbone、哪种 Neck 以及如何设计 Head 结构。
在本节,我们将使用python语言和pytorch深度学习框架开始搭建我们的YOLOv1网络。
下方的图1展示了我们所要搭建的YOLOv1的网络结构图,这将是我们接下来的工作的“蓝图”。
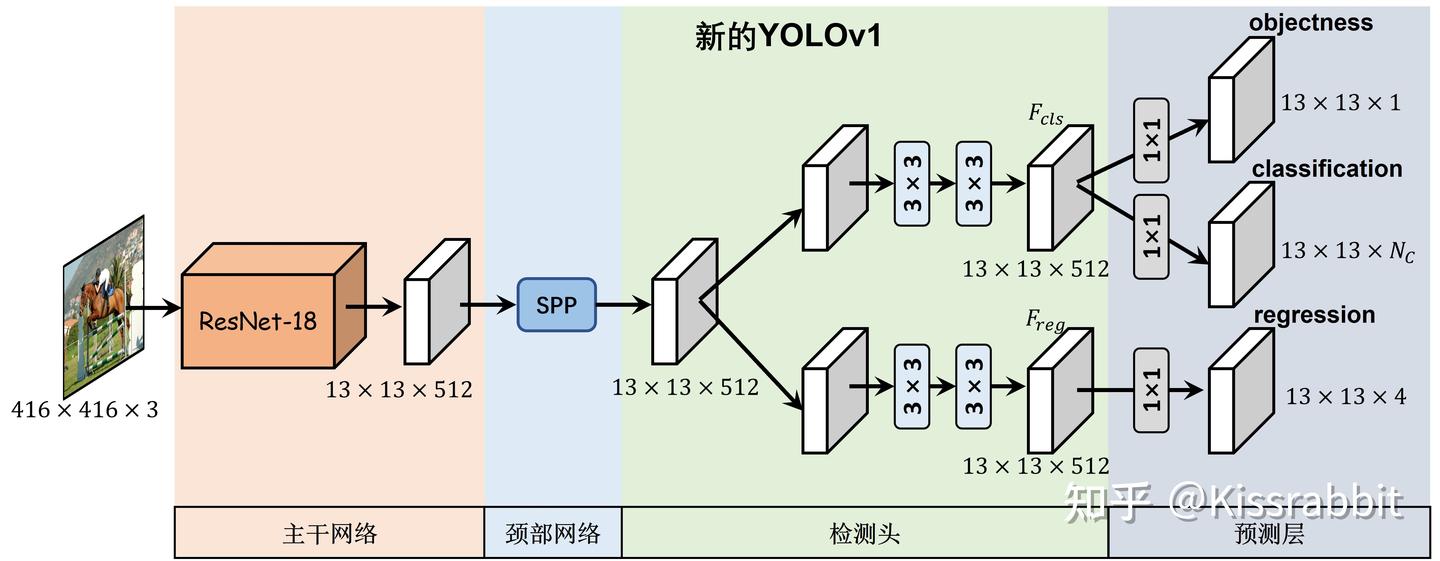
根据这一蓝图,我们可以先搭建起来一个整体的框架,如下方的代码所示。接下来,我们将一步一步地去完善这一个框架。
# ODLab/models/detectors/yolov1/yolov1.pyclass YOLOv1(nn.Module):def __init__(self,cfg,device,img_size=None,num_classes=20,conf_thresh=0.01,nms_thresh=0.5,trainable=False,deploy=False,nms_class_agnostic :bool = False):super(YOLOv1, self).__init__()# ------------------------- 基础参数 ---------------------------self.cfg = cfg # 模型配置文件self.img_size = img_size # 输入图像大小self.device = device # cuda或者是cpuself.num_classes = num_classes # 类别的数量self.trainable = trainable # 训练的标记self.conf_thresh = conf_thresh # 得分阈值self.nms_thresh = nms_thresh # NMS阈值self.stride = 32 # 网络的最大步长self.deploy = deployself.nms_class_agnostic = nms_class_agnostic# >>>>>>>>>>>>>>>>>>>>>>>>> Backbone网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的backbone网络# self.backbone# >>>>>>>>>>>>>>>>>>>>>>>>> Neck网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的neck网络# self.neck# >>>>>>>>>>>>>>>>>>>>>>>>> Head网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的head网络# self.head# >>>>>>>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的预测层# self.preddef create_grid(self, fmp_size):# To do:# 生成一个tensor:grid_xy,每个位置的元素是网格的坐标,# 这一tensor将在获得边界框参数的时候会用到。def decode_boxes(self, pred, fmp_size):# 将网络输出的tx,ty,tw,th四个量转换成bbox的(x1,y1),(x2,y2)def postprocess(self, bboxes, scores):# 后处理代码,包括阈值筛选和非极大值抑制@torch.no_grad()def inference(self, x):# 测试阶段的前向推理代码def forward(self, x, target=None):# 训练阶段的前向推理代码
既然是小白,我们搞慢点,先来逐部分详细解释这段 YOLOv1 模型类的代码框架。
这段代码定义了一个 PyTorch 模型类 YOLOv1,它包含了模型构建和前向传播所需的主要组件和方法。
- 类定义与初始化 (
__init__)
class YOLOv1(nn.Module):def __init__(self,cfg, # 配置文件对象,可能包含模型结构、超参数等device, # 计算设备 ('cuda' 或 'cpu')img_size=None, # 输入图像尺寸 (e.g., 416)num_classes=20, # 要检测的类别数 (默认为VOC的20类)conf_thresh=0.01, # 置信度分数阈值,用于过滤低置信度预测nms_thresh=0.5, # 非极大值抑制 (NMS) 的IoU阈值trainable=False, # 模式标志:True为训练,False为测试/验证deploy=False, # 部署模式标志,可能用于简化输出(如ONNX导出)nms_class_agnostic :bool = False): # NMS是否跨类别进行(True则所有类别一起做NMS)super(YOLOv1, self).__init__()# ------------------------- 基础参数 ---------------------------self.cfg = cfgself.img_size = img_sizeself.device = deviceself.num_classes = num_classesself.trainable = trainableself.conf_thresh = conf_threshself.nms_thresh = nms_threshself.stride = 32 # 网络的总下采样步长( backbone + neck)self.deploy = deployself.nms_class_agnostic = nms_class_agnostic
- 目的: 初始化模型的超参数和结构组件。
- 关键参数:
cfg: 一个配置文件对象,通常来自yaml文件,它集中定义了 Backbone、Neck、Head 的具体结构(如层数、通道数等),使得代码更灵活,无需修改代码即可改变模型结构。device: 指定模型加载到 GPU 还是 CPU。num_classes: 决定了分类输出的维度。conf_thresh&nms_thresh: 后处理参数,在测试/推理阶段使用。trainable: 控制模型处于训练模式还是评估模式(影响 Batch Normalization 和 Dropout 等层的行为)。stride=32: 表示从输入图像到最终特征图的总体下采样倍数。例如,输入416x416,输出特征图尺寸为13x13(416/32=13)。这是一个关键参数,用于将特征图上的坐标映射回原图。
- 网络组件定义 (Backbone, Neck, Head, Pred)
# >>>>>>>>>>>>>>>>>>>>>>>>> Backbone网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的backbone网络# self.backbone# >>>>>>>>>>>>>>>>>>>>>>>>> Neck网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的neck网络# self.neck# >>>>>>>>>>>>>>>>>>>>>>>>> Head网络 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的head网络# self.head# >>>>>>>>>>>>>>>>>>>>>>>>> 预测层 <<<<<<<<<<<<<<<<<<<<<<<<<<<<# To do:构建我们的预测层# self.pred
- 目的: 声明模型的核心架构模块。这些部分是待实现的,根据博客内容,它们将被具体构建:
self.backbone: 特征提取主干网络 (如 ResNet, CSPDarknet)。self.neck: 特征金字塔或融合网络 (如 FPN, PAN)。self.head: 检测头,通常由几个卷积层组成,负责输出最终的预测 tensor。self.pred: 可能是一个最终的卷积层,将head的输出通道数转换为模型最终需要的维度S x S x (B*5 + C)。有时这个层会被合并到head中。
- 网格生成 (
create_grid)
def create_grid(self, fmp_size):# To do:# 生成一个tensor:grid_xy,每个位置的元素是网格的坐标,# 这一tensor将在获得边界框参数的时候会用到。
- 目的: 为特征图上的每个单元格生成其左上角的坐标网格。
- 工作原理:
- 输入
fmp_size是特征图的高度H和宽度W。 - 它会创建一个形状为
(H, W, 2)的张量。 - 这个张量在
(i, j)位置的值是(j, i)。例如,对于13x13的特征图,位置(0, 0)的值为(0, 0),位置(0, 1)的值为(1, 0),…,位置(12, 12)的值为(12, 12)。 - 为什么需要它? YOLO 预测的是边界框中心相对于其所在网格左上角的偏移量 (
tx, ty)。在解码时,需要加上网格的左上角坐标(就是这个函数生成的)并归一化,才能得到框在原始图像上的绝对坐标。
- 输入
- 边界框解码 (
decode_boxes)
def decode_boxes(self, pred, fmp_size):# 将网络输出的tx,ty,tw,th四个量转换成bbox的(x1,y1),(x2,y2)
- 目的: 将网络输出的原始预测值转换为人可读的边界框坐标。
- 输入:
pred: 网络的原始输出张量,形状通常为(B, H, W, B*(5+C))或(B, B*(5+C), H, W)。fmp_size: 特征图尺寸(H, W)。
- 处理过程 (以 YOLOv1 为例):
- 从
pred中切片出tx, ty, tw, th和置信度conf以及类别概率cls_pred。 - 使用
sigmoid函数处理tx, ty,将它们限制在(0, 1)范围内,表示中心点在网格内的偏移。 - 使用
create_grid生成的网格坐标。解码后的中心点bx = sigmoid(tx) + grid_x,by = sigmoid(ty) + grid_y。 - 处理
tw, th。原始 YOLOv1 是直接预测宽高,但现代实现常用exp(tw) * anchor_w或类似方式。这里需要看作者具体如何实现。最终得到bw和bh。 - 将所有坐标
(bx, by, bw, bh)乘以stride(这里是 32) 来将它们从特征图尺度映射回原图尺度。 - 最后计算边界框的左上角
(x1, y1)和右下角(x2, y2)坐标。
- 从
- 后处理 (
postprocess)
def postprocess(self, bboxes, scores):# 后处理代码,包括阈值筛选和非极大值抑制
- 目的: 对模型输出的所有预测框进行筛选,得到最终干净、可靠的检测结果。仅在推理阶段使用。
- 处理步骤:
- 置信度阈值过滤: 剔除置信度
conf低于self.conf_thresh的预测框。 - 非极大值抑制 (NMS):
- 按类别循环(除非
nms_class_agnostic=True)。 - 对每个类别,根据置信度分数进行排序。
- 遍历排序后的框,移除所有与当前最高分框的 IoU 超过
self.nms_thresh的其他框。
- 按类别循环(除非
- 返回经过筛选后保留的边界框、分数和类别标签。
- 置信度阈值过滤: 剔除置信度
- 推理方法 (
inference)
@torch.no_grad()def inference(self, x):# 测试阶段的前向推理代码
- 目的: 模型部署或测试时使用的完整前向传播流程。
@torch.no_grad(): 装饰器,关闭 PyTorch 的梯度计算,大幅减少内存消耗并加速计算。- 流程:
- 通过
self.backbone、self.neck、self.head进行前向传播,得到原始预测pred。 - 调用
self.decode_boxes(pred, ...)得到解码后的边界框坐标和分数。 - 调用
self.postprocess(bboxes, scores)进行后处理,得到最终检测结果。 - 返回结果。
- 通过
- 前向传播方法 (
forward)
def forward(self, x, target=None):# 训练阶段的前向推理代码
- 目的: 训练和验证模式下的前向传播。这是 PyTorch
nn.Module的核心方法。 - 输入:
x: 输入图像批次。target: (仅在训练时提供) 真实标签(GT),用于计算损失。
- 行为:
- 如果
target不是None(训练模式):- 进行前向传播得到
pred。 - 计算损失函数(例如 YOLO 的坐标损失、置信度损失、分类损失)。
- 返回损失值
loss和一个可能包含损失明细的字典。
- 进行前向传播得到
- 如果
target是None(验证模式或简单推理):- 进行前向传播得到
pred。 - (可选)可能进行解码和后处理,或者直接返回
pred供外部计算指标(如mAP)。 - 返回预测结果。
- 进行前向传播得到
- 如果
总结
这段代码是一个高度模块化、结构清晰的 YOLOv1 实现框架。它严格区分了:
- 模型构建 (
__init__中的组件定义) - 核心计算 (
forward和inference) - 解码逻辑 (
decode_boxes,create_grid) - 后处理 (
postprocess)
这种设计使得代码易于阅读、调试和扩展。待实现的 Backbone, Neck, Head 部分将会根据传入的 cfg 配置文件来具体实例化,这提供了极大的灵活性,可以轻松尝试不同的网络架构。
在深入展开的时候,先看看这个部分是怎么工作的。
我们把这个 YOLOv1 的代码想象成一个 智能工厂的流水线,用最通俗易懂的方式解释它的工作流程。
YOLOv1 模型工作流程(工厂流水线版)
整个模型就像一家专门从图片中找出物品并画框的智能工厂。它的工作分为两大模式:训练模式(工厂学习和自我改进)和推理模式(工厂正式干活)。
一、工厂的蓝图与筹备 (
__init__函数)
在工厂开工前,需要先设计好蓝图和准备好所有设备。
- 确定工厂参数:收到总部发来的
cfg配置文件,里面规定了要用什么机器、流水线多宽等。同时确定要检测的物品种类数(num_classes)、合格分数(conf_thresh)、以及判断两个框是不是同一个物的标准(nms_thresh)等。 - 组装三条核心流水线:
- Backbone(主干特征提取线):就像工厂的眼睛和初级筛选部门。它的任务是对输入的原材料(图片)进行快速扫描,提取出图片里所有有用的基本特征(如边缘、颜色块、纹理等)。这条线通常由一些强大的、现成的网络(如 ResNet)担任。
- Neck(特征融合线):就像工厂的信息整合部门。它接收 Backbone 送来的不同粗细(不同尺度)的特征信息。它的任务是把这些信息巧妙地融合起来,确保无论是大物体(用粗略特征)还是小物体(用精细特征)都不会被遗漏。这是对原始 YOLOv1 的一个重要升级。
- Head(检测头):就像工厂的最终决策大脑。它接收 Neck 送来的融合好的高级特征信息,然后直接在特征图的每一个位置上,预测出:
(x, y, w, h):一个边界框的初步位置和大小。confidence:这个框里“有物体”的把握有多大。class_scores:如果这里有物体,它分别是各个类别的概率是多少。
二、工厂的正式工作流程
场景一:训练模式 (
forward函数) - 工厂学徒期
目标:让工厂学会如何正确找东西。需要师傅提供标准答案(target)来纠正它。
- 流水线加工:图片送入 Backbone -> Neck -> Head,最终得到一堆“原始预测”(
pred)。但这些预测一开始全是错的。 - 师傅纠错:工厂的“老师傅”(损失函数 Loss Function)会拿着标准答案(
target,图片中物体框的真实位置和类别)来对比工厂的原始预测(pred)。 - 计算损失:老师傅会严厉地指出:“你这个框的位置偏了 5 个像素!”、“你把这个狗 confidently 认成了猫,大错特错!”。所有这些错误都被量化成一个数值,叫损失(Loss)。
- 自我改进:工厂根据这个损失值,反向调整三条流水线(Backbone, Neck, Head)上所有机器的螺丝(模型参数),争取下次做得更好。
- 输出:这个阶段不输出具体的框,只输出一个损失值,告诉外界“我这次错得有多离谱”。
场景二:推理/检测模式 (
inference函数) - 工厂正式干活
目标:用训练好的工厂对新图片进行检测。不需要标准答案。
- 关闭学习开关:
@torch.no_grad()表示工厂按既定流程工作,不再自我调整。 - 流水线加工:和训练模式一样,图片送入 Backbone -> Neck -> Head,得到“原始预测”(
pred)。 - 解码 Decode (
decode_boxes):原始预测是一些很难懂的数字。解码部门的工作就是把这些数字翻译成人能看懂的信息。- 他们有一个“网格坐标纸”(
create_grid生成的网格),知道每个预测对应原图上的哪个区域。 - 他们把预测的偏移量和缩放比例换算成图片上真实的边框坐标
(x1, y1, x2, y2)和真实的置信度分数。
- 他们有一个“网格坐标纸”(
- 后处理 Postprocess (
postprocess):解码后会有成千上万个框,很多是重复的或瞎猜的。质检部门负责筛选。- 第一轮筛选(置信度阈值):信心不足(分数低于
conf_thresh)的框,直接扔掉。 - 第二轮筛选(非极大值抑制 NMS):对于剩下的框,同一个物体可能被好几个框圈中。NMS 会找出分数最高的那个框作为代表,然后把和它重叠度太高(IoU 超过
nms_thresh)的其他框都扔掉,保证一个物体只留一个最准的框。
- 第一轮筛选(置信度阈值):信心不足(分数低于
- 出货:经过以上所有步骤,工厂最终输出一份清洁的检测报告:一系列画好的框、每个框是什么物体、以及工厂对这个判断的把握有多大。
总结
这个流程可以简单地概括为以下步骤:
训练: 图片 -> 流水线(Backbone-Neck-Head) -> 原始预测 -> 与正确答案对比算损失 -> 调整参数
推理: 图片 -> 流水线 -> 原始预测 -> 解码成真实框 -> 过滤和去重 -> 最终检测结果
希望这个“工厂流水线”的比喻能让你对 YOLOv1 的代码结构和工作原理有一个清晰直观的理解!
一、搭建YOLOv1
首先,我们来搭建YOLOv1的网络结构,包括Backbone网络、Neck网络、Detection head网络以及最后的预测层。为了能够顺利搭建网络,我们预先写好了后续会用到的YOLOv1的配置文件,其内容如下方所示:
# RT-ODLab/config/model_config/yolov1_config.pyyolov1_cfg = {# input'trans_type': 'ssd','multi_scale': [0.5, 1.5],# model'backbone': 'resnet18','pretrained': True,'stride': 32, # P5'max_stride': 32,# neck'neck': 'sppf','expand_ratio': 0.5,'pooling_size': 5,'neck_act': 'lrelu','neck_norm': 'BN','neck_depthwise': False,# head'head': 'decoupled_head','head_act': 'lrelu','head_norm': 'BN','num_cls_head': 2,'num_reg_head': 2,'head_depthwise': False,# loss weight'loss_obj_weight': 1.0,'loss_cls_weight': 1.0,'loss_box_weight': 5.0,# training configuration'trainer_type': 'yolov8',
}
来呗
我们把这段配置代码想象成一个 建造超级视觉AI机器人的“配方”或“蓝图”。
这个配方详细说明了要用什么材料、怎么组装、以及如何训练这个机器人,让它能在图片里又快又准地找到目标。
配方详解(YOLOv1配置版)
- 【准备原材料】- 数据预处理 (
trans_type&multi_scale)
'trans_type': 'ssd'- 通俗解释:规定给图片“做预处理”的流水线标准。这里用的是和SSD算法一样的标准流程(比如调整大小、颜色微调等),这是久经考验的方案,照做就行。
'multi_scale': [0.5, 1.5]- 通俗解释:给机器人看不同尺寸的图片来训练。就像让学生不仅要做正常大小的试卷,还要做放大和缩小的试卷,这样他考试时不管题目字体大小都能适应。
[0.5, 1.5]表示图片会随机缩放至原大小的0.5倍到1.5倍,极大提升机器人检测不同大小物体的能力。
- 通俗解释:给机器人看不同尺寸的图片来训练。就像让学生不仅要做正常大小的试卷,还要做放大和缩小的试卷,这样他考试时不管题目字体大小都能适应。
- 【搭建核心骨架】- Backbone主干网络 (
backbone&pretrained)
'backbone': 'resnet18'- 通俗解释:选择机器人的“眼睛和大脑基础”。这里选用的是ResNet18这个模型。它是一个非常高效且强大的现成模型,已经在数百万张图片上学习过如何提取特征。就像给机器人装上了一个经验丰富的“老兵”的眼睛。
'pretrained': True- 通俗解释:使用“预训练”权重。意思是不是从零开始训练这个“老兵”的眼睛,而是直接用它已经学好的经验作为起点,然后针对我们特定的找任务进行微调。这能节省大量训练时间,并且效果通常更好。
- 【组装信息融合层】- Neck颈部网络 (
neck等一系列参数)
'neck': 'sppf'- 通俗解释:在“眼睛”和“决策大脑”之间,加一个**“信息整合中台”**。
SPPF是一个很强大的模块,它能把“眼睛”看到的不同尺度的信息(大物体轮廓和小物体细节)融合在一起,这样无论物体大小,机器人都能看清楚。
- 通俗解释:在“眼睛”和“决策大脑”之间,加一个**“信息整合中台”**。
'expand_ratio': 0.5,'pooling_size': 5…- 通俗解释:这些是这个“信息中台”的具体工程设计参数。比如
pooling_size: 5表示用一个5x5的窗口来汇聚信息,就像用不同大小的筛子来筛选不同颗粒的信息。
- 通俗解释:这些是这个“信息中台”的具体工程设计参数。比如
- 【安装决策大脑】- Head头部网络 (
head等一系列参数)
'head': 'decoupled_head'- 通俗解释:这是对原始YOLOv1的一个重大升级!原始模型用一个脑子同时思考“框在哪”和“是什么”两个问题。现在我们用**“解耦头”**,也就是拆成两个专家小组:
- 一个定位专家组 (
num_reg_head: 2):专门负责精确预测物体的位置和框的大小。 - 一个分类专家组 (
num_cls_head: 2):专门负责判断物体属于哪个类别。
- 一个定位专家组 (
- 好处:分工明确,专业的人做专业的事,让定位和分类都更准确。
- 通俗解释:这是对原始YOLOv1的一个重大升级!原始模型用一个脑子同时思考“框在哪”和“是什么”两个问题。现在我们用**“解耦头”**,也就是拆成两个专家小组:
- 【设定训练重点】- 损失权重 (
loss_*_weight)
'loss_box_weight': 5.0'loss_obj_weight': 1.0'loss_cls_weight': 1.0- 通俗解释:告诉机器人,在训练时哪方面的错误更重要。这里
loss_box_weight: 5.0意味着:- “框的位置不准” 这种错误非常严重,要高度重视!(权重是5倍)
- “没看到物体” 和 “认错了类别” 的错误也很重要,但相对次要(权重是1倍)。
- 这样机器人就会花更多精力去学习如何把框画得更准。
- 通俗解释:告诉机器人,在训练时哪方面的错误更重要。这里
- 【选择教练】- 训练器类型 (
trainer_type)
'trainer_type': 'yolov8'- 通俗解释:选择哪位名师来训练我们的机器人。这里指定使用YOLOv8官方提供的训练方法。这套方法包含了最新的训练技巧和优化策略,就像请了最顶尖的教练来指导,能最大程度激发机器人的潜能。
总结
这个“配方”远不止是原始的YOLOv1,而是一个用现代技术深度升级和优化的强力版本:
- 更强的眼睛:用了现成的强大主干网络
ResNet,而不是原始的自定义网络。 - 更强的信息融合:增加了
SPPF颈部和FPN/PAN结构,能更好地处理不同大小的物体。 - 更强的决策大脑:使用了“解耦头”,将定位和分类任务分开,精度更高。
- 更科学的训练:采用了最新的训练策略和损失权重设计。
这个配置文件,就是建造一个高性能、高精度、现代化YOLO检测器的完整蓝图。
1.1 搭建Backbone网络
这一部分,我们来搭建主干网络:ResNet18。
由于PyTorch官网已经提供了ResNet的源码和预训练模型,因此,这里我们直接使用PyTorch官方提供的代码。
在下方的代码中,我们展示了PyTorch官方实现的ResNet网络的必要部分的代码。
# RT-ODLab/models/detectors/yolov1/yolov1_backbone.py# --------------------- ResNet -----------------------
class ResNet(nn.Module):def __init__(self, block, layers, zero_init_residual=False):super(ResNet, self).__init__()self.inplanes = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0])self.layer2 = self._make_layer(block, 128, layers[1], stride=2)self.layer3 = self._make_layer(block, 256, layers[2], stride=2)self.layer4 = self._make_layer(block, 512, layers[3], stride=2)...def forward(self, x):"""Input:x: (Tensor) -> [B, C, H, W]Output:c5: (Tensor) -> [B, C, H/32, W/32]"""c1 = self.conv1(x) # [B, C, H/2, W/2]c1 = self.bn1(c1) # [B, C, H/2, W/2]c1 = self.relu(c1) # [B, C, H/2, W/2]c2 = self.maxpool(c1) # [B, C, H/4, W/4]c2 = self.layer1(c2) # [B, C, H/4, W/4]c3 = self.layer2(c2) # [B, C, H/8, W/8]c4 = self.layer3(c3) # [B, C, H/16, W/16]c5 = self.layer4(c4) # [B, C, H/32, W/32]return c5## build resnet
def build_backbone(model_name='resnet18', pretrained=False):if model_name == 'resnet18':model = resnet18(pretrained)feat_dim = 512elif model_name == 'resnet34':model = resnet34(pretrained)feat_dim = 512elif model_name == 'resnet50':model = resnet34(pretrained)feat_dim = 2048elif model_name == 'resnet101':model = resnet34(pretrained)feat_dim = 2048return model, feat_dim
通过调用build_backbone函数即可调用指定的ResNet网络,如ResNet18函数时。当pretrained参数被设置为True时,这部分代码会自动下载由PyTorch官方已提供的ImageNet预训练权重。
在YOLOv1的主体代码中,我们写上下面的代码即可搭建Backbone网络:
# Backbone网络
self.backbone, feat_dim = build_backbone(cfg['backbone'], trainable&cfg['pretrained'])
继续来看看呗
我们要教一个机器人如何“看”图片并找到里面的物体,而 ResNet 就是它的“眼睛和视觉大脑”。
故事:ResNet —— 一个精明的图片“压缩与理解”流水线
这个流水线(ResNet)的任务不是直接找物体,而是把一张高清大图,压缩并提炼成一张小小的、但信息极度浓缩的“特征地图”。后续的 Neck 和 Head 部门(下一道工序)会拿着这张小地图去精确地定位物体。
第一部分:流水线的设计蓝图(
class ResNet)
- 初始准备区(
__init__方法)
这里规定了流水线的所有工作站:
self.conv1: 第一道粗加工站。用一个巨大的 7x7 筛子(卷积核),大步流星(stride=2)地把图片快速过一遍。- 输入:原始图片
[3, H, W](3表示颜色通道) - 输出:初步特征
[64, H/2, W/2]。图片尺寸缩一半,但特征通道数变为64。
- 输入:原始图片
self.bn1和self.relu: 标准化和激活站。把粗加工后的材料标准化一下,然后通过一个“激活函数”让重要信息凸显出来,无关信息被抑制。self.maxpool: 最大池化站。进一步压缩图片尺寸。stride=2意味着尺寸再缩一半。- 输入:
[64, H/2, W/2] - 输出:
[64, H/4, W/4]。至此,图片尺寸已经变为原来的 1/4。
- 输入:
- 核心精加工区(
self.layer1~self.layer4)
这是 ResNet 的精华所在!它由 4 个核心车间组成,每个车间都由若干台相同的“残差机器”(block,如 BasicBlock)构成。
self.layer1:一级精加工车间。- 任务:对输入进行深度特征提取,不改变尺寸(
stride=1)。 - 输入输出:
[64, H/4, W/4]->[64, H/4, W/4]
- 任务:对输入进行深度特征提取,不改变尺寸(
self.layer2:二级精加工车间。- 任务:继续提取更复杂的特征,并且把尺寸缩小一倍(
stride=2)! - 输入输出:
[64, H/4, W/4]->[128, H/8, W/8](通道数翻倍,尺寸减半)
- 任务:继续提取更复杂的特征,并且把尺寸缩小一倍(
self.layer3:三级精加工车间。- 任务:同上,继续提取和缩小。
- 输入输出:
[128, H/8, W/8]->[256, H/16, W/16]
self.layer4:四级精加工车间。- 任务:最后一级加工,得到最抽象、最精华的特征。
- 输入输出:
[256, H/16, W/16]->[512, H/32, W/32]
为什么叫“残差”机器?
想象一下学习新知识。最好的方式不是把旧知识全丢掉,而是在旧知识的基础上,只学习“新知识”和“旧知识”的差别(残差)。这样学习起来更轻松、更高效,也不容易遗忘。ResNet 的每个 block 就是这么工作的,这也是它为什么能做得那么深(层数多)还不失效的秘诀。
- 流水线工作流程(
forward方法)
这就是把一张图片x送入流水线的全过程,我们清晰地看到数据是如何一步步被加工和压缩的:
def forward(self, x):c1 = self.conv1(x) # 粗加工: [B, 3, H, W] -> [B, 64, H/2, W/2]c1 = self.bn1(c1) # 标准化c1 = self.relu(c1) # 激活c2 = self.maxpool(c1) # 池化: [B, 64, H/2, W/2] -> [B, 64, H/4, W/4]c2 = self.layer1(c2) # 一级加工: 尺寸不变 [B, 64, H/4, W/4]c3 = self.layer2(c2) # 二级加工: [B, 64, H/4, W/4] -> [B, 128, H/8, W/8]c4 = self.layer3(c3) # 三级加工: [B, 128, H/8, W/8] -> [B, 256, H/16, W/16]c5 = self.layer4(c4) # 四级加工: [B, 256, H/16, W/16] -> [B, 512, H/32, W/32]return c5 # 返回最终提炼出的“特征小地图”
最终成果:一张尺寸为原图 1/32 的“特征小地图”(c5)。例如,输入 416x416 的图片,会得到 13x13 的特征图。这张图里每一个小格子(比如13x13里的某一个),都对应着原图上一大片区域(32x32像素)的精华信息。
第二部分:选择并装备流水线(
build_backbone函数)
这部分就像工厂的采购部,根据你的订单(配置参数)去获取指定的流水线。
if model_name == 'resnet18': 订单是 ResNet18 号流水线。- 它就帮你联系 PyTorch 官方工厂,调来一条 ResNet18 流水线 (
model = resnet18(pretrained))。 - 同时告诉你,这条流水线最终产出的“特征小地图”的厚度(通道数) 是 512 (
feat_dim = 512)。这个数字对后续搭建 Neck 和 Head 至关重要,因为它们需要知道输入数据的形状。
- 它就帮你联系 PyTorch 官方工厂,调来一条 ResNet18 流水线 (
pretrained=True: 采购“预训练”好的流水线。- 这意味着这条流水线已经在几百万张图片(ImageNet 数据集)上“练习”过了,已经学会了如何高效地提取通用特征。我们直接拿来用,只需要稍微微调一下,它就能在我们的特定任务(检测物体)上表现得非常出色,这比从零训练一条新流水线要快得多、好得多!
第三部分:在YOLO工厂中安装流水线
最后,在你的 YOLOv1 主工厂里,只用一行代码就能完成Backbone的搭建:
self.backbone, feat_dim = build_backbone(cfg['backbone'], trainable&cfg['pretrained'])
这行代码的意思是:
“根据配置文件 cfg 里的指令,去建造 (build_backbone) 我的主干网络。我要的型号是 cfg['backbone'](比如 ‘resnet18’),并且如果当前是训练模式且配置要求用预训练模型,就给我搬那条预训练过的流水线过来。”
总结
这段代码实现了一个高效的特征提取流水线(Backbone),它:
- 逐步压缩图片尺寸(从 H/W 到 H/32, W/32)。
- 逐步增加信息浓度(通道数从3增加到512)。
- 利用“残差学习”,使得网络可以非常深,从而提取到非常复杂和抽象的特征。
- 通过预训练,获得了强大的通用图像特征提取能力。
- 最终输出一张小而精的“特征地图”,为后续的物体检测任务奠定了坚实的基础。
这就是为什么我们不使用原始YOLOv1的Backbone,而要用ResNet——因为它更强大、更高效、更现代!
漂亮
1.2 搭建Neck网络
按照上一节所讲的,Neck部分我们选择SPP网络,其结构非常简单,仅仅是若干不同大小的maxpooling层堆叠而成,相关的代码如下所示,这里,我们参考了YOLOv5中的Fast版本的SPP实现。
# RT-ODLab/models/detectors/yolov1/yolov1_neck.py# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
class SPPF(nn.Module):"""This code referenced to https://github.com/ultralytics/yolov5"""def __init__(self, in_dim, out_dim, expand_ratio=0.5, pooling_size=5, act_type='lrelu', norm_type='BN'):super().__init__()inter_dim = int(in_dim * expand_ratio)self.out_dim = out_dimself.cv1 = Conv(in_dim, inter_dim, k=1, act_type=act_type, norm_type=norm_type)self.cv2 = Conv(inter_dim * 4, out_dim, k=1, act_type=act_type, norm_type=norm_type)self.m = nn.MaxPool2d(kernel_size=pooling_size, stride=1, padding=pooling_size // 2)def forward(self, x):x = self.cv1(x)y1 = self.m(x)y2 = self.m(y1)return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))def build_neck(cfg, in_dim, out_dim):model = cfg['neck']print('==============================')print('Neck: {}'.format(model))# build neckif model == 'sppf':neck = SPPF(in_dim=in_dim,out_dim=out_dim,expand_ratio=cfg['expand_ratio'], pooling_size=cfg['pooling_size'],act_type=cfg['neck_act'],norm_type=cfg['neck_norm'])return neck
在我们的YOLOv1主体代码框架中,我们可以通过调用build_neck函数来搭建SPP模块:
## 颈部网络
self.neck = build_neck(cfg, feat_dim, out_dim=512)
head_dim = self.neck.out_dim
故事:SPP模块 —— 一个“多孔径信息筛”工作站
想象一下,Backbone(ResNet)部门送来的“特征地图”是一堆混合了不同大小关键信息的原料。有的信息很大(比如大象的轮廓),有的信息很小(比如远处的一只猫)。我们的任务是不改变这张地图的尺寸,但让它包含的信息更丰富、更鲁棒。
SPP模块就是一个非常聪明的**“多孔径信息筛”工作站**。
第一部分:工作站的设计(
class SPPF)
这个工作站的设计非常巧妙,它只做三件事:
- 初步压缩(
self.cv1)
self.cv1 = Conv(...)- 比喻:这是一个初步压缩器。进来的原料(
in_dim维特征)有点多,先用一个1x1的卷积核把它压缩一下,减少通道数(inter_dim = int(in_dim * expand_ratio))。这就像把一堆杂乱的文件先粗略分类,放进更少的文件夹里,方便后续处理。
- 比喻:这是一个初步压缩器。进来的原料(
- 核心操作:多孔径筛选(
self.m和forward中的操作)
这是整个工作站的精华!
-
self.m = nn.MaxPool2d(...)- 比喻:这是一个固定孔径的“最大信息筛”。它的孔径大小由
pooling_size=5决定。 - 工作原理:这个筛子会在特征图的每一个小区域(
5x5的窗口)里,只留下最显著、最亮的那个特征点(这就是MaxPooling的“取最大值”操作),忽略其他次要信息。 - 神奇之处:它不改变特征图尺寸(因为
stride=1且做了padding),只做信息提炼。
- 比喻:这是一个固定孔径的“最大信息筛”。它的孔径大小由
-
forward函数里的连环筛:y1 = self.m(x) # 用筛子筛第一遍 y2 = self.m(y1) # 把第一遍筛过的结果,再筛第二遍! return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))- 比喻:我们来玩一个“连环筛”的游戏!
- 第一筛 (
y1):对原始输入x筛一遍。这个结果代表了原图中中等尺度(受5x5孔径影响)的显著信息。 - 第二筛 (
y2):把y1再筛一遍。这相当于在一个更大的感受野(可以想象成9x9的区域)里找最大值,它捕捉的是更大尺度的显著信息。 - 第三筛 (
self.m(y2)):再把y2筛一遍!这相当于在一个巨大的(13x13)感受野里找最大值,捕捉超大尺度的全局显著信息。
- 第一筛 (
- 最终,我们把四种材料放到一起:
x: 原始材料(包含所有最精细的细节)y1: 中等尺度信息y2: 大尺度信息self.m(y2): 超大尺度信息
- 用
torch.cat把它们全部拼接起来。现在,我们的特征图厚度(通道数)变成了原来的4倍(inter_dim * 4),因为它同时包含了从“细节”到“全局”的所有尺度的精华信息!
- 比喻:我们来玩一个“连环筛”的游戏!
- 最终整合(
self.cv2)
self.cv2 = Conv(...)- 比喻:现在我们有了一摞不同尺度的信息报告,太多了,需要一位最终整合员。
- 这位整合员(又一个
1x1卷积)的工作是把这摞厚厚的报告(inter_dim * 4通道)压缩、整合成一份格式统一、精炼的最终报告(out_dim通道),送给下一个部门(Head)。
SPP的核心思想:****“不管你关心的信息是大是小,我同时给你看一遍,保证一个都漏不掉!”** 这极大地增强了模型对不同大小物体的检测能力。
第二部分:工作站采购部(
build_neck函数)
这部分代码就是根据总公司的蓝图(cfg配置字典)来订购和组装上面那个SPP工作站。
neck = SPPF(in_dim=in_dim, # 告诉工厂:进来的原料厚度是feat_dim(来自Backbone)out_dim=out_dim, # 我最终要的成品厚度是512expand_ratio=cfg['expand_ratio'], # 中间压缩率用0.5pooling_size=cfg['pooling_size'], # 给我配一个孔径为5的筛子act_type=cfg['neck_act'], # 激活函数用LeakyReLUnorm_type=cfg['neck_norm'] # 标准化用BatchNorm
)
它读取配置文件里的参数,像填订单一样,定制了一个符合我们要求的SPPF工作站。
第三部分:在YOLO工厂中安装工作站
最后,在你的YOLO主工厂里,用两行代码就完成了Neck的搭建:
self.neck = build_neck(cfg, feat_dim, out_dim=512)
head_dim = self.neck.out_dim
- 第一行:调用采购部(
build_neck函数),命令是:“根据cfg的配置,建造一个Neck。它输入的通道数是feat_dim(这是Backbone告诉我的),输出的通道数你给我做成512。” - 第二行:记下这个新工作站最终产出的维度
head_dim(其实就是512),因为下一个部门(Head)需要知道它要接收的数据有多“厚”。
总结
SPP模块是一个极其巧妙而有效的设计,它:
- 不改变输入特征的宽高,只改变其通道数。
- 通过同一个池化层的重复应用,低成本地实现了多尺度特征融合。
- 让后续的检测头(Head)同时拥有细节特征和全局语义特征,从而无论是大目标还是小目标,都能获得更好的检测效果。
这就是YOLOv1配置中“添加Neck模块”的具体实现,也是它性能远超原版的关键升级之一。
1.3 搭建Detection head网络
这一部分就相对简单了,只需要搭建两条分支,每条分支放置若干层卷积层即可,如下方的代码所示:
# RT-ODLab/models/detectors/yolov1/yolov1_head.pyclass DecoupledHead(nn.Module):def __init__(self, cfg, in_dim, out_dim, num_classes=80):super().__init__()print('==============================')print('Head: Decoupled Head')self.in_dim = in_dimself.num_cls_head=cfg['num_cls_head']self.num_reg_head=cfg['num_reg_head']self.act_type=cfg['head_act']self.norm_type=cfg['head_norm']# cls headcls_feats = []self.cls_out_dim = max(out_dim, num_classes)for i in range(cfg['num_cls_head']):if i == 0:cls_feats.append(Conv(in_dim, self.cls_out_dim, k=3, p=1, s=1, act_type=self.act_type,norm_type=self.norm_type,depthwise=cfg['head_depthwise']))else:cls_feats.append(Conv(self.cls_out_dim, self.cls_out_dim, k=3, p=1, s=1, act_type=self.act_type,norm_type=self.norm_type,depthwise=cfg['head_depthwise']))# reg headreg_feats = []self.reg_out_dim = max(out_dim, 64)for i in range(cfg['num_reg_head']):if i == 0:reg_feats.append(Conv(in_dim, self.reg_out_dim, k=3, p=1, s=1, act_type=self.act_type,norm_type=self.norm_type,depthwise=cfg['head_depthwise']))else:reg_feats.append(Conv(self.reg_out_dim, self.reg_out_dim, k=3, p=1, s=1, act_type=self.act_type,norm_type=self.norm_type,depthwise=cfg['head_depthwise']))self.cls_feats = nn.Sequential(*cls_feats)self.reg_feats = nn.Sequential(*reg_feats)def forward(self, x):"""in_feats: (Tensor) [B, C, H, W]"""cls_feats = self.cls_feats(x)reg_feats = self.reg_feats(x)return cls_feats, reg_feats# build detection head
def build_head(cfg, in_dim, out_dim, num_classes=80):head = DecoupledHead(cfg, in_dim, out_dim, num_classes) return head
在我们的YOLOv1主体代码框架中,我们可以通过调用build_head函数来搭建Decoupled head:
## 检测头
self.head = build_head(cfg, head_dim, head_dim, num_classes)
继续瞅瞅
故事:Decoupled Head —— “分工明确的专家团队”
想象一下,Neck(SPP模块)送来的是一份信息非常丰富的“综合情报报告”。这份报告里既有关于“是什么”(分类)的线索,也有关于“在哪里”(定位)的线索,它们混在一起。
现在,我们的任务是要从这份报告里得出两个明确的结论:
- 物体是什么? (分类任务)
- 物体的精确位置在哪? (回归任务)
原始YOLOv1的做法是:让一个团队同时处理这两个问题。这就像让一个医生既负责看X光片(分类:有没有病灶?),又负责拿手术刀做手术(回归:病灶的精确位置和大小?)。虽然也能做,但效率和精度可能不是最优。
而“解耦头”的做法是:成立两个专业的专家团队,一个专门负责“分类”,一个专门负责“定位”。它们各自研究同一份情报,但只专注于解决自己最擅长的问题。这就是“解耦”(Decoupled)的含义——将耦合在一起的任务分离开。
第一部分:组建专家团队(
class DecoupledHead)
这个类就是在组建这两个专家团队。
- 团队配置(
__init__方法中的参数)
num_cls_head和num_reg_head:这决定了每个专家团队有多少层(即,有多少位专家进行接力分析)。比如num_cls_head=2表示分类专家组有2层卷积层。act_type和norm_type:这是给每位专家配备的标准工作装备(激活函数和标准化层),确保他们的工作流程高效稳定。depthwise:这是一种更高效、更轻量化的“专家工作模式”(深度可分离卷积)。
- 组建分类专家组 (
cls_feats)
cls_feats = []
for i in range(cfg['num_cls_head']):if i == 0:# 第一位专家:直接接触原始情报cls_feats.append(Conv(in_dim, self.cls_out_dim, k=3, p=1, s=1, ...))else:# 后续专家:基于前一位专家的分析结果进行深化cls_feats.append(Conv(self.cls_out_dim, self.cls_out_dim, k=3, p=1, s=1, ...))
self.cls_feats = nn.Sequential(*cls_feats) # 将专家们串联成一个流水线
- 比喻:分类专家组是一个分析流水线。
- 第一位专家:他从总情报 (
in_dim) 中接手,开始初步分析,并把他的发现整理成一份标准的分类报告格式 (cls_out_dim)。 - 第二位专家:他拿到前一位的报告,并不去看原始情报了。他的任务是进一步提炼和确认这份报告,让结论更加可靠。他输出的还是同样格式的报告。
nn.Sequential就像把这两位专家安排在一个房间里,情报从第一位传到最后一位,完成整个分类分析流程。
- 第一位专家:他从总情报 (
- 组建定位专家组 (
reg_feats)
reg_feats = []
for i in range(cfg['num_reg_head']):if i == 0:# 第一位专家:直接接触原始情报reg_feats.append(Conv(in_dim, self.reg_out_dim, k=3, p=1, s=1, ...))else:# 后续专家:基于前一位专家的分析结果进行深化reg_feats.append(Conv(self.reg_out_dim, self.reg_out_dim, k=3, p=1, s=1, ...))
self.reg_feats = nn.Sequential(*reg_feats) # 将专家们串联成一个流水线
- 比喻:定位专家组的的工作模式和分类组完全一样,但他们是另一批专家,他们的工作目标不同:
- 他们的任务是分析物体的精确坐标 (
x, y, w, h)。 - 他们输出的报告格式 (
reg_out_dim) 也是为了后续计算坐标而设计的。
- 他们的任务是分析物体的精确坐标 (
关键点:两个团队独立工作,互不干扰。它们都从同一份原始情报 (x) 开始,但各自发展出自己的专业分析结果。
第二部分:团队工作流程(
forward方法)
def forward(self, x):cls_feats = self.cls_feats(x) # 把情报交给分类专家组,得到分类结论reg_feats = self.reg_feats(x) # 把同一份情报交给定位专家组,得到定位结论return cls_feats, reg_feats # 返回两份专家报告
这个过程非常简单清晰:
- 输入:来自Neck的“综合情报”
x。 - 过程:将
x同时送入两个专家团队。 - 输出:得到两份专家报告:
cls_feats:这是一张“是什么”的热力图,每个位置的值代表了该处是某个类别的概率。reg_feats:这是一张“在哪里”的偏移量表,每个位置的值用于计算最终边界框的精确坐标。
第三部分:团队调度中心(
build_head函数)
这个函数就是YOLO工厂的人力资源部,它根据总公司的要求(cfg配置)来招募和组建上面那两个专家团队。
def build_head(cfg, in_dim, out_dim, num_classes=80):head = DecoupledHead(cfg, in_dim, out_dim, num_classes)return head
它告诉 DecoupledHead 类:
in_dim:专家们要分析的情报有多“厚”(输入通道数)。out_dim:我们希望专家们输出的报告有多“厚”(输出通道数)。num_classes:分类专家需要知道一共有多少种物体要区分。cfg:其他所有人员配置细节,比如要招几位专家、用什么装备等。
第四部分:在YOLO工厂中启用团队
最后,在主代码里,用一行代码就完成了两个专家团队的组建:
self.head = build_head(cfg, head_dim, head_dim, num_classes)
这行代码的意思是:“人力资源部,请按照 cfg 里的配置,帮我组建一个检测头。输入输出的情报厚度都是 head_dim(512),要检测的类别数是 num_classes。”
总结
这段代码实现了一个“分工明确”的检测头:
- 专业化:将“分类”和“定位”这两个不同性质的任务交给两个独立的专家团队(分支)处理,比一个团队同时处理两个任务效果更好。
- 深度化:每个团队都由多层(
num_*_head)专家(卷积层)构成,允许对特征进行更深度的处理,从而做出更准确的判断。 - 并行处理:两个团队同时工作,效率极高。
这就是“解耦头”(Decoupled Head)的核心思想,也是现代目标检测器相比YOLOv1等早期模型的一个重要演进,它显著提升了检测精度。
1.4 搭建预测层
最后,我们只需要放置三层1x1卷积,分别去完成objectness预测、classification预测以及bbox预测即可,如下方的代码所示。
## 预测层
self.obj_pred = nn.Conv2d(head_dim, 1, kernel_size=1)
self.cls_pred = nn.Conv2d(head_dim, num_classes, kernel_size=1)
self.reg_pred = nn.Conv2d(head_dim, 4, kernel_size=1)
故事:预测层 —— “三位专业裁判”
想象一下,Decoupled Head(解耦头)里的两个专家团队已经完成了他们的工作,输出了两份高度提炼的报告:
- 分类专家组的报告 (
cls_feats):一张图,上面标记了每个位置“可能是什么”的丰富特征。 - 定位专家组的报告 (
reg_feats):一张图,上面标记了每个位置“可能在哪”的丰富特征。
现在,我们需要从这两份报告中读出最终的、明确的预测数值。这个过程就像请来三位专业裁判,他们各自负责一项评分,并且他们的工作极其简单高效:
三位裁判的工作(三行代码)
这三位裁判的工作方式一模一样,他们都是“1x1卷积裁判”。
- 物体裁判 (
self.obj_pred)
self.obj_pred = nn.Conv2d(head_dim, 1, kernel_size=1)
- 任务:判断一个格子里到底有没有物体。
- 工作方式:
- 他只看定位专家组的报告 (
reg_feats的通道数head_dim)。 - 他用一个神奇的“1x1标准答案板”(
1x1卷积核)在整个报告上扫描。 - 输出:对于报告上的每一个点,他只给出一个分数(输出通道为
1)。这个分数就是“物体置信度”,越接近1表示他越确信这个位置有一个物体。
- 他只看定位专家组的报告 (
- 分类裁判 (
self.cls_pred)
self.cls_pred = nn.Conv2d(head_dim, num_classes, kernel_size=1)
- 任务:判断这个物体具体是什么类别。
- 工作方式:
- 他只看分类专家组的报告 (
cls_feats的通道数head_dim)。 - 他也用一个“1x1标准答案板”扫描报告。
- 输出:对于每一个点,他给出一个长度为
num_classes的分数列表(输出通道为num_classes)。比如有20个类别,他就输出20个分数。分数最高的那个类别,就是他最终判断的结果。
- 他只看分类专家组的报告 (
- 定位裁判 (
self.reg_pred)
self.reg_pred = nn.Conv2d(head_dim, 4, kernel_size=1)
- 任务:判断这个物体框的确切位置和大小。
- 工作方式:
- 他也是看定位专家组的报告 (
reg_feats)。 - 他同样用“1x1标准答案板”扫描。
- 输出:对于每一个点,他给出4个数值(输出通道为
4)。这4个数值通常对应边界框的中心点坐标偏移量 (tx, ty) 和宽高的缩放量 (tw, th)。注意:这些是原始偏移量,需要后续用decode_boxes函数解码成真实的坐标。
- 他也是看定位专家组的报告 (
为什么用“1x1卷积”当裁判?
这体现了极致的简洁和高效:
- 不改变空间结构:裁判只是在每个位置(
H, W保持不变)上对已有的深度特征(head_dim维)做一次“总结陈词”,不会改变特征图的高和宽。 - 专职专用:他们的任务仅仅是将深度特征通道数映射到我们需要的特定维数(1、
num_classes或 4)。1x1卷积是实现这一目的最直接、参数最少的操作。 - 深度融合:虽然每个裁判只输出很少的值,但他们做出判断时,是综合了输入特征所有通道的信息(因为1x1卷积会进行跨通道的信息融合)。
工作流程串联
整个流程在推理时是这样的:
- Backbone:“眼睛”看到图片,输出初步特征。
- Neck (SPPF):“信息整合中台”对特征进行多尺度融合,输出 richer 的特征。
- Head (Decoupled):两个“专家团队”分别处理分类和定位信息。
- Prediction Layer (裁判):
- 定位裁判和物体裁判查看定位专家的报告 (
reg_feats),分别给出[B, 4, H, W]的偏移量和[B, 1, H, W]的置信度。 - 分类裁判查看分类专家的报告 (
cls_feats),给出[B, num_classes, H, W]的类别分数。
- 定位裁判和物体裁判查看定位专家的报告 (
- 后处理:将三位裁判的输出合并,经过解码、阈值过滤、NMS等操作,得到最终的检测框
[x1, y1, x2, y2]、置信度、类别标签。
总结
这三行代码定义的预测层,是整个YOLO模型的输出接口。它们的作用是:
obj_pred:将特征转换为“是否有物”的置信度。cls_pred:将特征转换为“是何种类”的概率分布。reg_pred:将特征转换为“框在何处”的原始偏移量。
它们以最轻量、最高效的方式,完成了从抽象特征到具体预测值。
1.5 测试阶段的前向推理
在完成了网络结构的搭建后,我们参考最开始给出的图1,依葫芦画瓢地写出前向推理部分的代码,这部分的代码逻辑比较简单,读者直接阅读代码即可。
@torch.no_grad()
def inference(self, x):# 主干网络feat = self.backbone(x)# 颈部网络feat = self.neck(feat)# 检测头cls_feat, reg_feat = self.head(feat)# 预测层obj_pred = self.obj_pred(cls_feat)cls_pred = self.cls_pred(cls_feat)reg_pred = self.reg_pred(reg_feat)fmp_size = obj_pred.shape[-2:]# 对 pred 的size做一些view调整,便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred = cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred = reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# 测试时,笔者默认batch是1,# 因此,我们不需要用batch这个维度,用[0]将其取走。obj_pred = obj_pred[0] # [H*W, 1]cls_pred = cls_pred[0] # [H*W, NC]reg_pred = reg_pred[0] # [H*W, 4]# 每个边界框的得分scores = torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())# 解算边界框, 并归一化边界框: [H*W, 4]bboxes = self.decode_boxes(reg_pred, fmp_size)if self.deploy:# [n_anchors_all, 4 + C]outputs = torch.cat([bboxes, scores], dim=-1)return outputselse:# 将预测放在cpu处理上,以便进行后处理scores = scores.cpu().numpy()bboxes = bboxes.cpu().numpy()# 后处理bboxes, scores, labels = self.postprocess(bboxes, scores)return bboxes, scores, labels
对于上面的代码,我们做一些必要的说明。在上方的代码中,分别对应于objectness预测、classification预测和bbox预测的三个变量obj_pred、cls_pred、reg_pred的shape都是[B, C, H, W],其中,B是batch size,C是channel,H是特征图的高,W 是特征图的宽。为了方便后续的处理,我们将shape[B, C, H, W]调整成了[B,N,C]的格式,其中N=H*W,这样的操作可以理解为我们将所有网格的预测框都汇总到了一起, 后续去计算损失的时候也会方便一些。当然,这一步没有任何的物理意义,仅仅是为了方便后续的操作。
在完成了上述的reshape操作后,我们即可去计算每一个边界框的得分:
# 每个边界框的得分
scores = torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())
这里,我们使用到了开平方sqrt操作,这是考虑到边界框的置信度obj_pred.sigmoid()和类别的置信度cls_pred.sigmoid()都是0~1范围内的数,两个小于1的数乘在一起只会更小,因此采用开根号的方式来校正数量级,这一操作也是借鉴与FCOS(Fully Convolutional One-Stage)工作 。
随后,我们再使用预测出来的边界框偏移量reg_pred 去解耦出来最终的边界框坐标,对于这一部分的原理,我们将会再下一接做详细的原理讲解,这里暂且卖一个关子。
# 解算边界框, 并归一化边界框: [H*W, 4]
bboxes = self.decode_boxes(reg_pred, fmp_size)最终,我们将所有的预测结果统统丢进后处理的函数中,去完成阈值筛选和非极大值抑制,当这一步骤也完成后,我们就得到了最终的YOLOv1的检测结果。
这一部分的前向推理常用在测试阶段,比如我们训练好了模型后,需要去计算模型在测试集上的性能,那么就需要我们的模型对输入的图片进行推理,输出检测结果。另一方面,在实际场景运行时,我们的模型也需要使用这部分的推理去处理每一张输入的图片,给出检测结果。
小白笔记来啦!!!
故事:YOLO工厂的“正式生产流水线”
这段代码描述了训练好的模型如何对一张新图片进行检测的完整流程。我们继续沿用之前的比喻,这就像是工厂接到一个订单(一张新图片),然后启动全自动化流水线,最终输出产品(检测结果)。
流水线启动 (
@torch.no_grad())
@torch.no_grad()- 比喻:这是关闭学习模式,进入生产模式的开关。在这个模式下,工厂的机器不会记录任何生产数据用于自我改进(不计算梯度),只是单纯地执行既定流程。这能大幅提高生产速度并减少资源占用。
第一步:三级加工 (
feat = self.backbone(x)->feat = self.neck(feat)->cls_feat, reg_feat = self.head(feat))
这三步我们已经很熟悉了,就是原材料的三级加工:
- Backbone(初级加工):用“ResNet眼睛”快速扫描图片,提取基础特征 (
feat)。 - Neck(精细加工):用“SPPF信息中台”对特征进行多尺度融合,让特征更丰富 (
feat)。 - Head(专业分工):将融合后的特征送入“两个专家团队”,分别产出用于分类 (
cls_feat) 和定位 (reg_feat) 的专项报告。
第二步:专家评判 (
obj_pred = self.obj_pred(cls_feat)…)
这步是三位裁判上场,对专家报告进行最终打分:
obj_pred:物体裁判审视分类专家的报告,给出每个位置“有物体”的置信分。cls_pred:分类裁判审视分类专家的报告,给出每个位置“是某类”的各类别分数。reg_pred:定位裁判审视定位专家的报告,给出每个位置框的4个原始偏移量。
此时,三位裁判的输出格式都是 [B, C, H, W](比如 [1, 80, 13, 13]),这就像有13x13个格子,每个格子里都有一摞打分卡。
第三步:整理报告(
permute和flatten操作)
obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)
- 比喻:现在我们的报告是按网格方式存放的(
13x13格,每格一摞分数),不方便后续的“质检部门”(后处理)工作。我们需要把它重新整理一下。 permute(0, 2, 3, 1):改变维度顺序。这就像把“每格一摞分数”的摆放方式,改成“把所有格子的分数摞分别一张张摊开平铺”。从[Batch, Channel, Height, Width]变成[Batch, Height, Width, Channel]。flatten(1, 2):将高度和宽度维度合并。这就像把13x13的网格图撕下来,把所有格子按顺序粘成一条长长的清单。格式变成了[Batch, Height*Width, Channel](例如[1, 169, 80])。- 目的:这个操作没有数学意义,纯粹是为了编程方便。这样,所有的预测框就都排列在一个维度上,后续的阈值过滤、排序、NMS等操作实现起来就非常简单直观。
第四步:计算最终得分 (
scores = torch.sqrt(...))
scores = torch.sqrt(obj_pred.sigmoid() * cls_pred.sigmoid())
- 比喻:这是质量综合得分的计算公式。
obj_pred.sigmoid():物体裁判打的分,通过sigmoid函数转换成0-1之间的“有物概率”。cls_pred.sigmoid():分类裁判打的分,转换成0-1之间的“类别概率”(取分数最高的那个类别的概率)。- 相乘 (
*):一个格子的最终得分,既要相信“这里有个东西”,也要相信“这个东西是某个类别”。两者是同时成立的关系,所以用乘法综合。但两个小于1的数相乘,结果会变得更小(例如0.9 * 0.9 = 0.81)。 - 开根号 (
sqrt):为了校正数值尺度。取平方根后,数值会相对变大一些(sqrt(0.81) ≈ 0.9),更接近原始置信度的水平,使得分数分布更合理,便于后续设置阈值。这是一个非常实用的工程技巧。
第五步:解码坐标 (
bboxes = self.decode_boxes(reg_pred, fmp_size))
- 比喻:定位裁判给出的 (
tx, ty, tw, th) 是**“图纸上的相对坐标”。现在需要一位解码员**,根据这张图纸的尺寸 (fmp_size),把这些相对坐标换算成**“真实世界中的绝对坐标”**(x1, y1, x2, y2)。 - 这个解码过程涉及将偏移量加上网格坐标、用指数函数处理宽高、并映射回原图尺寸等步骤。这是核心算法,所以作者说会在下一节详述。
第六步:质检与包装(后处理
postprocess)
- 阈值筛选:质检员说:“综合得分低于
conf_thresh(比如0.5) 的产品都是次品,扔掉!”。 - 非极大值抑制 (NMS):质检员又说:“好几个框框的都是同一个物体,我只留得分最高的那一个,其他的都扔掉!”。这确保了每个物体只被检测一次。
- 最终出品:经过层层筛选,最终得到干净、准确的检测结果:
bboxes(框坐标),scores(置信度),labels(类别标签)。
两个输出分支 (
if self.deploy)
else分支(常规测试):将结果移到CPU并转为NumPy格式,进行后处理,返回给人看的最终结果。if self.deploy分支(部署模式):直接返回拼接好的Tensor。这个模式是为了简化输出,便于将模型部署到手机、摄像头等终端设备(例如转换成ONNX格式时),这些设备上的后处理代码可能用C++等语言编写。
总结
这段 inference 代码是整个YOLO模型的总装流水线,它:
- 串联所有组件:指挥Backbone、Neck、Head、Prediction层有序工作。
- 转换数据格式:将网络输出转换成便于后处理的形式。
- 执行核心算法:计算综合得分、解码边界框坐标。
- 进行最终质检:通过阈值和NMS输出最可靠的检测结果。
这就是模型在实际应用时所做的每一步,理解了这个流程,你就完全理解了YOLOv1是如何从输入一张图片,到最后输出检测框的。
1.6 训练阶段的前向推理
最后,我们再介绍一下训练阶段会使用到的推理函数。相较于测试阶段的推理,训练阶段的推理往往不包含后处理的,而是直接将网络的预测结果做一些必要的调整后就输出,以便去完成后续的标签分配和损失函数的计算等。对于这一部分的代码,实现起来也较为简单,读者可以直接阅读下方的代码
def forward(self, x):if not self.trainable:return self.inference(x)else:# 主干网络feat = self.backbone(x)# 颈部网络feat = self.neck(feat)# 检测头cls_feat, reg_feat = self.head(feat)# 预测层obj_pred = self.obj_pred(cls_feat)cls_pred = self.cls_pred(cls_feat)reg_pred = self.reg_pred(reg_feat)fmp_size = obj_pred.shape[-2:]# 对 pred 的size做一些view调整,便于后续的处理# [B, C, H, W] -> [B, H, W, C] -> [B, H*W, C]obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)cls_pred = cls_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)reg_pred = reg_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)# decode bboxbox_pred = self.decode_boxes(reg_pred, fmp_size)# 网络输出outputs = {"pred_obj": obj_pred, # (Tensor) [B, M, 1]"pred_cls": cls_pred, # (Tensor) [B, M, C]"pred_box": box_pred, # (Tensor) [B, M, 4]"stride": self.stride, # (Int)"fmp_size": fmp_size # (List) [fmp_h, fmp_w]} return outputs
再完成了必要的reshape操作后(对应torch中的view操作),我们再使用偏移量预测reg_pred 结算出box_pred,即预测的边界框的坐标,后续我们在计算损失时会用到这一变量。最后,我们将所有的预测结果以及其他的必要的参数统一放到outputs变量中,去参与后续的处理。
马上要结束本篇了!
这段训练阶段的前向传播代码是模型学习的核心,它的目的和测试阶段完全不同。
故事:YOLO工厂的“内部质检与学习”流程
想象一下,测试阶段的推理 (inference) 是工厂的正式生产线,目的是为客户提供完美成品。而训练阶段的这个 forward 函数,则是工厂的内部质检和学习会。它的目的不是出货,而是找出当前生产流程中的错误,从而改进工艺。
核心区别:目的不同
- 测试/推理 (
inference):输入图片 -> 输出检测结果 (给用户看) - 训练 (
forward):输入图片 -> 输出“未经加工的原始预测数据” (给“损失函数”和“标签分配”模块使用,用于计算错误并指导模型更新)
流程解析
第一步:模式判断 (
if not self.trainable)
if not self.trainable:return self.inference(x) # 如果是测试模式,直接调用正式的推理流程
else:... # 否则,进入下面的训练流程
- 比喻:工厂大门有个打卡机。如果今天是“生产日”(非训练模式),工人直接去流水线干活。如果是“学习日”(训练模式),工人们则前往会议室。
第二步:特征提取与预测(与推理阶段相同)
feat = self.backbone(x)
feat = self.neck(feat)
cls_feat, reg_feat = self.head(feat)
obj_pred = self.obj_pred(cls_feat)
cls_pred = self.cls_pred(cls_feat)
reg_pred = self.reg_pred(reg_feat)
- 过程:这一步和推理流程完全一样。因为无论是学习还是生产,加工原料的流程是不变的。Backbone、Neck、Head、Prediction层都会正常工作,产出原始的预测值
obj_pred,cls_pred,reg_pred。
第三步:整理数据(与推理阶段相同)
obj_pred = obj_pred.permute(0, 2, 3, 1).contiguous().flatten(1, 2)
...
- 目的:同样是为了后续处理方便,将数据从
[B, C, H, W]的网格格式转换为[B, H*W, C]的清单格式。这样,每个预测框都成了清单上独立的一行。
第四步:解码边界框(关键步骤)
box_pred = self.decode_boxes(reg_pred, fmp_size)
- 比喻:在内部学习会上,我们不能只看“图纸上的相对坐标”(
reg_pred),我们需要知道根据当前工艺,实际生产出的“样品框”的精确尺寸 (box_pred) 是多少。 - 为什么训练需要解码?:因为损失函数(Loss Function)需要计算预测框 (
box_pred) 和真实框(Ground Truth)之间的直接差距,比如IoU(交并比)或坐标误差。我们必须把网络输出的偏移量解码成真实的坐标,才能进行这种比较。
第五步:打包学习材料(与推理阶段根本不同)
outputs = {"pred_obj": obj_pred, # 模型预测的“有无物体”的原始分数"pred_cls": cls_pred, # 模型预测的“物体类别”的原始分数"pred_box": box_pred, # 模型预测的“边界框”的真实坐标"stride": self.stride, # 总步长(32),用于映射网格"fmp_size": fmp_size # 特征图尺寸,用于映射网格
}
return outputs
- 比喻:学习会开始了。我们不会把“成品”(经过后处理的结果)交给老师傅,而是把所有原始的学习材料打包好送过去。这个包裹里包含:
pred_obj:所有网格的“有没有物体”的原始考试答案(还没用Sigmoid打分)。pred_cls:所有网格的“属于哪个类别”的原始考试答案。pred_box:所有网格的“框在哪里”的原始考试答案(已解码成真实坐标)。stride和fmp_size:考试答案的索引和评分标准。老师傅需要知道哪个答案对应原图的哪个位置。
后续会发生什么?(为下一章铺垫)
这个 outputs 字典不会被直接用于显示,而是会立即送给两个非常重要的模块:
-
标签分配 (Label Assignment):
- 比喻:一位“标准答案分发员”。他会拿着“真实标签”(一张图里所有物体的真实位置和类别),和模型预测的
pred_box进行对比。 - 任务:决定
outputs清单里的哪一行预测应该负责检测哪一个真实物体。他会给清单里的某些行贴上“正样本”的标签(表示这些预测是好的、应该被鼓励的),给其他行贴上“负样本”的标签(表示这些预测是差的、应该被抑制的)。
- 比喻:一位“标准答案分发员”。他会拿着“真实标签”(一张图里所有物体的真实位置和类别),和模型预测的
-
损失函数 (Loss Function):
- 比喻:一位“严厉的老师傅”。
- 任务:他拿到
outputs(模型的原始答案)和“标签分配”的结果(哪些答案对应哪些标准答案)。 - 工作:他开始逐项批改试卷,计算:
pred_obj和“正负样本标签”之间的误差。pred_cls和“真实类别”之间的误差。pred_box和“真实框坐标”之间的误差。
- 输出:所有这些误差汇总成一个总分——损失值 (Loss)。这个分数直接反映了模型当前“错得有多离谱”。
这个损失值会反向传播回去,指导Backbone、Neck、Head等所有部门的工人(模型参数)如何调整自己的工作方式,以便在下一次“学习会”上能拿到更高的分数(更低的损失)。
总结
这段训练用的 forward 代码是模型自我学习和改进的核心。它:
- 不进行任何后处理(无阈值过滤,无NMS)。
- 输出原始、未加工的预测数据。
- 核心步骤是解码边界框,为计算损失做准备。
- 最终目的是为标签分配和损失计算提供所需的全部输入。
理解了这个流程,你就明白了YOLO是如何通过比较“预测”和“真实”之间的差距来实现自我优化的。
二、结束语
到此,我们获得了YOLOv1网络的搭建,并且实现了前向推理。但是,在推理的代码中还遗留了几个重要的问题尚待处理:
- 如何从边界框偏移量reg_pred解耦出边界框坐标box_pred?
- 如何实现后处理操作?
- 如何计算训练阶段的损失?
受篇幅限制,我们将这三个问题留到后续的章节中去一一解决。在本章,读者只需要学会搭建我们的YOLOv1网络、理清推理的代码逻辑即可,在脑海里,最好能构建出对于YOLOv1的整体架构的“图像”记忆。从下一节开始,我们将一一解决这遗留的三个问题。