OC-初识NSArray的底层逻辑
NSArray的底层逻辑
文章目录
- NSArray的底层逻辑
- 占位符
- init后的空数组
- 只有单个元素的NSArray
- 大于一个元素的NSArray
- 可变数组NSMutableArray
- 存储方式
- 类簇
- 遍历NSArray
- for循环
- 枚举
- for-in
- 多线程下的遍历方法
- 性能分析
- 分析
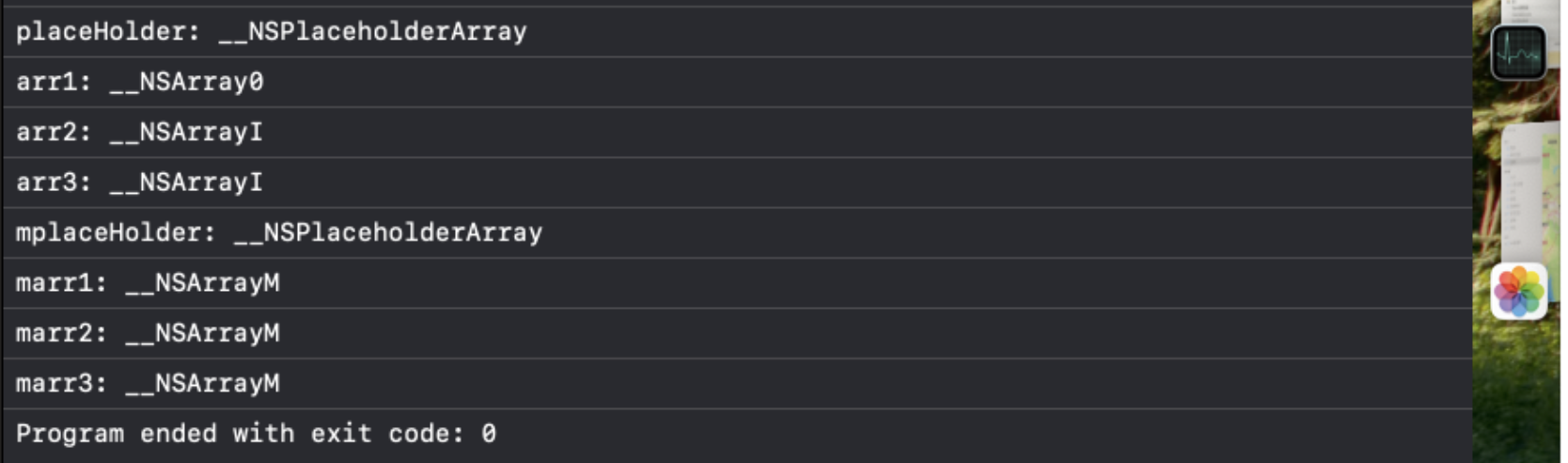
首先我们看一下下面这段代码的输出:
int main(int argc, const char * argv[]) {@autoreleasepool {NSArray* placeHolder = [NSArray alloc];NSArray* arr1 = [[NSArray alloc] init];NSArray* arr2 = [[NSArray alloc] initWithObjects:@1,nil];NSArray* arr3 = [[NSArray alloc] initWithObjects:@1, @2, nil];NSArray* arr4 = [[NSArray alloc] initWithObjects:@1, @2, @3,nil];NSLog(@"placeHolder: %s", object_getClassName(placeHolder));NSLog(@"arr1: %s", object_getClassName(arr1));NSLog(@"arr2: %s", object_getClassName(arr2));NSLog(@"arr3: %s", object_getClassName(arr3));NSMutableArray* mplaceHolder = [NSMutableArray alloc];NSMutableArray* marr1 = [[NSMutableArray alloc] init];NSMutableArray* marr2 = [[NSMutableArray alloc] initWithObjects:@1, nil];NSMutableArray* marr3 = [[NSMutableArray alloc] initWithObjects:@1, @2, nil];NSMutableArray* marr4 = [[NSMutableArray alloc] initWithObjects:@1, @2, @3, nil];NSLog(@"mplaceHolder: %s", object_getClassName(mplaceHolder));NSLog(@"marr1: %s", object_getClassName(marr1));NSLog(@"marr2: %s", object_getClassName(marr2));NSLog(@"marr3: %s", object_getClassName(marr3));}return 0;
}
占位符
根据上面的输出我们发现,NSArray和NSMutableArray的alloc结果都是获得一个名为_NSPlaceholderArray的类,顾名思义这个类就是用来进行占位的。
NSArray* placeHolder2 = [NSArray alloc];NSMutableArray* mplaceHolder2 = [NSMutableArray alloc];NSLog(@"placeHolder: %p", placeHolder);NSLog(@"placeHolder2: %p", placeHolder2);NSLog(@"mplaceHolder: %p", mplaceHolder);NSLog(@"mplaceHolder2: %p", mplaceHolder2);

我们输出一下地址发现,这两种占位符的地址是相同的.
当元素为空时,返回的是_NSArray0的单例;
为了区分可变与不可变类型,在init的时候,会根据是NSArray还是NSMutableArray来创建immutablePlaceHolder和mutablePlaceholder,这两种都是_NSPlaceholderArray类型的
init后的空数组
对于空的NSArray来说,由于NSArray是不可变的,也就是说空的NSArray只有一种(即单例),我们可以通过打印NSArray对象的引用计数值来判断。即调用对象的retainCount方法,注意需要关闭ARC。
如果输出一个非常大的数,那么就能说明这是一个单例类的对象了
只有单个元素的NSArray
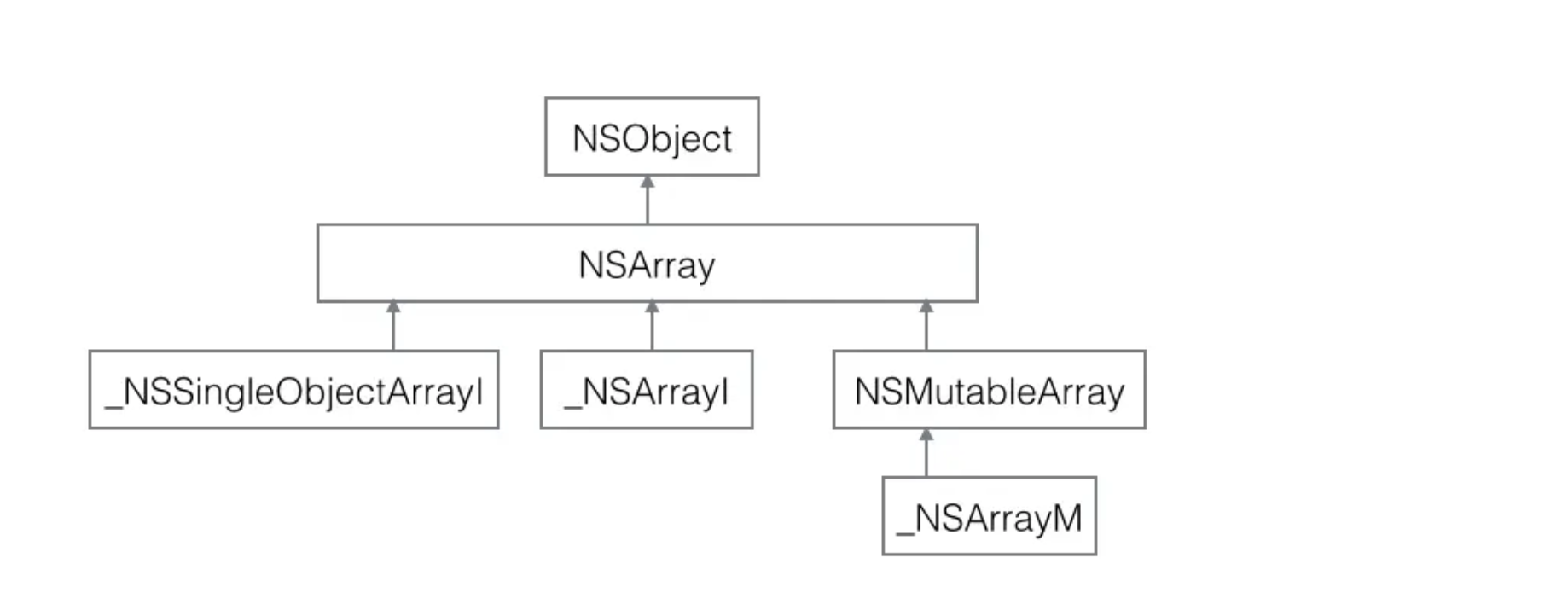
对于单个元素的NSArray的数组,我们打印出的类名是_NSSingleObjectArrayI,其结构体定义如下:
@interface __NSSingleObjectArrayI : NSArray {id Object;
}
大于一个元素的NSArray
对于大于一个元素的NSArray,输出的类名是__NSArrayI,其结构体定义如下:
@interface __NSArrayI : NSArray {NSUInteger _used;id _list[0];
}
其中的_used是数组元素的个数,调用数组的count方法时,返回的就是_used值。
其中的id_list[0]可以看成id*_list(在内存机制上还是有区别的),被称为柔性数组
当我们定义一个结构体,并在结构体末尾放置一个大小为0的数组时,编译器会将这个数组视为柔性数组,这个柔性数组的大小是在运行时根据需要动态分配内存来确定的。因此,通过访问结构体的柔性数组成员,实际上可以访问结构体后面的额外分配的内存空间,这样就能实现动态长度的数组
我们简单了解下柔性数组的注意事项:
- 内存是连续的,结构体系和数据在同一块连续内存中,malloc一次,free一次(如果使用指针来存储的话,结构体和数据是两块不连续的内存,需要malloc两次和free两次)
- 必须动态分配内存,柔性数组是不能在栈上定义的。
- 只需释放一次内存,结构体和柔性数组的内存是连续的
- 需要自己控制变量长度,避免出现数组越界的问题
可变数组NSMutableArray
通过上面的代码和运行结果我们可以发现,无论什么情况,我们alloc、init创建出的数组类名都是_NSArrayM,因为可变数组是可以随意添加和删除数据的,其结构体如下:
@interface __NSArrayM : NSMutableArray {NSUInteger _used; NSUInteger _offset;int _size:28;int _unused:4;uint32_t _mutations;id* _list;
}
可变数组的内部也是一块连续内存id* _list,正如__NSArrayI的id _ _list[0]一样。但是注意内存的连续状态
_used:当前对象数目
_offset:实际对象数组的起始偏移
_size: 已分配的 _ list大小(能储存的对象的个数)使用位域存储设计,用28比特位存储容量,最大可表示2^28-1个元素
mutations:修改标记,每次对 _NSArrayM的修改操作都会使 _mutations加1
id* list是一个循环数组,并且在增删操作时会动态地重新分配以符合当前的存储需求
_unused:预留的4位空间,为后面使用做准备
存储方式
_NSArrayM底层通过一块连续的线性内存模拟环形结构,我们可以将指向 _list的内存想象成一个首尾相接的圆环,元素从 _offset位置开始存储,当存储到内存末尾时,会绕到内存开头继续存储。(实际线性,模拟环形)
类簇
遍历NSArray
for循环
for (int i = 0; i < arr.count; i++) {id object = arr[i];
}
枚举
我们使用OC提供的枚举器实现便利数组
NSEnumrator* enumrator = [array objectEnumrator];
id object;
while (object = [enumrator nextObject]) { //执行相关操作
}
for-in
for (id object in array) {//执行相关操作
}
多线程下的遍历方法
[array enumrateObjectsWithOptions:NSEnumerationConcurrent usingBlock:^(id _Nonnull obj, NSUInteger idx, BOOL* _Nonnull stop){//
}];
NSArray提供该方法用于遍历数组中的所有对象。
-
参数Options:指定遍历的选项,Concurrent就是并发遍历
-
usingBlock:会在遍历过程中对数组中的每个元素执行。
- obj:当前元素
- idx:当前元素索引
- stop:是一个指向BOOL类型的指针,控制遍历是否停止,通过修改为YES终止遍历
系统会启动多个线程,并分配给每个线程一部份元素进行处理,这些线程在并发的方式下同时执行usingBlock,每个线程遍历不同元素,不必等待其他线程
性能分析
图示我们可以发现,随着数据的增多,不同遍历方式的性能差别愈发明显,我们觉得的并发遍历方式的耗时确实最高的,反而for-in遍历的性能比较好。
分析
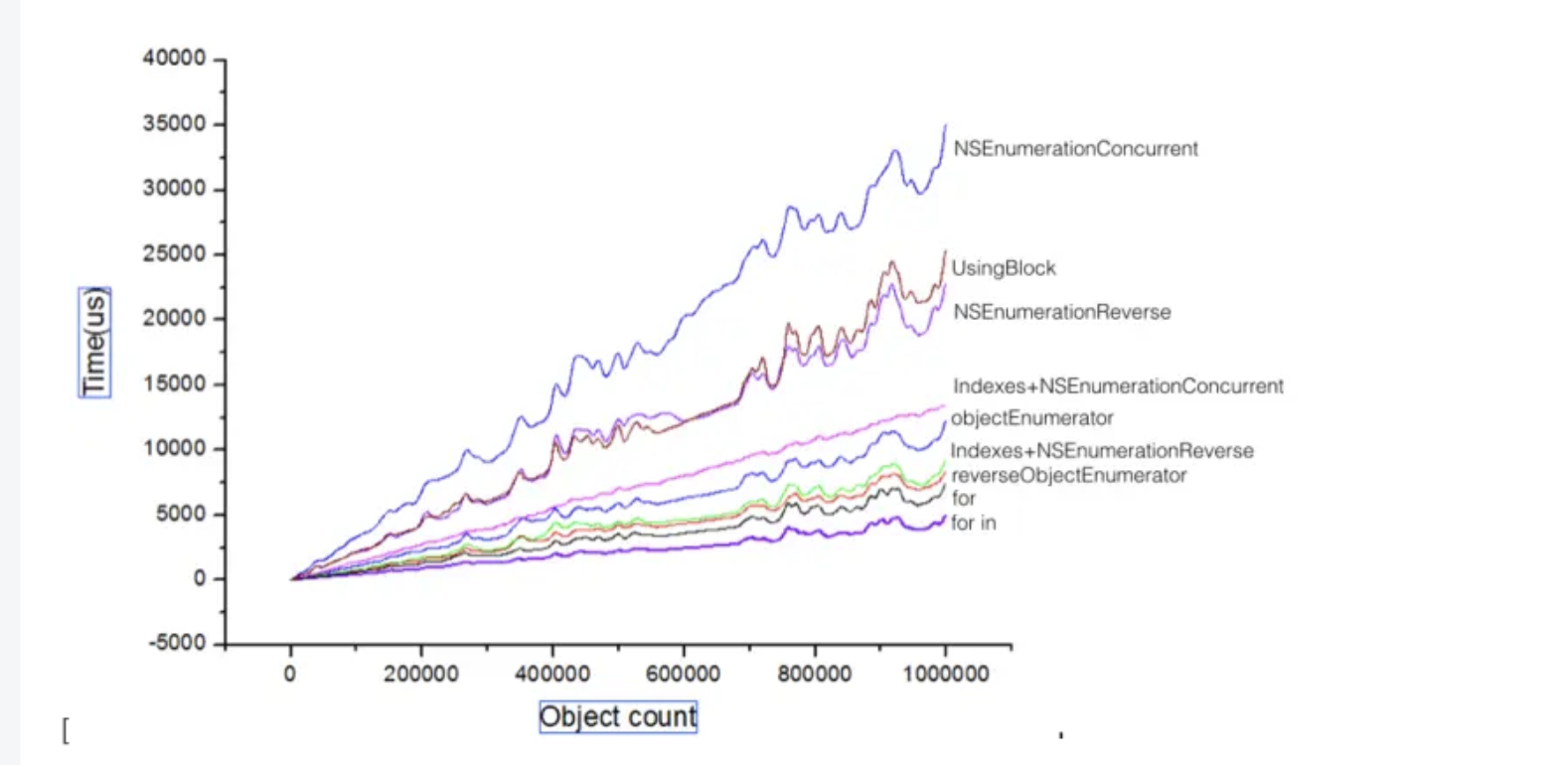
这里我们直接看结论:
- for-in:背后使用的是快速枚举机制(fast enumeration),在底层优化了迭代器,避免了传统for循环可能产生的开销
- 例如,NSArray数组会将元素保存在连续的内存块中,这样,CPU可以利用缓存局部性,提高访问速度。相对而言,传统的for循环需要进行复杂的索引计算,损失性能
- 在NSArray或者字典中,数据通常是顺序存储或者通过哈希表存储,以此来有效利用CPU缓存
- 使用引用传递避免不必要的对象拷贝,就是直接去访问对象。
- 对于多线程的并发遍历方法,虽然在大量数据下性能消耗很大,但是其采用了多线程,这分担了主线程的压力,并且在需要对元素进行复杂处理的情况是非常合适。
由于笔者的能力有限,在学长的博客中学到了这些知识,对于更深层的内容等后面有能力了再继续拓展