点云-标注-分类-航线规划软件 (一)点云自动分类
在点云-标注-分类-航线规划软件,除了支持人工手动标注以外,系统还支持点云自动分类功能:
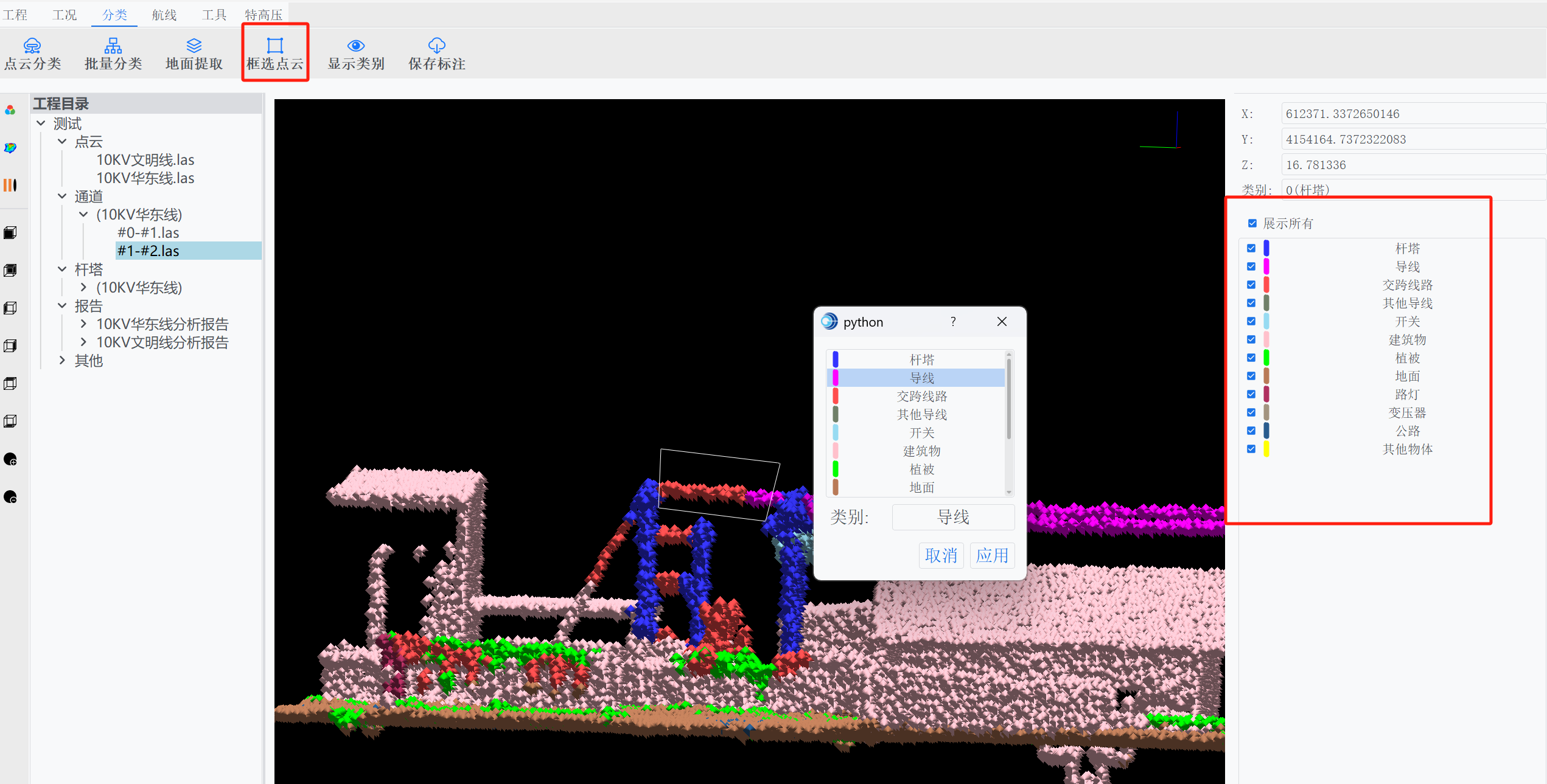
具体的,使用的点云分类算法为RandLa-Net,该网络模型介绍如下:
三维点云语义分割作为计算机视觉与遥感感知领域的核心任务之一,旨在为无序、非结构化的点云数据中每一个点赋予语义类别标签。在电力巡检、智能电网、基础设施建模等工程场景中,该技术可实现对输电线路关键部件(如杆塔、导线、绝缘子)及周边环境要素(如植被、房屋、地面)的自动化识别与空间定位,具有重要的工程应用价值。
然而,传统基于深度学习的点云分割方法(如 PointNet++ 、KPConv 、PointCNN [)在处理大规模点云时,普遍存在计算复杂度高、内存占用大、推理效率低等问题,难以满足工业级实时处理需求。为此,Hu 等人于 CVPR 2020 提出 RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds,通过引入随机采样策略与局部特征注意力聚合机制,在保持较高分割精度的同时,显著提升模型推理效率,成为当前工业级点云处理的代表性轻量化架构。
网络架构与核心原理
RandLA-Net 采用编码器-解码器(Encoder-Decoder)架构,其整体网络结构如下:
整体网络结构
网络包含 4 层编码器与 4 层解码器,每层执行:
- 随机采样(下采样率 4×)
- LocSE + Attentive Pooling 特征提取
- MLP 升维
解码阶段采用**三线性插值(Trilinear Interpolation)**上采样,并通过跳跃连接(Skip Connection)融合低层几何细节与高层语义信息,最终输出逐点语义概率分布。
输入:N × (3 + C),C 为额外通道数(如强度、RGB)
输出:N × K,K 为语义类别数(如杆塔、导线、植被、房屋等)
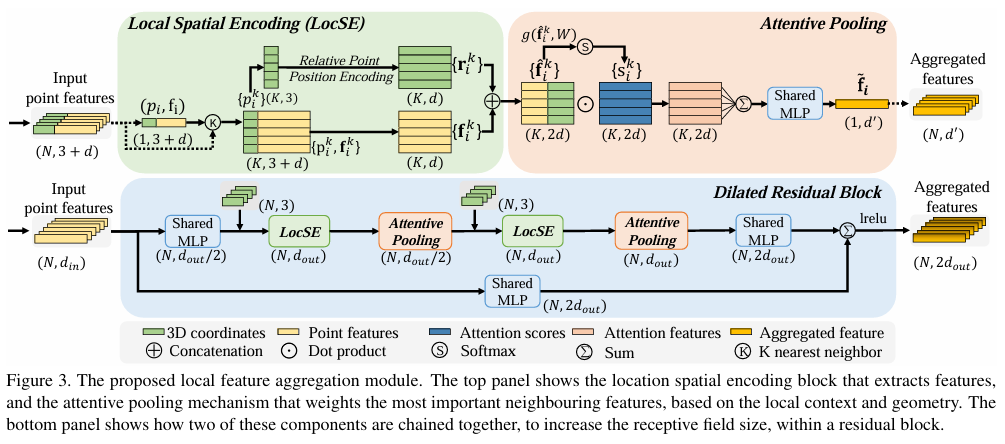
RandLaNet的核心创新体现在以下三方面:
随机采样下采样策略(Random Sampling)
传统方法广泛采用最远点采样(Farthest Point Sampling, FPS)以保证采样点的空间均匀性,但其时间复杂度为 O(n²),在大规模点云中成为性能瓶颈。RandLA-Net 创新性地采用**均匀随机采样(Uniform Random Sampling)**作为下采样策略,将采样复杂度降至 O(1),极大提升处理效率。
理论补偿机制:虽牺牲理论最优的空间覆盖性,但通过后续局部特征增强模块(LocSE + Attentive Pooling)弥补信息损失,实验证明在多个基准数据集(Semantic3D, SemanticKITTI, S3DIS)上精度损失可忽略(<0.5% mIoU),而速度提升达 200 倍以上。
局部空间编码模块(Local Spatial Encoding, LocSE)
为缓解随机采样导致的局部几何结构信息丢失,RandLA-Net 引入 LocSE 模块,对每个中心点 p_i 及其 k 个近邻点 {p_j},计算其相对空间位移向量:
Δp_ij = [x_j - x_i, y_j - y_i, z_j - z_i, ||p_j - p_i||₂]
该四维向量经多层感知机(MLP)映射后,与原始点特征拼接,形成增强后的局部空间感知特征。该机制显式建模点间相对位置关系,提升网络对细长结构(如导线)、垂直结构(如杆塔)等电力设施的空间敏感性。
注意力池化聚合(Attentive Pooling)
在特征聚合阶段,传统方法多采用最大池化(Max Pooling)或平均池化(Average Pooling),忽略邻域点贡献的差异性。RandLA-Net 设计注意力权重机制,对每个邻域点 p_j 学习其相对于中心点 p_i 的重要性权重 α_ij:
α_ij = softmax(MLP([f_i, f_j, Δp_ij]))
f_i' = Σ_j (α_ij ⋅ f_j)
其中 f_i, f_j 为点特征,Δp_ij 为 LocSE 输出。该机制实现自适应邻域特征加权聚合,有效抑制噪声点干扰,增强对关键结构点(如金具连接处、绝缘子串端点)的特征表达能力。
具体实现
那么,这个网络具体是如何使用的呢,在单机版分类软件中,为了使软件能够稳定运行,我们采用了一种流式处理的方式来进行点云分类,简单来讲,就是通过流式读取点云(每次读取100000个点)然后进行累积,当点云的大小达到一个G时,我们再将点云输入到模型中进行推理,这样做的好处是能够让一些性能稍弱的电脑也能够正常使用:
def process_large_las_streaming(file_path, output_dir, target_size_gb=1, chunk_size=1000000,db_utils=None):temp_files = []try:Path(output_dir).mkdir(parents=True, exist_ok=True)temp_output_dir = Path(output_dir) / "temp"temp_output_dir.mkdir(parents=True, exist_ok=True)avg_point_size = 32 # 这里可以考虑使用更精确的方法来估计单个点的大小target_point_count = int(target_size_gb * 1024**3 / avg_point_size)processed_points = 0total_points = 0with laspy.open(file_path) as reader:header = copy_header(reader.header)if header.point_count > 0:total_points = header.point_countelse:print("Warning: Header point count is 0. Estimating total points from chunks.")combined_obj = LasObj()for points in reader.chunk_iterator(chunk_size):# 将当前块的数据添加到 combined_obj 中combined_obj.x = np.concatenate((combined_obj.x, points.x))combined_obj.y = np.concatenate((combined_obj.y, points.y))combined_obj.z = np.concatenate((combined_obj.z, points.z))combined_obj.classification = np.concatenate((combined_obj.classification, points.classification))if hasattr(points, 'red'):combined_obj.red = np.concatenate((combined_obj.red, points.red))combined_obj.green = np.concatenate((combined_obj.green, points.green))combined_obj.blue = np.concatenate((combined_obj.blue, points.blue))processed_points += len(points)if len(combined_obj.x) >= target_point_count or (total_points > 0 and processed_points >= total_points):# 更新头部信息中的点数temp_header = copy_header(header)temp_header.point_count = len(combined_obj.x)# 推理分类labels = inference_api.pd_inference(combined_obj)belong_file="1Points/"+os.path.basename(file_path)cut_points = db_utils.select("cuts", where_clause="belong_file = ?", params=(belong_file,),order_by="CAST(name AS INTEGER) ASC")points_data = [(float(row[2]), float(row[3]), float(row[4])) for row in cut_points] # xyz分别对应第2,3,4个字段towers = np.array(points_data)protected_labels = {4,9,} # 示例需要保护的标签(如卷子、变压器)# 优化分类points_mine = np.column_stack((combined_obj.x, combined_obj.y, combined_obj.z))labels=process_point_cloud_with_boxes(points_mine,labels,towers)#处理导线labels =optimize_classification(points_mine, labels, towers, grid_size=1.0, tower_radius=1.0, protected_labels=protected_labels)#处理杆塔#labels=refine_labels_by_knn(points_mine,labels)combined_obj.classification = labels# 保存到临时文件temp_file = temp_output_dir / f"{Path(file_path).stem}_{processed_points}.las"save_to_las(combined_obj, str(temp_file), temp_header)temp_files.append(temp_file)print(f"Progress: {processed_points}/{total_points if total_points > 0 else 'unknown'} points processed.")combined_obj = LasObj()# 处理剩余的点云数据if len(combined_obj.x) > 0:temp_header = copy_header(header)temp_header.point_count = len(combined_obj.x)labels = inference_api.pd_inference(combined_obj)combined_obj.classification = labelstemp_file = temp_output_dir / f"{Path(file_path).stem}_{processed_points}.las"save_to_las(combined_obj, str(temp_file), temp_header)temp_files.append(temp_file)print(f"Progress: {processed_points}/{total_points if total_points > 0 else 'unknown'} points processed.")# 在合并时覆盖原始文件merge_temp_files_with_laspy(temp_files, file_path)except Exception as e:print(f"Error processing file: {e}")raisefinally:for temp_file in temp_files:if temp_file.exists():temp_file.unlink()
在上述方法中,可大致分为 预处理(即划分1GB点云)、模型推理以及后处理三个过程,其中模型推理的代码如下:
labels = inference_api.pd_inference(combined_obj)
该方法传入的是一个lasObj,具体实现如下:
def pd_inference(lasObj):print('tf 开始推理')time1 = time.time()chosen_snap_0 = resource_path('resources/pd_model/model0/snap-177.meta')chosen_snap_1 = resource_path('resources/pd_model/model1/snap-45.meta')chosen_snap_2 = resource_path('resources/pd_model/model2/snap-94.meta')pred = tester_service.runner(lasObj, chosen_snap_0,chosen_snap_1, chosen_snap_2)time2 = time.time()print(f'tf 推理结束,本次推理共用时 {time2 - time1}s')return pred
runner方法定义如下,我们发现RandLaNet一次性预测所有类别时,其效果不理想,因此采用分段式预测的方式,即首先预测植被和其他物体,随后将其他物体的点云提取出来,放入第二个模型,第二个模型负责预测电力物、建筑物、公路以及地面,随后再将电力物点云提取出来,送入第三个模型,负责细分电力物,如导线、杆塔等,最终,将分类后的点云按照对应的ID(索引)赋值对应的类别即可。
def runner(las_file, chosen_snap_0,chosen_snap_1, chosen_snap_2):tf.logging.set_verbosity(tf.logging.ERROR)# 定义类别映射字典res_dict = {'tower': 0, # 杆塔'wire': 1, # 导线'cross_wire': 2, # 交叉导线'other_wire': 3, # 其他导线'swich': 4, # 开关'building': 5, # 建筑物'plant': 6, # 植被'ground': 7, # 地面'lantern': 8, # 路灯'transformer': 9, # 变压器'road': 10, # 公路'otherthing': 11 # 其他物体}# 模型0的类别映射:将点云分为“其他”和“植被”label_to_names_0 = {0: 'other', # 其他1: 'plant' # 植被}# 模型1的类别映射:将“其他”类别进一步分类为“电力物”、“建筑物”、“公路”等label_to_names_1 = {0: 'power', # 电力物1: 'building', # 建筑物2: 'ground', # 地面3: 'road' , # 公路}# 模型2的类别映射:将“电力物”类别细分为具体的电力相关类别label_to_names_2 = {0: 'tower', # 杆塔1: 'wire', # 导线2: 'other_wire', # 其他导线3: 'swich', # 开关4: 'lantern', # 路灯5: 'transformer', # 变压器6: 'otherthing' # 其他物体}# 清空会话tf.keras.backend.clear_session()# 读取点云数据并归一化pointcloud_arr = np.vstack((las_file.x, las_file.y, las_file.z)).transpose()points_arr = pointcloud_arrx_min = pointcloud_arr[:, 0].min()y_min = pointcloud_arr[:, 1].min()z_min = pointcloud_arr[:, 2].min()points_arr[:, 0] -= x_minpoints_arr[:, 1] -= y_minpoints_arr[:, 2] -= z_min# 加载配置文件config = read_yaml_config(resource_path("configs/configs.yaml"))parameter0 = config.get('parameter0') # 模型0的参数parameter1 = config.get('parameter1') # 模型1的参数parameter2 = config.get('parameter2') # 模型2的参数# =============================== 模型0推理 ===============================# 模型0任务:将点云分为“其他”和“植被”data_0, preds_0 = model_test("peidian_0", cfg0, points_arr, label_to_names_0, len(label_to_names_0), chosen_snap_0,sub_grid_size=parameter0)# 提取出“其他”类别的点云送入模型1preds_ind_other = np.where(preds_0 == 0)[0] # “其他”类别的索引other_data = data_0[preds_ind_other]# =============================== 模型1推理 ===============================# 模型1任务:将“其他”类别进一步分类为“电力物”、“建筑物”、“公路”等tf.keras.backend.clear_session()data_1, preds_1 = model_test("peidian_1", cfg1, other_data, label_to_names_1, len(label_to_names_1), chosen_snap_1,sub_grid_size=parameter1)# 提取出“电力物”类别的点云送入模型2preds_ind_power = np.where(preds_1 == 0)[0] # “电力物”类别的索引power_data = data_1[preds_ind_power]# =============================== 模型2推理 ===============================# 模型2任务:将“电力物”类别细分为具体的电力相关类别tf.keras.backend.clear_session()data_2, preds_2 = model_test("peidian_2", cfg2, power_data, label_to_names_2, len(label_to_names_2), chosen_snap_2,sub_grid_size=parameter2)# =============================== 合并结果 ===============================# 初始化最终结果为模型0的预测结果pred_result = copy.deepcopy(preds_0)# 将模型0的“其他”类别替换为模型1和模型2的预测结果for label_1 in label_to_names_1:idx_in_preds_1 = np.where(preds_1 == label_1)[0] # 模型1中属于该类别的索引if label_to_names_1[label_1] == 'power': # 如果是“电力物”类别,继续替换为模型2的结果for label_2 in label_to_names_2:idx_in_preds_2 = np.where(preds_2 == label_2)[0] # 模型2中属于该类别的索引pred_result[preds_ind_other[preds_ind_power[idx_in_preds_2]]] = res_dict[label_to_names_2[label_2]]else:# 将模型1的非“电力物”类别直接映射到最终结果pred_result[preds_ind_other[idx_in_preds_1]] = res_dict[label_to_names_1[label_1]]# 将模型0的“植被”类别映射到最终结果idx_plant = np.where(preds_0 == 1)[0]pred_result[idx_plant] = res_dict['plant']del data_1del data_2gc.collect()return pred_result
至于具体的网络推理代码,我这里就不再赘述了,大家可以下载 RandLaNet 的源码自行了解,至此,便介绍完了点云的自动分类流程,随后,会进行后处理过程,该过程则是通过机器学习的方式,对分类结果进行进一步的优化。
码字不易,给个赞呗!