jupyter notebook用简易python代码跑本地模型
- python代码
# ========== 1. Rule-Based(原始版) ==========
def rule_based_sentiment(text):positive_words = ["good", "great", "happy", "love"]negative_words = ["bad", "sad", "terrible", "hate"]text = text.lower()if any(word in text for word in positive_words):return "Positive"elif any(word in text for word in negative_words):return "Negative"else:return "Neutral"print("Rule-Based (orig):", rule_based_sentiment("I love NLP but hate math!"))# ========== 2. Rule-Based(改进版:计数) ==========
def rule_based_sentiment_improved(text):positive_words = ["good", "great", "happy", "love"]negative_words = ["bad", "sad", "terrible", "hate"]text = text.lower()pos_count = sum(word in text for word in positive_words)neg_count = sum(word in text for word in negative_words)if pos_count > neg_count:return "Positive"elif neg_count > pos_count:return "Negative"else:return "Neutral"print("Rule-Based (improved):", rule_based_sentiment_improved("I love NLP but hate math!"))# ========== 3. Naive Bayes(不变) ==========
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNBtexts = ["I love NLP", "This is great", "I hate this", "This is terrible"]
labels = ["Positive", "Positive", "Negative", "Negative"]vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
model = MultinomialNB()
model.fit(X, labels)print("Naive Bayes:", model.predict(vectorizer.transform(["I love this project"]))[0])# ========== 4. Transformer(显式指定模型,消除警告) ==========
from transformers import pipelinesentiment_model = pipeline("sentiment-analysis",model="D:\hf\SmolLM3-3B"
)result = sentiment_model("I love NLP but hate math!")
print("Transformer:", result[0]['label'])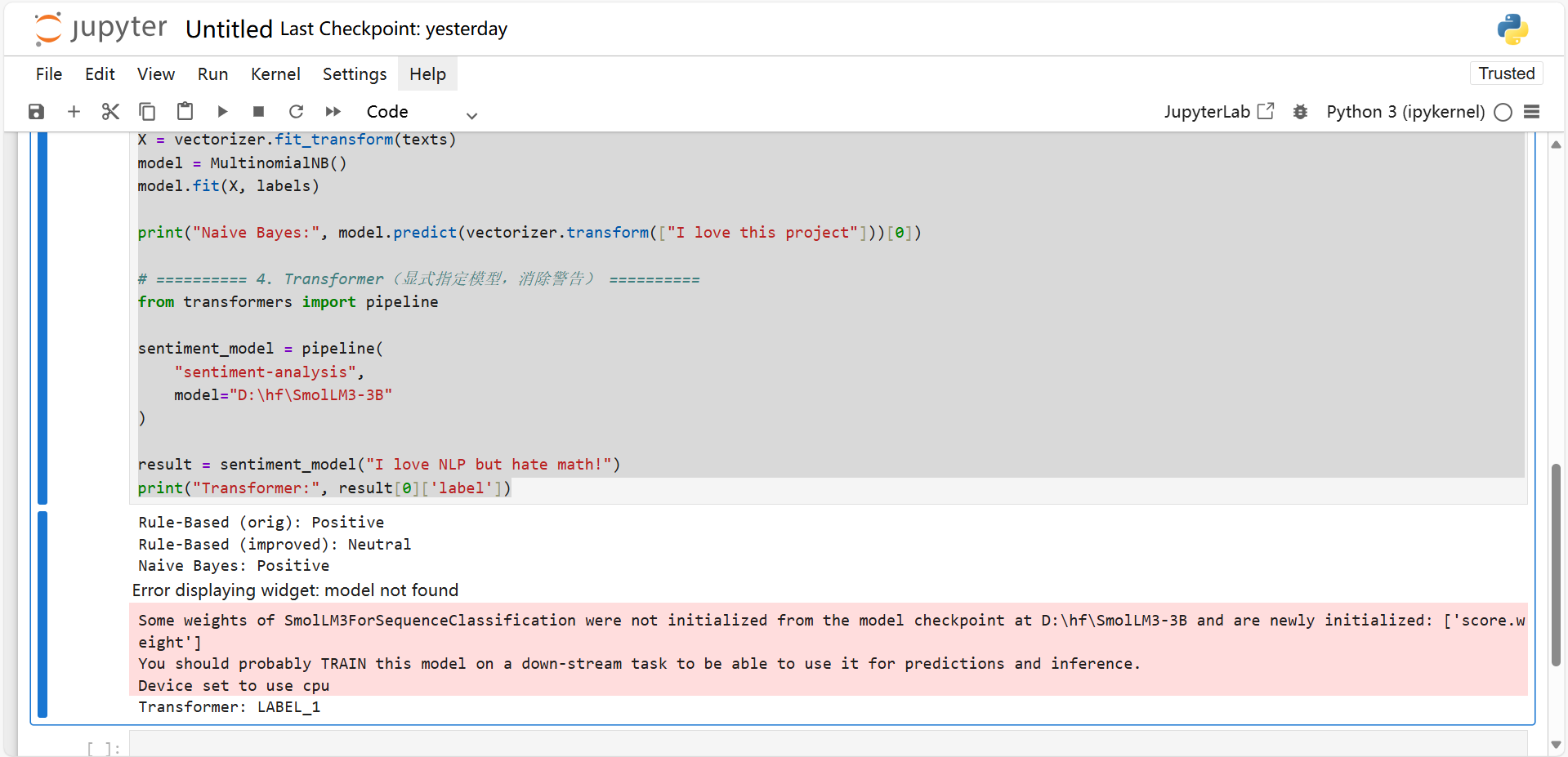
- 下载相关模块
python -m pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simplepip install transformerspip install Torch- 拉取模型
pip install -U huggingface_hub
huggingface-cli download <模型名称> ^--local-dir <本地路径> ^--local-dir-use-symlinks False- 模型名称在下面网址查询
hugging face 官网
hugging face 国内镜像站点如果官网不稳定无法进入
- 问题
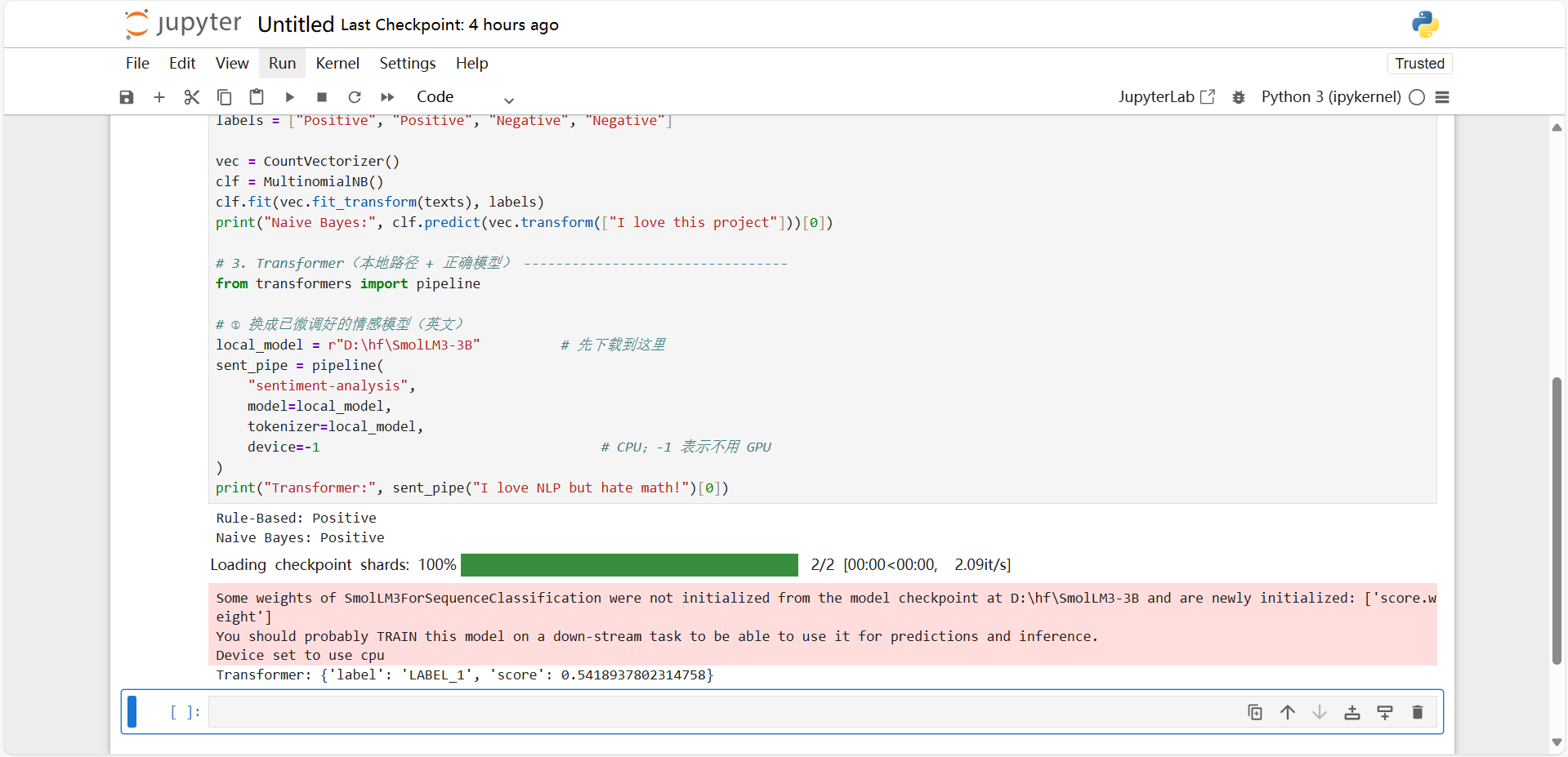
原因:模型不匹配,笔者下载的SmolLM3-3B模型并不是专门做情感微调的模型,这里可以看到代码成功调用本地SmolLM3-3B模型但出现警告。
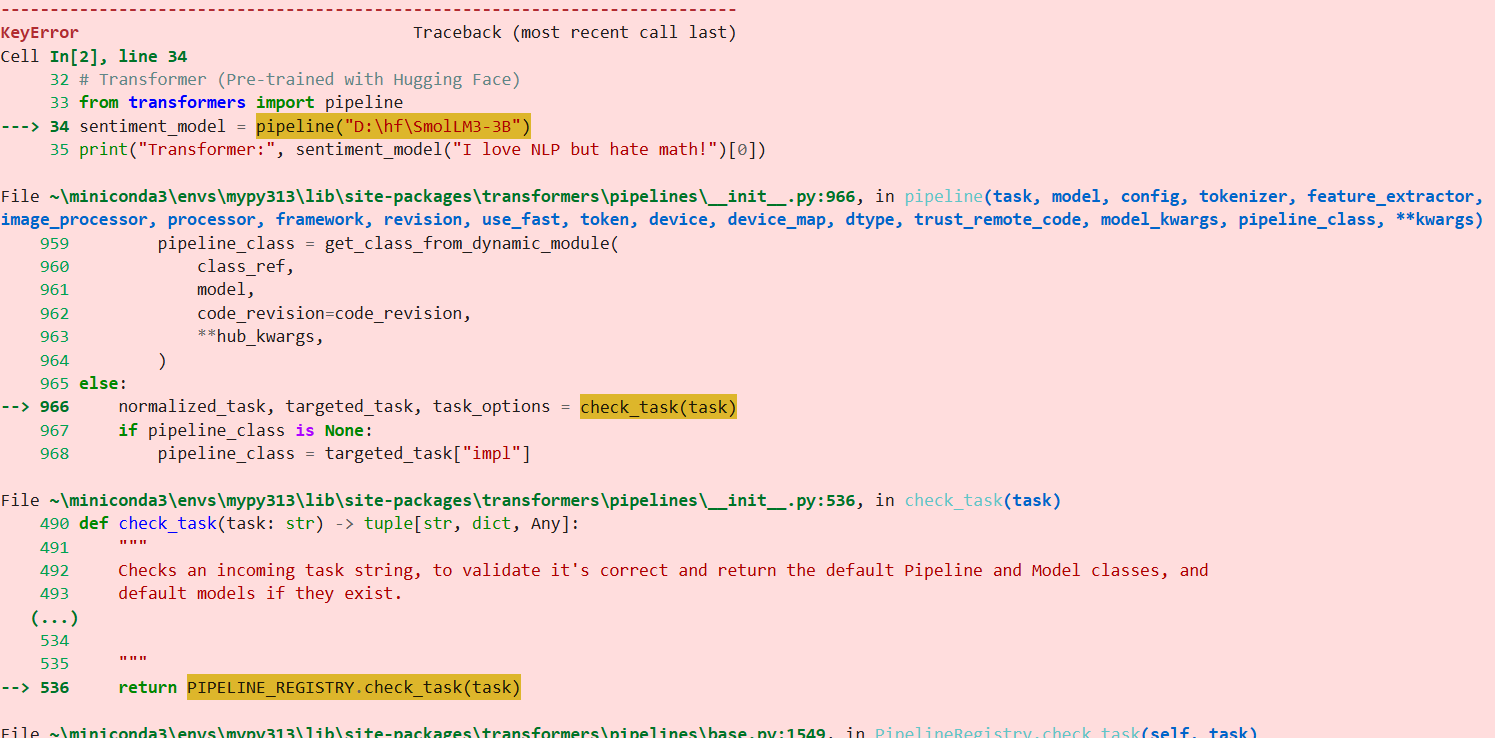
原因:无法成功链接模型,出现此处问题的python代码如下:
def rule_based_sentiment(text):positive_words = ["good", "great", "happy", "love"]negative_words = ["bad", "sad", "terrible", "hate"]text = text.lower()if any(word in text for word in positive_words):return "Positive"elif any(word in text for word in negative_words):return "Negative"else:return "Neutral"print("Rule-Based:", rule_based_sentiment("I love NLP but hate math!"))# Statistical (Naive Bayes)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB# Training Data
texts = ["I love NLP", "This is great", "I hate this", "This is terrible"]
labels = ["Positive", "Positive", "Negative", "Negative"]vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)model = MultinomialNB()
model.fit(X, labels)print("Naive Bayes:", model.predict(vectorizer.transform(["I love this project"]))[0])# Transformer (Pre-trained with Hugging Face)
from transformers import pipeline
sentiment_model = pipeline("sentiment-analysis")
print("Transformer:", sentiment_model("I love NLP but hate math!")[0])![]()
此处是下载本地时可能会出现的警告:huggingface-cli download 已经被废弃,请使用hf download下载
结语:朝乾夕惕,功不唐捐,玉汝于成