ELK大总结20250922
1 ELK 概述
ELK 是一套用于日志收集、存储、分析和可视化的开源技术栈,由 Elasticsearch、Logstash、Kibana 三个核心组件的首字母组成,目前官方已将其更名为Elastic Stack,但 “ELK” 的称呼仍被广泛使用。
🔧 ELK 三大核心组件的作用
三个组件分工明确、协同工作,形成完整的日志处理流程:
- Logstash:日志收集与预处理作为 “日志搬运工”,负责从多源(如服务器、应用、数据库)采集日志,进行过滤、清洗、格式转换(如 JSON 化)等预处理,再将标准化后的日志发送到 Elasticsearch 存储。
- Elasticsearch:日志存储与检索基于 Lucene 的分布式搜索引擎,负责存储所有预处理后的日志数据,支持毫秒级的全文检索和复杂查询,能快速定位特定日志(如报错日志、特定用户行为日志)。
- Kibana:日志可视化与分析作为 “可视化面板”,提供图形化界面(如折线图、柱状图、仪表盘),将 Elasticsearch 中的日志数据转化为直观报表,支持实时监控、异常告警、自定义分析视图(如服务器 CPU 使用率趋势、应用报错频次统计)。
📌 ELK 的典型应用场景
ELK 本质是解决 “日志分散难管理、出问题难排查” 的痛点,常见场景包括:
- 服务器 / 应用监控:集中查看多台服务器的系统日志、应用运行日志,快速定位故障(如 Java 应用的 NullPointerException)。
- 业务数据分析:分析用户行为日志(如点击、下单、访问路径),统计转化率、热门功能等业务指标。
- 安全审计:收集防火墙、数据库的操作日志,监控异常行为(如多次失败的登录尝试、未授权的数据访问)。
✨ 扩展:ELK 的常见补充组件
为适配更复杂的场景,ELK 常搭配其他工具使用:
- Filebeat:轻量级日志采集器,替代 Logstash 部署在资源有限的服务器上(如边缘节点),占用内存低,更适合大规模集群的日志采集。
- Beats 家族:除 Filebeat 外,还有 Metricbeat(采集系统 / 应用指标)、Packetbeat(采集网络数据包)等,丰富数据采集类型。
- Elastic APM:应用性能监控工具,与 ELK 联动,分析应用的响应时间、接口调用耗时等性能数据。
1.Elasticsearch
| Elasticsearch 概念 | 传统数据库对应概念 | 作用说明 |
|---|---|---|
| Index(索引) | Database(数据库) | 存储一类相似数据的集合(如 “服务器日志索引”“电商商品索引”),每个索引有独立的配置和分片策略。 |
| Type(类型) | Table(表) | 早期用于区分索引内的不同数据类型(如 “商品索引” 内的 “电子产品”“服装”),ES 7.0 后已被移除,推荐一个索引对应一种数据类型。 |
| Document(文档) | Row(行) | 索引内的最小数据单元,以 JSON 格式存储(如一条服务器日志、一个商品信息),每个文档有唯一的_id标识。 |
| Field(字段) | Column(列) | 文档内的具体属性(如 “日志时间”“商品价格”),ES 会自动识别字段类型(如文本型、数值型、日期型),也可手动定义。 |
| Shard(分片) | - | 索引的 “分块”,将大索引拆分为多个小分片分布在不同节点,实现并行存储和查询,提升性能。 |
| Replica(副本) | - | 分片的 “备份”,用于故障恢复和负载分担(查询请求可分发到副本节点),副本数量可手动配置。 |
1.部署和管理
Elasticsearch 基于 Java 语言实现

[root@es-node1 ~]#echo "fs.file-max = 1000000" >> /etc/sysctl.conf
[root@node1 ~]#cat /usr/lib/sysctl.d/elasticsearch.conf
2.安装Elasticsearch
https://www.elastic.co/cn/downloads/elasticsearch
[root@ubuntu2404 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-9.0.4-amd64.deb #安装部署elasticsearch
........
........
3.编辑配置文件
注意编辑的时候要备份原来的配置文件,以免修改不顺利!!!
#ELK集群名称,单节点无需配置,同一个集群内每个节点的此项必须相同,新加集群的节点
此项和其它节点相同即可加入集群,而无需再验证
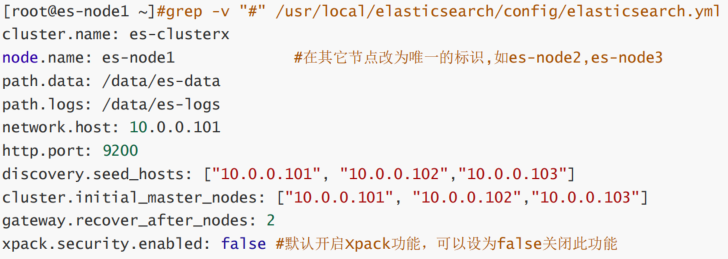
cluster.name: ELK-Cluster #当前节点在集群内的节点名称,同一集群中每个节点要确保此名称唯一
node.name: es-node1 #ES 数据保存目录,包安装默认路径:/var/lib/elasticsearch/,生产建议修改
path.data: /data/es-data #ES 日志保存目录,包安装默认路径:/var/log/elasticsearch/,生产建议修改
path.logs: /data/es-logs#服务启动的时候立即分配(锁定)足够的内存,防止数据写入swap,提高启动速度,但是true可以
会导致启动失败,需要优化
bootstrap.memory_lock: true#指定该节点用于集群的监听IP,默认监听在127.0.0.1:9300,集群模式必须修改此行,单机默认即可
network.host: 0.0.0.0 #指定HTTP的9200/TCP的监听地址,默认127.0.0.1
http.host: 0.0.0.0#监听端口
http.port: 9200#发现集群的node节点列表,可以添加部分或全部节点IP
#在新增节点到已有集群时,此处需指定至少一个已经在集群中的节点地址,给予可用性,一般添加
所有节点地址
discovery.seed_hosts: ["10.0.0.101","10.0.0.102","10.0.0.103"]#集群初始化时指定希望哪些节点可以被选举为 master,只在初始化时使用,新加节点到已有集群时此项可不配置
cluster.initial_master_nodes: ["10.0.0.101","10.0.0.102","10.0.0.103"]#一个集群中的 N 个节点启动后,才允许进行数据恢复处理,默认是1,一般设为所有节点的一半以上,防止出
现脑裂现象,当集群无法启动时,可以将之修改为1,或者将下面行注释掉,实现快速恢复启动
gateway.recover_after_nodes: 2#设置是否可以通过正则表达式或者_all匹配索引库进行删除或者关闭索引库,默认true表示必须需要明确指
定索引库名称,不能使用正则表达式和_all,生产环境建议设置为 true,防止误删索引库。
action.destructive_requires_name: true简言之上图总结如下显示
#必须分配权限,否则服务无法启动
[root@es-node1 ~]# chown -R elasticsearch.elasticsearch /data/
4.验证端口监听成功
#9200端口集群访问端口,9300集群同步端口
[root@es-node1 ~]#ss -ntlp|grep java
LISTEN 0 128 *:9200 *:*
users:(("java",pid=2372,fd=225))
LISTEN 0 128 *:9300 *:*
users:(("java",pid=2372,fd=211))
2.Logstash
| 阶段(Stage) | 核心作用 | 常见插件示例 |
|---|---|---|
| Input(输入) | 从各种数据源采集数据 | - file:读取服务器本地日志文件(如 Nginx、Linux 系统日志)- beats:接收 Filebeat 等轻量采集器的数据(分布式场景常用)- kafka:从 Kafka 消息队列拉取数据- tcp/udp:接收网络端口传输的日志 |
| Filter(过滤) | 对数据进行清洗、转换、提取 | - grok:解析非结构化日志(如把 “时间 + IP + 请求” 的字符串拆成字段)- mutate:修改字段(添加、删除、重命名、类型转换)- date:统一时间字段格式(适配 Elasticsearch 时间索引)- drop:过滤掉无用数据(如排除测试环境日志) |
| Output(输出) | 将处理后的数据发送到目标系统 | - elasticsearch:输出到 Elasticsearch(ELK 标准流程)- file:输出到本地文件- kafka:写入 Kafka 供其他系统消费- stdout:打印到控制台(调试时常用) |